这是2016年作者早期分享的博客,希望对华为云的读者有帮助。最近SQL语句写得比较多,也发现了自己的很多不足之处。在此先写一篇关于SQL语句的在线笔记,方便大家学习和后面的工作,SQL Server、MySQL、Oracle基本语法都类似,接下来我需要阅读《SQL Server性能优化与管理的艺术》。 最后,希望这篇文章对你有所帮助吧!重点是select语句的用法。目录如下:
- 一.创建数据库和表
- 1.创建数据库
- 2.创建表并设置主键
- 3.插入数据
- 二.select查询操作
- 1.通过日期计算年龄
- 2.获取某列所有不同的属性值 group by
- 3.查询字符串匹配like和多值属性判断in
- 4.查询输出某列属性中某个特定值
- 5.子查询统计不同阶段学生总数
- 6.使用子查询按行动态输出学院相关信息
- 7.Oracle数据库null设置成自定义值的方法
- 8.Oracle计算百分比trunc方法
- 9.Oracle查询除法/运算
- 10.Oracle统计某个属性逗号分隔值的个数
- 11.Oracle使用CASE WHEN替代子查询
- 12.Oracle子查询中使用a.* 统计所有字段
- 13.Oracle使用decode函数防止除法分母为0
一. 创建数据库和表
1.创建数据库
--创建数据库
create database StudentMS
--使用数据库
use StudentMS
--删除数据库
--drop database StudentMS
2.创建表并设置主键(外键类似)

--创建学生表 (属性:姓名、学号(pk)、学院、出生日期、性别、籍贯)
create table xs
(
name varchar(10) not null,
id varchar(10) not null,
xy varchar(10),
birthday datetime,
xb char(2),
jg varchar(8)
)
--创建学生表主键:学号
alter table xs
add constraint
pk_xs primary key(id)
--创建表学生表外键:系代号 此表中xdh已被省略
alter table xs
add constraint
fk_xs foreign key(xdh)
references xb (xdh)
3.插入数据
总共插入10个学生的数据,其中如birthday可为null,如下:
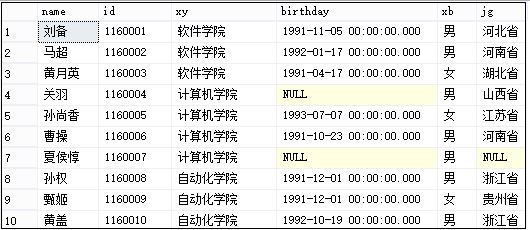
总共插入10个学生的数据,其中如birthday可为null,如下:
二. select查询操作
1.通过日期计算年龄
通过 (当前日期-出生日期) 两种方法:
1). year(getdate()) - year(birthday)
2). datediff(YY, birthday, getdate())
代码如下:
输出如下所示,后面也可以计算不同年龄段的人数:
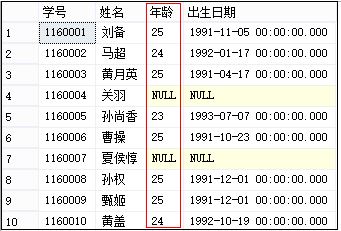
1). year(getdate()) - year(birthday)
2). datediff(YY, birthday, getdate())
代码如下:
输出如下所示,后面也可以计算不同年龄段的人数:
注意:Oracle会报错“ORA-00904: 'DATEDIFF' invalid identifier”, 它的方法如下:
Trunc(MONTHS_BETWEEN(SYSDATE, BIRTH_DATE)/12)
函数Trunc在这里对带有小数位数的数字取整数部分,SYSDATE为oracle的获取当前日期的函数,BIRTH_DATE为我自己的数据库表中存储生日日期的字段。
判断年份等于当前年份方法:YEAR=to_char(sysdate, 'yyyy')
如果BIRTH_DATE是字符串类型,则计算年龄语句如下:
Trunc(MONTHS_BETWEEN(SYSDATE, to_date(BIRTH_DATE,'yyyy-mm-dd'))/12)
2.获取某列所有不同的属性值 group by
它的功能包括:获取学院列所有学院信息,也可以用来统计所有学生同名的人数。
输出结果:

统计不同学院的人数信息:
统计不同学院的人数信息:
select xy as 学院, count(*) as 总人数 from xs group by xy;

