
上篇文章中我们讲到了输入的“变异”以及选择“变异”模式的一些心得,这篇文章我们就来看看实现模式选择的一些技术细节。同时我们也要跳出单一路径的思想,让我们的fuzzing找到更多的路径。
CFG
cfg是程序控制流图(control flow graph)的简写,说大白话就是将程序按照if、else、while、函数调用等进行“分块”,然后根据调用顺序连线即可,就类似我们生活中用到的流程图。搞逆向的小伙伴应该不陌生,ida pro就会对逆向的程序进行解析,并生成对应的cfg。对于程序来讲,我们经常通过构建cfg的方式来了解程序的执行过程并进行分析。可以想象,如果你可以绘制程序的cfg,那上一篇文章中提到的许多技术都可以轻松实现。
考虑到难度,我们还是以“白盒”测试为主,毕竟ida pro那样能对“黑盒”程序还原cfg的技术距离我们还是很遥远的。fuzzingbook给出了自己的cfg生成class来对python程序进行流程分析,但是没有做解释说明,我们就以它的实现为例来一边复现一边学习,详细代码大家可以在这里查看。
import ast
import inspect
import astor
src = inspect.getsource(cgi_decode)
print(src)
test = ast.parse(src)
print(ast.dump(test))
inspect是python自带的module,它用于检查指定程序的相关信息,我们调用的getsource函数能够获得程序的源码,这里使用的cgi_decode就是我们上一篇文章中用到的函数。
ast是抽象语法树(Abstract Syntax Trees)的简写,python的这个模块能将读取到的代码进行解析,根据语法生成树状结构,方便我们了解程序的执行流,我们只需要调用ast.parse就可以完成语法分析的工作。它主要分为两个部分:
- 词法分析,它将程序的每一个字符串都会标记为对应的“身份”(比如变量、关键字),形成一条流状结构
- 语法分析,将流作为输入,按照语法对其进行解析,形成树状结构
我们简单写一个if else的小程序来简单说明一下:
def easy_if(a):
if a>10:
return False
else:
return True
对于这个程序来说:
- def就是function define的关键字,后面的easy_if是对应的函数名字,后面括号,那么括号里面的a就是参数
- 往下是if,是关键字,if后面就应该是一个比较的句子,那么对句子再进行分析:
- a是左值
- 大于号是比较运算符
- 10是右值
- return返回语句
- else,后面不用接东西
- return返回语句
进行简单的“重装”(比如把def、函数名、参数扔到一块)程序很简单,一直是直线结构,直到ifelse出现了分叉,当然,我们也不用存储if的分叉,我们可以值存储if和if的条件作为一个块,而具体的分支作为块中的块。这样形成一种带有递归思想的结构。如果更进一步,我们还可以对于每个module,我们都把函数作为module块中的一部分,在我们解析时,调用module块,然后就可以找到函数块,函数块中代码块,代码块中有ifelse和循环块,这样就形成了套娃结构。这样说可能会让你听的有些迷糊,我们来看看图片就明白了
如下所示是树状结构,块与块分离:
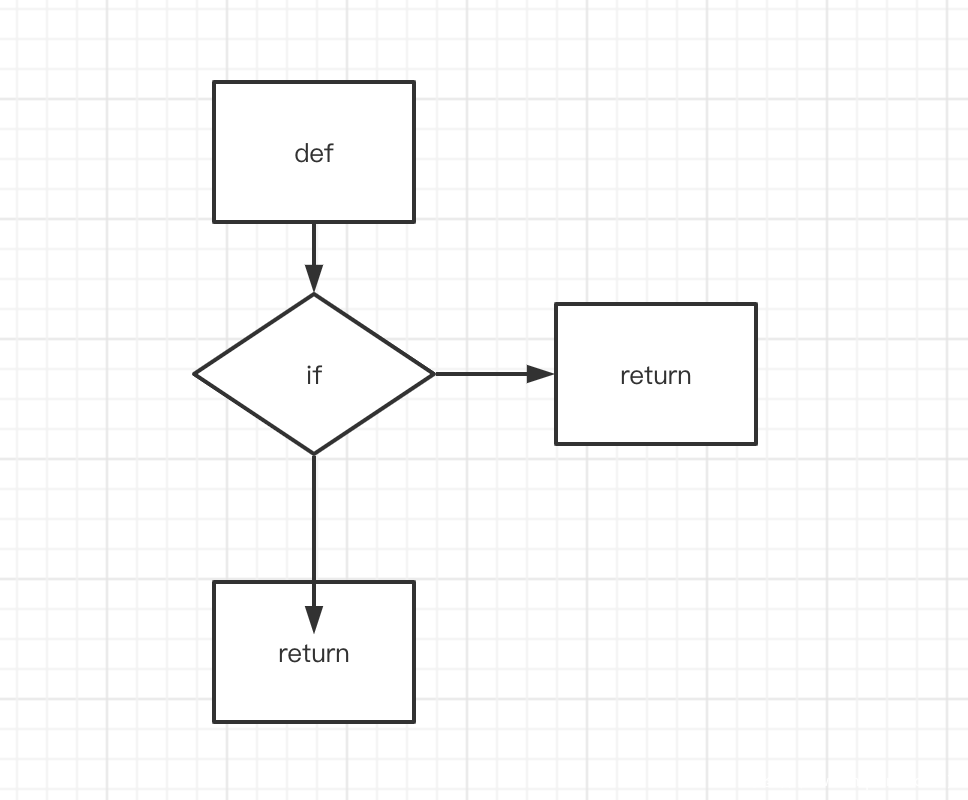
如下所示,块与块有关系:
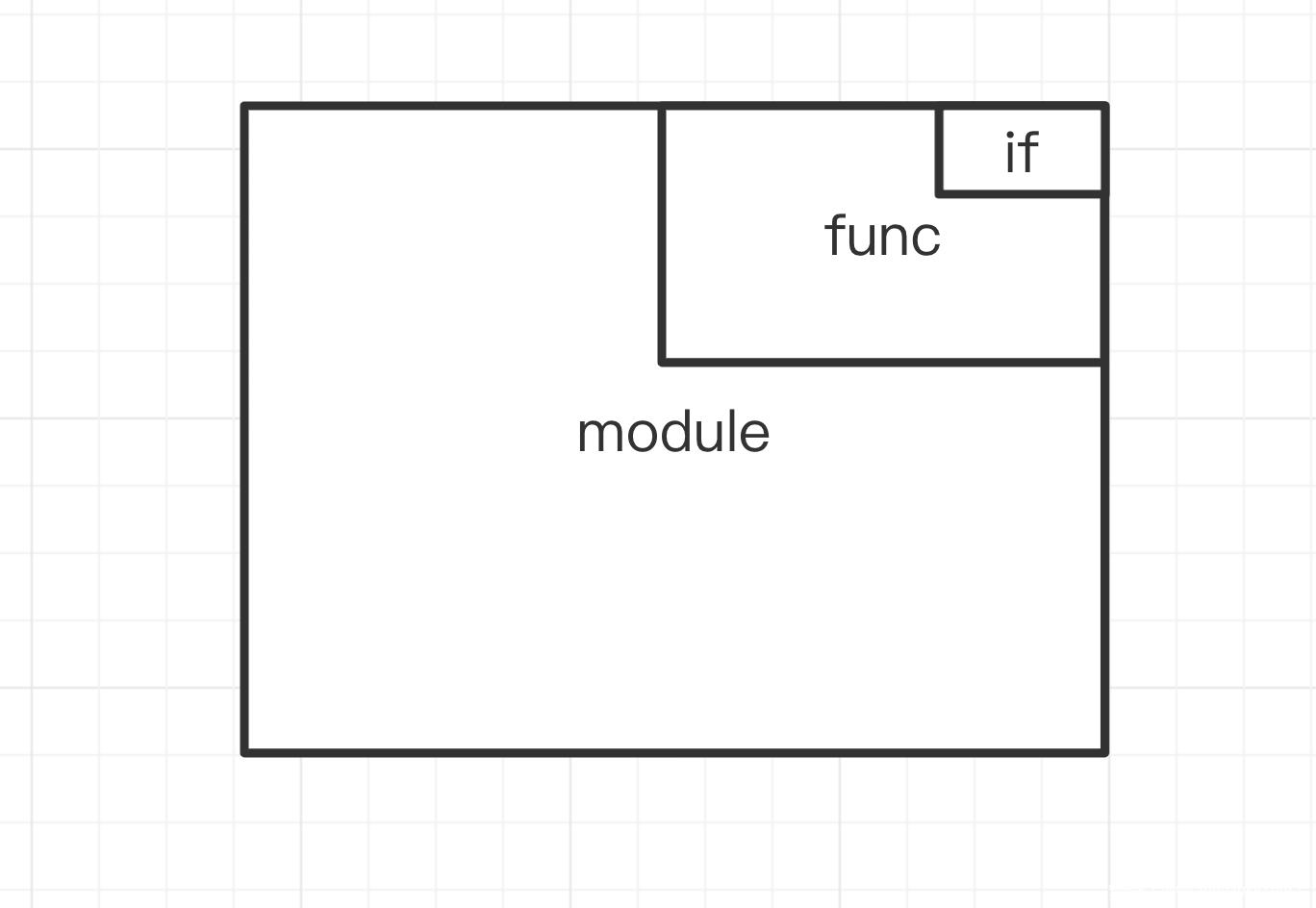
