背景
随着业务规模不断增长,传统单体结构变得越来越臃肿,在此背景下,单体应用在演进的过程中,进行微服务化拆分改造,成为主流的演进方向,逐步衍生出了微服务架构。
在微服务架构中,注册中心是最核心的组件之一,它承担着数量庞大的不同微服务之间的动态寻址问题。如下图:

注册中心架构按CAP定理可以分为AP和CP两种架构,现在市面上的注册中心CP架构的注册中心有zk,etcd,nacos1.0等,AP架构的有:eureka,nacos2.0等。
ServiceComb Service-Center简介
ServiceComb项目是华为开源的微服务框架,于 2017 年 11 月捐赠给 Apache 社区并启动孵化。作为一站式微服务解决方案,ServiceComb包含 java-chassis, service-center,kie, pack等多个子项目,Service-Center就是其注册中心组件。
Service-Center 是一个高可用、无状态的微服务注册中心,基于Go 语言实现,可提供服务实例注册、发现、依赖管理、黑白名单控制等管理能力。
随着业务规模扩大,我们在实践中发现Service-Center 1.X版本因其CP架构设计,存在性能天花板,只能达到万级别的实例管理能力。据此,我们开展了一系列性能优化的探索,例如切换底层存储(etcd换成Mongo DB)、异步批量注册、心跳长连接等等,在实践中性能有了显著的提升,下面将详细展开介绍。
Service-Center 1.X版本架构以及问题
首先我们来看一下service-center 1.X版本的架构,并结合测试分析存在的几个关键问题。
双层架构
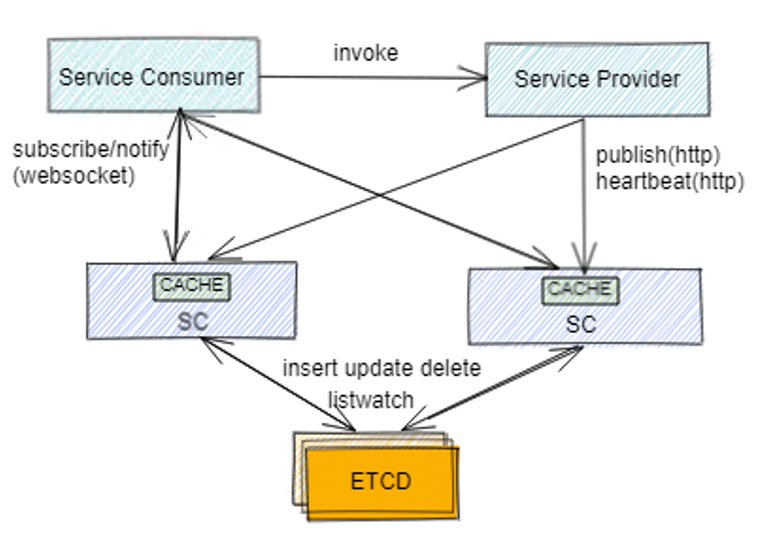
Service-Center是双层架构,分为session层(图中SC节点)和data层(图中etcd节点)。SC主要用于跟客户端交互,接收注册请求、推送实例信息等,etcd中持久化了服务信息、实例信息,同时将所有数据同步给了所有SC,充当了一个同步器。
Service-Center客户端通过HTTP请求发送注册请求到SC节点,然后SC把注册信息存储到etcd数据库里,并且缓存到本地内存中。
provider实例客户端会向SC层发送注册请求和心跳请求,两种都是HTTP请求;consumer实例客户端会向SC层发送订阅请求,基于websocket协议,建立websocket长连接,通过listwatch机制,获取SC中新注册的实例。
Service-Center的实例信息最终会存储到etcd数据库中,并且其他SC通过监听etcd的变化,同步获取所有实例信息。
问题发现与分析
在测试中我们发现了几个问题:

心跳请求频繁
实例通过心跳续约,每30s上报一次心跳,当服务/实例规模上升时,心跳请求轮询数量众多。心跳请求又是基于HTTP短连接模型的,每次客户请求都会创建和销毁TCP连接,而销毁释放TCP连接需要一定的时间,导致有很多TIME_WAIT状态的连接,这样一来业务处理的时间小于连接建立销毁的时间,导致资源空耗严重。
逐条写数据库
注册数据逐条写到etcd,每一个注册请求都会对应一条写DB的操作,随着规模的增长,对etcd的压力显著增大,这时写etcd 就成为瓶颈点。
etcd强一致性
etcd集群数据同步采用RAFT强一致算法,根据CAP理论,保证了强一致性,系统在可用性上就需要做出牺牲。etcd在写操作存在性能上限,导致服务实例注册速度慢;读操作虽然SC层有缓存机制,请求量过大时,会造成对etcd读请求压力过大及service center内存不够问题。
Service-Center 2.0版本高性能优化
双层架构

该架构兼容了1.X架构的功能,并且新增了DB存储对接Mongo DB的功能、websocket心跳长连接的功能、异步批量注册等功能(具体的选型过程可见后面章节)。
优化点
存储切换
1.选型调研
对于etcd的性能限制的问题,我们对底层数据库进行了选型,需要一个满足最终一致性、批量操作、横向扩展、订阅、高可用、TTL等功能的DB,经筛选发现MongoDB是一个适合的数据库,同时还具有文档结构存储方式,方便获取数据,完全能满足性能要求。
2.实现细节
实现过程中,首先我们保证功能向前兼容,可以通过配置来选择存储使用etcd还是MongoDB,
做到了客户端和服务端交互无感知。
SC实现了一套流程来对接mongo DB,如下图。API、订阅等流程复用了1.X中的逻辑,数据缓存因为跟etcd的存储结构存在差异,单独实现了对mongo DB结构的适配,Dao层封装了service\instance\Dependency等资源的CRUD接口,最终通过mongo的client与mongo DB交互。
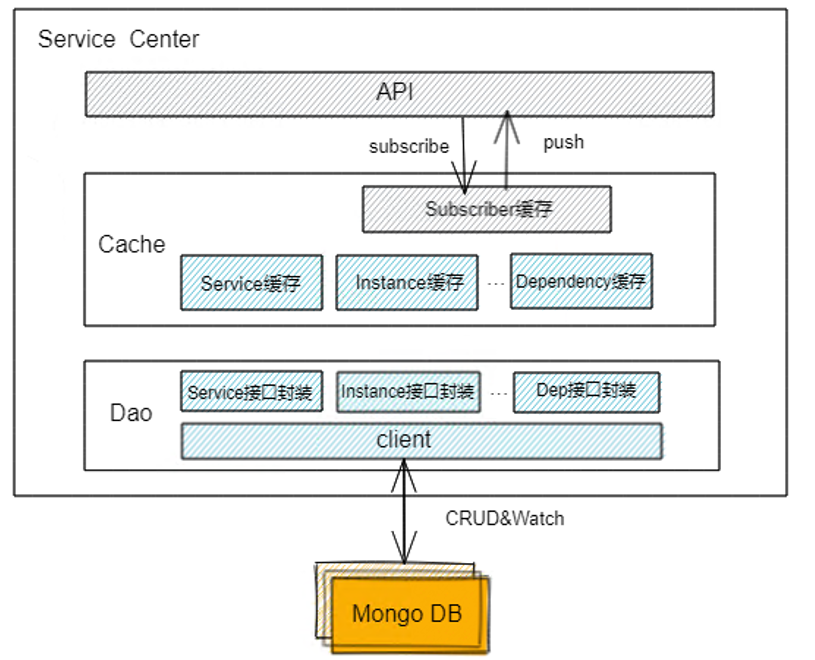
Cache和同步实现
缓存以及多个SC之间的数据同步是通过SC与mongo DB的list watch机制实现的。SC启动时,会触发list watch定时任务,list操作即调用查询所有资源接口,list操作会定时执行,时间可以通过配置文件配置(默认120s);而watch操作用到了MongoDB的Change Stream机制,下面详细介绍一下。
Mongo DB的Change Stream机制,是指通过一次Change Stream API 调用,即可从MongoDB侧获取增量修改。通过 resume token 来标识拉取位置,只需在 API 调用时,带上上次结果的 resume token,即可从上次的位置接着订阅,这样可以保证数据不丢失。
SC启动doWatch流程后,传入resume token与mongo与建立watch长连接,这期间mongo DB会实时推送变更数据给SC,并更新resume token。在异常情况下,因mongo DB故障或其他原因导致watch失败或断连,SC则记录故障前的resume token,下次watch重新建立连接时传入resume token,SC就可以接着故障前的记录订阅,保证了不丢数据,也保证了可用性。
Dao层封装
Mongo DB是文档存储结构,在DB里创建了service 、instance、dependency等集合来存储服务、实例、依赖关系的信息。然后封装了每个集合的CRUD操作命令,并且封装了一些公共的过滤条件用于不同的文档操作(查询,更新,删除)。在实践中还发现了DB慢查询问题,为了解决该问题,我们设计了合理的索引,然后SC在启动流程中加上了建立索引的流程,保证有效高效的进行数据库操作。
当然在DB操作方面还有一定的优化空间,后面我们也会继续去分析优化方法,保证高效的数据库操作。
3.优化成果
切换Mongo DB之后与使用etcd的SC接口性能进行了对比测试,SC(8u16g*2)+Mongo DB(16u32g*2)的规格下,Mongo DB注册服务接口TPS达到5w,相比etcd只有6k,提升了8倍,Mongo DB注册实例接口TPS达到3w,相比etcd版本的4k,提升了7.5倍。
心跳长连接
1.选型调研
因为心跳HTTP请求对资源空耗过多,于是我们分析并尝试使用长连接来解决问题。对grpc、thrift、websocket进行了一个简单的测试。简单定义了传输消息的protobuf文件,在2台4u8g的机子上分别部署server和client。下表是相关的测试数据(每组数据分别测了10次取了平均值):

