Python RegEx:
正则表达式可用于搜索,编辑和处理文本。这将在Python下的所有子域中打开各种各样的应用程序。Python RegEx几乎被所有初创公司广泛使用,在其应用程序方面具有良好的行业吸引力,并使正则表达式成为现代程序员的资产。
在此Python RegEx博客中,我们将检查以下概念:
- Why we use Regular Expressions?
- What are Regular Expressions?
- Basic Regular Expressions operations
- Email verification using Regular Expressions
- Phone number verification using Regular Expressions
- Web Scraping using Regular Expressions
为什么要使用正则表达式?
为了回答这个问题,我们将看看我们面临的各种问题,这些问题又可以通过使用正则表达式解决。
请考虑以下情形:
您有一个包含大量数据的日志文件。从此日志文件中,您只希望获取日期和时间。正如您所看到的图像,乍看之下日志文件的可读性很低。

在这种情况下,可以使用正则表达式来识别模式并轻松提取所需的信息。
考虑下一种情况–您是一名销售人员,您有很多电子邮件地址,其中许多地址是伪造的/无效的。看看下面的图片:

您可以做的是,您可以使用正则表达式来验证电子邮件地址的格式,并从真实的ID中过滤出虚假的ID。
下一个场景与带有销售员示例的场景非常相似。考虑下图:

我们如何验证电话号码,然后根据原籍国对其进行分类?
每个正确的数字都会有一个特定的模式,可以使用正则表达式对其进行跟踪和跟踪。
接下来是另一个简单的场景:

我们有一个学生数据库,其中包含姓名,年龄和地址等详细信息。考虑一下区号最初为59006但现在已更改为59076的情况。为每个学生手动更新区号将很耗时,而且过程很漫长。
基本上,要使用正则表达式解决这些问题,我们首先从包含PIN码的学生数据中找到一个特定的字符串,然后将其全部替换为新的字符串。
正则表达式可以与多种语言一起使用。如:
- Java
- Python
- Ruby
- Swift
- Scala
- Groovy
- C#
- PHP
- Javascript
正则表达式还可以帮助我们解决其他n种情况。我将在此Python RegEx博客的后续部分中向您介绍相同的内容。
因此,接下来在这个Python RegEx博客上,让我们看一下正则表达式实际上是什么。
什么是正则表达式?
正则表达式用于标识文本字符串中的搜索模式。它还有助于找出数据的正确性,甚至可以使用正则表达式进行诸如查找,替换和格式化数据之类的操作。
考虑以下示例:
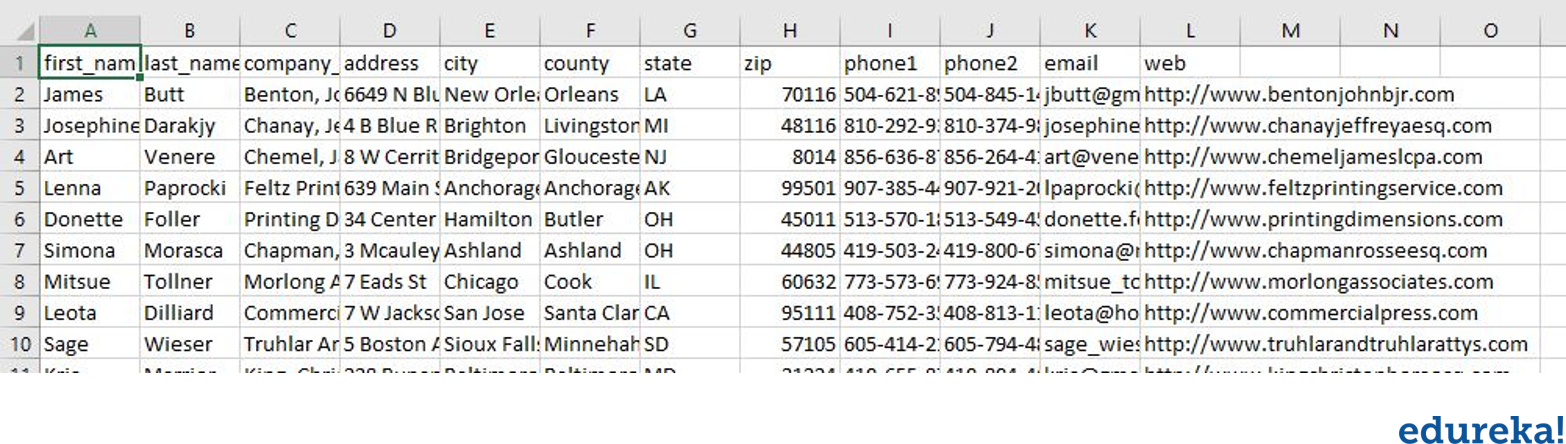
在给定字符串的所有数据中,让我们说我们只需要城市。可以将其转换为仅包含名称和城市的格式化字典。现在的问题是,我们可以确定一种模式来猜测名称和城市吗?另外,我们也可以找到年龄。随着年龄的增长,这很容易,对吧?它只是一个整数。
我们该如何命名?如果看一下模式,所有名称都以大写字母开头。借助正则表达式,我们可以使用此方法识别姓名和年龄。
考虑以下代码:
import re
Nameage = '''
Janice is 22 and Theon is 33
Gabriel is 44 and Joey is 21
'''
ages = re.findall(r'd{1,3}', Nameage)
names = re.findall(r'[A-Z][a-z]*',Nameage)
ageDict = {}
x = 0
for eachname in names
ageDict[eachname] = ages[x]
x+=1
print(ageDict)此时无需担心语法,但是由于Python具有出色的可读性,因此您可以很好地猜测代码的正则表达式部分正在发生什么。
{'Janice':'22','Theon':'33','Gabriel':'44','Joey':'21'}接下来在这个Python RegEx博客上,让我们检查一下使用正则表达式可以执行的所有操作。
您可以使用正则表达式执行的操作-RegEx示例:
您可以通过使用正则表达式执行许多操作。在这里,我列出了一些对帮助您更好地了解正则表达式的用法至关重要的东西。
让我们开始这个Python RegEx博客,首先检查如何在字符串中找到一个特定的单词。
在字符串中查找一个单词:
考虑以下代码:
import re
if re.search("inform","we need to inform him with the latest information"):
print("There is inform")我们在这里所做的所有搜索都是为了在搜索字符串中是否存在单词notify。如果是的话,那么我们将得到一个输出,说那里是notify。
我们可以通过编写将执行类似操作的方法来稍微增加一点。
import re
allinform = re.findall("inform","We need to inform him with the latest information!")
for i in allinform:
print(i)在此情况下,在此情况下,将两次发现通知。一个来自信息,另一个来自信息。
这样就很容易在正则表达式中找到一个单词,如上所示。
接下来在此Python RegEx博客上,我们将介绍如何使用正则表达式生成迭代器。
生成迭代器:
生成迭代器是查找并报告字符串的开始和结束索引的简单过程。考虑以下示例:
import re
Str = "we need to inform him with the latest information"
for i in re.finditer("inform.", Str):
locTuple = i.span()
print(locTuple)对于找到的每个匹配项,都会打印开始索引和结束索引。当执行上述程序时,您能猜出我们得到的输出吗?在下面查看。
输出:
(11, 18)
(38, 45)很简单,对不对?
接下来在这个Python RegEx博客上,我们将检查如何使用正则表达式将单词与模式匹配。
将单词与模式匹配:
考虑一个输入字符串,在该字符串中您必须将某些单词与该字符串匹配。要详细说明,请查看以下示例代码:
import re
Str = "Sat, hat, mat, pat"
allStr = re.findall("[shmp]at", Str)
for i in allStr:
print(i)字符串中有什么共同点?您会看到字母“ a”和“ t”在所有输入字符串中都是通用的。代码中的[shmp]表示要找到的单词的起始字母。因此,将考虑以字母s,h,m或p开头的任何子字符串进行匹配。其中的任何一个都必须在末尾加上“ at”。
输出:
hat
mat
pat请注意,它们都区分大小写。正则表达式具有惊人的可读性。一旦了解了基础知识,就可以全面展开这些知识了,这很容易,对吗?
接下来在这个Python RegEx博客上,我们将检查如何使用正则表达式一次匹配一系列字符。
匹配的字符范围系列:
我们希望输出所有首字母应在h和m之间并强制在at之后的所有单词。看看下面的例子,我们应该意识到应该得到的输出是帽子和垫子,对吗?
import re
Str = "sat, hat, mat, pat"
someStr = re.findall("[h-m]at", Str)
for i in someStr:
print(i)输出:
hat
mat现在让我们对上述程序进行非常小的更改,以获得截然不同的结果。查看下面的代码,并尝试捕捉上一个和下一个之间的区别:
import re
Str = "sat, hat, mat, pat"
someStr = re.findall("[^h-m]at", Str)
for i in someStr:
print(i)发现细微的差别?我们在正则表达式中添加了脱字符号(^)。这样做会否定随后发生的一切的影响。除了向我们提供从h到m的所有内容的输出之外,我们还将向您提供除此以外的所有内容的输出。
我们可以预期的输出是单词,该单词不是以h和m之间的字母开头,而是最后一个字母。
输出:
sat
pat接下来,在此Python RegEx博客上,我将说明如何使用正则表达式替换字符串。
替换字符串:
接下来,我们可以使用正则表达式签出另一个操作,在该操作中,我们用其他东西替换字符串的项。它非常简单,可以用下面的代码来说明:
import re
Food = "hat rat mat pat"
regex = re.compile("[r]at")
Food = regex.sub("food", Food)
print(Food)在上面的示例中,单词rat被替换为food。最终输出将如下所示。正则表达式的替代方法就是利用这种情况,它也具有各种各样的实际用例。
输出:
hat food mat pat接下来在此Python RegEx博客上,我们将检查Python的一个独特问题,称为Python反斜杠问题。
反斜杠问题:
考虑下面显示的示例代码:
import re
randstr = "Here is Edureka"
print(randstr)输出:
Here is Edureka这是反斜杠问题。斜杠之一从输出中消失。可以使用正则表达式解决此特定问题。
import re
randstr = "Here is Edureka"
print(re.search(r"Edureka", randstr))输出如下:
<re.Match对象;span =(8,16),match ='Edureka'>如您所见,找到了双斜杠的匹配项。这就是使用正则表达式解决反斜杠问题的简单程度。
接下来在这个Python RegEx博客上,我将引导您逐步了解如何使用正则表达式匹配单个字符。
匹配单个字符:
字符串中的单个字符可以使用正则表达式轻松进行单独匹配。查看以下代码段:
import re
randstr = "12345"
print("Matches: ", len(re.findall("d{5}", randstr)))预期的输出是给定输入字符串中出现的第5个数字。
输出:
符合条件:1接下来在这个Python RegEx博客上,我将引导您逐步了解如何使用正则表达式删除换行符空间。
删除换行符空间:
我们可以在Python中使用正则表达式轻松删除换行符空间。考虑如下所示的另一段代码:
import re
randstr = '''
You Never
Walk Alone
Liverpool FC
'''
print(randstr)
regex = re.compile("
")
randstr = regex.sub(" ", randstr)
print(randstr)输出:
You Never
Walk Alone
Liverpool FC
You Never Walk Alone Liverpool FC您可以从上面的输出中签出,新行已替换为空格,并且输出打印在一行上。
根据替换字符串的方式,您还可以使用其他许多东西。它们列出如下:
- :退格键
- :换页
:回车- :制表符
- :垂直制表符
考虑另一个示例,如下所示:
import re
randstr = "12345"
print("Matches:", len(re.findall("d", randstr)))输出:
Matches: 5从上面的输出中可以看到,d匹配字符串中存在的整数。但是,如果我们将其替换为D,它将与所有内容匹配但与d完全相反的整数。
接下来在这个Python RegEx博客上,让我们逐步介绍一些在Python中使用正则表达式的重要实际用例。
正则表达式的实际用例
我们将检查每天广泛使用的3个主要用例。以下是我们将要检查的概念:
- Phone Number Verification
- E-mail Address Verification
- Web Scraping
让我们通过检查第一种情况开始Python RegEx教程的这一部分。
电话号码验证:
问题陈述–需要在任何相关情况下轻松验证电话号码。
考虑以下电话号码:
- 444-122-1234
- 123-122-78999
- 111-123-23
- 67-7890-2019
电话号码的一般格式如下:
- Starts with 3 digits and ‘-‘ sign
- 3 middle digits and ‘-‘ sign
- 4 digits in the end
在下面的示例中,我们将使用w。请注意,w = [a-zA-Z0-9_]
import re
phn = "412-555-1212"
if re.search("w{3}-w{3}-w{4}", phn):
print("Valid phone number")输出:
Valid phone number电子邮件验证:
问题陈述–在任何情况下都要验证电子邮件地址的有效性。
考虑以下电子邮件地址示例:
- Anirudh@gmail.com
- Anirudh @ com
- AC .com
- 123 @.com
手动地,您只需一眼就可以从无效的ID中识别出有效的邮件ID。但是,如何让我们的程序为我们做到这一点呢?考虑到针对该用例遵循以下准则,这非常简单。
指导原则:
所有电子邮件地址应包括:
- 1 to 20 lowercase and/or uppercase letters, numbers, plus . _ % +
- An @ symbol
- 2 to 20 lowercase and uppercase letters, numbers and plus
- A period symbol
- 2 to 3 lowercase and uppercase letters
代码:
import re
email = "ac@aol.com md@.com @seo.com dc@.com"
print("Email Matches: ", len(re.findall("[w._%+-]{1,20}@[w.-]{2,20}.[A-Za-z]{2,3}", email)))
输出:
Email Matches: 1从上面的输出中可以看到,在输入的4封电子邮件中,我们只有一封有效的邮件。
这基本上证明了使用正则表达式并实际使用它们是多么简单和高效。
网页抓取
问题陈述–根据要求删除网站上的所有电话号码。
要了解网页抓取,请查看下图:

我们已经知道,一个网站将包含多个网页。让我们说我们需要从这些页面中抓取一些信息。
基本上,Web抓取用于从网站中提取信息。您可以将提取的信息以XML,CSV甚至MySQL数据库的形式保存。这可以通过使用Python正则表达式轻松实现。
import urllib.request
from re import findall
url = "<a href="http://www.summet.com/dmsi/html/codesamples/addresses.html">http://www.summet.com/dmsi/html/codesamples/addresses.html</a>"
response = urllib.request.urlopen(url)
html = response.read()
htmlStr = html.decode()
pdata = findall("(d{3}) d{3}-d{4}", htmlStr)
for item in pdata:
print(item)输出:
(257)563-7401
(372)587-2335
(786)713-8616
(793)151-6230
(492)709-6392
(654)393-5734
(404)960-3807
(314)244-6306
(947) )278-5929
(684)579-1879
(389)737-2852
(660)663-4518
(608)265-2215
(959)119-8364
(468)353-2641
(248)675-4007
(939)353 -1107
(570)873-7090
(302)259-2375
(717)450-4729
(453)391-4650
(559)104-5475
(387)142-9434
(516)745-4496
(326)677-3419
(746)679-2470
(455)430-0989
(490)936-4694
(985)834-8285
(662)661-1446
(802)668-8240
(477)768-9247
(791)239-9057
(832)109-0213
(837)196-3274
(268)442-2428
(850)676-5117
(861)546-5032
(176) )805-4108
(715)912-6931
(993)554-0563
(357)616-5411
(121)347-0086
(304)506-6314
(425)288-2332
(145)987-4962
(187)582 -9707
(750)558-3965
(492)467-3131
(774)914-2510
(888)106-8550
(539)567-3573
(693)337-2849
(545)604-9386
(221)156-5026
(414)876-0865
(932)726-8645
(726)710-9826
(622)594-1662
(948)600-8503
(605) 900-7508
(716) 977-5775
(368) 239-8275
(725) 342-0650
(711) 993-5187
(882) 399-5084
(287) 755-9948
(659) 551-3389
(275) 730-6868
(725) 757-4047
(314) 882-1496
(639) 360-7590
(168) 222-1592
(896) 303-1164
(203) 982-6130
(906) 217-1470
(614) 514-1269
(763) 409-5446
(836) 292-5324
(926) 709-3295
(963) 356-9268
(736) 522-8584
(410) 483-0352
(252) 204-1434
(874) 886-4174
(581) 379-7573
(983) 632-8597
(295) 983-3476
(873) 392-8802
(360) 669-3923
(840) 987-9449
(422) 517-6053
(126) 940-2753
(427) 930-5255
(689) 721-5145
(676) 334-2174
(437) 994-5270
(564) 908-6970
(577) 333-6244
(655) 840-6139我们首先要导入执行网络抓取所需的软件包。最终结果包括使用正则表达式进行网络抓取而提取的电话号码。
结论
希望本Python RegEx教程能够帮助您学习开始使用Python中的正则表达式所需的所有基础知识。
当您尝试开发需要使用正则表达式和类似原理的应用程序时,这将非常方便。现在,您还应该能够使用这些概念在正则表达式和Web Scraping的帮助下轻松开发应用程序。