对于倒排索引来说,很重要的一件事情就是需要对文本进行分词,经过分词可以获取情感、词性、质性、词频等等的数据。
Elasticsearch 分词工作原理
在 Elasticsearch 中进行行分词的需要经过分析器的3个模块,字符过滤器将文本进行替换或者删除,在由分词器进行拆分成单词,最后由Token过滤器将一些无用语气助词删掉。

英文分词
在Elasticsearch 中共支持5种不同的分词模式,在不同的场景下发挥不同的效果。
standard (过滤标点符号)
GET /_analyze
{
"analyzer": "standard",
"text": "The programmer's holiday is 1024!"
}
- 1
- 2
- 3
- 4
- 5

simple (过滤数字和标点符号)
GET /_analyze
{
"analyzer": "simple",
"text": "The programmer's holiday is 1024!"
}
- 1
- 2
- 3
- 4
- 5
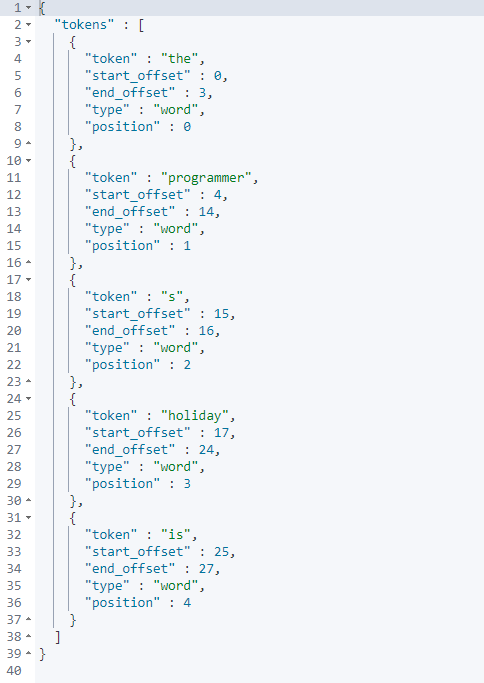
whitespace (不过滤,按照空格分隔)
GET /_analyze
{
"analyzer": "whitespace",
"text": "The programmer's holiday is 1024!"
}
- 1
- 2
- 3
- 4
- 5
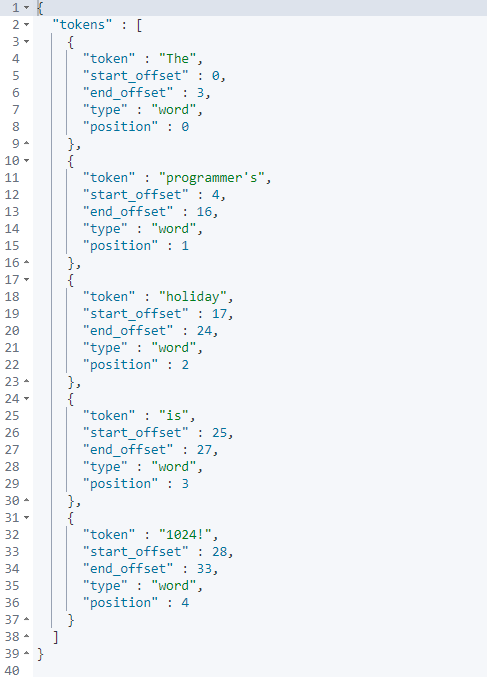
stop (过滤停顿单词及标点符号,例如is are等等)
GET /_analyze
{
"analyzer": "stop",
"text": "The programmer's holiday is 1024!"
}
- 1
- 2
- 3
- 4
- 5

keyword (视为一个整体不进行任何处理)
GET /_analyze
{
"analyzer": "keyword",
"text": "The programmer's holiday is 1024!"
}
- 1
- 2
- 3
- 4
- 5
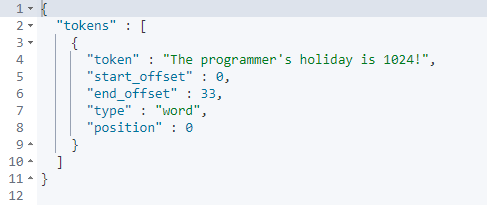
中文分词
因为 Elasticsearch 默认的分词器只能按照单字进行拆分,无法具体分析其语意等,所以我们使用 analysis-icu 来代替默认的分词器。
GET /_analyze
{
"analyzer": "standard",
"text": "南京市长江大桥"
}
- 1
- 2
- 3
- 4
- 5
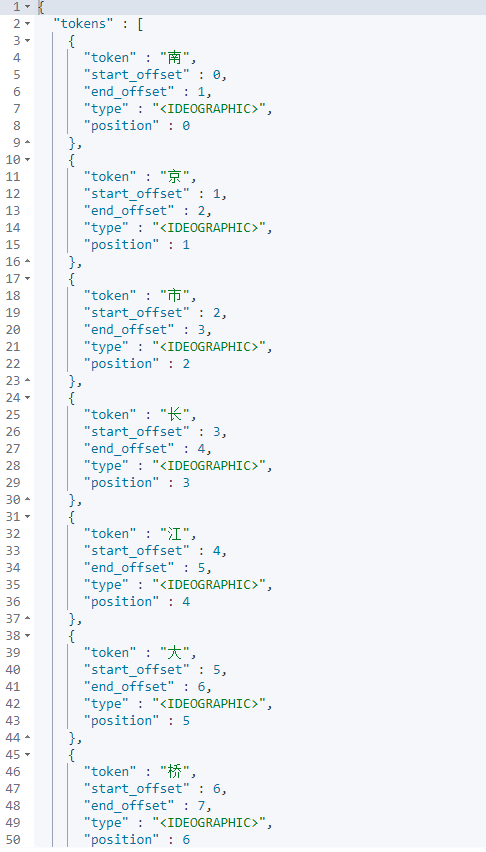
通过命令./bin/elasticsearch-plugin install analysis-icu进行安装
GET /_analyze
{
"analyzer": "icu_analyzer",
"text": "南京市长江大桥"
}
- 1
- 2
- 3
- 4
- 5

其他的中文分词器
elasticsearch-thulac-plugin 支持中文分词和词性标注功能
https://github.com/microbun/elasticsearch-thulac-plugin
elasticsearch-analysis-ik 支持热更新分词字典及自定义词库
https://github.com/medcl/elasticsearch-analysis-ik
文章来源: yekangming.blog.csdn.net,作者:叶康铭,版权归原作者所有,如需转载,请联系作者。
原文链接:yekangming.blog.csdn.net/article/details/109103707