@Author:Runsen
@[toc]
人脸检测,看似要使用深度学习,觉得很高大牛逼,其实通过opencv就可以制作人脸识别的窗口。

今天,Runsen教大家将构建一个简单的Python脚本来处理图像中的人脸,使在OpenCV库中两种方法 。
首先,我们将使用haar级联分类器,这对初学者来说是一种简单的方法(也不太准确),也是最方便的方法。
其次是单发多盒检测器(或简称SSD),这是一种深度神经网络检测图像中对象的方法。
使用Haar级联进行人脸检测
基于haar特征的级联分类器的,OpenCV已经为我们提供了一些分类器参数,因此我们无需训练任何模型,直接使用。
opencv的安装
pip install opencv-python
我们首先导入OpenCV:
import cv2
下面对示例图像进行测试,我找来了我学校的两个漂亮美女的图像:


image = cv2.imread("beauty.jpg")
函数imread()从指定的文件加载图像,并将其作为numpy的 N维数组返回。
在检测图像中的面部之前,我们首先需要将图像转换为灰度图:
image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
下面,因为要初始化人脸识别器(默认的人脸haar级联),需要下载对应的参数xml文件,
这里选择最初的haarcascade_frontalface_default.xml
下面代码就是加载使用人脸识别器
face_cascade = cv2.CascadeClassifier("haarcascade_fontalface_default.xml")
现在让我们检测图像中的所有面孔:
# 检测图像中的所有人脸
faces = face_cascade.detectMultiScale(image_gray)
print(f"{len(faces)} faces detected in the image.")
detectMultiScale() 函数将图像作为参数并将不同大小的对象检测为矩形列表,因此我们绘制矩形,同样有rectangle方法提供
#为每个人脸绘制一个蓝色矩形
for x, y, width, height in faces:
# 这里的color是 蓝 黄 红,与rgb相反,thickness设置宽度
cv2.rectangle(image, (x, y), (x + width, y + height), color=(255, 0, 0), thickness=2)
最后,让我们保存新图像:
cv2.imwrite("beauty_detected.jpg", image)
基于haar特征的级联分类器的结果图

我们惊奇的发现图片1是没有设备出来的,这是因为存在障碍物,

我们惊奇的发现图片2是竟然设别出来了两个窗口。
Haar级联结合摄像头
使用Haar级联进行人脸检测可以说是opencv最基础的效果,下面我们利用摄像头将Haar级联进行合并,这样就可以达到开头的效果。
import cv2
#创建新的cam对象
cap = cv2.VideoCapture(0)
#初始化人脸识别器(默认的人脸haar级联)
face_cascade = cv2.CascadeClassifier("haarcascade_fontalface_default.xml")
while True:
# 从摄像头读取图像
_, image = cap.read()
# 转换为灰度
image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 检测图像中的所有人脸
faces = face_cascade.detectMultiScale(image_gray, 1.3, 5)
# 为每个人脸绘制一个蓝色矩形
for x, y, width, height in faces:
cv2.rectangle(image, (x, y), (x + width, y + height), color=(255, 0, 0), thickness=2)
cv2.imshow("image", image)
if cv2.waitKey(1) == ord("q"):
break
cap.release()
cv2.destroyAllWindows()
使用SSD的人脸检测
上面的效果是已经过时了,但是OpenCV为我们提供了包装中dnn模块cv2,从而可以直接加载经过预训练的深度学习模型。
2015年底有人提出了一个实时对象检测网络Single Shot MultiBox Detector缩写为SSD
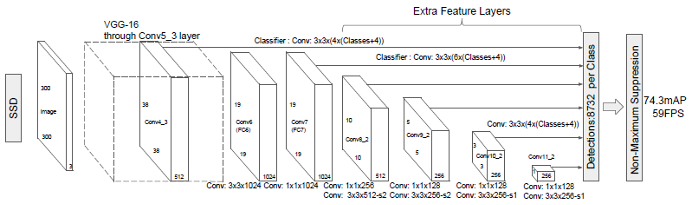
SSD对象检测网络简单说可以分为三个部分:
- 基础网络(backbone) 这里为VGG16
- 特征提取Neck,构建多尺度特征
- 检测头 – 非最大抑制与输出
要开始使用SSD在OpenCV中,需要下载RESNET人脸检测模型和其预训练的权重,然后将其保存到代码weights工作目录:

import cv2
import numpy as np
# 下载链接:https://raw.githubusercontent.com/opencv/opencv/master/samples/dnn/face_detector/deploy.prototxt
prototxt_path = "weights/deploy.prototxt.txt"
# 下载链接:https://raw.githubusercontent.com/opencv/opencv_3rdparty/dnn_samples_face_detector_20180205_fp16/res10_300x300_ssd_iter_140000_fp16.caffemodel
model_path = "weights/res10_300x300_ssd_iter_140000_fp16.caffemodel"
# 加载Caffe model
model = cv2.dnn.readNetFromCaffe(prototxt_path, model_path)
# 读取所需图像
image = cv2.imread("beauty.jpg")
# 获取图像的宽度和高度
h, w = image.shape[:2]
现在,需要这个图像传递到神经网络中,由于下载的模型是(300, 300) px的。
因此,我们需要将图像调整为的(300, 300)px形状:
# 预处理图像:调整大小并执行平均减法。 104.0, 177.0, 123.0 表示b通道的值-104,g-177,r-123
# 在深度学习中通过减去数人脸据集的图像均值而不是当前图像均值来对图像进行归一化,因此这里写死了
blob = cv2.dnn.blobFromImage(image, 1.0, (300, 300),(104.0, 177.0, 123.0))
将此blob对象用作神经网络的输入,获取检测到的面部:
# 将图像输入神经网络
model.setInput(blob)
# 得到结果
output = np.squeeze(model.forward())
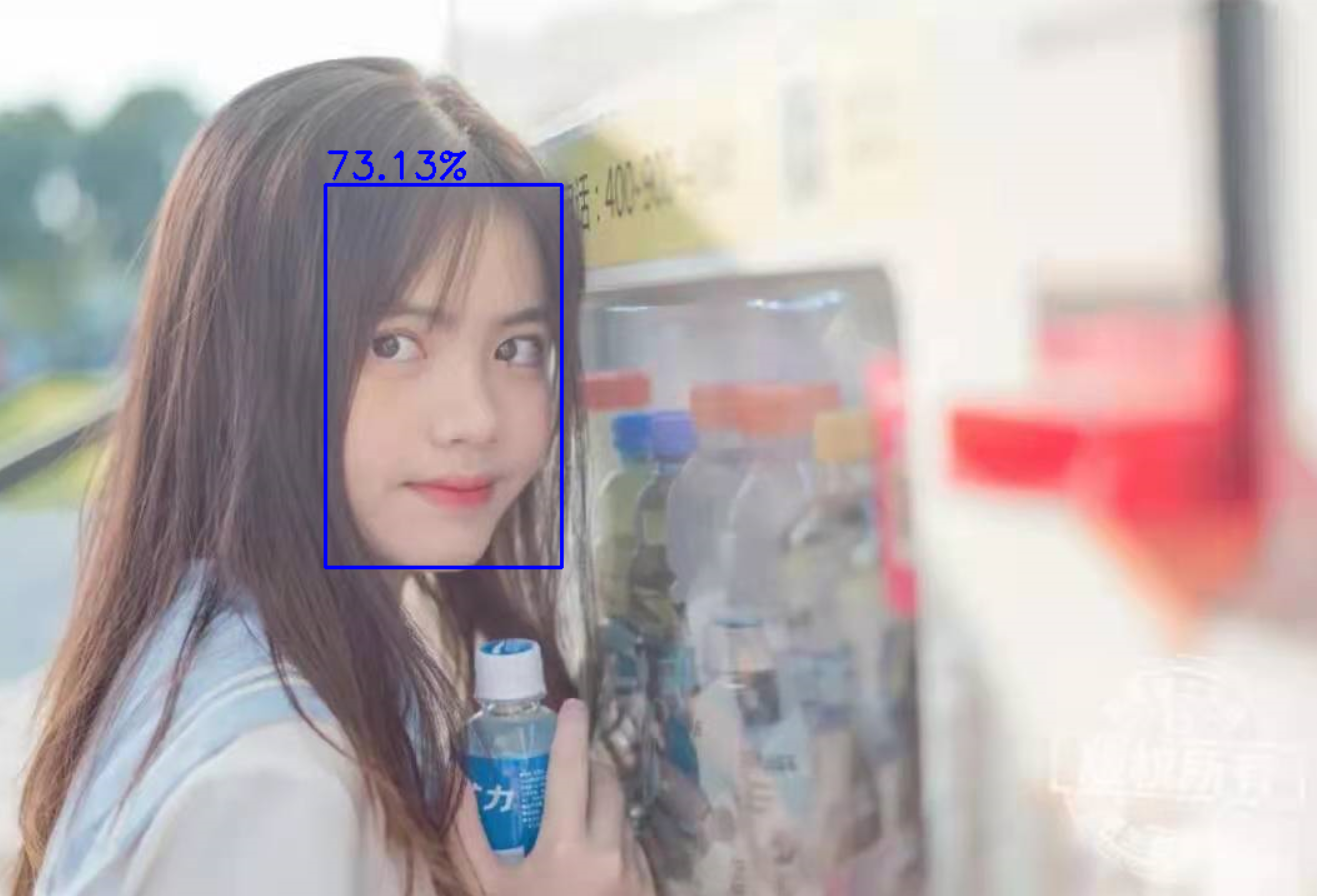
输出对象output 具有所有检测到的对象,在这种情况下一般都是人脸,让我们遍历output,并在取一个置信度大于50%的判断条件:
font_scale = 1.0
# output.shape ==(200, 7)
for i in range(0, output.shape[0]):
# 置信度
confidence = output[i, 2]
# 如果置信度高于50%,则绘制周围的方框
if confidence > 0.5:
# 之前将图片变成300*300,接下来提取检测到的对象的模型的置信度后,我们得到周围的框 output[i, 3:7],然后将其width与height原始图像的和相乘,以获得正确的框坐标
box = output[i, 3:7] * np.array([w, h, w, h])
# 转换为整数
start_x, start_y, end_x, end_y = box.astype(np.int)
# 绘制矩形
cv2.rectangle(image, (start_x, start_y), (end_x, end_y), color=(255, 0, 0), thickness=2)
# 添加文本
cv2.putText(image, f"{confidence*100:.2f}%", (start_x, start_y-5), cv2.FONT_HERSHEY_SIMPLEX, font_scale, (255, 0, 0), 2)
最后我们展示并保存新图像:
cv2.imshow("image", image)
cv2.waitKey(0)
cv2.imwrite("beauty_detected.jpg", image)

