方法一:
-
#coding=utf-8
-
from bs4 import BeautifulSoup
-
from selenium import webdriver
-
-
urls = ('http://gkcx.eol.cn/soudaxue/queryProvince.html?page={}'.format(i) for i in range(1,166))
-
-
driver=webdriver.Firefox()
-
-
driver.maximize_window()
-
-
for url in urls:
-
#print ("正在访问{}".format(url))
-
driver.get(url)
-
data = driver.page_source
-
soup = BeautifulSoup(data, 'lxml')
-
grades = soup.find_all('tr')
-
for grade in grades:
-
if '<td>' in str(grade):
-
print(grade.get_text())
代码说明:
from bs4 import BeautifulSoup 使用BeautifulSoup 解析网页数据
from selenium import webdriver 使用selenium爬取动态数据
urls = ('http://gkcx.eol.cn/soudaxue/queryProvince.html?page={}'.format(i) for i in range(1,166)) 一个包含所有需要爬取的网站生成器
driver=webdriver.Firefox() 打开Firefox浏览器
driver.maximize_window() 窗口最大化
driver.get(url) 浏览器自动跳转到该url链接
data = driver.page_source 获取页面元素,里面就包含了需要爬取的数据
soup = BeautifulSoup(data, 'lxml')
grades = soup.find_all('tr')
for grade in grades:
if '<td>' in str(grade):
print(grade.get_text())
通过对数据的分析,写出上面的查找方法,即可获取所有数据。
通过这种方法获取数据,简单,也比较直观,缺点是太慢了。
现在通过方法二是获取数据。
用火狐浏览器打开需要爬取的网页,右键 查看元素,选择网络,默认就好。
(有些老版本的火狐浏览器可能需要安装firebug插件)
点击第二页,看看都加载了哪些网页和数据。
分析如下图:
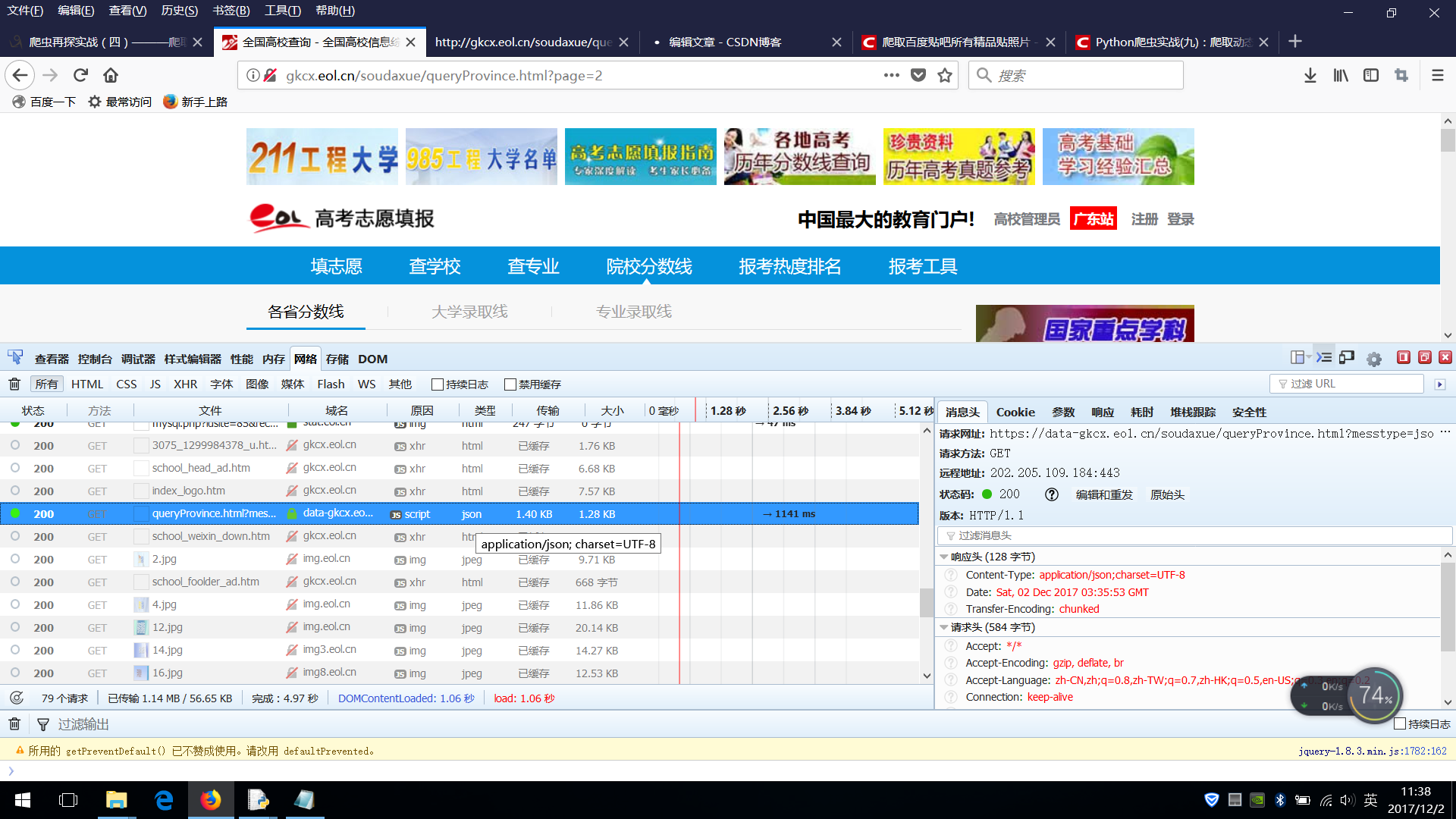
分析得知类型为json的那一栏即是我们需要的数据
查看消息头里面的请求网站
https://data-gkcx.eol.cn/soudaxue/queryProvince.html?messtype=jsonp&callback=jQuery183005011523805365803_1512185796058&luqutype3=&province3=&year3=&luqupici3=&page=2&size=10&_=1512185798203
