
题目按照上线时间排序
Real_CHECKIN
题如其名,真的是签到题,出题的时候调试符号都没去。扔进PEID可以看出是upx壳,脱壳后用ida f5就能看到基本上和源码完全一致的伪代码。
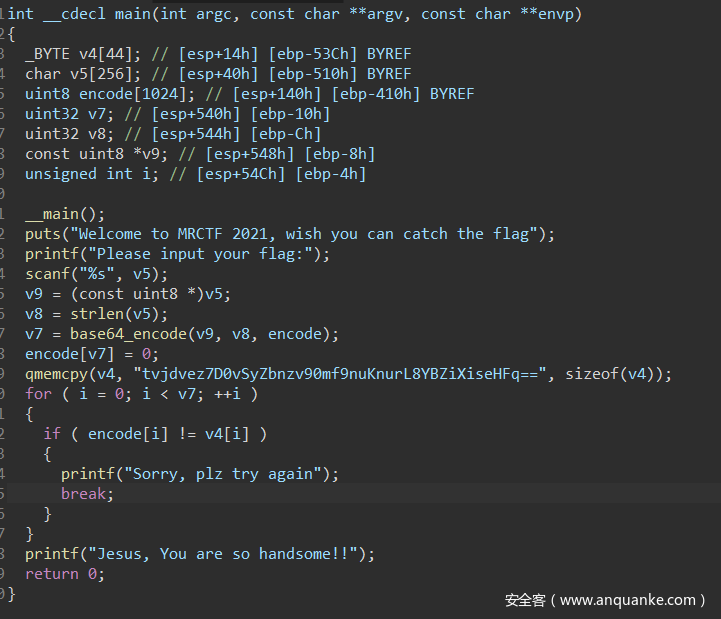
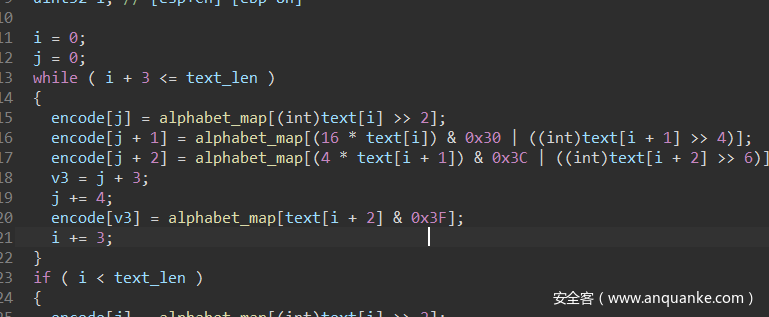
直接由函数名知道是base64编码,进入base64_encode函数并查看alphabet_map,可以发现base64换表了,用python写个脚本就得到flag了

import base64
my_base64table = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789+/"
std_base64table ="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
s = "tvjdvez7D0vSyZbnzv90mf9nuKnurL8YBZiXiseHFq=="
s = s.translate(str.maketrans(my_base64table,std_base64table))
print(base64.b64decode(s))
# MRCTF{wElc0Me_t0_MRCTF_2o21!!!}
EzGame
该题目使用了Unity3D来编写,但是使用的并非传统的Mono虚拟机,而是il2cpp,该框架能够将C#转化为C++代码,然后运行在其虚拟机中
题目要求分析
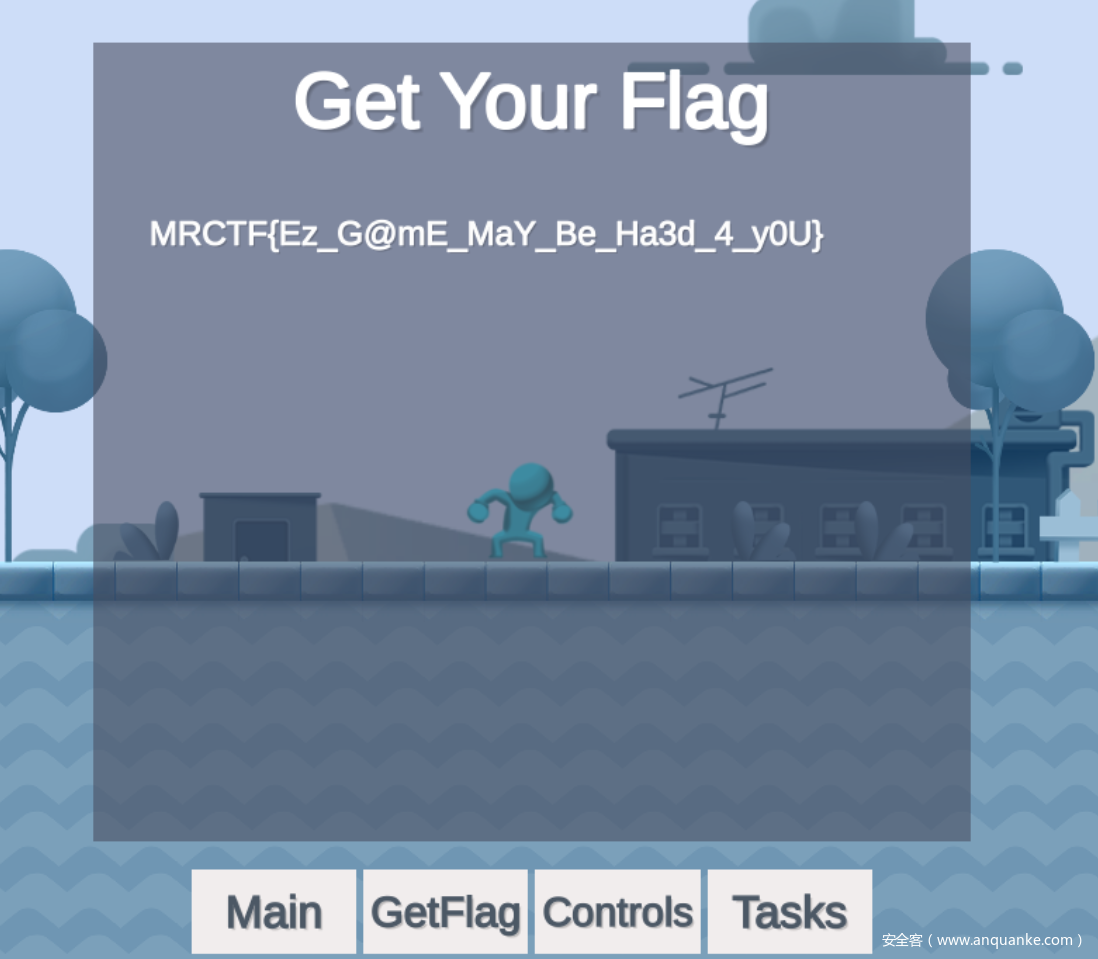
先按ESC打开菜单页面,找到有GetFlag按钮,然后必然是拿不到Flag的,后面还有Tasks,显示需要干什么
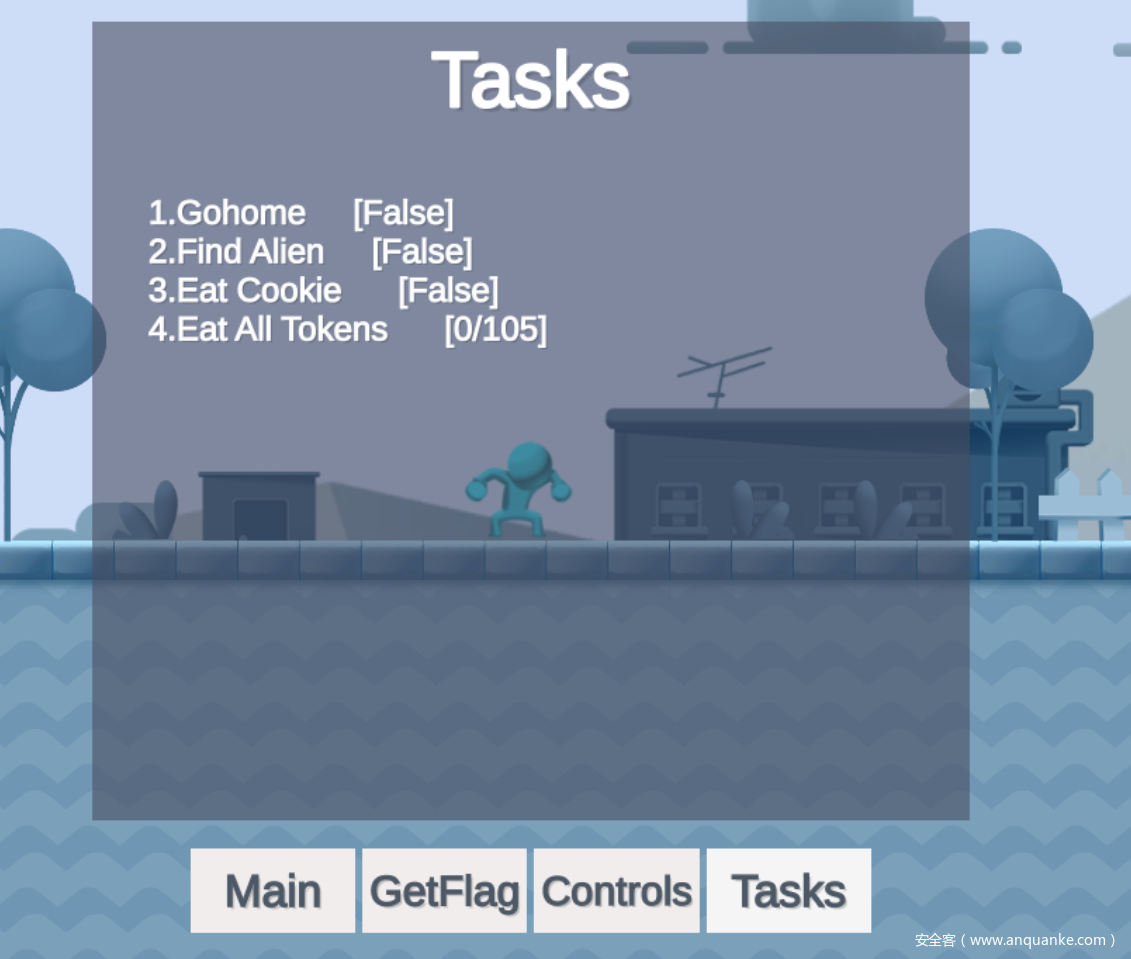
然后GetFlag按钮提示不能死的太多次
所以可以总结出需要以下几点
- 1.吃到所有的星星
- 2.找到外星人
- 3.吃到饼干
- 4.到家里,也就是终点
- 5.不能死太多次
至于如何找到外星人和饼干还有通关,我就不多说了


