前言
由于太久没水博客了,。

什么是NLP?
首先引入一个简单的列子,判断一个词的词性,是动词还是名词。用机器学习的思路,我们有一系列样本(x,y),这里 x 是词语,y 是它们的词性,我们要构建 f(x)->y 的映射这样理解.在 NLP 中,把 x 看做一个句子里的一个词语,y 是这个词语的上下文词语,那么这里的 f,便是 NLP 中经常出现的『语言模型』(language model),这个模型的目的,就是判断 (x,y) 这个样本,是否符合自然语言的法则,更通俗点说就是:词语x和词语y放在一起,是不是人话。
什么是word2vec?
2013年,Google开源了一款用于词向量计算的工具——word2vec,引起了工业界和学术界的关注。首先,word2vec可以在百万数量级的词典和上亿的数据集上进行高效地训练;其次,该工具得到的训练结果——词向量(word embedding),可以很好地度量词与词之间的相似性。再举个列子,对于一句话:『她们 夸 彭于晏 到 没朋友』,如果输入 x 是『彭于晏』,那么 y 可以是『她们』、『夸』、『帅』、『没朋友』这些词
现有另一句话:『她们 夸 我 帅 到 没朋友』,如果输入 x 是『我』,那么不难发现,这里的上下文 y 跟上面一句话一样
从而 f(彭于晏) = f(我) = y,所以大数据告诉我们:我 = 彭于晏(完美的结论)。
统计语言模型给出了这一类问题的一个基本解决框架。对于一段文本序列
S=w1,w2,…,wT
概率可以表示为:

即将序列的联合概率转化为一系列条件概率的乘积。但是这样会出现一个严重的问题导致计算量巨大的参数。因为所有单词的的条件概率都计算了,这样一个原始的模型在实际中并没有什么用。而在实际生活中关联词也一般与前2个词语和后2个词语有关有关。p(wt|w1,w2,…,wt−1)≈p(wt|wt−n+1,…,wt−1)
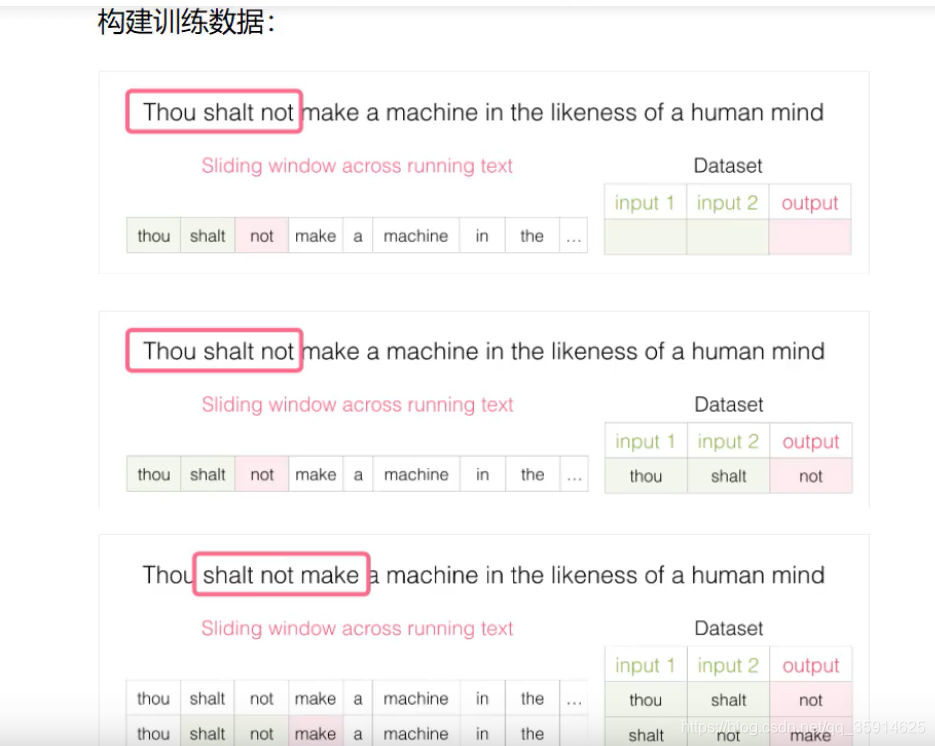
我们是怎么样构建训练数据的啦?
