AI修图到底有多强?
前几日,Adobe Max 大会刚刚结束,Photoshop 2021版便登上了国外各大媒体版面。
其原因是,新版Ps工具中内置了AI驱动工具,诸如“天空置换”等高难度修图问题,现在点点鼠标就可以轻松实现,而且效果远超手动操作。
无论是拍人拍景或是其他,“天空”都可以说是摄像中的关键元素。比如,一张平平无奇的景色图加上落日余晖的天空色调,是不是有内味了?

对于短视频爱好者来说,如果也能达到如此处理效果岂不是更佳?
没错,今天小编就是要给大家介绍一款基于原生视频的AI处理方法,不仅可以一键切置换天空背景,还可以打造任意“天空之城”。
AI视频修复新玩法
这项AI处理方法来自密歇根大学的一位华人博士后的最新研究。该方法基于视觉技术可一键调整视频中的天空背景和天气转换。
比如,《星际迷航》等科幻电影中经常出现的浩瀚星空、宇宙飞船,也可以利用这项技术融入随手拍的视频中。

公路片秒变科幻片,画面毫无违和感。
视频中的蓝色的天空背景也随飞船变成了灰蒙蒙的色调,一种世界末日的即视感有木有?

当然它的玩法还不止如此。
动漫迷也可以创建自己的移动城堡。喜欢《天空之城》《哈尔的移动城堡》的朋友应该对这一幕应该非常熟悉。

又或者在视频中挂一个超级月亮,又是另一番景象。

好像只要脑洞够大,利用这项AI技术,视频创作就有无限种玩法。
另外,它还具备天气转换的功能,比如晴空万里、阴雨绵绵、雷雨交加等各种天气都可以在视频中随意切换。


喜欢玩Vlog的朋友听着是不是非常心动了?研究人员表示,现在已经在考虑将其制作成插件/脚本的形式,方便相关从业者或行业使用。
在此之前,这项技术的AI代码已经在Github开源,懂技术的朋友可以优先安装体验了~

Github地址:https://github.com/jiupinjia/SkyAR
技术原理
不同于传统研究,研究人员提出了一种完全基于视觉的解决方案。它的好处就是可以处理非静态图像,同时不受拍摄设备的限制,也不需要用户交互,可以处理在线或离线视频。
上述实验视频,均是通过手持智能手机和行车记录仪在野外拍摄的。经过该方法处理后,其在视频质量、运动动态、照明转换方面都达到了较高的保真度。比如在浮动城堡,超级月亮样例中,使用单个NVIDIA Titan XP GPU卡,该方法可以在输出分辨率为640 x 320时达到24 fps的实时处理速度,在854 x 480时达到接近15 fps的实时处理速度。
具体来说,该方法分为三个核心模块:
天空遮罩框架(Sky Matting Network):用于检测视频帧中天空区域的视频框架。该框架是采用了基于深度学习的预测管道,能够产生更精确的检测结果和更具视觉效果的天空蒙版。
运动估计(Motion Estimation):用于恢复天空运动的运动估计器。天空视频需要在真实摄像机的运动下进行渲染和同步。
图像融合(Image Blending):用于将用户指定的天空模板混合到视频帧中的Skybox。除此之外,还用于重置和着色,使混合结果在其颜色和动态范围内更具视觉逼真感。
完整框架如下图:
天空遮罩框架:利用深卷积神经网络(CNN)的优势,在一个像素级回归框架下对天空冰雹进行预测,该框架可以产生粗尺度和细尺度的天空蒙版。天空遮罩框架由一个分段编码器( Segmentation Encoder )、一个掩模预测解码器(Mask Prediction Decoder)和一个软细化模块(Soft Refinement Module)组成。其中,编码器的目的是学习下采样输入图像的中间特征表示。解码器被用来训练和预测粗糙的天空。优化模块同时接收粗糙的天空蒙版和高分辨率输入,并生成一个高精度的天空蒙版。
运动估计:研究人员直接估计了目标在无穷远处的运动,并创建了一个用于图像混合的天空盒(Skybox),通过将360°天空盒模板图像混合到透视窗口来渲染虚拟天空背景。
假设天空模式的运动是由一个矩阵M2R33来模拟的。 由于天空中的物体(如云、太阳或月亮)应该位于同一个位置,假设它们的透视变换参数是固定值,并且已经包含在天空盒背景图像中,然后使用迭代Lucas-Kanade和金字塔方法计算光学流,从而可以逐帧跟踪一组稀疏特征点。对于每对相邻帧,给定两组2D特征点,使用基于RANSAC的鲁棒模糊估计来计算具有四个自由度(仅限于平移、旋转和均匀缩放)的最佳2D变换。
图像融合:在预测天空蒙版时,输出像素值越高,表示像素属于天空背景的概率越高。在常规方法中,通常利用图像遮罩方程,将新合成的视频帧与背景进行线性组合,以作为它们的像素级组合权重。
但由于前景色和背景色可能具有不同的色调和强度,因此直接进行上述方法可能会导致不切实际的结果。 因此,研究人员应用重新着色和重新照明技术将颜色和强度从背景转移到前景。
实验结果
研究人员采用了天空电视台上的一个数据集。 该数据集基于AED20K数据集构建而成,包括多个子集,其中每个子集对应于使用不同方法创建真实的填空遮罩。
本次试验使用“ADE20K+DE+GF”子集进行了培训和评估,该训练集中有9187张图像,验证集中有885张图像。以下为基于该方法的视频天空增强效果:

