声明:本博客只是简单的爬虫示范,并不涉及任何商业用途。
一.前言
近日有空,博主又开始了新一轮的爬虫实战,这次将魔掌伸向了新浪微博。在今日的热搜榜上有着关于“阿凡达重映首日票房超2200万”话题的一条热搜,于是我便准备以其为目标,爬取该话题下的微博中评论数据。在爬虫的开始前,我发现微博在网上分为几个版本:微博网页端(http://weibo.com)、微博手机端(http://m.weibo.cn)和微博移动端(http://weibo.cn)(来源于Python爬虫之微博评论数据的爬取(十))。在最开始,我分别对其进行了抓包分析,发现微博手机端的评论数据比较规整,爬取难度也比较适中,这里用其进行练手。
二.抓包分析
本次抓包使用的是Fiddler(下载链接),首先打开要爬取评论的微博链接,可以看到下图所示的界面:
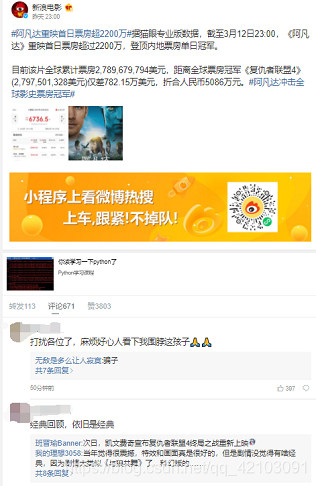
其评论数据发现是要拖动滑动条才会出现新的评论数据,于是我便打开了Fiddler,然后拖动了几次滑动条,发现在Fiddler的界面中出现了包含评论的json数据:
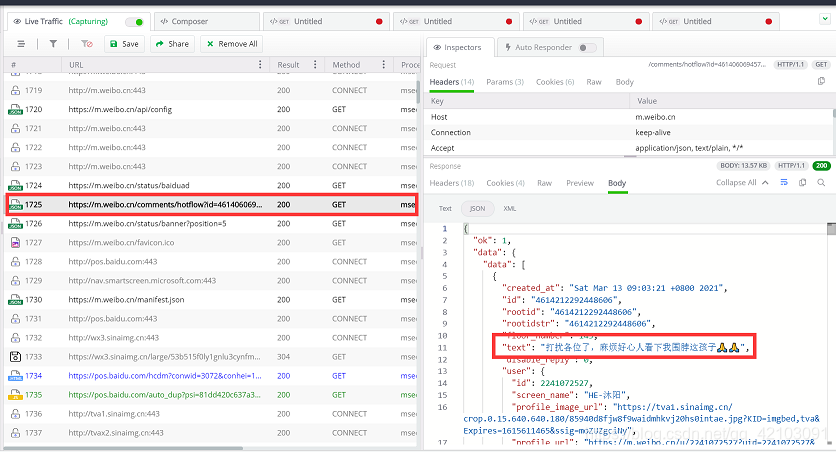
其所对应的链接如下:
https://m.weibo.cn/comments/hotflow?id=4614060694573362&mid=4614060694573362&max_id_type=0
https://m.weibo.cn/comments/hotflow?id=4614060694573362&mid=4614060694573362&max_id=141324114725178&max_id_type=0
https://m.weibo.cn/comments/hotflow?id=4614060694573362&mid=4614060694573362&max_id=139125100631186&max_id_type=0
- 1
- 2
- 3
可以发现:id和mid字段即为待爬取微博的链接中的detail/后的字段(链接:https://m.weibo.cn/detail/4614060694573362),max_id为一个分页参数,可以在json文件的末尾中找到,例如:
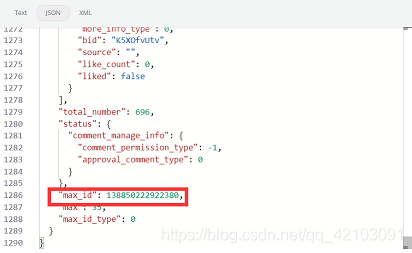
另外,我在爬虫的过程中发现max_id_type字段并不会一直为0,当爬取到一定的页数后必须该字段改为1才能继续获取到包含评论的json数据。
综上,我们可以获取构造链接的方法:即从当前爬取的json数据的末尾获取max_id字段,然后用于构造新的链接去获取新的评论数据,但获取失败后,将max_id_type的值改为1继续进行评论数据的获取。
三.爬虫过程
3.1 获取Headers参数
在Fiddler界面点击该链接,可以在右侧获取到该请求所需要的参数,示例如下:
headers = { "Host": "m.weibo.cn", "Connection": "keep-alive", "Accept": "application/json, text/plain, */*", "MWeibo-Pwa": "1", "X-XSRF-TOKEN": "f950a4", "X-Requested-With": "XMLHttpRequest", "User-Agent": ua.chrome, "Sec-Fetch-Site": "same-origin", "Sec-Fetch-Mode": "cors", "Sec-Fetch-Dest": "empty", "Referer": "https://m.weibo.cn/detail/4614060694573362", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6", "Cookie": "略"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
上述headers即为requests.get()方法中的headers参数(需要自己抓包获取一下)。
3.2 json数据解析
解析需要使用到json模块,首先利用json.loads()函数加载文本为python字典,然后利用key获取对应的value,获取的时候建议使用dict.get(key)方法,否则可以会因此不存在键而报错。
3.3 数据保存
影评数据通过Pandas模块保存为csv文件,其中包含5列数据分别为:
- user_na:用户名;
- user_c:用户评论内容;
- t:评论时间;
3.4 注意事项
虽然获取json数据的链接经过抓包分析后了解了一部分构造原理,但是新浪微博的反扒措施还是使得一次爬取的数据量不大,倘若有知道如何解决的欢迎在评论区告知一下,目前要想获取更多的数据,只能在不同的时间段进行爬取。
四.爬虫部分代码及可视化展示
4.1 爬虫主程序代码
import json
import time
import requests
from fake_useragent import UserAgent
import pandas as pd
import random
from proxy_ip import extractIP
import traceback
import re
import os
requests.packages.urllib3.disable_warnings()
ua = UserAgent()
headers = { "Host": "m.weibo.cn", "Connection": "keep-alive", "Accept": "application/json, text/plain, */*", "MWeibo-Pwa": "1", "X-XSRF-TOKEN": "da898d", "X-Requested-With": "XMLHttpRequest", "User-Agent": ua.chrome, "Sec-Fetch-Site": "same-origin", "Sec-Fetch-Mode": "cors", "Sec-Fetch-Dest": "empty", "Referer": "https://m.weibo.cn/detail/4614060694573362", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6", "Cookie": "换上自己登陆微博的cookie"
