回顾前文
DataFrame
DataFrame是pandas最重要的类,我们通过分析DataFrame的属性来了解数据,通过使用DataFrame的方法来分析数据。
DataFrame关键属性案例演示
csv文件依旧使用上一篇的test.csv。
columns属性
import pandas as pd
csv_file = 'test.csv'
df = pd.read_csv(csv_file)
print(df.columns)
print(type(df.columns))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Index(['a', 'b'], dtype='object')
<class 'pandas.core.indexes.base.Index'> # pandas的一个关键属性
- 1
- 2
换上values:print(df.columns.values)
结果:['a' 'b']
是所有列的名称。
现在要找出所有包含‘a’的列:
for name in df.columns.values: if name.find('a')>=0: print(name)
- 1
- 2
- 3
这是一个办法。那有没有简洁一点的办法,就像lambda函数那样的,也是有办法的。
list(filter(lambda x:x.find('a')>=0,df.columns.values))
# filter生成器参数:第一个为函数指针,第二个为一个数组,作为函数指针的参数传入。
# 由于filter的返回值是一个元组,所以用列表强转一下
- 1
- 2
- 3
- 4
index属性
print(df.index)
print(type(df.index))
- 1
- 2
RangeIndex(start=0, stop=3, step=1)
<class 'pandas.core.indexes.range.RangeIndex'>
- 1
- 2
从0开始,到3结束,步长为1。
values属性
print(df.values)
print(type(df.values))
- 1
- 2
[[ 1. 2.]
[ 3. 4.]
[nan 5.]]
<class 'numpy.ndarray'>
- 1
- 2
- 3
- 4
可以看出,是一个多维数组。
dtypes属性
print(df.dtypes['a'])
print(type(df.dtypes))
- 1
- 2
float64
<class 'pandas.core.series.Series'>
- 1
- 2
这个我就不多说了吧,上一篇都有讲过了。
size 和 shape 属性
这俩直接看吧,
print(df.size)
print(df.shape)
- 1
- 2
- 3
6 # 有多少个元素
(3, 2) # 几行几列
- 1
- 2
pandas的数据类型
多说无益,直接看:
基础数据类型:
离散型:objec(字符串),bool,timedelta
连续型:int,float,datatime
数据类型转换:
astype方法
to_numeric方法
to_datatime方法
上一篇讲过的这里不再赘述。
converters参数转换数据类型
前边讲过可以在读取的时候指定dtype参数对指定列的数据类型进行修改,但是那个太笼统了,有时候你就改不了,像我昨天遇到一个NAN,还不让我强转为int类型。
def toint(x): try: return int(float(x)) # 你也不知道传进来的是什么数据类型,还是先转为float再说 except: return 0 df = pd.read_csv(csv_file,converters={'a':toint})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
解析时间数据类型
为了操作方便,我给csv文件加上了一列时间:
a,b,data
1,2,2018-10-1
3,4,2020-12-12
,5
- 1
- 2
- 3
- 4
df = pd.read_csv(csv_file,parse_dates=['data'])
print(df.dtypes['data'])
print(df.head())
- 1
- 2
- 3
datetime64[ns] a b data
0 1.0 2 2018-10-01
1 3.0 4 2020-12-12
2 NaN 5 NaT
- 1
- 2
- 3
- 4
- 5
- 6
pandas数据持久化
保存数据到csv
to_csv()是DataFrame类的方法,常用参数释义如下:
path_or_buf:文件保存位置
sep:分隔符,如果不写,默认是‘,’
columns:指定保存的列
header:是否保存列名称
index:是否保存索引列
index_label:索引列名称
- 1
- 2
- 3
- 4
- 5
- 6
实验
保存到csv
df = pd.read_csv(csv_file,parse_dates=['data'])
df.to_csv('test2.csv',sep='\t')
- 1
- 2
- 3
a b data
0 1.0 2 2020-10-21
1 3.0 4 2020-10-21
2 5
- 1
- 2
- 3
- 4
- 5
指定列保存且不保存索引列
df = pd.read_csv(csv_file,parse_dates=['data'])
df.to_csv('test3.csv',columns='a',index = False)
- 1
- 2
- 3
a
1.0
3.0
""
- 1
- 2
- 3
- 4
指定索引列
df = pd.read_csv(csv_file,parse_dates=['data'])
df.to_csv('test4.csv',index_label='ID')
# 感觉更像是给索引列起个名字
- 1
- 2
- 3
- 4
ID,a,b,data
0,1.0,2,2020-10-21
1,3.0,4,2020-10-21
2,,5,
- 1
- 2
- 3
- 4
保存数据到json