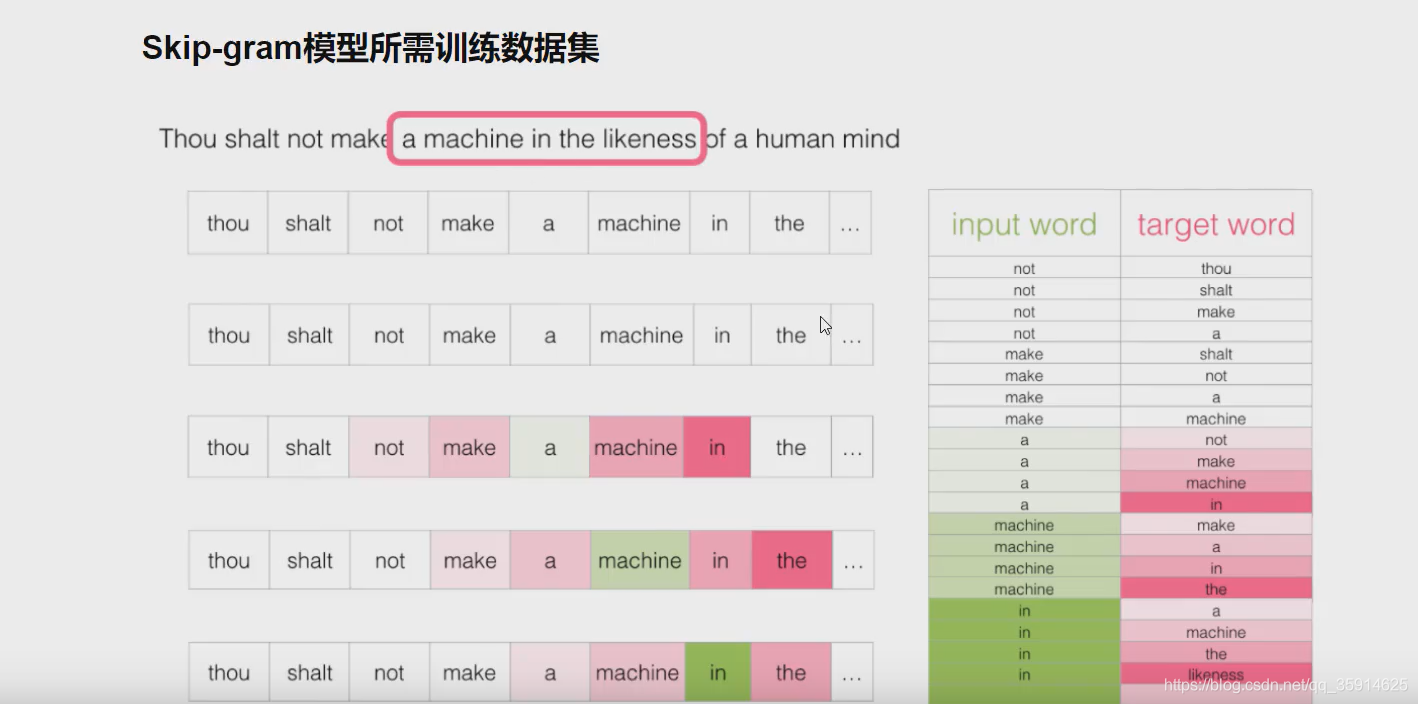
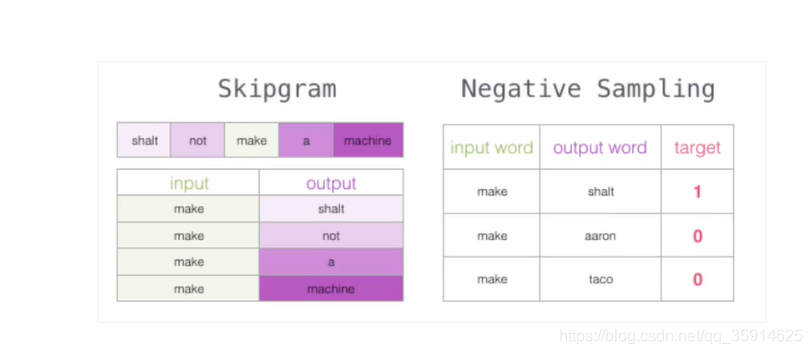
我们采用滑动窗口,在滑动窗口中不断取滑动,这里我们每次滑动3个单词。这样我们可以构建出每一对的数据
什么是CBOW和skipgram?
