概述
在 Prometheus 的架构设计中,Prometheus Server 并不直接服务监控特定的目标,其主要任务负责数据的收集,存储并且对外提供数据查询支持。因此为了能够能够监控到某些东西,如主机的 CPU 使用率,我们需要使用到 Exporter。Prometheus 周期性的从 Exporter 暴露的 HTTP 服务地址(通常是 /metrics)拉取监控样本数据。
从上面的描述中可以看出 Exporter 可以是一个相对开放的概念,其可以是一个独立运行的程序独立于监控目标以外,也可以是直接内置在监控目标中。只要能够向 Prometheus 提供标准格式的监控样本数据即可。
这里为了能够采集到主机的运行指标如 CPU, 内存,磁盘等信息。我们可以使用 node_exporter。
node_exporter 用于采集服务器层面的运行指标,包括机器的 loadavg、filesystem、meminfo等基础监控,类似于传统主机监控维度的 zabbix-agent
node-export 由 prometheus 官方提供、维护,不会捆绑安装,但基本上是必备的 exporter
功能
node_exporter 用于提供 *NIX 内核的硬件以及系统指标。
-
如果是 windows 系统,可以使用 wmi_exporterr
-
如果是采集 NVIDIA 的 GPU 指标,可以使用 prometheus-dcgm
根据不同的 *NIX 操作系统,node_exporter 采集指标的支持也是不一样的,如: -
diskstats 支持 Darwin, Linux
-
cpu 支持Darwin, Dragonfly, FreeBSD, Linux, Solaris 等,
详细信息参考:node_exporter
我们可以使用 –collectors.enabled 参数指定node_exporter 收集的功能模块,或者用 –no-collector 指定不需要的模块,如果不指定,将使用默认配置。
安装
二进制包
node_exporter 同样采用 Golang 编写,并且不存在任何的第三方依赖,只需要下载,解压即可运行。可以从https://prometheus.io/download/ 获取最新的 node_exporter 版本的二进制包。
curl -OL https://github.com/prometheus/node_exporter/releases/download/v1.1.2/node_exporter-1.1.2.darwin-amd64.tar.gz
tar -xzf node_exporter-1.1.2.darwin-amd64.tar.gz
运行 node_exporter:
cd node_exporter-1.1.2.darwin-amd64
cp node_exporter-1.1.2.darwin-amd64/node_exporter /usr/local/bin/
node_exporter
启动成功后,可以看到以下输出:
INFO[0000] Listening on :9100 source="node_exporter.go:76"
访问 http://localhost:9100/ 可以看到以下结果:
# curl http://localhost:9100
<html>
<head><title>Node Exporter</title></head>
<body>
<h1>Node Exporter</h1>
<p><a href="/metrics">Metrics</a></p>
</body>
</html>
docker容器
docker run -d \
--net="host" \
--pid="host" \
-v "/:/host:ro,rslave" \
quay.io/prometheus/node-exporter \
--path.rootfs /host
使用 Kubernetes Operator 安装
参考:Kubernetes 集群监控 kube-prometheus 部署
node_exporter 监控指标
如果是二进制或者 docke r部署,部署成功后可以访问:http://${IP}:9100/metrics,可以看到当前 node_exporter 获取到的当前主机的所有监控数据,如下所示:
......
de_cpu_seconds_total{cpu="2",mode="nice"} 1.43
node_cpu_seconds_total{cpu="2",mode="softirq"} 77.66
node_cpu_seconds_total{cpu="2",mode="steal"} 618.42
node_cpu_seconds_total{cpu="2",mode="system"} 20981.5
node_cpu_seconds_total{cpu="2",mode="user"} 26925.45
node_cpu_seconds_total{cpu="3",mode="idle"} 2.52970118e+06
node_cpu_seconds_total{cpu="3",mode="iowait"} 58.83
node_cpu_seconds_total{cpu="3",mode="irq"} 0
node_cpu_seconds_total{cpu="3",mode="nice"} 1.57
node_cpu_seconds_total{cpu="3",mode="softirq"} 54.37
node_cpu_seconds_total{cpu="3",mode="steal"} 538.14
node_cpu_seconds_total{cpu="3",mode="system"} 18511.33
node_cpu_seconds_total{cpu="3",mode="user"} 24297.44
# HELP node_disk_io_now The number of I/Os currently in progress.
# TYPE node_disk_io_now gauge
node_disk_io_now{device="dm-0"} 0
node_disk_io_now{device="dm-1"} 0
node_disk_io_now{device="vda"} 0
# HELP node_disk_io_time_seconds_total Total seconds spent doing I/Os.
# TYPE node_disk_io_time_seconds_total counter
node_disk_io_time_seconds_total{device="dm-0"} 0.321
node_disk_io_time_seconds_total{device="dm-1"} 13765.443000000001
node_disk_io_time_seconds_total{device="vda"} 317.065
......
