欢迎大家来到“Python从零到壹”,在这里我将分享约200篇Python系列文章,带大家一起去学习和玩耍,看看Python这个有趣的世界。所有文章都将结合案例、代码和作者的经验讲解,真心想把自己近十年的编程经验分享给大家,希望对您有所帮助,文章中不足之处也请海涵。Python系列整体框架包括基础语法10篇、网络爬虫30篇、可视化分析10篇、机器学习20篇、大数据分析20篇、图像识别30篇、人工智能40篇、Python安全20篇、其他技巧10篇。您的关注、点赞和转发就是对秀璋最大的支持,知识无价人有情,希望我们都能在人生路上开心快乐、共同成长。
前一篇文章讲述了 BeautifulSoup 爬取豆瓣TOP250电影,通过案例的方式让大家熟悉Python网络爬虫。这篇文章将详细讲解Requests库爬取豆瓣电影TOP250,并存储至CSV文件。豆瓣TOP250是非常适合入门的案例,也能普及简单的预处理知识。 希望对您有所帮助,本文参考了作者CSDN的文章和学生杨友的博客,从学生的角度实现网络爬虫,可能对读者更友好。参考链接如下:
文章目录
最后推荐大家关注我学生CSDN的博客,十分怀恋给他们上课的情形,博客也写得不错,写作风格和我也很像,哈哈~ 学生杨友问我 “他现在不编程该行了,觉得遗憾吗?” 我的回答是 “有点遗憾,但只要是我学生的选择,自己喜欢,我都支持;也希望他们积极的去做,把每一件事做好做深,如有需要定会帮助,一起加油!”
前文赏析:
requests模块是用Python语言编写的、基于urllib的第三方库,采用Apache2 Licensed开源协议的http库。它比urllib更方便简洁,既可以节约大量的工作,又完全满足http测试需求。requests是一个很实用的Python库,编写爬虫和测试服务器响应数据时经常会用到,使用requests可以轻而易举的完成浏览器相关操作。功能包括:
- 支持HTTP连接保持和连接池
- 支持使用cookie保持会话
- 支持文件上传
- 支持自动响应内容的编码
- 支持国际化的URL和POST数据自动编码
推荐大家从requests官方网站进行学习,这里只做简单介绍。官方文档地址:
假设读者已经使用“pip install requests”安装了requests模块,下面讲解该模块的基本用法。
1.导入requests模块
使用语句如下:
import requests
2.发送请求
requests模块可以发送http常用的两种请求:GET请求和POST请求。其中GET请求可以采用url参数传递数据,它是从服务器上获取数据;而POST请求是向服务器传递数据,该方法更为安全,更多用法请读者下来学习。
下面给出使用GET请求和POST请求获取某个网页的方法,得到一个命名为r的Response对象,通过这个对象获取我们所需的信息。
import requests
r = requests.get('https://github.com/timeline.json')
r = requests.post("http://httpbin.org/post")
其他方法如下:
requests.put("http://httpbin.org/put")
requests.delete("http://httpbin.org/delete")
requests.head("http://httpbin.org/get")
requests.options("http://httpbin.org/get")
3.传递参数
url通常会传递某种数据,这种数据采用键值对的参数形式置于url中,比如:
- http://www.eastmountyxz.com/index.php?key=value
requests通过params关键字设置url参数,以一个字符串字典来提供这些参数。假设作者想传递 key1=value1 和 key2=value2 到httpbin.org/get ,那么你可以使用如下代码:
import requests
payload = {'key1':'value1', 'key2':'value2'}
r = requests.get('http://httpbin.org/get', params=payload)
print(r.url)
print(r)
输出结果如下图所示:

4.响应内容
requests会自动解码来自服务器的内容,并且大多数Unicode字符集都能被无缝地解码。当请求发出后,Requests会基于HTTP头部对响应的编码作出有根据的推测。
使用语句如下:
import requests
r = requests.get('https://github.com/timeline.json')
print(r.text)
输出结果如下图所示:

常用响应内容包括:
- r.encoding
获取当前的编码 - r.encoding = ‘utf-8’
设置编码 - r.text
以encoding解析返回内容。字符串方式的响应体,会自动根据响应头部的字符编码进行解码 - r.content
以字节形式(二进制)返回。字节方式的响应体,会自动为你解码gzip和deflate压缩 - r.headers
以字典对象存储服务器响应头,但是这个字典比较特殊,字典键不区分大小写,若键不存在则返回None - r.status_code
响应状态码 - r.raw
返回原始响应体,也就是urllib的response对象,使用r.raw.read() - r.ok
查看r.ok的布尔值便可以知道是否登陆成功 - r.json()
Requests中内置的JSON解码器,以json形式返回,前提返回的内容确保是json格式的,不然解析出错会抛异常 - r.raise_for_status()
失败请求(非200响应)抛出异常
post发送json请求:
import requests
import json
r = requests.post('https://api.github.com/some/endpoint',
data=json.dumps({'some': 'data'}))
print(r.json())
5.定制请求头
如果你想为请求添加http头部,只要简单地传递一个字典(dict)给消息头headers参数即可。例如,我们给github网站指定一个消息头,则语句如下:
import requests
data = {'some': 'data'}
headers = {'content-type': 'application/json',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'}
r = requests.post('https://api.github.com/some/endpoint',
data=data,
headers=headers)
print(r.text)
输出结果如下图所示:

6.获取状态码和Cookies
- r.headers
返回字典类型,头信息 - r.requests.headers
返回发送到服务器的头信息 - r.status_code
响应状态码 - r.cookies
返回cookie - r.history
返回重定向信息,可以在请求是加上 allow_redirects = false 阻止重定向
具体示例如下:
import requests
#获取返回状态
r = requests.get('https://github.com/Ranxf')
print(r.status_code)
print(r.headers)
print(r.cookies)
#打印解码后的返回数据
r1 = requests.get(url='http://dict.baidu.com/s',
params={'wd': 'python'})
print(r1.url)
print(r1.text)
输出结果如下图所示:

同时响应状态码可以结合异常处理,如下:
import requests
URL = 'http://ip.taobao.com/service/getIpInfo.php' # 淘宝IP地址库API
try:
r = requests.get(URL, params={'ip': '8.8.8.8'}, timeout=1)
r.raise_for_status() # 如果响应状态码不是 200,就主动抛出异常
except requests.RequestException as e:
print(e)
else:
result = r.json()
print(type(result), result, sep='\n')
7.超时设置
设置秒数超时,仅对于链接有效。
r = requests.get('url',timeout=1)
8.代理设置
proxies = {'http':'ip1','https':'ip2' }
requests.get('url',proxies=proxies)
本小节只是简单介绍了requests模块,推荐读者下来结合案例和官方网站进行更深入的学习和操作。
豆瓣(Douban)是一个社区网站,创立于2005年3月6日。该网站以书影音起家,提供关于书籍、电影、音乐等作品的信息,其作品描述和评论都是由用户提供,是Web 2.0网站中具有特色的一个网站。
当我们拿到一个网页的时候,第一步并不是去测试它能否能使用requests简单请求到html,而是要去选择合适的方法进行爬取该网页,弄明白它数据的加载方式,才可以让我们的事半功倍,选择一个好的请求方法也可以提升我们爬虫程序的效率。
本文主要介绍爬取豆瓣电影排名前250名的电影信息。地址为:
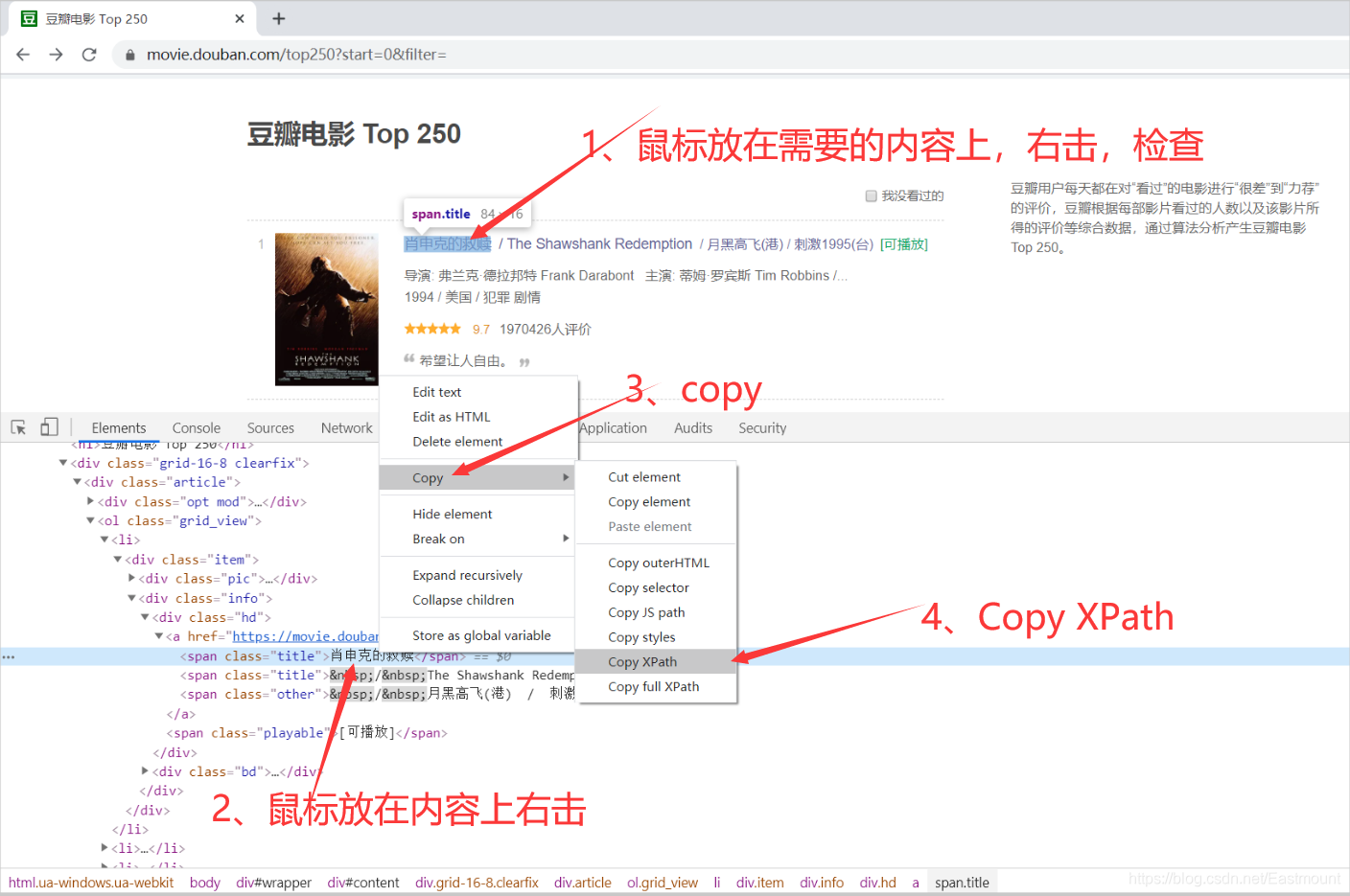
右键审查元素显示HTML源代码,如下图所示。