最左边是输入视频的起始帧,右边的图像序列是不同时间段下的输出效果
天气转换的效果,分别为晴到多云,晴到小雨,多云到晴天以及多云到多雨。

需要强调的是,在合成雨天图像时,研究人员通过屏幕混合在结果的顶部添加动态雨层(视频源)和雾层。 结果显示,只需对skybox模板和重新照明因子稍作修改,就可以实现视觉逼真的天气转换。
与CycleGAN的比较结果。CycleGAN是一种基于条件生成对抗网络的非成对图像到图像转换方法。在定性方面,该方法表现出更高的保真度。

第一行为两个原始的输入帧;第三行为CycleGAN结果
在定性比较上,PI和NIQE的得分值越低越好。
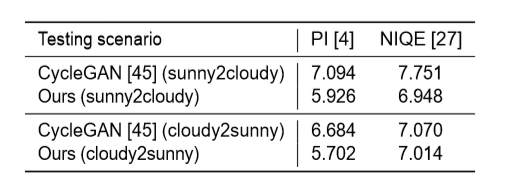
可以看出,该方法在定量指标和视觉质量方面都优于CycleGAN。
更多论文详细内容,可参见:https://arxiv.org/abs/2010.11800
相关作者
Zhengxia Zou,是该项研究的第一作者,目前是密歇根大学安娜堡分校的博士后研究员 。
他于2013年和2018年获得北京航空航天大学的学士学位和博士学位,后加入密歇根大学,其研究兴趣包括计算机视觉在遥感、自动驾驶以及视频游戏中的相关应用。
近几年,其发表的多篇相关论文被ACM、CVPR以及AAAI顶会收录。
对于该项研究,Zhengxia Zou认为,除了视频领域的应用外,还有一个潜在应用空间—数据扩充。 他说,
数据集的规模和质量是计算机视觉技术的基础,在现实场景中,即使ImageNet、MS-COCO等大规模数据集,在应用中也存在采样偏差带来的局限,而该方法对于提高深度学习模型在检测、分割、跟踪等各种视觉任务中的泛化能力具有很大的潜力。
不过,目前研究也存在一定的局限性,主要体现在两个方面,
一是天空遮罩网络无法检测到夜间视频中的天空区域。
二是当视频中某段时间内没有天空像素,或者没有纹理时,天空背景的运动就无法精确建模。
其原因是用于运动估计的特征点被假定为位于同一位置,并且使用距离第二远的特征点来估计运动会不可避免地引入误差。
因此,在未来的工作中,研究会着重于三个方向进行优化:第一是自适应天空光照;第二是鲁棒背景运动估计;第三是探索基于天空渲染的数据增强对目标检测和分割的有效性。
引用链接:
https://jiupinjia.github.io/skyar/
雷锋网雷锋网(公众号:雷锋网)雷锋网
雷锋网原创文章,未经授权禁止转载。详情见转载须知。
