前言
faster-rcnn做为一款优秀的two-stage目标检测,它的思想在很多地方都能看到。今天我们就来说说吧!!!
论文地址
https://arxiv.org/abs/1506.01497
github地址
https://github.com/yanjingke/faster-rcnn-keras
什么是目标检测?
图片分类任务,就是算法对其中的对象进行分类。而今天我们要了解构建神经网络的另一个问题,即目标检测问题。这意味着,我们不仅要用算法判断图片中是不是一辆汽车, 还要在图片中标记出它的位置, 用边框或红色方框把汽车圈起来, 这就是目标检测问题。 其中“定位”的意思是判断汽车在图片中的具体位置。
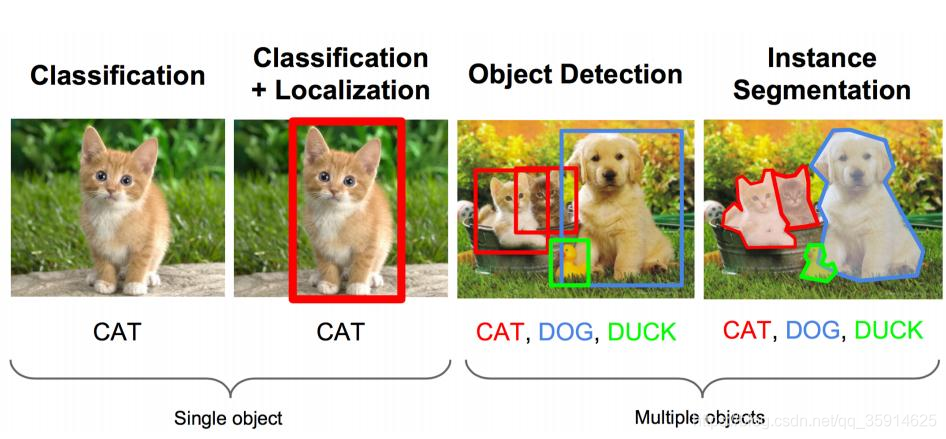
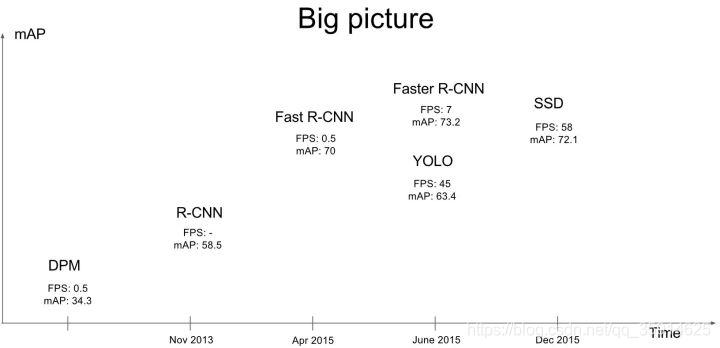
近几年来,目标检测算法取得了很大的突破。比较流行的算法可以分为两类,一类是基于Region Proposal的R-CNN系算法(R-CNN,Fast R-CNN, Faster R-CNN等),它们是two-stage的,需要先算法产生目标候选框,也就是目标位置,然后再对候选框做分类与回归。而另一类是Yolo,SSD这类one-stage算法,其仅仅使用一个卷积神经网络CNN直接预测不同目标的类别与位置。第一类方法是准确度高一些,但是速度慢,但是第二类算法不仅速度快,而且准确度很高。这可以在下图中看到。
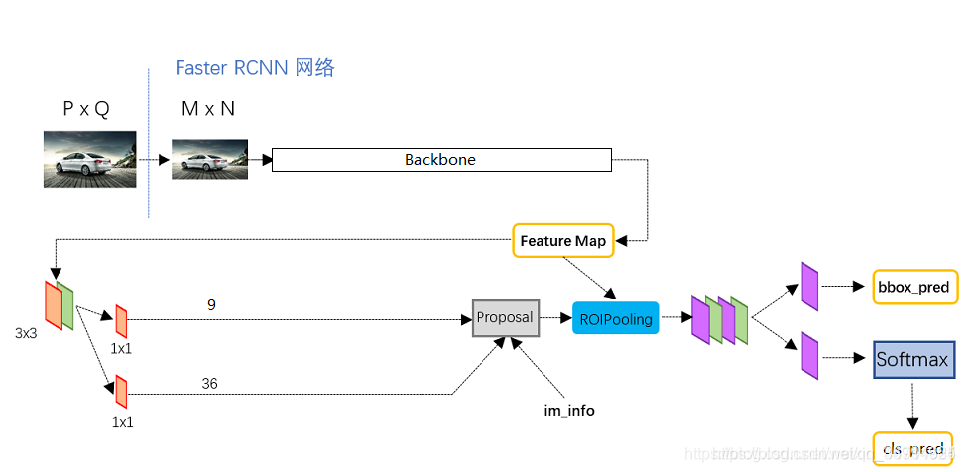
faster -Rcnn优点
Faster R-CNN创新点:
1.设计 RPN(论文里说有点注意力机制的味道),利用CNN卷积操作后的特征图生成region proposals,代替了Selective Search的方法,速度上提升明显;
2.训练 RPN 与检测网络Fast R-CNN共享卷积层,大幅提高网络的检测速度。
3.FasterR-CNN将一直以来分离的region proposal和CNN分类融合到了一起,使用端到端的网络进行目标检测,无论在速度上还是精度上都得到了不错的提高。
RPN的核心思想是使用CNN卷积神经网络直接产生Region Proposal,使用的方法本质上就是滑动窗口。RPN的作用:
1.输出是否是前景的classification和进行位置的regression
2.采用了9个anchor 多尺度预测
预备知识
faster-rcnn—anchor解读
anchor实际上就是矩形,多个anchor的中心点重合。对于一个滑窗,我们可以同时预测多个proposal,就是因为有多个anchor。
anchor的设置,相当于提前在图片上做预选,通常在生成anchor时,每一张图片上将会对应成千上万的anchor也就是候选框,可想而知,如此庞大的候选框数量,肯定能够满足对图上实例进行检测的需要,效果如下图所示

在faster-RCNN中每个像素点有9个anchor,这9个anchor是作者设置的,论文中scale ==[128,256,512],长宽比[1;1,1:2,2:1],所以有9种。自己可以根据目标的特点做出不同的设计。对于一幅W×H的feature map,共有W×H×k个锚点。
我计算了下faster-RCNN的Backbone anchor数量大概有12996个。那么有了这些框框,网络便可以学习这些框框中的事物以及框框的位置,最终可以进行分类和回归。
每个anchor-size对应着三种scale和三个ratio,那么每个anchor-size将对应生成9个先验框,同时生成的所有先验框均满足:
1.同一种scale,面积相同,形状不同
2.同一种ratio,形状相同,面积不同
3.对于scale和ratio的理解:scale指anchor的大小(可以当做宽)、ratio即为宽高比
anchor实现步骤:
1.因为我们最终的每个网格是是9个先验框,所以利用scale和ratio的长度相乘得到9
2.我们最终获得的anchor里面存放的是左上角和右下角的偏移量,最终生成(9x4)的数组
我们以Backbone 38x38的特征层为例,
self.anchor_box_scales = [128, 256, 512]
self.anchor_box_ratios = [[1, 1], [1, 2], [2, 1]]
if sizes is None: sizes = config.anchor_box_scales
if ratios is None: ratios = config.anchor_box_ratios num_anchors = len(sizes) * len(ratios)
anchors = np.zeros((num_anchors, 4))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
首先生成[9,4]大小全为0的矩阵:
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
接下来,需要求解以w=h=[128, 256, 512]为基础的9种anchor的宽和高。
首先,我们需要求出三种scale的anchor对应的宽(W),此时只是做scale变换,不涉及ratios,自然所求的anchor都是大小不一的正方形
anchors[:, 2:] = np.tile(sizes, (2, len(ratios))).T
- 1
生成anchor_size=32在三种scale下的9个宽、高。第三列即为宽、第四列即为高。这样我们便得到了9个大小不一的正方形anchor。
[ 0. 0. 128. 128.]
[ 0. 0. 256. 256.]
