目录
一、为什么需要zookeeper
分布式协调管理者,用于在进群的环境下,选举出主节点,当主节点挂掉了之后,会选举其他的nameNode作为主节点,以保证集群的高可用性。
二、单机安装 zookeeper

三、常用的zk命令
ls 查看节点列表
create /app1 “some_data” 创建节点
set /app1 "other_data" 设置节点的值
get /app1 获取节点的值
delete /app1 删除节点

四、使用ZooInspector 查看zookeeper
下载 https://issues.apache.org/jira/secure/attachment/12436620/ZooInspector.zi
下载之后是一个压缩文件,解压后获取到一个jar包,直接双击打开
输入 zk 的 ip:端口 ,连接超时时间信息等
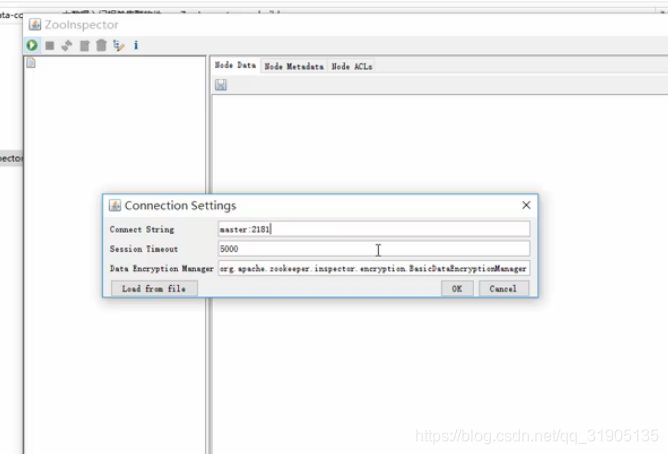
连接成功之后,双击 文件夹 展开即可看到zk节点列表
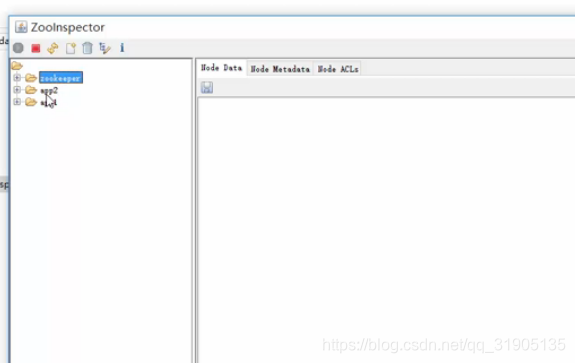
五、zk数据模型
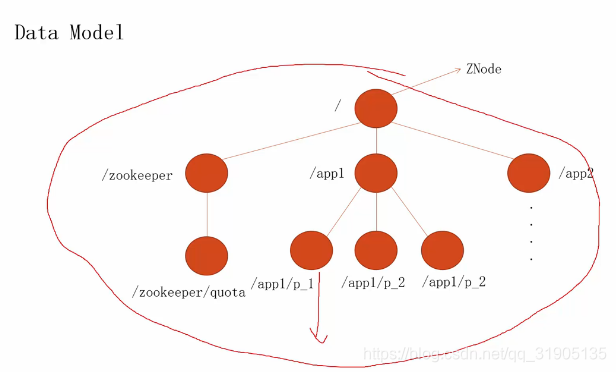
zk每个节点的默认最大为1M,超过1M会报错。
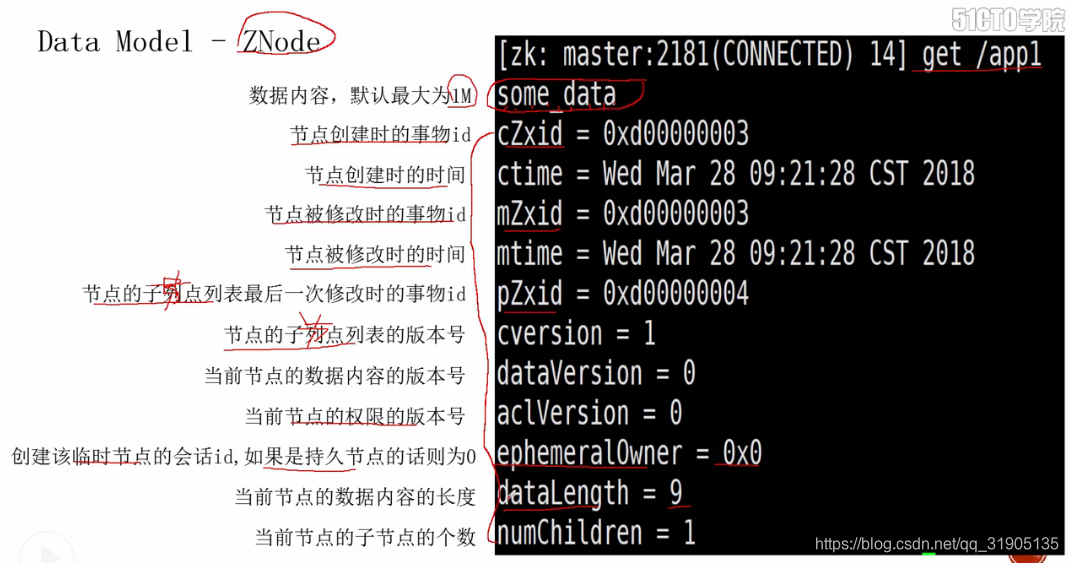
六、安装分布式的zk

