想开始您的数据科学家职业生涯,但不知道从哪里开始?你是在正确的地方!嘿伙计们,欢迎来到这个很棒的数据科学教程博客,它将让您开始进入数据科学世界。要获得有关数据科学的深入知识,让我们看看今天要学习的内容:
-
- 为什么是数据科学?
- 什么是数据科学?
- 谁是数据科学家?
- 工作趋势
- 如何解决数据科学中的问题?
- 数据科学组件
- 数据科学家的工作角色
为什么是数据科学?
有人说数据科学家是“21 世纪最性感的工作”。为什么?因为在过去的几年里,公司一直在存储他们的数据。每个公司都这样做,突然导致了数据爆炸。数据已经成为当今最丰富的东西。
但是,您将如何处理这些数据?让我们通过一个例子来理解这一点:
假设您有一家制造手机的公司。你发布了你的第一个产品,它大受欢迎。每项技术都有生命,对吧?所以,现在是时候想出一些新的东西了。但是你不知道应该创新什么,以满足用户的期望,他们急切地等待你的下一个版本?
贵公司有人提出了一个想法,即使用用户生成的反馈并选择我们认为用户在下一个版本中期望的东西。
在数据科学中,您可以应用各种数据挖掘技术,如情感分析等,并获得所需的结果。
不仅如此,您还可以做出更好的决策,通过提出有效的方法来降低生产成本,并为您的客户提供他们真正想要的东西!
有了这个,数据科学可以带来无数的好处,因此您的公司绝对有必要拥有一个数据科学团队。 像这样的要求导致今天“数据科学”成为一门学科,因此我们正在为您撰写有关数据科学教程的博客。:)
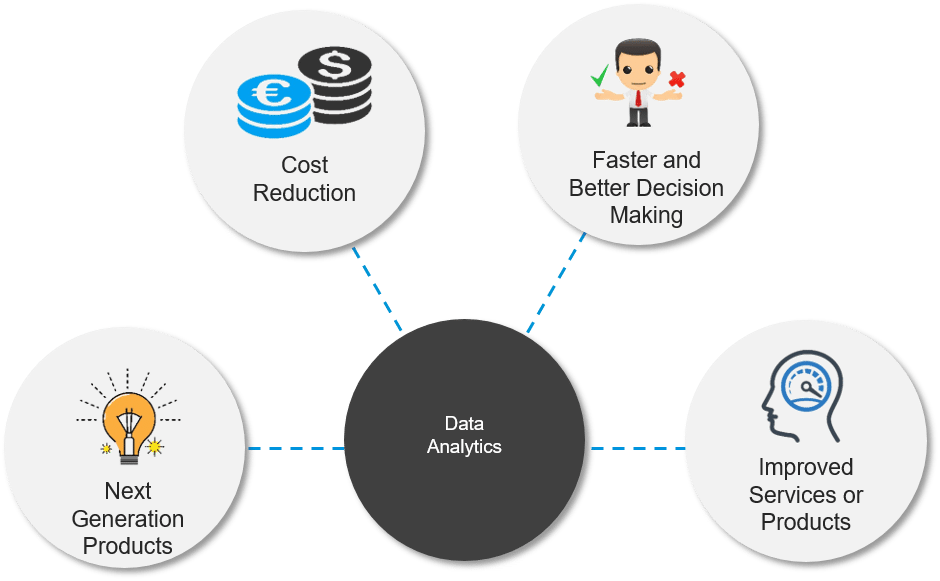
数据科学教程:什么是数据科学?
数据科学一词最近随着数理统计和数据分析的发展而出现。这段旅程令人惊叹,我们今天在数据科学领域取得了如此多的成就。
在接下来的几年里,我们将能够像麻省理工学院的研究人员所声称的那样预测未来。凭借他们出色的研究,他们已经在预测未来方面达到了一个里程碑。他们现在可以用他们的机器预测电影的下一个场景会发生什么!如何?好吧,到目前为止,您的理解可能有点复杂,但不要担心,在本博客结束时,您也会得到答案。
回过头来,我们谈论的是数据科学,它也被称为数据驱动科学,它利用科学方法、流程和系统从各种形式的数据中提取知识或见解,即结构化或非结构化。
这些方法和过程是什么,是我们今天要在本数据科学教程中讨论的内容。
展望未来,谁进行了所有这些头脑风暴,或者谁在实践数据科学?一个数据科学家。
谁是数据科学家?