对应的HTML部分代码如下:
<li><div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img alt="肖申克的救赎"src="https://img3.doubanio.com/.../p480747492.webp" >
</a>
</div>
<div class="info">...</div>
</div></li>
网站翻页是网络爬虫中至关重要的一环,我们进入豆瓣电影 Top 250,查看它的网页结构。点击 “下一页” ,查看它的URL链接,会发现下面的规律:
第1页URL:https://movie.douban.com/top250?start=0&filter=
第2页URL:https://movie.douban.com/top250?start=25&filter=
第3页URL:https://movie.douban.com/top250?start=50&filter=
...
第10页URL:https://movie.douban.com/top250?start=225&filter=
它是存在一定规律的,top250?start=25表示获取第2页(序号为26到50号)的电影信息;top250?start=50表示获取第3页(序号为51到75号)的电影信息,依次类推。
方法一:
我们结合数学公式写一个循环获取完整的250部电影信息。核心代码如下:
i = 0
while i<10:
num = i*25 #每次显示25部 URL序号按25增加
url = 'https://movie.douban.com/top250?start=' + str(num) + '&filter='
crawl(url) #爬虫电影信息
i = i + 1
方法二:
需要写一个for循环,生成从0到225的数字即可,从上面的链接可以看出来,它的间隔为25,for page in range(0, 226, 25) 必须要取超过停止数据225,因为255不包含在其中,25是它的公差,程序表示为:
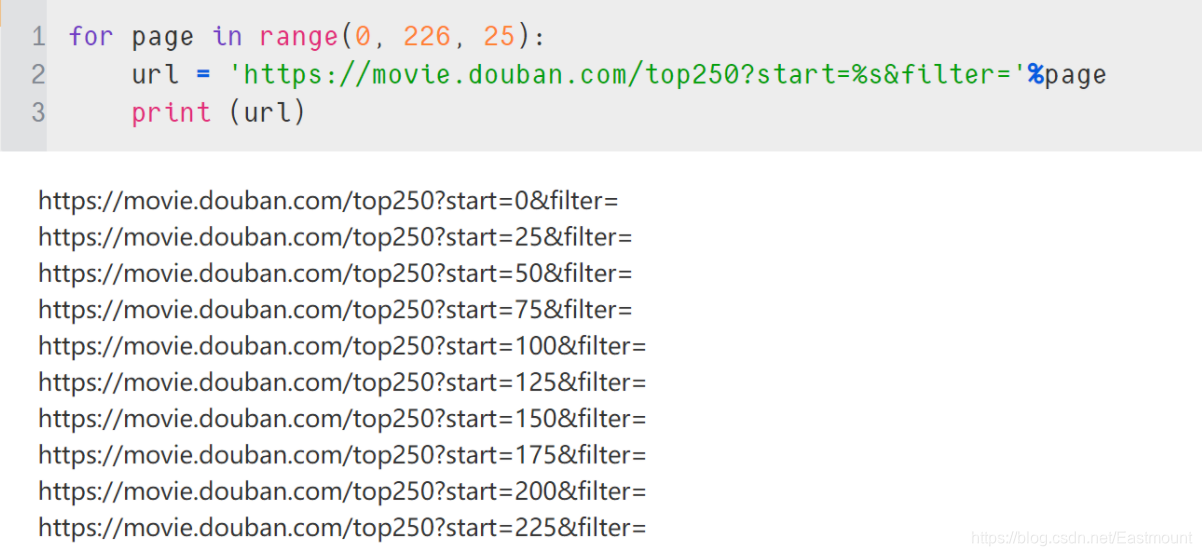
接下来使用python的requests库去代替浏览器请求网页的服务器,返回HTML文件,提取并保存信息,再生成下一页的链接,继续上面请求服务器的操作爬取信息。
在向服务器发出请求时,我们先选择第一个链接来进行测试,完成本页所有内容的获取,然后再获取所有页面的信息。
- 如果没有安转
requests, 可以使用pip直接安转 - 步骤:win+r运行——>cmd——>pip install requests
- 网页点击右键,打开检查,选择Network,All
- 刷新网页,选择第一个文件,双击,选择headers
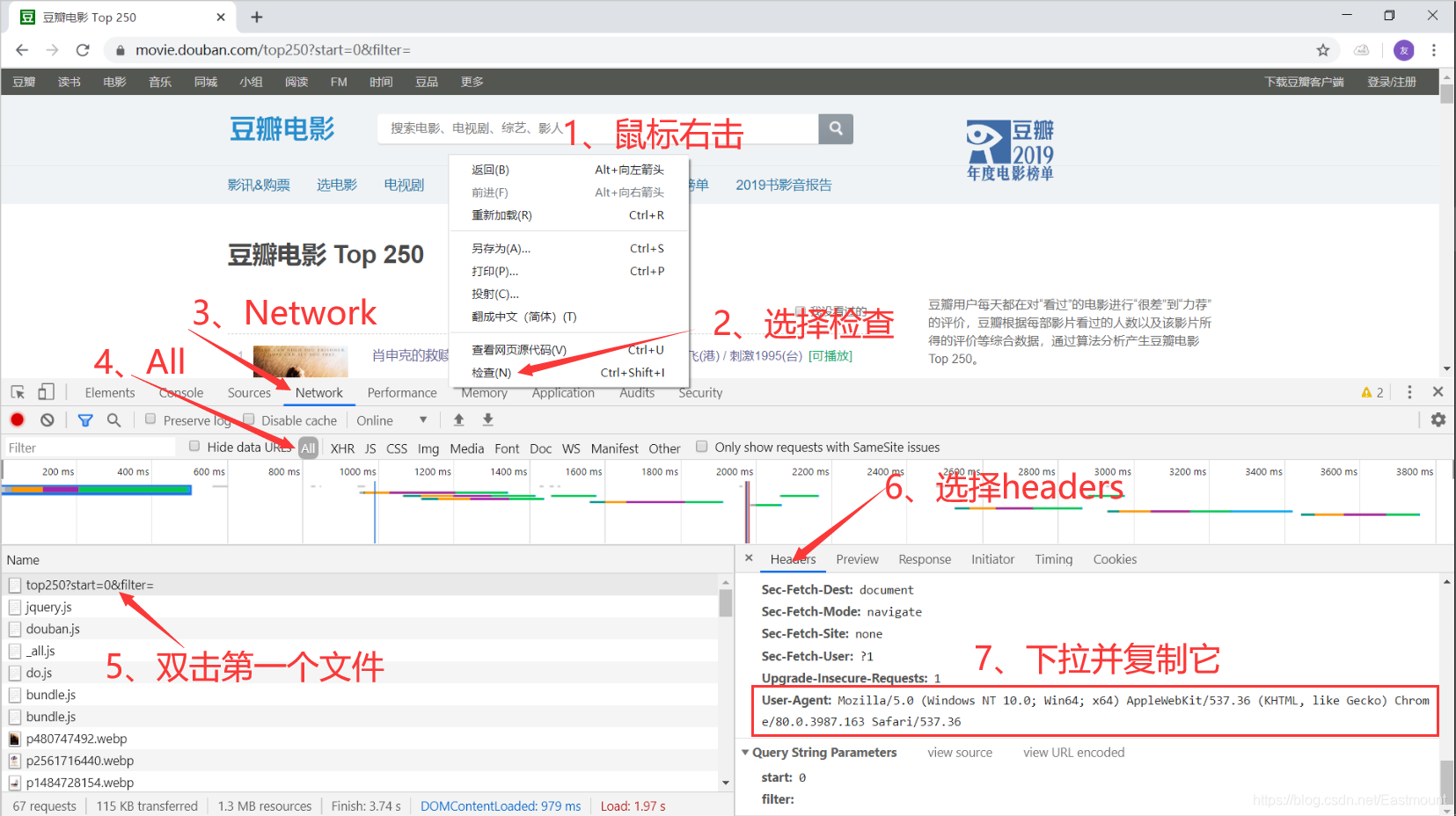
设置的浏览器代理必须为字典型,如:
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
请求源代码向服务器发出请求,200代表成功。如果在后面加上 .text 表示输出文本内容。
- url是用一个链接
- headers是用来做浏览器代理的内容
requests.get(url = url, headers = headers)
这里以第一页内容为例,核心代码如下所示:
import requests
#设置浏览器代理,它是一个字典
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
url = 'https://movie.douban.com/top250?start=0&filter='
#向服务器发出请求
r = requests.get(url = url, headers = headers)
print(r.text)
输出结果如下图所示:

xpath是按照HTML标签的方式进行定位的,谷歌浏览器自带有xpath,可以直接复制过来使用,简单方便,运行速度快。输出结果为:
- //*[@id=“content”]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]
我们使用xpath时,也必须先对网页进行 lxml 库中的 etree 解析,把它变为特有的树状形式,才能通过它进行节点定位。
from lxml import etree #导入解析库
html_etree = etree.HTML(reponse) #树状结构解析
当我们提取标签内的文本时,需要在复制到的xpath后面加上 /text() ,告诉它我们需要提取的内容是一个标签呈现的数据,如《肖申克的救赎》。
<span class="title">肖申克的救赎</span>
结合xpath所提取的文字代码为:
# coding:utf-8
# By:Eastmount 2021-02-25
import requests
from lxml import etree
#设置浏览器代理,它是一个字典
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
url = 'https://movie.douban.com/top250?start=0&filter='
#向服务器发出请求
r = requests.get(url = url, headers = headers).text
#解析DOM树结构
html_etree = etree.HTML(r)
name = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]/text()')
print ("这是数组形式:",name)
print ("这是字符串形式:",name[0])
输出结果如下所示:
这是数组形式: ['肖申克的救赎']
这是字符串形式: 肖申克的救赎
每一个链接都是在标签内的,通常放在 src=" " 或者 href=" " 之中,如