她是(善良)的小女孩。对于这句话来说,(她是)和 (的小女孩)叫做上下文,(善良)为结果 。
如下图,输入为上下文,推断输出为结果叫做CBOW。

在CBOW输入层是上下文的词语的词向量,在训练CBOW模型,词向量只是个副产品,确切来说,是CBOW模型的一个参数。训练开始的时候,词向量是个随机值,随着训练的进行不断被更新)。
投影层对其求和,所谓求和,就是简单的所有向量加法。
输出层输出最可能的w。由于语料库中词汇量是固定的|C|个,所以上述过程其实可以看做一个多分类问题。给定特征,从|C|个分类中挑一个。
在CBOW中采用哈夫曼树构建词向量,其中根节点表示出现的频率次数,叶子节点表示推段出来的向量。采用哈夫曼树也可以解决编码的问题
比如需要通过世界杯上我喜欢(足球),通过构建哈夫曼树负正正负推测出了足球,
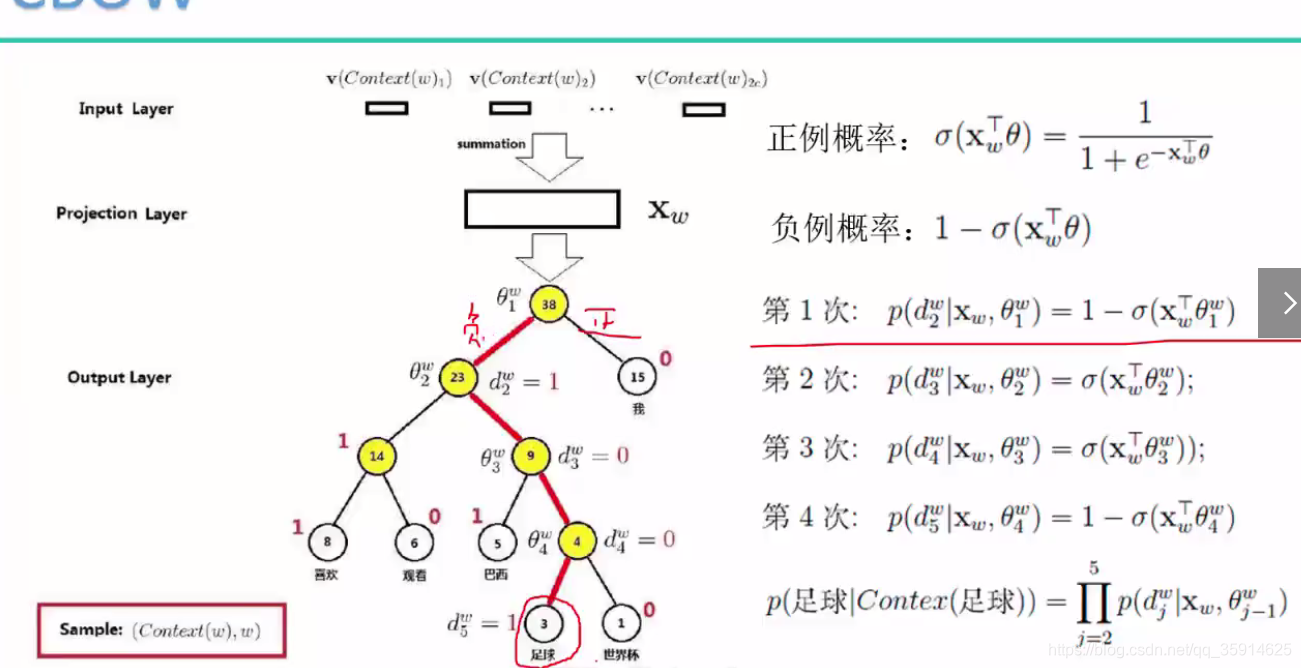
其中优化的loss值函数如下:dj表示正列或者负列,正列为0 ,负列为1.其中p值越大越好。

进行梯度上升更新,这里不仅要更新w,还要更新x.分别对Q和x求导更新。不过x是上下文的词向量的和,不是上下文单个词的词向量。怎么把这个更新量应用到单个词的词向量上去呢?word2vec采取的是直接将Xw的更新量整个应用到每个单词的词向量上去。


如下图,输入为结果,推断输出为上下文叫做skipgram。
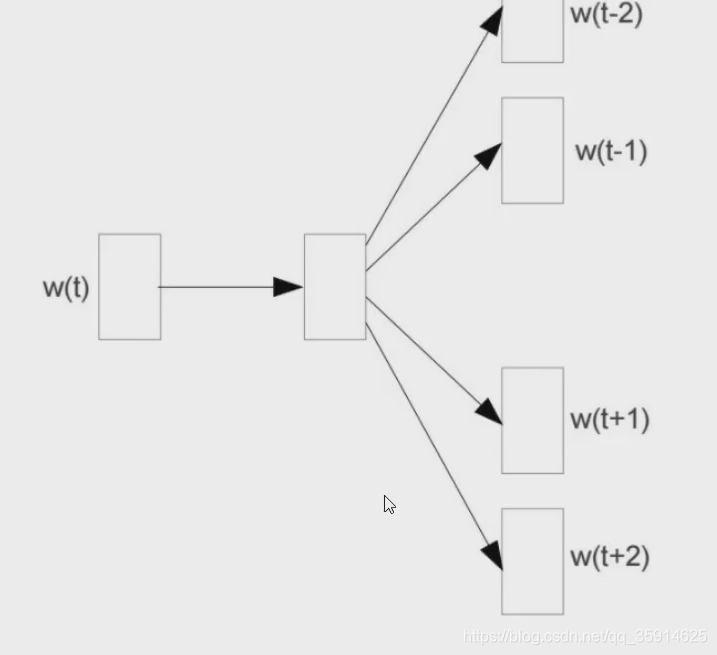
在反向传播中,不仅会更新权重w还会更新输入的向量,达到更好的推断出相似度。

但是如果一个语料库稍微过大了,直接预测后面的单词,可能计算起来特别耗时特别慢。我们可以把需要预测的都看成输入,预测相似度,这样就可以省下很多时间。这样就转成softmax------0,1的任务
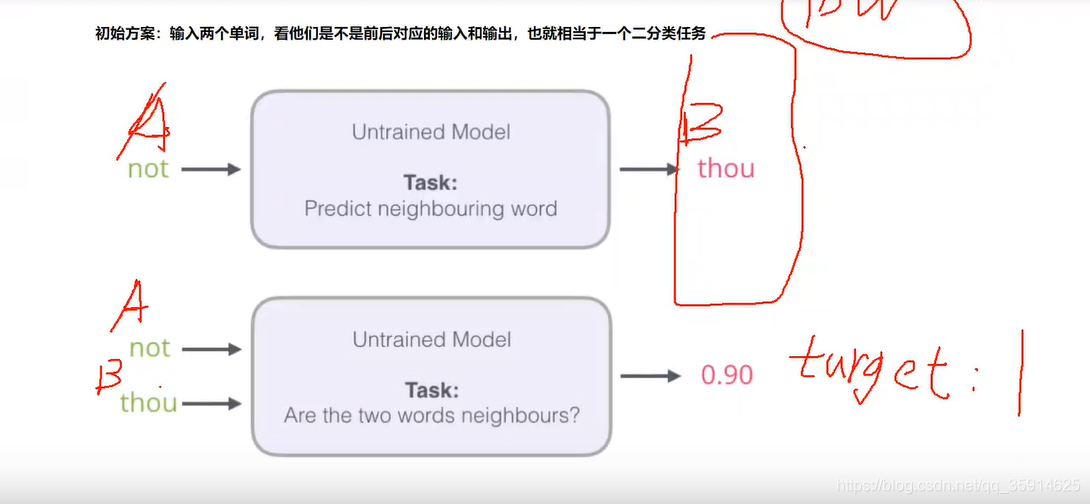
在构建标签中,如果我们直接构建输入数据会导致全为1都是正列样本,所以我们还要手动构建一些负列样本。
代码
# bs4 nltk gensim
import os
import re
import numpy as np
import pandas as pd
from bs4 import BeautifulSoup
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
from sklearn.linear_model import LogisticRegression
import nltk
from nltk.corpus import stopwords
nltk.download()
# 用pandas读入训练数据¶
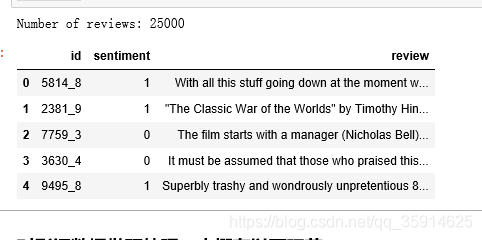
df = pd.read_csv('../data/labeledTrainData.tsv', sep='\t', escapechar='\\')
print('Number of reviews: {}'.format(len(df)))
df.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