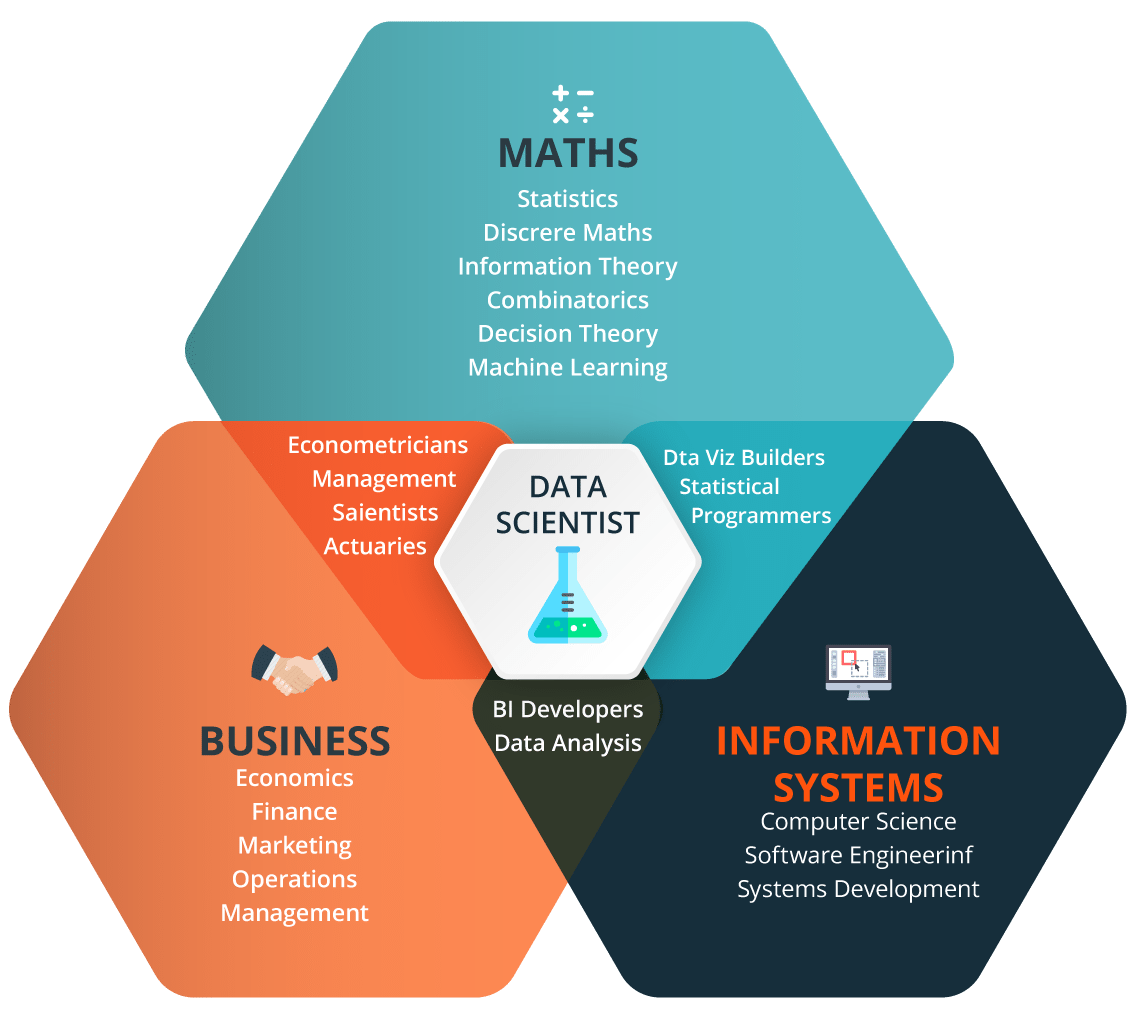
正如您在图像中看到的,数据科学家是所有行业的大师!他应该精通数学,他应该在商业领域取得领先,并且还应该具有出色的计算机科学技能。害怕的?别这样 虽然你需要在所有这些领域都做得很好,但即使你不是,你并不孤单!没有“完整的数据科学家”这样的东西。如果我们谈论在企业环境中工作,工作是在团队之间分配的,其中每个团队都有自己的专长。