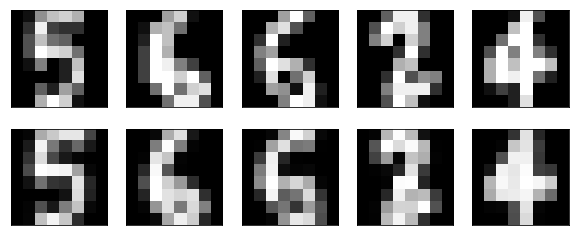@Author:Runsen
-
本文博客目标:了解自动编码器的基本知识
-
参考文献
我们将探索一种称为 Autoencoders 的无监督学习神经网络。
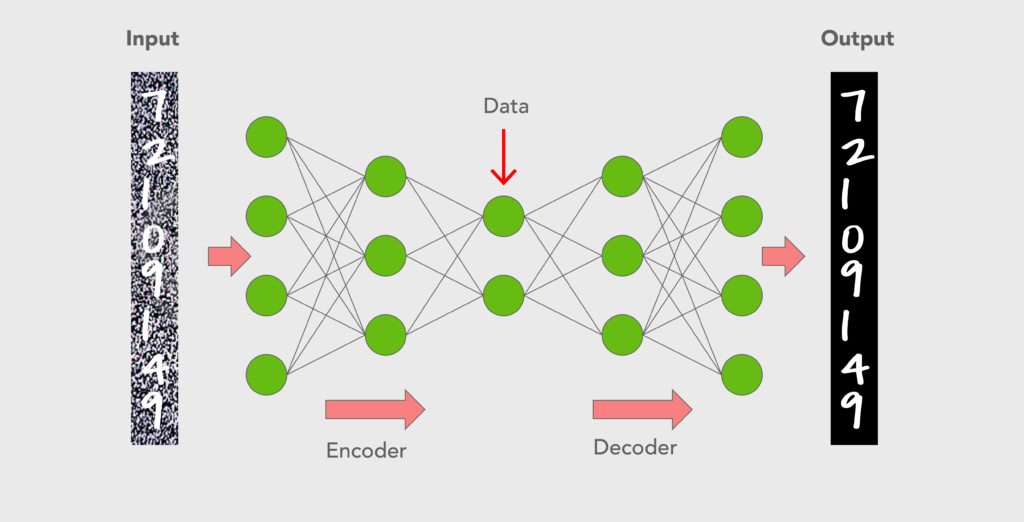
因此,自编码器是用于在输出层重现输入的深层神经网络,即输出层中的神经元数量与输入层中的神经元数量完全相同
自动编码器
- 一种无监督神经网络结构,用于获得压缩编码
- 主要用于降维、生成模型、去噪等。
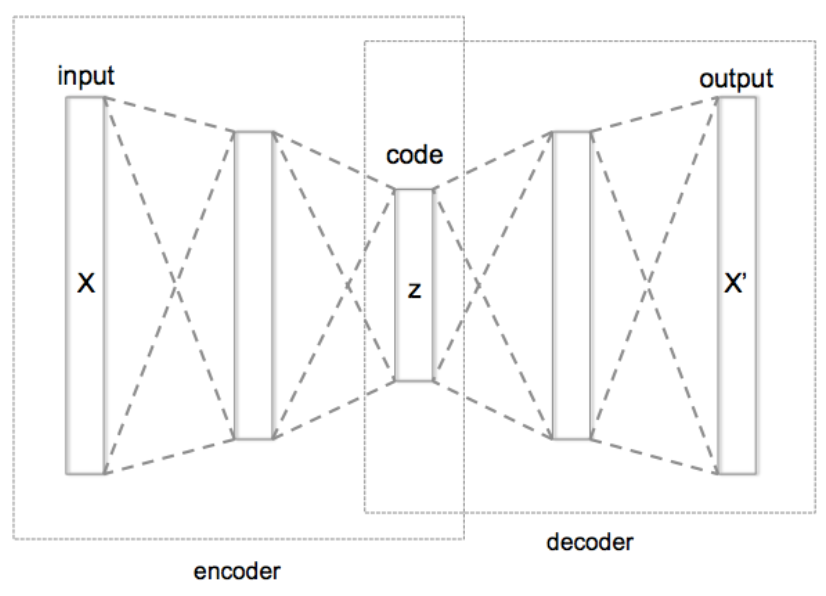
- 自动编码器的两个主要部件;encoder and decoder
- encoder编码器将输入压缩成一小组“代码”(通常,编码器输出的维数远小于编码器输入)
- 然后decoder解码器将编码器输出扩展为与编码器输入具有相同维数的输出
- 换句话说,autoencoder的目标是在学习数据的有限表示(即“代码”)的同时“重建”输入
自编码器有两部分,即编码器和解码器。

编码器压缩输入数据,解码器进行相反的操作以生成数据的未压缩版本,以尽可能准确地重建输入。
我们将使用 kears 创建一个自动编码器神经网络并在Digits 数据集上进行测试。
Load dataset
- Digits dataset in sklearn
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import normalize
from sklearn import datasets
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
from keras.layers import Input, Dense
from keras.models import Model
data = datasets.load_digits()
X_data = data.images
y_data = data.target
X_data = X_data.reshape(X_data.shape[0], 64)
# fit in data instances into interval [0,1]
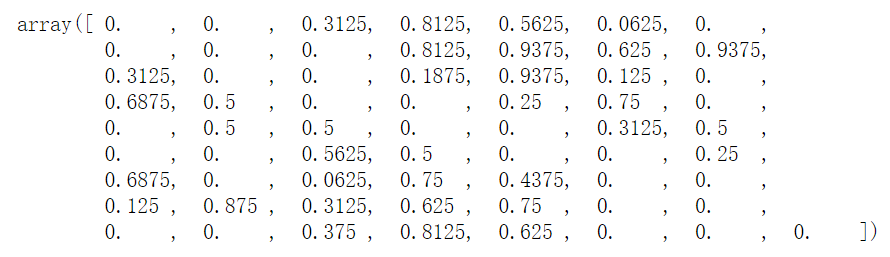
X_data = X_data / 16.
X_data[0]
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size = 0.3, random_state = 777)
简易自动编码器
- 只有一个隐藏层的简单自动编码器
- 因此,编码器和解码器都由两层组成
# define coding dimension
code_dim = 6
inputs = Input(shape = (X_train.shape[1],), name = 'input') # input layer
code = Dense(code_dim, activation = 'relu', name = 'code')(inputs) # hidden layer => represents "codes"
outputs = Dense(X_train.shape[1], activation = 'softmax', name = 'output')(code) # output layer
auto_encoder = Model(inputs = inputs, outputs = outputs)
auto_encoder.summary()

SVG(model_to_dot(auto_encoder).create(prog='dot', format='svg'))
encoder = Model(inputs = inputs, outputs = code)
decoder_input = Input(shape = (code_dim,))
decoder_output = auto_encoder.layers[-1]
decoder = Model(inputs = decoder_input, outputs = decoder_output(decoder_input))
auto_encoder.compile(optimizer='adam', loss='binary_crossentropy')
训练模型
- 请注意,特性和目标是相同的(即,X_train)
%%time
auto_encoder.fit(X_train, X_train, epochs = 1000, batch_size = 50, validation_data = (X_test, X_test), verbose = 0)
Wall time: 1min 28s
encoded = encoder.predict(X_test)
decoded = decoder.predict(encoded)
plt.figure(figsize = (10,4))
n = 5
for i in range(n):
# 可视化测试数据实例
ax = plt.subplot(2, n, i+1)
plt.imshow(X_test[i].reshape(8,8))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 可视化编码解码测试数据实例
ax = plt.subplot(2, n, i+n+1)
plt.imshow(decoded[i].reshape(8,8))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
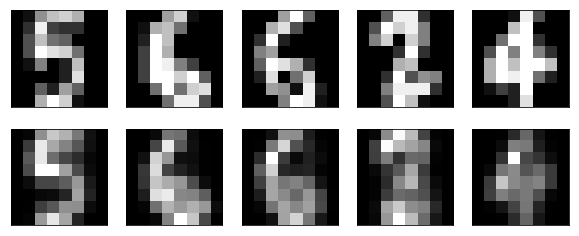
深度自动编码器
- 自动编码器可以由几层组成,即深层自动编码器
def encoder_decoder(code_dim = 10):
inputs = Input(shape = (X_train.shape[1],))
code = Dense(50, activation= 'relu')(inputs)
code = Dense(50, activation = 'relu')(code)
code = Dense(code_dim, activation = 'relu')(code)
outputs = Dense(50, activation = 'relu')(code)
outputs = Dense(50, activation = 'relu')(outputs)
outputs = Dense(X_train.shape[1], activation = 'sigmoid')(outputs)
auto_encoder = Model(inputs = inputs, outputs = outputs)
auto_encoder.compile(optimizer = 'adam', loss = 'binary_crossentropy')
return auto_encoder
auto_encoder = encoder_decoder()
auto_encoder.fit(X_train, X_train, epochs = 1000, batch_size = 50, validation_data = (X_test, X_test), verbose = 0)
decoded = auto_encoder.predict(X_test)
plt.figure(figsize = (10,4))
n = 5
for i in range(n):
# visualizing test data instances
ax = plt.subplot(2, n, i+1)
plt.imshow(X_test[i].reshape(8,8))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# visualizing encode-decoded test data instances
ax = plt.subplot(2, n, i+n+1)
plt.imshow(decoded[i].reshape(8,8))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()