欢迎大家来到“Python从零到壹”,在这里我将分享约200篇Python系列文章,带大家一起去学习和玩耍,看看Python这个有趣的世界。所有文章都将结合案例、代码和作者的经验讲解,真心想把自己近十年的编程经验分享给大家,希望对您有所帮助,文章中不足之处也请海涵。Python系列整体框架包括基础语法10篇、网络爬虫30篇、可视化分析10篇、机器学习20篇、大数据分析20篇、图像识别30篇、人工智能40篇、Python安全20篇、其他技巧10篇。您的关注、点赞和转发就是对秀璋最大的支持,知识无价人有情,希望我们都能在人生路上开心快乐、共同成长。
前一篇文章讲述了Selenium基础技术,通过三个基于Selenium技术的爬虫,爬取Wikipedia、百度百科和互动百科消息盒的例子,从实际应用出发来学习网络爬虫。本文将进入数据分析部分,主要普及网络数据分析的基本概念,讲述数据分析流程和相关技术,同时详细讲解Python提供的若干第三方数据分析库,包括Numpy、Pandas、Matplotlib、Sklearn等。基础文章,希望对您有所帮助。
Web数据分析是一门多学科融合的学科,它涉及统计学、数据挖掘、机器学习、数据科学、知识图谱等领域。数据分析是指用适当的统计方法对所收集数据进行分析,通过可视化手段或某种模型对其进行理解分析,从而最大化挖掘数据的价值,形成有效的结论。
文章目录
下载地址:
前文赏析:
第一部分 基础语法
第二部分 网络爬虫
- [Python从零到壹] 四.网络爬虫之入门基础及正则表达式抓取博客案例
- [Python从零到壹] 五.网络爬虫之BeautifulSoup基础语法万字详解
- [Python从零到壹] 六.网络爬虫之BeautifulSoup爬取豆瓣TOP250电影详解
- [Python从零到壹] 七.网络爬虫之Requests爬取豆瓣电影TOP250及CSV存储
- [Python从零到壹] 八.数据库之MySQL基础知识及操作万字详解
- [Python从零到壹] 九.网络爬虫之Selenium基础技术万字详解(定位元素、常用方法、键盘鼠标操作)
- [Python从零到壹] 十.网络爬虫之Selenium爬取在线百科知识万字详解(NLP语料构造必备技能)
第三部分 数据分析
- [Python从零到壹] 十一.数据分析之Numpy、Pandas、Matplotlib和Sklearn入门知识万字详解(1)
什么是数据分析?
网络数据分析(Web Data Analysis)是指采用合适的统计分析方法,建立正确的分析模型,对Web网络数据进行分析,提取有价值的信息和结论,挖掘出数据的价值,从而造福社会和人类。数据分析可以帮助人们做出预测和提前判断,以便采取适当行动解决问题。
数据分析的目的是从海量数据或无规则数据集中把有价值的信息挖掘出来,把隐藏的信息提炼出来,并总结出所研究数据的内在规律,从而帮助用户进行决策、预测和判断。数据分析通常包括前期准备、数据爬取、数据预处理、数据分析、可视化绘图及分析评估六个步骤,如图1所示。
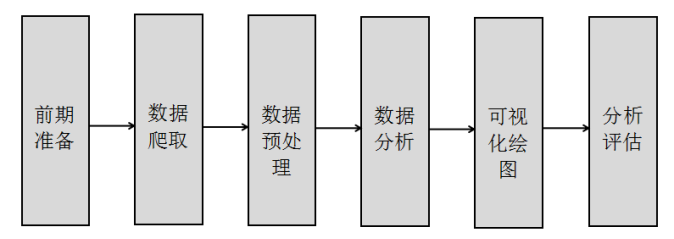
- 前期准备。在获取数据之前,先要决定本次数据分析的目标,这些目标需要进行大量的数据收集和前期准备,判断整个实验是否能向着正确的方向前进。
- 数据爬取。读者可以利用Python爬取所需的数据集,定义相关的特征,采用前文讲述的爬虫知识进行爬取。也可以针对常见的数据集进行简单的数据分析。
- 数据预处理。如果想要提高数据质量,纠正错误数据或处理缺失值,就需要进行数据预处理操作,包括数据清洗、数据转化、数据提取、数据计算等。注意,文本语料比较特殊,需要经过中文分词、数据清洗、特征提取、权重计算,将文本内容转换为向量的形式预处理操作,才能进行后面的数据分析。
- 数据分析。读者根据所研究的内容,构建合理的算法模型,训练模型并预测业务结构。数据科学家需要拥有良好的数学、机器学习、编程背景知识,常见数据分析的方法包括回归分析、聚类分析、分类分析、关联规则挖掘、主题模型等。
- 可视化绘图。经过数据分析后的数据通常需要进行可视化绘图操作,包括绘制散点图、拟合图形等,通过可视化操作让用户直观的感受数据分析的结果。
- 分析评估。最后需要对模型实验的结果进行评估,同时需要优化算法、优化结果,重复以前业务流程,从而更好利用数据的价值,造福整个社会。
Python数据分析的核心流程是什么?
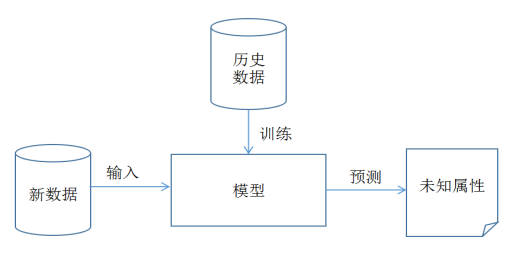
下图是数据分析的核心模型,主要划分为训练和预测两部分内容。
- 训练。输入历史数据进行训练,得到分析模型。
- 预测。输入新数据集,采用训练得模型进行预测操作,并绘制相关图形和评估结果。
选择Python作为数据分析的编程语言,主要原因有以下四个方面:
- Python简单易学,容易上手。不像其他语言需要掌握大量的数据结构和语法知识才能进行实例操作,并且Python可以通过极少的代码实现一些数据分析案例,提升开发人员的学习兴趣,破解新手的心理障碍。
- Python语言支持开源。丰富强大的第三方库让我们做数据分析更得心应手,科学计算、数据预处理、数据读取、数据分析、数据可视化、深度学习等各个领域都有对应的库支撑,并且各个库可以相互调用,常见数据分析库包括Numpy、Pandas、Matplotlib、Sklearn等。
- Python是一门脚本语言,可以进行快速开发。开发时间效率相对较高,比如第一部分介绍的Python数据爬取内容,通过Java代码去实现,就需要大量的代码,而Python的代码量更小,写代码和学习效率更高。
- Python语言随着深度学习、人工智能的浪潮,也在不断变强、拥有更丰富的扩展包。而在学习深度学习知识之前,我们需要了解Python数据分析及机器学习的基础知识。
同时,在开始Python数据分析之前,我们需要提到另一个与它紧密相关的概念,即数据挖掘。那它们之间究竟存在什么区别呢?
- 数据分析和数据挖掘的侧重点不同,数据分析主要侧重于通过对历史数据进行统计分析,从而挖掘出深层次的价值,并将结果的有效信息呈现出来;
- 数据挖掘是从数据中发现知识规则,并对未知数据进行预测分析的过程。
- 数据分析和数据挖掘两者是紧密关联的,数据分析结果需要进一步数据挖掘才能指导决策,而数据挖掘进行价值评估过程也需要调整先验约束而再次进行数据分析。但相同的地方是二者都需要有数据作为支撑,都需要掌握相关的统计学、计算科学、机器学习、可视化绘图工具等知识,都需要挖掘出数据的价值供用户、社会使用,提出正确的解决方案并进行预测决策,因此数据分析师和数据挖掘师并没有明显的界限。

