朴素贝叶斯原理
讲的很好不赘述了:
https://zhuanlan.zhihu.com/p/26262151
朴素贝叶斯例子

朴素贝叶斯文本分类:
完整可运行代码在最底下!!!
要实现的任务是根据已有的训练集:
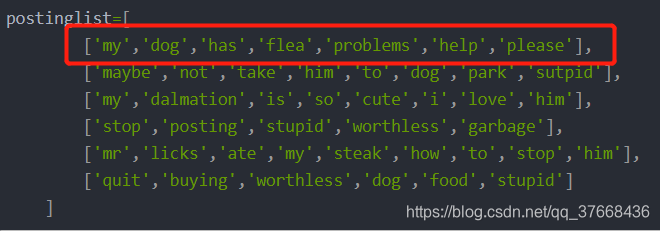
postinglist=[ ['my','dog','has','flea','problems','help','please'], ['maybe','not','take','him','to','dog','park','sutpid'], ['my','dalmation','is','so','cute','i','love','him'], ['stop','posting','stupid','worthless','garbage'], ['mr','licks','ate','my','steak','how','to','stop','him'], ['quit','buying','worthless','dog','food','stupid'] ]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
以及他的标签(0:表示积极 1:表示消极):
classvec=[ 0, 1, 0, 1, 0, 1
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
进行处理(也可以说是训练吧)之后对我们输入的词:
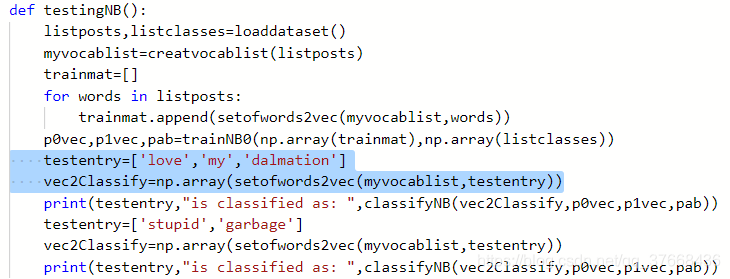
testentry=['love','my','dalmation']
testentry=['stupid','garbage']
- 1
- 2
进行一个类别的判断。得到结果:
['love', 'my', 'dalmation'] is classified as: 0
['stupid', 'garbage'] is classified as: 1
- 1
- 2
具体过程
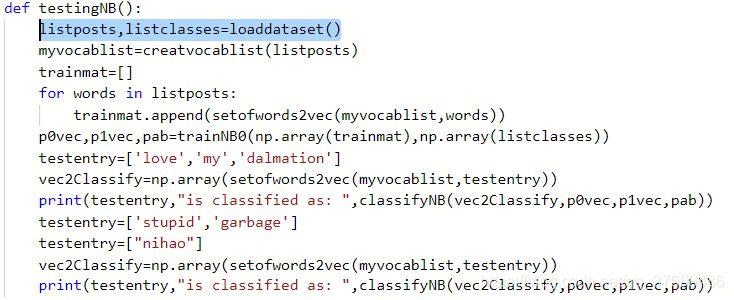
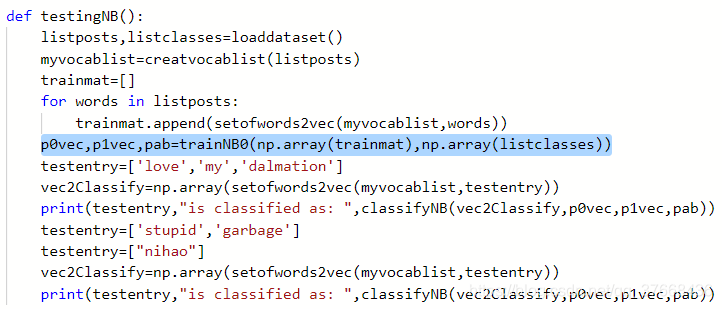
根据main函数中的testingNB介绍流程:
code1
def loaddataset(): postinglist=[ ['my','dog','has','flea','problems','help','please'], ['maybe','not','take','him','to','dog','park','sutpid'], ['my','dalmation','is','so','cute','i','love','him'], ['stop','posting','stupid','worthless','garbage'], ['mr','licks','ate','my','steak','how','to','stop','him'], ['quit','buying','worthless','dog','food','stupid'] ] classvec=[0,1,0,1,0,1] return postinglist,classvec
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
根据函数的定义
listposts=[ ['my','dog','has','flea','problems','help','please'], ['maybe','not','take','him','to','dog','park','sutpid'], ['my','dalmation','is','so','cute','i','love','him'], ['stop','posting','stupid','worthless','garbage'], ['mr','licks','ate','my','steak','how','to','stop','him'], ['quit','buying','worthless','dog','food','stupid'] ]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
listclasses=[0,1,0,1,0,1]
- 1
code2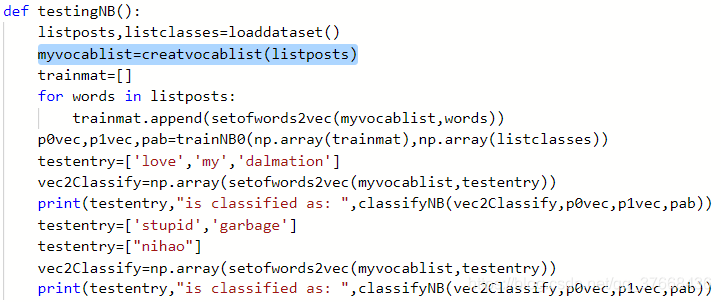
def creatvocablist(dataset): vocabset=set([]) for document in dataset: vocabset=vocabset|set(document) return list(vocabset)
- 1
- 2
- 3
- 4
- 5
这个函数document依次为
[‘my’,‘dog’,‘has’,‘flea’,‘problems’,‘help’,‘please’]
[‘maybe’,‘not’,‘take’,‘him’,‘to’,‘dog’,‘park’,‘sutpid’]
[‘my’,‘dalmation’,‘is’,‘so’,‘cute’,‘i’,‘love’,‘him’]
…
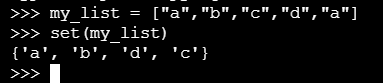
set函数对列表去重,例如:
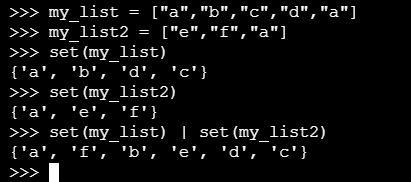
vocabset|set(document)是对两个列表取并集,例如:
因此这个函数执行完的输出为,对listposts去重后所有的单词的集合:
myvocablist =
[
'ate', 'cute', 'help', 'sutpid', 'i', 'love', 'stop', 'worthless', 'how', 'him', 'so',
'steak', 'my', 'food', 'quit', 'dog', 'garbage', 'flea', 'buying', 'please', 'take', 'has',
'dalmation', 'stupid', 'not', 'licks', 'to', 'maybe', 'posting', 'park', 'problems', 'is',
'mr'
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这个集合也就是我们训练集的字典,长度33.
code3
这段代码的输入是:
myvocablist =
[
'ate', 'cute', 'help', 'sutpid', 'i', 'love', 'stop', 'worthless', 'how', 'him', 'so',
'steak', 'my', 'food', 'quit', 'dog', 'garbage', 'flea', 'buying', 'please', 'take', 'has',
'dalmation', 'stupid', 'not', 'licks', 'to', 'maybe', 'posting', 'park', 'problems', 'is',
'mr'
]
postinglist=[ ['my','dog','has','flea','problems','help','please'], ['maybe','not','take','him','to','dog','park','sutpid'], ['my','dalmation','is','so','cute','i','love','him'], ['stop','posting','stupid','worthless','garbage'], ['mr','licks','ate','my','steak','how','to','stop','him'], ['quit','buying','worthless','dog','food','stupid'] ]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
输出trainmat是:

字典长度是33,postinglist的长度是6也就是6条训练数据,输出的trainmat长度是6 * 33
其实这段代码就是对输入的文本根据我们的字典进行编码:
例如第一行:
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0]
根据字典:
myvocablist =
[
'ate', 'cute', 'help', 'sutpid', 'i', 'love', 'stop', 'worthless', 'how', 'him', 'so',
'steak', 'my', 'food', 'quit', 'dog', 'garbage', 'flea', 'buying', 'please', 'take', 'has',
'dalmation', 'stupid', 'not', 'licks', 'to', 'maybe', 'posting', 'park', 'problems', 'is',
'mr'
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
可以解码成:help my dog flea please has problems
与第一条语料对应:
code4
def trainNB0(trainmatrix,traincategory): numtraindocs=len(trainmatrix) numwords=len(trainmatrix[0]) pAbusive=sum(traincategory)/float(numtraindocs) p0num=np.ones(numwords);p1num=np.ones(numwords) p0denom=2.0;p1denom=2.0 for i in range(numtraindocs): if traincategory[i]==1: p1num+=trainmatrix[i] p1denom+=sum(trainmatrix[i]) else: p0num+=trainmatrix[i] p0denom+=sum(trainmatrix[i]) p1vec=np.log(p1num/float(p1denom)) p0vec=np.log(p0num/float(p0denom)) return p0vec,p1vec,pAbusive
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
我们给这个函数的输入为编码的语料和这个语料对应的标签:
[
0,
1,
0,
1,
0,
1
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
因此可以知道每个值:
def trainNB0(trainmatrix,traincategory): numtraindocs=len(trainmatrix) # 6 numwords=len(trainmatrix[0]) # 33 pAbusive=sum(traincategory)/float(numtraindocs) # (0 + 1 + 0 + 1 + 0 + 1) / 6 = 1/2 p0num=np.ones(numwords);p1num=np.ones(numwords) # 创建两个33个1的矩阵, 拉普拉斯平滑(加1平滑),解决0概率出现问题 p0denom=2.0;p1denom=2.0
- 1
- 2
- 3
- 4
- 5
- 6
下面这段代码就是判断当前语料的标签是0还是1,是1的把这个语料中每个词出现几次加到p1num中存起来。是0的加到p0num中。p1denom记录1类别中总的词数,p0denom同理。
for i in range(numtraindocs): if traincategory[i]==1: p1num+=trainmatrix[i] p1denom+=sum(trainmatrix[i]) else: p0num+=trainmatrix[i] p0denom+=sum(trainmatrix[i])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
p1vec=np.log(p1num/float(p1denom))#消极类中该词汇出现的概率,取对数是防止浮点数下溢出
p0vec=np.log(p0num/float(p0denom))#积极类中该词汇的概率
- 1
- 2
浮点数下溢解释:当两个非常小的数相乘时,所得结果会更小,计算机在处理浮点数时,如果超出了浮点数的表示范围就会丢失掉非常低位的精度,由于log有性质:ln(a * b) = ln(a) + ln(b),因此可以对连乘进行取log这样换成log值相加就不会出现浮点数下溢的情况。
code5
def setofwords2vec(vocabset,inputset): returnvec=[0]*len(vocabset) for word in inputset: if word in vocabset: returnvec[vocabset.index(word)]=1 else: print("the word %s is not in my vocabulary"%word) return returnvec
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这段代码和处理训练的语料一样,把用于测试的语料转成1 * 33的向量表示。
code6
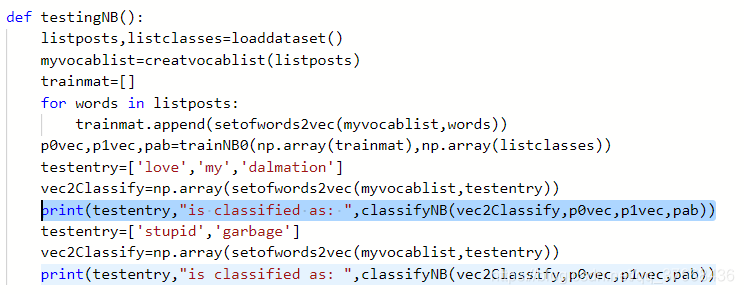
def classifyNB(vec2Classify,p0vec,p1vec,pclass1): p1=sum(vec2Classify*p1vec)+np.log(pclass1) p0=sum(vec2Classify*p0vec)+np.log(1-pclass1) if p1>p0: return 1 else: return 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
p1=sum(vec2Classifyp1vec)+np.log(pclass1)这句把标签为1且测试的单词在训练集中出现的频率累加
p0=sum(vec2Classifyp0vec)+np.log(1-pclass1)这句把标签为0且测试的单词在训练集中出现的频率累加
最后判断p1和p0谁大就属于哪一个类别!
完整代码(python3可运行)
import numpy as np
def loaddataset(): postinglist=[ ['my','dog','has','flea','problems','help','please'], ['maybe','not','take','him','to','dog','park','sutpid'], ['my','dalmation','is','so','cute','i','love','him'], ['stop','posting','stupid','worthless','garbage'], ['mr','licks','ate','my','steak','how','to','stop','him'], ['quit','buying','worthless','dog','food','stupid'] ] classvec=[0,1,0,1,0,1] return postinglist,classvec
def creatvocablist(dataset): vocabset=set([]) for document in dataset: vocabset=vocabset|set(document) return list(vocabset)
def setofwords2vec(vocabset,inputset): returnvec=[0]*len(vocabset) for word in inputset: if word in vocabset: returnvec[vocabset.index(word)]=1 else: print("the word %s is not in my vocabulary"%word) return returnvec
def trainNB0(trainmatrix,traincategory): numtraindocs=len(trainmatrix) numwords=len(trainmatrix[0]) pAbusive=sum(traincategory)/float(numtraindocs) p0num=np.ones(numwords);p1num=np.ones(numwords) p0denom=2.0;p1denom=2.0 for i in range(numtraindocs): if traincategory[i]==1: p1num+=trainmatrix[i] p1denom+=sum(trainmatrix[i]) else: p0num+=trainmatrix[i] p0denom+=sum(trainmatrix[i]) p1vec=np.log(p1num/float(p1denom)) p0vec=np.log(p0num/float(p0denom)) return p0vec,p1vec,pAbusive
def classifyNB(vec2Classify,p0vec,p1vec,pclass1): p1=sum(vec2Classify*p1vec)+np.log(pclass1) p0=sum(vec2Classify*p0vec)+np.log(1-pclass1) if p1>p0: return 1 else: return 0
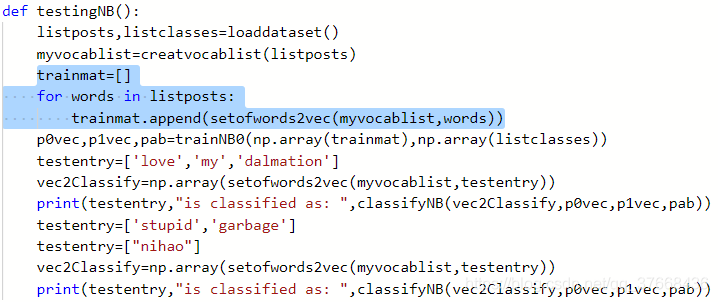
def testingNB(): listposts,listclasses=loaddataset() myvocablist=creatvocablist(listposts) trainmat=[] for words in listposts: trainmat.append(setofwords2vec(myvocablist,words)) p0vec,p1vec,pab=trainNB0(np.array(trainmat),np.array(listclasses)) testentry=['love','my','dalmation'] vec2Classify=np.array(setofwords2vec(myvocablist,testentry)) print(testentry,"is classified as: ",classifyNB(vec2Classify,p0vec,p1vec,pab)) testentry=['stupid','garbage'] vec2Classify=np.array(setofwords2vec(myvocablist,testentry)) print(testentry,"is classified as: ",classifyNB(vec2Classify,p0vec,p1vec,pab))
if __name__ == '__main__': testingNB()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
运行结果:

文章来源: blog.csdn.net,作者:只会git clone的程序员,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_37668436/article/details/115034088