推荐一款非常好用的kafka管理平台,kafka的灵魂伴侣
滴滴开源LogiKM一站式Kafka监控与管控平台
这篇文章源自于,一位群友的问题,然后就写下了这篇文章

先定义一下名词: 迁移前的Broker: OriginBroker 、 迁移后的副本 TargetBroker
前提
在这之前如果你比较了解 分区重分配的原理 的话,下面的可能更好理解;
推荐你阅读一下下面几篇文章(如果你点不进去说明我还没有发布)
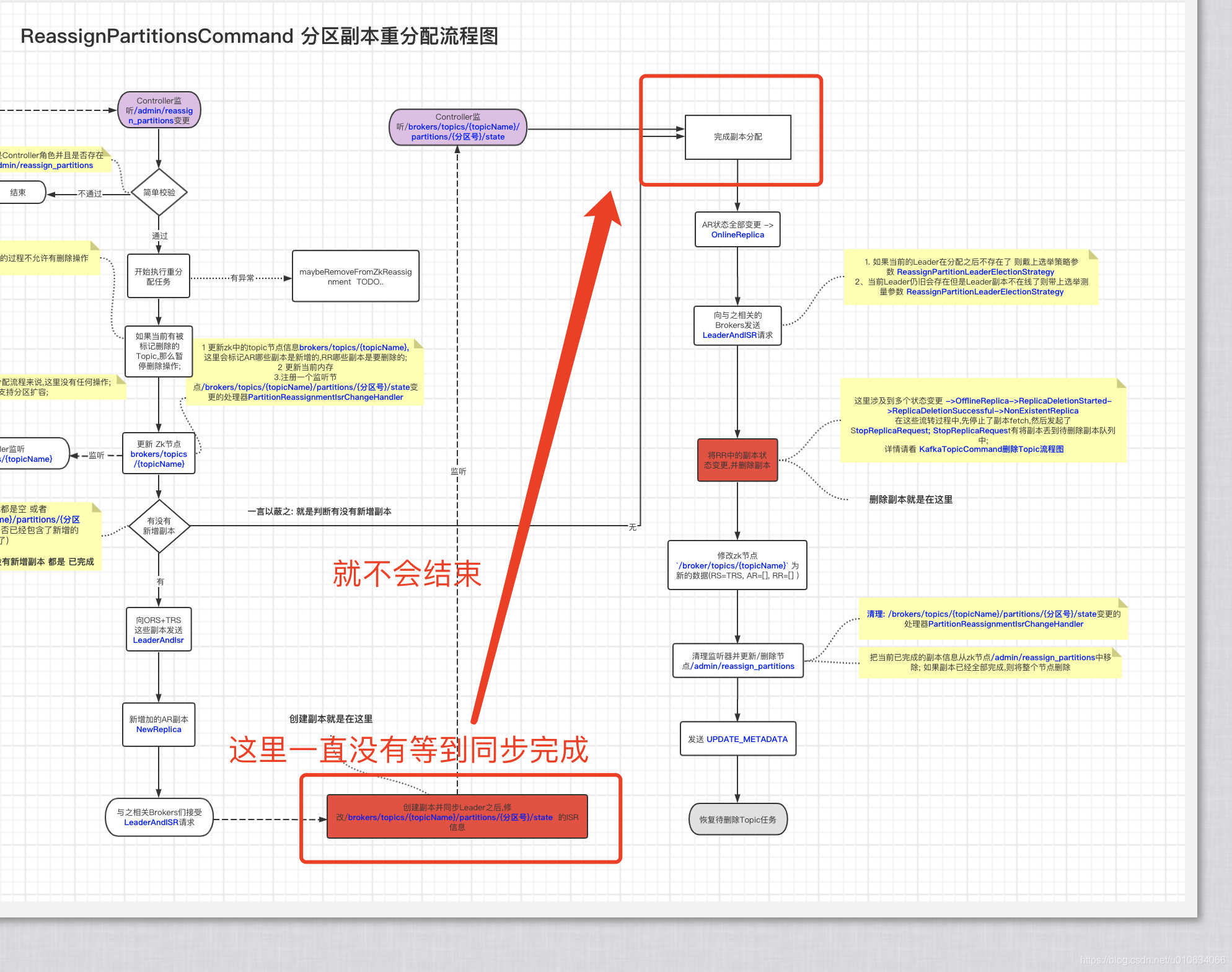
【kafka源码】ReassignPartitionsCommand源码分析(副本扩缩、数据迁移、副本重分配、副本跨路径迁移)
【kafka运维】副本扩缩容、数据迁移、副本重分配、副本跨路径迁移
Kafka的灵魂伴侣Logi-KafkaManger(4)之运维管控–集群运维(数据迁移和集群在线升级)
如果你不想费那个精力,那直接看下面我画的这张图,你自己也能分析出来可能出现的问题;以及怎么排查

所有异常情况
1. TargetBroker若不在线,迁移脚本执行会失败
TargetBroker若不在线, 在开始执行任务脚本的时候,校验都不会被通过呢
情景演示
| BrokerId | 角色 | 状态 | 副本 |
|---|---|---|---|
| 0 | 普通Broker | 正常 | test-0 |
| 1 | 普通Broker | 宕机 | 无 |
现在将分区topic-test-0 从Broker0 迁移到 Broker1
sh bin/kafka-reassign-partitions.sh --zookeeper xxxxxx:2181/kafka3 --reassignment-json-file config/reassignment-json-file.json --execute --throttle 1000000
执行异常
Partitions reassignment failed due to The proposed assignment contains non-existent brokerIDs: 1
kafka.common.AdminCommandFailedException: The proposed assignment contains non-existent brokerIDs: 1
at kafka.admin.ReassignPartitionsCommand$.parseAndValidate(ReassignPartitionsCommand.scala:348)
at kafka.admin.ReassignPartitionsCommand$.executeAssignment(ReassignPartitionsCommand.scala:209)
at kafka.admin.ReassignPartitionsCommand$.executeAssignment(ReassignPartitionsCommand.scala:205)
at kafka.admin.ReassignPartitionsCommand$.main(ReassignPartitionsCommand.scala:65)
at kafka.admin.ReassignPartitionsCommand.main(ReassignPartitionsCommand.scala)
2. TargetBroker在开始迁移过程中宕机,导致迁移任务一直在进行中
一般这种情况是出现在, 写入了节点
/admin/reassign_partitions/之后, 有一台/N台targetBroker中途宕机了, 导致这台Broker不能正常的创建新的副本和同步Leader操作,就不能够继续往后面走了
情景演示
模拟这种情况,我们可以手动写入了节点/admin/reassign_partitions/重分配信息例如:

- 创建一个节点写入的信息如下, 其中Broker-1 不在线; 模拟在分配过程中宕机了;
{"version":1,"partitions":[{"topic":"test","partition":0,"replicas":[1]}]}
- 看到
/broker/topics/{topicName}中的节点已经变更为下面的了
- 接下来应该要像Broker-1发送
LeaderAndIsr请求让它创建副本并且同步Leader;但是这个时候Broker-1是不在线的状态;所以就会导致 这个任务一直在进行中, 如果你想进行其他的重分配就会提示如下There is an existing assignment running.
解决方法
只要知道什么情况,那解决问题思路就很清晰了, 只要把挂掉的Broker重启就行了;
3. 被迁移副本没有找到Leader,导致TargetReplica一直不能同步副本
只要被迁移的副本的Leader服务挂了,并且还没有选举出新的Leader, 那么就没地方同步了
这种情况跟 情况2类似,但也有不同, 不同在于 这里可能是其他的Broker挂了导致的
情景演示
| BrokerId | 角色 | 状态 | 副本 |
|---|---|---|---|
| 0 | 普通Broker | 正常 | 无 |
| 1 | 普通Broker | 宕机 | test-0 |
现在将分区test-0 从Broker1 迁移到 Broker0
{"version":1,"partitions":[{"topic":"test","partition":0,"replicas":[0],"log_dirs":["any"]}]}
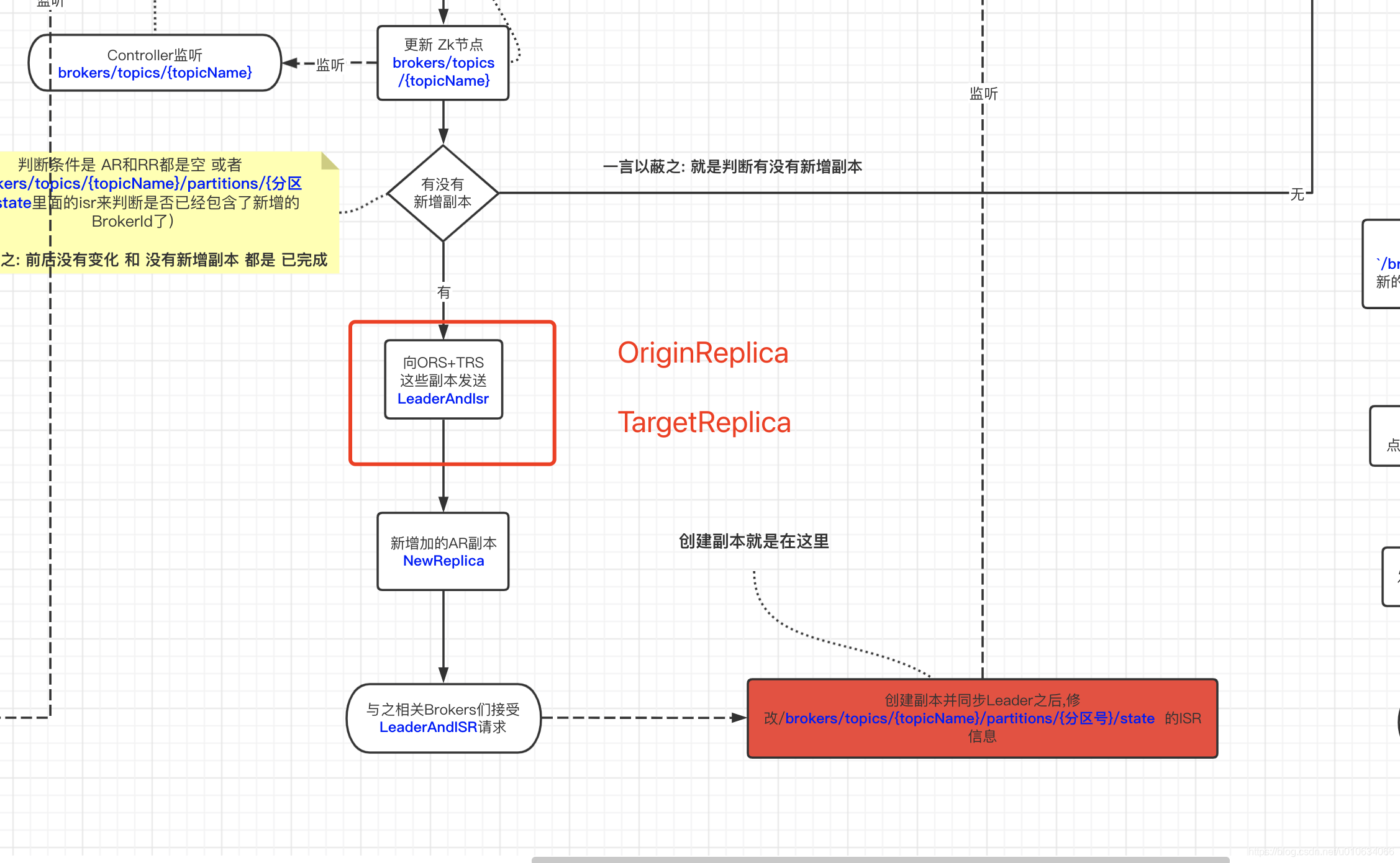
看上面的图, TargetReplica会收到LeaderAndIsr 然后开始创建副本,并且zk中也写入了TargetBroker的AR信息;
然后开始去同步Leader的副本信息,这个时候Leader是谁? 是Broker-1上的test-0;(只有一个副本),然后准备去同步的时候,OriginBroker不在线,就同步不了,所以TargetReplica只是创建了副本,但是还没有同步数据;如下
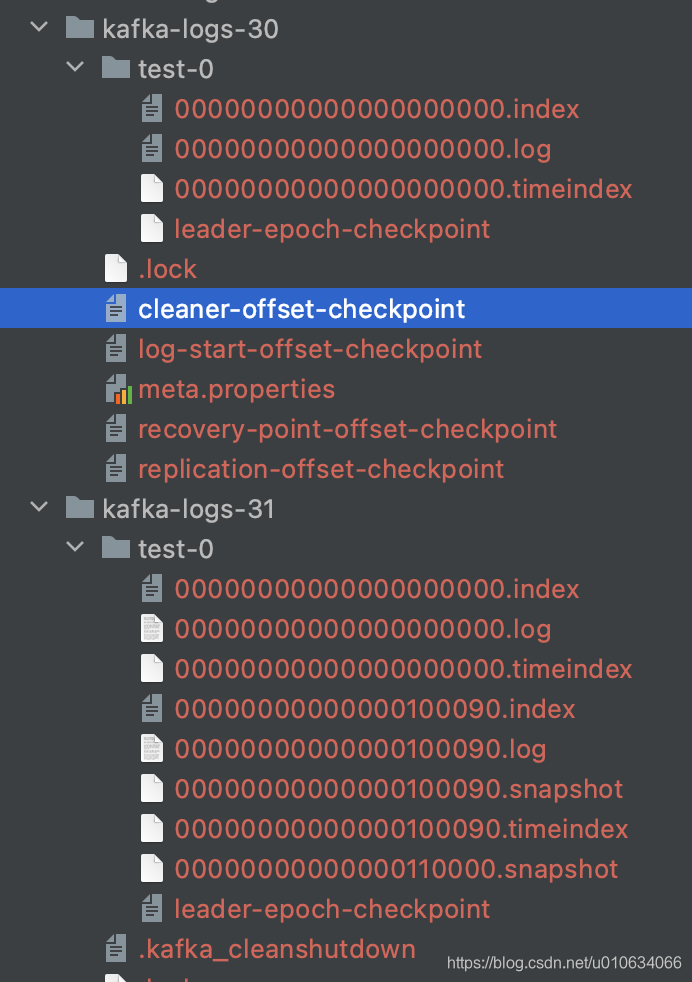
TargetReplica被创建,但是没有数据; 又因为OriginBroker不在线,所以也没有被删除副本(下图kafka-logs-30 是Broker0;kafka-logs-31是Broker1)
- 因为整个分区重分配任务没有完成,所以
/admin/reassign_partitions/还未删除
{“version”:1,“partitions”:[{“topic”:“test”,“partition”:0,“replicas”:[0]}]}

- /broker/topics/{topicName} 中的节点会更新为下图, 其中
ARRR都还没有被清空

brokers/topics/test/partitions/0/state节点 看Leader为-1,并且ISR中也没有加入TargetBroker

只要是没有同步成功,那么整个分区流程就会一直进行中;
解决方案
一般出现这种情况还是少见的,基本上单副本才会出现这种情况
一般就算OriginBroker挂了,导致一个副本下线了,那么其他的副本会承担起Leader的角色
如果只有一个副本,那么就会造成这种异常情况了,这个时候只需要把OriginBroker重启一下就行了
4. 限流导致重分配一直完成不了
我们一般在做分区副本重分配任务的时候,一般都会加上一个限流值
--throttle: 迁移过程Broker之间传输的速率,单位 bytes/sec
注意这个值是Broker之间的限流, 并不仅仅指的是这次迁移的几个分区副本的限流;而是包含其他Topic自身正常的数据同步的流量; 所以如果你这个限流值设置的很小, 速率比正常情况下的同步速率还要小
又或者你的同步速率比创建消息的速率都要慢, 那么这个任务是永远完不成的!
情景演示
- 创建重分配任务, 限流值 1
sh bin/kafka-reassign-partitions.sh --zookeeper xxxx:2181/kafka3 --reassignment-json-file config/reassignment-json-file.json --execute --throttle 1 - 基本上这个速率是别想完成了,
admin/reassign_partitions节点一直在 - zk中的限流配置

解决方案
将限流阈值设置大一点,重新执行一下上面的脚本,限流值加大
sh bin/kafka-reassign-partitions.sh --zookeeper xxxx:2181/kafka3 --reassignment-json-file config/reassignment-json-file.json --execute --throttle 100000000
(虽然这里执行之后还是会提醒你有任务在进行中,但是会重写限流信息的)
千万记得 任务结束要用 --verify来把限流值移除掉! 不然他会一直存在的;
5. 数据量太大,同步的贼慢
出现这个情况是很常见的一个事情,它也不属于异常, 性能问题你没办法,但是往往我们做数据迁移的时候会忽略一个问题; 那就是过期数据太多,迁移这个过期数据本身就没有什么意义;
可以看我之前的文章 Kafka的灵魂伴侣Logi-KafkaManger(4)之运维管控–集群运维(数据迁移和集群在线升级)
减少迁移的有效数据,能够大大增加数据迁移的效率;

解决方案
减少迁移的数据量
如果要迁移的Topic 有大量数据(Topic 默认保留7天的数据),可以在迁移之前临时动态地调整retention.ms 来减少数据量;
当然手动的来做这个操作真的是太让你烦心了, 你可以有更聪明的选择
Kafka的灵魂伴侣Logi-KafkaManger(4)之运维管控–集群运维(数据迁移和集群在线升级)
可视化的进行数据迁移、分区副本重分配;
设置限流、减小数据迁移量、迁移完成自动清理限流信息
排查问题思路
上面我把我能想到的所有可能出现的问题解决方案都列举了出来; 那么碰到了
重分配任务一直在进行中怎么快速定位和解决呢?There is an existing assignment running.
1. 先看/admin/reassign_partitions里面的数据
假设一次任务如下; 有两个分区 test-0分区分在Broker[0,1] test-1分区在Broker[0,2]
{"version":1,"partitions":[{"topic":"test","partition":0,"replicas":[0,1]},
{"topic":"test","partition":1,"replicas":[0,2]}]}
恰好图中Broker1宕机了,test-0就不能完成了,test-1则正常完成; 那么这个时候/admin/reassign_partitions节点就是
{"version":1,"partitions":[{"topic":"test","partition":0,"replicas":[0,1]}]}
所以我们先看节点的数据,能够让我们指定 是哪个分区重分区出现了问题 ;
从上面数据可以指定, test-0 这个分区没有完成,对应的Broker有 [0,1]
2. 再看brokers/topics/{TopicName}/partitions/{分区号}/state数据
通过步骤1 我知道 test-0 有问题,我就直接看节点/brokers/topics/test/partitions/0/state得到数据
这里分两种情况看
-
如下
{"controller_epoch":28,"leader":0,"version":1,"leader_epoch":2,"isr":[0]}可以发现 ISR:[0], 只有0 ; 正常来说应该是我上面设置的[0,1]; 那问题就定位在 Broker-1中的副本没有加入到ISR中;
接下来的问题就是排查为啥Broker-1 没有加入到ISR了; -
如下, leader:-1 的情况
{"controller_epoch":28,"leader":-1,"version":1,"leader_epoch":2,"isr":[0]}leader:-1 表示当前没有Leader; 新增的副本没有地方去同步数据,就很迷茫;
所以接下来要排查的就是其该TopicPartition的其他副本所在Broker是不是都宕机了; 如何确定其他Broker?
看AR是否都正常;AR数据在brokers/topics/{topicName}可以看到 ;当然你可以通过 滴滴开源-LogIKM 一站式Kafka监控与管控平台 更简单的去排查这个步骤;如下
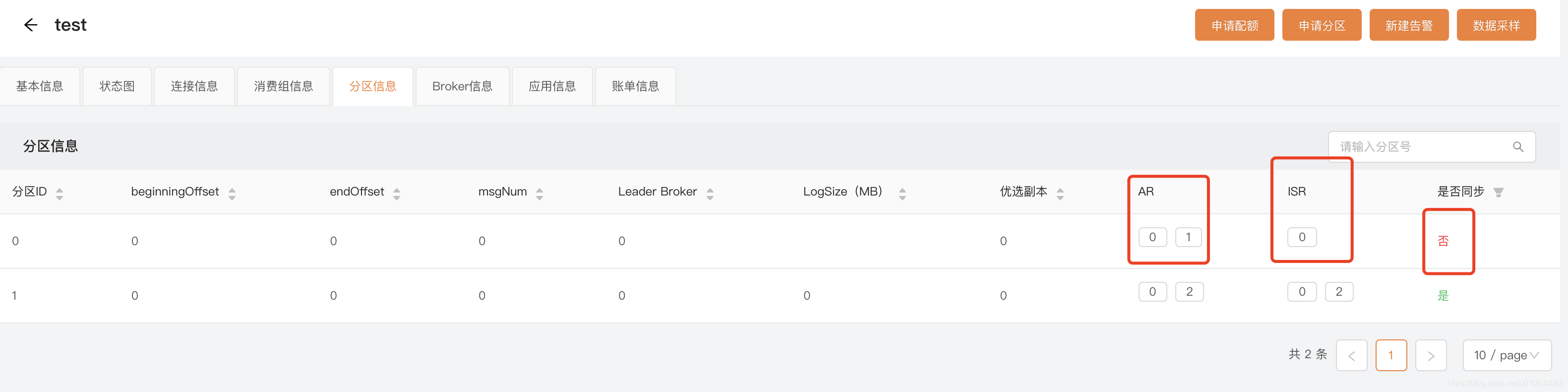
3. 根据步骤2确定对应的Broker是否异常
如果找到有Broker异常,直接重启就完事了;
4.查询限流大小
如果步骤3还没有解决问题,也没有Broker异常,那么再判断一下流量限制的问题了
-
首先看看节点
/config/brokers/{brokerId}是否配置了限流信息;

-
还有节点
/config/topics/{topicName}的信息

-
并且看到Broker节点也没有加入到ISR, 那么妥妥的同步速率问题了

-
如果查询到的限流值比较小的话,可以适当的调大一点
sh bin/kafka-reassign-partitions.sh --zookeeper xxxx:2181/kafka3 --reassignment-json-file config/reassignment-json-file.json --execute --throttle 100000000
5. 重新执行重分配任务(停止之前的任务)
如果上面还是没有解决问题,那么可能是你副本数据量太大,迁移的数据太多, 或者你TargetBroker网络情况不好等等,网络传输已经达到上限,这属于性能瓶颈的问题了,或许你该考虑一下 是不是重新分配一下;或者找个夜深人静的晚上做重分配的操作;
情景演示
-
test-0 分区 原本只在Broker [0]中, 现在重分配到 [0,1], 用
--throttle 1模拟一下网络传输速率慢, 性能瓶颈等


这个节点一直会存在,一直在进行中,
adding_replicas也一直显示[1] -
同时可以看到 Broker-1 是存活的

-
但是不在ISR里面的

-
判断出来 可能同步速率更不上, TargetBroker可能网络状况不好,或者本身压力也挺大; 换个TargetBroker
-
直接删除节点
/admin/reassign_partitions,然后重新执行一下重分配任务; 重分配到[0,2]中{"version":1,"partitions":[{"topic":"test","partition":0,"replicas":[0,2]}]}
可以看到已经在zk中写入了新的分配情况;
但是topic节点中却没有变更AR和ARS

这是因为Controller虽然收到了节点的新增通知/admin/reassign_partitions; 但是在校验的时候,它内存里面保存过之前的重分配任务,所以对Controller而言,它认为之前的任务还是没有正常结束的,所以也就不会走后门的流程; -
重新选举Controller角色,重新加载
/admin/reassign_partitions; 我在文章【kafka源码】Controller启动过程以及选举流程源码分析里面分析过,Controller重新选举会重新加载/admin/reassign_partitions节点并继续任务的执行; 切换之后如下,变更正常

切换Controller,需要你主动去删除zk节点 /controller
当然还有更简单的方式 滴滴开源LogiKM 一站式Kafka监控与管控平台 如下

指定一些空闲的Broker当做Controller,并立即切换是一个明智的选择;
解决方案
-
数据量太大是因为很多过期数据; 如果你重分配的时候没有考虑清理过期数据; 那么就重新分配把
但是重分配任务同一时间只能有一个,所以你只能暴力删除/admin/reassign_partitions;然后重新分配一下;
注意重新分配的时候,请务必设置临时的数据过期时间,减少迁移数据; 并且还要让Controller切换一下; -
总结起来是
①. 删除节点/admin/reassign_partitions
②. 重新执行重分配任务
③. 让Controller发生重选举
排查工具+思考
分析完上面的问题, 起始这个问题排查起来,还是挺麻烦的,看这个看那个指标什么的;
是不是可以有一个工具来自动帮我 排查问题+提供解决方案;
既然排查思路有了,可视化,自动化,工具化 也不是什么难事吧;
所以我在 滴滴开源LogiKM 一站式Kafka监控与管控平台 上准备提一个ISSUE, 来简单的实现这么一个功能;
看什么时候比较空的时候来完成它,你要是有兴趣,也可以一起来完成它!
现实案例分析
周五快下班的时候, 群里面有个同学问了一句下面这个问题, 然后我就我回复了一下;
后来为了具体分析就拉了一个小群来寻找蛛丝马迹


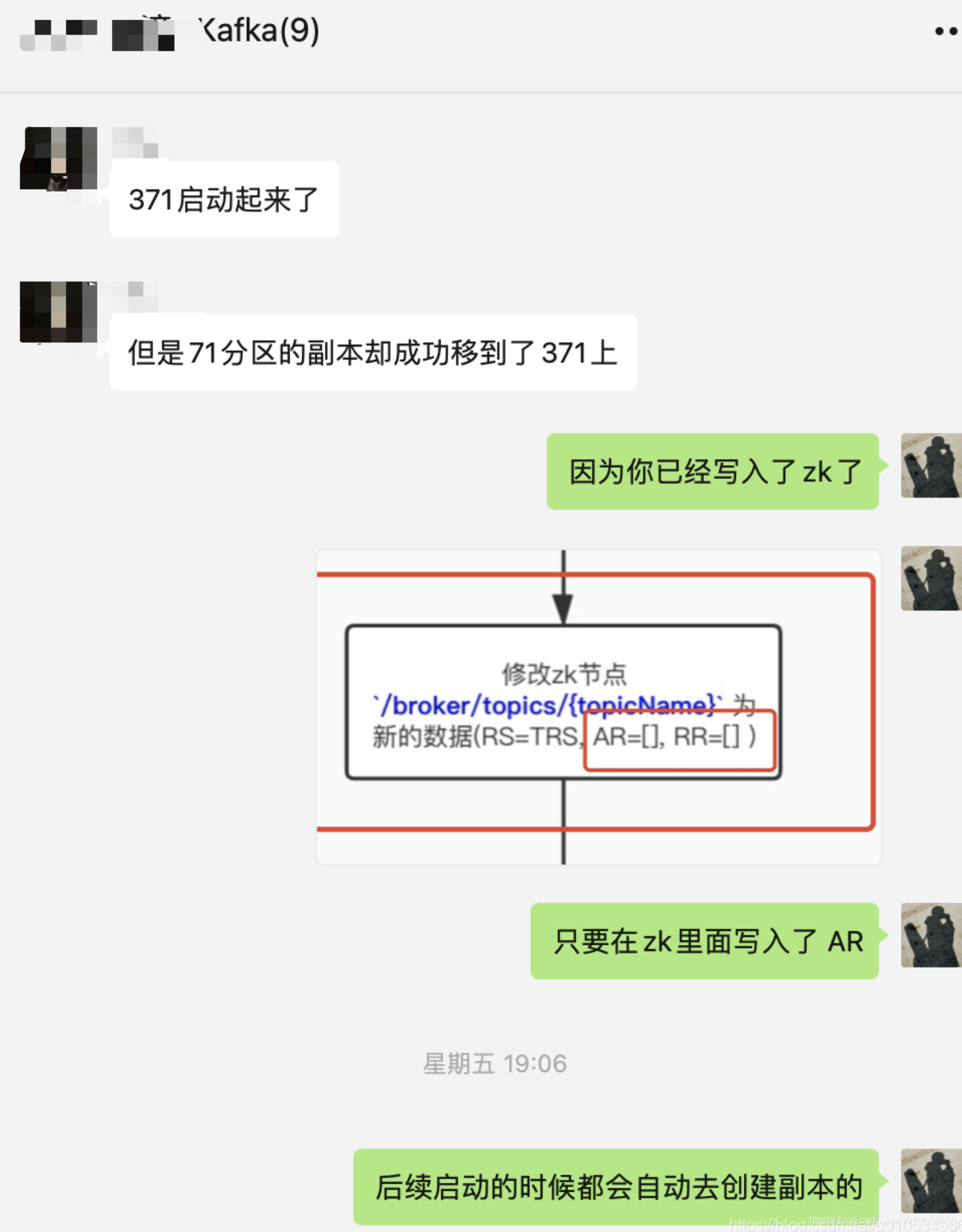
具体的日志我就不贴出来了,太多了;
这位同学在 进行分区重分配的过程中, 持久了很久,一直在进行中, 后来去百度 说让在zk中删除 重分配任务节点;
我告知了节点之后,然后立马删除了这个节点,后来发现某一台迁移的 TargetBroker挂了, 让他们重启之后,重分配的任务仍旧接着进行下去了, 也就是说 TargetBroker 依然正常的完成了副本的分配;
问题分析
其实这个问题就是我们上面分析过的 第二种情况 2. TargetBroker在开始迁移过程中宕机,导致迁移任务一直在进行中
具体为什么TargetBroker为什么会宕机 这不是我们分析的范畴;
因为TargetBroker宕机了,导致任务不能结束; 这个时候只需要重启TargetBroker就可以了;
虽然他们直接暴力删除了节点/admin/reassign_partitions ; 问题也不大;
影响点在下一次开始重分配的任务时候, Controller内存里面还是报错的之前的信息,所以下一次的任务不会被执行;
但是如果你让Controller重新分配之后,那么就会继续执行了,没有什么影响;
虽然他们这次删除了节点, 也里面开始了下一次的分配; 但是因为它重启了 TargetBroker ;让原来的任务顺利的进行了下去; 哪怕没有切换Controller, 也是不会影响下一次的重分配任务的;(因为顺利进行 Controller被通知的之前的已经结束了)
如果你有其他可能出现的异常,或者其他有关于kafka、es、agent等等相关问题,请联系我,我会补充这篇文章
欢迎Star和共建由滴滴开源的kafka的管理平台,非常优秀非常好用的一款kafka管理平台
满足所有开发运维日常需求