写在前面
2016年4月参加了哈尔滨工业大学深圳研究生院举办的创新创业比赛,司职算法组长,切入点定在了音色识别和相似明星音才艺展示推荐算法上,不才,拿到了一等奖,趁佳节未散与大家分享。
项目进度安排
2016年1月~2016年3月:前期工作中了解学习了语音信号处理的基本原理,查阅有关文献了解到了声音音色信息的描述方式,梅尔(Mel)倒谱系数的意义,推导了相关公式并实现了MFCC(Mel Frequency Cepstral Coefficient)参数的计算,阅读并了解了有关说话人识别,音色识别和MFCC参数的相关应用情况。
2016年4月~2016年6月:后期工作中组内部分成员同软件组(还是什么组?)共同合作完成了由算法向实际应用的转化,另一部分成员进行了后续的算法优化,添加了噪声预处理环节,并期待利用支持向量机(SVM),K-均值聚类(K-means)等机器学习算法实现更好的音色识别效果。
项目实施方案与原理
在MFCC参数提取方面,我们遵循[1]中所述的计算流程,编程实现了对一段语音的MFCC参数提取:
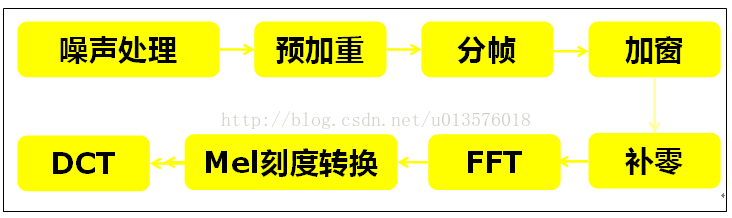
具体的编程环节这里暂时不介绍,从Mel刻度转换后我们得到的MFCC参数多达40余个,为了避免特征泛化导致识别率降低,我们需要对这些特征进行筛选。还好这个工作已经有人替我们完成[2],通过离散傅里叶变换(DCT),我们可以得到需要的C2~C16的特征值作为说话人的音色描述子。用了别人的工作,我们还应该本着严谨的态度对其进行验证。这里我们设计一个二类分类实验,利用SVM来进行音色描述子优劣的描述。利用现有数据库的测试数据,我们实现了如下的测试结果:
SVM十次十折实验利用MFCC参数作为特征可实现97.5%的识别准确率。
SVM再处理多类分类问题时存在着运算速度和效率上的限制,从这一点考虑,我们先使用了最简单的最小欧式距离法进行识别,该算法在小参考集下运算速度较快,但大参考集时运算耗时会严重增长,为了解决这个问题,我们提出了使用K-means聚类+最小欧式距离结合的方法,利用聚类算法,将大型的数据集分成若干个小的数据集,并且以聚类中心作为该集合的label,识别过程中首先进行类间匹配,接下来再进行类内匹配。
算法上的项目创新点有二:
其一,首次使用MFCC参数作为歌手的识别推荐系统下,需要解决很多噪声处理和歌手特征提取的难题;
不足之处的反思
目前采用的特征还只是MFCC参数这一个角度,特征的类型较为单一,在未来的研究中,可以增加一些更为有效的特征作为音色的描述,同时,可以引进更大的标准数据库,在互联网上利用爬虫等数据挖掘手段收集更多的明星声音来扩充我们的标准库。作为一款娱乐应用,这个APP已经具备了初步市场化的能力,但是一首歌终究还是由音色,音调和节奏等多方面组成,我们推荐结果的好坏是一个取决于APP使用者很主观的评价准则。如何实现APP的可持续发展,如何让APP保持活力,维持用户数量和用户活跃度等等都是很不确定的因素。
reference:
[2]甄斌,吴玺宏,刘志敏,迟惠生. 语音识别和说话人识别中各倒谱分量的相对重要性[J].北京大学学报(自然科学版),2001,03:371-378.
Attachment:
展示一下最后APP的结果:

以及移动端的逻辑关系:

文章来源: zclhit.blog.csdn.net,作者:zclhit_,版权归原作者所有,如需转载,请联系作者。
原文链接:zclhit.blog.csdn.net/article/details/54922927