[ 0. 0. 512. 512.]
[ 0. 0. 128. 128.]
[ 0. 0. 256. 256.]
[ 0. 0. 512. 512.]
[ 0. 0. 128. 128.]
[ 0. 0. 256. 256.]
[ 0. 0. 512. 512.]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
接下来将做ratio变换:
ratio变换的实质:将以上生成的正方形anchor按照一定比例缩放,求得缩放后的宽,保持scale不变,求得高。
for i in range(len(ratios)): # print(str(i)+"_"+"*"*100) # print(anchors[3*i:3*i+3, 2]*ratios[i][0]) # print( anchors[3*i:3*i+3, 3]*ratios[i][1]) anchors[3*i:3*i+3, 2] = anchors[3*i:3*i+3, 2]*ratios[i][0] anchors[3*i:3*i+3, 3] = anchors[3*i:3*i+3, 3]*ratios[i][1]
- 1
- 2
- 3
- 4
- 5
- 6
[[ 0. 0. 128. 128.]
[ 0. 0. 256. 256.]
[ 0. 0. 512. 512.]
[ 0. 0. 128. 256.]
[ 0. 0. 256. 512.]
[ 0. 0. 512. 1024.]
[ 0. 0. 256. 128.]
[ 0. 0. 512. 256.]
[ 0. 0. 1024. 512.]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这种形式的坐标,并不是我们想要的,因为它只记录了当前anchor的宽和高。并没有给出坐标信息。
那么我们采取的办法是,以当前anchor的中心点为坐标原点建立直角坐标系,求出左上角坐标和右下角坐标,存入当前数组,格式为(x1,y1,x2,y2)。
##间隔取值 anchors[:, 0::2] -= np.tile(anchors[:, 2] * 0.5, (2, 1)).T anchors[:, 1::2] -= np.tile(anchors[:, 3] * 0.5, (2, 1)).T # print(anchors)
- 1
- 2
- 3
- 4
此时的anchor数组为:
[[ -64. -64. 64. 64.]
[-128. -128. 128. 128.]
[-256. -256. 256. 256.]
[ -64. -128. 64. 128.]
[-128. -256. 128. 256.]
[-256. -512. 256. 512.]
[-128. -64. 128. 64.]
[-256. -128. 256. 128.]
[-512. -256. 512. 256.]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
将anchor偏移量叠加到到原图上
以上我们得到的只是当前anchor相对于自身中心点的坐标,我们还要将
那么映射的思路为:
首先生成3838的网格坐标,对于每一个网格,将9个anchor分别嵌入进去,得到基于网格的anchor坐标。我们加了0.5,我们为什么要加0.5,其实我们把38x38看成网格,那么我们所求的网格点坐标其实都是每个小网格中心点的坐标,网格的边长是1。中心点肯定是要乘上0.5的。
# [0,1,2,3,4,5……37] # [0.5,1.5,2.5……37.5] # [8,24,……] shift_x = (np.arange(0, shape[0], dtype=keras.backend.floatx()) + 0.5) * stride shift_y = (np.arange(0, shape[1], dtype=keras.backend.floatx()) + 0.5) * stride # print(shift_x) shift_x, shift_y = np.meshgrid(shift_x, shift_y) shift_x = np.reshape(shift_x, [-1]) shift_y = np.reshape(shift_y, [-1]) # print(shift_x,shift_y) shifts = np.stack([ shift_x, shift_y, shift_x, shift_y ], axis=0) shifts = np.transpose(shifts)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
最终我们得到的结果为:
[[ 8. 8. 8. 8.]
[ 24. 8. 24. 8.]
[ 40. 8. 40. 8.]
...
[568. 600. 568. 600.]
[584. 600. 584. 600.]
[600. 600. 600. 600.]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
此处我们构造了和anchor相同的结构,网格上第一列和第三列、第二列和第四列都是相同的。第一列是网格上38x38个点的横坐标,第二列是38x38个点的纵坐标。接下来,我们便可以直接做映射。
在上述中,我们得到的anchor坐标实际上可以看做是以anchor本身的中心点为坐标原点得到的,那么坐标值实际上可以看做是左上角和右下角两个点对中心点的偏移量。那么如果我们将中心点换做的back bone的网格点,然后将偏移量叠加至上面,不就完成了anchor到back bone的映射嘛。
代码:
number_of_anchors = np.shape(anchors)[0] k = np.shape(shifts)[0] print(np.array(np.reshape(shifts, [k, 1, 4])).shape) shifted_anchors = np.reshape(anchors, [1, number_of_anchors, 4]) + np.array(np.reshape(shifts, [k, 1, 4]), keras.backend.floatx()) shifted_anchors = np.reshape(shifted_anchors, [k * number_of_anchors, 4])
- 1
- 2
- 3
- 4
- 5
- 6

具体代码对应我github上Vision_For_prior.py文件。
什么是Smooth L1 Loss
首先看L1 loss 和 L2 loss 定义:

写成差的形式,f(x) 为预测值, Y 为 groud truth

对于L2 Loss:当 x 增大时 L2 损失对 x 的导数也增大。这就导致训练初期,预测值与 groud truth 差异过于大时,损失函数对预测值的梯度十分大,训练不稳定。从下面的形式 L2 Loss的梯度包含 (f(x) - Y),当预测值 f(x) 与目标值 Y 相差很大时(此时可能是离群点、异常值(outliers)),容易产生梯度爆炸
对于L1 Loss:根据方程 (5),L1 对 x 的导数为常数。这就导致训练后期,预测值与 ground truth 差异很小时, L1 损失对预测值的导数的绝对值仍然为 1,而 learning rate 如果不变,损失函数将在稳定值附近波动,难以继续收敛以达到更高精度。
从上面的导数可以看出,L2 Loss的梯度包含 (f(x) - Y),当预测值 f(x) 与目标值 Y 相差很大时,容易产生梯度爆炸,而L1 Loss的梯度为常数,通过使用Smooth L1 Loss,在预测值与目标值相差较大时,由L2 Loss转为L1 Loss可以防止梯度爆炸。
Fast RCNN里提出了Smooth L1 Loss。
faster-RCNN 代码讲解
预测部分
Faster-RCNN可以采用多种的主干特征提取网络,常用的有VGG,Resnet,Xception等等,本文采用的是Resnet网络.Faster-Rcnn对输入进来的图片尺寸没有固定,但是一般会把输入进来的图片短边固定成600.

