作者:李响
引 言
图1展示了知识的金字塔结构,其中,智慧(Intelligence)是知识应用的顶峰,是人类特有的一种问题求解能力,它可以回答人类为什么以及如何使用信息这类问题。语用网就是站在智慧这一层上解决动态知识表达和网络信息使用等问题,主要体现在系统对现实世界中用户上下文动态变化的反应能力。语用网利用具有经验学习能力的Agent在服务参与者之间进行通信与协商,达到理解用户真实意图的目的,并为用户推荐最适合的服务。
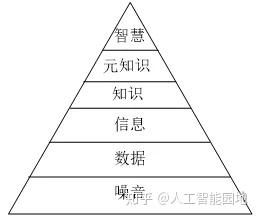
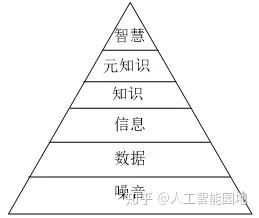
图1 知识的金字塔结构
在现实世界中,只有正确的信息在正确的时间以及正确的地点,并以正确的方式呈现给用户,才不会成为不受欢迎的噪音。原始的语法网主要控制信息提供者,很少对信息消费者进行控制;语义网的出现,使得网络上的信息具有更加清晰的含义,便于人和机器的理解,但它仍缺乏对信息消费者的控制;而新兴的语用网是对信息消费者加以控制,使得用户可以自定义怎样使用信息及将现有的信息转换成个人相关信息。图2展示了信息消费者与提供者对于信息表达能力的控制。


图2 信息提供者和消费者对信息表达能力的控制
从语法网(Web 1.0)发展到语用网(Web 4.0)的历程如图3所示。

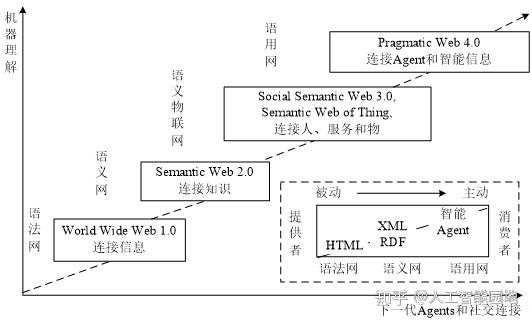
图3 网络发展的历程
由图3可知,终端用户可编程Agent协同语义知识、基于规则的决策及反应逻辑交互,导致了被动网络(Passive Web)向主动网络(Active Web)的转变。
AI语用网的定义视角
基于AI的语用网最具代表性的三个视角如下:
(1)软件工程视角:语用网是为了解决计算协作问题而发明的计算机系统模型,如图4所示,语用网系统是用软件的协作来仿真人类社会的实践过程,因此被称为“虚拟社会(Virtual Society)”,其技术基础是当前炙手可热的P2P网络技术。
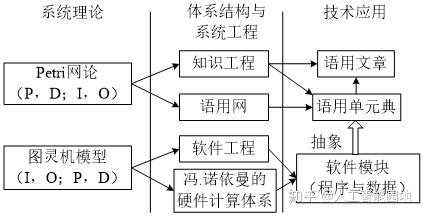
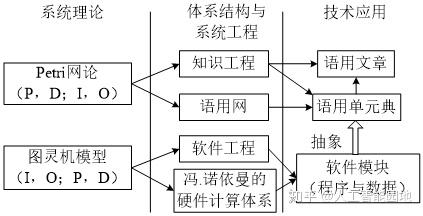
图4 软件工程视角的语用网体系结构
(2)语言学和符号学视角:语用网作为一种通信(Communication)和协同(Collaboration)的平台,关注上下文是如何影响对话中句子(Sentences)的含义解释,也就是说,语用网并不打算归入到语义网中,但它试图利用语义网中智能Agent、本体及基于这些表示进行基于规则的推理、自主决策和反应,将与上下文无关的程序演变成高度上下文感知的应用程序。