如果你学过编译原理,那么你对上面的过程一定不陌生,这实际上也是编译器在编译代码的时候要干的活,本质上都是理解程序的“意思”,我们这里使用的ast.parse就自动为我们干了。实践中我们直接调人家写好的工具即可。如果你只是想了解一下这部分内容,看懂fuzzingbook的实现,到这就可以过了,如果你想自己去写,那还是要去系统学习的。
我们打印一下,输出结果如下:
Module(
body=[FunctionDef(name='easy_if', args=arguments(posonlyargs=[], args=[arg(arg='a', annotation=None, type_comment=None)],
vararg=None, kwonlyargs=[], kw_defaults=[], kwarg=None, defaults=[]),
body=[If(test=Compare(left=Name(id='a', ctx=Load()), ops=[Gt()], comparators=[Constant(value=10, kind=None)]),
body=[Return(value=Constant(value=False, kind=None))], orelse=[Return(value=Constant(value=True, kind=None))])], decorator_list=[], returns=None, type_comment=None)], type_ignores=[]
)
对照我们上面的分析,你应该很容易看懂module的结构,它记录的信息非常详细。与我们上面的套娃结构类似,我们可以通过循环的形式,不停的拿到中号套娃、小号套娃,进而实现程序结构的遍历。
接下来我们着手构建我们自己的节点类,把ast为我们解析到的内容拉到我们的树上来,为的是能够自定义我们的cfg输出的信息、增添接口等。
class CFGNode(dict):
def __init__(self, parents=[], ast=None):
assert type(parents) is list
register_node(self)
self.parents = parents
self.ast_node = ast
self.update_children(parents)
self.children = []
self.calls = []
我们先只看关键部分,节点定义parents来保存节点的父节点,children来保存子节点,update_children函数用来将自己添加到父节点的children中,实际上就是在模拟ast的node结构。
class PyCFG:
def __init__(self):
self.founder = CFGNode(
parents=[], ast=ast.parse('start').body[0])
self.founder.ast_node.lineno = 0
self.functions = {}
self.functions_node = {}
我们的cfg类则是首先会创建一个founder的node节点,作为初始节点,然后我们的任务就是往上挂后续的节点。启动代码如下:
cfg = PyCFG()
cfg.gen_cfg(fnsrc)
'''
def gen_cfg(self, src):
node = ast.parse(src)
nodes = self.walk(node, [self.founder])
self.last_node = CFGNode(parents=nodes, ast=ast.parse('stop').body[0])