Resnet采用Inverted residual在3x3网络结构前利用1x1卷积降维,在3x3网络结构后,利用1x1卷积升维,相比直接使用3x3网络卷积效果更好,参数更少,先进行压缩,再进行扩张。
在Resnet50中它有两个结构分别名为Conv Block和Identity Block,Conv block输入和输出是是不同的,而Identity Block输入和输出是相同的。这样做意味着后面的特征层的内容会有一部分由其前面的某一层线性贡献。
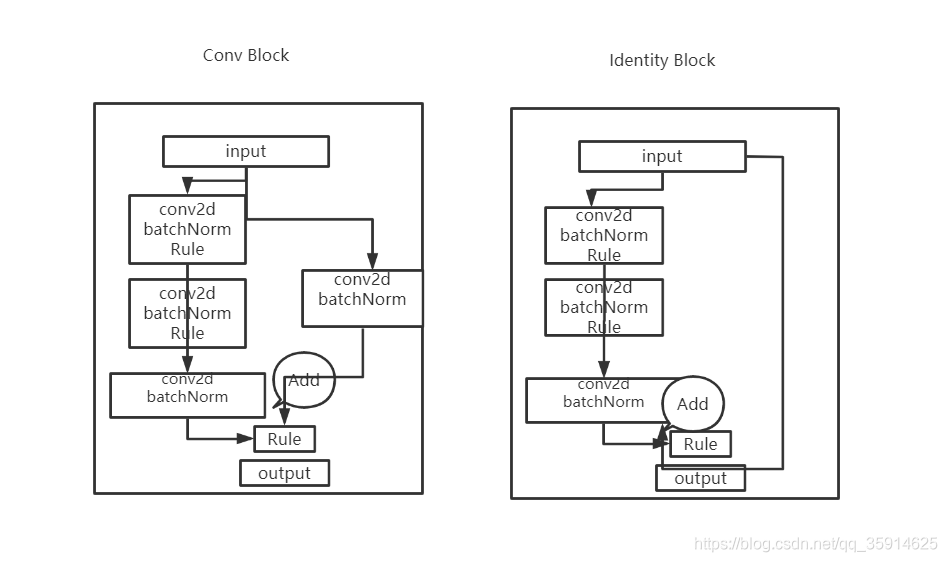
总的resnet50结构

而在Faster-RCNN的主干特征提取网络部分只包含了长宽压缩了四次的内容,第五次压缩后的内容在ROI中使用。

#-------------------------------------------------------------#
# ResNet50的网络部分
#-------------------------------------------------------------#
from __future__ import print_function
import numpy as np
from keras import layers
from keras.layers import Input
from keras.layers import Dense,Conv2D,MaxPooling2D,ZeroPadding2D,AveragePooling2D,TimeDistributed,Add
from keras.layers import Activation,Flatten
from keras.models import Model
from keras.preprocessing import image
import keras.backend as K
from keras.utils.data_utils import get_file
from keras.applications.imagenet_utils import decode_predictions
from keras.applications.imagenet_utils import preprocess_input
from keras.engine import Layer, InputSpec
from keras import initializers, regularizers
from keras import backend as K
class BatchNormalization(Layer): def __init__(self, epsilon=1e-3, axis=-1, weights=None, beta_init='zero', gamma_init='one', gamma_regularizer=None, beta_regularizer=None, **kwargs): self.supports_masking = True self.beta_init = initializers.get(beta_init) self.gamma_init = initializers.get(gamma_init) self.epsilon = epsilon self.axis = axis self.gamma_regularizer = regularizers.get(gamma_regularizer) self.beta_regularizer = regularizers.get(beta_regularizer) self.initial_weights = weights super(BatchNormalization, self).__init__(**kwargs) def build(self, input_shape): self.input_spec = [InputSpec(shape=input_shape)] shape = (input_shape[self.axis],) self.gamma = self.add_weight(shape, initializer=self.gamma_init, regularizer=self.gamma_regularizer, name='{}_gamma'.format(self.name), trainable=False) self.beta = self.add_weight(shape, initializer=self.beta_init, regularizer=self.beta_regularizer, name='{}_beta'.format(self.name), trainable=False) self.running_mean = self.add_weight(shape, initializer='zero', name='{}_running_mean'.format(self.name), trainable=False) self.running_std = self.add_weight(shape, initializer='one', name='{}_running_std'.format(self.name), trainable=False) if self.initial_weights is not None: self.set_weights(self.initial_weights) del self.initial_weights self.built = True def call(self, x, mask=None): assert self.built, 'Layer must be built before being called' input_shape = K.int_shape(x) reduction_axes = list(range(len(input_shape))) del reduction_axes[self.axis] broadcast_shape = [1] * len(input_shape) broadcast_shape[self.axis] = input_shape[self.axis] if sorted(reduction_axes) == range(K.ndim(x))[:-1]: x_normed = K.batch_normalization( x, self.running_mean, self.running_std, self.beta, self.gamma, epsilon=self.epsilon) else: # need broadcasting broadcast_running_mean = K.reshape(self.running_mean, broadcast_shape) broadcast_running_std = K.reshape(self.running_std, broadcast_shape) broadcast_beta = K.reshape(self.beta, broadcast_shape) broadcast_gamma = K.reshape(self.gamma, broadcast_shape) x_normed = K.batch_normalization( x, broadcast_running_mean, broadcast_running_std, broadcast_beta, broadcast_gamma, epsilon=self.epsilon) return x_normed def get_config(self): config = {'epsilon': self.epsilon, 'axis': self.axis, 'gamma_regularizer': self.gamma_regularizer.get_config() if self.gamma_regularizer else None, 'beta_regularizer': self.beta_regularizer.get_config() if self.beta_regularizer else None} base_config = super(BatchNormalization, self).get_config() return dict(list(base_config.items()) + list(config.items()))
def identity_block(input_tensor, kernel_size, filters, stage, block): filters1, filters2, filters3 = filters conv_name_base = 'res' + str(stage) + block + '_branch' bn_name_base = 'bn' + str(stage) + block + '_branch' x = Conv2D(filters1, (1, 1), name=conv_name_base + '2a')(input_tensor) x = BatchNormalization(name=bn_name_base + '2a')(x) x = Activation('relu')(x) x = Conv2D(filters2, kernel_size,padding='same', name=conv_name_base + '2b')(x) x = BatchNormalization(name=bn_name_base + '2b')(x) x = Activation('relu')(x) x = Conv2D(filters3, (1, 1), name=conv_name_base + '2c')(x) x = BatchNormalization(name=bn_name_base + '2c')(x) x = layers.add([x, input_tensor]) x = Activation('relu')(x) return x
def conv_block(input_tensor, kernel_size, filters, stage, block, strides=(2, 2)): filters1, filters2, filters3 = filters conv_name_base = 'res' + str(stage) + block + '_branch' bn_name_base = 'bn' + str(stage) + block + '_branch' x = Conv2D(filters1, (1, 1), strides=strides, name=conv_name_base + '2a')(input_tensor) x = BatchNormalization(name=bn_name_base + '2a')(x) x = Activation('relu')(x) x = Conv2D(filters2, kernel_size, padding='same', name=conv_name_base + '2b')(x) x = BatchNormalization(name=bn_name_base + '2b')(x) x = Activation('relu')(x) x = Conv2D(filters3, (1, 1), name=conv_name_base + '2c')(x) x = BatchNormalization(name=bn_name_base + '2c')(x) shortcut = Conv2D(filters3, (1, 1), strides=strides, name=conv_name_base + '1')(input_tensor) shortcut = BatchNormalization(name=bn_name_base + '1')(shortcut) x = layers.add([x, shortcut]) x = Activation('relu')(x) return x
def ResNet50(inputs): img_input = inputs x = ZeroPadding2D((3, 3))(img_input) x = Conv2D(64, (7, 7), strides=(2, 2), name='conv1')(x) x = BatchNormalization(name='bn_conv1')(x) x = Activation('relu')(x) x = MaxPooling2D((3, 3), strides=(2, 2), padding="same")(x) x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1, 1)) x = identity_block(x, 3, [64, 64, 256], stage=2, block='b') x = identity_block(x, 3, [64, 64, 256], stage=2, block='c') x = conv_block(x, 3, [128, 128, 512], stage=3, block='a') x = identity_block(x, 3, [128, 128, 512], stage=3, block='b') x = identity_block(x, 3, [128, 128, 512], stage=3, block='c') x = identity_block(x, 3, [128, 128, 512], stage=3, block='d') x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a') x = identity_block(x, 3, [256, 256, 1024], stage=4, block='b') x = identity_block(x, 3, [256, 256, 1024], stage=4, block='c') x = identity_block(x, 3, [256, 256, 1024], stage=4, block='d') x = identity_block(x, 3, [256, 256, 1024], stage=4, block='e') x = identity_block(x, 3, [256, 256, 1024], stage=4, block='f') # model = Model(img_input, [x], name='resnet50') return x