但问题是,你应该至少精通这些领域之一。此外,即使这些技能对您来说是新的,也请冷静!这可能需要时间,但这些技能是可以培养的,相信我,你花时间投资是值得的。为什么?好吧,让我们看看就业趋势。

数据科学家工作趋势
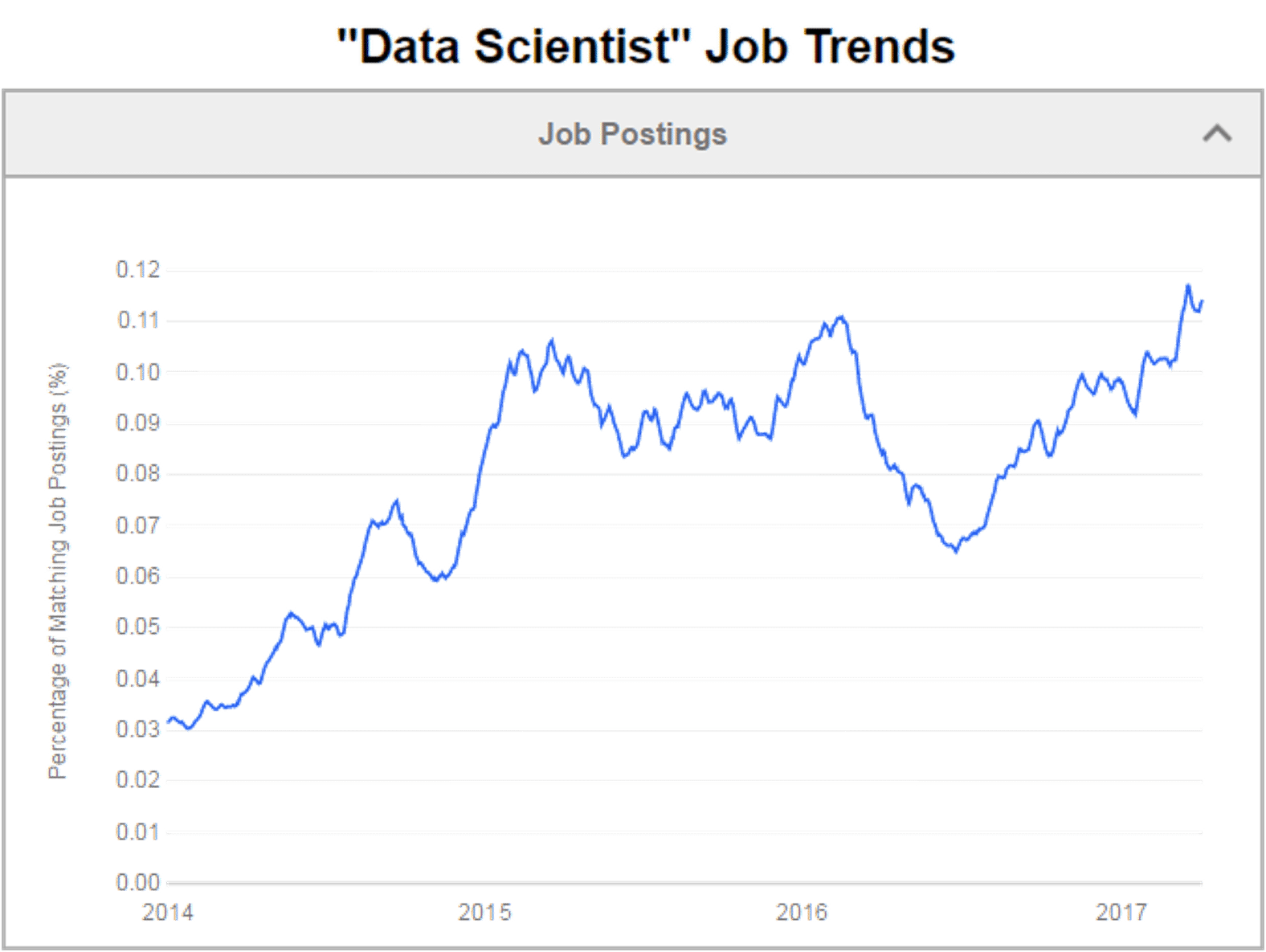
好吧,图表说明了一切,不仅数据科学家有很多职位空缺,而且这些工作的薪水也很高!不,我们的博客不会涵盖工资数字!
