前言
机器学习中可以将数据集分为两个子集,即训练集、测试集。更好的方式是将数据集分为三个子集,即训练集、验证集、测试集。
一、划分为训练集、测试集
数据集划分为两个子集的概念:
训练集—用于训练模型;
测试集—用于测试训练后模型
比如,将数据集划分为一个训练集、一个测试集:

使用此方案时,需要确保测试集满足以下两个条件:
- 规模足够大,可产生具有统计意义的结果。
- 能代表整个数据集。即,挑选的测试集的特征应该与训练集的特征相同。
当测试集满足上述两个条件,通常能得到一个能够较好泛化到新数据的模型。
使用训练集、测试集训练模型的过程
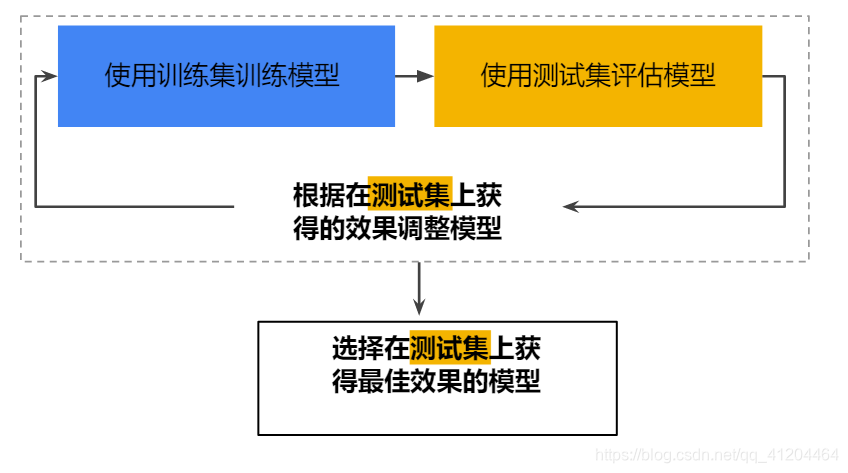
“调整模型”是指调整模型相关的参数、超参数、模型结构,比如:学习率、添加或移除特征,或从小设计全新模型等等。
二、划分为训练集、验证集、测试集
将数据集划分为三个子集,如下图所示,可以大幅降低过拟合的发送几率:

使用训练集、验证集、测试集训练模型的过程
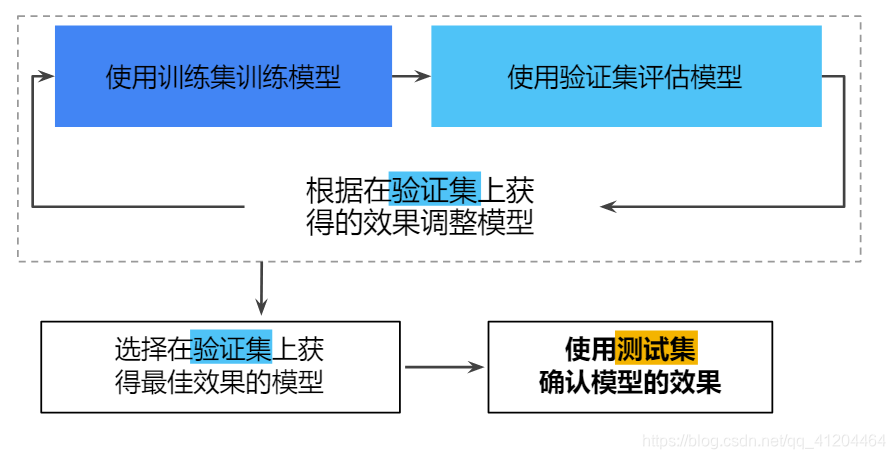
首先选择早验证集上获得最佳效果的模型。然后使用测试集再次检查该模型。
这个方法训练出来的模型通过会更好,是因为暴露给测试集的信息更少。
划分为训练集、验证集、测试集方法中,通过测试集调整模型效果,从中不断学习测试集的规律;从而使得测试集和新数据有区别,模型对测试集有些认识了,对新数据还是完全不认识的情况下预测的
注意
不断适应测试集和验证集会使其逐渐失去效果。适应相同数据来决定超参数设置或其它模型改进的次数越多,对于这些结果能够真正泛化到未见过的新数据的效果就越低。
建议:收集更多数据来“刷新”测试集和验证集。重新开始是一种很好的重置方式。
关键词
训练集(training set),数据集的子集,用于训练模型。与验证集和测试集相对。
验证集(validation set),数据集的一个子集,从训练集分离而来,用于调整超参数。与训练集和测试集相对。
测试集(test set),数据集的子集,用于在模型经过验证集的初步验证后,进行测试模型。与训练集和验证集相对。
过拟合(overfitting),创建的模型与训练数据过于匹配,以至于模型无法根据新数据做出正确的预测。
参考:https://developers.google.cn/machine-learning/crash-course/training-and-test-sets/splitting-data
参考:https://developers.google.cn/machine-learning/crash-course/validation/another-partition