在使用Python做数据分析时,常常需要用到各种扩展包,常见的包括Numpy、Scipy、Pandas、Sklearn、Matplotlib、Networkx、Gensim等,如下所示。
- NumPy
提供数值计算的扩展包,拥有高效的处理函数和数值编程工具,用于数组、矩阵和矢量化等科学计算操作。很多扩展包都依赖于它。
import numpy as np
np.array([2, 0, 1, 5, 8, 3])
#生成数组
- SciPy
SciPy是一个开源的数学、科学和工程计算包,提供矩阵支持,以及矩阵相关的数值计算模块。它是一款方便、易于使用、专为科学和工程设计的Python工具包,包括统计、优化、整合、线性代数模块、傅里叶变换、信号和图像处理、常微分方程求解器等。
from scipy import linalg
linalg.det(arr)
#计算矩阵行列式
- Pandas
它是Python强大的数据分析和探索数据的工具包,旨在简单直观地处理“标记”和“关系”数据。它设计用于快速简便的数据处理,聚合和可视化,支持类似于SQL语句的模型,支持时间序列分析,能够灵活的处理分析数据。
import pandas as pd
pd.read_csv('test.csv')
#读取数据
- SKlearn
Scikit-Learn为常见的机器学习算法提供了一个简洁而规范的分析流程,包含多种机器学习算法。该库结合了高质量的代码和良好的文档,使用起来非常方便,并且代码性能很好,其实就是用Python进行机器学习的行业标准。
from sklearn import linear_model
linear_model.LinearRegression()
#调用线性回归模型
- Matplotlib
它是Python强大的数据可视化工具、2D绘图库,可以轻松生成简单而强大的可视化图形,可以绘制散点图、折线图、饼状图等图形。但其库本身过于复杂,绘制的图需要大量的调整才能变精致。
import matplotlib.pyplot as plt
plt.plot(x,y,'o')
#绘制散点图
- Seaborn
Seaborn是由斯坦福大学提供的一个python绘图库,绘制的图表更加赏心悦目,它更关注统计模型的可视化,如热图。Seaborn能理解Pandas的DataFrame类型,所以它们一起可以很好地工作。
import seaborn as sns
sns.distplot(births['a'], kde=False)
#绘制直方图
- Networkx
NetworkX是一个用来创建、操作、研究复杂网络结构、动态和功能的Python扩展包。NetworkX库支持图的快速创建,可以生成经典图、随机图和综合网络,其节点和边都能存储数据、权重,是一个非常实用的、支持图算法的复杂网络库。
import networkx as nx
DG = nx.DiGraph()
#导入库并创建无多重边有向图
- Gensim
Gensim是一个从非结构的文本中挖掘文档语义结构的扩展包,它无监督地学习到文本隐层的主题向量表达。Gensim实现了潜在语义分析(LSA)、LDA模型、TF-IDF、Word2vec等在内的多种主题模型算法,并提供了诸如相似度计算等API接口。
from gensim import models
tfidf = models.TfidfModel(data)
#调用TF-IDF模型
- NLTK
NLTK是自然语言工具包(Natural Language Toolkit),用于符号和统计自然语言处理的常见任务。 旨在促进自然语言处理及其相关领域的教学和研究。常见功能包括文本标记、实体识别、提取词干、语义推理等。
from nltk.book import *
text1.concordance("monstrous")
#搜索文本功能
- Statsmodels
Statsmodels是一个包含统计模型、统计测试和统计数据挖掘的Python模块,用户通过它的各种统计模型估计方法来进行统计分析,包括线性回归模型、广义线性模型、时间序列分析模型、各种估计量等算法。
import statsmodels.api as sm
results = sm.OLS(y, X).fit()
#回归模型
- TensorFlow
TensorFlow是一个开源的数据流图计算库,是Google公司2015年11月开源的第二代深度学习框架。它使用数据流图进行数值分析,TensorFlow使用有向图表示一个计算任务,图的节点表示对数据的处理,图的边Flow描述数据的流向,tensor(意为张量)表示数据,它的多层节点系统可以在大型数据集上快速训练人工神经网络。其他常见的深度学习框架或库是Theano、Keras。
import tensorflow as tf
x = tf.constant(1.0)
#输入一个常量
接下来作者将对其中比较重要常用的四个扩展包(Numpy、Pandas、Matplotlib、Sklearn)进行简单的介绍,这些包更多的实例应用将在后面章节实例中讲解。
注意:本文数据分析部分推荐读者使用Anaconda或PyCharm中的集成环境,它已经集成安装了所使用的数据分析扩展包,安装后可以直接调用。
NumPy(Numeric Python)是Python提供的数值计算扩展包,拥有高效的处理函数和数值编程工具,专为进行严格的数字处理而产生,用于科学计算。比如:矩阵数据类型、线性代数、矢量处理等。这个库的前身是1995年就开始开发的一个用于数组运算的库,经过长时间的发展,基本成了绝大部分Python科学计算的基础包,当然也包括提供给Python接口的深度学习框架。

由于Python没有提供数组,列表(List)可以完成数组操作,但不是真正意义上的数组,当数据量增大时,其速度很慢,所以提供了Numpy扩展包完成数组操作,很多高级扩展包也依赖于它,比如Scipy、Matplotlib、Pandas等。
Array是数组,它是Numpy库中最基础的数据结构,Numpy可以很方便地创建各种不同类型的多维数组,并且执行一些基础操作。一维数组常见操作代码如下所示。
#coding=utf-8
#By:Eastmount CSDN 2021-06-28
#导入包并重命名np
import numpy as np
#定义一维数组
a = np.array([2, 0, 1, 5, 8, 3])
print('原始数据:', a)
#输出最大、最小值及形状
print('最小值:', a.min())
print('最大值:', a.max())
print('形状', a.shape)
输出如下所示:

代码通过np.array定义了一个数组[2, 0, 1, 5, 8, 3],其中min计算最小值,max计算最大值,shape表示数组的形状,因为是一维数组,故行为为6L(6个数字)。
同时,Numpy库最重要的一个知识点是数组的切片操作。数据分析过程中,通常会对数据集进行划分,比如将训练集和测试集分割为“80%-20%”或“70%-30%”的比例,通常采用的方法就是切片。
#coding=utf-8
#By:Eastmount CSDN 2021-06-28
#导入包并重命名np
import numpy as np
#定义一维数组
a = np.array([2, 0, 1, 5, 8, 3])
print('原始数据:', a)
#输出最大、最小值及形状
print('最小值:', a.min())
print('最大值:', a.max())
print('形状', a.shape)
#数据切片
print('切片操作:')
print(a[:-2])
print(a[-2:])
print(a[:1])
输出结果如下图所示:

- a[:-2]表示从头开始获取,“-2”表示后面两个值不取,结果:[2 0 1 5]。
- a[-2:]表示起始位置从后往前数两个数字,获取数字至结尾,即获取最后两个值[8 3]。
- a[:1]表示从头开始获取,获取1个数字,即[2]。
下面输出Array数组的类型,即numpy.ndarray,并调用sort()函数排序,代码如下:
#coding=utf-8
#By:Eastmount CSDN 2021-06-28
#导入包并重命名np
import numpy as np
#定义一维数组
a = np.array([2, 0, 1, 5, 8, 3])
print('原始数据:', a)
#输出最大、最小值及形状
print('最小值:', a.min())
print('最大值:', a.max())
print('形状', a.shape)
#数据切片
print('切片操作:')
print(a[:-2])
print(a[-2:])
print(a[:1])
#排序
print(type(a))
a.sort()
print('排序后:', a)
# <type 'numpy.ndarray'>
# 排序后: [0 1 2 3 5 8]
输出结果如下图所示:

Array定义二维数组如[[1,2,3],[4,5,6]],下图表示二维数组的常见操作,定义了数组6*6的矩阵。
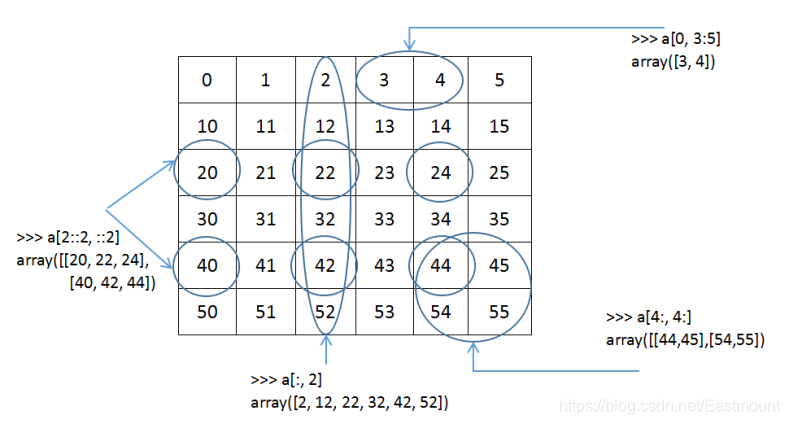
- a[0, 3:5]表示获取第1行,第4和5列的两个值,即[3, 4]。注意数组下标a[0]表示获取第一个值,同样,a[3]是获取第4个值。
- a[4:, 4:]表示从第5行开始,获取后面所有行,同时列也是从第5列开始,获取到后面所有列的数据,输出结果为[[44,45],[54,55]]。
- a[2::2,::2]表示从第3行开始获取,每次空一行,则获取第3、5行数据,列从头开始获取,也是各一列获取一个值,则获取第1、3、5列,结果为:[[20,22,24],[40,42,44]]。
基础代码如下:
#coding=utf-8
#By:Eastmount CSDN 2021-06-28
#定义二维数组
import numpy as np
c = np.array([[1, 2, 3, 4],[4, 5, 6, 7], [7, 8, 9, 10]])
print('形状:', c.shape)
print('获取值:', c[1][0])
print('获取某行:')
print(c[1][:])
print('获取某行并切片:')
print(c[0][:-1])
print(c[0][-1:])
输出结果如下:
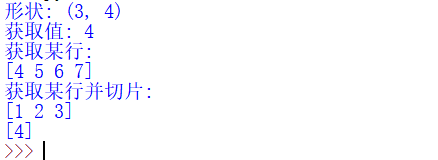
获取某个值c[1][0],其结果为第2行,第一列,即为4;获取某一行的所有值,则为c[1][:],其结果为[4,5,6,7];获取某行并进行切片操作,c[0][:-1]获取第一行,从第一列到倒数第一列,结果为[1,2,3];c[0][-1:]获取第一行,从倒数第一列到结束,即为4。
同时如果想获取矩阵中的某一列数据怎么实现呢?因为在进行数据分析时,通常需要获取某一列特征进行分析,或者作为可视化绘图的x或y轴数据。
[[1, 2, 3, 4],
[4, 5, 6, 7],
[7, 8, 9,10]]
比如需要获取第3列数据[3, 6, 9],代码如下:
#获取具体某列值
print('获取第3列:')
print(c[:,np.newaxis, 2])
# 获取第3列:
# [[3]
# [6]
# [9]]
其他操作,包括调用函数,定义数组等。
#coding=utf-8
#By:Eastmount CSDN 2021-06-28
import numpy as np
#调用sin函数和2的3次方
print(np.sin(np.pi/6))
print(type(np.sin(0.5)))
f = np.power(2, 3)
print(f)
#范围定义
print(np.arange(0,4))
print(type(np.arange(0,4)))
#调用求和函数、平均值函数、标准差函数
print(np.sum([1, 2, 3, 4]))
print(np.mean([4, 5, 6, 7]))
print(np.std([1, 2, 3, 2, 1, 3, 2, 0]))
输出如下所示:
0.49999999999999994
<class 'numpy.float64'>
8
[0 1 2 3]
<class 'numpy.ndarray'>
10
5.5
0.9682458365518543
同时,Numpy扩展包的线性代数模块(Linalg)和随机模块(Random)也是非常重要的模块,后续的数据分析主要利用数组和矩阵进行,也推荐读者自行阅读了解。
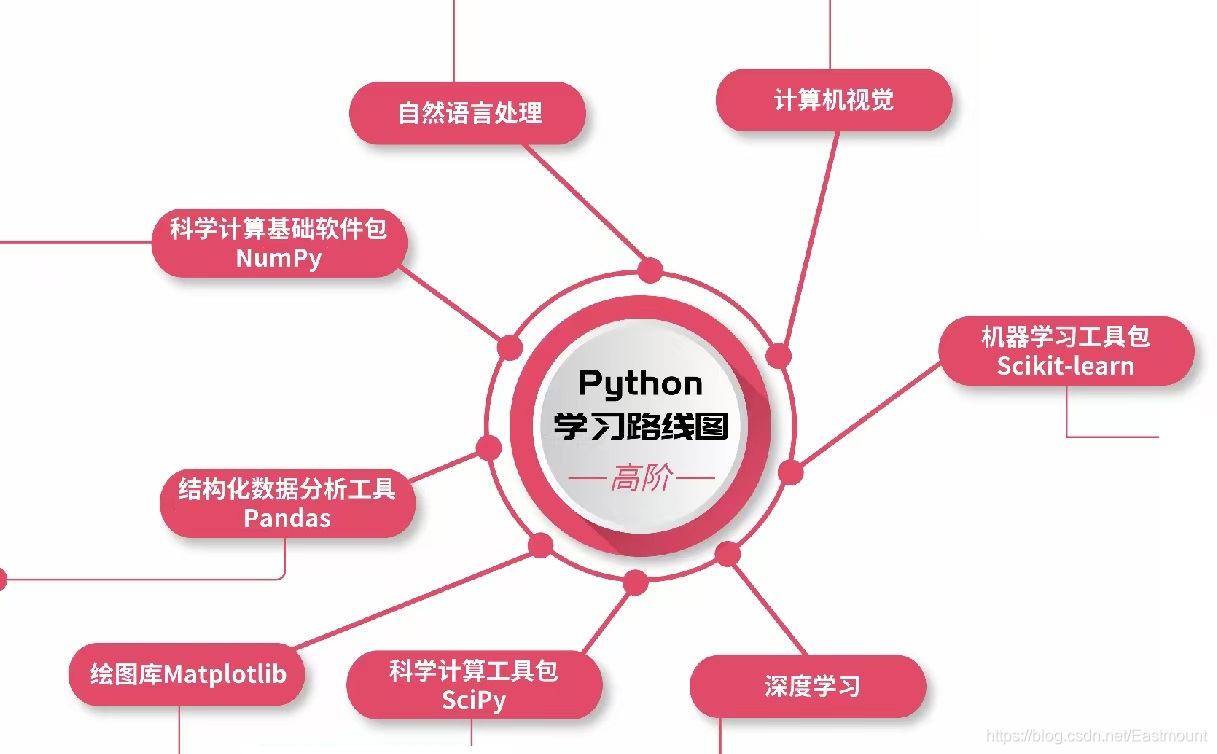
熟悉作者的读者都知道,2021年初我和CSDN许老师完成了一份《Python成长路线图》,这里也给出NumPy的思维导图。许老师是非常谦逊又有才华的前辈,值得我们每个人学习。很愉快的一次合作,同时感谢CSDN和周老师,也欢迎大家继续补充和指正,后续文章会详细介绍NumPy应用。