def identity_block_td(input_tensor, kernel_size, filters, stage, block, trainable=True): nb_filter1, nb_filter2, nb_filter3 = filters if K.image_dim_ordering() == 'tf': bn_axis = 3 else: bn_axis = 1 conv_name_base = 'res' + str(stage) + block + '_branch' bn_name_base = 'bn' + str(stage) + block + '_branch' x = TimeDistributed(Conv2D(nb_filter1, (1, 1), trainable=trainable, kernel_initializer='normal'), name=conv_name_base + '2a')(input_tensor) x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2a')(x) x = Activation('relu')(x) x = TimeDistributed(Conv2D(nb_filter2, (kernel_size, kernel_size), trainable=trainable, kernel_initializer='normal',padding='same'), name=conv_name_base + '2b')(x) x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2b')(x) x = Activation('relu')(x) x = TimeDistributed(Conv2D(nb_filter3, (1, 1), trainable=trainable, kernel_initializer='normal'), name=conv_name_base + '2c')(x) x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2c')(x) x = Add()([x, input_tensor]) x = Activation('relu')(x) return x
def conv_block_td(input_tensor, kernel_size, filters, stage, block, input_shape, strides=(2, 2), trainable=True): nb_filter1, nb_filter2, nb_filter3 = filters if K.image_dim_ordering() == 'tf': bn_axis = 3 else: bn_axis = 1 conv_name_base = 'res' + str(stage) + block + '_branch' bn_name_base = 'bn' + str(stage) + block + '_branch' x = TimeDistributed(Conv2D(nb_filter1, (1, 1), strides=strides, trainable=trainable, kernel_initializer='normal'), input_shape=input_shape, name=conv_name_base + '2a')(input_tensor) x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2a')(x) x = Activation('relu')(x) x = TimeDistributed(Conv2D(nb_filter2, (kernel_size, kernel_size), padding='same', trainable=trainable, kernel_initializer='normal'), name=conv_name_base + '2b')(x) x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2b')(x) x = Activation('relu')(x) x = TimeDistributed(Conv2D(nb_filter3, (1, 1), kernel_initializer='normal'), name=conv_name_base + '2c', trainable=trainable)(x) x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2c')(x) shortcut = TimeDistributed(Conv2D(nb_filter3, (1, 1), strides=strides, trainable=trainable, kernel_initializer='normal'), name=conv_name_base + '1')(input_tensor) shortcut = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '1')(shortcut) x = Add()([x, shortcut]) x = Activation('relu')(x) return x
def classifier_layers(x, input_shape, trainable=False): x = conv_block_td(x, 3, [512, 512, 2048], stage=5, block='a', input_shape=input_shape, strides=(2, 2), trainable=trainable) x = identity_block_td(x, 3, [512, 512, 2048], stage=5, block='b', trainable=trainable) x = identity_block_td(x, 3, [512, 512, 2048], stage=5, block='c', trainable=trainable) x = TimeDistributed(AveragePooling2D((7, 7)), name='avg_pool')(x) return x
if __name__ == "__main__": inputs = Input(shape=(600, 600, 3)) model = ResNet50(inputs) model.summary()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
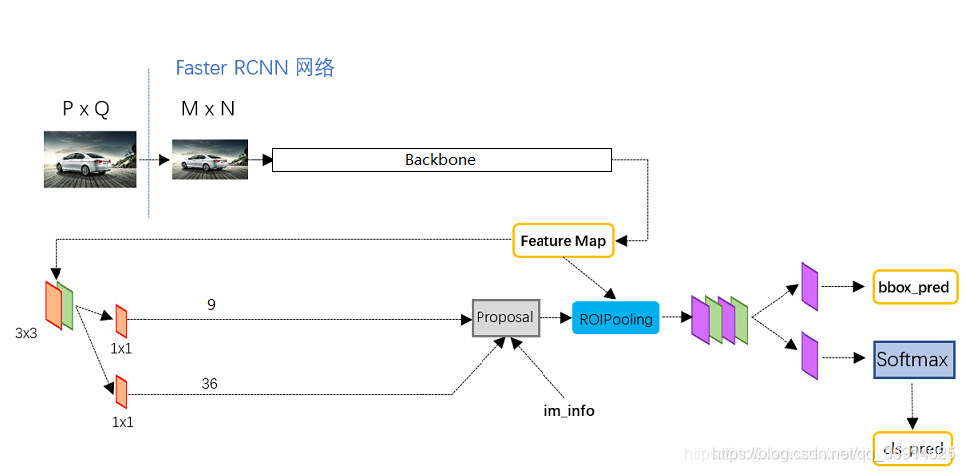
1.获得Proposal预测结果
将整张图片输进主干特征提取,得到feature map,卷积特征输入到RPN,得到候选框的特征信息,对候选框中提取出的特征,使用分类器判别是否属于一个特定类别,对于属于某一特征的候选框,用回归器进一步调整其位置。
其中feature maps被共享用于后续的RPN层和RoI池化层。
RPN网络用于生成region proposals.该层通过softmax判断anchors属于前景(foreground)还是背景(background),再利用边框回归修正anchors,获得精确的proposals。
RPN里会使用一次3x3的卷积后,进行一个9通道的1x1卷积,还有一个36通道的1x1卷积。
其中,9 x 4的卷积用于预测公用特征层上每一个网格点上 每一个先验框的变化情况。(为什么说是变化情况呢,这是因为Faster-RCNN的预测结果需要结合先验框获得预测框,预测结果就是先验框的变化情况。)
9 x 1的卷积用于预测公用特征层上每一个网格点上每一个预测框内部是否包含了物体。

def get_rpn(base_layers, num_anchors): x = Conv2D(512, (3, 3), padding='same', activation='relu', kernel_initializer='normal', name='rpn_conv1')(base_layers) x_class = Conv2D(num_anchors, (1, 1), activation='sigmoid', kernel_initializer='uniform', name='rpn_out_class')(x) x_regr = Conv2D(num_anchors * 4, (1, 1), activation='linear', kernel_initializer='zero', name='rpn_out_regress')(x) x_class = Reshape((-1,1),name="classification")(x_class) x_regr = Reshape((-1,4),name="regression")(x_regr) return [x_class, x_regr, base_layers]
def get_model(config,num_classes): inputs = Input(shape=(None, None, 3)) roi_input = Input(shape=(None, 4)) base_layers = ResNet50(inputs) num_anchors = len(config.anchor_box_scales) * len(config.anchor_box_ratios) rpn = get_rpn(base_layers, num_anchors) model_rpn = Model(inputs, rpn[:2])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
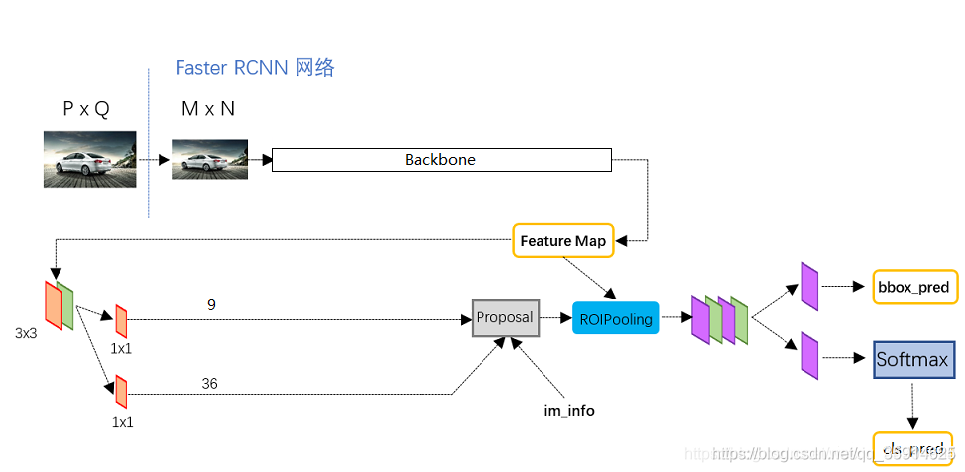
2.获得Proposal预测解码
Proposal预测框的解码部分,我们通过Backbone经过3x3的卷积和1x1获得了
num_priors x 4的卷积 用于预测 该特征层上 每一个网格点上 每一个先验框的变化情况。
num_priors x num_classes的卷积 用于预测 该特征层上 每一个网格点上 每一个预测框对应的种类(这里预测的是否有物体的概率)。
利用预设好的 预先设定好的9个anchor框进行调整。
先验框虽然可以代表一定的框的位置信息与框的大小信息,但是其是有限的,无法表示任意情况,因此还需要调整,faster rcnn1x1 num_priors x 4的卷积的结果对先验框进行调整。
num_priors x 4中的num_priors表示了这个网格点所包含的先验框数量,其中的4表示了框的左上角xy轴,右下角xy的调整情况。
代码:
def decode_boxes(self, mbox_loc, mbox_priorbox): # 获得先验框的宽与高 prior_width = mbox_priorbox[:, 2] - mbox_priorbox[:, 0] prior_height = mbox_priorbox[:, 3] - mbox_priorbox[:, 1] # 获得先验框的中心点 prior_center_x = 0.5 * (mbox_priorbox[:, 2] + mbox_priorbox[:, 0]) prior_center_y = 0.5 * (mbox_priorbox[:, 3] + mbox_priorbox[:, 1]) # 真实框距离先验框中心的xy轴偏移情况 decode_bbox_center_x = mbox_loc[:, 0] * prior_width / 4 decode_bbox_center_x += prior_center_x decode_bbox_center_y = mbox_loc[:, 1] * prior_height / 4 decode_bbox_center_y += prior_center_y # 真实框的宽与高的求取 decode_bbox_width = np.exp(mbox_loc[:, 2] / 4) decode_bbox_width *= prior_width decode_bbox_height = np.exp(mbox_loc[:, 3] /4) decode_bbox_height *= prior_height # 获取真实框的左上角与右下角 decode_bbox_xmin = decode_bbox_center_x - 0.5 * decode_bbox_width decode_bbox_ymin = decode_bbox_center_y - 0.5 * decode_bbox_height decode_bbox_xmax = decode_bbox_center_x + 0.5 * decode_bbox_width decode_bbox_ymax = decode_bbox_center_y + 0.5 * decode_bbox_height # 真实框的左上角与右下角进行堆叠 decode_bbox = np.concatenate((decode_bbox_xmin[:, None], decode_bbox_ymin[:, None], decode_bbox_xmax[:, None], decode_bbox_ymax[:, None]), axis=-1) # 防止超出0与1 decode_bbox = np.minimum(np.maximum(decode_bbox, 0.0), 1.0) return decode_bbox