}
def parse(text): """ 功能:解析json数据 text:待解析的文本内容 """ comments,max_id = [],None js_data = json.loads(text) datas = js_data.get('data') if datas: contents = datas.get('data') # 获取json末尾的max_id max_id = datas.get('max_id') for content in contents: # 获取用户名 user_na = content.get('user').get('screen_name') # 获取评论内容 user_c = content.get('text') # 筛选掉评论内容中的部分html代码 if '<span' in user_c: user_c = re.search('(.?)<span .*',user_c).group(1) # 去掉评论中的空格 user_c = user_c.replace(' ','') # 获取评论时间 t = content.get('created_at') print(user_na,user_c,t) comments.append([user_na,user_c,t]) return comments,max_id
def Spider(comment_counts,weibo_id,IPs=None): """ 爬虫主程序 wb_id待爬取的微博的id comment_counts:评论数 IPs:代理IP列表 """ clist,max_id = [],None # 获取需要爬取的页数 lengh = comment_counts // 20 session = requests.Session() # max_id_type的值 flag = 0 fail_nums = 0 for i in range(1,lengh + 1): # 10次获取json数据失败则退出爬虫程序 if fail_nums >= 10:break try: if i == 1: # 首个json评论数据没有max_id字段 url = "https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id_type=0".format(weibo_id,weibo_id) else: url = "https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id={}&max_id_type={}".format(weibo_id,weibo_id,max_id,flag) time.sleep(3.5) print("clawing {}st pages:{}".format(i,url)) if IPs is not None: index = random.randint(0,len(IPs) - 1) proxies = {"http":"{}:8080".format(IPs[index])} response = session.get(url=url,headers=headers,proxies=proxies,verify=False) else: response = session.get(url=url,headers=headers,verify=False) comments,cur_id = parse(response.text) if cur_id == None: flag = 1 fail_nums += 1 else: flag = 0 max_id = cur_id clist += comments except Exception: print("clawing {}st page failed".format(i)) traceback.print_exc() session.close() Saver(clist,'comments.csv')
def Saver(clist,file_name): """ 功能:保存评论为csv文件 clist:获取的数据 append:是否为追加文件到原有的文件中去 """ datas = pd.DataFrame(clist,columns=["user_na","user_c","t"]) file_path = "datas/{}".format(file_name) if os.path.exists(file_path): datas.to_csv(file_path,index=False,header=False,mode="a") else: datas.to_csv(file_path,index=False)
if __name__ == "__main__": # 微博列表,内容为id:评论条数 weibo_list = { '4614060694573362':900, '4614186683074288':700, '4614208131958609':1500 } # 抓取代理IP IPs = extractIP() print(IPs) if IPs == []:IPs = None # 爬取微博列表中的微博所对应的评论 for weibo_id,comment_counts in weibo_list.items(): Spider(comment_counts,weibo_id,IPs=IPs)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
爬虫程序的运行过程如下:

最终三条微博经过两次爬取加去重后还剩下1000多条评论数据。
4.2 可视化分析
对于词云图的绘制,先需要利用jieba分词来对影评内容进行分词,然后利用wordcloud模块来进行词云图的绘制,下面是评论的词云图:

五.结语
完整项目Github地址(求star):weibo_comment
以上便是本文的全部内容,要是觉得不错的话就点个赞或关注一下博主吧,你们的支持是博主继续创作的不解动力,当然若是有任何问题也敬请批评指正!!!
文章来源: blog.csdn.net,作者:斯曦巍峨,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_42103091/article/details/114745856