好吧,我们现在知道,学习数据科学实际上是有意义的,不仅因为它非常有用,而且你在不久的将来会有一个很好的职业生涯。
让我们现在开始学习数据科学的旅程,并开始,
如何解决数据科学中的问题?
所以现在,让我们讨论一个人应该如何处理一个问题并用数据科学来解决它。数据科学中的问题使用算法来解决。但是,最重要的判断是使用哪种算法以及何时使用它?
基本上,您在数据科学中会面临 5 种问题。
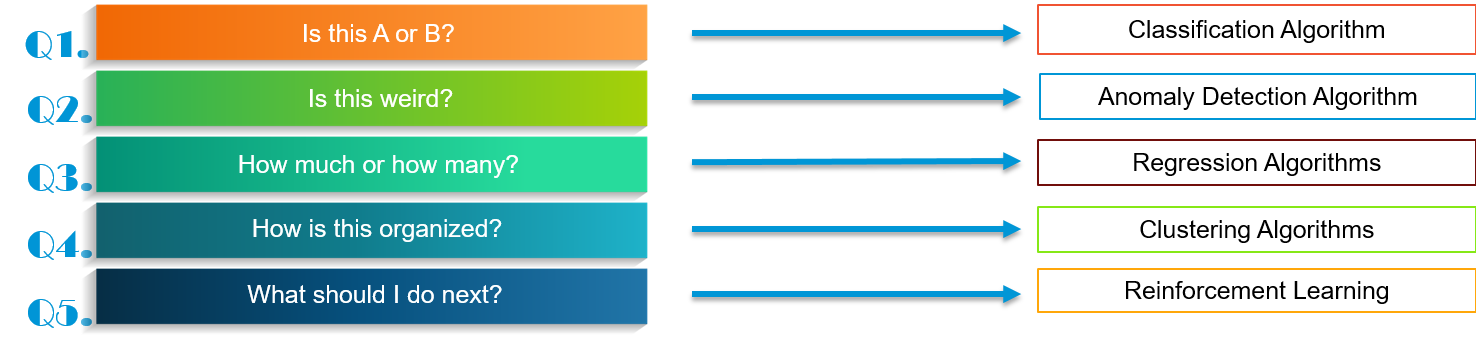
让我们一一解决这些问题和相关算法:
这是A还是B?
对于这个问题,我们指的是有明确答案的问题,如在有固定解决方案的问题中,答案可以是是或否、1 或 0、感兴趣、可能或不感兴趣。
例如:
问:你要喝什么,茶还是咖啡?
在这里,你不能说你想要可乐!由于该问题仅提供茶或咖啡,因此您只能回答其中之一。
当我们只有两种类型的答案,即是或否,1 或 0 时,称为 2 – 类别分类。有两个以上的选项,它被称为多类分类。
总之,无论何时遇到问题,答案都是分类的,在数据科学中,您将使用分类算法解决这些问题。
本数据科学教程中的下一个问题,您可能会遇到,可能是这样的,
这很奇怪吗?
此类问题涉及模式,可以使用异常检测算法解决。
例如:
尝试将问题联系起来“这很奇怪吗?” 到这张图,

上面的模式有什么奇怪的?那个红人,不是吗?
每当模式出现中断时,算法都会标记该特定事件以供我们查看。信用卡公司已经实现了该算法的实际应用,其中,用户的任何异常交易都会被标记以供审查。因此,实施安全并减少人员对监视的努力。
让我们看看本数据科学教程中的下一个问题,不要害怕,处理数学!
多少或多少?
不喜欢数学的小伙伴们可以放心啦!回归算法来了!
因此,每当有可能需要数字或数值的问题时,我们都会使用回归算法来解决它。
例如:

明天的温度是多少?
由于我们期望在对这个问题的响应中有一个数值,我们将使用回归算法来解决它。
在本数据科学教程中继续前进,让我们讨论下一个算法,
这是如何组织的?
假设你有一些数据,现在你不知道如何理解这些数据。因此,问题是,这是如何组织的?
好吧,您可以使用聚类算法来解决它。他们是如何解决这些问题的?让我们来看看:
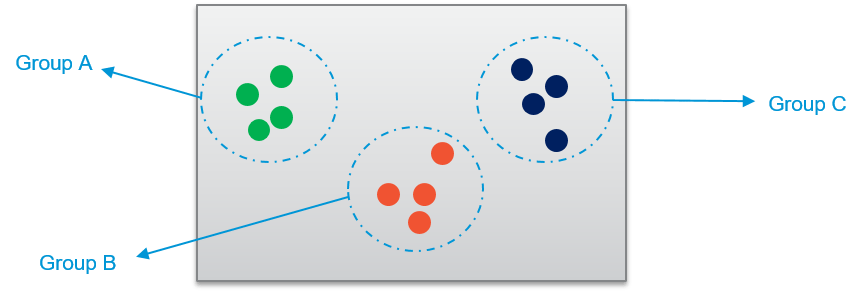
聚类算法根据共同的特征对数据进行分组。例如在上图中,点是根据颜色组织的。同样,无论是任何数据,聚类算法都试图理解它们之间的共同点,从而将它们“聚类”在一起。
在本数据科学教程中,您可能会遇到的下一个也是最后一个问题是,
我接下来该怎么做?
每当您遇到问题时,您的计算机必须根据您提供的培训做出决定,这涉及到强化算法。
例如:

您的温度控制系统,当它必须决定是降低房间温度还是升高温度时。
这些算法是如何工作的?
这些算法基于人类心理学。我们喜欢被欣赏对吗?计算机实现这些算法,并期望在接受培训时得到赞赏。如何?让我们来看看。
你不是教计算机做什么,而是让它决定做什么,在行动结束时,你给出正面或负面的反馈。因此,与其定义系统中什么是对什么是错,不如让系统“决定”做什么,最后给出反馈。
这就像训练你的狗一样。你无法控制你的狗做什么,对吧?但是当他做错了你可以责骂他。同样,当他做预期的事情时,也许会拍拍他的背。
让我们在上面的例子中应用这个理解,假设你正在训练温度控制系统,所以无论何时。房间里的人数增加,系统必须采取行动。要么降低温度,要么升高温度。由于我们的系统不了解任何内容,因此需要随机决定,让我们假设,它会增加温度。因此,您给出了负面反馈。有了这个,计算机就会知道,只要房间里的人数增加,就不会增加温度。
类似的其他动作,你应该给出反馈。随着您的系统正在学习每个反馈,因此在下一个决策中变得更加准确,这种类型的学习称为强化学习。
现在,我们在本数据科学教程中学到的算法涉及一个常见的“学习实践”。我们让机器学习对吗?
什么是机器学习?