对影评数据做预处理,大概有以下环节:
去掉html标签
移除标点
切分成词/token
去掉停用词
重组为新的句子
df['review'][1000]
#去掉HTML标签的数据
example = BeautifulSoup(df['review'][1000], 'html.parser').get_text()
example
#全部转成小写
words = example_letters.lower().split()
words
#去停用词
stopwords = {}.fromkeys([ line.rstrip() for line in open('../stopwords.txt')])
words_nostop = [w for w in words if w not in stopwords]
words_nostop
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
df = pd.read_csv('../data/unlabeledTrainData.tsv', sep='\t', escapechar='\\')
print('Number of reviews: {}'.format(len(df)))
df.head()
df['clean_review'] = df.review.apply(clean_text)
df.head()
import warnings
warnings.filterwarnings("ignore")
tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
def split_sentences(review): raw_sentences = tokenizer.tokenize(review.strip()) sentences = [clean_text(s) for s in raw_sentences if s] return sentences
sentences = sum(review_part.apply(split_sentences), [])
print('{} reviews -> {} sentences'.format(len(review_part), len(sentences)))
sentences_list = []
for line in sentences: sentences_list.append(nltk.word_tokenize(line))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
sentences:可以是一个list
sg: 用于设置训练算法,默认为0,对应CBOW算法;sg=1则采用skip-gram算法。
size:是指特征向量的维度,默认为100。大的size需要更多的训练数据,但是效果会更好. 推荐值为几十到几百。
window:表示当前词与预测词在一个句子中的最大距离是多少
alpha: 是学习速率
seed:用于随机数发生器。与初始化词向量有关。