饼干路上就可以看到,外星人则在出生点的地底下,可以通过出生点左边墙壁的缝隙出去到达
但是为了吃掉饼干和找到外星人都会导致死亡次数增加,所以不妨使用CE搜索死亡次数,然后锁定成0
就不用担心死亡了
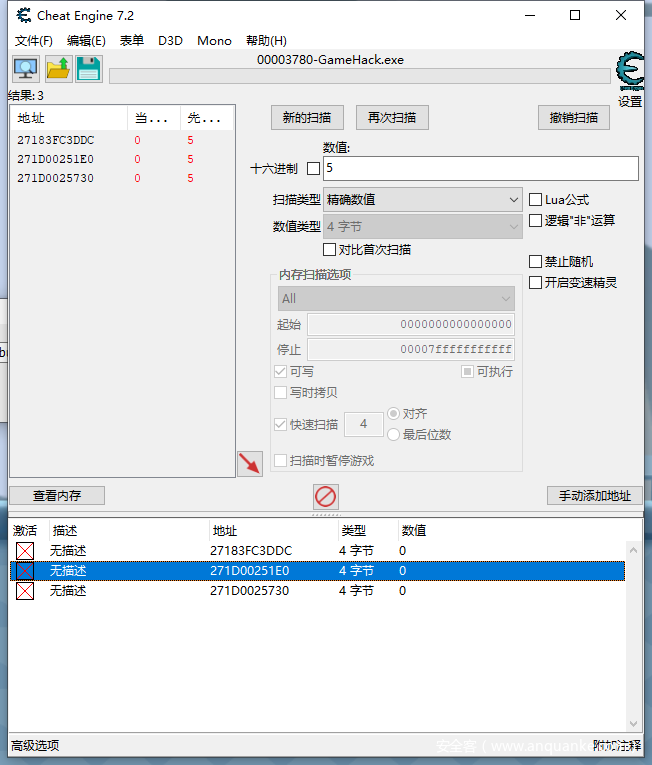
接下来就是要解决吃饼干的事情,事实上单纯通过CE修改并没有什么用
会发现它检测出来了,所以单纯使用CE是做不出这个题目的,所以到这里的都是废话,看了也做不出
继续分析框架
U3d的程序逻辑都是放在GameAssembly.dll里的
可以发现该游戏使用的il2cpp是有工具来反编译GameAssembly.dll的,虽然将源码编译成了C++,但是可以IDA,然后还有个IL2CPPDumper工具,
能够dump出该DLL里的所有类以及类里的方法和成员
然后可以通过dnspy来打开dummydll里的dll看这些东西,注意这些都是假的,并没有代码,但是可以大致看出程序结构
可以发现在GetFlag类里有很多和flag相关的东西
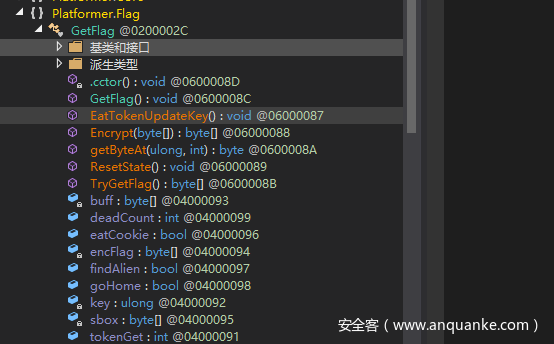
比如死亡次数,吃了多少星星,是否拿到饼干,是否找到外星人,正与游戏逻辑相符,还有encflag,key
还有个方法需要注意,就是EatTokenUpdateKey,其他都是加密方法。
这就是CE直接修改数目无法得到flag的原因,需要每次吃到星星后EatTokenUpdateKey方法,才能得到真正的key来解密flag

可以找到RVA,然后试试打开IDA,我们来看GameAssembly.dll里的这个函数代码,
然后关闭IDA——坏蛋出题人加了Themida的壳
当然出题人也很想钓到去掉这个壳的WP 哈哈哈哈
考虑使用IL2CPP的API
我们可以发现IL2CPP的源码中有许多的API函数,都是以il2cpp_XXXX_XXXX_XXX来命名的

这点可以在GameAssembly.dll(未加壳之前)的导出表中得到验证,要是熟悉java的反射机制可以猜出这些函数的用处,这就是能够操控il2cpp虚拟机的API