下面是完整代码
import cv2
import numpy as np
# 下载链接:https://raw.githubusercontent.com/opencv/opencv/master/samples/dnn/face_detector/deploy.prototxt
prototxt_path = "weights/deploy.prototxt.txt"
# 下载链接:https://raw.githubusercontent.com/opencv/opencv_3rdparty/dnn_samples_face_detector_20180205_fp16/res10_300x300_ssd_iter_140000_fp16.caffemodel
model_path = "weights/res10_300x300_ssd_iter_140000_fp16.caffemodel"
model = cv2.dnn.readNetFromCaffe(prototxt_path, model_path)
image = cv2.imread("beauty.jpg")
h, w = image.shape[:2]
blob = cv2.dnn.blobFromImage(image, 1.0, (300, 300),(104.0, 177.0, 123.0))
model.setInput(blob)
output = np.squeeze(model.forward())
font_scale = 1.0
for i in range(0, output.shape[0]):
confidence = output[i, 2]
if confidence > 0.5:
box = output[i, 3:7] * np.array([w, h, w, h])
start_x, start_y, end_x, end_y = box.astype(np.int)
cv2.rectangle(image, (start_x, start_y), (end_x, end_y), color=(255, 0, 0), thickness=2)
cv2.putText(image, f"{confidence*100:.2f}%", (start_x, start_y-5), cv2.FONT_HERSHEY_SIMPLEX, font_scale, (255, 0, 0), 2)
cv2.imshow("image", image)
cv2.waitKey(0)
cv2.imwrite("beauty_detected.jpg", image)
SSD结合摄像头的人脸检测
SSD结合摄像头的人脸检测方法更好,更准确,但是每秒传输帧数FPS方面可能低,因为它不如Haar级联方法快,但这问题并不大。
下面是SSD结合摄像头的人脸检测的全部代码
import cv2
import numpy as np
prototxt_path = "weights/deploy.prototxt.txt"
model_path = "weights/res10_300x300_ssd_iter_140000_fp16.caffemodel"
model = cv2.dnn.readNetFromCaffe(prototxt_path, model_path)
cap = cv2.VideoCapture(0)
while True:
_, image = cap.read()
h, w = image.shape[:2]
blob = cv2.dnn.blobFromImage(image, 1.0, (300, 300), (104.0, 177.0, 123.0))
model.setInput(blob)
output = np.squeeze(model.forward())
font_scale = 1.0
for i in range(0, output.shape[0]):
confidence = output[i, 2]
if confidence > 0.5:
box = output[i, 3:7] * np.array([w, h, w, h])
start_x, start_y, end_x, end_y = box.astype(np.int)
cv2.rectangle(image, (start_x, start_y), (end_x, end_y), color=(255, 0, 0), thickness=2)
cv2.putText(image, f"{confidence*100:.2f}%", (start_x, start_y-5), cv2.FONT_HERSHEY_SIMPLEX, font_scale, (255, 0, 0), 2)
cv2.imshow("image", image)
if cv2.waitKey(1) == ord("q"):
break
cv2.destroyAllWindows()
cap.release()

最后,Please give me a Like and pay attention me