由此可见,规则(Rule)在语用网中扮演着极其重要的角色,它能将数据自动地转换成信息,将信息解释成语义知识,从现有知识中推导出新结论和决策,并根据变化的条件和发生的事件智能地做出反应(Reaction),图5展示了上述的转换过程。
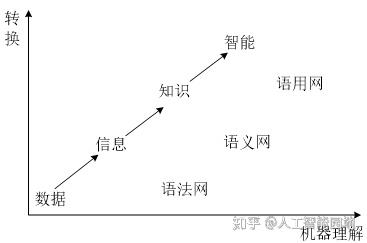
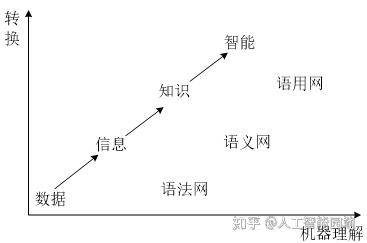
图5 机器智能的语义-语用知识转换
语用网是建立在语法网和语义网之上,可以通过适当的技术,如本体协商系统、基于本体的业务交互等,有效地增强人类协同能力。从这一观点来看,语用网是通过改善协同的质量和合理性、社区中面向目标的对话(Conversations)对语义网进行补充,它感兴趣的是用户需要因特网处理什么(What)以及怎么处理(How),即怎样从一个通信行为的上下文中获得含义,并对其进行处理,包括用户如何过滤信息、访问信息、处理信息和共享信息。
(3)信息系统视角:语用网是由描述人们为什么以及如何使用信息的工具、实践(Practices)和理论(Theories)组成。我们可从信息系统的角度提炼出如图6所示的符号阶梯图。


图6符号阶梯
从图6可以看出,实践基本上都属于可共享的规范领域,这些规范不仅适用于行为(规范和约束),还适用于解释、评价及通信。
AI语用网的特征与原则
语用网的出现及发展,促进了服务与用户之间理解和交互模式的改变,并对语义信息进行更深入地解释和推理以消除信息含义与静态语义之间的不一致性。
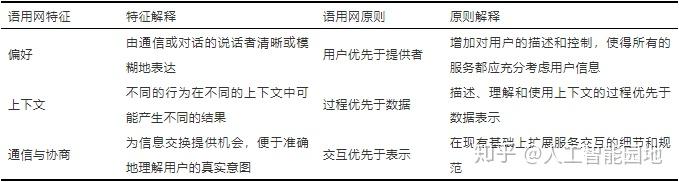
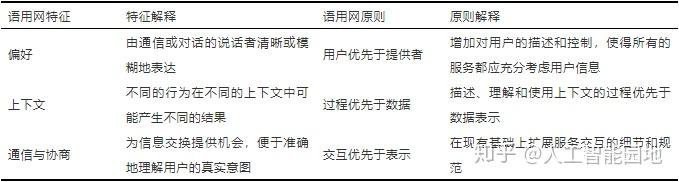
语用网具有表1所描述的特征与原则。
表1 语用网的特征与原则
AI语用网的基础设施
规则响应(Rule Responder)Agent是将语义网扩展成语用网的基础设施,可以协同基于规则的事件处理Agent网络实现分布式推理服务。它将分布式多Agent系统的人工智能理论融合到较大的规模实践中,并集成各种产生式规则、反应规则、事件/行为逻辑规则及(复杂)事件/动作消息。规则响应Agent为虚拟组织的规则交换构建了面向服务的方法、基于规则的中间件及它们的含义协商过程,其架构如图7所示。

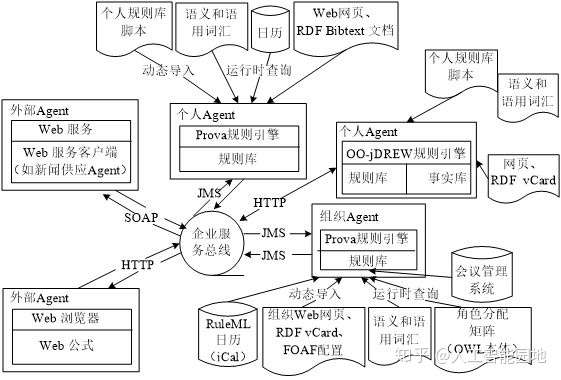
图7 规则响应Agent架构