所以只需要调用EatTokenUpdateKey方法然后修改一下那几个Field即可,即可满足题目的约束条件,最后的key一定是正确的
但是调用需要的反射的代码怎么执行呢,可以考虑frida或者dll注入,这里使用dll注入,然后使用GetProcAddress获得API地址并如下调用即可
- il2cpp_class_for_each 是用于遍历加载的类,其中getclass是个callback
- il2cpp_class_get_name 得到当前处理的类名称,看看是否是GetFlag类
- il2cpp_class_get_method 是通过一个iterator来遍历类下面所有方法
- il2cpp_method_get_name 是通过一个method得到其名称,找到了就获得了EatTokenUpdateKey方法对象了
- il2cpp_class_get_field_from_name 是通过名称得到类下面的成员
- il2cpp_field_static_set_value 是设置静态变量的值
- il2cpp_runtime_invoke 是给与方法和对象,还有参数来调用,这里对象是空(静态方法无对象)。
以上方法的用法可以去Il2cpp的源码就可以看懂了

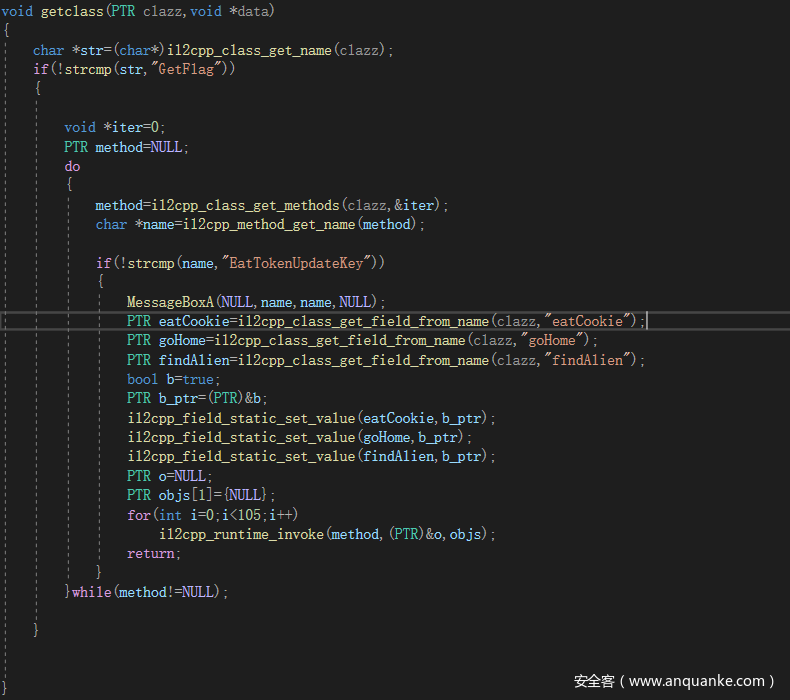
注意最后一个invoke的for循环次数取决于你已经捡了多少个星星,不然会导致flag得不到
编译出dll后,先等一会,呼出getflag界面,其实就是为了让GetFlag先加载,防止找不到该类
然后使用dll注入工具注入该dll即可
直接按下getflag,轻松获得flag。
- 后记:该题目的设计思路来源于某个游戏,也是il2cpp+themida的组合,然而开发人员却没有注意到il2cpp自己导出了很多运行时函数,所以还是能够大体的做到透视,改血量等操作,只要把il2cpp的源码改掉,去掉那些API即可使这种攻击失效,或者直接源码级混淆
Dynamic Debug
本来想整个反调试+SMC的活,使得调试状态和静态反编译的情况下都看不到真实的验证代码,结果把附件传错了,动调状态下直接能看到真实逻辑了,让这题瞬间成签到题了..
题解
- 进去发现是静态链接,尝试用 sig 识别库函数,libc2.30的能识别出大多数函数
![]()
- 通过查找字符串很轻松就能找到main函数
![]()
- 找到了用于验证的函数,里面加了花指令,但这里一定不要patch,因为smc就是解密的这段代码,这里patch了解密后的代码就肯定有问题了
- 动调起来之后这段代码就变了,这时候可以在动调状态下patch
- patch之后可以查看伪代码了,就是个 TEA 加密
![]()
- 找个解密脚本跑一下就行了

class MyTea:
def __init__(self, key):
assert(type(key) == bytes)
assert(len(key) == 16)
self.k = [0]*4
for i in range(4):
self.k[i] = self.btoi(key[4*i:4*i+4])
@staticmethod
def btoi(b):
return int.from_bytes(b, byteorder="little", signed=False)
@staticmethod
def itob(i):
return int.to_bytes(i, 4, "little")
def decrypt(self, ciphertext: bytes):
plaintext = b''
for i in range(len(ciphertext)//8):
plaintext += self.decrypt_8_char(ciphertext[i*8:i*8+8])
return plaintext
def decrypt_8_char(self, sub_str):
assert(type(sub_str) == bytes)
assert(len(sub_str) == 8)
v0 = self.btoi(sub_str[:4])
v1 = self.btoi(sub_str[4:])
delta = 0x9e3779b9
sum = delta * 32
sum &= 0xffffffff
for _ in range(32):
v1 -= ((v0 << 4) + self.k[2]) ^ (v0 + sum) ^ ((v0 >> 5) + self.k[3])
v1 &= 0xFFFFFFFF
v0 -= ((v1 << 4) + self.k[0]) ^ (v1 + sum) ^ ((v1 >> 5) + self.k[1])
v0 &= 0xFFFFFFFF
sum -= delta
sum &= 0xffffffff
return self.itob(v0)+self.itob(v1)
if __name__ == "__main__":
cipher = [int.to_bytes(n, 1, "little")for n in [0x99, 0xA1, 0x85, 0x55, 0x68, 0x5D, 0x82, 0x7E, 0x39, 0x00,
0x4D, 0x94, 0x43, 0x69, 0x72, 0x71, 0x06, 0x43, 0x51, 0x6A,
0x00, 0xAD, 0x14, 0x4B, 0x3F, 0x0D, 0xD2, 0x64, 0x15, 0xDB,
0x37, 0x9F]]
cipher=b''.join(cipher)
key = b'ilike_dynamicdbg'
t = MyTea(key)
plain = t.decrypt(cipher)
print(plain)
# 'MRCTF{Dyn4m1c_d3buG_1s_a_ki11eR}'
- 实际上,这道题的自解密部分是在 .init_array 里,是很简单的亦或解密,但是亦或的 bytes 存储在了 dns 的 txt 记录里,所以纯静态调试是不可能做出来的,有兴趣的dalao可以跟一下解密的函数,基本过程就是 res_query 解析域名下的 txt 记录,base64 decode,最后再 smc
古神的低语
题目采用了LLVM对CFG进行了混淆,有两种混淆:
控制流平坦化
其实是一种变种的控制流平坦化,将原有的switch结构转化成了if嵌套
来实现跳转到哪个真实块,且if用于判断区间,那么原有的变量的数落在哪个区间那个区间才会被执行,所以就难以人眼判断真实块的后继是什么
且拥有多个预分发块,市面上的angr去控制路平坦化脚本失去了作用
函数合并
该混淆能够将个函数混合在一起成为一个MixFunction,然后通过一个标识变量来确定调用的是函数的哪个部分,增加了逆向的难度
-
解决方案
对于函数合并目前没有想到好的分割方法,但是对于第一种混淆可以修改一下基于angr的deflat脚本,来实现去除混淆
因为只需要将多个预分发块合成一个就可以按常规方法去除混淆了,但是对于MixFunction似乎去除有点问题,目前还没研究清楚
#!/usr/bin/env python3
import sys
sys.path.append("..")
sys.setrecursionlimit(3000)
import argparse
import angr
import pyvex
import claripy
import struct
from collections import defaultdict
import am_graph
from util import *
import logging
logging.getLogger('angr.state_plugins.symbolic_memory').setLevel(logging.ERROR)
# logging.getLogger('angr.sim_manager').setLevel(logging.DEBUG)
def get_relevant_nop_nodes(supergraph, pre_dispatcher_nodes, prologue_node, retn_node):
# relevant_nodes = list(supergraph.predecessors(pre_dispatcher_node))
relevant_nodes = []
nop_nodes = []
for node in supergraph.nodes():
should_nop=True
for pre_dispatcher_node in pre_dispatcher_nodes:
if supergraph.has_edge(node, pre_dispatcher_node) and node.size > 8:
# XXX: use node.size is faster than to create a block
relevant_nodes.append(node)
should_nop=False
break
if node.addr in (prologue_node.addr, retn_node.addr, pre_dispatcher_node.addr):
should_nop=False
break
if should_nop is True:
nop_nodes.append(node)
return relevant_nodes, nop_nodes
def symbolic_execution(project, relevant_block_addrs, start_addr, hook_addrs=None, modify_value=None, inspect=False):
def retn_procedure(state):
ip = state.solver.eval(state.regs.ip)
project.unhook(ip)
return
def statement_inspect(state):
expressions = list(
state.scratch.irsb.statements[state.inspect.statement].expressions)
if len(expressions) != 0 and isinstance(expressions[0], pyvex.expr.ITE):
state.scratch.temps[expressions[0].cond.tmp] = modify_value
state.inspect._breakpoints['statement'] = []
if hook_addrs is not None:
skip_length = 4
if project.arch.name in ARCH_X86:
skip_length = 5
for hook_addr in hook_addrs:
project.hook(hook_addr, retn_procedure, length=skip_length)
state = project.factory.blank_state(addr=start_addr)
if inspect:
state.inspect.b(
'statement', when=angr.state_plugins.inspect.BP_BEFORE, action=statement_inspect)
sm = project.factory.simulation_manager(state)
sm.step()
while len(sm.active) > 0:
for active_state in sm.active:
if active_state.addr in relevant_block_addrs:
return active_state.addr
sm.step()
return None
def main():
parser = argparse.ArgumentParser(description="deflat control flow script")
parser.add_argument("-f", "--file", help="binary to analyze")
parser.add_argument(
"--addr", help="address of target function in hex format")
args = parser.parse_args()
if args.file is None or args.addr is None:
parser.print_help()
sys.exit(0)
filename = args.file
start = int(args.addr, 16)
project = angr.Project(filename, load_options={'auto_load_libs': False})
# do normalize to avoid overlapping blocks, disable force_complete_scan to avoid possible "wrong" blocks
cfg = project.analyses.CFGFast(normalize=True, force_complete_scan=False)
target_function = cfg.functions.get(start)
# A super transition graph is a graph that looks like IDA Pro's CFG
supergraph = am_graph.to_supergraph(target_function.transition_graph)
base_addr = project.loader.main_object.mapped_base >> 12 << 12
# get prologue_node and retn_node
prologue_node = None
for node in supergraph.nodes():
if supergraph.in_degree(node) == 0:
prologue_node = node
if supergraph.out_degree(node) == 0 and len(node.out_branches) == 0:
retn_node = node
if prologue_node is None or prologue_node.addr != start:
print("Something must be wrong...")
sys.exit(-1)
pre_dispatcher_nodes=[]
main_dispatcher_node = list(supergraph.successors(prologue_node))[0]
for node in supergraph.predecessors(main_dispatcher_node): #Fixed
if node.addr != prologue_node.addr:
pre_dispatcher_nodes.append(node)
pre_dispatcher_node=pre_dispatcher_nodes[0]
relevant_nodes, nop_nodes = get_relevant_nop_nodes(
supergraph, pre_dispatcher_nodes, prologue_node, retn_node)
if len(pre_dispatcher_nodes)>1:
print('Multiple pre_dispatcher_nodes detected...\ntry to merge pre_dispatchers into one....')
print('************************merge*****************************')
with open(filename, 'rb') as origin:
# Attention: can't transform to str by calling decode() directly. so use bytearray instead.
origin_data = bytearray(origin.read())
origin_data_len = len(origin_data)
fixed_file = filename + '_merged'
fixing = open(fixed_file, 'wb')
target = pre_dispatcher_node
for nodes in relevant_nodes:
block = project.factory.block(nodes.addr, size=nodes.size)
last_instr = block.capstone.insns[-1]
file_offset = last_instr.address - base_addr
print("------------------------"+hex(nodes.addr)+"------------------------")
if project.arch.name in ARCH_X86:
fill_nop(origin_data, file_offset,
last_instr.size, project.arch)
patch_value = ins_j_jmp_hex_x86(last_instr.address, target.addr, 'jmp')
elif project.arch.name in ARCH_ARM:
patch_value = ins_b_jmp_hex_arm(last_instr.address, target.addr, 'b')
if project.arch.memory_endness == "Iend_BE":
patch_value = patch_value[::-1]
elif project.arch.name in ARCH_ARM64:
# FIXME: For aarch64/arm64, the last instruction of prologue seems useful in some cases, so patch the next instruction instead.
if parent.addr == start:
file_offset += 4
patch_value = ins_b_jmp_hex_arm64(last_instr.address+4, target.addr, 'b')
else:
patch_value = ins_b_jmp_hex_arm64(last_instr.address, target.addr, 'b')
if project.arch.memory_endness == "Iend_BE":
patch_value = patch_value[::-1]
patch_instruction(origin_data, file_offset, patch_value)
for useless in pre_dispatcher_nodes:
if useless!=target:
fill_nop(origin_data,useless.addr -base_addr,useless.size,project.arch)
fixing.write(origin_data)
fixing.close()
print('Merge Successfully!\nPlease run this scripts on %s again' % fixed_file)
sys.exit(-1)
print('*******************relevant blocks************************')
print('prologue: %#x' % start)
print('main_dispatcher: %#x' % main_dispatcher_node.addr)
print('pre_dispatcher: %#x' % pre_dispatcher_node.addr)
print('retn: %#x' % retn_node.addr)
relevant_block_addrs = [node.addr for node in relevant_nodes]
print('relevant_blocks:', [hex(addr) for addr in relevant_block_addrs])
print('*******************symbolic execution*********************')
relevants = relevant_nodes
relevants.append(prologue_node)
relevants_without_retn = list(relevants)
relevants.append(retn_node)
relevant_block_addrs.extend([prologue_node.addr, retn_node.addr])
flow = defaultdict(list)
patch_instrs = {}
for relevant in relevants_without_retn:
print('-------------------dse %#x---------------------' % relevant.addr)
block = project.factory.block(relevant.addr, size=relevant.size)
has_branches = False
hook_addrs = set([])
for ins in block.capstone.insns:
if project.arch.name in ARCH_X86:
if ins.insn.mnemonic.startswith('cmov'):
# only record the first one
if relevant not in patch_instrs:
patch_instrs[relevant] = ins
has_branches = True
elif ins.insn.mnemonic.startswith('call'):
hook_addrs.add(ins.insn.address)
elif project.arch.name in ARCH_ARM:
if ins.insn.mnemonic != 'mov' and ins.insn.mnemonic.startswith('mov'):
if relevant not in patch_instrs:
patch_instrs[relevant] = ins
has_branches = True
elif ins.insn.mnemonic in {'bl', 'blx'}:
hook_addrs.add(ins.insn.address)
elif project.arch.name in ARCH_ARM64:
if ins.insn.mnemonic.startswith('cset'):
if relevant not in patch_instrs:
patch_instrs[relevant] = ins
has_branches = True
elif ins.insn.mnemonic in {'bl', 'blr'}:
hook_addrs.add(ins.insn.address)
if has_branches:
tmp_addr = symbolic_execution(project, relevant_block_addrs,
relevant.addr, hook_addrs, claripy.BVV(1, 1), True)
if tmp_addr is not None:
flow[relevant].append(tmp_addr)
tmp_addr = symbolic_execution(project, relevant_block_addrs,
relevant.addr, hook_addrs, claripy.BVV(0, 1), True)
if tmp_addr is not None:
flow[relevant].append(tmp_addr)
else:
tmp_addr = symbolic_execution(project, relevant_block_addrs,
relevant.addr, hook_addrs)
if tmp_addr is not None:
flow[relevant].append(tmp_addr)
print('************************flow******************************')
for k, v in flow.items():
print('%#x: ' % k.addr, [hex(child) for child in v])
print('%#x: ' % retn_node.addr, [])
print('************************patch*****************************')
with open(filename, 'rb') as origin:
# Attention: can't transform to str by calling decode() directly. so use bytearray instead.
origin_data = bytearray(origin.read())
origin_data_len = len(origin_data)
recovery_file = filename + '_recovered'
recovery = open(recovery_file, 'wb')
# patch irrelevant blocks
for nop_node in nop_nodes:
fill_nop(origin_data, nop_node.addr-base_addr,
nop_node.size, project.arch)
# remove unnecessary control flows
for parent, childs in flow.items():
if len(childs) == 1:
parent_block = project.factory.block(parent.addr, size=parent.size)
last_instr = parent_block.capstone.insns[-1]
file_offset = last_instr.address - base_addr
# patch the last instruction to jmp
if project.arch.name in ARCH_X86:
fill_nop(origin_data, file_offset,
last_instr.size, project.arch)
patch_value = ins_j_jmp_hex_x86(last_instr.address, childs[0], 'jmp')
elif project.arch.name in ARCH_ARM:
patch_value = ins_b_jmp_hex_arm(last_instr.address, childs[0], 'b')
if project.arch.memory_endness == "Iend_BE":
patch_value = patch_value[::-1]
elif project.arch.name in ARCH_ARM64:
# FIXME: For aarch64/arm64, the last instruction of prologue seems useful in some cases, so patch the next instruction instead.
if parent.addr == start:
file_offset += 4
patch_value = ins_b_jmp_hex_arm64(last_instr.address+4, childs[0], 'b')
else:
patch_value = ins_b_jmp_hex_arm64(last_instr.address, childs[0], 'b')
if project.arch.memory_endness == "Iend_BE":
patch_value = patch_value[::-1]
patch_instruction(origin_data, file_offset, patch_value)
else:
instr = patch_instrs[parent]
file_offset = instr.address - base_addr
# patch instructions starting from `cmovx` to the end of block
fill_nop(origin_data, file_offset, parent.addr +
parent.size - base_addr - file_offset, project.arch)
if project.arch.name in ARCH_X86:
# patch the cmovx instruction to jx instruction
patch_value = ins_j_jmp_hex_x86(instr.address, childs[0], instr.mnemonic[len('cmov'):])
patch_instruction(origin_data, file_offset, patch_value)
file_offset += 6
# patch the next instruction to jmp instrcution
patch_value = ins_j_jmp_hex_x86(instr.address+6, childs[1], 'jmp')
patch_instruction(origin_data, file_offset, patch_value)
elif project.arch.name in ARCH_ARM:
# patch the movx instruction to bx instruction
bx_cond = 'b' + instr.mnemonic[len('mov'):]
patch_value = ins_b_jmp_hex_arm(instr.address, childs[0], bx_cond)
if project.arch.memory_endness == 'Iend_BE':
patch_value = patch_value[::-1]
patch_instruction(origin_data, file_offset, patch_value)
file_offset += 4
# patch the next instruction to b instrcution
patch_value = ins_b_jmp_hex_arm(instr.address+4, childs[1], 'b')
if project.arch.memory_endness == 'Iend_BE':
patch_value = patch_value[::-1]
patch_instruction(origin_data, file_offset, patch_value)
elif project.arch.name in ARCH_ARM64:
# patch the cset.xx instruction to bx instruction
bx_cond = instr.op_str.split(',')[-1].strip()
patch_value = ins_b_jmp_hex_arm64(instr.address, childs[0], bx_cond)
if project.arch.memory_endness == 'Iend_BE':
patch_value = patch_value[::-1]
patch_instruction(origin_data, file_offset, patch_value)
file_offset += 4
# patch the next instruction to b instruction
patch_value = ins_b_jmp_hex_arm64(instr.address+4, childs[1], 'b')
if project.arch.memory_endness == 'Iend_BE':
patch_value = patch_value[::-1]
patch_instruction(origin_data, file_offset, patch_value)
assert len(origin_data) == origin_data_len, "Error: size of data changed!!!"
recovery.write(origin_data)
recovery.close()
print('Successful! The recovered file: %s' % recovery_file)
if __name__ == '__main__':
main()
第一次执行之后会提示检测到多个预分发块,然后合并,第二次执行即可去掉该混淆
-
分析main函数
去除之后的main函数逻辑比较分明,只是再MixFunction处有点难看
先是输入部分,很容易看懂,输入的密码长度必须是32位![]()
然后对用户名由字符串转化成为了16进制数据![]()
接下来就调用了几次MixFunction,可以看到前两个函数对usr进行操作,但是并未涉及pwd![]()
然后动调发现生成了数据到out_stream数组里,可以考虑dump出来,就不用管生成的过程了,由于出题人把源码弄丢了,只能dump来做了
其实这是个ZUC流密码算法生成的流![]()
然后是使用了ezkeyforenc字符串,不难想到是加密算法的密钥
而后面两个函数形式是一样的,第一个传入pwd地址,第二个传入pwd[16],不难想到这应该是分块加密算法
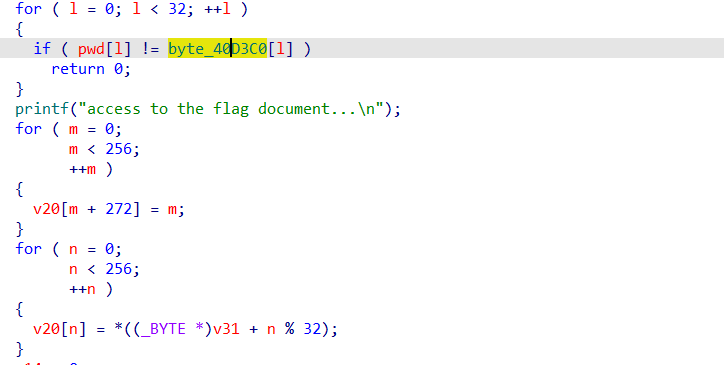
而16字节的分块加密算法最常见的就是AES,然后F7入函数跟踪,明显见到了AES的sbox,所以大概就清楚这里是AES了![]()
接下来就是一个两层for循环的加密,每次是8字节,而且使用了之前算出来的流秘钥![]()
类比TEA的加密算法,不难写出解密算法![]()
然后后面就是比较数据了,且比较成功后使用的是对比成功的数据,所以只要满足数据对比,后面的过程不用关心
虽然后面就是个RC4算法解密文件而已![]()
![]()






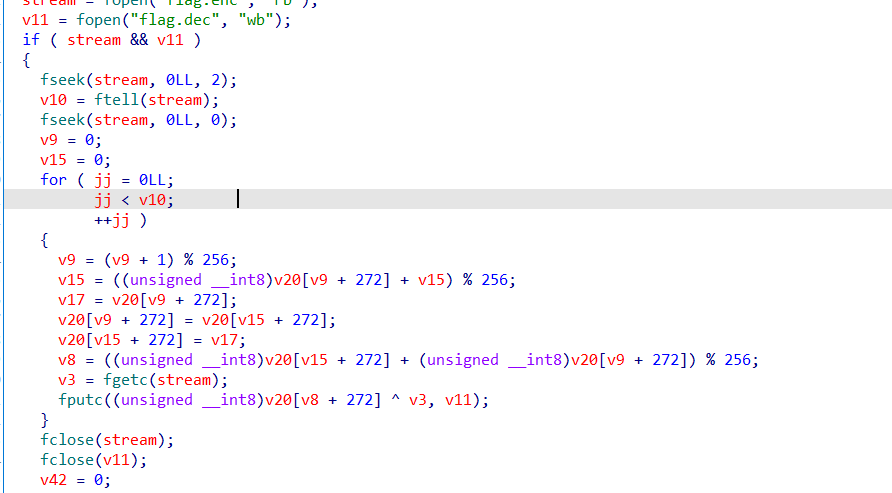
所以直接先解密的得到AES加密后的数据,然后解AES即可
#include<cstdio>
using namespace std;
unsigned char cmp_data[] =
{
0xD0, 0xA1, 0x81, 0xBC, 0x7C, 0x9B, 0x02, 0xE4, 0x2F, 0x33,
0x36, 0xE8, 0xBB, 0x12, 0x92, 0xF4, 0x12, 0xB2, 0xB1, 0x73,
0xF3, 0xDB, 0xF8, 0xC3, 0xFC, 0xDF, 0xD4, 0x50, 0xDC, 0x8C,
0x5B, 0xE9, 0x00
};
unsigned int ror(unsigned int x,unsigned int n)
{
unsigned int t=n%32;
return ((x>>t)|(x<<(32-t)));
}
unsigned int shift(unsigned int x)
{
unsigned int t=0;
for(int i=0;i<32;i++)
t^=(x>>i)&1;
return ((x<<1)|t);
}
unsigned int keys[]={0x0DC050901,0x2EB1699F,0x0B95BA4FD,0x920D9F20,0x7036ABC3,0x5E49A50A,0xADD61640,0x6C50DFFF};
unsigned int key1s[256],key2s[256];
void encode(unsigned int *plain1,unsigned int *plain2,unsigned int key1,unsigned int key2)