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
3.Proposal非极大抑制
这里可以参考我的另一篇博客
当然得到最终的获得真实框的调整结果后,取出取出每一类得分大于confidence_threshold的框和得分。利用框的位置和得分进行非极大抑制,得到最终结果。
非极大抑制的执行过程如下所示:
1、对所有图片进行循环。
2、找出该图片中得分大于门限函数的框。在进行重合框筛选前就进行得分的筛选可以大幅度减少框的数量。
3、判断第2步中获得的框的种类与得分。
4、对种类进行循环,非极大抑制的作用是筛选出一定区域内属于同一种类得分最大的框,对种类进行循环可以帮助我们对每一个类分别进行非极大抑制。这里只有1类
5、根据得分对该种类进行从大到小排序。
6、每次取出得分最大的框,计算其与其它所有预测框的重合程度,重合程度过大的则剔除。
代码:
def detection_out(self, predictions, mbox_priorbox, num_classes, confidence_threshold=0.5): # 网络预测的结果 # 置信度 mbox_conf = predictions[0] mbox_loc = predictions[1] # 先验框 mbox_priorbox = mbox_priorbox results = [] # 对每一个图片进行处理 for i in range(len(mbox_loc)): results.append([]) decode_bbox = self.decode_boxes(mbox_loc[i], mbox_priorbox) for c in range(num_classes): c_confs = mbox_conf[i, :, c] c_confs_m = c_confs > confidence_threshold if len(c_confs[c_confs_m]) > 0: # 取出得分高于confidence_threshold的框 boxes_to_process = decode_bbox[c_confs_m] confs_to_process = c_confs[c_confs_m] # 进行iou的非极大抑制 feed_dict = {self.boxes: boxes_to_process, self.scores: confs_to_process} idx = self.sess.run(self.nms, feed_dict=feed_dict) # 取出在非极大抑制中效果较好的内容 good_boxes = boxes_to_process[idx] confs = confs_to_process[idx][:, None] # 将label、置信度、框的位置进行堆叠。 labels = c * np.ones((len(idx), 1)) c_pred = np.concatenate((labels, confs, good_boxes), axis=1) # 添加进result里 results[-1].extend(c_pred) if len(results[-1]) > 0: # 按照置信度进行排序 results[-1] = np.array(results[-1]) argsort = np.argsort(results[-1][:, 1])[::-1] results[-1] = results[-1][argsort] return results
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
经过Proposal解码和非极大抑制,默认传入ROIPing有300个框框
def detect_image(self, image): image_shape = np.array(np.shape(image)[0:2]) old_width = image_shape[1] old_height = image_shape[0] old_image = copy.deepcopy(image) width, height = get_new_img_size(old_width, old_height) image = image.resize([width, height]) photo = np.array(image, dtype=np.float64) # 图片预处理,归一化 photo = preprocess_input(np.expand_dims(photo, 0)) preds = self.model_rpn.predict(photo) # 将预测结果进行解码 anchors = get_anchors(self.get_img_output_length(width, height), width, height) rpn_results = self.bbox_util.detection_out(preds, anchors, 1, confidence_threshold=0) R = rpn_results[0][:, 2:] print(len(R))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
4.feature map上进行截取
事实上建议框就是对图片哪一个区域有物体存在进行初步筛选。
通过主干特征提取网络,我们可以获得一个公用特征层,当输入图片为600x600x3的时候,它的shape是38x38x1024,然后建议框利用ROIpooing会对这个公用特征层进行截取。
其中RoiPoolingConv就是建议框会对这38x38个区域进行截取,也就是认为这些区域里存在目标,然后将截取的结果进行resize,resize到14x14x1024
class RoiPoolingConv(Layer): ''' ROI pooling layer for 2D inputs. See Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition, K. He, X. Zhang, S. Ren, J. Sun # Arguments pool_size: int Size of pooling region to use. pool_size = 7 will result in a 7x7 region. num_rois: number of regions of interest to be used # Input shape list of two 4D tensors [X_img,X_roi] with shape: X_img: `(1, channels, rows, cols)` if dim_ordering='th' or 4D tensor with shape: `(1, rows, cols, channels)` if dim_ordering='tf'. X_roi: `(1,num_rois,4)` list of rois, with ordering (x,y,w,h) # Output shape 3D tensor with shape: `(1, num_rois, channels, pool_size, pool_size)` ''' def __init__(self, pool_size, num_rois, **kwargs): self.dim_ordering = K.image_dim_ordering() assert self.dim_ordering in {'tf', 'th'}, 'dim_ordering must be in {tf, th}' self.pool_size = pool_size self.num_rois = num_rois super(RoiPoolingConv, self).__init__(**kwargs) def build(self, input_shape): self.nb_channels = input_shape[0][3] def compute_output_shape(self, input_shape): return None, self.num_rois, self.pool_size, self.pool_size, self.nb_channels def call(self, x, mask=None): assert(len(x) == 2) img = x[0] rois = x[1] outputs = [] for roi_idx in range(self.num_rois): x = rois[0, roi_idx, 0] y = rois[0, roi_idx, 1] w = rois[0, roi_idx, 2] h = rois[0, roi_idx, 3] x = K.cast(x, 'int32') y = K.cast(y, 'int32') w = K.cast(w, 'int32') h = K.cast(h, 'int32') rs = tf.image.resize_images(img[:, y:y+h, x:x+w, :], (self.pool_size, self.pool_size)) outputs.append(rs) final_output = K.concatenate(outputs, axis=0) final_output = K.reshape(final_output, (1, self.num_rois, self.pool_size, self.pool_size, self.nb_channels)) final_output = K.permute_dimensions(final_output, (0, 1, 2, 3, 4)) return final_output
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
5. 获得最后预测结果
每次输入的建议框的数量默认情况是128(论文里说的32)但是128效果要好点。然后再对每个建议框再进行残差网络。利用全连接获得(num_classes-1)x4全连接。num_classes-1为20,因为采用的是voc数据集。num_classes的全连接用于对最后获得的框进行分类,(num_classes-1)x4全连接用于对相应的建议框进行调整,之所以-1是不包括被认定为背景的框。

def identity_block_td(input_tensor, kernel_size, filters, stage, block, trainable=True): nb_filter1, nb_filter2, nb_filter3 = filters if K.image_dim_ordering() == 'tf': bn_axis = 3 else: bn_axis = 1 conv_name_base = 'res' + str(stage) + block + '_branch' bn_name_base = 'bn' + str(stage) + block + '_branch' x = TimeDistributed(Conv2D(nb_filter1, (1, 1), trainable=trainable, kernel_initializer='normal'), name=conv_name_base + '2a')(input_tensor) x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2a')(x) x = Activation('relu')(x) x = TimeDistributed(Conv2D(nb_filter2, (kernel_size, kernel_size), trainable=trainable, kernel_initializer='normal',padding='same'), name=conv_name_base + '2b')(x) x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2b')(x) x = Activation('relu')(x) x = TimeDistributed(Conv2D(nb_filter3, (1, 1), trainable=trainable, kernel_initializer='normal'), name=conv_name_base + '2c')(x) x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2c')(x) x = Add()([x, input_tensor]) x = Activation('relu')(x) return x