ast.copy_location(self.last_node.ast_node, self.founder.ast_node)
self.update_children()
self.update_functions()
self.link_functions()
'''
我们创建cfg对象后,就对源代码进行ast.parse操作,然后进行walk,即游走操作,在节点间游走,就相当于是遍历ast结构了,游走中会将node不断挂在树上,最后再挂上stop节点,就算是大功告成了。所以重点就是walk操作了,我们看看它的代码:
def walk(self, node, myparents):
fname = "on_%s" % node.__class__.__name__.lower()
if hasattr(self, fname):
fn = getattr(self, fname)
v = fn(node, myparents)
return v
else:
return myparents
首先它得到了node.__class__.__name__,其实这就是我们上面看到的body的“名字”,比如我们的def语句对应的就是FunctionDef,我们通过getattr函数从节点获取这个“函数”,我们做个类似hook的操作,自己在节点类中定义对应的functiondef函数,这样,getattr获取的函数就是我们自己写的函数,我们就可以对每一个节点做我们自己的操作了。总结起来就是下面的流程:
- 找节点
- 调用节点名称对应的函数
- 重复知道结束
可以看到,我们需要写出ast所有语句名字对应的函数,并对函数进行符合语句语意的编写,这是最难的地方,比如我们看一下on_module操作的代码,它代表了一个module的开始:
def on_module(self, node, myparents):
p = myparents
for n in node.body:
p = self.walk(n, p)
return p
它实际上就是在遍历自己的body,去游走body中的其他节点。在我们的例子中,它会进入到on_functiondef函数中,它的流程也类似:
- 保存函数名、传入参数等信息
- 生成函数开始的节点,方便我们后续使用
- 生成函数结束的节点,同上
- 遍历它的body找到函数中的其他语句
- 一些其他操作
对于每一种语句,我们都需要编写这样的函数,这需要你对ast结构非常熟悉,这里就不再展开了。除了这些必须要写的,我们还可以保存一些自己的结构,用来定制我们的cfg,比如对于每一句代码,我们可以维护一个coverage,用来统计我们这一行代码走过的次数,我们还可以维护一个全局的cfg来保存我们程序走过的总流程,保存一个局部的cfg来测试我们的模式的性能,后续我们还会用cfg来计算函数的距离等等,可以说只要有了这个的基础,我们就可以玩出花来了。
大家可以看看fuzzingbook的代码,在这基础上进行自己的修改,不建议自己重写,一方面确实是代码量比较大,一方面涉及到ast的知识门槛比较高,大家在基础上定制就好了,至于后续绘图什么的,只需要调用绘制图形的module即可。对于非python类程序,其实只有有源码,按照上面的思路,都可以得到抽象语法树,这里就不再赘述了。
调度器、路径执行率与多路径
上一篇文章中我们提到了要选择模式,但是选择模式就需要对每个模式的变异结果进行统计学分析,看看哪些模式能够获得更好的效果(注意哦,这里我可没说是代码覆盖率,答案在后面揭晓),我们假设我们现在有三个模式:
population = ["anquanke.com", "1999.10.05", "asa9ao"]
我们在初始情况下,不知道三者的代码覆盖率,我们就按照1:1:1的概率分配,简单写一个调度器:
import random
class PowerSchedule(object):
def choose(self, population):
pos = random.randint(0, len(population)-1)
return population[pos]
这样我们就可以随机选择一个模式来进行变异了,我们可以把它继承到Fuzzer类中,现在我们的fuzzer类就有了变异、调度、模式存储的能力,我们的fuzzer在三个模式的基础上进行变异,而三个模式的原始语意都不相同,这里的语意指的是模式的结构所代表的含义,比如说,anquanke.com代表了网址,第二个则是出生年月,如果语意不同,那在此基础上进行“小”变异,得到的一般是符合该语意的字符串,比如ansdadda.com,虽然看不出它是啥网站,但是它确实是个网址的语意;如果“大”变异,或者”小“变异多了,也会产生新的语意,但新的语意一般不可控,所以最可靠的还是我们基础的模式,我们现在有了这三种模式,这样我们生成的变异结果就更加多样了。
class Fuzzer():
def __init__(self, seeds, mutator, schedule):
self.seeds = seeds
self.mutator = mutator
self.schedule = schedule
当然了调度器不可能这么简单,我们可以改进一下,比如,我们为每个模式设置energy变量,初始默认为1,如果这个模式被证明有效,那就对energy进行放大,然后我们根据energy来进行调度,比如我们使用softmax:
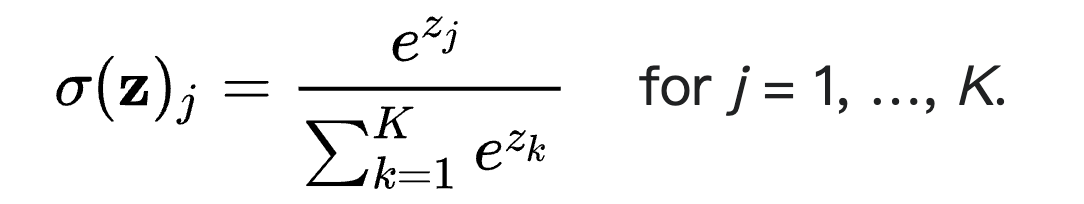
这个函数是归一化指数函数,它可以将我们的一堆energy转换为概率,你的energy越大,概率就越大,比如,我们的energy序列为[1.0, 2.0, 3.0, 4.0, 1.0, 2.0, 3.0],我们在计算softmax之后的结果就是[0.024, 0.064, 0.175, 0.475, 0.024, 0.064, 0.175],我们可以通过这种方式依照概率选择合适的模式。当然你也可以使用其他归一化函数来处理energy,softmax比起其他归一化函数最大的特点是它会让强者更强,弱者更弱,但缺点就是在大小差距过大时,小的energy对应的模式被选到的可能性就几乎为0了(当然这也可以是优点,后续会提到)。
用energy来计算概率是个很好的方式,但我们还需要处理如何放大或者缩小energy这个问题,fuzzingbook上给出的方案是将路径保存下来,然后检测这条路径走了多少遍,走的越多,你的energy就越少,公式如下:
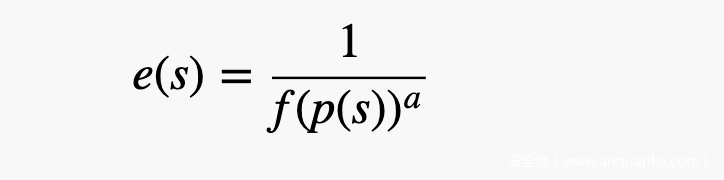
p函数用来得到模式s对应的路径,f函数检查这路径走了多少遍,a是超参数,只要是正的就行,具体取值可以在实践中不断修改。总体来看,这是一个减函数,对应的语意就是:一条路径走的越多,它的energy就越小,而路径就是对应模式的,其实就是模式如果“僵化”了,那就降低这个模式的概率。
我们来看一下代码:
def getPathID(coverage):
pickled = pickle.dumps(coverage)
return hashlib.md5(pickled).hexdigest()