xpath为:
//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a
提取链接时,需要在复制到的xpath后面加上 /@href , 指定提取链接。
movie_url = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/@href')
print ("这是数组形式:",movie_url)
print ("这是字符串形式:",movie_url[0])
输出结果如下所示:
这是数组形式: ['https://movie.douban.com/subject/1292052/']
这是字符串形式: https://movie.douban.com/subject/1292052/
这个网页中电影的星级没有用几颗星的文本表示,而是标签表示的,如:

所以只需要取出 class=" " 中的内容就可以得到星级了,复制它的xpath,和提取链接的方法一样,在后面加上 /@class 即可。
rating = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[2]/div/span[1]/@class')
print ("这是数组形式:",rating)
print ("这是字符串形式:",rating[0])
输出结果如下所示:
这是数组形式: ['rating5-t']
这是字符串形式: rating5-t
前面第四篇文章我们详细介绍了正则表达式的内容,它常常会与网络爬虫和数据预处理结合起来,简化我们的工作。这里需要把结果中的信息匹配出来,可以使用正在表达式,单独提取自己需要的信息,如星级,它都是以 rating5-t 方式呈现的,但是我们只需要它数字5位置的部分,所以需要进行二次提取。
正则表达式中可以使用 .*? 来进行匹配信息,没有加括号时可以去掉不一样的信息,不需要提取出来,加括号 (.*?) 可以提取出括号内的内容,如:
import re
test = "rating5-t"
text = re.findall('rating(.*?)-t', test)
print (text)
输出结果为:
['5']
这里再举一个简单的例子:

比如评价数,我们xpath提取到的数据格式为: 1056830人评价 ,保存的时候只需要数字即可,现在把数字提取出来:
import re
data = "1059232人评价"
num = re.sub(r'\D', "", data)
print("这里的数字是:", num)
输出结果为:
这里的数字是: 1059232
我们在使用Python进行网络爬虫或数据分析时,通常会遇到CSV文件,类似于Excel表格。第三篇文章我们详细介绍了CSV文件的操作,保存内容与把大象放进冰箱是一样的,分别为打开冰箱,把大象装进去,关闭冰箱。这里我们进行简单说明。
基本流程如下:
- 导入CSV模块
- 创建一个CSV文件对象
- 写入CSV文件
- 关闭文件
# -*- coding: utf-8 -*-
import csv
c = open("test-01.csv", "w", encoding="utf8", newline='') #写文件
writer = csv.writer(c)
writer.writerow(['序号','姓名','年龄'])
tlist = []
tlist.append("1")
tlist.append("小明")
tlist.append("10")
writer.writerow(tlist)
print(tlist,type(tlist))
del tlist[:] #清空
tlist.append("2")
tlist.append("小红")
tlist.append("9")
writer.writerow(tlist)
print(tlist,type(tlist))
c.close()
输出结果如下图所示:

基本流程如下:
- 导入CSV模块
- 创建一个CSV文件对象
- 读取CSV文件
- 关闭文件
# -*- coding: utf-8 -*-
import csv
c = open("test-01.csv", "r", encoding="utf8") #读文件
reader = csv.reader(c)
for line in reader:
print(line[0],line[1],line[2])
c.close()
输出结果如下图所示:

在文件操作中编码问题是最让人头疼的,尤其Python2的时候。但只需要环境编码一致,注意相关转换也能有效解决,而Python3文件读写操作写清楚encoding编码方式就能正常显示。
通过前面的 xpath 只能提取到一条信息,如果我们要提取所有的信息,写一个 for 循环把它遍历出来即可。先复制几个电影名字的 xpath,如前三个的:

li 标签前的作为父级,后面的为子集,./ 代替父级的位置,改写为:
li = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li')
for item in li:
name = item.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0]
print (name)
此时的代码如下所示:
# coding:utf-8
# By:Eastmount & ayouleyang 2021-02-25
import requests
from lxml import etree
#设置浏览器代理,它是一个字典
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
url = 'https://movie.douban.com/top250?start=0&filter='
#向服务器发出请求
r = requests.get(url = url, headers = headers).text
#解析DOM树结构
html_etree = etree.HTML(r)
name = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]/text()')
print ("这是数组形式:",name)
print ("这是字符串形式:",name[0])
#提取链接
movie_url = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/@href')
print ("这是数组形式:",movie_url)
print ("这是字符串形式:",movie_url[0])
#提取打分
rating = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[2]/div/span[1]/@class')
print ("这是数组形式:",rating)
print ("这是字符串形式:",rating[0])
#提取本页所有电影名
li = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li')
for item in li:
name = item.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0]
print (name)
输出结果如下图所示:

最终代码如下所示:
# coding:utf-8
# By:Eastmount & ayouleyang 2021-02-25
import requests
from lxml import etree
import csv, re
#设置浏览器代理,它是一个字典
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
#创建文件夹并打开
fp = open("./豆瓣top250.csv", 'a', newline='', encoding = 'utf-8-sig')
writer = csv.writer(fp) #写入
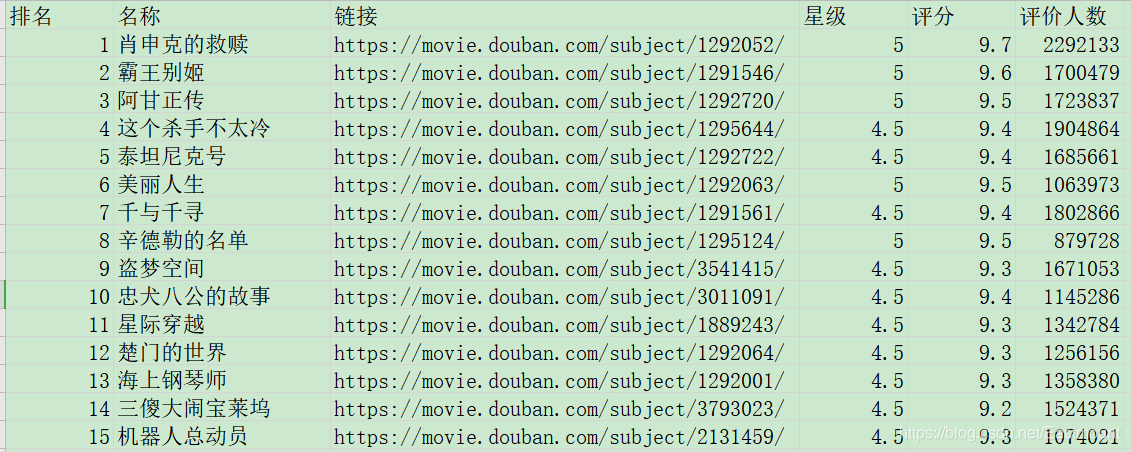
writer.writerow(('排名', '名称', '链接', '星级', '评分', '评价人数'))
#循环遍历TOP250的URL
for page in range(0, 226, 25): #226
print ("正在获取第%s页"%page)
url = 'https://movie.douban.com/top250?start=%s&filter='%page
#请求源代码
reponse = requests.get(url = url, headers = headers).text
#解析DOM树结构
html_etree = etree.HTML(reponse)
#定位节点 注意迭代xpath应用
li = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li')
for item in li:
#排名
rank = item.xpath('./div/div[1]/em/text()')[0]
#电影名称
name = item.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0]
#链接
dy_url = item.xpath('./div/div[2]/div[1]/a/@href')[0]
#评分 正则表达式提取
rating = item.xpath('./div/div[2]/div[2]/div/span[1]/@class')[0]
rating = re.findall('rating(.*?)-t', rating)[0]
if len(rating) == 2:
star = int(rating) / 10 #int()转化为数字
else:
star = rating
#评价人数
rating_num = item.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]
content = item.xpath('./div/div[2]/div[2]/div/span[4]/text()')[0]
content = re.sub(r'\D', "", content)
#print (rank, name, dy_url, star, rating_num, content)
#写入内容
writer.writerow((rank, name, dy_url, star, rating_num, content))
fp.close()
运行结果如下图所示:

最终保存的文件如下图所示:

在学习网络爬虫之前,读者首先要掌握分析网页节点、审查元素定位标签,甚至是翻页跳转、URL分析等知识,然后才是通过Python、Java或C#实现爬虫的代码。本文作者结合自己多年的网络爬虫开发经验,深入讲解了Requests技术网页分析并爬取了豆瓣电影信息,读者可以借用本章的分析方法,结合Requests库爬取所需的网页信息,并学会分析网页跳转,尽可能爬取完整的数据集。
该系列所有代码下载地址:
2020年在github的绿瓷砖终于贴完了第一年提交2100余次,获得1500多+stars,开源93个仓库,300个粉丝。挺开心的,希望自己能坚持在github打卡五年,督促自己不断前行。简单总结下,最满意的资源是YQ爆发时,去年2月分享的舆情分析和情感分析,用这系列有温度的代码为武汉加油;最高赞的是Python图像识别系列,也获得了第一位来自国外开发者的贡献补充;最花时间的是Wannacry逆向系列,花了我两月逆向分析,几乎成为了全网最详细的该蠕虫分析;还有AI系列、知识图谱实战、CVE复现、APT报告等等。当然也存在很多不足之处,希望来年分享更高质量的资源,也希望能将安全和AI顶会论文系列总结进来,真诚的希望它们能帮助到大家,感恩有你,一起加油~

希望能与大家一起在华为云社区共同承载,原文地址:https://blog.csdn.net/Eastmount/article/details/108887652
【生长吧!Python】有奖征文火热进行中:https://bbs.huaweicloud.com/blogs/278897
(By:娜璋之家 Eastmount 2021-07-07 夜于武汉 )
参考文献如下:
- 作者书籍《Python网络数据爬取及分析从入门到精通》
- python爬虫之爬取豆瓣电影top250实战教学 - 杨友
- 作者博客:https://blog.csdn.net/Eastmount
- 北京豆网科技有限公司——豆瓣
- https://2.python-requests.org/en/master/
- Python—requests模块详解 - lanyinhao