def conv_block_td(input_tensor, kernel_size, filters, stage, block, input_shape, strides=(2, 2), trainable=True): nb_filter1, nb_filter2, nb_filter3 = filters if K.image_dim_ordering() == 'tf': bn_axis = 3 else: bn_axis = 1 conv_name_base = 'res' + str(stage) + block + '_branch' bn_name_base = 'bn' + str(stage) + block + '_branch' x = TimeDistributed(Conv2D(nb_filter1, (1, 1), strides=strides, trainable=trainable, kernel_initializer='normal'), input_shape=input_shape, name=conv_name_base + '2a')(input_tensor) x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2a')(x) x = Activation('relu')(x) x = TimeDistributed(Conv2D(nb_filter2, (kernel_size, kernel_size), padding='same', trainable=trainable, kernel_initializer='normal'), name=conv_name_base + '2b')(x) x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2b')(x) x = Activation('relu')(x) x = TimeDistributed(Conv2D(nb_filter3, (1, 1), kernel_initializer='normal'), name=conv_name_base + '2c', trainable=trainable)(x) x = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '2c')(x) shortcut = TimeDistributed(Conv2D(nb_filter3, (1, 1), strides=strides, trainable=trainable, kernel_initializer='normal'), name=conv_name_base + '1')(input_tensor) shortcut = TimeDistributed(BatchNormalization(axis=bn_axis), name=bn_name_base + '1')(shortcut) x = Add()([x, shortcut]) x = Activation('relu')(x) return x
def classifier_layers(x, input_shape, trainable=False): x = conv_block_td(x, 3, [512, 512, 2048], stage=5, block='a', input_shape=input_shape, strides=(2, 2), trainable=trainable) x = identity_block_td(x, 3, [512, 512, 2048], stage=5, block='b', trainable=trainable) x = identity_block_td(x, 3, [512, 512, 2048], stage=5, block='c', trainable=trainable) x = TimeDistributed(AveragePooling2D((7, 7)), name='avg_pool')(x) return x def get_classifier(base_layers, input_rois, num_rois, nb_classes=21, trainable=False): pooling_regions = 14 input_shape = (num_rois, 14, 14, 1024) out_roi_pool = RoiPoolingConv(pooling_regions, num_rois)([base_layers, input_rois]) out = classifier_layers(out_roi_pool, input_shape=input_shape, trainable=True) out = TimeDistributed(Flatten())(out) out_class = TimeDistributed(Dense(nb_classes, activation='softmax', kernel_initializer='zero'), name='dense_class_{}'.format(nb_classes))(out) out_regr = TimeDistributed(Dense(4 * (nb_classes-1), activation='linear', kernel_initializer='zero'), name='dense_regress_{}'.format(nb_classes))(out) return [out_class, out_regr]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
在预测完还要进行最后一非极大抑制和解码,获得预测结果。
解码:
R = rpn_results[0][:, 2:] # print(len(R)) R[:, 0] = np.array(np.round(R[:, 0] * width / self.config.rpn_stride), dtype=np.int32) R[:, 1] = np.array(np.round(R[:, 1] * height / self.config.rpn_stride), dtype=np.int32) R[:, 2] = np.array(np.round(R[:, 2] * width / self.config.rpn_stride), dtype=np.int32) R[:, 3] = np.array(np.round(R[:, 3] * height / self.config.rpn_stride), dtype=np.int32) R[:, 2] -= R[:, 0] R[:, 3] -= R[:, 1] base_layer = preds[2] delete_line = [] for i, r in enumerate(R): if r[2] < 1 or r[3] < 1: delete_line.append(i) R = np.delete(R, delete_line, axis=0) bboxes = [] probs = [] labels = [] for jk in range(R.shape[0] // self.config.num_rois + 1): ROIs = np.expand_dims(R[self.config.num_rois * jk:self.config.num_rois * (jk + 1), :], axis=0) if ROIs.shape[1] == 0: break # print(R.shape[0] // self.config.num_rois) if jk == R.shape[0] // self.config.num_rois: # pad R curr_shape = ROIs.shape target_shape = (curr_shape[0], self.config.num_rois, curr_shape[2]) ROIs_padded = np.zeros(target_shape).astype(ROIs.dtype) ROIs_padded[:, :curr_shape[1], :] = ROIs print( ROIs[0, 0, :]) ROIs_padded[0, curr_shape[1]:, :] = ROIs[0, 0, :] ROIs = ROIs_padded [P_cls, P_regr] = self.model_classifier.predict([base_layer, ROIs]) for ii in range(P_cls.shape[1]): if np.max(P_cls[0, ii, :-1]) < self.confidence: continue label = np.argmax(P_cls[0, ii, :-1]) (x, y, w, h) = ROIs[0, ii, :] cls_num = np.argmax(P_cls[0, ii, :-1]) (tx, ty, tw, th) = P_regr[0, ii, 4 * cls_num:4 * (cls_num + 1)] tx /= self.config.classifier_regr_std[0] ty /= self.config.classifier_regr_std[1] tw /= self.config.classifier_regr_std[2] th /= self.config.classifier_regr_std[3] cx = x + w / 2. cy = y + h / 2. cx1 = tx * w + cx cy1 = ty * h + cy w1 = math.exp(tw) * w h1 = math.exp(th) * h x1 = cx1 - w1 / 2. y1 = cy1 - h1 / 2. x2 = cx1 + w1 / 2 y2 = cy1 + h1 / 2 x1 = int(round(x1)) y1 = int(round(y1)) x2 = int(round(x2)) y2 = int(round(y2)) bboxes.append([x1, y1, x2, y2]) probs.append(np.max(P_cls[0, ii, :-1])) labels.append(label) if len(bboxes) == 0: return old_image # 筛选出其中得分高于confidence的框 labels = np.array(labels) probs = np.array(probs) boxes = np.array(bboxes, dtype=np.float32) boxes[:, 0] = boxes[:, 0] * self.config.rpn_stride / width boxes[:, 1] = boxes[:, 1] * self.config.rpn_stride / height boxes[:, 2] = boxes[:, 2] * self.config.rpn_stride / width boxes[:, 3] = boxes[:, 3] * self.config.rpn_stride / height results = np.array( self.bbox_util.nms_for_out(np.array(labels), np.array(probs), np.array(boxes), self.num_classes - 1, 0.4)) top_label_indices = results[:, 0] top_conf = results[:, 1] boxes = results[:, 2:] boxes[:, 0] = boxes[:, 0] * old_width boxes[:, 1] = boxes[:, 1] * old_height boxes[:, 2] = boxes[:, 2] * old_width boxes[:, 3] = boxes[:, 3] * old_height
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
非极大抑制:
def nms_for_out(self,all_labels,all_confs,all_bboxes,num_classes,nms): results = [] nms_out = tf.image.non_max_suppression(self.boxes, self.scores, self._top_k, iou_threshold=nms) for c in range(num_classes): c_pred = [] mask = all_labels == c if len(all_confs[mask]) > 0: # 取出得分高于confidence_threshold的框 boxes_to_process = all_bboxes[mask] confs_to_process = all_confs[mask] # 进行iou的非极大抑制 feed_dict = {self.boxes: boxes_to_process, self.scores: confs_to_process} idx = self.sess.run(nms_out, feed_dict=feed_dict) # 取出在非极大抑制中效果较好的内容 good_boxes = boxes_to_process[idx] confs = confs_to_process[idx][:, None] # 将label、置信度、框的位置进行堆叠。 labels = c * np.ones((len(idx), 1)) c_pred = np.concatenate((labels, confs, good_boxes),axis=1) results.extend(c_pred) return results
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24

训练部分
在训练部分我们先要训练建议框网络,然后在训练ROIpoling后面的网络。
1、建议框网络的训练
真实框的编码
在我们出入网络的时候真实框并不是和预测值相同类型数值,所以不能直接训练和计算loss。我们需要转换成对于faster-rcnn网络的预测结果的的格式信息。从预测结果获得真实框的过程被称作解码,而从真实框获得预测结果的过程就是编码的过程。