这是p函数,他把我们走过的路径用pickle模块(机器学习经常用它保存训练好的模型,它用序列化的形式将数据保存)进行保存,返回对应的md5值作为id,要注意,如果路径一样的话,保存的实际上是一个东西,所以md5也一样,同样的路径返回的id必然一样,这样实际上我们就有了对应coverage的唯一标识,我们可以用它作为key做一个字典。
id_dic = {}
def getIdFreq(id):
id_dic.setdefault(id,0)
id_dic[id]+=1
return id_dic[id]
这是f函数,它根据上面的md5查到对应的频率,当然,每查一次我们可以认为这条路径又被调用了一遍,所以给他的频率++。
把这些加到PowerSchedule类中,我们的调度器就初具雏形了。不知道你看到这里有没有疑惑,为什么在这里我们选择模式没有考虑到代码覆盖率的问题,反而是在让路径重复越多的模式调用的反而越少呢?这实际上让我们的fuzzing有了更强的“探索性”,比如下面的例子:
if 输入==a:
200行代码
elif 输入==b:
100行代码
我们假设a、b两个变量是正交的,ab之间没有关系(即用一个模式的变异结果只能得到a、b中的一个),那么如果我们选了a模式,代码覆盖率是200,b模式是100,如果盲目追求一个模式的话,就会导致我们永远在a代码中打转,一辈子测试不到b代码,但显然这两者我们都应该是要测试到的,所以简单的考虑代码覆盖率,最终的结果就是我们cfg的一条路径上卡死。在实际中,虽然不可能存在正交的字符串,但是模式语意之间的转换是非常困难的,就像是anquanke.com到出生年月,如果你只选择了前者,那你想找到出生年月的模式可是要费一番功夫,这种情况只考虑代码覆盖就显然有问题了。
我们引入调度器后,实际上是引入了路径执行频率的概念,即,每一条路径执行的次数,我们上面调度器的公式也可以看作是路径执行频率的倒数,目的就是为了让不经常执行到的代码能够执行,最终将各个代码的运行次数处于一个比较平衡的区间。
这就又有一个问题:模式怎么生成新的呢?我们一直在聊模式选择,也给出了几种方案,但都是在指定的模式的基础上进行选择或者在复杂的算法基础上的,模式如果以这种形式进行增殖,那迟早会“饿死”的情况(模式越选越少,或者是选到一定数量就没办法再选新的了),为了解决这个问题,我们需要大量“垃圾”模式来“养蛊”,我们可以用这样的代码来不断增加”垃圾“模式:
while True:
if i==10:
将fuzzing字符串添加到模式
i=0
else:
i++
如此,我们可以快速扩充我们的模式,而模式由于收到变异的影响,会诞生越来越多相差十分大的模式。我们还可以采取“大”变异来加速生成新模式。
while True:
if 该加新模式了:
多次变异
else:
普通变异
模式从最开始的anquanke.com会慢慢变成hello world等各式各样的字符串,我们会得到越来越多的语意,而垃圾模式又会因为我们的调度器,生成的概率越来越低,如果低于某个阀值的话,我们可以把它去掉,如此以来,我们就会得到一系列较为理想的模式,找到程序对应的语意。
而为什么我说使用softmax呢?因为softmax在energy差距较大的时候,直接将energy小的模式的概率算成无限接近于0,也就省下了我们设置阀值清除垃圾模式的步骤了。
总结
这篇文章中我们学习了fuzzingbook中提出的cfg实现方法,有了能够构建程序流图的能力,引入了调度器与路径执行频率的概念,让我们的fuzzer有了多路径探索、模式更新的能力,fuzzing初具雏形,下一篇文章中我们将聚特定路径探索的问题,帮助我们fuzzing再度升级。