Trunc(MONTHS_BETWEEN(SYSDATE, BIRTH_DATE)/12)
函数Trunc在这里对带有小数位数的数字取整数部分,SYSDATE为oracle的获取当前日期的函数,BIRTH_DATE为我自己的数据库表中存储生日日期的字段。
判断年份等于当前年份方法:YEAR=to_char(sysdate, 'yyyy')
如果BIRTH_DATE是字符串类型,则计算年龄语句如下:
Trunc(MONTHS_BETWEEN(SYSDATE, to_date(BIRTH_DATE,'yyyy-mm-dd'))/12)
2.获取某列所有不同的属性值 group by
它的功能包括:获取学院列所有学院信息,也可以用来统计所有学生同名的人数。
输出结果:
select xy as 学院, count(*) as 总人数 from xs group by xy;
PS:如果需要排序可以添加order by xy,而统计重名学生可通过having count(*)>1。
推荐:http://www.cnblogs.com/rainman/archive/2013/05/03/3058451.html
3.查询字符串匹配like和多值属性判断in
推荐:http://www.cnblogs.com/rainman/archive/2013/05/03/3058451.html
3.查询字符串匹配like和多值属性判断in
LIKE 操作符用于在 WHERE 子句中搜索列中的指定模式:SQL LIKE 操作符 - w3school
输出结果:
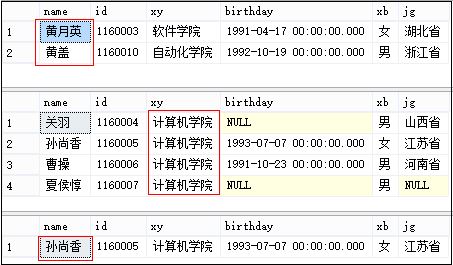
LIKE匹配某个字段的变量的方法:DL_BHXNZYMC like '%' || ZY_NAME ||'%'
输出如下所示,也可以某个字段包含的个数:
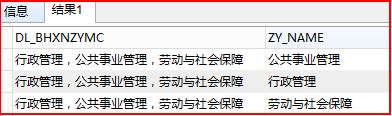
IN 操作符允许我们在 WHERE 子句中规定多个值,换种说法就是替换or:
IN 操作符允许我们在 WHERE 子句中规定多个值,换种说法就是替换or:
输出结果:
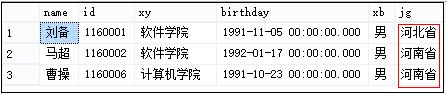
4.查询输出某列属性中的某个特定值
4.查询输出某列属性中的某个特定值
比如我希望输出软件学院这个值,可以使用group by分组再定义这个值。其缺点是这个值必需是定义存在的,当然如果C#或JAVA可以定义变量连接这个值。
输出结果:
 5.子查询统计不同阶段学生总数
5.子查询统计不同阶段学生总数
使用子查询统计不同学院总人数、不同性别总人数和河北/河南学生总人数。
输出结果:

PS:当时需要设计一条SQL,统计各个学院的教师总数、高级职称教师总数、35岁以下青年教师总数、教授教师总数;而且输出是一行,每个学院共5个值,例如:
 上面这种显示方法非常局限,不能实现动态的查询,如果增加新的学院,你SQL语句中 where xy='软件学院' 需要相应修改,如果是连接前端建议使用逗号连接查询。当然,SQL语句更理想的输出如下:(参考6)
上面这种显示方法非常局限,不能实现动态的查询,如果增加新的学院,你SQL语句中 where xy='软件学院' 需要相应修改,如果是连接前端建议使用逗号连接查询。当然,SQL语句更理想的输出如下:(参考6)
.gif "点击并拖拽以移动")
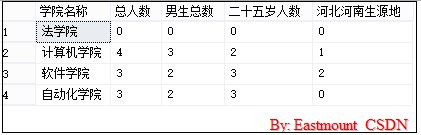
6.使用子查询按行动态输出学院相关信息
获取每个学院总人数、男生总人数、小于等于25岁的总人数和生源地河北河南人数。
这种方法通常是多个表之间的夸表查询,首先创建一个学院表:学院名称和学院代码。
输出如下,这里插入一个法学院,它的统计结果都为空:

然后,子查询SQL语句如下:
输出结果:
输出结果:
LIKE匹配某个字段的变量的方法:DL_BHXNZYMC like '%' || ZY_NAME ||'%'
输出如下所示,也可以某个字段包含的个数:
输出结果:
比如我希望输出软件学院这个值,可以使用group by分组再定义这个值。其缺点是这个值必需是定义存在的,当然如果C#或JAVA可以定义变量连接这个值。
输出结果:
使用子查询统计不同学院总人数、不同性别总人数和河北/河南学生总人数。
输出结果:
PS:当时需要设计一条SQL,统计各个学院的教师总数、高级职称教师总数、35岁以下青年教师总数、教授教师总数;而且输出是一行,每个学院共5个值,例如:
6.使用子查询按行动态输出学院相关信息
获取每个学院总人数、男生总人数、小于等于25岁的总人数和生源地河北河南人数。
这种方法通常是多个表之间的夸表查询,首先创建一个学院表:学院名称和学院代码。
输出如下,这里插入一个法学院,它的统计结果都为空:
然后,子查询SQL语句如下:
输出结果:
7.Oracle数据库null设置成自定义值的方法
方法包括主要有两个,参考:http://www.soso.io/article/72986.html
1). nvl(expr1, expr2)
若EXPR1是NULL,則返回EXPR2,否則返回EXPR1。nvl(person_name,“未知”)表示若person_name字段值为空时返回“未知”,如不为空则返回person_name的字段值。通过这个函数可以定制null的排序位置。 |
2). decode(DEPARTMENT_NAME, null, 'NULL', DEPARTMENT_NAME)
如果部门名称在表中值为null,则用NULL替代,也可设置为"空"各种自定义字符串。decode函数比nvl函数更强大,同样它也可以将输入参数为空时转换为一特定值。
如decode(person_name,null,“未知”, person_name)表示当person_name为空时返回“未知”,如不为空则返回person_name的字段值。
PS:而SQL Server中没有函数decode,但是其实质可以通过case when来实现和替代。
参考:http://blog.csdn.net/hu_shengyang/article/details/10533865
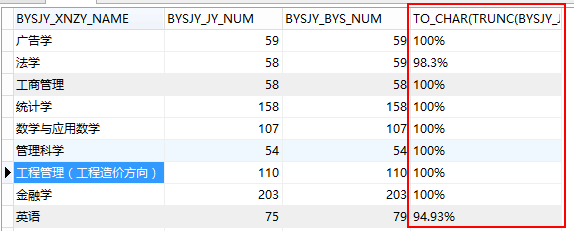
8.Oracle计算百分比trunc方法
核心SQL语句如下:to_char(trunc(NUM/ALL_NUM*100, 2)) || '%
其中NUM除以ALL_NUM总数,并且保留两位有效数字,如下图所示:
9.Oracle查询除法/运算
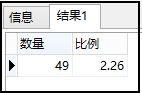
主要语句:select a/b from c;
如:1.0*男生人数/ 人总数*100,使用trunc主要是小数点保留两位有效数字。
如果出现错误:[Err]ORA-01476: divisor is equal to zero,可修改为:select decode(b,0,0,a/b) from c。
输出如下所示:
10.Oracle统计某个属性逗号分隔值的个数
如下图所示,学科大类中包括各个学科专业名称,通过逗号分隔,如何统计个数呢?
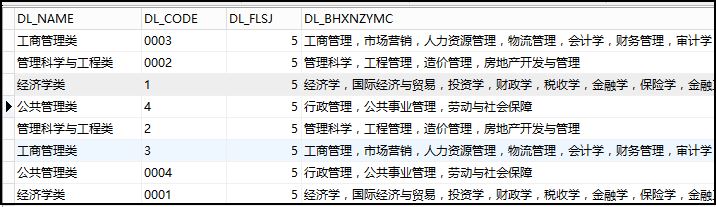
SQL代码如下,Orcale使用length,其他是len函数:
运行结果如下所示:
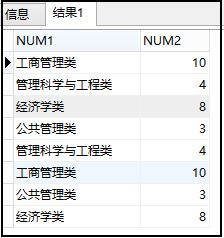
11.Oracle使用CASE WHEN替代子查询
前面第5步中使用子查询进行统计:
输出结果:
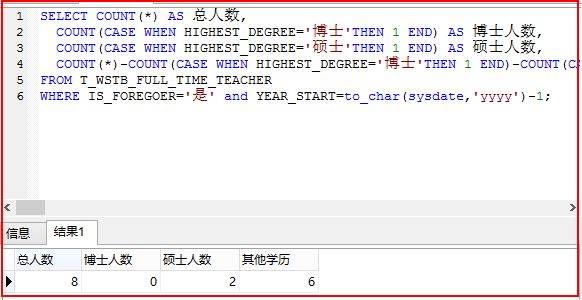
在Oracle中如果想减少代码量或者不适用子查询,可以CASE WHEN语句进行替代。
这段SQL语句表示求教师表IS_FOREGOER学科带头人且入校年份为2015年的总人数、博士人数、硕士人数和其他学历的人数。
COUNT(CASE WHEN HIGHEST_DEGREE='博士' THEN 1 END) AS NUM2
表示当最高学历HIGHEST_DEGREE字段为'博士'时,统计数量加1。
当然如果需要计算学院各个班级的总人口,可以采用使用下面的SQL:
COUNT(CASE WHEN DW_NAME='软件学院' THEN NUM_STU END) AS NUM2
也可以使用提到的CASE防止除法计算分母为0,ZS总数、SHSJ社会实践人数。即:
round((case when ZS!=0 then SHSJ/ZS else 0 end),3) as bl
输出如下图所示:
12.Oracle子查询中使用a.* 统计所有字段
前面5的子查询需要设置不同的字段,而这里是使用a.*统计所有字段,其中a表示子查询重命名的结果,给人以很清新的感觉,虽然有点华而不实吧!