-
科学计算基础软件包NumPy
NumPy概述、安装配置、创建数组、操作数组、常用函数、掩码数组、矩阵对象、随机抽样子模块 -
NumPy概述
NumPy的前世今生、NumPy数组 vs Python列表、NumPy数组类型和属性、维轴秩、广播和矢量化 -
安装配置
-
创建数组

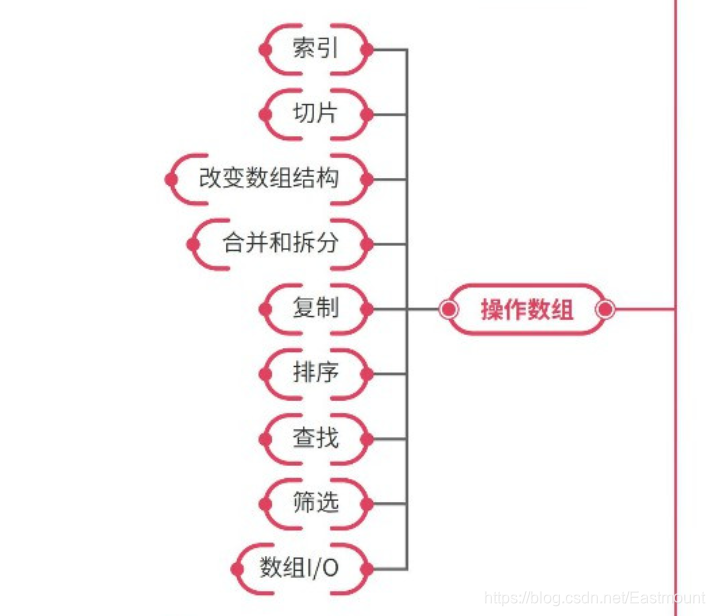
- 操作数组
索引、切片、改变数组结构、合并和拆分、复制、排序、查找、筛选、数组IO
- 常用函数
np.nan和np.inf、函数命名空间、数学函数、统计函数、插值函数、多项式拟合函数、自定义广播函数

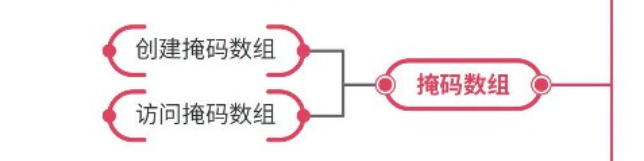
- 掩码数组
创建掩码数组、访问掩码数组
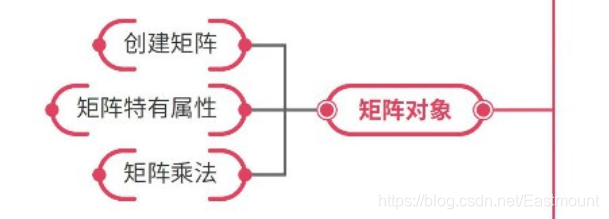
- 矩阵对象
创建矩阵、矩阵特有属性、矩阵乘法
- 随机抽样子模块
随机数、随机抽样、正态分布、伪随机数的深度思考

Pandas是面板数据(Panel Data)的简写。它是Python最强大的数据分析和探索工具之一,因金融数据分析工具而开发,支持类似于SQL语句的模型,可以对数据进行增删改查等操作,支持时间序列分析,也能够灵活的处理缺失的数据。首先声明该扩展包的功能非常强大,作者只是讲述了它的基础部分内容,后面随着学习深入会讲述更多它的用法,同时也建议读者自行学习。下一篇文章将详细介绍Pandas可视化绘图方法。

Pandas可以进行统计特征函数计算,包括均值、方差、标准差、分位数、相关系数和协方差等,这些统计特征能反映出数据的整体分布。
- sum():该函数用于计算数据样本的总和
- mean():该函数用于计算数据样本的算数平均值
- std():该函数用于计算数据样本的标准差
- Cov():该函数用于计算数据样本的协方差矩阵
- var():该函数用于计算数据样本的方差
- describe():该函数用于描述数据样本的基本情况,包括均值、标准差等
Pandas最重要的是Series和DataFrame子类,其导入方法如下:
from pandas import Series, DataFrame
import pandas as pd
下面从读写文件、Series和DataFrame的用法分别讲解,其中利用Pandas读写CSV、Excel文件是数据分析非常重要的基础手段。
读写文件常用的方法如下,包括读写Excel文件、CSV文件和HDF5文件等。
#将数据写入excel文件,文件名为foo.xlsx
df.to_excel('foo.xlsx', sheet_name='Sheet1')
#从excel文件中读取数据
pd.read_excel('foo.xlsx', 'Sheet1', index_col=None, na_values=['NA'])
#将数据写入csv文件,文件名为foo.csv
df.to_csv('foo.csv')
#从csv文件中读取数据
pd.read_csv('foo.csv')
#将数据写入HDF5文件存储
df.to_hdf('foo.h5','df')
#从HDF5存储中读取数据
pd.read_hdf('foo.h5','df')
下面通过一个具体的实例数据来讲解Pandas的用法,数据集共包含3列数据,分别是用户A、用户B、用户C的消费数据,共10行,对应十天的消费情况,并且包含缺失值。

Pandas读取数据的简易代码如下:
#coding=utf-8
#By:Eastmount CSDN 2021-06-28
import pandas as pd
#读取数据,其中参数header设置Excel无标题头
data = pd.read_excel("data.xls", header=None)
print(data)
#计算数据长度
print('行数', len(data))
#计算用户A\B\C消费求和
print(data.sum())
#计算用户A\B\C消费算术平均数
mm = data.sum()
print(mm)
#输出预览前5行数据
print('预览前5行数据')
print(data.head())
调用Pandas扩展包的read_excel()函数读取“test15.xls”表格文件,参数Header=None表示不读取标题头,然后输出data数据。data.sum()表示对三个用户的消费数据求和,data.head()表示预览输出前5行数据。输出数据如下,NaN表示空值(Not a Number)。

同时,Pandas提供了describe()函数输出数据的基本信息,包括count()、mean()、std()、min()、max()等函数。
#输出数据基本统计量
print('输出数据基本统计量')
print(data.describe())
输出数据基本统计量
0 1 2 3
count 10.00000 9.000000 9.000000 8.000000
mean 5.50000 237.167778 335.235556 493.886875
std 3.02765 1.021161 65.198685 28.565643
min 1.00000 235.830000 206.430000 435.350000
25% 3.25000 236.270000 324.030000 484.147500
50% 5.50000 237.410000 328.080000 501.282500
75% 7.75000 238.030000 388.020000 515.645000
max 10.00000 238.650000 404.040000 517.090000
>>>
更多Pandas可视化画图操作参考下一篇文章。
Series是一维标记数组,可以存储任意数据类型,包括整型、字符串、浮点型和Python对象等,轴标一般指索引。

首先,通过传递一个List对象来创建一个Series,其默认创建整型索引。
#coding=utf-8
#By:Eastmount CSDN 2021-06-28
from pandas import Series, DataFrame
a = Series([4, 7, -5, 3])
print('创建Series:')
print(a)
输出如下,默认为0-4的整型索引。
创建Series:
0 4
1 7
2 -5
3 3
dtype: int64
然后,创建一个带有索引的Series,从而确定每个数据点的Series。Series的一个重要功能是在算术运算中它会自动对齐不同索引的数据。
b = Series([4, 7, -5, 3], index=['d', 'b', 'a', 'c'])
print('创建带有索引的Series:')
print(b)
输出如下所示:
创建带有索引的Series:
d 4
b 7
a -5
c 3
dtype: int64
如果你有一些数据在一个Python字典中,你可以通过传递字典来创建一个Series。
sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
c = Series(sdata)
print('通过传递字典创建Series:')
print(c)
states = ['California', 'Ohio', 'Oregon', 'Texas']
d = Series(sdata, index=states)
print('California没有字典为空:')
print(d)
输出数据如下:
通过传递字典创建Series:
Ohio 35000
Oregon 16000
Texas 71000
Utah 5000
dtype: int64
California没有字典为空:
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
dtype: float64
注意:Series、Numpy中的一维数组(Array)和Python基础数据结构List的区别是:List中的元素可以是不同的数据类型,而Array和Series中则只允许存储相同的数据类型,这样可以更有效的使用内存,提高运算效率。
DataFrame是二维标记数据结构,列可以是不同的数据类型。它是常用的Pandas对象,和Series一样可以接收多种输入,包括Lists、Dicts、Series和DataFrame等。初始化对象时,除了数据还可以传index和columns这两个参数。
下面简单讲解DataFrame常用的三种使用方法。
- (1)在Pandas中用函数 isnull 和 notnull 来检测数据丢失,如pd.isnull(a)、pd.notnull(b)。Series也提供了这些函数的实例方法,如a.isnull()。
- (2)Pandas提供了大量的方法能够轻松的对Series,DataFrame和Panel对象进行各种符合各种逻辑关系的合并操作。如:Concat、Merge(类似于SQL类型的合并)、Append (将一行连接到一个DataFrame上)。
- (3)DataFrame中常常会出现重复行,DataFrame提供的Duplicated方法返回一个布尔型Series,表示各行是否是重复行;还有一个drop_duplicated方法,它返回一个移除了重复行的DataFrame。
总之,Pandas是非常强大的一个数据分析包,很多功能都需要我们自己去慢慢摸索。
-
结构化数据分析工具Pandas
Pandas概览、数据结构、基本操作、高级应用 -
Pandas概述
Pandas的特点、安装和使用

- 数据结构
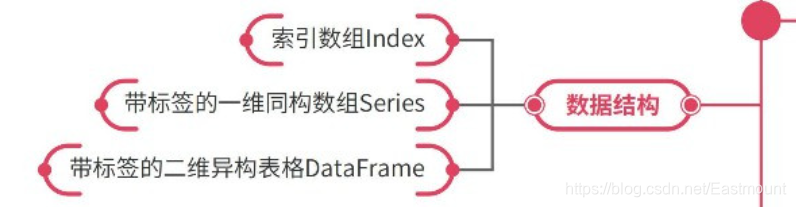
索引数组index、带标签的一维同构数组Series、带标签的二维异构表格DataFrame
- 基本操作
数据预览、数据选择、改变数据结构、改变数据类型、广播与矢量化运算、行列级广播函数

- 高级应用
分组、聚合、层次化索引、表级广播函数、日期时间索引对象、透视表、数据可视化、数据IO
Matplotlib是Python强大的数据可视化工具、2D绘图库(2D plotting library),可以方便的创建海量类型的2D图表和一些基本的3D图表,类似于MATLAB和R语言。Matplotlib提供了一整套和Matlab相似的命令API,十分适合交互式地进行制图,而且也可以方便地将它作为绘图控件,嵌入GUI应用程序中。
Matplotlib是一名神经生物学家John D. Hunter博士于2007年创建,函数设计上参考了Matlab,现在在Python的各个科学计算领域都得到了广泛应用。Matplotlib官网地址为:
- http://matplotlib.org/
Matplotlib作图库常用的函数如下:
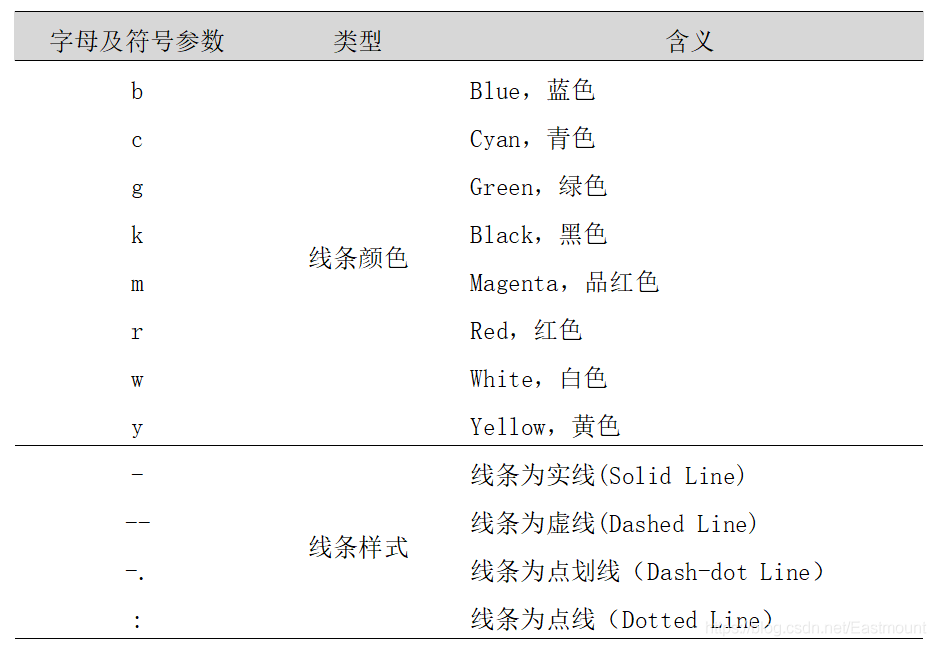
- Plot():用于绘制二维图、折线图,其格式为plt.plot(X,Y,S)。其中X为横轴,Y为纵轴,参数S为指定绘图的类型、样式和颜色,详见表15.3所示。
- Pie():用于绘制饼状图(Pie Plot)。
- Bar():用于绘制条形图(Bar Plot)。
- Hist():用于绘制二维条形直方图。
- Scatter():用于绘制散点图。
下表绘图常见样式和颜色。
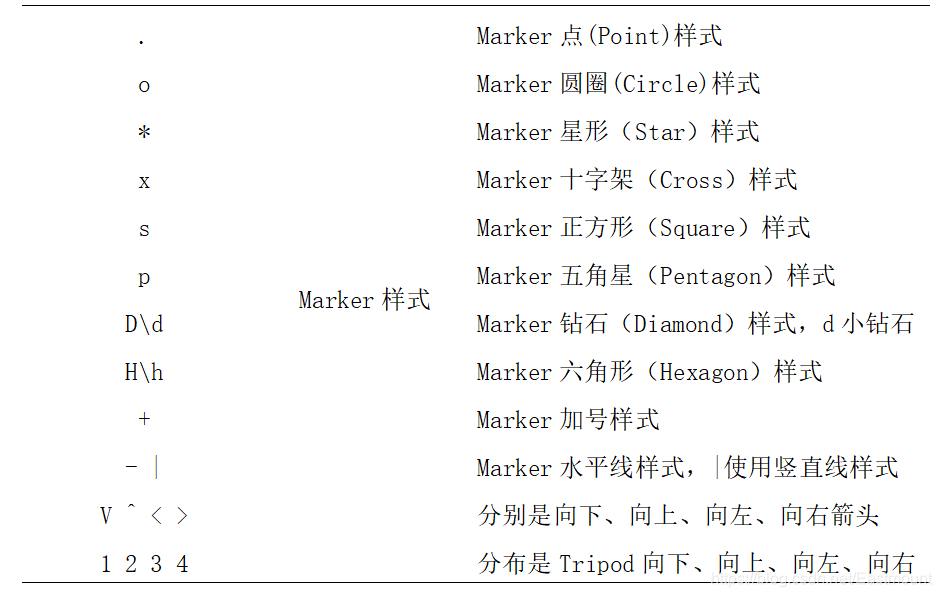
举例如下,该代码表示绘制散点图(Scatter),横轴为x,纵轴为y,c=y_pred对聚类的预测结果画出散点图,marker='o’表示用圆圈(Circle)绘图,s表示设置尺寸大小(Size)。
plt.scatter(x, y, c=y_pred, marker='o', s=200)
下列代码是调用Matplotlib绘制柱状图的源代码,该代码结合Pandas扩展包读取前文表15.2的用户消费数据,分别是用户A、用户B、用户C十天的消费数据。
Matplotlib绘图主要包括以下几个步骤:
- 导入Matplotlib扩展包及其子类。
- 设置绘图的数据及参数,数据通常是经过Sklearn机器学习包分析后的结果。
- 调用Matplotlib.pyplot子类的Plot()、Pie()、Bar()、Hist()、Scatter()等函数进行绘图。
- 设置绘图的X轴坐标、Y轴坐标、标题、网格线、图例等内容。
- 最后调用show()函数显示已绘制的图形。
示例完整代码如下:
#coding=utf-8
#By:Eastmount CSDN 2021-06-28
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv("data.csv", header=None)
print(data)
mm = data.sum() #求和
print(mm[1:]) #第一列为序号,取后面三列值
ind = np.arange(3) #3个用户 0 1 2
width = 0.35 #设置宽度
x = [u'用户A', u'用户B', u'用户C']
plt.rc('font', family='SimHei', size=13) #中文字体显示
#绘图
plt.bar(ind, mm[1:], width, color='r', label='sum num')
plt.xlabel(u"用户")
plt.ylabel(u"消费数据")
plt.title(u"用户消费数据对比柱状图")
plt.legend()
#设置底部名称
plt.xticks(ind+width/2, x, rotation=40) #旋转40度
plt.show()
下面详细讲解这部分的核心代码:
-
data = pd.read_csv(“data.csv”, header=None)
调用Pandas扩展包的read_cvs()读取test15_03.csv文件,将数据存储至data变量中。 -
mm = data.sum()
然后调用data.sum()函数求和,返回值为[55, 2134.510, 3017.120, 3951.095],对应三个用户的消费金额总额,第一列为十行数据序号求和。 -
import matplotlib.pyplot as plt
导入matplotlib.pyplot扩展包,pyplot是用来画图的方法,重命名为plt变量方便调用,比如显示图形时调用plt.show()函数即可,而不用调用matplotlib.pyplot.show()函数。 -
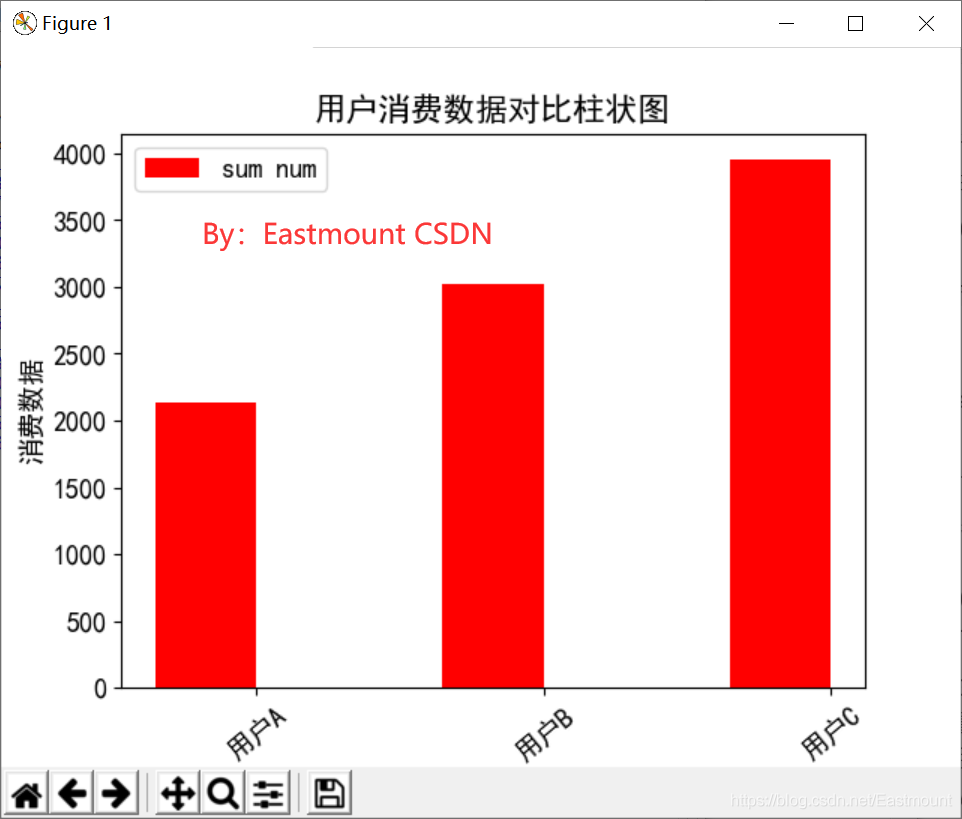
plt.bar(ind, mm[1:], width, color=‘r’, label=‘sum num’)
plt.bar()函数用于绘制条形图(Bar Plot)。参数ind值为[0,1,2],表示三个用户的序号;mm[1:]对应柱状图的高度,其值获取三个用户消费额总和(从第2个值开始获取);width表示柱状图之间间隔,即0.35;color表示设置柱状图的颜色,r表示红色;label是设置右上角的图形标注,自定义赋值为“sum num”。 -
plt.title(“用户消费数据对比柱状图”)
设置绘制图形的标题为“用户消费数据对比柱状图”。 -
plt.xlabel(“用户”)
表示绘制图形的X轴坐标标题,即为“用户”。 -
plt.ylabel(“消费数据”)
表示绘制图形的Y轴坐标标题,即为“消费数据”。 -
plt.legend()
表示设置右脚上的图例。 -
plt.grid()
表示绘制图形的背景网格线显示。 -
plt.show()
表示调用pyplot.show()将填充数据的图形显示出来。
输出如图所示:
注意:Matplotlib图显示中文通常为乱码,如果想在图表中能够显示中文字符和负号等,则需要增加下面这段代码进行设置。
import matplotlib.pyplot as plt
plt.rcParams['font.sas-serig']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
-
绘图库Matplotlib
安装配置、Matplotlib快速入门、图形绘制、风格和样式、Matplotlib扩展 -
Matplotlib快速入门
画布、子图与子图布局、坐标轴与刻度的名称、图例和文本标注、显示和保存
- 图形绘制
曲线图、散点图、直方图、饼图、箱线图、绘制图像、极坐标绘图
- 风格和样式
画布设置、子图布局、颜色、线条和点的样式、坐标轴、刻度、文本、图例、网格设置
- Matplotlib扩展
使用BaseMap绘制地图、3D绘图工具包

学习Python数据分析或机器学习,你就不得不知道Scikit-Learn扩展包。它是用于Python数据挖掘和数据分析的经典、实用扩展包,通常缩写为Sklearn。Scikit-Learn中的机器学习模型是非常丰富的,包括线性回归、决策树、SVM、KMeans、KNN、PCA等等,用户可以根据具体分析问题的类型选择该扩展包的合适模型,从而进行数据分析。
本系列后续数据分析的绝大部分内容都是基于该扩展包的,同时推荐大家学习官网的模型用法和实例文档。

Scikit-learn的基本功能主要被分为六个部分:
- 回归(Regression)
- 分类(Classification)
- 聚类(Clustering)
- 数据降维(Dimensionality Reduction)
- 模型选择(Model Selection)
- 数据预处理(Preprocessing)

例如下面代码对数据x、y数组进行简单聚类分析,代码如下:
#coding=utf-8
#By:Eastmount CSDN 2021-06-28
from sklearn.cluster import KMeans
X = [[1],[2],[3],[4],[5]]
y = [4,2,6,1,3]
clf = KMeans(n_clusters=2)
clf.fit(X,y)
print(clf)
print(clf.labels_)
调用Sklearn.cluster聚类包中KMeans()函数进行聚类,并且类簇数设置为2,即n_clusters=2。输出如下类标签为:[1 1 0 0 0],表示前2个点(1, 4)、(2, 2)为第1类,后三个点(3, 6)、(4, 1)、(5, 3)为第0类。更多聚类知识见后面文章。