def encode_box(self, box, return_iou=True): iou = self.iou(box) encoded_box = np.zeros((self.num_priors, 4 + return_iou)) # 找到每一个真实框,重合程度较高的先验框 assign_mask = iou > self.overlap_threshold if not assign_mask.any(): assign_mask[iou.argmax()] = True if return_iou: encoded_box[:, -1][assign_mask] = iou[assign_mask] # 找到对应的先验框 assigned_priors = self.priors[assign_mask] # 逆向编码,将真实框转化为FasterRCNN预测结果的格式 # 先计算真实框的中心与长宽 box_center = 0.5 * (box[:2] + box[2:]) box_wh = box[2:] - box[:2] # 再计算重合度较高的先验框的中心与长宽 assigned_priors_center = 0.5 * (assigned_priors[:, :2] + assigned_priors[:, 2:4]) assigned_priors_wh = (assigned_priors[:, 2:4] - assigned_priors[:, :2]) # 逆向求取FasterRCNN应该有的预测结果 encoded_box[:, :2][assign_mask] = box_center - assigned_priors_center encoded_box[:, :2][assign_mask] /= assigned_priors_wh encoded_box[:, :2][assign_mask] *= 4 encoded_box[:, 2:4][assign_mask] = np.log(box_wh / assigned_priors_wh) encoded_box[:, 2:4][assign_mask] *= 4 return encoded_box.ravel()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
但是由于原始图片中可能存在多个真实框,可能同一个先验框会与多个真实框重合度较高,我们只取其中与真实框重合度最高的就可以了。
我们还要经过一次筛选,iou最大的那个真实框筛选出来。
我们会忽略一些重合度相对较高但是不是非常高的先验框,一般将重合度在0.4-0.5之间的先验框进行忽略。
def ignore_box(self, box): iou = self.iou(box) ignored_box = np.zeros((self.num_priors, 1)) # 找到每一个真实框,重合程度较高的先验框 assign_mask = (iou > self.ignore_threshold)&(iou<self.overlap_threshold) if not assign_mask.any(): assign_mask[iou.argmax()] = True ignored_box[:, 0][assign_mask] = iou[assign_mask] return ignored_box.ravel() def assign_boxes(self, boxes, anchors): self.num_priors = len(anchors) self.priors = anchors assignment = np.zeros((self.num_priors, 4 + 1)) assignment[:, 4] = 0.0 if len(boxes) == 0: return assignment # 对每一个真实框都进行iou计算 ingored_boxes = np.apply_along_axis(self.ignore_box, 1, boxes[:, :4]) # 取重合程度最大的先验框,并且获取这个先验框的index ingored_boxes = ingored_boxes.reshape(-1, self.num_priors, 1) # (num_priors) ignore_iou = ingored_boxes[:, :, 0].max(axis=0) # (num_priors) ignore_iou_mask = ignore_iou > 0 assignment[:, 4][ignore_iou_mask] = -1 # (n, num_priors, 5) encoded_boxes = np.apply_along_axis(self.encode_box, 1, boxes[:, :4]) # 每一个真实框的编码后的值,和iou # (n, num_priors) encoded_boxes = encoded_boxes.reshape(-1, self.num_priors, 5) # 取重合程度最大的先验框,并且获取这个先验框的index # (num_priors) best_iou = encoded_boxes[:, :, -1].max(axis=0) # (num_priors) best_iou_idx = encoded_boxes[:, :, -1].argmax(axis=0) # (num_priors) best_iou_mask = best_iou > 0 # 某个先验框它属于哪个真实框 best_iou_idx = best_iou_idx[best_iou_mask] assign_num = len(best_iou_idx) # 保留重合程度最大的先验框的应该有的预测结果 # 哪些先验框存在真实框 encoded_boxes = encoded_boxes[:, best_iou_mask, :] assignment[:, :4][best_iou_mask] = encoded_boxes[best_iou_idx,np.arange(assign_num),:4] # 4代表为背景的概率,为0 assignment[:, 4][best_iou_mask] = 1 # 通过assign_boxes我们就获得了,输入进来的这张图片,应该有的预测结果是什么样子的 return assignment
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
在正负样本数量我们总共设置了256个,如果正样本大于128个,我们随机选128个,如果不满足用负样本来填充。
def generate(self): while True: shuffle(self.train_lines) lines = self.train_lines for annotation_line in lines: img,y=self.get_random_data(annotation_line) height, width, _ = np.shape(img) if len(y)==0: continue boxes = np.array(y[:,:4],dtype=np.float32) boxes[:,0] = boxes[:,0]/width boxes[:,1] = boxes[:,1]/height boxes[:,2] = boxes[:,2]/width boxes[:,3] = boxes[:,3]/height box_heights = boxes[:,3] - boxes[:,1] box_widths = boxes[:,2] - boxes[:,0] if (box_heights<=0).any() or (box_widths<=0).any(): continue y[:,:4] = boxes[:,:4] anchors = get_anchors(get_img_output_length(width,height),width,height) # 计算真实框对应的先验框,与这个先验框应当有的预测结果 assignment = self.bbox_util.assign_boxes(y,anchors) num_regions = 256 classification = assignment[:,4] regression = assignment[:,:] mask_pos = classification[:]>0 num_pos = len(classification[mask_pos]) if num_pos > num_regions/2: val_locs = random.sample(range(num_pos), int(num_pos - num_regions/2)) temp_classification = classification[mask_pos] temp_regression = regression[mask_pos] temp_classification[val_locs] = -1 temp_regression[val_locs,-1] = -1 classification[mask_pos] = temp_classification regression[mask_pos] = temp_regression mask_neg = classification[:]==0 num_neg = len(classification[mask_neg]) mask_pos = classification[:]>0 num_pos = len(classification[mask_pos]) if len(classification[mask_neg]) + num_pos > num_regions: val_locs = random.sample(range(num_neg), int(num_neg + num_pos - num_regions)) temp_classification = classification[mask_neg] temp_classification[val_locs] = -1 classification[mask_neg] = temp_classification classification = np.reshape(classification,[-1,1]) regression = np.reshape(regression,[-1,5]) tmp_inp = np.array(img) tmp_targets = [np.expand_dims(np.array(classification,dtype=np.float32),0),np.expand_dims(np.array(regression,dtype=np.float32),0)] yield preprocess_input(np.expand_dims(tmp_inp,0)), tmp_targets, np.expand_dims(y,0)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
loss值计算
常规的交叉熵loss和smooth计算
smooth计算:看预备知识

def cls_loss(ratio=3): def _cls_loss(y_true, y_pred): # y_true [batch_size, num_anchor, num_classes+1] # y_pred [batch_size, num_anchor, num_classes] labels = y_true anchor_state = y_true[:,:,-1] # -1 是需要忽略的, 0 是背景, 1 是存在目标 classification = y_pred # 找出存在目标的先验框 indices_for_object = tf.where(keras.backend.equal(anchor_state, 1)) labels_for_object = tf.gather_nd(labels, indices_for_object) classification_for_object = tf.gather_nd(classification, indices_for_object) cls_loss_for_object = keras.backend.binary_crossentropy(labels_for_object, classification_for_object) # 找出实际上为背景的先验框 indices_for_back = tf.where(keras.backend.equal(anchor_state, 0)) labels_for_back = tf.gather_nd(labels, indices_for_back) classification_for_back = tf.gather_nd(classification, indices_for_back) # 计算每一个先验框应该有的权重 cls_loss_for_back = keras.backend.binary_crossentropy(labels_for_back, classification_for_back) # 标准化,实际上是正样本的数量 normalizer_pos = tf.where(keras.backend.equal(anchor_state, 1)) normalizer_pos = keras.backend.cast(keras.backend.shape(normalizer_pos)[0], keras.backend.floatx()) normalizer_pos = keras.backend.maximum(keras.backend.cast_to_floatx(1.0), normalizer_pos) normalizer_neg = tf.where(keras.backend.equal(anchor_state, 0)) normalizer_neg = keras.backend.cast(keras.backend.shape(normalizer_neg)[0], keras.backend.floatx()) normalizer_neg = keras.backend.maximum(keras.backend.cast_to_floatx(1.0), normalizer_neg) # 将所获得的loss除上正样本的数量 cls_loss_for_object = keras.backend.sum(cls_loss_for_object)/normalizer_pos cls_loss_for_back = ratio*keras.backend.sum(cls_loss_for_back)/normalizer_neg # 总的loss loss = cls_loss_for_object + cls_loss_for_back return loss return _cls_loss
