
代码指针完整性(CPI,更详细的介绍可以参考我之前的文章)是2014年提出的一种针对控制流劫持攻击的防御措施,CPI将进程内存划分为安全区和常规区,对敏感指针,尤其是代码指针放置到安全区做了保护。其作者认为该机制能够对控制流劫持攻击实现完全的防御,但遗憾的是,CPI(主要指基于信息隐藏的实现)做了两个并不总是成立的假设:
- 安全区的信息不会被泄露。
- 对安全区的暴力破解将会导致程序出现崩溃。
而实际上,安全区的信息可能被泄露,而精心构造的扫描策略能够在不导致程序崩溃的前提下对安全区地址进行破解,这就是我接下来要为大家介绍的攻击。
对于CPI的攻击是由MIT的Isaac Evans等人提出来的,攻击完全在CPI机制所假设的情景下进行:
- 攻击者对进程内存有完全的控制权,但不能修改代码段。
- 攻击者可以对任意地址(代码段外的)进行读写。
- 攻击者不能干涉程序加载。
实际攻击时是利用了栈溢出漏洞,对某一个数据指针实现了完全的控制,而这完全是在CPI的假设之内的。具体攻击步骤如下:
实施时间侧信道攻击,收集相关数据
侧信道攻击(side channel attack),是针对目标运行过程中的时间消耗、功率、或者是物理化学特性(如电磁辐射)等信息对目标进行攻击的一种攻击手段,更准确的定义大家可以自行了解。而顾名思义,时间侧信道攻击关注的就是目标运行时的时间消耗。对于CPI的攻击就需要实施时间侧信道攻击。
比如如下代码片段:

如果指针被攻击者控制,使其指向内存中的某个位置,则此时可以通过改变ptr的值,读取出不同内存地址的值,造成代码执行时间不同,从而服务器的响应时间不同。根据响应时间,可以估计任意内存地址的值。示意图如下:
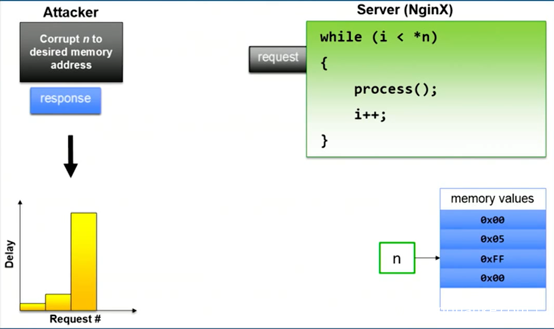
而此处显然是一个普通的数据指针,这样的指针在CPI机制中是不受保护的。这样一来,借由栈溢出漏洞,或者是堆污染漏洞(取决于目标指针在堆上还是栈上)就可以实现对目标指针的控制,进而得到相关信息。
实际攻击时是利用了nginx 1.6.2版本存在的栈溢出漏洞,控制了nginx_http_parse.c中的如下指针nelts:
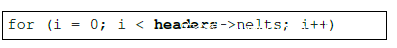
攻击者将其指向了一个精心选择的位置。CPI虽然有48bit(AMD64架构高16位地址不可用)位置用于地址分配。在某些系统内可用位数可能更加少,如64位的ubuntu 14.04,其只有46.5bit可用于虚拟内存分配。因为其有8192(213)个段描述符,每段32位,另外有三个唯一标识符local、global、interrupt,则共有13+32+1.5(3个标志需要2比特,但其中一个需要共用)=46.5bit。但实际上内存分配(包括安全区)往往依赖于mmap函数和随机化,所以攻击者只需关注mmap为目标程序分配的基址,只有28个bit可供分配(这是由提出地址随机化ASLR的论文确定的)。所以该位置只需位于mmap函数为nginx分配的区域中即可。
实际进行时间侧信道攻击时,具体的时间消耗指标是0.6kb的一个静态网页在1Gbit线路下处理一次http请求的往返时间。可以通过响应时间来估计相应的值,时间侧信道攻击重点关注以下等式:
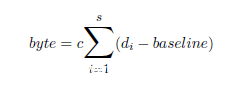
byte代表当前指针指向的内容,取值从0到255,是待估计的值。
c是一个待定常数(也就是样本量与累计响应时间的斜率)。
baseline是http请求的平均时间,反映了其他因素影响,应该去除。
di代表当前处理第i次请求,且byte不为0时的时间。
s代表样本容量,在此处也就是发送的请求数。实验中收集了10000个样本。
当byte=0时,显然有:
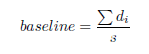
当byte=255时,则有:
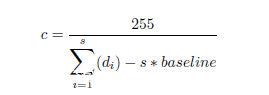
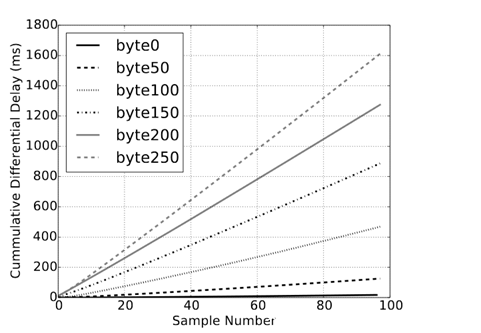
实验中观测到的baseline为3.2ms。样本量和累计响应时间具体关系如下:
下图展示了实际值与估计值的关系:
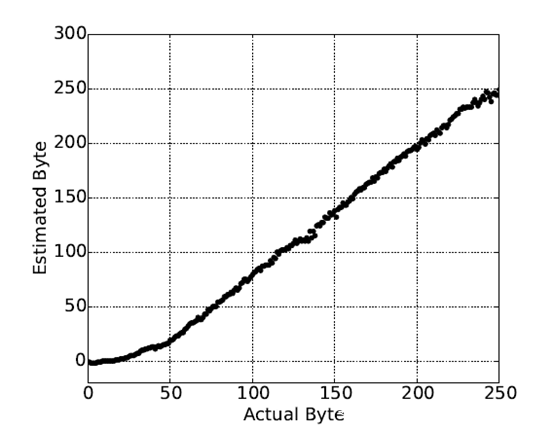
可以看到,我们能以较高的准确度对目标值进行估计,接下来就是对安全区的定位了。
定位安全区
攻击者对现有的x86-64架构下的CPI实现进行了分析,发现0x7bfff73b9000到0x7efff73b9000之间可以确保处于安全区。可以让前述nelts指针指向这范围里的任何一个地址,实验中选取了0x7efff73b9000。安全区在内存中大体位置如下:
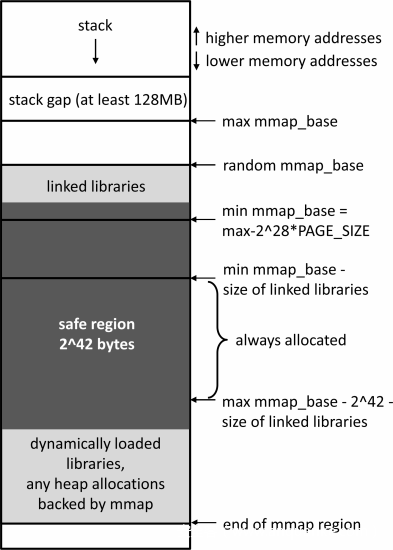
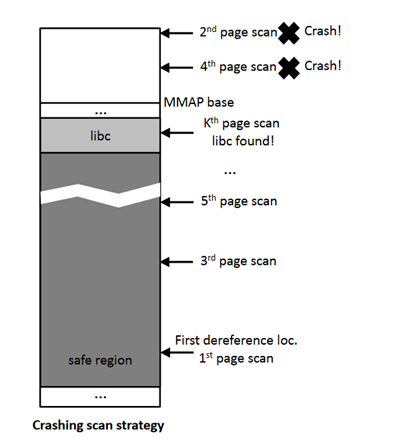
最高地址处是进程占用的栈,然后是一段至少为128MB的间隔,在之后是mmap函数分配的区域,mmap的基址是随机分配的(如果有随机化),其最大最小值已经在图中标出。动态链接库一旦被放入mmap机制处,安全区就紧随其后,大小为2^42字节。而注意到,图中大括号部分总是位于安全区,这也是上述0x7bfff73b9000到0x7efff73b9000的来源。
不会导致崩溃的算法
由上图可以很直观的看到,只要能定位到动态链接库(通常为libc,以下均使用libc描述),安全区也就能够定位了(上述的地址一般来说是无效的,只能用做扫描的开始)。开始已在上述安全区地址后,以一个libc的大小(实验得出的数量级为2^21字节)为单位,向高地址检查(通过时间侧信道),直到命中libc。
整个算法可以描述如下:
- 将数据指针指向0x7efff73b9000。
- 向高地址调整一个libc大小。
- 扫描一些字节值,如果全为0,说明仍在安全区,返回第2步。
- 结束。
在最坏的情形下,我们需要2^28*page_size(通常是4KB)次读取,但由于内存是页对齐的,所以实际上只需要2^28次即可。由于安全区大小有2^42字节,十分稀疏,几乎全由0构成,故可以取足够多的值,通过当前值是否为0判断是否命中libc,这又能进一步较少读取次数。为了保证准确性,选取libc每页偏移为1272和1672的字节(这两者至少有一个不为0)和另外5个字节,同时为每个字节准备30个样本进行时间侧信道攻击来估计数据。下图展示了样本量和误报率(将0识别为非0,可能导致将安全区误认为libc)的关系。
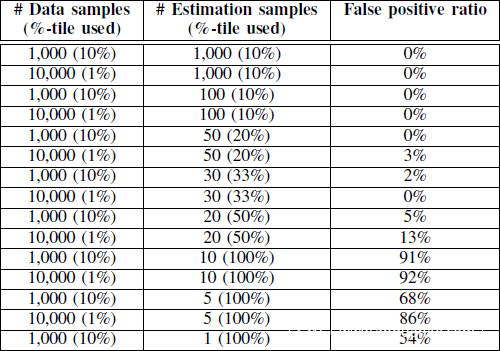
可以看到,在前述发送10000个请求的前提下,每个字节采集30个样本已经能保证误报率为0。
这样一来,实际的最大读取次数就进一步被降低为228 * 212/221 = 219次。不会导致崩溃的算法在定位libc阶段需要进行7*219*30=110100480次读取,约耗时97小时。图示如下:
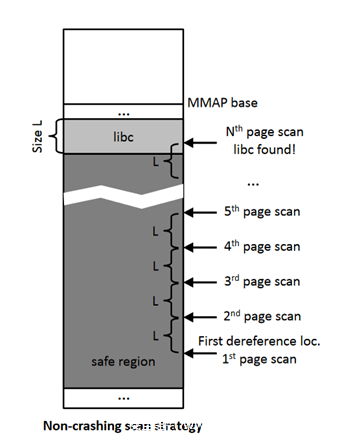
现在已经定位到libc,但我们仍不知道我们具体在libc的什么位置,所以,攻击者从页内偏移3333的位置再取70个字节,与本地libc进行匹配,又要再耗时1小时,总计耗时98小时。
会导致崩溃的算法
如果我们可以接受程序崩溃的话,就可以引入二分查找算法。任何在mmap基址之上的地址将会导致崩溃,那么我们只要找到这样一个地址X即可:
X本身安全,但X向高地址调整一个libc大小后导致崩溃。
这说明X位于libc中。在二分查找算法下,我们只需最多读19次,并最多造成19次崩溃即可定位到上述X。给定可以接受的崩溃次数T,则扫描可以覆盖的最大内存数量f(i, j)和崩溃次数i,页读取数j有如下递推关系:
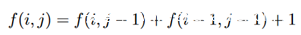
T与读取次数关系可绘制图像如下:
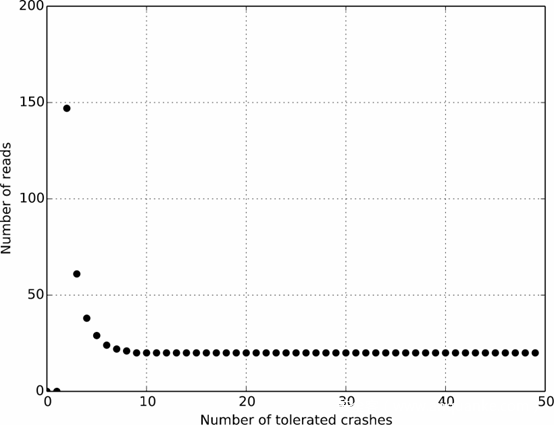
可能导致崩溃的算法如下:
会导致崩溃的算法则要快得多,在平均12次崩溃之后,耗费几秒就能定位到libc的具体位置。
实施以上两个算法,可以很方便的定位到libc基址libc_base,而安全区基址safe_region_address可以计算如下:
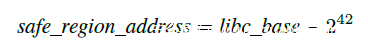
至此,安全区的定位就完成了。
攻击安全区
现在,攻击者已经明确了安全区基址,某个代码指针ptr_address的地址只需要与掩码cpi_addr_mask(0x00fffffffff8)进行运算即可。接下来要做的就是使用前述nelts指针,改变安全区的read_handler入口,然后就可以修改代码指针的相关元数据(存储有其值,地址上下界等信息),是目标代码指针指向系统调用sysenter。而x86-64环境下借由sysenter进行的攻击就是老生常谈了。这里简单介绍一下。攻击者可修改相关寄存器的值,使sysenter直接执行某个命令,或者是让控制流转向某个ROP链的开头。实际攻击时,耗费了6s完成整个攻击。接下来我简单的为大家介绍一下攻击过程。(涉及到的脚本暂时还没有开放)
开启nginx服务器,启动攻击脚本:
服务器显示有10次崩溃:
libc具体位置和安全区的起始位置已经被定位到:
继续进行,成功开启shell:
回头看:CPI的设计缺陷