示例

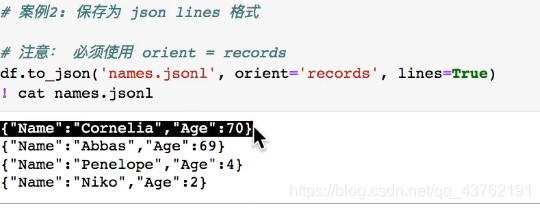
没拿到资料,所以暂时没有例子。
等我过两天做数据分析之后就有了。
保存数据到Excel
DataFrame.to_excel(excel_writer, sheet_name='Sheet1', columns=None, header=True, index=True)
- 1
参数释义:
好像也没啥好释义的了,前边都讲过了。
直接演示吧。
df = pd.read_csv(csv_file,parse_dates=['data'])
df.to_excel('text1.xlsx',sheet_name='a')
- 1
- 2
- 3
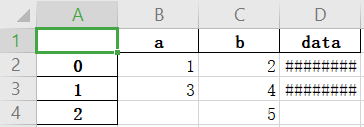
这个日期写入出了问题。。
怎么办?凉拌
转object写入,动手试试,亲测可用、
此外还要注意,在写入的时候,相应的Excel应在电脑上没有被人为打开、
往多个表中写入数据
这里需要使用到ExcelWriter
df = pd.read_csv(csv_file,parse_dates=['data'])
with pd.ExcelWriter('test4.xlsx') as f: df.to_excel(f,sheet_name='a',columns=['a'],index=True,index_label='ID') df.to_excel(f, sheet_name='b', columns=['b','data'], index=True, index_label='ID')
- 1
- 2
- 3
- 4
- 5
请自行查看结果。
保存数据到MySQL
def to_sql( self, name, con, schema=None, if_exists="fail", index=True, index_label=None, chunksize=None, dtype=None, method=None, )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
参数释义:(释义过的参数不再赘述)
schema:用于创建数据库对象,基本上都是使用默认值。
if_exists:如果表存在怎么办?
fail:抛出ValueError异常
replace:在插入数据之前删除表。注意不是仅删除数据,是删除原来的表,重新建表哦。
append:插入新数据。如果有主键,要避免主键冲突;看清表的格式,DataFrame的columns与表的columns是对应的;DF的index默认是作为一列数据的,也就是说默认会写入数据库的
- 1
- 2
- 3
index:将索引作为一列写入数据库,默认为True,也就是说默认DF的索引是要写入数据库的,index_label为列名
index_label:将索引写入数据库时的列名,默认为index;如果DF是多级索引,则index_label应为一个序列
chunksize:批处理,每次处理多少条数据。默认全部,一般没啥用,除非数据量太大,明显感觉卡的时候可以分批处理。
dtype:一个字典,指定列的数据类型。键是列的名字,值是sqlalchemy types或者sqlite3的字符串形式。如果是新建表,则需要指定类型,不然会以存储量最大类型作为默认类型。比如varchar类型就会成为text类型,空间资源浪费很多。如果是添加数据,则一般不需要规定该参数。
method:哪种类型的插入语句?
None:默认单行插入
‘multi’:多行插入
callable:以回调函数插入,写函数的名字,没用过。
- 1
- 2
- 3
在这里我想说:如果你不是很急着存取数据库,且数据量又大,不妨直接写到csv里面,后期直接从csv中导入数据到数据库。
使用apply处理每一行数据
DataFrame.apply(func,axis)
- 1
常用参数释义:
func:函数指针,用于内部处理的函数
axis:给函数指针传的参数,
1:按行处理数据
0:按列处理数据
- 1
- 2
演示
给a列数据乘方吧。
df = pd.read_csv(csv_file,dtype = {'data':object})
print(df.head())
df['aa'] = df.apply(lambda x: x.a*x.a,axis = 1) #你可以试试按列处理
print(df.head())
- 1
- 2
- 3
- 4
- 5
- 6
ID a b data
0 0 1.0 2 2020-10-21
1 1 3.0 4 2020-10-21
2 2 NaN 5 NaN ID a b data aa
0 0 1.0 2 2020-10-21 1.0
1 1 3.0 4 2020-10-21 9.0
2 2 NaN 5 NaN NaN
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
常用的就按行处理。
暂且到这儿,下一篇进入一个小小的实战总结。

文章来源: lion-wu.blog.csdn.net,作者:看,未来,版权归原作者所有,如需转载,请联系作者。
原文链接:lion-wu.blog.csdn.net/article/details/111767816