前言
今天来玩一下混沌工程的开源工具之一的 ChaosMesh。ChaosMesh 的目标是要做一个通用的混沌测试工具。
ChaosMesh 是要和 k8s 结合使用的,其中用了云原生的能力。
Chaos Mesh 的基本工作流原理
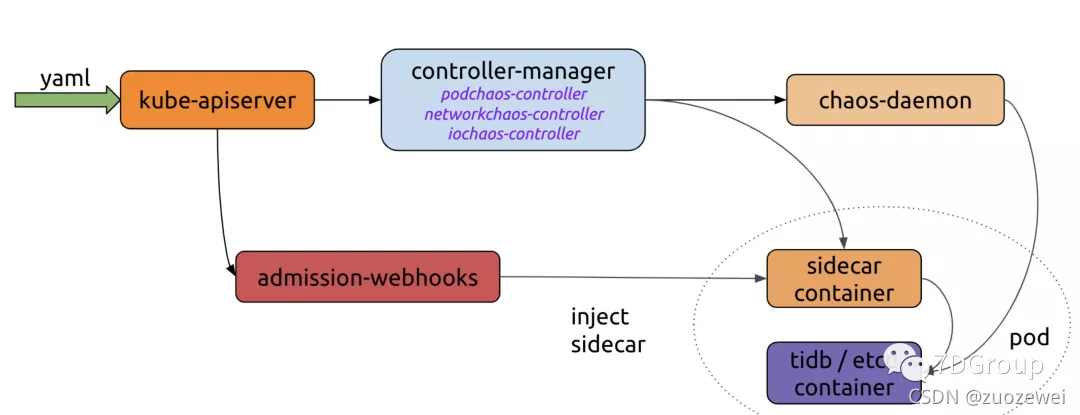
从原理图上可以看出大概的工作流程:
- 用户用 yaml 文件或 k8s 客户端创建更新 Chaos 对象。
- Chaos-mesh 通过 watch api server中的 chaos 对象创建更新或删除事件,由 controller-manager/chaos-daemon 和 sidecar 协作提供注入能力。
- admission-webhooks 用来接收 http 回调,提供状态信息。
Chaos Mesh 功能点
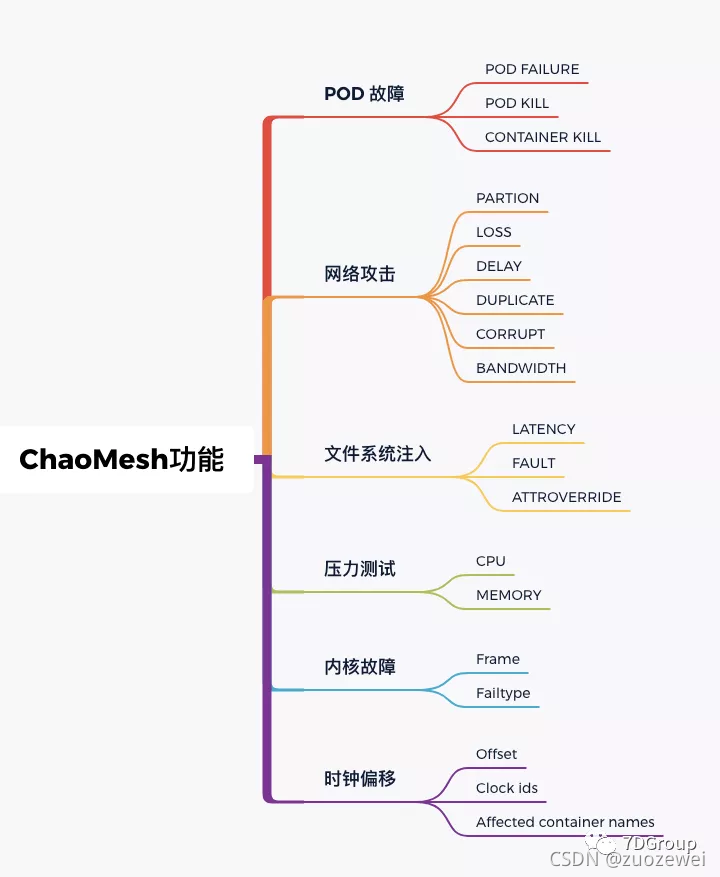
道这些大概的内容之后,我们来具体使用一下。
Chaos Mesh 安装
前提条件:
- k8s集群(包括helm3)
Chaos Mesh的安装比较简单,步骤如下:
[root@s5 ChaosMesh]# helm repo add chaos-mesh https://charts.chaos-mesh.org
[root@s5 ChaosMesh]# kubectl create ns chaos-testing
[root@s5 ChaosMesh]# helm install chaos-mesh chaos-mesh/chaos-mesh --namespace=chaos-testing
检查一下安装结果:
[root@s5 ChaosMesh]# kubectl get pods --namespace chaos-testing -l app.kubernetes.io/instance=chaos-mesh
NAME READY STATUS RESTARTS AGE
chaos-controller-manager-58bc5ff9d8-bvwht 1/1 Running 0 99s
chaos-daemon-5bzjd 1/1 Running 0 99s
chaos-daemon-jjtnb 1/1 Running 0 99s
chaos-dashboard-5878548c46-rnz47 1/1 Running 0 99s
[root@s5 ChaosMesh]#
正常生成了几个 pod。
你要是有兴趣也可以安装 ChaosMesh 提供的一个简单的试验示例。直接执行如下命令即可。
[root@s5 ChaosMesh]# curl -sSL https://mirrors.chaos-mesh.org/v1.2.1/web-show/deploy.sh | bash
请注意:这个示例默认安装到 default 的 namespace。
Chaos Mesh 访问
1.查看 chaosmesh dashboard 的 nodeport 端口,然后访问 ip:port 如下:
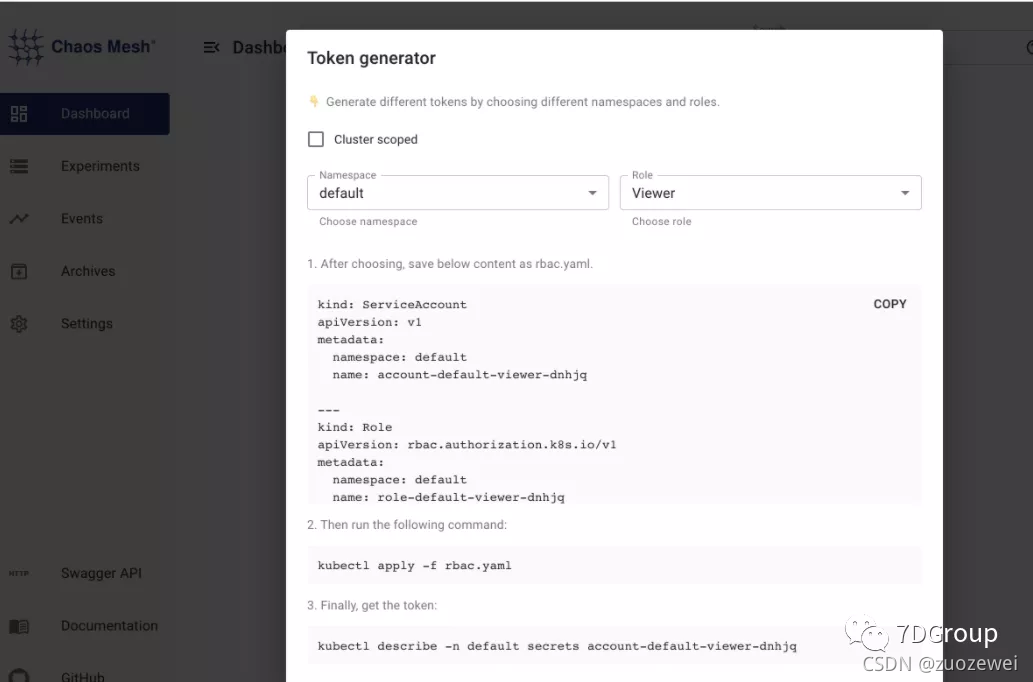
这里是提供 token 生成的步骤。你如果要对整个 k8s 进行操作,可以选择 cluster scoped,并且 role 可以选择manager,在下面就会生成 对应的 RBAC 内容,然后直接按步骤 apply 就行了。
2.登录之后看到如下界面。
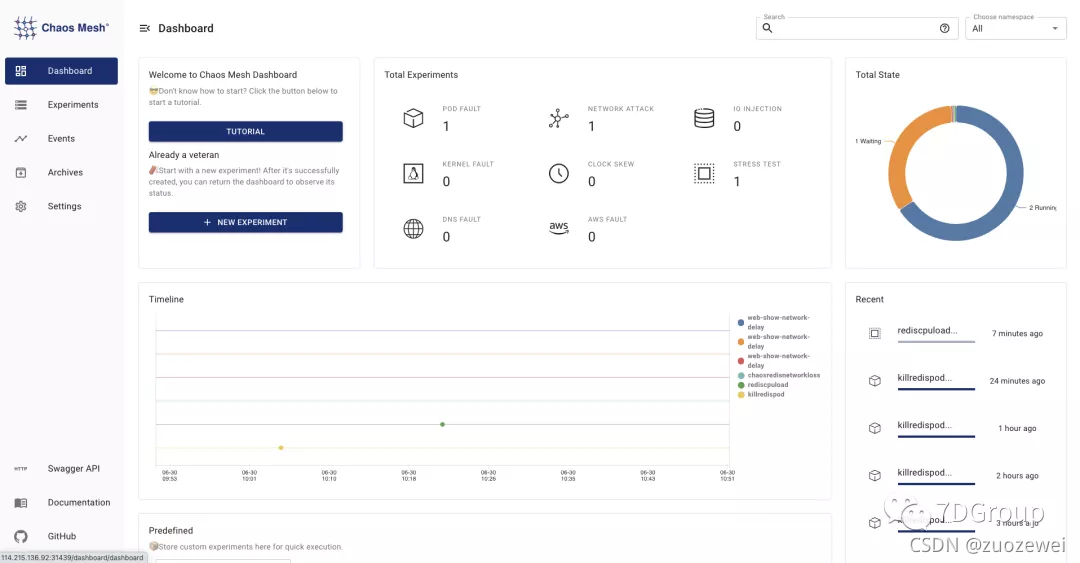
Chaos Mesh 使用之模拟CPU负载
1.点击 NEW EXPERIMENT,选择 STRESS TEST (注意哦,这里可不是指的性能测试中的概念)。
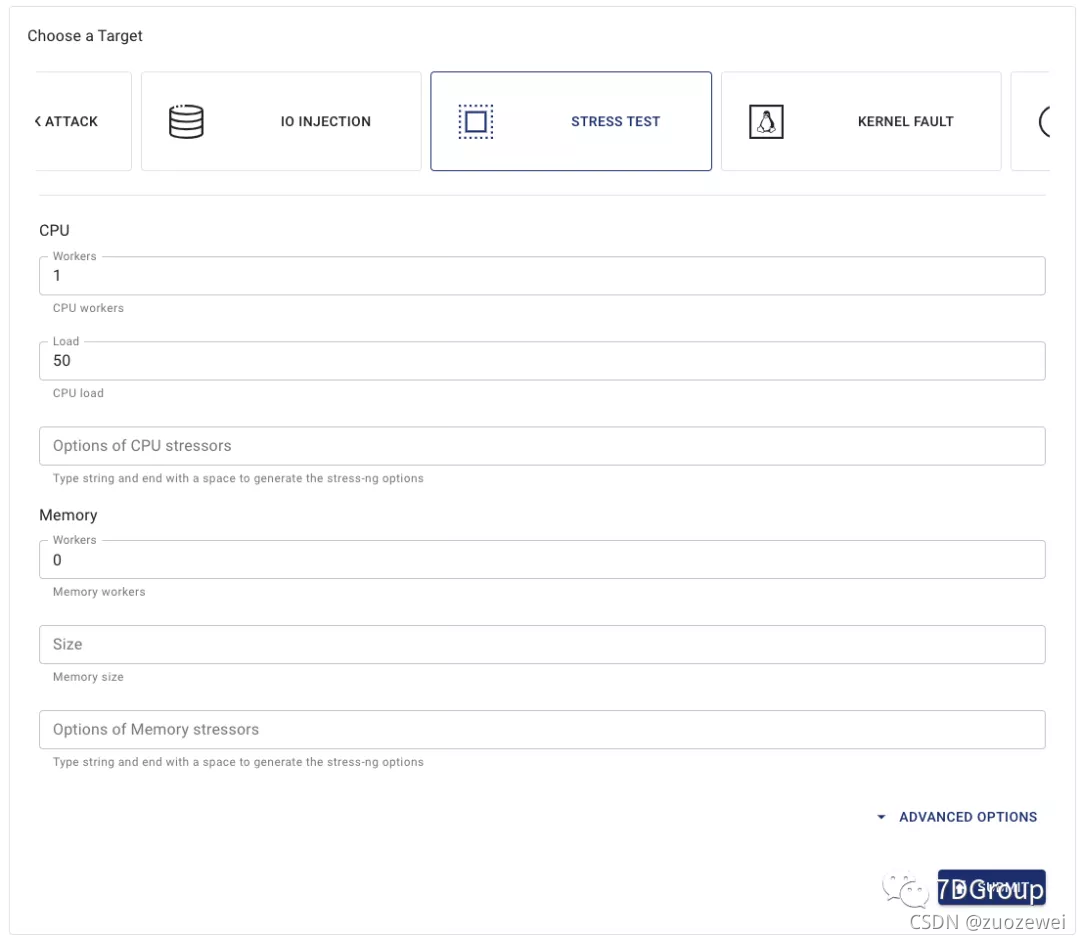
2. 输入个 CPU worker 数量以及 CPU 负载百分比(注意,这里纯是指 CPU 使用率,和 chaosblade/chaostoolkit 的逻辑没有本质的区别)。然后点击提交。
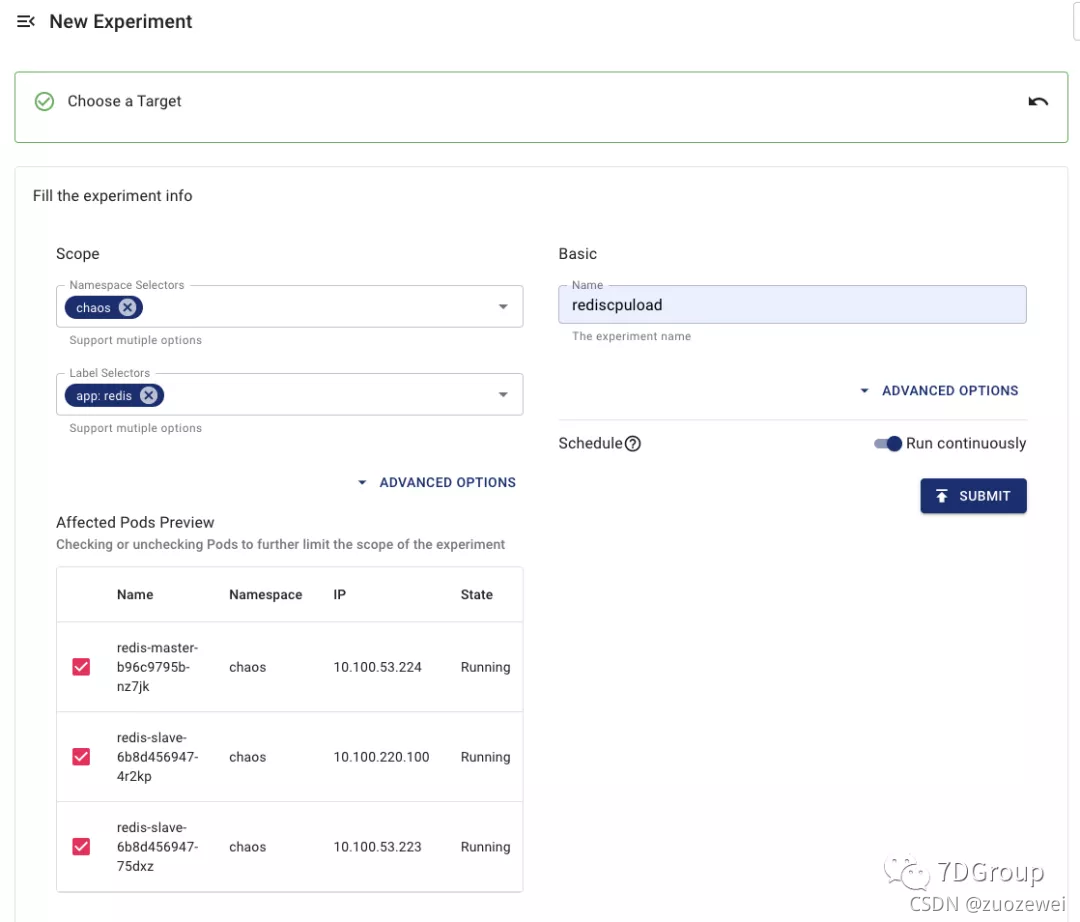
3.紧接着选择试验目标。这里也和其他的混沌工具一样,使用的是 label_selector。然后点两次提交。
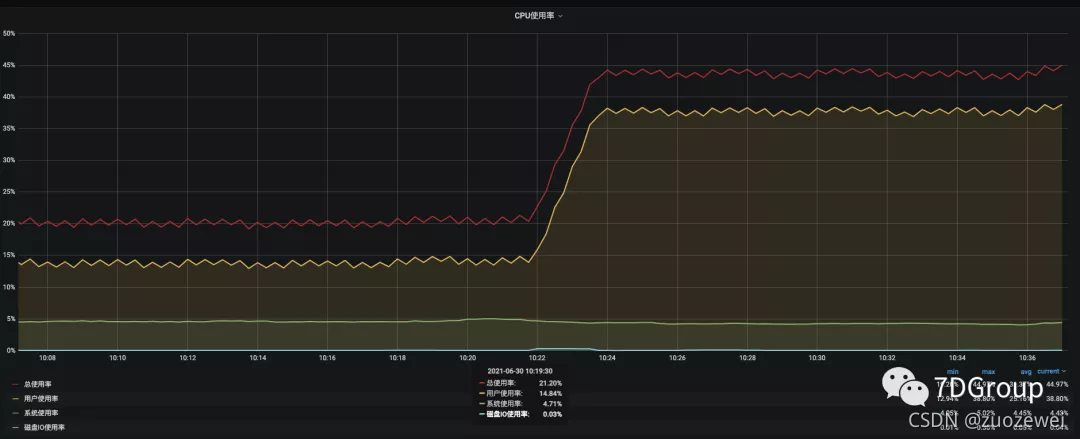
4.然后到相应的 POD 所在的 Worker 上查看 CPU 使用率,即可得到如下结果。
6. 到相应的 worker 中查看进程,可以看到如下信息。
top - 02:38:38 up 35 days, 12:33, 0 users, load average: 5.07, 4.08, 2.55
Tasks: 7 total, 1 running, 6 sleeping, 0 stopped, 0 zombie
%Cpu0 : 29.2 us, 3.0 sy, 0.0 ni, 67.4 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 st
%Cpu1 : 34.0 us, 4.4 sy, 0.0 ni, 61.3 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 st
KiB Mem: 8008964 total, 7834456 used, 174508 free, 32984 buffers
KiB Swap: 0 total, 0 used, 0 free. 1203140 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
11 root 20 0 59088 3980 1096 S 45.3 0.0 7:45.77 stress-ng-cpu
1 root 20 0 4436 652 548 S 0.0 0.0 0:00.00 sh
6 root 20 0 17984 1448 1164 S 0.0 0.0 0:00.00 run.sh
7 root 20 0 41508 2500 1476 S 0.0 0.0 0:03.83 redis-server
10 root 20 0 58444 3864 3512 S 0.0 0.0 0:00.00 stress-ng
12 root 20 0 19356 3148 1488 S 0.0 0.0 0:00.01 bash
34 root 20 0 19896 1396 1004 R 0.0 0.0 0:00.00 top
可以看到这个工具是直接在 worker中 启动了一个叫 stress-ng-cpu 的进程。通过这个名字,我们就能理解,这就是用 stress-ng 这个工具启动一个进程。
这个逻辑和 chaostoolkit、chaosblade 也是一样的逻辑,无非就是在 worker 中启动一个新的进程,把 CPU 消耗掉。
总结
本篇就写到这里吧,后面没事接着整理,在整理这些东西的过程中,我觉得需要的技术栈比性能工程要小很多,所以轻松+愉快地就可以做到了。可见技术的基础知识体系是多么重要。
给你留两个思考题:
- 在混沌工程中,用这样的逻辑模拟CPU使用率,可以覆盖什么样的生产场景?又不能覆盖什么样的生产场景?
- 在能覆盖的场景中,由于是新启动了一个进程,那在系统级的异常反应,有什么特点?