每一个监控指标之前都会有一段类似于如下形式的信息:
# HELP node_disk_io_time_seconds_total Total seconds spent doing I/Os.
# TYPE node_disk_io_time_seconds_total counter
node_disk_io_time_seconds_total{device="dm-0"} 0.321
node_disk_io_time_seconds_total{device="dm-1"} 13765.443000000001
node_disk_io_time_seconds_total{device="vda"} 317.065
其中 HELP 用于解释当前指标的含义,TYPE 则说明当前指标的数据类型。
除了这些以外,在当前页面中根据物理主机系统的不同,你还可能看到如下监控指标:
- node_boot_time_seconds:系统启动时间
- node_cpu_seconds_total:系统CPU使用量
- nodedisk*:磁盘IO
- nodefilesystem*:文件系统用量
- node_load1:系统负载
- node_memory*:内存使用量
- node_network*:网络带宽
- node_time:当前系统时间
- go_*:node exporter中go相关指标
- process_*:node exporter自身进程相关运行指标
配置 Prometheus
为了能够让 Prometheus Server 能够从当前 node exporter 获取到监控数据,这里需要修改 Prometheus 配置文件。编辑 prometheus.yml 并在 scrape_configs 节点下添加以下内容:
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
# 采集node exporter监控数据
- job_name: 'node'
static_configs:
- targets: ['172.16.106.84:9100']
重新启动 Prometheus Server
访问 http://${IP}:9090/,进入到 Prometheus Server。如果输入“up”并且点击执行按钮以后,可以看到如下结果:
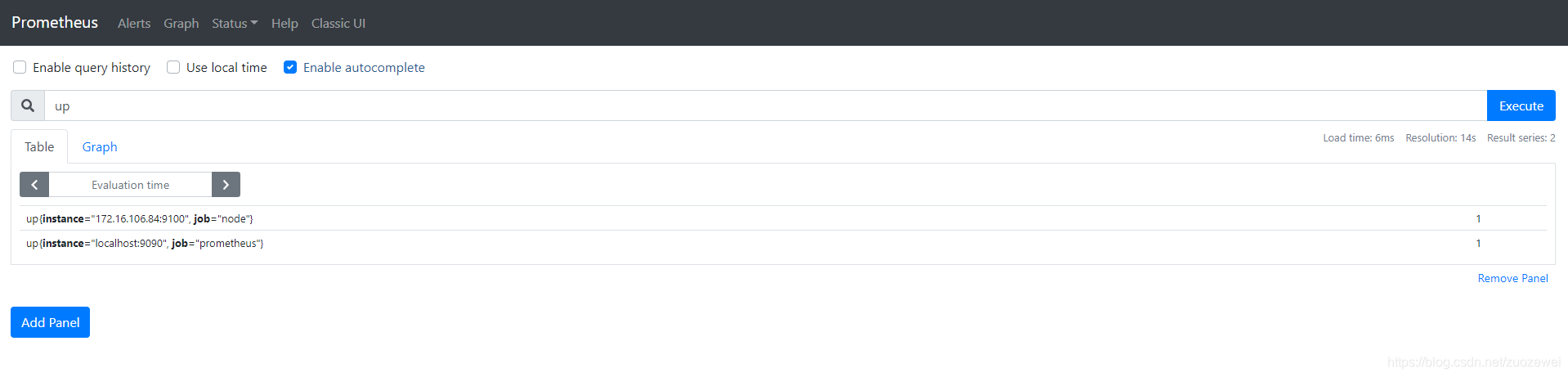
其中“1”表示正常,反之“0”则为异常。
此时查看 targets 状态:
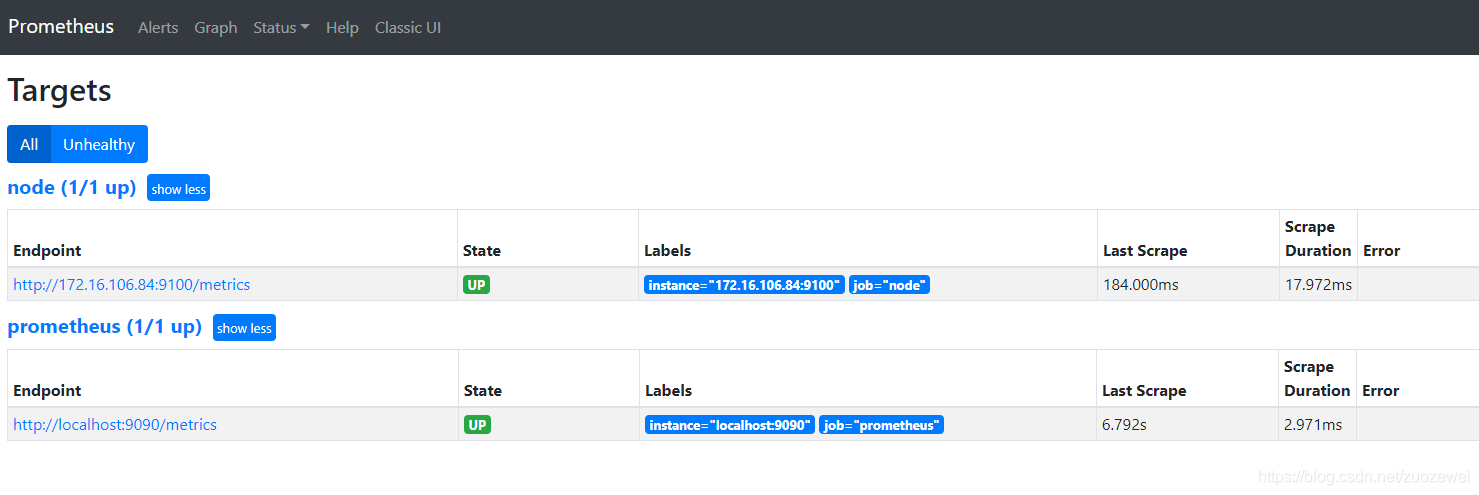
注意:对于而一组用于相同采集目的的实例,或者同一个采集进程的多个副本则通过一个一个任务(Job)进行管理。
* job: node
* instance 2: 1.2.3.4:9100
* instance 4: 5.6.7.8:9100
对于配置文件设置如下:
job_name: node
static_configs:
- targets: ['172.16.106.116:9100']
labels:
instance: vm-1
- targets: ['172.16.106.119:9100']
labels:
instance: vm-2
使用 PromQL 查询监控数据
Prometheus UI 是 Prometheus 内置的一个可视化管理界面,通过 Prometheus UI 用户能够轻松的了解 Prometheus 当前的配置,监控任务运行状态等。 通过 Graph 面板,用户还能直接使用 PromQL 实时查询监控数据,也可以使用 PromQL 表达式查询特定监控指标的监控数据。如下所示,查询主机负载变化情况,可以使用关键字 node_load1 可以查询出 Prometheus 采集到的主机负载的样本数据,这些样本数据按照时间先后顺序展示,形成了主机负载随时间变化的趋势图表:
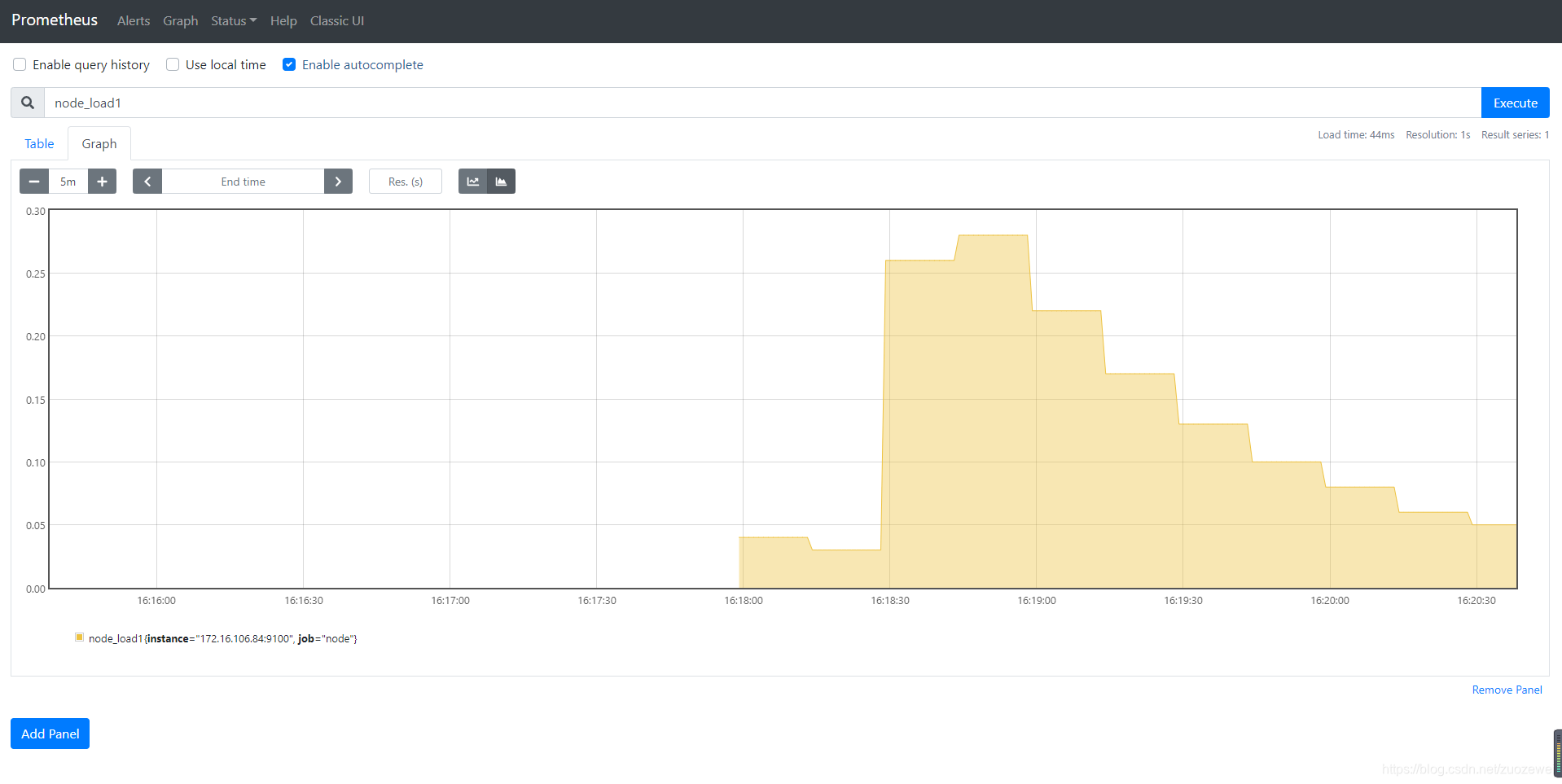
PromQL 是 Prometheus 自定义的一套强大的数据查询语言,除了使用监控指标作为查询关键字以为,还内置了大量的函数,帮助用户进一步对时序数据进行处理。例如使用 rate() 函数,可以计算在单位时间内样本数据的变化情况即增长率,因此通过该函数我们可以近似的通过 CPU 使用时间计算 CPU 的利用率:

这时如果要忽略是哪一个 CPU 的,只需要使用 without 表达式,将标签 CPU 去除后聚合数据即可:
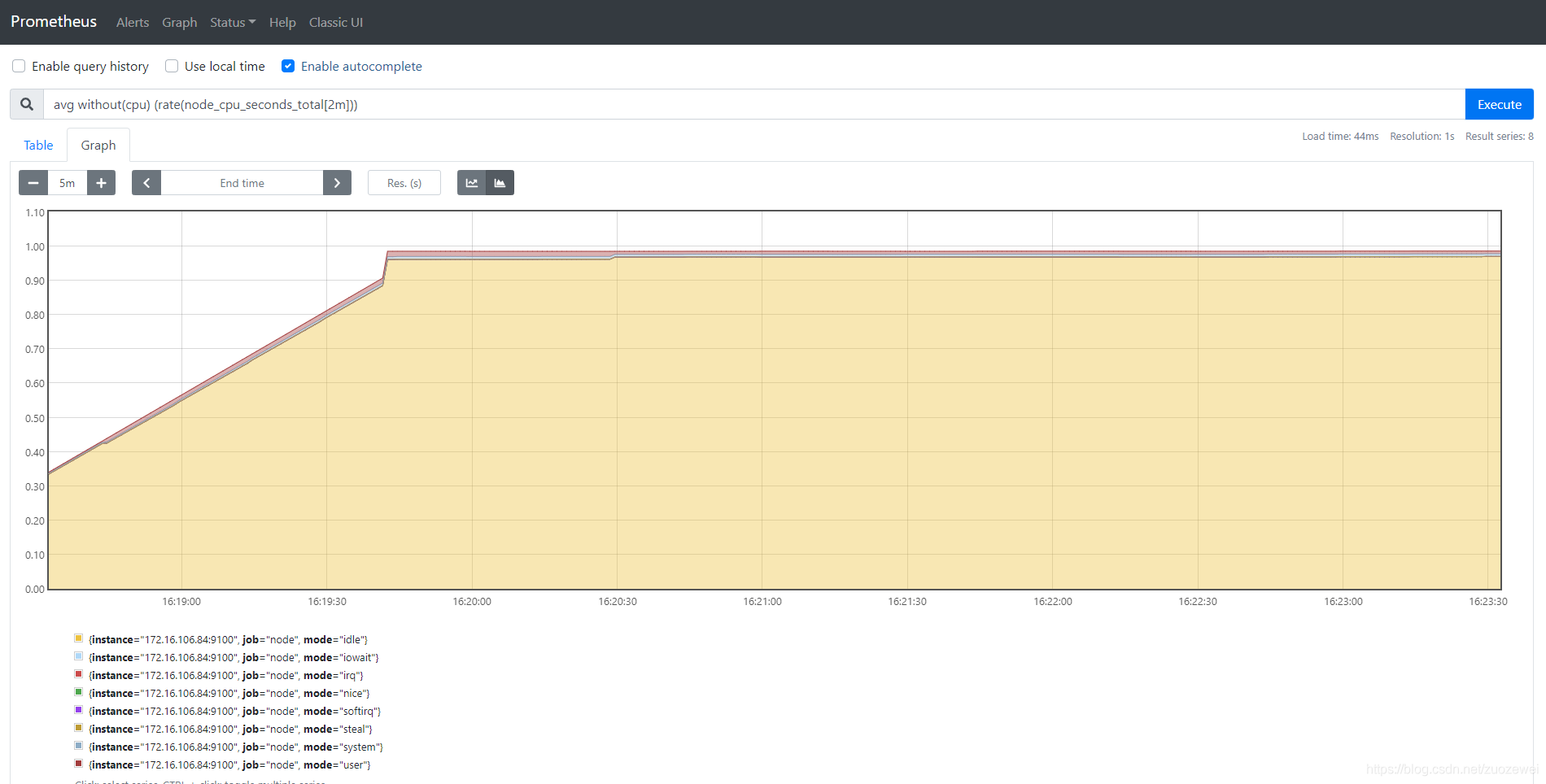
