@Author:Runsen
@[toc]
循环神经网络RNN
-
前馈神经网络(例如 MLP 和 CNN)功能强大,但它们并未针对处理“顺序”数据进行优化
-
换句话说,它们不具有先前输入的“记忆”
-
例如,考虑翻译语料库的情况。 你需要考虑 “context” 来猜测下一个出现的单词
-
RNN 适合处理顺序格式的数据,因为它们具有 循环 结构
-
换句话说,他们保留序列中早期输入的记忆
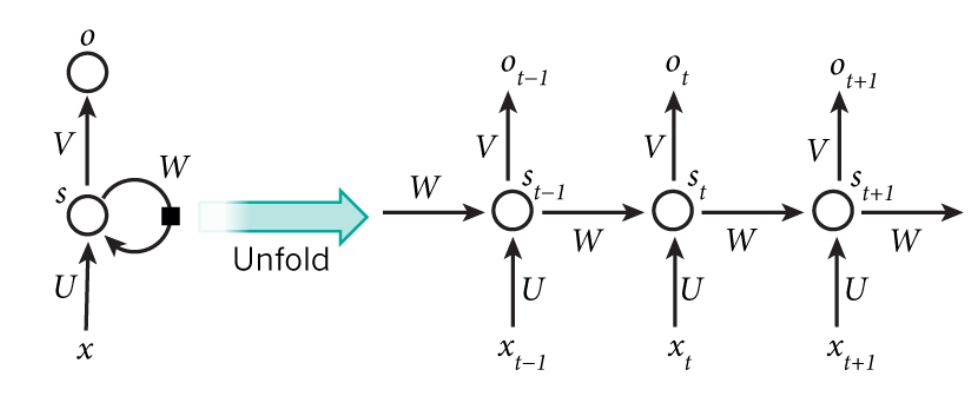
- 但是,为了减少参数数量,不同时间步长的每一层需要共享相同的参数
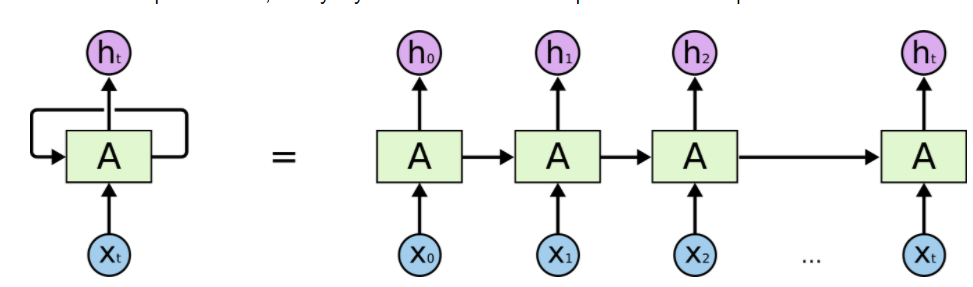
Load Dataset
import numpy as np
from sklearn.metrics import accuracy_score
from tensorflow.keras.datasets import reuters
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
# parameters for data load
num_words = 30000
maxlen = 50
test_split = 0.3
(X_train, y_train), (X_test, y_test) = reuters.load_data(num_words = num_words, maxlen = maxlen, test_split = test_split)
# pad the sequences with zeros
#填充参数设置为“post”=> 0 被附加到序列的末尾
X_train = pad_sequences(X_train, padding = 'post')
X_test = pad_sequences(X_test, padding = 'post')
X_train = np.array(X_train).reshape((X_train.shape[0], X_train.shape[1], 1))
X_test = np.array(X_test).reshape((X_test.shape[0], X_test.shape[1], 1))
y_data = np.concatenate((y_train, y_test))
y_data = to_categorical(y_data)
y_train = y_data[:1395]
y_test = y_data[1395:]
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)

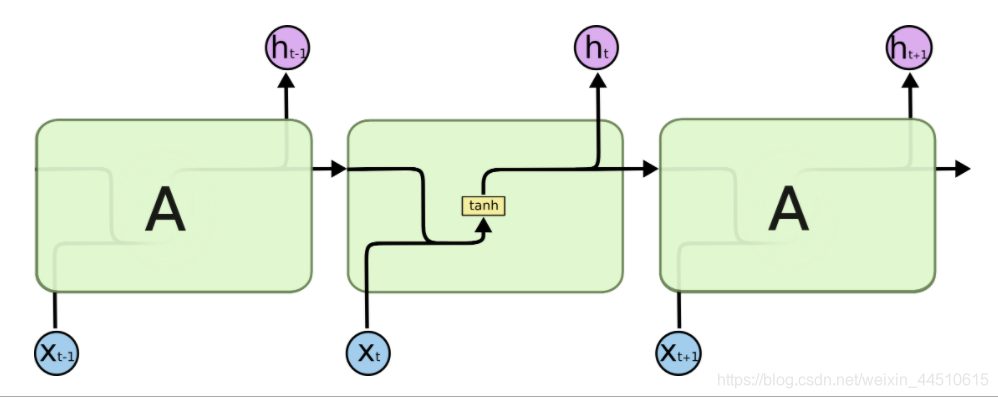
1. Vanilla RNN
- Vanilla RNN 结构简单
- 然而,他们遭受“长期依赖”的问题
- 因此,无法长时间保持顺序内存
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, SimpleRNN, Activation
from tensorflow.keras import optimizers
from tensorflow.keras.wrappers.scikit_learn import KerasClassifier
def vanilla_rnn():
model = Sequential()
model.add(SimpleRNN(50, input_shape = (49,1), return_sequences = False))
model.add(Dense(46))
model.add(Activation('softmax'))
adam = optimizers.Adam(lr = 0.001)
model.compile(loss = 'categorical_crossentropy', optimizer = adam, metrics = ['accuracy'])
return model
model = KerasClassifier(build_fn = vanilla_rnn, epochs = 200, batch_size = 50, verbose = 1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
y_test_ = np.argmax(y_test, axis = 1)
print(accuracy_score(y_pred, y_test_))
0.7495826377295493
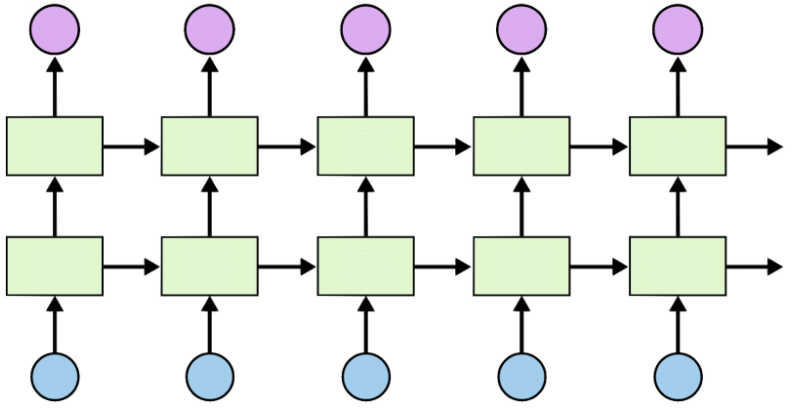
2. Stacked Vanilla RNN
- 可以堆叠 RNN 层以形成更深的网络
def stacked_vanilla_rnn():
model = Sequential()
model.add(SimpleRNN(50, input_shape = (49,1), return_sequences = True)) # return_sequences parameter has to be set True to stack
model.add(SimpleRNN(50, return_sequences = False))
model.add(Dense(46))
model.add(Activation('softmax'))
adam = optimizers.Adam(lr = 0.001)
model.compile(loss = 'categorical_crossentropy', optimizer = adam, metrics = ['accuracy'])
return model
model = KerasClassifier(build_fn = stacked_vanilla_rnn, epochs = 200, batch_size = 50, verbose = 1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(accuracy_score(y_pred, y_test_))
0.7746243739565943
3. LSTM
- LSTM(long short-term memory)是一种改进的结构,用于解决长期依赖问题

from tensorflow.keras.layers import LSTM
def lstm():
model = Sequential()
model.add(LSTM(50, input_shape = (49,1), return_sequences = False))
model.add(Dense(46))
model.add(Activation('softmax'))
adam = optimizers.Adam(lr = 0.001)
model.compile(loss = 'categorical_crossentropy', optimizer = adam, metrics = ['accuracy'])
return model
model = KerasClassifier(build_fn = lstm, epochs = 200, batch_size = 50, verbose = 1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# accuracy improves by adopting LSTM structure
print(accuracy_score(y_pred, y_test_))
0.8464106844741235
4. Stacked LSTM
- LSTM 层也可以堆叠
def stacked_lstm():
model = Sequential()
model.add(LSTM(50, input_shape = (49,1), return_sequences = True))
model.add(LSTM(50, return_sequences = False))
model.add(Dense(46))
model.add(Activation('softmax'))
adam = optimizers.Adam(lr = 0.001)
model.compile(loss = 'categorical_crossentropy', optimizer = adam, metrics = ['accuracy'])
return model
model = KerasClassifier(build_fn = stacked_lstm, epochs = 200, batch_size = 50, verbose = 1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(accuracy_score(y_pred, y_test_))
0.8480801335559266