PS: 这部分代码是我的学生XW写的表2-6,非常不错,感觉自愧不如,学习之~
其中表对应各学院的信息,但希望你能学习这种SQL语句的格式。
输出如下图所示:

13.Oracle使用decode函数防止除法分母为0
Oracle中通常需要统计如男生占全班总人数比例等用法,此时如果分母为0,它会报错"[Err] ORA-01476: divisor is equal to zero"。那怎么办呢?
解决方法:使用函数decode,当分母为0时直接返回0,否则进行除法运算。
selecta/b from c; 修改成如下即可:select decode(b, 0, 0, a/b) from c;
例如:decode(XF_ALL, 0, 0,trunc(XF_JZXSYJXHJ / XF_ALL * 100, 1)) as BL
下面这段代码是涉及到子查询的除法运算所占百分比:
当然也可以使用前面11提到的CASE防止分母为0,即:
round((case when ZS!=0 then SHSJ/ZS else 0 end),3) as bl
最后希望文章对你有所帮助,这是一篇我的在线笔记,同时后面结合自己实际项目和SQL性能优化,将分享一些更为专业的文章~
10.Oracle统计某个属性逗号分隔值的个数
如下图所示,学科大类中包括各个学科专业名称,通过逗号分隔,如何统计个数呢?
SQL代码如下,Orcale使用length,其他是len函数:
运行结果如下所示:
11.Oracle使用CASE WHEN替代子查询
前面第5步中使用子查询进行统计:
输出结果:
这段SQL语句表示求教师表IS_FOREGOER学科带头人且入校年份为2015年的总人数、博士人数、硕士人数和其他学历的人数。
COUNT(CASE WHEN HIGHEST_DEGREE='博士' THEN 1 END) AS NUM2
表示当最高学历HIGHEST_DEGREE字段为'博士'时,统计数量加1。
当然如果需要计算学院各个班级的总人口,可以采用使用下面的SQL:
COUNT(CASE WHEN DW_NAME='软件学院' THEN NUM_STU END) AS NUM2
也可以使用提到的CASE防止除法计算分母为0,ZS总数、SHSJ社会实践人数。即:
round((case when ZS!=0 then SHSJ/ZS else 0 end),3) as bl
输出如下图所示:
12.Oracle子查询中使用a.* 统计所有字段
前面5的子查询需要设置不同的字段,而这里是使用a.*统计所有字段,其中a表示子查询重命名的结果,给人以很清新的感觉,虽然有点华而不实吧!
PS: 这部分代码是我的学生XW写的表2-6,非常不错,感觉自愧不如,学习之~
其中表对应各学院的信息,但希望你能学习这种SQL语句的格式。
输出如下图所示:
13.Oracle使用decode函数防止除法分母为0
Oracle中通常需要统计如男生占全班总人数比例等用法,此时如果分母为0,它会报错"[Err] ORA-01476: divisor is equal to zero"。那怎么办呢?
解决方法:使用函数decode,当分母为0时直接返回0,否则进行除法运算。
selecta/b from c; 修改成如下即可:select decode(b, 0, 0, a/b) from c;
例如:decode(XF_ALL, 0, 0,trunc(XF_JZXSYJXHJ / XF_ALL * 100, 1)) as BL
下面这段代码是涉及到子查询的除法运算所占百分比:
当然也可以使用前面11提到的CASE防止分母为0,即:
round((case when ZS!=0 then SHSJ/ZS else 0 end),3) as bl
三. 总结
最后希望文章对你有所帮助,这是一篇我的在线笔记,同时后面结合自己实际项目和SQL性能优化,将分享一些更为专业的文章~
希望能与大家一起在华为云社区共同承载,原文地址:https://blog.csdn.net/Eastmount/article/details/50528621
【绽放吧!数据库】有奖征文火热进行中:https://bbs.huaweicloud.com/blogs/285617
(By:娜璋之家 Eastmount 2021-07-25 夜于武汉)