1. 背景描述
透视表是一种能对多维数据进行分析统计的工具,具有筛选处理、分类汇总,优化显示等强大的功能,是Excel中最好用的数据分析工具之一。
在自动化办公中,使用python的pivot_table(),搭配合适的聚合函数,就能有效地实现透视表的强大功能,并且能更快速便捷地完成数据统计分析过程。
2. 关键参数
pivot_table()共有9个参数,分别为:1. values, 2. index, 3. columns, 4. aggfunc, 5. fill_value, 6. margins, 7. dropna, 8. margins_name, 9. observed。其中的常用的有6个:
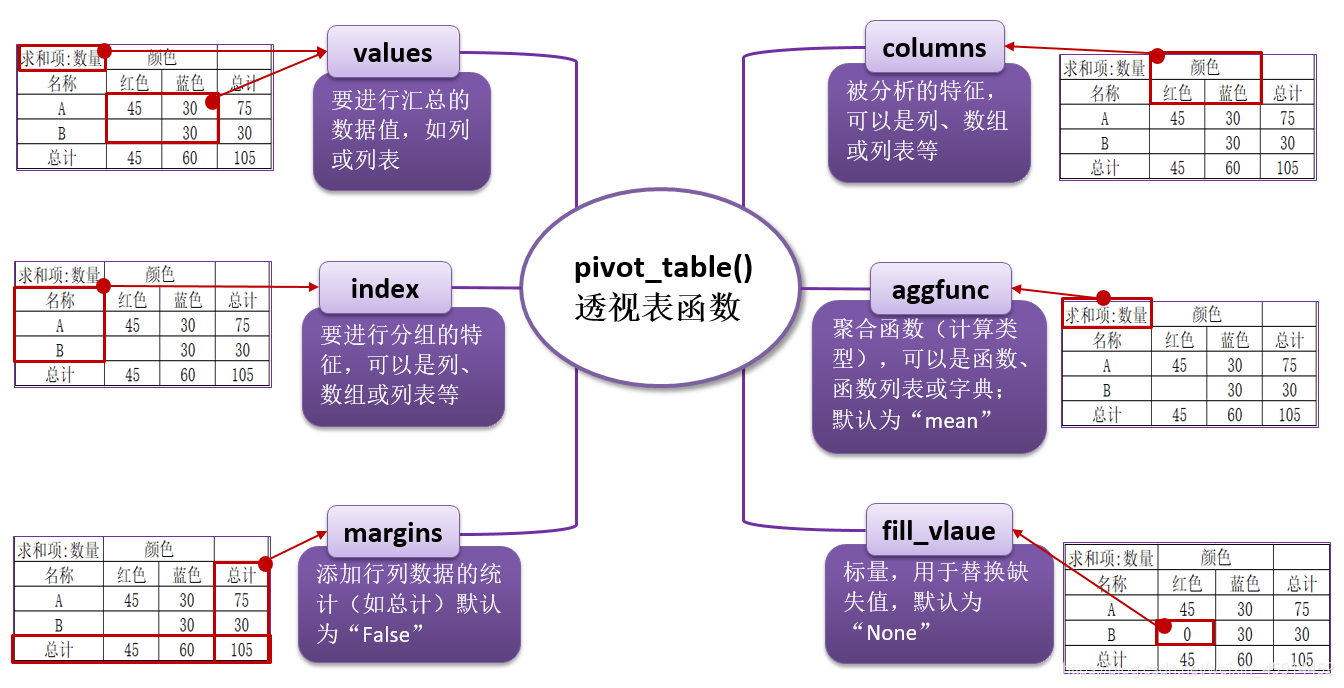
3. 应用示例代码
# 建立数据表
import numpy as np
import pandas as pd
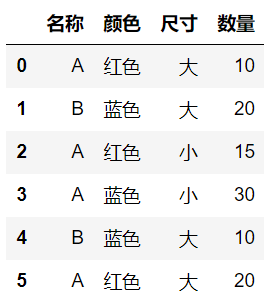
df = pd.DataFrame({"名称": ["A", "B", "A", "A", "B", "A"], "颜色": ["红色", "蓝色", "红色", "蓝色", "蓝色", "红色"], "尺寸": ["大", "大", "小", "小", "大", "大"], "数量": [10, 20, 15, 30, 10, 20]})
df
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
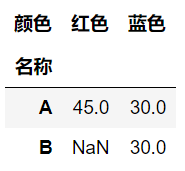
1. 简单的分组分类统计
# 1. 单层统计 -- 根据名称分组统计不同颜色的数量总和
table = pd.pivot_table(df, values="数量", index="名称", columns="颜色", aggfunc=np.sum)
table
- 1
- 2
- 3
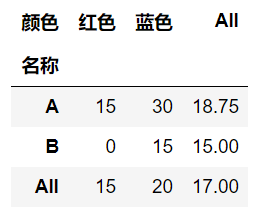
2. fill_value参数:设定fill_value=0: 缺失值充填为0;
marigins 参数:设定margins=True: 对行和列的数据进行统计输出
# 2. 单层统计 -- 根据名称分组统计不同颜色的数量平均值
table = pd.pivot_table(df, values="数量", index="名称", columns="颜色", aggfunc="mean", fill_value=0, margins=True)
table
- 1