min_count: 可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉, 默认值为5
max_vocab_size: 设置词向量构建期间的RAM限制。如果所有独立单词个数超过这个,则就消除掉其中最不频繁的一个。每一千万个单词需要大约1GB的RAM。设置成None则没有限制。
workers参数控制训练的并行数。
hs: 如果为1则会采用hierarchica·softmax技巧。如果设置为0(defau·t),则negative sampling会被使用。
negative: 如果>0,则会采用negativesamp·ing,用于设置多少个noise words
iter: 迭代次数,默认为5
# 设定词向量训练的参数
num_features = 300 # Word vector dimensionality
min_word_count = 40 # Minimum word count
num_workers = 4 # Number of threads to run in parallel
context = 10 # Context window size
model_name = '{}features_{}minwords_{}context.model'.format(num_features, min_word_count, context)
from gensim.models.word2vec import Word2Vec
model = Word2Vec(sentences_list, workers=num_workers, \ size=num_features, min_count = min_word_count, \ window = context)
# If you don't plan to train the model any further, calling
# init_sims will make the model much more memory-efficient.
model.init_sims(replace=True)
# It can be helpful to create a meaningful model name and
# save the model for later use. You can load it later using Word2Vec.load()
model.save(os.path.join('..', 'models', model_name))
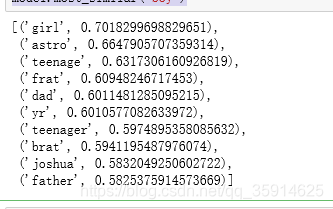
model.most_similar("boy")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
文章来源: blog.csdn.net,作者:快了的程序猿小可哥,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_35914625/article/details/108936101