
什么是前缀树?
直接说可能不太理解,我直接来张图:

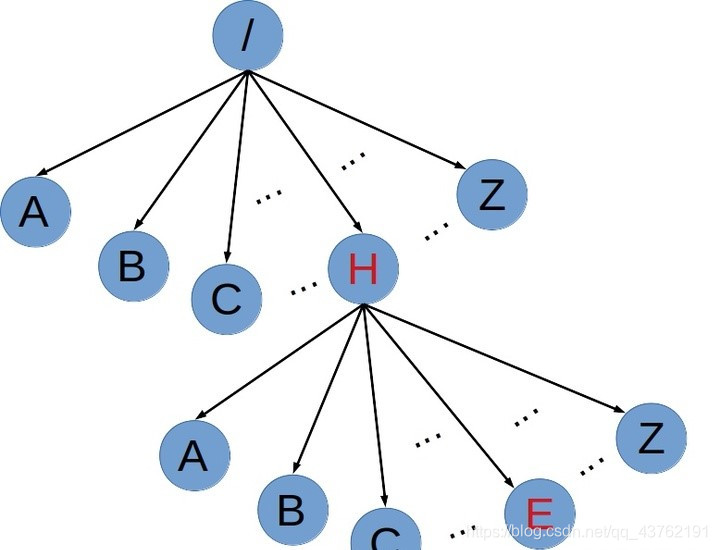
晓得了吧,一种特殊的N叉树。用于检索字符串数据集中的键。
Trie的应用场景
自动补全
就是前面那张谷歌的图,我也想自己截,奈何技术跟不上啊。
拼写检测
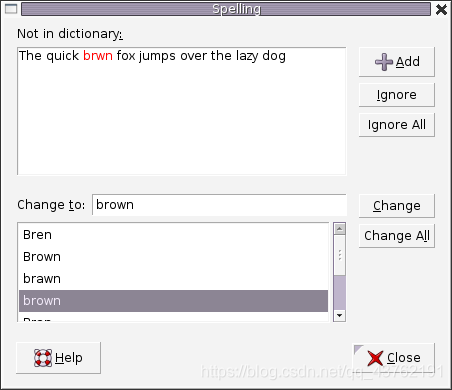
最长前缀匹配
比方说正则表达式,不过正则比这个要复杂一些了。
可以用来提取出表中所有以“ABC”开头的数据,但是数据表浩如烟海,你总不能让我去遍历吧!!!
Trie存在即合理
在平衡树、哈希表等树据结构的重重包围之下,Trie还是占据了一席之地,那么它有什么突出点呢?
这些树据结构,虽然各有千秋,但是总有鞭长莫及的时候,碧如:
找到具有同一前缀的全部键值。
按词典序枚举字符串的数据集。
- 1
- 2
没办法吧!!
随着哈希表大小增加,会出现大量的冲突,时间复杂度可能增加到 O(n)与哈希表相比,Trie 树在存储多个具有相同前缀的键时可以使用较少的空间。此时 Trie 树只需要 O(m)的时间复杂度,其中 m 为键长(顶多5*m)。而在平衡树中查找键值需要 O(mlogn)时间复杂度。
Trie的实现
节点结构
Trie 树是一个有根的树,其结点具有以下字段:。
最多 R 个指向子结点的链接,其中每个链接对应字母表数据集中的一个字母。
布尔字段,以指定节点是对应键的结尾还是只是键前缀。
- 1
- 2
class Trie {
private: bool isEnd; Trie* next[26];
public: void insert(string word); bool search(string word); bool startsWith(string prefix); //前缀匹配
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
先捋一下这个节点结构,会发现它没有包当前节点值。这是为什么呢?这是由于它的字母映射表机制决定的(next)。
next当中包括了接下来可能会出现的所有字母,所以只需:
for (int i = 0; i < 26; i++) { char ch = 'a' + i; if (parentNode->next[i] == NULL) { //说明父结点的后一个字母不可为 ch } else { //说明父结点的后一个字母可以是 ch }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
自己捋一下。
增
往前缀树中插入一个单词。
这有三种情况。
1、这个单词已经存在
2、这个单词已经是前缀了
3、这个单词不存在
对这三种情况,首先要做的都是遍历这棵树。
如果存在,那就没事儿了。
如果是前缀,那就改成完整的单词。
如果不存在,那就把缺少的字母补进去,并设为完整的单词。
void insert(string word) { Trie* node = this; for (char c : word) { if (node->next[c-'a'] == NULL) { node->next[c-'a'] = new Trie(); } node = node->next[c-'a']; } node->isEnd = true;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
查
在前缀树中查找一个单词是否存在。
这里有两种情况:
查到一半发现单词断层了,这妥妥的没了、
查到最后,结果这个单词只是前缀,那也是不行的。
bool search(string word) { Trie* node = this; for (char c : word) { node = node->next[c - 'a']; if (node == NULL) { return false; } } return node->isEnd;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
前缀匹配
匹配一个单词是否是前缀树中的前缀。
你看呢?
bool search(string word) { Trie* node = this; for (char c : word) { node = node->next[c - 'a']; if (node == NULL) { return false; } } return true;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
习题推荐
文章来源: lion-wu.blog.csdn.net,作者:看,未来,版权归原作者所有,如需转载,请联系作者。
原文链接:lion-wu.blog.csdn.net/article/details/114939297