在已有的x86-64架构下的CPI实现中,段保护已经不可用。而其使用以地址为下标的数组来实现元数据,所以该数组地址被存储在一个静态表__llvm__cpi_table中,使得默认设置下没有任何特殊保护。这可能是由于是早期版本的关系。另外,不管有没有实施随机化,安全区的分配总是依赖于mmap来进行,这使得整个CPI无法防御经由内存泄露进行的攻击。而很多系统暂不支持地址随机化,或者是只能实施局部的随机化,这都会削弱CPI的安全性。而在32位系统内,CPI使用了段寄存器(gs寄存器),这可能会导致TLS(thread local storage,线程本地存储)冲突,以libc为例,其中使用了gs寄存器的指令约有3000条。而简单的换用其他寄存器,如fs寄存器,有可能导致兼容性问题,比如wine就需要使用到fs寄存器。而当CPI向其作者提出的那样用以保护系统内核的话,由于操作系统对这些寄存器有着特殊的用途,使用这样的寄存器更是会造成不可避免的冲突。
改进CPI
对CPI的改进要立足于增加攻击过程中的崩溃次数,但必须指出的是,这些改进都无法百分百防御对不支持段保护的系统的攻击。
- 扩充安全区大小。这是一个最直接,最简单的想法,但遗憾是的是,单纯的扩充安全区大小并不能抵抗前述进行的侧信道攻击。所以必须增加额外的寄存器来保护偏移量,并为相关操作设计专门的指令。
- 对安全区实施严格地址随机化。这将会使得没有映射的内存块变大,增加攻击时访问到这些区域的机会,进而触发崩溃。但正如前述二分查找算法所显示的,攻击者能够在有限的崩溃里达到目标。类似堆喷射进行大量的堆分配和泄露任何动态链接库的地址都能破解随机化。
- 使用哈希函数。这会来巨大的开销,同时哈希函数的安全性没有绝对的保证。
- 缩减安全区。这和第1点恰恰相反,看似有道理,但是如果mmap仍然是连续的,则其实质没有改变。所以必须同时搭配不连续的mmap。更小的安全区会引入额外开销,并且有可能没有足够空间用以保护敏感指针。
- 使用不连续的随机mmap。这一方案必须搭配第4点使用,否则任何破解随机化的技术(如第2点当中提及的两项)都将削弱其安全性。
CPI作者的回应
攻击公开后,CPI作者做了正式的回应。有趣的是,回应的标题是Getting The Point(er),而攻击论文的标题是Missing the Point(er)。回应重申,CPI的正确性是经过形式化证明的,攻击只是针对其中最简单的一种实现。其他更复杂的实现会导致更多的程序崩溃(约51000次,对CPS来说约867000次),而作者相信这样的崩溃是能被检测到的。
结语
信息安全的发展从来就不是攻击或者是防御单方面能够推动的。道高一尺魔高一丈在信安领域体现的最为明显。一个人造出了坚固的盾,就有千百人想要用一把锋利的矛来攻破它(有些人选择绕开持盾者,更有甚者,直接看准时机杀死拿盾的人)。反之亦然。信息安全就在这样的发展过程中,从无到有,由小而大。
一点八卦
提出攻击的论文是由美国国防部及美国空军赞助的。具体可见如下论文注释:

“此项工作由国防部国防研究与工程办公室副主任在空军FA8721-05-C-0002号合同框架内赞助。本文任何意见,解释,结论和建议是作者的观点,不一定得到美国政府的认可。”