通过分析可知,相同条件下,thrift的资源消耗率最低,但是吞吐率最低;websocket的吞吐率最高,资源消耗也适中。我们最终选择了websocket,是因为原有1.X架构里SC订阅推送用的就是websocket长连接,考虑到长连接复用问题。其实grpc也是很好的备选项,它能额外能支持stream,适合传输一些大数据,以及服务端和客户端长时间的数据交互,我们后期不排除会支持grpc。
websocket长连接复用了HTTP的握手通道,客户端通过HTTP请求与websocket服务端协商升级协议,协议升级完成后,后续的数据交换则遵照websocket协议。
2.实现细节
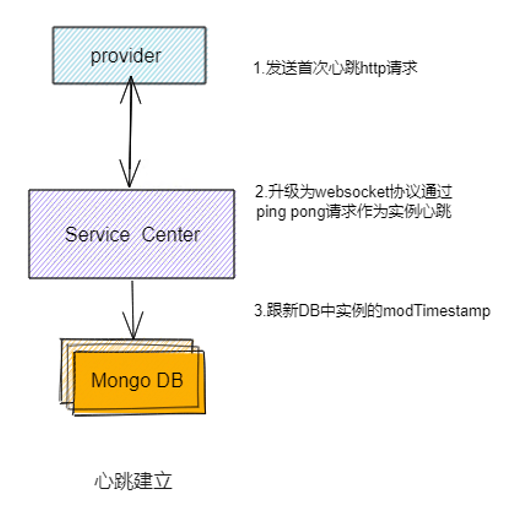
在实例注册完之后,客户端发送HTTP心跳请求,SC接收到心跳请求后把HTTP协议升级为websocket协议, 然后SC通过websocket长连接每30s发送一次ping请求给客户端,客户端则返回 pong 请求给SC,这样SC就能知道实例是否还在线。
SC收到心跳之后,还会去更新DB中实例的modTimestamp列,这是为了配合Mongo DB的TTL索引机制,来保证SC故障场景没有数据残留,后面文章会详细说明。
实例正常下线时候,会主动调用注销接口的,但不排除有些实例可能意外下线了,还没来得及调用注销接口,这时候SC发送ping请求给客户端,就无法得到响应了,这样SC识别到心跳超时,就会主动去删除DB中存储的实例信息,保证实例及时下线。
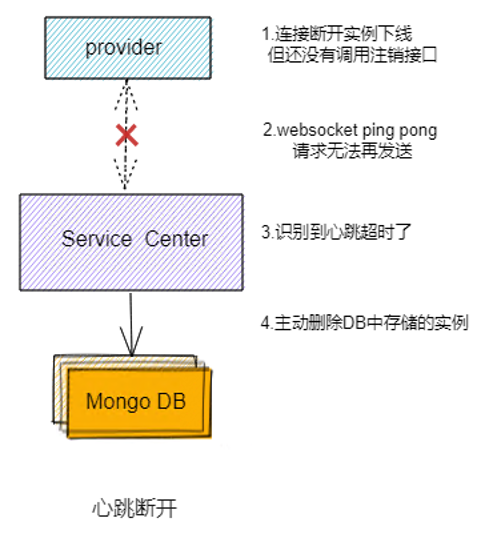
当所有SC实例故障时,websocket连接断连,注销接口也无法调用,这时DB中的实例就可能永远无法下线了,为了解决这个问题我们用到了Mongo DB的TTL索引机制。
TTL全称是(Time To Live), TTL索引能对一个单列配置过期属性来实现对文档的自动过期删除,我们对实例的modTimestamp列创建TTL索引,默认设置expireAfterSeconds为300s, 这样 Mongo DB会自动去清理超过300s没有报心跳的实例。