真正的请求网站 https://data-gkcx.eol.cn/soudaxue/queryProvince.html
参数 messtype=jsonp&callback=jQuery183005011523805365803_1512185796058&luqutype3=&province3=&year3=&luqupici3=&page=2&size=10&_=1512185798203
也可以点击右侧的参数栏参看参数
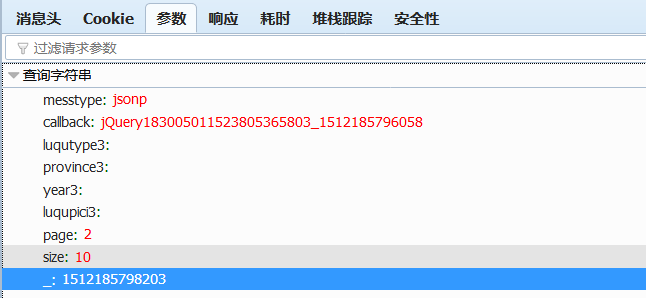
page 表示当前页数
size表示每页显示的条目数
写出代码
-
#coding=utf-8
-
import requests
-
import json
-
from prettytable import PrettyTable
-
-
-
if __name__=='__main__':
-
-
url = 'https://data-gkcx.eol.cn/soudaxue/queryProvince.html'
-
-
row = PrettyTable()
-
row.field_names = ["地区", "年份", "考生类别", "批次","分数线"]
-
-
for i in range(1,34):
-
data ={"messtype":"json",
-
"page":i,
-
"size":50,
-
"callback":
-
"jQuery1830426658582613074_1469201131959",
-
"_":"1469201133189",
-
}
-
school_datas = requests.post(url,data = data).json()
-
datas = school_datas["school"]
-
for data in datas:
-
row.add_row((data["province"] ,data["year"],data["bath"],data["type"], data["score"]))
-
-
-
print(row)
代码说明
for i in range(1,34):
一共是 1644条,每页显示的最大条数是50条,1600/50 = 32,还有44条就是33页,所以范围就应该是(1,34)
data ={"messtype":"json",
"page":i,
"size":50,
"callback":
"jQuery1830426658582613074_1469201131959",
"_":"1469201133189",
}
分析得出的提交数据,使用post方式。
文章来源: blog.csdn.net,作者:悦来客栈的老板,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq523176585/article/details/78693900