def smooth_l1(sigma=1.0): sigma_squared = sigma ** 2 def _smooth_l1(y_true, y_pred): # y_true [batch_size, num_anchor, 4+1] # y_pred [batch_size, num_anchor, 4] regression = y_pred regression_target = y_true[:, :, :-1] anchor_state = y_true[:, :, -1] # 找到正样本 indices = tf.where(keras.backend.equal(anchor_state, 1)) regression = tf.gather_nd(regression, indices) regression_target = tf.gather_nd(regression_target, indices) # 计算 smooth L1 loss # f(x) = 0.5 * (sigma * x)^2 if |x| < 1 / sigma / sigma # |x| - 0.5 / sigma / sigma otherwise regression_diff = regression - regression_target regression_diff = keras.backend.abs(regression_diff) regression_loss = tf.where( keras.backend.less(regression_diff, 1.0 / sigma_squared), 0.5 * sigma_squared * keras.backend.pow(regression_diff, 2), regression_diff - 0.5 / sigma_squared ) normalizer = keras.backend.maximum(1, keras.backend.shape(indices)[0]) normalizer = keras.backend.cast(normalizer, dtype=keras.backend.floatx()) loss = keras.backend.sum(regression_loss) / normalizer return loss return _smooth_l1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
2、ROI网络的先验框的训练
已经可以对建议框网络进行训练了,建议框网络会提供一些位置的建议,在ROI网络部分,其会将建议框根据进行一定的截取,并获得对应的预测结果,事实上就是将上一步建议框当作了ROI网络的先验框。
因此,我们需要计算所有建议框和真实框的重合程度,并进行筛选,如果某个真实框和建议框的重合程度大于0.5则认为该建议框为正样本,如果重合程度小于0.5大于0.1则认为该建议框为负样本,在正负样本数量我们总共设置了128个,如果正样本大于64个,我们随机选64个,如果不满足用负样本来填充。
R = results[0][:, 2:] X2, Y1, Y2, IouS = calc_iou(R, config, boxes[0], width, height, NUM_CLASSES) if X2 is None: rpn_accuracy_rpn_monitor.append(0) rpn_accuracy_for_epoch.append(0) continue neg_samples = np.where(Y1[0, :, -1] == 1) pos_samples = np.where(Y1[0, :, -1] == 0) if len(neg_samples) > 0: neg_samples = neg_samples[0] else: neg_samples = [] if len(pos_samples) > 0: pos_samples = pos_samples[0] else: pos_samples = [] rpn_accuracy_rpn_monitor.append(len(pos_samples)) rpn_accuracy_for_epoch.append((len(pos_samples))) if len(neg_samples)==0: continue if len(pos_samples) < config.num_rois//2: selected_pos_samples = pos_samples.tolist() else: selected_pos_samples = np.random.choice(pos_samples, config.num_rois//2, replace=False).tolist() try: selected_neg_samples = np.random.choice(neg_samples, config.num_rois - len(selected_pos_samples), replace=False).tolist() except: selected_neg_samples = np.random.choice(neg_samples, config.num_rois - len(selected_pos_samples), replace=True).tolist() sel_samples = selected_pos_samples + selected_neg_samples loss_class = model_classifier.train_on_batch([X, X2[:, sel_samples, :]], [Y1[:, sel_samples, :], Y2[:, sel_samples, :]]) write_log(callback, ['detection_cls_loss', 'detection_reg_loss', 'detection_acc'], loss_class, train_step) losses[iter_num, 0] = loss_rpn[1] losses[iter_num, 1] = loss_rpn[2] losses[iter_num, 2] = loss_class[1] losses[iter_num, 3] = loss_class[2] losses[iter_num, 4] = loss_class[3] train_step += 1 iter_num += 1 progbar.update(iter_num, [('rpn_cls', np.mean(losses[:iter_num, 0])), ('rpn_regr', np.mean(losses[:iter_num, 1])), ('detector_cls', np.mean(losses[:iter_num, 2])), ('detector_regr', np.mean(losses[:iter_num, 3]))])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
def calc_iou(R, config, all_boxes, width, height, num_classes): # print(all_boxes) bboxes = all_boxes[:,:4] gta = np.zeros((len(bboxes), 4)) for bbox_num, bbox in enumerate(bboxes): gta[bbox_num, 0] = int(round(bbox[0]*width/config.rpn_stride)) gta[bbox_num, 1] = int(round(bbox[1]*height/config.rpn_stride)) gta[bbox_num, 2] = int(round(bbox[2]*width/config.rpn_stride)) gta[bbox_num, 3] = int(round(bbox[3]*height/config.rpn_stride)) x_roi = [] y_class_num = [] y_class_regr_coords = [] y_class_regr_label = [] IoUs = [] # print(gta) for ix in range(R.shape[0]): x1 = R[ix, 0]*width/config.rpn_stride y1 = R[ix, 1]*height/config.rpn_stride x2 = R[ix, 2]*width/config.rpn_stride y2 = R[ix, 3]*height/config.rpn_stride x1 = int(round(x1)) y1 = int(round(y1)) x2 = int(round(x2)) y2 = int(round(y2)) # print([x1, y1, x2, y2]) best_iou = 0.0 best_bbox = -1 for bbox_num in range(len(bboxes)): curr_iou = iou([gta[bbox_num, 0], gta[bbox_num, 1], gta[bbox_num, 2], gta[bbox_num, 3]], [x1, y1, x2, y2]) if curr_iou > best_iou: best_iou = curr_iou best_bbox = bbox_num # print(best_iou) if best_iou < config.classifier_min_overlap: continue else: w = x2 - x1 h = y2 - y1 x_roi.append([x1, y1, w, h]) IoUs.append(best_iou) if config.classifier_min_overlap <= best_iou < config.classifier_max_overlap: label = -1 elif config.classifier_max_overlap <= best_iou: label = int(all_boxes[best_bbox,-1]) cxg = (gta[best_bbox, 0] + gta[best_bbox, 2]) / 2.0 cyg = (gta[best_bbox, 1] + gta[best_bbox, 3]) / 2.0 cx = x1 + w / 2.0 cy = y1 + h / 2.0 tx = (cxg - cx) / float(w) ty = (cyg - cy) / float(h) tw = np.log((gta[best_bbox, 2] - gta[best_bbox, 0]) / float(w)) th = np.log((gta[best_bbox, 3] - gta[best_bbox, 1]) / float(h)) else: print('roi = {}'.format(best_iou)) raise RuntimeError # print(label) class_label = num_classes * [0] class_label[label] = 1 y_class_num.append(copy.deepcopy(class_label)) coords = [0] * 4 * (num_classes - 1) labels = [0] * 4 * (num_classes - 1) if label != -1: label_pos = 4 * label sx, sy, sw, sh = config.classifier_regr_std coords[label_pos:4+label_pos] = [sx*tx, sy*ty, sw*tw, sh*th] labels[label_pos:4+label_pos] = [1, 1, 1, 1] y_class_regr_coords.append(copy.deepcopy(coords)) y_class_regr_label.append(copy.deepcopy(labels)) else: y_class_regr_coords.append(copy.deepcopy(coords)) y_class_regr_label.append(copy.deepcopy(labels)) if len(x_roi) == 0: return None, None, None, None X = np.array(x_roi) # print(X) Y1 = np.array(y_class_num) Y2 = np.concatenate([np.array(y_class_regr_label),np.array(y_class_regr_coords)],axis=1) return np.expand_dims(X, axis=0), np.expand_dims(Y1, axis=0), np.expand_dims(Y2, axis=0), IoUs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
文章来源: blog.csdn.net,作者:快了的程序猿小可哥,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_35914625/article/details/108413165