- 2
- 3
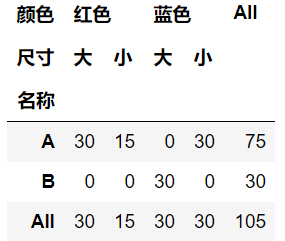
3. columns参数:传入列表,相当于同时对多个特征进行分类统计
# 3. 复合统计1 - 根据名称分组统计不同颜色和尺寸的数量总和
table = pd.pivot_table(df, values="数量", index="名称", columns=["颜色", "尺寸"], aggfunc="sum", fill_value=0,margins=True)
table
- 1
- 2
- 3
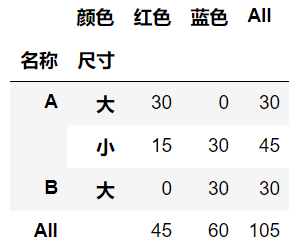
4. index参数:传入一个列表,就是相当于进行多层级的分组
# 4. 复合统计2 - 根据名称和大小分组统计不同颜色的数量总和
table = pd.pivot_table(df, values="数量", index=["名称", "尺寸"], columns=["颜色"], aggfunc="sum", fill_value=0, margins=True)
table
- 1
- 2
- 3
- 4
5. aggfunc参数: 聚合函数可以是函数,函数列表,字典。如果传递的是字典,则健为要聚合的列,值是函数或函数列表。聚合函数可包括:mean(平均值), sum(求和), max(最大值), min(最小值), size(计数), var(方差),std(标准差), median(中位数) 等。
# 5.复合统计3 - 根据名称统计不同颜色的数量总和,以及厚度的标准差
# 为方便演示,加入1新特征厚度值
df["厚度"] = [2, 5, 1, 2, 4, 5]
table = pd.pivot_table(df, values=["数量", "厚度"], index="名称", columns=["颜色"], aggfunc={"数量": np.sum, "厚度": np.std}, fill_value=0, margins=True)
table
- 1
- 2
- 3
- 4
- 5
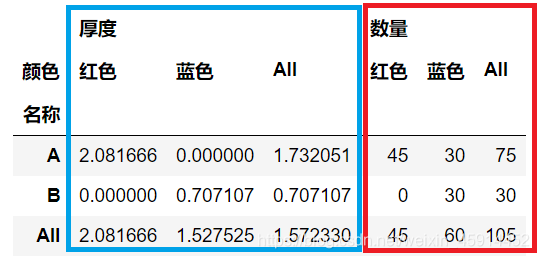
蓝色框 – 分组计算厚度的标准差
红色框 – 分组同步计算数量的总和
这种方法不但快速便捷,还能在同一个平面内展示不同指标使用不同的统计量计算的结果。
文章来源: blog.csdn.net,作者:若芷兰,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_45914452/article/details/114805469