3.优化成果
实现心跳长连接之前,SC(8u16g)规格下实例数量到3w时, SC节点因为HTTP连接建立断开的空耗,开始出现注册阶段CPU过高的情况,优化为长连接之后,实例注册节点运行更加稳定,CPU消耗减少一半,总体支持的数量也明显提升。
异步批量注册
- 前期测试
发现逐条注册对DB的压力问题之后,通过调研和测试发现批量写相比逐条写TPS能提升8倍,所以我们决定实现一套异步批量注册流程,来满足大规模、高性能的场景。
- 实现细节
左边是实例异步批量注册的流程图,右边是实例逐条注册的流程图:

默认使用逐条注册流程,如果规模大,对高性能有要求的场景可以开启异步批量注册。
正常情况:
异步注册收到实例注册请求后,把实例注册信息放入队列,最终通过定时任务批量注册到MongoDB中(默认100ms)。
异常情况下:
如果Mongo和服务中心的连接断开,注册失败,实例会被放入失败队列重新注册;
如果连续3次注册失败,熔断器会控制暂停5s,注册成功后恢复;
单个实例注册失败超过一定次数(默认500次),该实例将被丢弃,当心跳发现该实例不存在时SDK会重新注册。
- 测试结果
通过异步注册,提升了注册速度,降低了mongo DB的消耗,SC(8u16g*2)+Mongo DB(16u32g*2)的规格下异步注册实例接口TPS由3w,上升到9w,性能提高三倍。
Service-Center 整体性能测试
测试方法
我们进行了模拟真实场景进行测试,按1:1部署provider和consumer服务实例,consumer向SC订阅若干个服务,然后调用provider。
部署模式,如下图所示:

Client端部署
通过K8S集群部署provider deployment和consumer deployment,来模拟实例上下线,通过修改deployment的副本数来增加pod个数,每个Pod里面部署200个实例进程,可以通过部署100、200、400个pod来模拟2w、4w、8w实例的注册。
Service-Center部署
总资源为24u48g,两台4u8g虚机,两台8u16g虚机。
SC采用双节点部署,部署在4u8g节点。
Mongo DB采用副本集模式,主从节点分别部署在两台8u16g节点上, 因为mongo DB的仲裁节点,资源消耗较低,所以跟SC其中一个节点部署在一起。
测试方法:
provider和consumer, 按1:1的比例部署,先创建provider,再部署consumer,分别测试每个consumer订阅2、5、10个provider服务的情况。
性能测试报告
在24u48g的资源下,测试报告如下表:
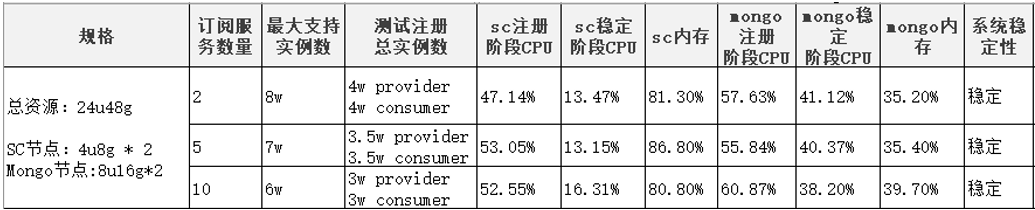
24u48g规格下Service-Center能支持的最大实例数量为8w。此时SC内存达到了80%,继续往上注册实例SC节点在注册阶段容易出现OOM,导致节点崩溃。
当consumer订阅数量上涨的时候,最大能支撑的服务数量略有下降,订阅2个服务时,最大能稳定支撑8w实例,而订阅5个和10个服务的时候,分别最大能支撑到7w、6w实例。
把资源扩大到32u64g后,Service-Center最大能支撑16w实例。

相比其他注册中心性能
同样在24u48g的资源下,我们测试了国内某流行开源注册中心的性能,结果如下表:

24u48g规格下,该注册中心最大支撑实例数为4w, 当测试注册5w、6w实例注册的时候系统就不稳定了,该注册中心注册阶段的CPU使用率接近100%,会出现集群节点崩溃的情况。
随着订阅数量上涨,最大支持的服务数量也会下降,性能瓶颈主要在于注册接的阶段和稳定阶段的CPU,实例数量上去CPU压力太大导致注册时候系统无法达到稳定状态,系统会崩溃。
测试过程中也参考了该注册中心官方的测试方法和数据,如下:
https://nacos.io/zh-cn/blog/performance-compare.html
Service-Center 性能测试结论
Service-Center在24u48g的规格下能稳定支撑8w实例,32u64g规格下,能稳定支撑16w实例;当前主要瓶颈在于SC(4u8g)内存不够, 横向扩展SC,或者扩大SC内存规格,支持实例的数量还有进一步上涨的空间。
跟某开源注册中心产品相比性能稍有优势,同等规格下能稳定支持的实例数量更多,注册阶段系统更加稳定。
ServiceComb Service-Center未来规划
通过持续的分析优化,我们也发现了当前架构还存在的一些问题,识别到可以持续改进的优化点,抽象复用:如Mongo/etcd代码持续抽象,保证只有数据库对接层代码不同,其他流程都能共用;架构设计:如缓存结构优化、心跳更新批量处理、长连接优化、Mongo DB分片、SDK亲和性调度优化等等;文档方面也可以逐步更新、细化官方文档细节内容,促进讨论与贡献。争取在持续优化后,在真实场景下,能支持百万级别实例管理。
作者简介:
傅紫叶:目前就职于华为云HCS实验室,从事云计算PaaS领域异地多活、注册中心等方向的研究与开发
罗健文:目前就职于华为云HCS实验室,从事云计算PaaS领域微服务架构、微服务治理等方向的研究与开发