数据可视化
Prometheus UI 提供了快速验证 PromQL 以及临时可视化支持的能力,而在大多数场景下引入监控系统通常还需要构建可以长期使用的监控数据可视化面板(Dashboard)。这时用户可以考虑使用第三方的可视化工具如 Grafana,Grafana是一个开源的可视化平台,并且提供了对 Prometheus 的完整支持。
二进制包安装:
wget https://dl.grafana.com/oss/release/grafana-7.4.5.linux-amd64.tar.gz
tar -zxvf grafana-7.4.5.linux-amd64.tar.gz
docker 安装:
docker run -d --name=grafana -p 3000:3000 grafana/grafana
访问 http://localhost:3000 就可以进入到 Grafana 的界面中,默认情况下使用账户 admin/admin 进行登录。
在 Grafana 首页中显示默认的使用向导,包括:安装、添加数据源、创建 Dashboard、邀请成员、以及安装应用和插件等主要流程:

这里将添加 Prometheus 作为默认的数据源,如下图所示,指定数据源类型为 Prometheus 并且设置 Prometheus 的访问地址即可,在配置正确的情况下点击“Add”按钮,会提示连接成功的信息:
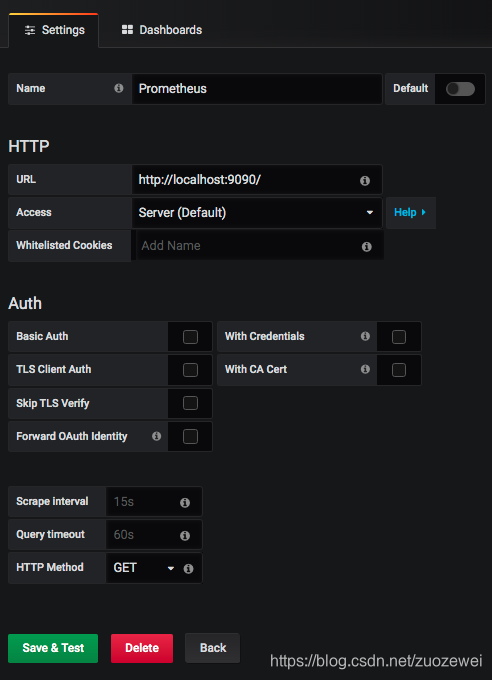
在完成数据源的添加之后就可以 在Grafana 中再配置一个 node_exporter 的模板,当然作为开源软件,Grafana 社区鼓励用户分享 Dashboard 通过 https://grafana.com/dashboards 网站,可以找到大量可直接使用的Dashboard:比如我这里选择了热门模板(ID:8919),展示效果如下:


扩展知识
推荐的exporter
node_exporterr 是Prometheus官方推荐的 exporter,类似的还有:
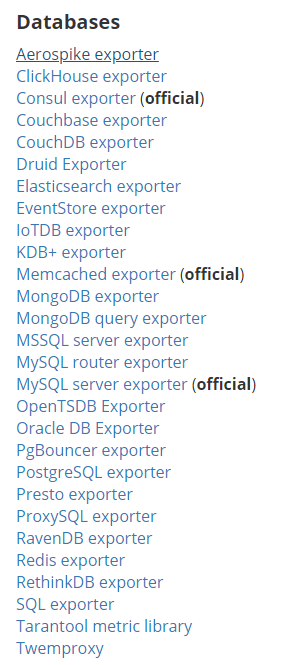
