BeautifulSoup爬取国家政策网目标话题的10篇文章,以及基于jieba的关键字生成
一:基本步骤
1.首先,写出需要访问的url,涉及到将中文转化为utf8编码,再转化为请求格式(后面有写如何转换)
2.urllib.request.urlopen(url)向浏览器发出请求,并返回一个html页面
3.此时我们用BeautifulSoup库以及页面解析器对返回的html页面进行解析,并找出存储文章链接的格子节点(标签名为div),返回BeautifulSoup对象
4.再通过对新对象解析,并且找出10条标签名为a的节点,将这些节点的herf属性值保存在列表中。
5.最后,通过对列表中的10条url进行访问,将页面内容分别保存至本地文件中。
二:具体实现
1.爬取有关“工资”的10篇文章
1-1:首先,网页请求query一般会将中文转化为类似于utf-8的编码格式,所以代码中我们需要将“工资”转化为目标格式
Python encode() 方法以 encoding 指定的编码格式编码字符串,默认为utf-8,返回的是字节码的形式
str.encode(encoding=‘UTF-8’)

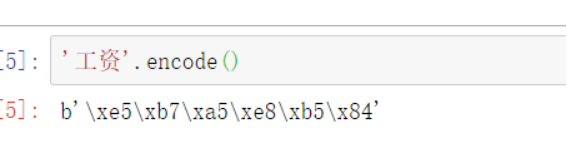
请求中需要把\x替换为%,所以要先转化为string类型,再调用replace方法(注意:因为\x是转义字符,不想让转义字符生效,需要显示字符串原来的意思,这就要用r和R来定义原始字符串。),然后将小写字母转化为大写字母,并最终索引我们需要的部分

用input()取代目标字符串就能爬取任意想要爬取的主题了
# -*- encoding:utf-8 -*-
import urllib.request # 导入urllib库的request模块
from bs4 import BeautifulSoup
import lxml #文档解析器
import os #os模块就是对操作系统进行操作
import numpy as np #列表、字典、字符串等中计算元素重复的次数
urls=[]
titles=[]
#爬取所有新闻的url和标题,存储在urls和titles中,这里range(1)表示只爬取1页。
for i in range(1): url='http://sousuo.gov.cn/s.htm?t=zhengce&q='+str(input().encode()).replace(r'\x', '%').upper()[2:-1] res = urllib.request.urlopen(url) #调用urlopen()从服务器获取网页响应(respone),其返回的响应是一个实例 html = res.read().decode('utf-8') #调用返回响应示例中的read(),可以读取html soup = BeautifulSoup(html, 'lxml') result = soup.find_all('div',attrs={'class': 'dys_middle_result_content'}) download_soup = BeautifulSoup(str(result), 'lxml') print(download_soup) url_all = download_soup.find_all('a') for a_url in url_all: a_title=a_url.get_text('target') titles.append(a_title) a_url = a_url.get('href') urls.append(a_url)
#定义txt存储路径。
picpath='./newws1/'#这里我用的是本程序路径,也可改为c盘或d盘等路径。
def txt(name, text): # 定义函数名 if not os.path.exists(picpath): # 路径不存在时创建一个 os.makedirs(picpath) savepath = picpath + name + '.txt' file = open(savepath, 'a', encoding='utf-8')#因为一个网页里有多个标签p,所以用'a'添加模式 file.write(text) # print(text) file.close
#读取urls中存储的ulrs[i],爬取文本。
for i in range(len(urls)): try: res = urllib.request.urlopen(urls[i]) html = res.read().decode('utf-8') soup = BeautifulSoup(html, 'lxml') print(str(i)+'saved') for p in soup.select('p'): t = p.get_text() txt(titles[i],t) except OSError: pass #如果报错就不管,继续读取下一个url continue
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47


2.对爬取到的文章内容进行关键词分析——jieba
基于TF-IDF算法的关键词抽取
import jieba.analyse
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
–sentence 为待提取的文本
–topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
–withWeight 为是否一并返回关键词权重值,默认值为 False
–allowPOS 仅包括指定词性的词,默认值为空,即不筛选
from jieba.analyse import *
rootdir = './newws1'
list = os.listdir(rootdir) #列出文件夹下所有的目录与文件
print(list)
s=""
for i in range(0,len(list)): path = os.path.join(rootdir,list[i]) if os.path.isfile(path): with open(path,encoding='utf-8') as f: data = f.read() s+=data
for keyword, weight in extract_tags(s, topK=10, withWeight=True): print('%s %s' % (keyword, weight))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

文章来源: blog.csdn.net,作者:高级cv算法设计师,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_44732013/article/details/114707304