-
机器学习工具包Scikit-learn
Scikit-learn概览、安装配置、数据集、数据预处理(Preprocessing)、分类(Classification)、回归(Regression)、聚类(Clustering)、成分分解与降维、模型评估与参数调优 -
数据集
Sklearn自带的数据集、样本生成器、加载其他数据集
- 数据预处理
标准化、归一化、正则化、离散化、特征编码、缺失值补全

- 分类
K近邻分类、贝叶斯分类、决策树分类、SVM分类、随机森林分类、集成学习(Bagging/Boosting)、神经网络模型
- 回归
线性回归、Lasso回归、支持向量机回归、K近邻回归、决策树回归、随机森林回归、逻辑回归
- 聚类
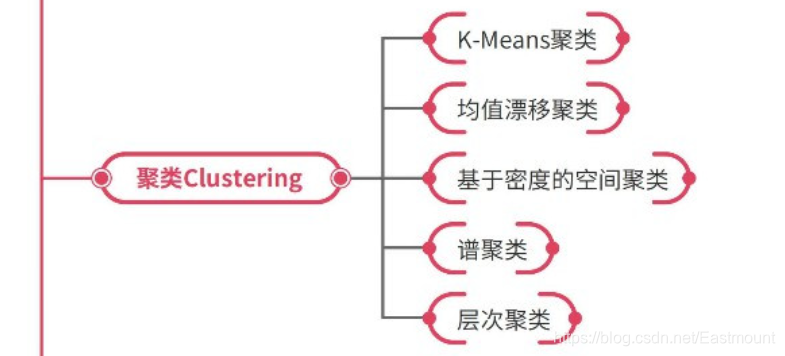
K-Means聚类、均值漂移聚类、基于密度的空间聚类、谱聚类、层次聚类
- 成分分解与降维
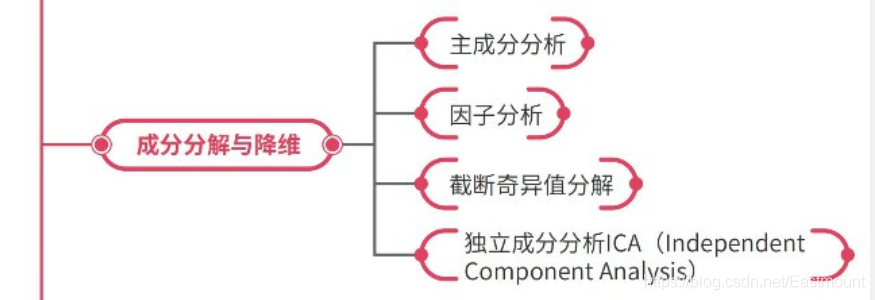
主成分分析、因子分析、截断奇异值分解、ICA
- 模型评估与参数调优
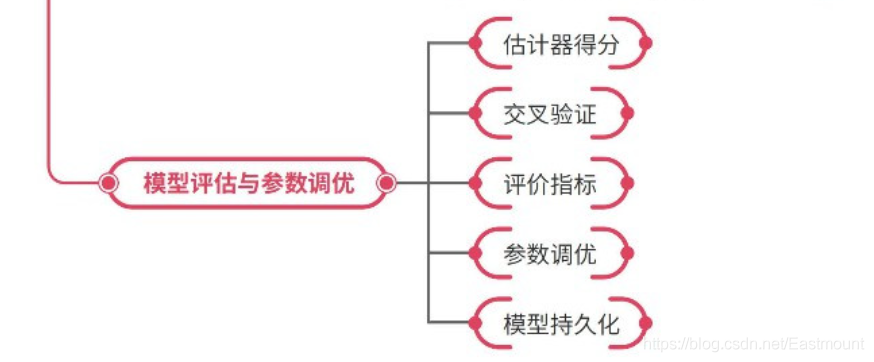
估计器得分、交叉验证、评价指标、参数调优、模型持久化
Python被广泛应用于数据分析或人工智能等领域,一部分原因就是因为其支持开源,拥有强大的第三方扩展包,比如Numpy、Scipy、Pandas、Matplotlib、Gensim、Statsmodels、Scikit-learn、Tensorflow等。本系列常用的数据分析包中,NumPy包用于数值计算;Scipy包用于数学、矩阵、科学和工程包计算;Pandas包用于数据分析和数据探索、可视化处理;Matplotlib包用于数据可视化、常用2D绘图领域;Sklearn包拥有众多的机器学习和数据分析算法。希望读者能认真学习本文讲解的各扩展包案例,后续文章也将围绕这些扩展包走进数据分析的世界。
该系列所有代码下载地址:
感谢在求学路上的同行者,不负遇见,勿忘初心。这周的留言感慨~
希望能与大家一起在华为云社区共同承载,原文地址:https://blog.csdn.net/Eastmount/article/details/118302426
【生长吧!Python】有奖征文火热进行中:https://bbs.huaweicloud.com/blogs/278897
(By:娜璋之家 Eastmount 2021-07-08 夜于武汉)
参考文献:
- [1] 杨秀璋. 专栏:知识图谱、web数据挖掘及NLP - CSDN博客[EB/OL]. (2016-09-19)[2017-11-07]. http://blog.csdn.net/column/details/eastmount-kgdmnlp.html.
- [2] matplotlib. Matplotlib官网[EB/OL]. (2002-2017)[2017-11-10]. http://matplotlib.org.
- [3] scikit-learn. Scikit-Learn官网[EB/OL]. (2017)[2017-11-10].http://scikit-learn.org/
stable/. - [4] pandas. Pandas官网[EB/OL]. (2017)[2017-11-10]. http://pandas.pydata.org/.
- [5] 杨秀璋.[Python数据挖掘课程] 一.安装Python及爬虫入门介绍 - CSDN博客[EB/OL].(2016-09-19)[2017-11-15]. http://blog.csdn.net/eastmount/article/details/52577215.
- [6] 杨秀璋.[Python数据挖掘课程] 六.Numpy、Pandas和Matplotlib包基础知识[EB/OL] . (2016-11-14)[2017-11-15]. http://blog.csdn.net/eastmount/article/details/53144633.
- [7] 达闻西. 给深度学习入门者的Python快速教程 - numpy和Matplotlib篇[EB/OL]. (2017)[2017-11-14]. https://zhuanlan.zhihu.com/p/24309547.
- [8] 张良均,王路,谭立云,苏剑林. Python数据分析与挖掘实战[M]. 北京:机械工业出版社,2016.
- [9] (美)Wes McKinney著. 唐学韬等译. 利用Python进行数据分析[M]. 北京:机械工业出版社,2013.