官方推荐的都会在 https://github.com/prometheus 下,在 exporter推荐页,也会有很多第三方的exporter,由个人或者组织开发上传,如果有自定义的采集需求,可以自己编写exporter。
注意版本
因为 node_exporter 是比较老的组件,有一些最佳实践并没有 merge 进去,比如符合 Prometheus 命名规范),因此建议使用较新版本,目前(2021.3)最新版本为 1.1.2
一些指标名字的变化(详细比对)
* node_cpu -> node_cpu_seconds_total
* node_memory_MemTotal -> node_memory_MemTotal_bytes
* node_memory_MemFree -> node_memory_MemFree_bytes
* node_filesystem_avail -> node_filesystem_avail_bytes
* node_filesystem_size -> node_filesystem_size_bytes
* node_disk_io_time_ms -> node_disk_io_time_seconds_total
* node_disk_reads_completed -> node_disk_reads_completed_total
* node_disk_sectors_written -> node_disk_written_bytes_total
* node_time -> node_time_seconds
* node_boot_time -> node_boot_time_seconds
* node_intr -> node_intr_total
解决版本问题的方法有两种:
- 一是在机器上启动两个版本的node-exporter,都让prometheus去采集。
- 二是使用指标转换器,他会将旧指标名称转换为新指标
- 对于 grafana 的展示,可以找同时支持两套指标的 dashboard 模板
实现原理
package main
import (
"fmt"
"net/http"
_ "net/http/pprof"
"os"
"os/user"
"sort"
"github.com/prometheus/common/promlog"
"github.com/prometheus/common/promlog/flag"