七、分布式zk的特点
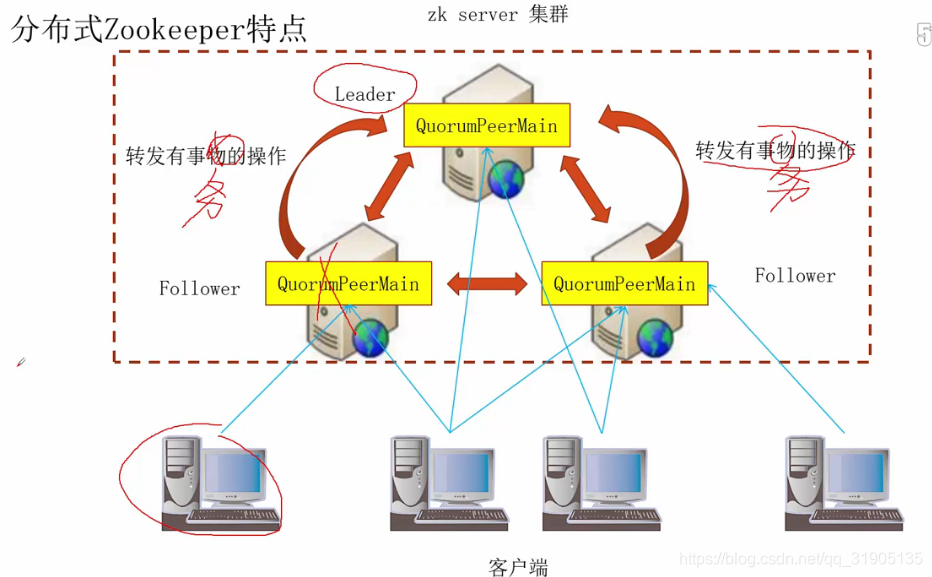
zk 集群会自动选举出一个 节点作为leader ,其他的节点作为 follower ,组成一个集群,对外提供服务。
不管连接哪个节点进行 数据的查看,数据都是一样的,说明每个节点之间的数据都是同步的。
如果在从节点上进行有关事务的操作,会先转发的leader节点上执行,比如创建节点等,
一个客户端可以同时连接这个集群中的多个节点,可以保证如果其中一个节点挂掉了,还能够继续从其他的节点获取数据。
文章来源: blog.csdn.net,作者:血煞风雨城2018,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_31905135/article/details/113337210