
作者:0x7F@知道创宇404实验室
0x00 前言
最近在使用 Golang 的 regexp 对网络流量做正则匹配时,发现有些情况无法正确进行匹配,找到资料发现 regexp 内部以 UTF-8 编码的方式来处理正则表达式,而网络流量是字节序列,由其中的非 UTF-8 字符造成的问题。
我们这里从 Golang 的字符编码和 regexp 处理机制开始学习和分析问题,并寻找一个有效且比较通用的解决方法,本文对此进行记录。
本文代码测试环境 go version go1.14.2 darwin/amd64
0x01 regexp匹配字节序列
我们将匹配网络流量所遇到的问题,进行抽象和最小化复现,如下:
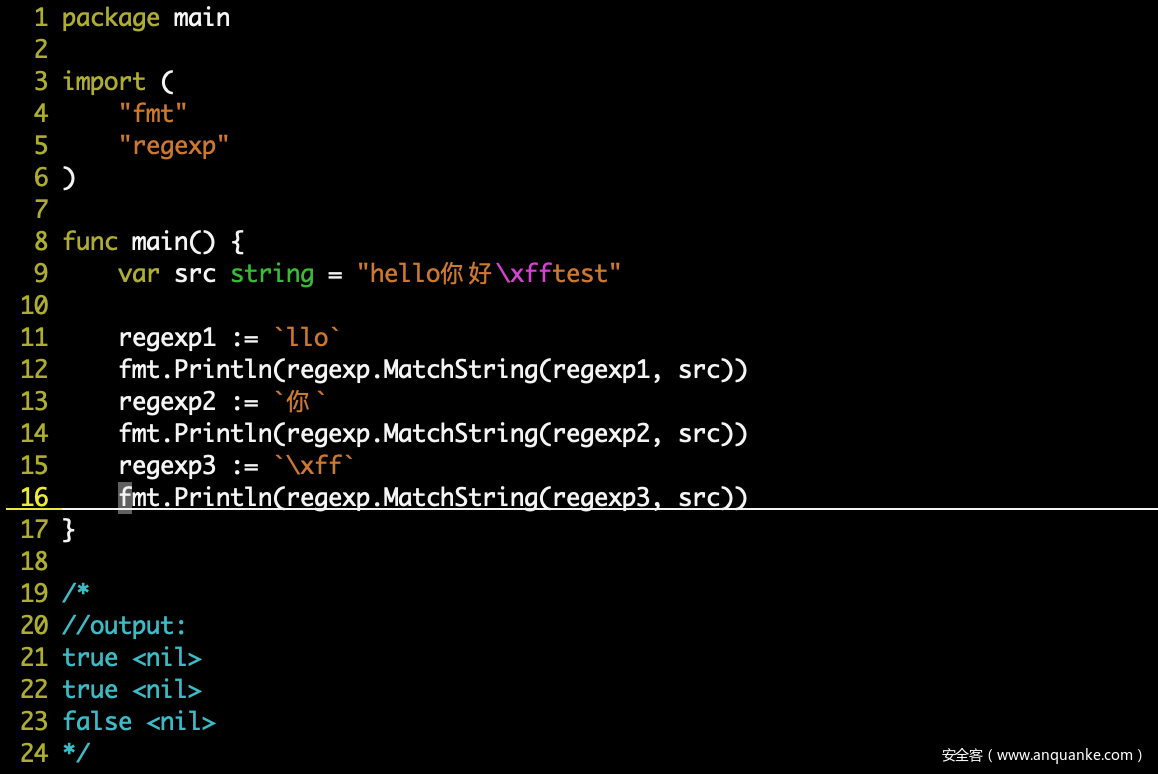
我们可以看到 \xff 没有按照预期被匹配到,那么问题出在哪里呢?
0x02 UTF-8编码
翻阅 Golang 的资料,我们知道 Golang 的源码采用 UTF-8 编码, regexp 库的正则表达式也是采用 UTF-8 进行解析编译(而且 Golang 的作者也是 UTF-8 的作者),那我们先来看看 UTF-8 编码规范。
1.ASCII
在计算机的世界,字符最终都由二进制来存储,标准 ASCII 编码使用一个字节(低7位),所以只能表示 127 个字符,而不同国家有不同的字符,所以建立了自己的编码规范,当不同国家相互通信的时候,由于编码规范不同,就会造成乱码问题。
“中文”
GB2312: \xd6\xd0\xce\xc4
ASCII: ????
2.Unicode
为了解决乱码问题,提出了 Unicode 字符集,为所有字符分配一个独一无二的编码,随着 Unicode 的发展,不断添加新的字符,目前最新的 Unicode 采用 UCS-4(Unicode-32) 标准,也就是使用 4 字节(32位) 来进行编码,理论上可以涵盖所有字符。
但是 Unicode 只是字符集,没有考虑计算机中的使用和存储问题,比如:
- 与已存在的 ASCII 编码不兼容,
ASCII(A)=65 / UCS-2(A)=0065 - 由于 Unicode 编码高字节可能为 0,C 语言字符串串函数将出现 00 截断问题
- 从全世界来看原来 ASCII 的字符串使用得最多,而换成 Unicode 过后,这些 ASCII 字符的存储都将额外占用字节(存储0x00)
3.UTF-8
后来提出了 UTF-8 编码方案,UTF-8 是在互联网上使用最广的一种 Unicode 的实现方式;UTF-8 是一种变长的编码方式,编码规则如下:
- 对于单字节的符号,字节的第一位设为 0,后面 7 位为这个符号的 Unicode 的码点,兼容 ASCII
- 对于需要 n 字节来表示的符号(n > 1),第一个字节的前 n 位都设为 1,第 n+1 位设置为 0;后面字节的前两位一律设为 10,剩下的的二进制位则用于存储这个符号的 Unicode 码点(从低位开始)。
编码规则如下:
Unicode符号范围(十六进制) | UTF-8编码方式(二进制)
00000000 - 0000007F | 0xxxxxxx
00000080 - 000007FF | 110xxxxx 10xxxxxx
00000800 - 0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx
00010000 - 0010FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
编码中文 你 如下:
Unicode: \u4f60 (0b 01001111 01100000)
UTF-8: \xe4\xbd\xa0 (0b 1110/0100 10/111101 10/100000)
(这里用斜线分割了下 UTF-8 编码的前缀)
1.根据 UTF-8 编码规则,当需要编码的符号超过 1 个字节时,其第一个字节前面的 1 的个数表示该字符占用了几个字节。
2.UTF-8 是自同步码(Self-synchronizing_code),在 UTF-8 编码规则中,任意字符的第一个字节必然以 0 / 110 / 1110 / 11110 开头,UTF-8 选择 10 作为后续字节的前缀码,以此进行区分。自同步码可以便于程序寻找字符边界,快速跳过字符,当遇到错误字符时,可以跳过该字符完成后续字符的解析,这样不会造成乱码扩散的问题(GB2312存在该问题)
0x03 byte/rune/string
在 Golang 中源码使用 UTF-8 编码,我们编写的代码/字符会按照 UTF-8 进行编码,而和字符相关的有三种类型 byte/rune/string。
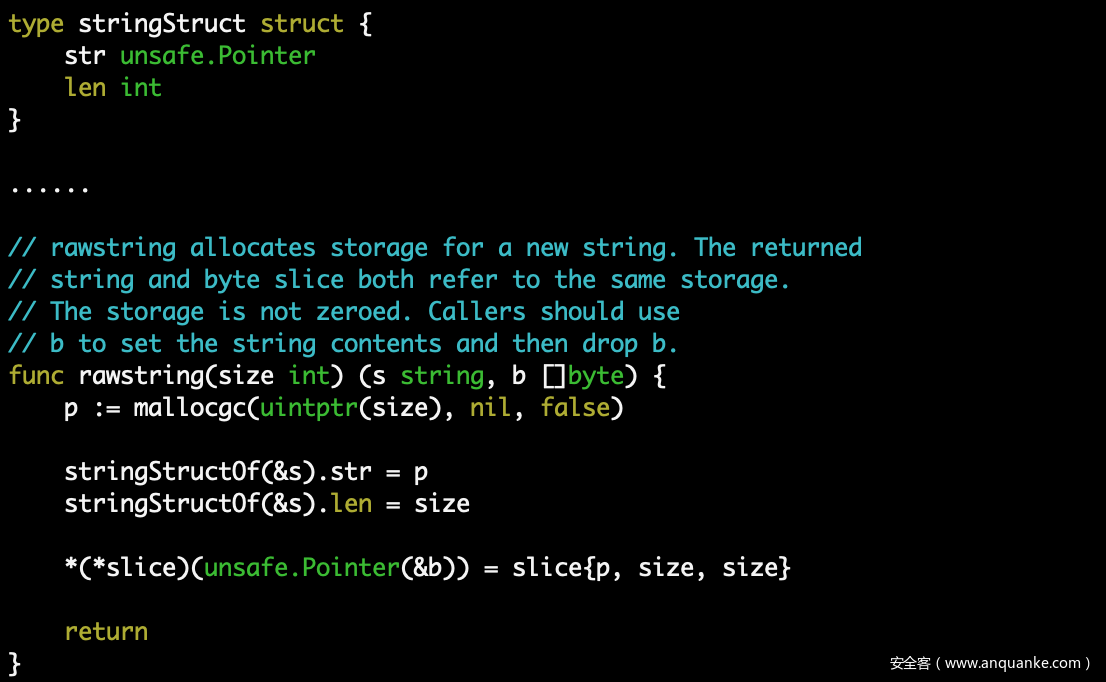
byte 是最简单的字节类型(uint8),string 是固定长度的字节序列,其定义和初始化在 https://github.com/golang/go/blob/master/src/runtime/string.go,可以看到 string 底层就是使用 []byte 实现的:
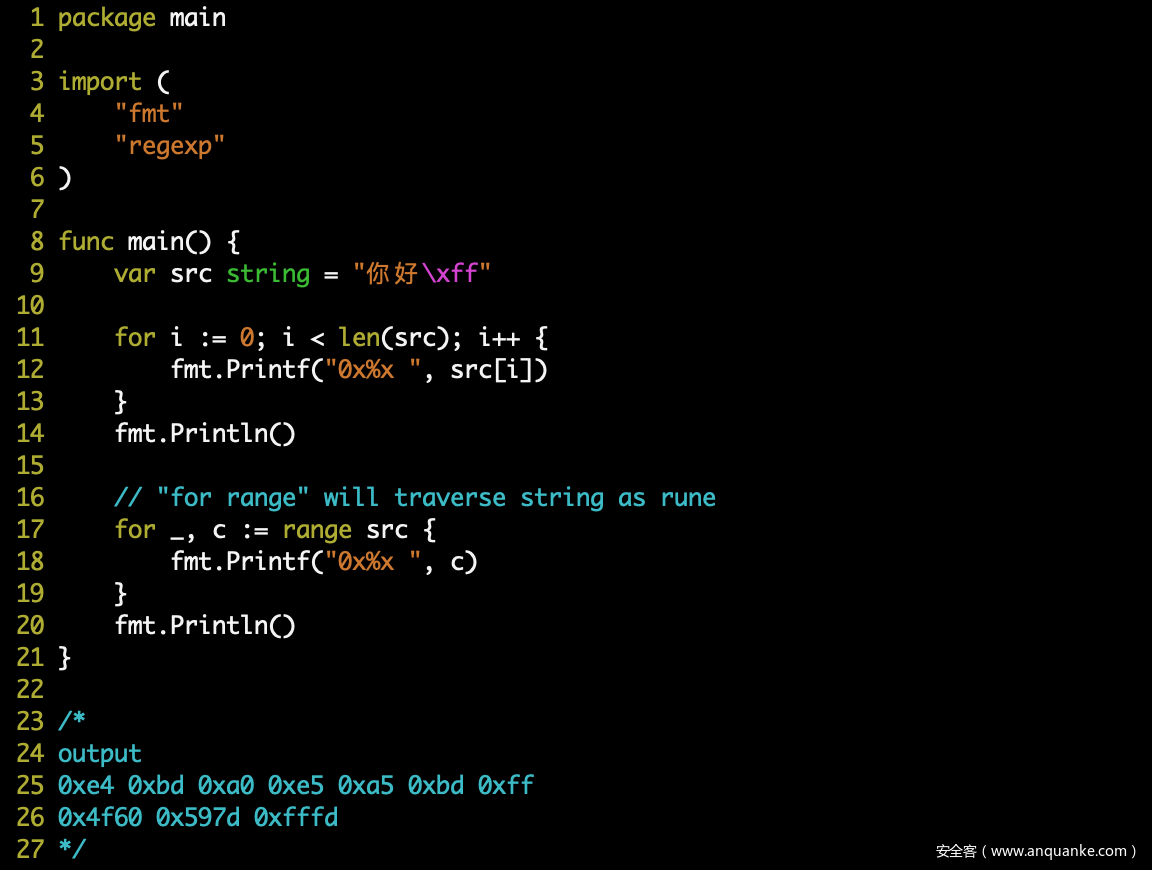
rune 类型则是 Golang 中用来处理 UTF-8 编码的类型,实际类型为 int32,存储的值是字符的 Unicode 码点,所以 rune 类型可以便于我们更直观的遍历字符(对比遍历字节)如下:
类型转换
byte(uint8) 和 rune(int32) 可以直接通过位扩展或者舍弃高位来进行转换。
string 转换比较复杂,我们一步一步来看:
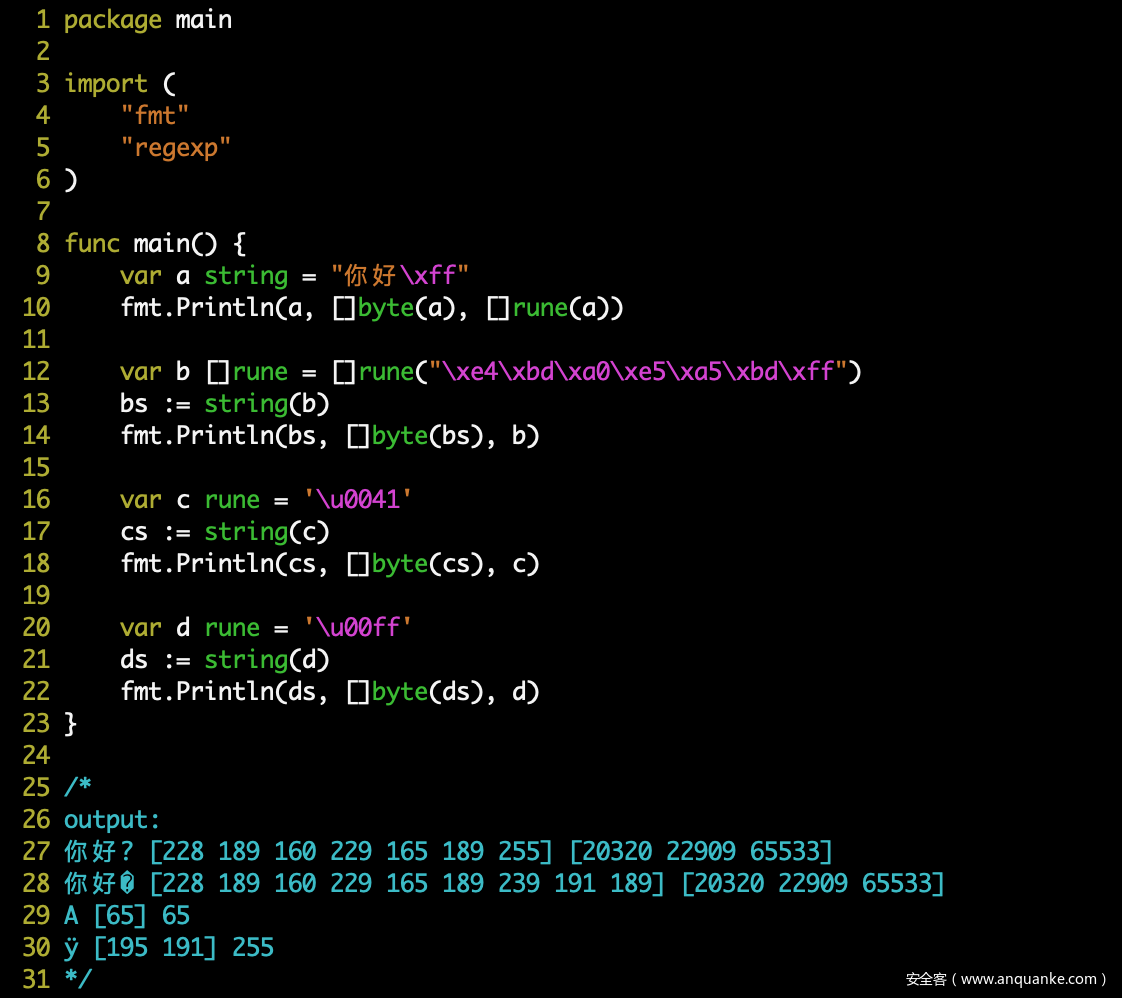
string 和 byte 类型相互转换时,底层都是 byte 可以直接相互转换,但是当单字节 byte 转 string 类型时,会调用底层函数 intstring() (https://github.com/golang/go/blob/master/src/runtime/string.go#L244),然后调用 encoderune() 函数,对该字节进行 UTF-8 编码,测试如下:
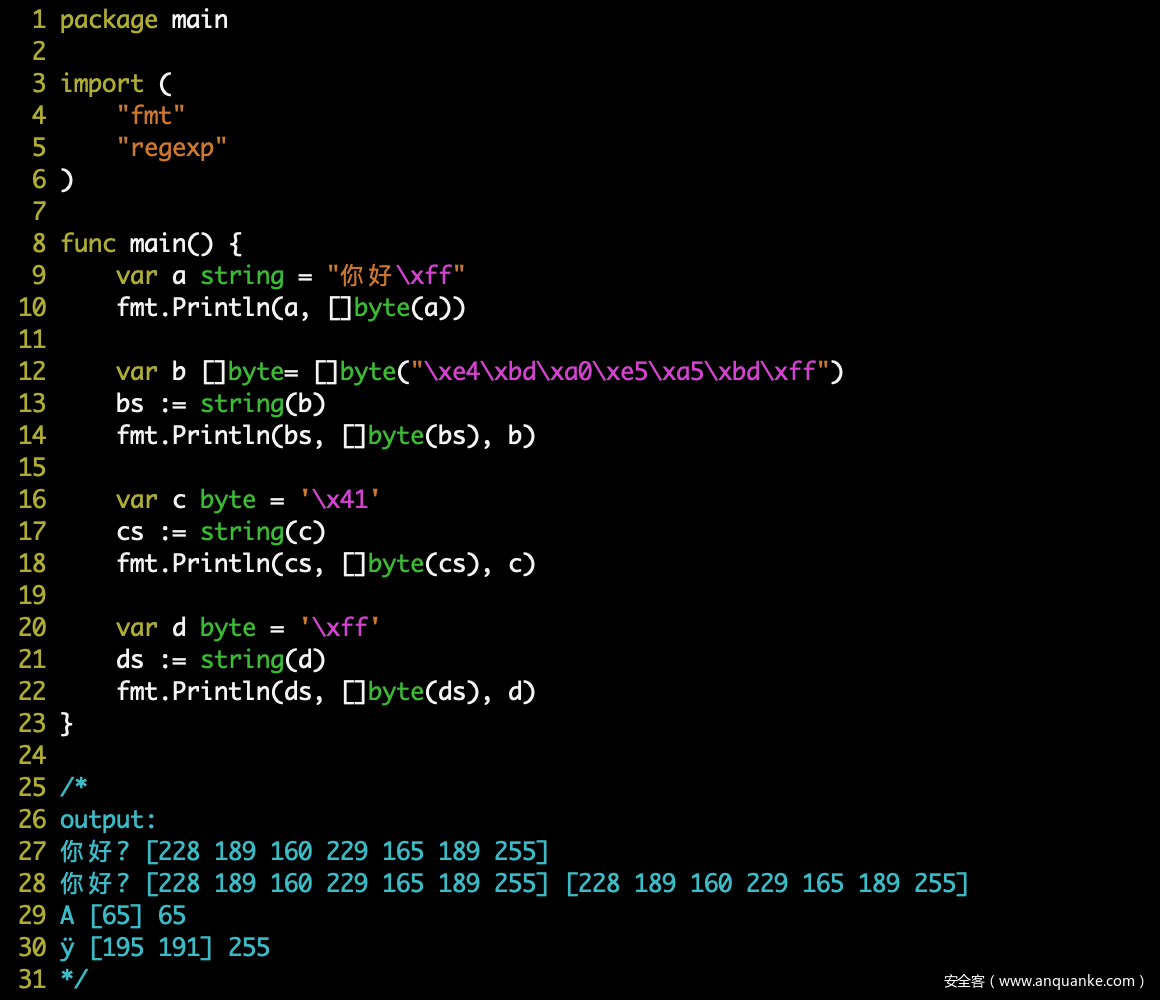
string 和 rune 类型相互转换时,对于 UTF-8 字符的相互转换,底层数据发生变化 UTF-8编码 <=> Unicode编码;而对于非 UTF-8 字符,将以底层单字节进行处理:
-
string => rune时,会调用stringtoslicerune()(https://github.com/golang/go/blob/master/src/runtime/string.go#L178),最终跟进到 Golang 编译器的for-range实现(https://github.com/golang/go/blob/master/src/cmd/compile/internal/walk/range.go#L220),转换时调用decoderune()对字符进行 UTF-8 解码,解码失败时(非 UTF-8 字符)将返回RuneError = \uFFFD; -
rune => string时,和byte单字节转换一样,会调用intstring()函数,对值进行 UTF-8 编码。
测试如下:
0x04 regexp处理表达式
在 regexp 中所有的字符都必须为 UTF-8 编码,在正则表达式编译前会对字符进行检查,非 UTF-8 字符将直接提示错误;当然他也支持转义字符,比如:\t \a 或者 16进制,在代码中我们一般需要使用反引号包裹正则表达式(原始字符串),转义字符由 regexp 在内部进行解析处理,如下:

当然为了让
regexp编译包含非 UTF-8 编码字符的表达式,必须用反引号包裹才行
我们在使用 regexp 时,其内部首先会对正则表达式进行编译,然后再进行匹配。
1.编译
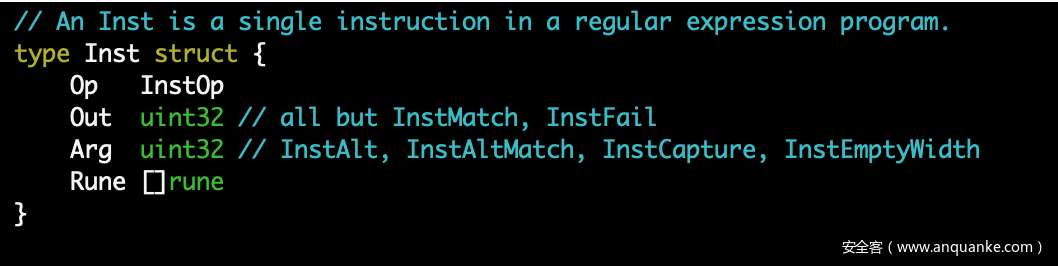
编译主要是构建自动机表达式,其底层最终使用 rune 类型存储字符(https://github.com/golang/go/blob/master/src/regexp/syntax/prog.go#L112),所以 \xff 通过转义后最终存储为 0x00ff (rune)
除此之外,在编译阶段 regexp 还会提前生成正则表达式中的前缀字符串,在执行自动机匹配前,先用匹配前缀字符串,以提高匹配效率。需要注意的是,生成前缀字符串时其底层将调用 strings.Builder 的 WriteRune() 函数(https://github.com/golang/go/blob/master/src/regexp/syntax/prog.go#L147),内部将调用 utf8.EncodeRune() 强制转换表达式的字符为 UTF-8 编码(如:\xff => \xc3\xbf)。
2.匹配
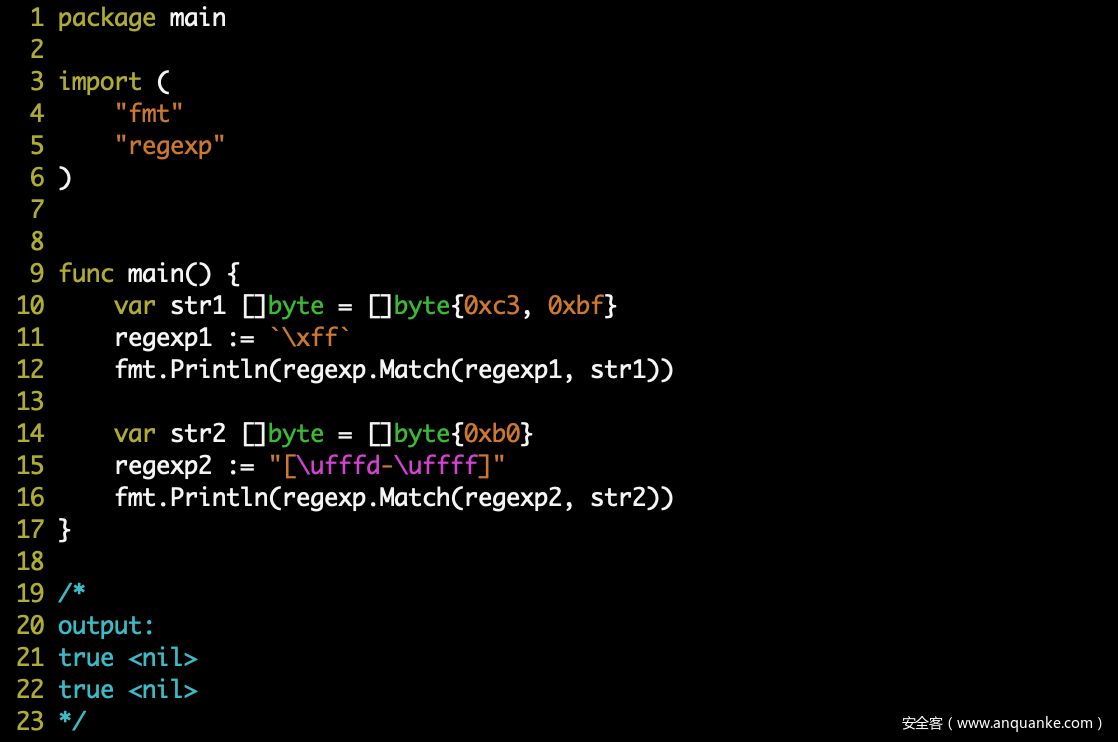
当匹配时,首先使用前缀字符串匹配,这里使用常规的字符串匹配。UTF-8 可以正常进行匹配,但当我们的字符串中包含非 UTF-8 字符就会出现问题,原因正则表达式中的前缀字符串已经被强制 UTF-8 编码了,示例如下:
regexp: `\xff`
real regexp prefix: []byte(\xc3\xbf)
string: "\xff"
real string: []byte(\xff)
[NOT MATCHED]
当执行自动机匹配时,将最终调用 tryBacktrace() 函数进行逐字节回溯匹配(https://github.com/golang/go/blob/master/src/regexp/backtrack.go#L140),使用 step() 函数遍历字符串(https://github.com/golang/go/blob/master/src/regexp/regexp.go#L383),该函数有 string/byte/rune 三种实现,其中 string/byte 将调用 utf8.DecodeRune*() 强制为 rune 类型,所以三种实现最终都返回 rune 类型,然后和自动机表达式存储的 rune 值进行比较,完成匹配。而这里当非 UTF-8 字符通过 utf8.DecodeRune*() 函数时,将返回 RuneError=0xfffd,示例如下:
(PS: 不应该用简单字符表达式,简单字符表达式将会直接使用前缀字符串完成匹配)
regexp: `\xcf-\xff`
real regexp inst: {Op:InstRune Out:4 Arg:0 Rune:[207 255]}
string: "\xff"
string by step(): 0xfffd
[NOT MATCHED]
比较复杂,不过简而言之就是 regexp 内部会对表达式进行 UTF-8 编码,会对字符串进行 UTF-8 解码。
了解 regexp 底层匹配运行原理过后,我们甚至可以构造出更奇怪的匹配:
0x05 解决方法
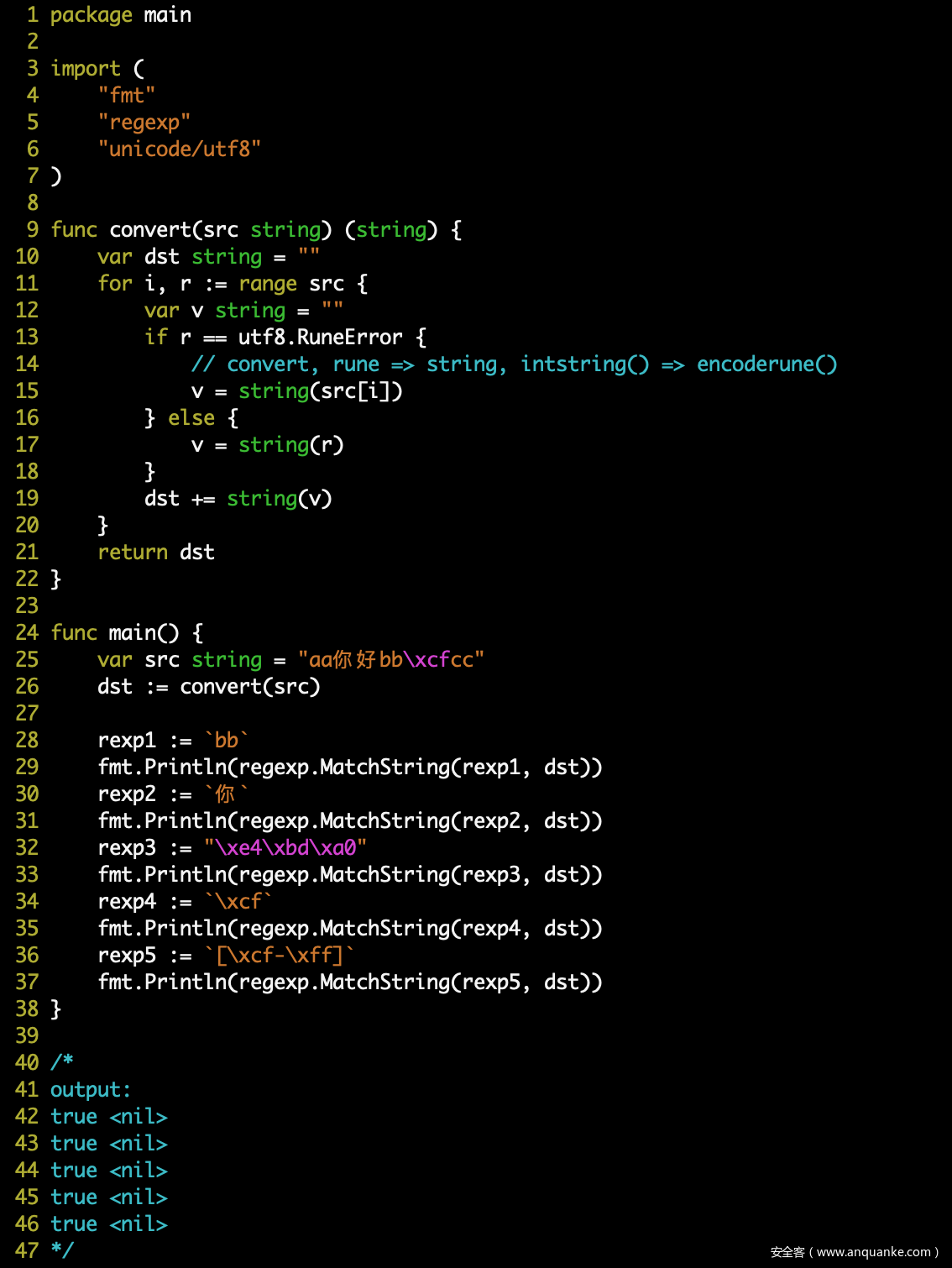
在了解以上知识点过后,就很容易解决问题了:表达式可以使用任意字符,待匹配字符串在匹配前手动转换为合法的 UTF-8 字符串。
因为当 regexp 使用前缀字符串匹配时,会自动转换表达式字符为 UTF-8 编码,和我们的字符串一致;当 regexp 使用自动机匹配时,底层使用 rune 进行比较,我们传入的 UTF-8 字符串将被正确通过 UTF-8 解码,可以正确进行匹配。
实现测试如下:
0x06 总结
关于开头提出的 regexp 匹配的问题到这里就解决了,在不断深入语言实现细节的过程中发现:Golang 本身在尽可能的保持 UTF-8 编码的一致性,但在编程中字节序列是不可避免的,Golang 中使用 string/byte 类型来进行处理,在 regexp 底层实现同样使用了 UTF-8 编码,所以问题就出现了,字节序列数据和编码后的数据不一致。
个人感觉 regexp 用于匹配字节流并不是一个预期的使用场景,像是 Golang 官方在 UTF-8 方面的一个取舍。
当然这个过程中,我们翻阅了很多 Golang 底层的知识,如字符集、源码等,让我们了解了一些 Golang 的实现细节;在实际常见下我们不是一定要使用标准库 regexp,还可以使用其他的正则表达式库来绕过这个问题。
References:
https://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
https://blog.golang.org/strings
https://zh.wikipedia.org/wiki/UTF-8
https://stackoverflow.com/questions/53009692/utf-8-encoding-why-prefix-10
https://en.wikipedia.org/wiki/Self-synchronizing_code
https://www.zhihu.com/question/19817672
https://pkg.go.dev/regexp/syntax
https://github.com/golang/go/issues/38006
https://github.com/golang/go/tree/master/src/regexp
https://golang.org/src/runtime/string.go
https://github.com/golang/go/blob/master/src/builtin/builtin.go
https://github.com/golang/gofrontend/blob/master/go/statements.cc#L6841
https://github.com/golang/go/blob/master/src/cmd/compile/internal/walk/range.go#L220
https://github.com/golang/go/blob/master/src/runtime/string.go#L244
https://github.com/golang/go/blob/master/src/runtime/string.go#L178