"github.com/go-kit/kit/log"
"github.com/go-kit/kit/log/level"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
"github.com/prometheus/common/version"
"github.com/prometheus/exporter-toolkit/web"
"github.com/prometheus/node_exporter/collector"
kingpin "gopkg.in/alecthomas/kingpin.v2"
)
可以看到 exporter 的实现需要引入 github.com/prometheus/client_golang/prometheus 库,client_golang 是 prometheus 的官方 go 库,既可以用于集成现有应用,也可以作为连接 Prometheus HTTP API 的基础库。
比如定义了基础的数据类型以及对应的方法:
Counter:收集事件次数等单调递增的数据
Gauge:收集当前的状态,比如数据库连接数
Histogram:收集随机正态分布数据,比如响应延迟
Summary:收集随机正态分布数据,和 Histogram 是类似的
参考地址:https://github.com/prometheus/client_golang/tree/master/prometheus
client_golang 库的详细解析可以参考:Prometheus 原理和源码分析
小结
或许有人觉得有了 Prometheus+Grafana+node_exporter 这样的组合工具之后,基本上都不再用手工执行什么命令了。但我们要了解的是,对于监控平台来说,它取的所有的数据必然是被监控者可以提供的数据,像 node_exporter 这样小巧的监控收集器,它可以获取的监控数据,并不是整个系统全部的性能数据,只是取到了常见的计数器而已。这些计数器不管是用命令查看,还是用这样炫酷的工具查看,它的值本身都不会变。所以不管是在监控平台上看到的数据,还是在命令行中看到的数据,我们最重要的是要知道含义以及这些值的变化对性能测试和分析的下一步骤的影响。
参考资料: