@Author:Runsen
谁都无法否认,长得好看的人就是更具有吸引力,赏心悦目谁都喜欢。好看的人无论在职场或情场,都一定更占优势。
但是,此「颜值」非彼「颜值」。一说到「颜值」,大部分想到的是脸蛋。
因此,对于我来说,希望模糊图像和视频的人脸。在本篇博客中,你将学习如何使用 Python 中的 OpenCV 库模糊图像和视频中的人脸。
为了模糊图像中显示的人脸,首先检测这些人脸及其在图像中的位置。对此,查看之前的一篇关于人脸检测的教程,在这里使用人脸检测的源代码。
我们使用基于SSD的人脸检测,具体源代码如下所示。
import cv2
import numpy as np
# 下载链接:https://raw.githubusercontent.com/opencv/opencv/master/samples/dnn/face_detector/deploy.prototxt
prototxt_path = "weights/deploy.prototxt.txt"
# 下载链接:https://raw.githubusercontent.com/opencv/opencv_3rdparty/dnn_samples_face_detector_20180205_fp16/res10_300x300_ssd_iter_140000_fp16.caffemodel
model_path = "weights/res10_300x300_ssd_iter_140000_fp16.caffemodel"
model = cv2.dnn.readNetFromCaffe(prototxt_path, model_path)
image = cv2.imread("beauty.jpg")
h, w = image.shape[:2]
blob = cv2.dnn.blobFromImage(image, 1.0, (300, 300),(104.0, 177.0, 123.0))
model.setInput(blob)
output = np.squeeze(model.forward())
font_scale = 1.0
for i in range(0, output.shape[0]):
confidence = output[i, 2]
if confidence > 0.5:
box = output[i, 3:7] * np.array([w, h, w, h])
start_x, start_y, end_x, end_y = box.astype(np.int)
cv2.rectangle(image, (start_x, start_y), (end_x, end_y), color=(255, 0, 0), thickness=2)
cv2.putText(image, f"{confidence*100:.2f}%", (start_x, start_y-5), cv2.FONT_HERSHEY_SIMPLEX, font_scale, (255, 0, 0), 2)
cv2.imshow("image", image)
cv2.waitKey(0)
cv2.imwrite("beauty_detected.jpg", image)
高斯模糊
模糊的算法有很多,其中有一种叫高斯模糊(Gaussian Blur),它将正态分布用于图像处理。
既然名称为高斯滤波器,那么其和高斯分布(正态分布)是有一定的关系的。
“高斯函数”(Gaussian function)的一维形式是
根据 的一维高斯函数,可以推导得到二维高斯函数:
所谓"模糊",可以理解成每一个像素都取周边像素的平均值。

上图中,2是中间点,周边点都是1。
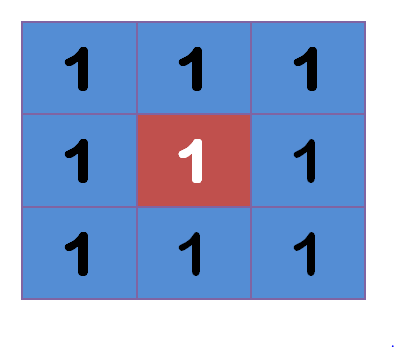
“中间点"取"周围点"的平均值,就会变成1。在数值上,这是一种"平滑化”。在图形上,就相当于产生"模糊"效果,"中间点"失去细节。
一般高斯模糊都有对应的权重矩阵。
假定中心点的坐标是(0,0),那么距离它最近的8个点的坐标如下:

为了计算权重矩阵,需要设定σ的值。假定σ=1.5,则模糊半径为1的权重矩阵如下:

这9个点的权重总和等于0.4787147,如果只计算这9个点的加权平均,还必须让它们的权重之和等于1,因此上面9个值还要分别除以0.4787147,得到最终的权重矩阵。

有了权重矩阵,就可以计算高斯模糊的值了。假设现有9个像素点,灰度值(0-255)如下:
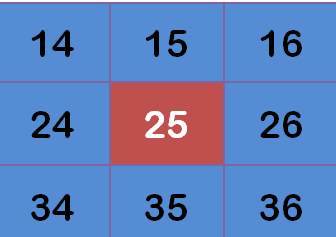
每个点乘以自己的权重值:

OpenCV 提供了 cv2.gaussianblur() 函数来对输入源图像应用高斯平滑。以下是 GaussianBlur() 函数的语法:
dst = cv2.GaussianBlur(src, ksize, sigmaX[, dst[, sigmaY[, borderType=BORDER_DEFAULT]]] )
| 参数 | 描述 |
|---|---|
| src | 输入图像 |
| dst | 输出图像 |
| ksize | 高斯核大小(height 和 width而定)。height 和 width 应该是奇数并且可以有不同的值。如果 ksize 设置为 [0 0],则 ksize 是根据 sigma 值计算的。 |
| sigmaX | sigma 沿 X 轴(水平方向)的内核标准偏差。 |
| sigmaY | sigma 沿 Y 轴(水平方向)的内核标准偏差。 |
| borderType | 边框类型 当内核应用于图像边界时指定图像边界。可能的值是: cv.BORDER_CONSTANT cv.BORDER_REPLICATE cv.BORDER_REFLECT cv.BORDER_WRAP cv.BORDER_REFLECT_101 cv.BORDER_TRANSPARENT cv.BORDER_REFLECT101 cv.BORDER_DEFAULT ISOLA. |
在 Python 中使用 OpenCV 实现高斯模糊的具体代码
import cv2
import numpy as np
import sys
# https://raw.githubusercontent.com/opencv/opencv/master/samples/dnn/face_detector/deploy.prototxt
prototxt_path = "weights/deploy.prototxt.txt"
# https://raw.githubusercontent.com/opencv/opencv_3rdparty/dnn_samples_face_detector_20180205_fp16/res10_300x300_ssd_iter_140000_fp16.caffemodel
model_path = "weights/res10_300x300_ssd_iter_140000_fp16.caffemodel"
# 加载Caffe模型
model = cv2.dnn.readNetFromCaffe(prototxt_path, model_path)
image_file = "image.jpg"
# 读取所需图像
image = cv2.imread(image_file)
# 获取图像的宽度和高度
h, w = image.shape[:2]
# 高斯模糊核的大小取决于原始图像的宽度和高度
kernel_width = (w // 7) | 1
kernel_height = (h // 7) | 1
# 预处理图像:调整大小并执行平均减法
blob = cv2.dnn.blobFromImage(image, 1.0, (300, 300), (104.0, 177.0, 123.0))
# 将图像输入神经网络
model.setInput(blob)
# 进行推理并得到结果
output = np.squeeze(model.forward())
# output 是一个 numpy 数组,它检测了所有的人脸,让我们迭代这个数组,只模糊我们确信它是人脸的部分:
for i in range(0, output.shape[0]):
confidence = output[i, 2]
# get the confidence
# 如果置信度高于40%,则模糊边界框(面)
if confidence > 0.4:
# 得到周围的盒子cordinate和升级到原来的形象
box = output[i, 3:7] * np.array([w, h, w, h])
# 转换为整数
start_x, start_y, end_x, end_y = box.astype(np.int)
# 获取人脸图像
face = image[start_y: end_y, start_x: end_x]
# 对这张脸应用高斯模糊
face = cv2.GaussianBlur(face, (kernel_width, kernel_height), 0)
# 将模糊的人脸放入原始图像中
image[start_y: end_y, start_x: end_x] = face
cv2.imshow("image", image)
cv2.waitKey(0)
cv2.imwrite("image_blurred.jpg", image)
在这里,我们不像之前在人脸检测教程中我们为每个检测到的人脸绘制边界框。相反,我们在这里获取框坐标并对其应用高斯模糊。
代码解析
-
cv2.GaussianBlur()方法使用高斯滤波器模糊图像,将中值应用于内核大小内的中心像素。它接受输入图像作为第一个参数,高斯核大小作为第二个参数中的元组,sigma 参数作为第三个参数。
-
我们从原始图像计算了高斯核大小,它必须是奇数和正整数,我将原始图像除以7,因此它取决于图像形状,并执行按位或以确保结果值是奇数,当然可以自己设置内核大小,越大越模糊。


下面结合摄像头模糊我这张的丑脸,具体代码如下所示。
import cv2
import numpy as np
import time
# https://raw.githubusercontent.com/opencv/opencv/master/samples/dnn/face_detector/deploy.prototxt
prototxt_path = "weights/deploy.prototxt.txt"
# https://raw.githubusercontent.com/opencv/opencv_3rdparty/dnn_samples_face_detector_20180205_fp16/res10_300x300_ssd_iter_140000_fp16.caffemodel
model_path = "weights/res10_300x300_ssd_iter_140000_fp16.caffemodel"
model = cv2.dnn.readNetFromCaffe(prototxt_path, model_path)
cap = cv2.VideoCapture(0)
while True:
start = time.time()
_, image = cap.read()
h, w = image.shape[:2]
# 高斯模糊核的大小取决于原始图像的宽度和高度
kernel_width = (w // 7) | 1
kernel_height = (h // 7) | 1
# 预处理图像:调整大小并执行平均减法
blob = cv2.dnn.blobFromImage(image, 1.0, (300, 300), (104.0, 177.0, 123.0))
# 将图像输入神经网络
model.setInput(blob)
# 进行推理并得到结果
output = np.squeeze(model.forward())
# output 是一个 numpy 数组,它检测了所有的人脸,让我们迭代这个数组,只模糊我们确信它是人脸的部分:
for i in range(0, output.shape[0]):
confidence = output[i, 2]
# get the confidence
# 如果置信度高于40%,则模糊边界框(面)
if confidence > 0.4:
# 得到周围的盒子cordinate和升级到原来的形象
box = output[i, 3:7] * np.array([w, h, w, h])
# 转换为整数
start_x, start_y, end_x, end_y = box.astype(np.int)
# 获取人脸图像
face = image[start_y: end_y, start_x: end_x]
# 对这张脸应用高斯模糊
face = cv2.GaussianBlur(face, (kernel_width, kernel_height), 0)
# 将模糊的人脸放入原始图像中
image[start_y: end_y, start_x: end_x] = face
cv2.imshow("image", image)
if cv2.waitKey(1) == ord("q"):
break
time_elapsed = time.time() - start
fps = 1 / time_elapsed
print("FPS:", fps)
cv2.destroyAllWindows()
cap.release()

当然,在Opencv也支持视频的传输,下面代码是实现读视频的人脸的模糊,具体如下所示。
import cv2
import numpy as np
import time
import sys
# https://raw.githubusercontent.com/opencv/opencv/master/samples/dnn/face_detector/deploy.prototxt
prototxt_path = "weights/deploy.prototxt.txt"
# https://raw.githubusercontent.com/opencv/opencv_3rdparty/dnn_samples_face_detector_20180205_fp16/res10_300x300_ssd_iter_140000_fp16.caffemodel
model_path = "weights/res10_300x300_ssd_iter_140000_fp16.caffemodel"
model = cv2.dnn.readNetFromCaffe(prototxt_path, model_path)
video_file = "长的丑就是罪.mp4"
# 从视频捕获帧
cap = cv2.VideoCapture(video_file)
fourcc = cv2.VideoWriter_fourcc(*"XVID")
_, image = cap.read()
print(image.shape)
out = cv2.VideoWriter("output.avi", fourcc, 20.0, (image.shape[1], image.shape[0]))
while True:
start = time.time()
captured, image = cap.read()
if not captured:
break
h, w = image.shape[:2]
kernel_width = (w // 7) | 1
kernel_height = (h // 7) | 1
# 预处理图像:调整大小并执行平均减法
blob = cv2.dnn.blobFromImage(image, 1.0, (300, 300), (104.0, 177.0, 123.0))
# 将图像输入神经网络
model.setInput(blob)
# 进行推理并得到结果
output = np.squeeze(model.forward())
# output 是一个 numpy 数组,它检测了所有的人脸,让我们迭代这个数组,只模糊我们确信它是人脸的部分:
for i in range(0, output.shape[0]):
confidence = output[i, 2]
# get the confidence
# 如果置信度高于40%,则模糊边界框(面)
if confidence > 0.4:
# 得到周围的盒子cordinate和升级到原来的形象
box = output[i, 3:7] * np.array([w, h, w, h])
# 转换为整数
start_x, start_y, end_x, end_y = box.astype(np.int)
# 获取人脸图像
face = image[start_y: end_y, start_x: end_x]
# 对这张脸应用高斯模糊
face = cv2.GaussianBlur(face, (kernel_width, kernel_height), 0)
# 将模糊的人脸放入原始图像中
image[start_y: end_y, start_x: end_x] = face
cv2.imshow("image", image)
if cv2.waitKey(1) == ord("q"):
break
time_elapsed = time.time() - start
fps = 1 / time_elapsed
print("FPS:", fps)
out.write(image)
cv2.destroyAllWindows()
cap.release()
out.release()
原视频: