
5.架构设计空间的探索
我们使用定制的模拟基础设施探索CHOCO TACO硬件的设计空间。硬件模型捕捉了并行和流水线的影响,并估计了时间、功率、面积和能量。我们在RTL中执行了各个硬件组件,并在通用的45nm技术节点中,用Cadence Genus进行合成。我们模拟了三阶段流水线式的乘法和除法单元。为了给存储器建模,我们使用了Destiny[38],利用其积极的导线技术对SRAM进行建模,对8字64字节的存储器访问的读取能量进行优化。我们的能源优化存储器的访问延迟限制了时钟频率,我们将设计的时钟频率定为100MHz。
A.性能权衡
我们通过对CHOCO-TACO硬件设计空间的系统探索,量化了面积、时间和功率的权衡。使用我们的模拟器,我们扫描了31340个不同的架构配置。对于每个模块中的每个块,研究将处理元素的数量从1到16以2的幂数变化,相应地改变内存容量,每个RNS-并行层在128到1024字节之间,除了NTT/INTT单元,它们需要一个固定的内存大小。对于每一种配置,该研究评估了单一加密操作的功率(泄漏和平均动态)、面积、能量和计算时间。设计探索的结果如图8所示。
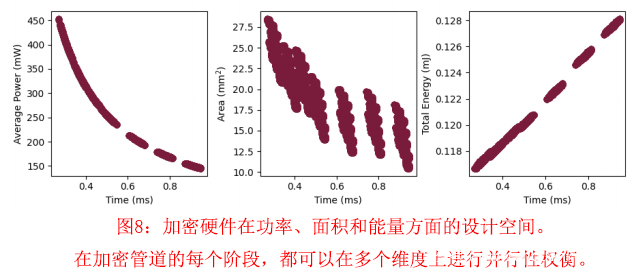
总的来说,设计空间显示出功率和面积的显著变化,有一个明显的帕累托边界,沿着这个边界,功率、时间和面积达到平衡。我们为CHOCO-TACO选择了一个工作点,将功率限制在200毫瓦,并选择运行时间在最佳运行时间(和能量)1%以内的最小设计。所选择的配置有19.3平方毫米的面积,消耗0.1228毫焦,在0.66毫秒内完成一次加密。图7以图形方式描述了这种配置。
B.CHOCO-TACO使加密变得快速和低能耗
我们评估了CHOCOTACO与软件加密基线相比在时间和能量方面的好处,显示在一系列的HE参数设置中,硬件支持提供了实质性的改进。图9显示了软件加密与硬件加速加密的比较数据。我们评估了SEAL的默认HE参数设置,以及CHOCO的参数设置(8192,3),如表3所示。基线是在我们的IMX6硬件上用软件运行的100次加密操作的平均值。结果如图9所示。我们省略了(32768,16)参数设置的基线数据,因为IMX6板没有足够的内存来加密这些参数的数据。值得注意的是,这种配置及其令人望而却步的内存要求在现有的加密推理解决方案中并不少见[14], [15] 。
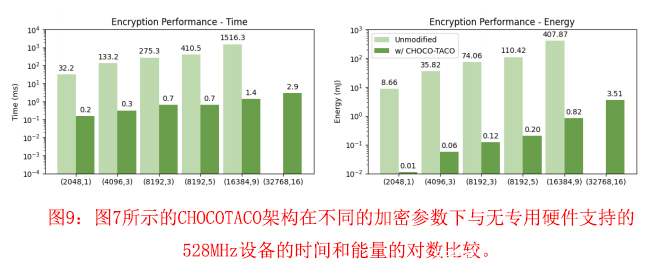
对于CHOCO(8192,3)配置,CHOCO-TACO在时间上比软件基线提高了417倍,在能量上提高了603倍。数据还显示了一种性能缩放趋势,即在硬件支持下,加密时间直接随N的增加而增加,软件则同时随 N和k而增加。可扩展性的好处来自于加速器结构中的并行性:复制的模块并行处理独立的RNS残基。与加密相比,解密从硬件加速中获得的好处较少,对于(8192,3)CHOCO参数的选择,仅比软件加速125倍。这种速度的下降是由于有限的并行性造成的,因为在这种参数选择下,解密只对一个单项式进行操作。
总的来说,CHOCO-TACO在时间和能量方面分别节省了1094倍和648倍,并且在HE参数设置方面提供了一致的收益。
6.评价
我们对CHOCO进行了评估,以显示算法优化和架构加速对资源受限设备参与客户端辅助的隐私保护计算的实用性的重要性。根据先前的工作,我们使用几个大规模的机器学习模型来评估CHOCO。我们展示了与现有的保留隐私的DNN推理解决方案相比,通信开销减少了三个数量级。这是由CHOCO优化所带来的较小的参数选择的直接结果,包括旋转冗余。此外,我们还证明了CHOCO-TACO提供的综合硬件加速比单独的专用NTT/INTT和二元产品加速多提高了54.3倍的有效客户端计算的运行时间。最终,我们演示了使用蓝牙通信的完整的CHOCO实现可以与TensrFlow Lite的本地计算相媲美,对于大型网络来说,推理能量减少了37%。
A.应用和方法
1)神经网络选择:我们评估了CHOCO对DNN推理的作用,实现了表5中四个图像分类DNN的客户端辅助加密版本。Lenet变体在MNIST数据[39]上操作,而其他更大的网络则对CIFAR-10图像[40]进行分类。我们使用Tensorflow 2.2.0[41]中的标准量化感知训练对未加密的数据进行DNN训练。评估是通过在每个网络中运行单幅图像推理来进行的。

2)客户建模:我们对运行在NXP IMX6评估套件上的软件进行了基线客户评估,该评估套件配备了528MHz的ARM Cortex-A7 CPU,32/128 kB的L1/L2缓存,以及4GB DDR3L SDRAM。我们使用制造商的应用说明AN5345[46]中269.5 mW的平均功率特性(运行Dhrystone)来估计功率和能量。我们遵循第2节的方法来估计HEAX的加速度,并使用第5节的硬件配置来模拟CHOCOTACO的加速度。
B.CHOCO优化减少了通信
第3-B节中提出的算法优化,包括旋转冗余,最大限度地减少噪音的增长,以实现更小的参数选择和相应的更小的密文。正如第2-A节中所述,表5中包括的所有网络都可以在CHOCO中使用不超过8192个元素的密文(N = 8192)进行评估。这与现有的HE解决方案[14]-[16]、[18]、[20]、[21]形成对比,后者通常使用16甚至32000个元素的密文。通过消除不必要的素数残基,CHOCO在N=8192时比SEAL的默认参数又减少了50%的密文大小。
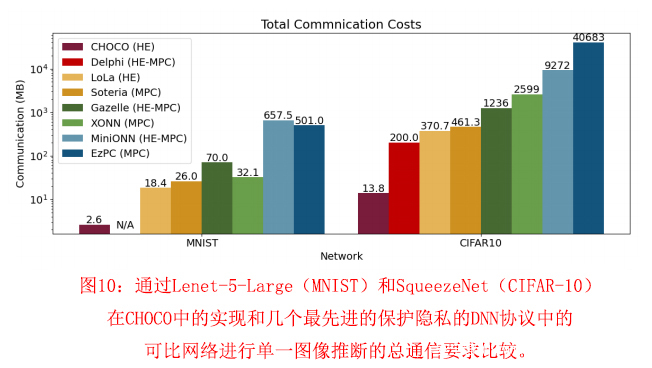
这种密文大小的减少直接转化为服务器运行时间、客户端责任(图11)和通信开销的改善。图10显示了与几个最先进的保护隐私的DNN协议相比,通信方面的改进。对Lenet-5-Large和SqueezeNet的CHOCO实现和分别进行MNIST和CIFAR-10单幅图像推理的类似网络进行了评估。它们包括离线预处理和在线计算的通信。尽管在这项工作中评估的网络在所有情况下都要大得多(更多的模型参数),但CHOCO比现有协议的性能高出三个数量级。由于更小的参数选择和更有效的密码文本打包,即使与LoLa[14]这种非客户辅助的加密推理协议相比,好处也是显而易见的。对于最接近的类似协议,即Gazelle[18],CHOCO仍然在通信开销方面提供了近90倍的改进。这种减少大大降低了端到端的延迟,特别是对于经常通过较低带宽通道(如蓝牙)进行通信的物联网设备。
C.CHOCO-TACO加速客户端计算
我们运行单图像推理来评估我们的硬件设置。我们将其与软件优化的基线以及只配备HEAX的NTT单元和Dyadic乘法单元的基线进行比较。软件优化基线包括CHOCO的算法优化,即旋转冗余,并且已经证明了比SEAL基线软件在标准排列和默认参数选择的情况下平均提高1.7倍。一个使用TensorFlow Lite(TFLite)软件在ARM Cortex-A7 CPU上运行本地推理的基线也被包括在内作为下限值。我们通过计算每个网络运行推理所需的加密和解密操作的数量,并乘以每个操作的成本,来计算主动客户端计算的时间和能量节约。我们假设客户计算和量化的时间,包括ReLu和Pooling,在CHOCO中保持与基线相同。图11报告了所产生的执行时间,将总时间分解为各组成部分。数据显示,与优化后的软件基线相比,客户端计算的平均速度提高了121倍,这与加密和解密的速度分别提高了417倍和125倍是一致的。
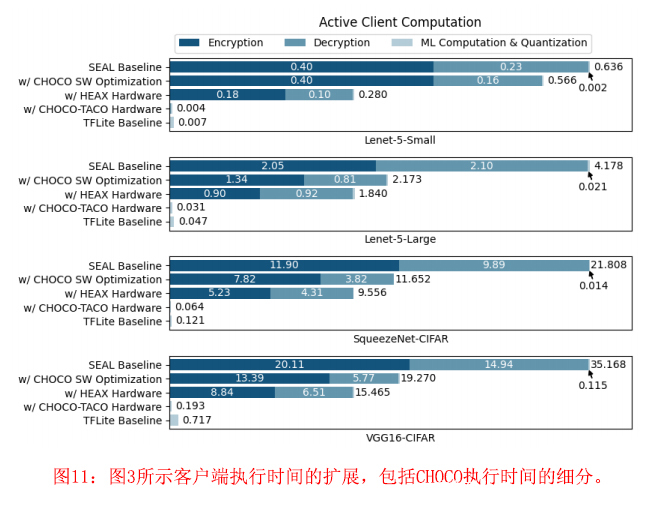
数据清楚地表明,加密和解密是客户端的瓶颈。NTT和Dyadic乘法只占这些业务约50%。因此,仅有用于这些子操作的专用硬件单元,包括但不限于HEAX[31]提供的硬件单元,是不够的。客户端辅助协议的加密操作仍然比用TF Lite在本地计算整个网络平均慢25倍。
加密和解密的全面硬件加速是必须的。CHOCO-TACO认识到这一点,并使用计算资源的最佳分配、最小的缓冲、紧密集成的存储器和多层次的并行性来解决剩余的50%的计算。通过CHOCO-TACO提供的加速,在客户端辅助的加密DNN推理中,客户端的计算时间平均比本地推理快2.2倍。
D.与本地计算相媲美的完整实施
为了了解端到端的好处,我们研究了CHOCO的一个参考实施,该实施使用10mW蓝牙通信,以22Mbps的速度在客户端和卸载之间进行通信[47] 。时间和能量的结果是由每个网络的数据通信要求分析出来的,包含在表五中。图12是与TFLite基线的端到端时间和能量结果的比较。数据显示,在一个完整的实施过程中,通信时间开始占主导地位。对于低功耗、低数据率的协议(如蓝牙),与本地计算相比,通信带来了24倍的平均时间开销。然而,在小型设备中,保存电池往往超过了对快速计算的需求。在能量消耗方面,CHOCO与TFLite基线具有同等竞争力。对于VGG,即被评估的最大和最复杂的DNN,CHOCO获得了高达37%的端到端能源消耗减少。

这些数据包含了几个主要的启发点。第一个启示是,硬件加速,如CHOCO-TACO,对于使客户端辅助加密计算的CHOCO模型的可行性至关重要。如果没有我们的硬件加速–即使有HEAX[31]的部分加速–加密和解密也是计算和能量的瓶颈。我们的硬件支持加速了整个加密和解密计算,使其成本下降,消除了它的瓶颈,并使CHOCO可行。其次,有意识的客户感知优化对于为资源受限的物联网客户带来隐私保护的计算至关重要。尽管通信仍然是时间和能量的关键瓶颈,但CHOCO的算法优化使这一成本降低了三个数量级。这种大幅减少首次使客户端的时间和能量要求与本地推理相竞争,甚至显示了端到端收益的可能性。第三,CHOCO-TACO的好处取决于计算的结构:VGG在性能和能源方面有很大的改进,而SqueezeNet则实现了收支平衡或亏损。我们在下一节中描述了这种依赖工作负载的好处。
E.网络设计
不同的工作负载从CHOCO计算中看到不同的好处,这是因为这些不同的工作负载所需的计算和通信速率不同。使用蓝牙通信的CHOCO为VGG节省了37%的能源,而SqueezeNet则节省了82.5%的能源开销。我们进行了一项微观基准研究来评估工作负载结构的这种影响。我们用各种不同维度的卷积DNN层构建工作负载。卷积层的结构改变了每层执行的乘积(MAC)操作的数量,以及发送和接收包含每层输入的密文所需的通信量。图13显示了这项研究的结果,绘制了这些微基准卷积点,以及VGG和SqueezeNet的每个层。对于微观基准点,我们将图像大小从2到32改变为2的幂,将图像通道值从32到512改变为2的幂。按照SqueezeNet和VGG16的实现,我们使用了大小为3或1的过滤器。数据显示,像VGG这样的工作负载(有可能看到其同样的能量效益)是将每MB通信的MAC数量最大化。像SqueezeNet这样的工作负载(有可能看到其收支平衡或成本)是每MB通信的MAC数量较少的工作负载。
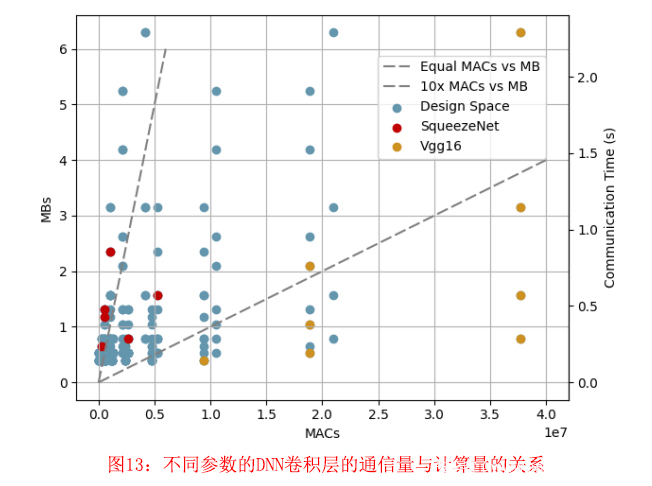
这些数据在解释CHOCO时提供了两个主要的好处。首先,数据显示,对每层计算(MACs)与通信(MBs)的快速分析比较有助于程序设计师决定他们的DNN程序应用是否会在CHOCO clientaided模型中看到能量效益。第二,这些数据指出了未来工作的机会,优化DNN结构,使CHOCO模型的每次通信计算量最大化。
F.具有隐私模式的CHOCO
CHOCO的目标是具有宽松的模型安全要求的用例,并对最小的客户端计算和通信进行优化。然而,当模型安全是一个严格的必要条件时,所提出的许多优化也会使参与混合HE-MPC协议的客户端受益。也就是说,旋转冗余可以应用于任何使用窗口旋转的HE算法,以减少噪声增长,并使参数选择更小,从而在计算和通信方面提供与其他协议类似的改进。此外,在任何客户端辅助的模型中,加密和解密将沿着关键路径反复进行。因此,像CHOCO-TACO中提出的硬件加速将继续有利于减少这些关键操作所需的时间和能量。
7.相关的工作
A.保护隐私的DNN推理
ML卸载需要数据隐私。最近的工作优化了以服务器为中心的指标,包括可用性[15]、[16],训练[48],吞吐量(通过批处理)[16]、[17]、[30],延迟(通过打包)[14]、[15]、[18]、[49],网络复杂性[17]、[18]、[20],性能[31]-[33],和模型隐私[11]-[13],[18]-[21] 。与之前关注服务器的工作不同,据我们所知,CHOCO是第一项在客户端辅助的HE中为资源受限的客户端设备进行优化的工作。
B.HE硬件支持
之前的一些工作使用硬件来加速基于格的密码学方案的内核[50]-[53],包括目前最先进的方案[23]-[26]。有些直接对HE进行加速[31], [32], [34], [54], 主要集中在硬件NTT上。正如我们在图3中所示,NTT加速可以提供帮助,但还不够。我们的工作是第一个全面优化HE密码基元的工作,这在客户端辅助的HE中是至关重要的。此外,与之前针对大型高功率GPU[55]-[57]和FPGA[31]-[34]的工作不同,CHOCO选择了ASIC实现,直接解决了客户端设备的低功耗、高能效操作的需求。
C.硬件安全
最近的架构提供了保护隐私的卸载计算。一些技术确保了数据隐私,如可信执行环境(TEEs)[8]-[10]和内存访问控制和混淆[58]-[61]。虽然这些先前的技术容易受到旁门左道的攻击,但HE不是,数据在卸载时仍然是私有的。由于其强大的、经过验证的隐私保证,HE是有利的。此外,客户端辅助的HE允许客户端和服务器之间进行TEE所不允许的互动[8]。
D.低功耗ML加速
通过软件[41]、[62]和硬件优化[63]、[64],客户端DNN的推理性能正在提高。用于私有推理的HE的一个替代方案是简单地给物联网设备配备本地ML加速和本地计算。然而,正如我们在第二节中所论证的,本地计算提出了严格的资源限制,并且需要在可能非常多的客户设备上维护(即更新)模型,而不是卸载服务器的集中模型。相比之下,CHOCO的目标是对ML(和其他)计算进行加密卸载,对集中管理的模型几乎没有限制。此外,CHOCO的支持直截了当地泛化到ML之外:给设备配备一个HE加密加速器,而不是专门的DNN硬件,就可以参与任何客户端辅助的加密计算,而不仅仅是ML。加程序研究是一个活跃的新兴领域[48]、[65]-[68];CHOCO-TACO会使广泛的现有和未来加密程序应用受益。
8.结论
在这项工作中,我们提出了CHOCO,即不透明计算卸载的客户端辅助HE,这是一个用于保护隐私的协作计算的客户端优化系统,能够让资源有限的物联网客户端设备参与进来。我们证明了,选择有效的加密参数对这种系统的性能至关重要,并提出旋转冗余作为加密算法的优化,以实现更有效的选择。由于其能够使用较小的密文,CHOCO比现有的保护隐私的DNN推理协议减少了高达三个数量级的通信开销。在剩余的客户端计算瓶颈的激励下,我们引入了CHOCO-TACO,通过硬件支持来加速关键路径上的HE加密和解密。通过利用并行性和支持本地数据存储,CHOCO-TACO在一次加密操作中拥有加速417倍和节省603倍的能量。当整合回完整的CHOCO系统时,这意味着DNN推理的客户端计算平均速度提高了121倍。对于使用蓝牙通信的参考实现,CHOCO-TACO的硬件和软件的综合优势使得协作式加密计算对使用TFLite的本地计算具有竞争力。这是一项以前无法克服的任务,这项工作通过其有意识的客户端软件优化,证明了资源有限的物联网客户端参与协作式加密计算是可行的,甚至是有利的。
参考文献
[1]H.-J. Chae, D. Yeager, J. Smith, and K. Fu, “Wirelessly powered sensor networks and computational rfifid,” 01 2013.
[2]A. Colin, E. Ruppel, and B. Lucia, “A reconfifigurable energy storage architecture for energy-harvesting devices,” SIGPLAN Not., vol. 53, no. 2, p. 767–781, Mar. 2018. [Online]. Available: https://doi.org/10.1145/3296957.3173210
[3]J. D. Garside, S. B. Furber, S. Temple, and J. V. Woods, “The amulet chips: Architectural development for asynchronous microprocessors,” in 2009 16th IEEE International Conference on Electronics, Circuits and Systems – (ICECS 2009), 2009, pp. 343–346.
[4]S. Liu, K. Pattabiraman, T. Moscibroda, and B. G. Zorn, “Flikker: Saving dram refresh-power through critical data partitioning,” SIGARCH Comput. Archit. News, vol. 39, no. 1, p. 213–224, Mar. 2011. [Online]. Available:https://doi.org/10.1145/1961295.1950391
[5]P. Sparks, “The route to a trillion devices: The outlook for iot investment to 2035,” arm, Tech. Rep., June 2017, https://community.arm.com/iot/b/internet-of-things/posts/white-paper-the-route-to-a-trillion-devices.
[6]N. Jackson and P. Dutta, “Permacam: A wireless camera sensor platform for multi-year indoor computer vision applications,” https://conix.io/wp-content/uploads/pubs/3113/jackson permacam conix 2020.pptx.pdf, Oct 2020.
[7] M. Nardello, H. Desai, D. Brunelli, and B. Lucia, “Camaroptera: A batteryless long-range remote visual sensing system,” in Proceedings of the 7th International Workshop on Energy Harvesting & EnergyNeutral Sensing Systems, ser. ENSsys’19. New York, NY, USA: Association for Computing Machinery, 2019, p. 8–14. [Online].
Available: https://doi.org/10.1145/3362053.3363491
[8] I. Corporation, Intel 64 and IA-32 Architectures Software Developer’s Manual, Nov 2020.
[9] J. Park, N. Kang, T. Kim, Y. Kwon, and J. Huh, “Nested enclave: Supporting fifine-grained hierarchical isolation with sgx,” in Proceedings of the ACM/IEEE 47th Annual International Symposium on Computer Architecture, ser. ISCA ’20. IEEE Press, 2020, p. 776–789. [Online]. Available:https://doi.org/10.1109/ISCA45697.2020.00069
[10] P. Subramanyan, R. Sinha, I. Lebedev, S. Devadas, and S. A. Seshia, “A formal foundation for secure remote execution of enclaves,” in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’17. New York, NY, USA: Association for Computing Machinery, 2017, p. 2435–2450. [Online]. Available: https://doi.org/10.1145/3133956.3134098
[11] A. Aggarwal, T. E. Carlson, R. Shokri, and S. Tople, “Soteria: In search of effificient neural networks for private inference,” 2020.
[12] M. S. Riazi, M. Samragh, H. Chen, K. Laine, K. Lauter, and F. Koushanfar, “XONN: Xnor-based oblivious deep neural network inference,” in 28th USENIX SecuritySymposium (USENIX Security
19). Santa Clara, CA: USENIX Association, Aug. 2019, pp. 1501–1518. [Online]. Available: https://www.usenix.org/conference/usenixsecurity19/presentation/riazi
[13] N. Chandran, D. Gupta, A. Rastogi, R. Sharma, and S. Tripathi, “Ezpc:Programmable, effificient, and scalable secure two-party computation for machine learning,” Cryptology ePrint Archive, Report 2017/1109, 2017,https://eprint.iacr.org/2017/1109.
[14] A. Brutzkus, O. Elisha, and R. Gilad-Bachrach, “Low latency privacy preserving inference,” in International Conference on Machine Learning, 2019.
[15] R. Dathathri, O. Saarikivi, H. Chen, K. Laine, K. Lauter, S. Maleki, and T. Musuvathi, M. Mytkowicz, “Chet: An optimizing compiler for fully-homomorphic neural-network inferencing,” in 40th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI). ACM, June 2019.
[16] N. Dowlin, R. Gilad-Bachrach, K. Laine, K. Lauter, M. Naehrig, and J. Wernsing, “Cryptonets: applying neural networks to encrypted data with high throughput and accuracy,” in 33rd International Conference on Machine Learning (ICML). ACM, June 2016.
[17] F. Boemer, A. Costache, R. Cammarota, and C. Wierzynski, “nGraphHE2: A high-throughput framework for neural network inference on encrypted data,” Aug2019, arXiv:1908.04172v2.
[18]C. Juvekar, V. Vaikuntanathan, and A. Chandrakasan, “Gazelle: A low latency framework for secure neural network inference,” in Proceedings of the 27th USENIXConference on Security Symposium, ser. SEC’18. USA: USENIX Association, 2018, p. 1651–1668.
[19] P. Mishra, R. Lehmkuhl, A. Srinivasan, W. Zheng, and R. A. Popa, “Delphi: A cryptographic inference service for neural networks,” in 29th USENIX Security Symposium (USENIX Security 20). USENIX Association, Aug. 2020, pp. 2505–2522. [Online]. Available: https://www.usenix.org/conference/usenixsecurity20/presentation/mishra
[20] J. Liu, M. Juuti, Y. Lu, and N. Asokan, “Oblivious neural network predictions via minionn transformations,” in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’17. New York, NY, USA: Association for Computing Machinery, 2017, p. 619–631. [Online]. Available: https://doi.org/10.1145/3133956.3134056
[21] B. Reagen, W. Choi, Y. Ko, V. Lee, G.-Y. Wei, H.-H. S. Lee, and D. Brooks, “Cheetah: Optimizing and accelerating homomorphic encryption for privateinference,” 2020.
[22] J. Fan and F. Vercauteren, “Somewhat practical fully homomorphic encryption,” Cryptology ePrint Archive, Report 2012/144, 2012, https: //eprint.iacr.org/2012/144.
[23] J. H. Cheon, A. Kim, M. Kim, and Y. Song, “Homomorphic encryption for arithmetic of approximate numbers,” Cryptology ePrint Archive, Report 2016/421, 2016, https://eprint.iacr.org/2016/421.
[24] C. Gentry, “Fully homomorphic encryption using ideal lattices,” in Proceedings of the 41st Annual ACM Symposium on Theory of Computing, ser. STOC 41. New York, NY, USA: Association for Computing Machinery, 2009, pp. 169–178.
[25] Z. Brakerski, “Fully homomorphic encryption without modulus switching from classical gapsvp,” in Proceedings of the 32nd Annual Cryptology Conference onAdvances in Cryptology — CRYPTO 2012 – Volume 7417. Berlin, Heidelberg: Springer-Verlag, 2012, p. 868–886. [Online]. Available:https://doi.org/10.1007/978-3-642-32009-5 50
[26] J. Fan and F. Vercauteren, “Somewhat practical fully homomorphic encryption,” Cryptology ePrint Archive, Report 2012/144, 2012, https: //eprint.iacr.org/2012/144.
[27] “Microsoft SEAL (release 3.4),” https://github.com/Microsoft/SEAL, Oct 2019,microsoft Research, Redmond, WA.
[28] K. Laine, Simple Encrypted Arithmetic Library 2.3.1, Microsoft Research, 2017.
[29] J. C. Bajard, N. Meloni, and T. Plantard, “Effificient rns bases for cryptography,”07 2005.
[30] E. Hesamifard, H. Takabi, and M. Ghasemi, “Deep neural networksclassifification over encrypted data,” in Proceedings of the Ninth ACM Conference on Data and Application Security and Privacy, ser. CODASPY ’19. New York, NY, USA: Association for Computing Machinery, 2019, p. 97–108. [Online]. Available: https://doi.org/10.1145/3292006.3300044
[31] M. S. Riazi, K. Laine, B. Pelton, and W. Dai, “Heax: An architecture for computing on encrypted data,” in Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, ser. ASPLOS ’20. New York, NY, USA: Association for Computing Machinery, 2020, p. 1295–1309. [Online]. Available: https://doi.org/10.1145/3373376.3378523
[32] F. Turan, S. S. Roy, and I. Verbauwhede, “Heaws: An accelerator forhomomorphic encryption on the amazon aws fpga,” IEEE Transactions on Computers, vol. 69, no. 8, pp. 1185–1196, 2020.
[33] S. S. Roy, F. Turan, K. Jarvinen, F. Vercauteren, and I. Verbauwhede, “Fpga-based high-performance parallel architecture for homomorphic computing on encrypted data,” Cryptology ePrint Archive, Report 2019/160, 2019,https://eprint.iacr.org/2019/160.
[34] A. Mert, E. Ozturk, and E. Savas, “Design and implementation ofencryption/decryption architectures for bfv homomorphic encryption scheme,” IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 28, no. 02, pp. 353–362, feb 2020.
[35] N. Zmora, G. Jacob, L. Zlotnik, B. Elharar, and G. Novik, “Neural network distiller: A python package for dnn compression research,” October 2019,https://arxiv.org/abs/1910.12232.
[36] S. Halevi and V. Shoup, “Algorithms in helib,” Cryptology ePrint Archive, Report 2014/106, 2014, https://eprint.iacr.org/2014/106.
[37] J. O’Connor, S. Neves, J.-P. Aumasson, and Z. Wilcox-O’Hearn, “Blake3,” https://github.com/BLAKE3-team/BLAKE3, 2019.
[38] M. Poremba, S. Mittal, D. Li, J. S. Vetter, and Y. Xie, “Destiny: A tool for modeling emerging 3d nvm and edram caches,” in 2015 Design, Automation Test in Europe Conference Exhibition (DATE), 2015, pp. 1543–1546.
[39]Y. LeCun, C. Cortes, and C. Burges, “Mnist handwritten digit database,” ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist, vol. 2, 2010.
[40]A. Krizhevsky, “Learning multiple layers of features from tiny images,” University of Toronto,Tech. Rep., 2009.
[41]M. Abadi et al., “TensorFlow: Large-scale machine learning on heterogeneous systems(release 2.2),” 2015, https://www.tensorflflow.org/.
[42]E. Freiman, “Digit recognizer for mlpack,” 2018, https://https://github.com/mlpack/models/tree/master/Kaggle.
[43] Tensorflflow, “Lenet-5-like convolutional mnist model example,” 2016, https://github.com/tensorflflow/models/blob/v1.9.0/tutorials/image/mnist/convolutional.py.
[43]D. Corvoysier, “Squeezenet for cifar-10,” 2017, https://github.com/kaizouman/tensorsandbox/tree/master/cifar10/models/squeeze.
[44]S. Liu and W. Deng, “Very deep convolutional neural network based image classifification using small training sample size,” pp. 730–734, Nov 2015.
[45]N. Semiconductors, “Imx6ull power consumption application note,” arm, Tech. Rep. AN5345-2, 10 2016, https://www.nxp.com/docs/en/application-note/AN5345.pdf.
[46]Y. Mao, C. You, J. Zhang, K. Huang, and K. B. Letaief, “A survey on mobile edge computing: The communication perspective,” IEEE Communications Surveys Tutorials, vol. 19, no. 4, pp.2322–2358, 2017.
[48] P. Mohassel and Y. Zhang, “Secureml: A system for scalable privacypreserving machinelearning,” in IEEE Symposium on Security and Privacy (SP). IEEE, May 2017, pp. 19–38.
[49] M. S. Riazi, C. Weinert, O. Tkachenko, E. M. Songhori, T. Schneider, and F. Koushanfar, “Chameleon: A hybrid secure computation framework for machine learning applications,” CoRR, vol. abs/1801.03239, 2018. [Online]. Available: http://arxiv.org/abs/1801.03239
[50] S. Roy, F. Vercauteren, N. Mentens, D. Chen, and I. Verbauwhede, “Compact ring-lwe cryptoprocessor,” in Proceedings of the 16th International Workshop on Cryptographic Hardware Embedded Systems (CHES). Springer, Sep 2014, pp. 371–391.
[51] R. de Clercq, S. Roy, F. Vercauteren, and I. Verbauwhede, “Effificient software implementation of ring-lwe encryption,” in DATE, Mar 2015, pp. 339–344.
[52] C. Renteria-Mejia and J. Velasco-Medina, “High-throughput ring-lwe cryptoprocessors,” IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 25, no. 08, pp. 2332–2345, aug2017.
[53] P. Longa and M. Naehrig, ““speeding up the number theoretic transform for faster ideallattice-based cryptography,” in Cryptology and Network Security. Springer, Nov 2016, pp.124–139.
[54] S. Kim, K. Lee, W. Cho, Y. Nam, J. H. Cheon, and R. A. Rutenbar, “Hardware architecture of a number theoretic transform for a bootstrappable rns-based homomorphic encryption scheme,”in 2020 IEEE 28th Annual International Symposium on Field-Programmable Custom ComputingMachines (FCCM), 2020, pp. 56–64.
[55] W. Dai and B. Sunar, “cuhe: A homomorphic encryption accelerator library,” in Cryptography and Information Security in the Balkans. Springer Ineternational Publishing, 2015, pp. 169–186.
[56] A. A. Badawi, V. Veeravalli, C. Mun, and K. Aung, “High-performance fv somewhat homomorphic encryption on gpus: An implementation using cuda,” in CHES, vol. 2018, no.2, 2018, pp. 70–95.
[57] A. Qaisar Ahmad Al Badawi, Y. Polyakov, K. M. M. Aung, B. Veeravalli, and K. Rohloff, “Implementation and performance evaluation of rns variants of the bfv homomorphic encryption scheme,” IEEE Transactions on Emerging Topics in Computing, pp. 1–1, 2019.
[58] L. Ren, X. Yu, C. W. Fletcher, M. van Dijk, and S. Devadas, “Design space exploration and optimization of path oblivious ram in secure processors,” in Proceedings of the 40th Annual International Symposium on Computer Architecture, ser. ISCA ’13. New York, NY, USA:Association for Computing Machinery, 2013, p. 571–582. [Online]. Available:https://doi.org/10.1145/2485922.2485971
[59] H. Sasaki, M. A. Arroyo, M. T. I. Ziad, K. Bhat, K. Sinha, and S. Sethumadhavan, “Practical byte-granular memory blacklisting using califorms,” in Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’52. New York, NY, USA: Associationfor Computing Machinery, 2019, p. 558–571. [Online].Available:https://doi.org/10.1145/3352460.3358299
[60] A. Shafifiee, R. Balasubramonian, M. Tiwari, and F. Li, “Secure dimm: Moving oram primitives closer to memory,” in 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA), 2018, pp. 428–440.
[61] C. Hunger, L. Vilanova, C. Papamanthou, Y. Etsion, and M. Tiwari, “Dats – data containers for web applications,” in Proceedings of the Twenty-Third International Conference on Architectural Support for Programming Languages and Operating Systems, ser. ASPLOS ’18. New York, NY, USA: Association for Computing Machinery, 2018, p. 722–736. [Online]. Available:https://doi.org/10.1145/3173162.3173213
[62] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N.Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, “Pytorch: An imperative style, high-performance deep learning library,” in Advances in Neural Information Processing Systems 32, H. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alch´e-Buc, E. Fox, and R. Garnett, Eds. Curran Associates, Inc., 2019, pp. 8024– 8035. [Online]. Available: http://papers.neurips.cc/paper/9015-pytorchan-imperative-style-high-performance-deep-learning-library.pdf
[63] Y. Chen, J. Emer, and V. Sze, “Eyeriss: A spatial architecture for energyeffificient dataflflow for convolutional neural networks,” in 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), 2016, pp. 367–379.
[64] S. Han, X. Liu, H. Mao, J. Pu, A. Pedram, M. A. Horowitz, and W. J. Dally, “Eie: Effificientinference engine on compressed deep neural network,” in 2016 ACM/IEEE 43rd AnnualInternational Symposium on Computer Architecture (ISCA), 2016.
[65] J. Wang, A. Arriaga, Q. Tang, and P. Y. Ryan, “Facilitating privacypreservingrecommendation-as-a-service with machine learning,” in Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’18. New York, NY, USA: Association for Computing Machinery, 2018, p. 2306–2308. [Online]. Available: https://doi.org/10.1145/3243734.3278504
[66] G. S. C¸ etin, Y. Dor¨oz, B. Sunar, and E. Savas¸, “Low depth circuits for effificient homomorphic sorting,” Cryptology ePrint Archive, Report 2015/274, 2015,https://eprint.iacr.org/2015/274.
[67] F. Baldimtsi and O. Ohrimenko, “Sorting and searching behind the curtain: Private outsourced sort and frequency-based ranking of search results over encrypted data,” Cryptology ePrint Archive, Report 2014/1017, 2014, https://eprint.iacr.org/2014/1017.
[68] y. GUO, X. Yuan, X. Wang, C. Wang, B. Li, and X. Jia, “Enabling encrypted rich queries in distributed key-value stores,” IEEE Transactions on Parallel and Distributed Systems, vol. 30, no. 6, pp. 1283–1297, 2019.