规则响应Agent早期的应用实例包括健康医疗领域、生命科学基础设施、基于规则的IT服务层次管理等,其近期的应用实例主要有如下四种:
(1)研讨会规划系统:规则响应Agent支持RuleML-2018研讨会组织会议,并负责RuleML研讨会办公网站的问答(Q&A)部分;
(2)病人支持系统:它属于社交语义网原型,允许每个病人查询其他病人的配置以找到或初始化匹配的组,并允许病人使用Prolog或N3表达自己的配置;
(3)信誉管理系统:该系统使用本体来表达简单或复杂的多维信誉对象,通过各种规则实现信誉管理功能,并有效地保护用户的隐私安全;
(4)语义复杂事件处理Agent网络:由实现分布式Prova推理服务的语义事件处理Agent构成,它使用基于规则的语义复杂事件处理逻辑来检测复杂事件。
Prova语义规则引擎
基于AI的语用网的基础设施—规则响应Agent的核心是规则引擎,如Prova、OOjDREW、Euler或Drools等,它们用来实现Agent角色的决策逻辑和反应逻辑。Agent可以使用语义网本体(如基于RDFS或OWL)给它的规则一个特定领域的含义,作为规则响应Agent的规则引擎必须具有很强的认知架构,可以实现基于目标/任务或基于学习功能的智能认知,因此,规则响应Agent选择Prova作为其语义规则引擎。
Prova(Prolog+Java)既是一种规则语言,又是一种具有高度表达能力的分布式规则引擎,它支持声明式决策规则(后向推理)、基于反应规则的工作流、基于规则的复杂事件处理(Complex Event Processing-CEP)以及对外部数据源(如数据库、Web服务和Java APIs)的动态访问。Prova可以结合声明式规则(Declarative Rule)、本体(词汇)、面向动态对象的程序推理以及通过查询语言SQL或SPARQL等访问外部数据源。Prova最关键的优势是将逻辑、数据访问、语义网和事件处理技术的紧密集成相分离,图8展示了Prova语义规则引擎的框架。
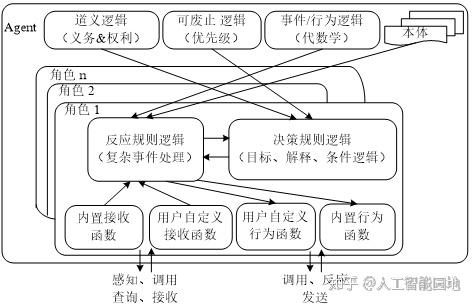
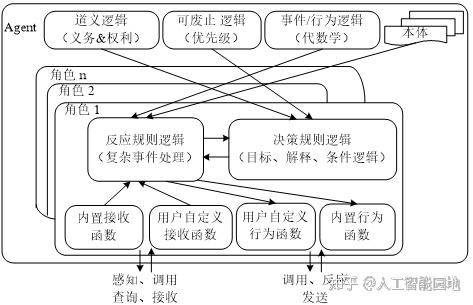
图8 Prova语义规则引擎框架
如图8所示,Prova主要支持如下四种规则:
(1)描述Agent决策逻辑的推导规则;
(2)描述约束和潜在冲突的完整性规则;
(3)定义全球ECA(Event-Condition-Action)类型的反应规则;
(4)定义基于复杂事件处理和行为逻辑的消息反应规则。
Agent间通信原理
Agent间通信遵循FIPA规范,FIPA(The Foundation for Intelligent Physical Agents)是由Agent领域的公司和学术机构组成的国际组织,并规定Agent间通信使用ACL(Agent Communication Language)语言,它在语法上类似于KQML语言,表2列举了ACL消息的主要参数。
表2 ACL消息中主要参数


AI语用网的应用实例——PWCAS系统
图9是AI语用网的PWCAS(Pragmatic web oriented context-aware system framework)系统架构图。
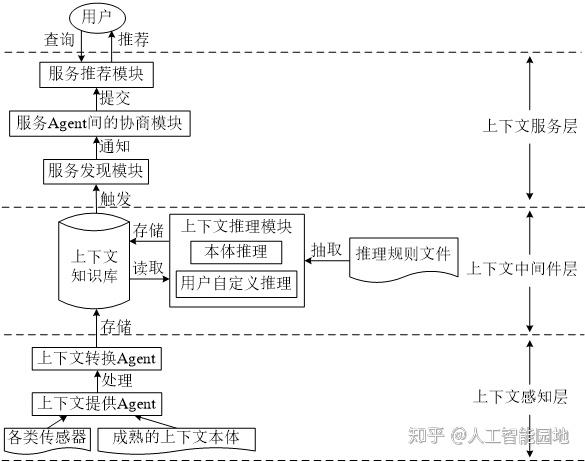
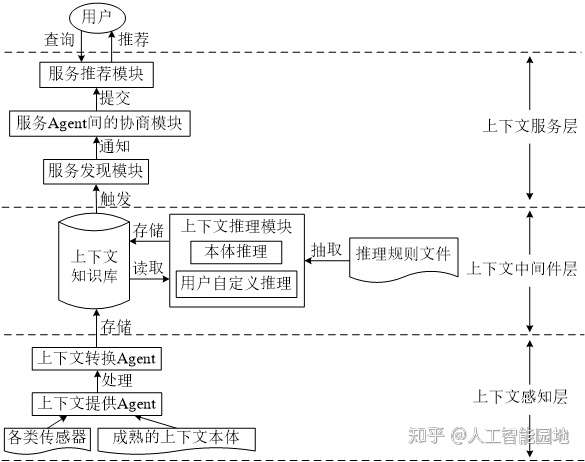
图9 面向语用网的上下文感知系统框架
在本文中,选取一个AI语用网具体的应用情境—智能会议室,对图9所示的PWCAS系统架构图的功能实现的整体流程加以实例说明,如图10所示。
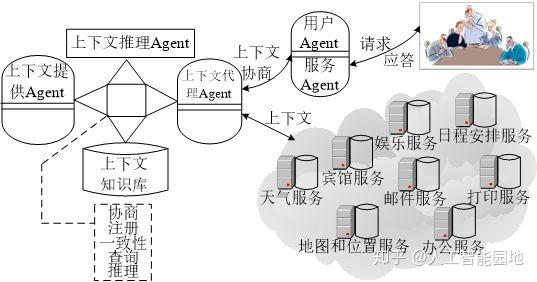
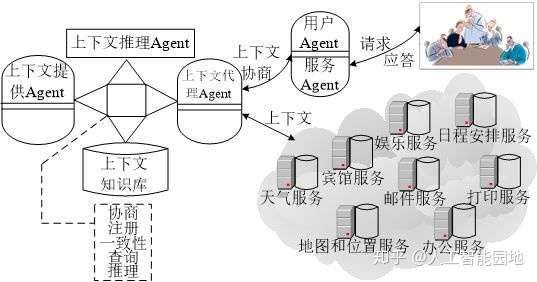
图10 基于上下文的智能会议室环境
如图10所示,有效的服务可以分为两类,一是预订的服务(Services in advance):如预订宾馆、日程安排和娱乐,此类服务来源于会议参加者在会议注册期间提供的配置;二是实时服务(Services on the fly):如地图和位置信息、天气和打印服务,此类服务来源于会议参加者的物理和逻辑上下文。
PWCAS系统的上下文知识库存储了与智能会议室领域相关的CoBra本体、用户配置及启发性知识。嵌入在物理环境中的上下文提供Agent从多种来源(如通过检测用户的RFID徽章、感知她携带的蓝牙设备的接近或利用声音/人脸识别技术)检测到用户的出席信息,将其提交给上下文知识库,在进行推理前先进行上下文不一致性检测和消解操作。
例如,当Mary携带智能设备进入智能会议室,部署在房间内的位置传感器感知到这一情境,于是向上下文知识库发送一条上下文信息:
<Person rdf:ID=”P3”>
<name>Mary </name>
<isNowIn>MeetingRoom </isNowIn>
</Person>Mary将智能设备落在房间内去了休息室,休息室的传感器感知到她戴在身上的RFID徽章,于是又向上下文知识库发送一条新的上下文信息:
<Person rdf:ID=”P3”>
<name>Mary </name>
<isNowIn>Restroom</isNowIn>
</Person>根据上下文知识库中的启发性知识“同一个人不能在同一时间出现在两个不同的地点”,发现上下文知识库存在不一致性,结合“用户穿戴的智能卡优先级高于携带的移动设备”这一策略,自动删除前一条优先级低的上下文信息,从而保障了上下文知识库的一致性。
本体推理模块根据上下文知识库中用户配置并结合OWL本体推理规则推导出用户当前所处的情境。其中,用户配置为确定用户与已知设备的关系提供了有用的信息,可以通过检测移动设备的位置来推导其主人的位置。
本体推理流程如图11所示。
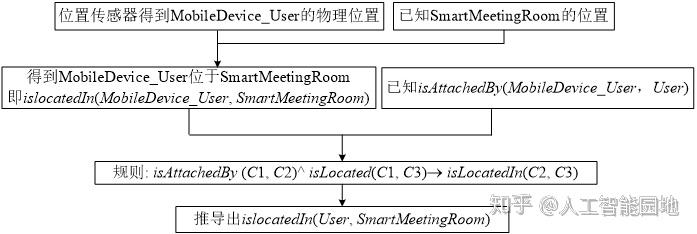
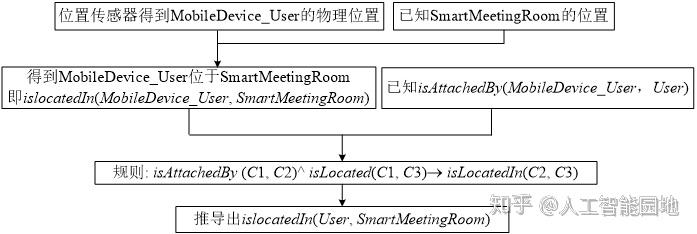
图11 本体推理过程
确定了用户当前位于智能会议室后,根据用户配置推导出用户角色及用户意图之类的具有决策能力的高层上下文,并将其作为上下文服务层的数据源。该配置还定义了agt:intends属性,描述他计划参加的会议,当Agent可以使用这个信息时,会议的RDF资源描述URI可以帮助推断参加会议的用户是演讲者还是观众。
表3明确列出了智能会议室领域涉及的若干Jena自定义规则。
表3 会议涉及的Jena自定义规则


用户自定义推理模块将meeting.rule导入Jena推理机中进行推理,推导出用户角色和意图后,提交给上下文服务层的服务发现模块。
上下文服务层中相应的服务Agent接收到通知后,认为接收到的通知就是用户的真实意愿,便与上下文代理Agent协商是否可以访问用户信息,若得到用户的授权,则主动为用户发送会议安排提醒。
另外,投影仪Agent接收到用户的意图,认为用户的意愿是打开PPT做演讲,于是查询用户Agent找到可以下载用户演示文稿的URL,自动为用户打开PPT,若上下文知识库中不存在这样的URL信息,则上下文提供Agent会执行适当的上下文获取行为,并尝试从外部来源获取所需的上下文。
总结
随着人工智能的发展,用户对服务的智能化和实时性的要求越来越高,并且由于开放动态的环境使得现实世界中动态知识的表达和使用越来越重要,本文从网络发展历程、AI语用网的定义、特征与原则、基础设施、语义规则引擎、Agent间通信原理以及AI语用网的应用实例进行阐述,意于解决在动态变化的环境下确定用户当前所处情境,在此基础上推导出用户的真实意图,并据此为用户提供最适合的服务。
文章来源: zhuanlan.zhihu.com,作者:,版权归原作者所有,如需转载,请联系作者。
原文链接:zhuanlan.zhihu.com/p/103594630