它是一种人工智能,使计算机能够自行学习,即无需明确编程。通过机器学习,机器可以在遇到新情况时更新自己的代码。
在本数据科学教程中,我们现在知道数据科学得到机器学习及其分析算法的支持。我们如何进行分析,我们在哪里进行分析。数据科学还有一些组件可以帮助我们解决所有这些问题。
在此之前,让我回答一下 MIT 如何预测未来,因为我认为你们现在可能能够将它联系起来。因此,麻省理工学院的研究人员用电影训练他们的模型,计算机学习人类如何反应,或者在采取行动之前他们如何行动。
例如,当你要和某人握手时,你会把手从口袋里拿出来,或者靠在这个人身上。基本上,我们所做的每一件事都有一个“预行动”。计算机在电影的帮助下接受了这些“预动作”的训练。通过观看越来越多的电影,他们的计算机能够预测角色的下一步行动。
容易不是吗?在本数据科学教程中,让我再向您提出一个问题!他们必须在此实施哪种机器学习算法?
数据科学组件
1. 数据集
你会分析什么?数据,对吗?您需要大量可以分析的数据,这些数据会被提供给您的算法或分析工具。您可以从过去进行的各种研究中获得这些数据。
2.R工作室![]()
R 是一种开源编程语言和软件环境,用于统计计算和图形,由 R 基金会支持。R 语言用于名为 R Studio 的 IDE。
为什么使用它?
- 编程和统计语言
- 除了用作统计语言之外,它还可以用作用于分析目的的编程语言。
- 数据分析和可视化
- 除了是最主要的分析工具之一,R 还是用于数据可视化的最受欢迎的工具之一。

- 简单易学
- R 是一个简单易学、易读易写的


- 免费和开源
- R 是 FLOSS(自由/自由和开源软件)的一个例子,这意味着人们可以自由分发该软件的副本、阅读它的源代码、修改它等。
R Studio 足以进行分析,直到我们的数据集变得庞大,同时也是非结构化的。这种类型的数据被称为大数据。
3. 大数据

大数据是指数据集的集合如此庞大和复杂,以至于难以使用现有的数据库管理工具或传统的数据处理应用程序进行处理。
现在要驯服这些数据,我们必须想出一个工具,因为没有传统软件可以处理这种数据,因此我们想出了 Hadoop。
4. Hadoop

Hadoop 是一个框架,它帮助我们以并行和分布式的方式存储和处理大型数据集。
让我们关注 Hadoop 的存储和处理部分。
Store
Hadoop 中的存储部分由 HDFS 处理,即 Hadoop 分布式文件系统。它在分布式生态系统中提供高可用性。它的工作方式是这样的,它将传入的信息分成块,并将它们分发到集群中的不同节点,从而实现分布式存储。
过程
MapReduce 是 Hadoop 处理的核心。算法执行两个重要任务,映射和归约。映射器将任务分解为并行处理的较小任务。一旦所有的映射器完成他们的工作,他们聚合他们的结果,然后这些结果被 Reduce 过程减少到一个更简单的值。要了解有关 Hadoop 的更多信息,您可以浏览我们的Hadoop 教程博客系列。
如果我们在数据科学中使用 Hadoop 作为我们的存储,那么使用 R Studio 处理输入就会变得困难,因为它无法在分布式环境中表现良好,因此我们使用了 Spark R。
5.Spark R
它是一个 R 包,提供了将 Apache Spark 与 R 一起使用的轻量级方式。为什么要在传统 R 应用程序上使用它?因为,它提供了一个分布式数据框实现,支持选择、过滤、聚合等操作,但在大型数据集上。
现在喘口气!我们已经完成了本数据科学教程中的技术部分,现在让我们从您的工作角度来看它。我想你现在已经在谷歌上搜索了数据科学家的薪水,但是,让我们讨论一下你作为数据科学家可以担任的工作角色。
数据科学家的工作角色
一些著名的数据科学家职位是:
- 数据科学家
- 数据工程师
- 数据架构师
- 数据管理员
- 数据分析师
- 业务分析师
- 数据/分析经理
- 商业智能经理
下面这个数据科学教程中的 Payscale.com 图表显示了美国和印度按技能划分的数据科学家平均工资。
提升数据科学和大数据分析技能以利用您的数据科学职业机会的时机已经成熟。这使我们到了数据科学教程博客的结尾。我希望这个博客能给你提供信息并增加价值。现在是进入数据科学世界并成为一名成功的数据科学家的时候了。