一、集合运算
在查询结果之间进行运算的操作
1 并集
指将两个查询的查询结果合并在一起(最多)
- 并集去重-UNION:将两个查询结果进行合并,若存在相同的数据,将重复数据去重
- 并集不去重-UNION ALL:将两个查询结果合并,且不会对重复数据进行去重操作
先合并后去重
SELECT EMPNO,ENAME FROM EMP
UNION
SELECT DEPTNO,DNAME FROM DEPT ORDER BY ENAME;
- 1
- 2
- 3

2 交集
交集(INTERSECT):指将两个查询结果共有的数据查出,
自动去重
3 差集
差集(MINUS):取仅在第一个查询结果中存在的数据,自动去重
4 总结
1.UNION、INTERSECT、MINUS 会进行去重 UNION ALL 不去重
2.只有差集 MINUS 会考虑查询结果的放置顺序,其他不需要考虑
3.列名可以不一致,但是列数要保持一致,数据类型也要保持一致
4.最终的列名和第一个查询结果中的列名相同
5.集合运算没有先后之分,依次从上到下执行,除非有括号
6.UNION、INTERSECT、MINUS 最终结果会按照第一列进行升序排列,UNION ALL 不会进行自动排序
7.ORDER BY 排序只能放在两查询中的后一个查询内,排序用第一个查询的列名,可以使用序号或别名 (多个集合时同样适用)·
二、行列转换
1 传统的行列转换
-
将某一维度的内容拆解成多个新的列
聚合函数 + CASE WHEN语句
订单日期 线上 线下
SELECT ORDER_DATE 订单日期, SUM(CASE WHEN ORDER_SRC = '线上' THEN CT ELSE 0 END) 线上, SUM(CASE WHEN ORDER_SRC = '线下' THEN CT ELSE 0 END) 线下
FROM ORDERS_SUM
GROUP BY ORDER_DATE;
- 1
- 2
- 3
- 4
- 5
- 6

-
将多个列合并成为一个新的维度
单查多列 + 并集运算 (UNION ALL)
SELECT STUDENT,'CHINESE' COURSE,CHINESE SCORE FROM SCORE_2
UNION ALL
SELECT STUDENT,'MATH' COURSE,MATH SCORE FROM SCORE_2
UNION ALL
SELECT STUDENT,'ENGLISH' COURSE,ENGLISH SCORE FROM SCORE_2;
- 1
- 2
- 3
- 4
- 5

2 行列转换专用函数
-
将维度数据拆解成多个列
SELECT * FROM TB PIVOT(SUM(TB.COL1) FOR TB.COL2 IN (VAL1 AS NEW_COL1,VAL2 AS NEW_COL2,VAL3 AS NEW_COL3))- 1
- 2
PIVOT函数内一定要有聚合函数
TB.COL1:被聚合分析的字段
TB.COL2:被拆解的字段
VAL1,VAL2,VAL3…:TB.COL2字段中的某值
NEW_COL1,NEW_COL2,NEW_COL3…:TB.COL2字段拆解后形成的新字段
AS NEW_COL部分可以不写,最终会以VAL作为字段名展示 -
将多个列合并成一个新的维度
SELECT * FROM TB UNPIVOT(NEW_COL1 FOR NEW_COL2 IN (TB.COL1 AS VAL1,TB.COL2 AS VAL2,TB.COL3 AS VAL3));- 1
- 2
UNPIVOT函数内不需要聚合函数
NEW_COL1:用来收纳交叉数据的字段,字段名自取
NEW_COL2:新合成的维度字段,字段名自取
TB.COL1,TB.COL2,TB.COL3…:被并入的字段
VAL1,VAL2,VAL3…:并入字段以怎样的数据内容录入新维度字段
AS VAL部分可以不写,最终会以TB.COL作为数据内容录入
补充
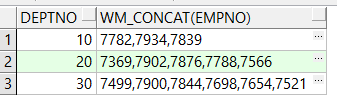
WM_CONCAT(COL_NAME):用于把列值合并到一行,中间用英文逗号隔开
文章来源: blog.csdn.net,作者:浅语呀,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/c727657851/article/details/115028611