{
//printf("%X %X %X %X\n",*plain1,*plain2,key1,key2);
unsigned int p1=*plain1,p2=*plain2,k1=key1,k2=key2;
for(int i=0;i<256;i++)
{
k1=shift(k2);
k2=shift(k1);
key1s[i]=k1;
key2s[i]=k2;
}
for(int i=0;i<256;i++)
{
p1-=(ror(p2,i)^(key1s[i]<<18)|(key2s[i]>>7));
p2-=(ror(p1,i)^(key2s[i]<<18)|(key1s[i]>>7));
}
p2^=p1;
p1^=p2;
*plain1=p1,*plain2=p2;
}
void decode(unsigned int *plain1,unsigned int *plain2,unsigned int key1,unsigned int key2)
{
//printf("%X %X %X %X\n",*plain1,*plain2,key1,key2);
unsigned int p1=*plain1,p2=*plain2,k1=key1,k2=key2;
p1^=p2;
p2^=p1;
for(int i=0;i<256;i++)
{
k1=shift(k2);
k2=shift(k1);
key1s[i]=k1;
key2s[i]=k2;
}
for(int i=255;i>=0;i--)
{
p2+=(ror(p1,i)^(key2s[i]<<18)|(key1s[i]>>7));
p1+=(ror(p2,i)^(key1s[i]<<18)|(key2s[i]>>7));
}
*plain1=p1,*plain2=p2;
}
int main()
{
unsigned int *ptr=(unsigned int *)(cmp_data);
for(int i=0;i<8;i+=2)
{
decode(&(ptr[i]),&(ptr[i+1]),keys[i],keys[i+1]);
}
for(int i=0;i<32;i++)
printf("\\x%02X",cmp_data[i]);
return 0;
}
然后输入密码即可解出音频,倒放即可在末尾听到flag
MR_Register
用tmd-gcc编译完能让ida找不到main
通过字符串搜索找奇怪数据的引用能找到main
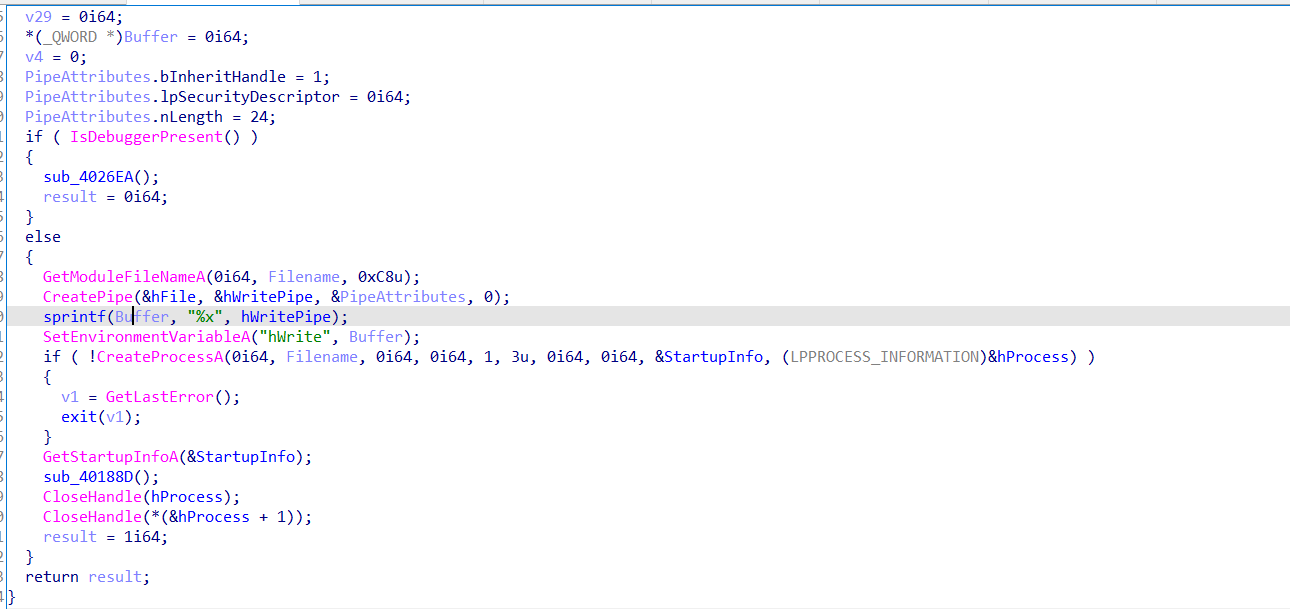
这里实现的是一个双进程,一个进程负责调试新生成的进程,导致正真逻辑所在进程不能再被另一个调试器附加,是一个反调试技巧,如果不被主进程调试则可能会使得程序无法继续执行,这里IsDebuggerPresent判断目前进程是被调试进程或是调试主进程

先进入被调试进程执行的函数内部分析,能看到一些输出,最后进行验证,如果v19 == 1就是flag正确
之前干的事就是在windows 的tmp目录下生成签名文件,进行注册,注册结束后进行check返回到v19
这里加密逻辑主要就关注到sub_401CA7,是对注册者的输入进行一个加密

内部实际已被混淆
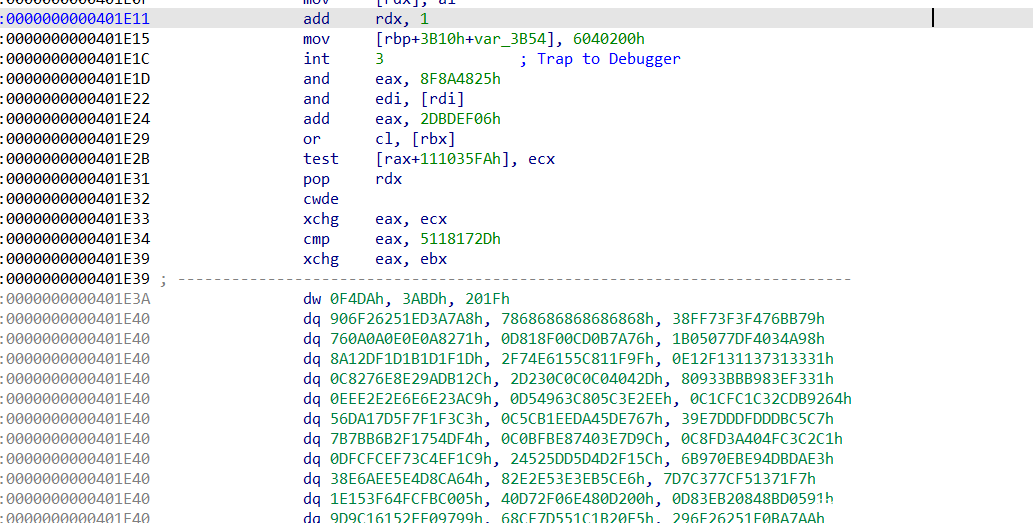
这里前面会有int 3触发断点,后面还有很多错误指令,实际是一个smc,那可以猜到就是先触发断点后被主进程调试器所捕获,然后进行解密,之后被调试进程继续运行
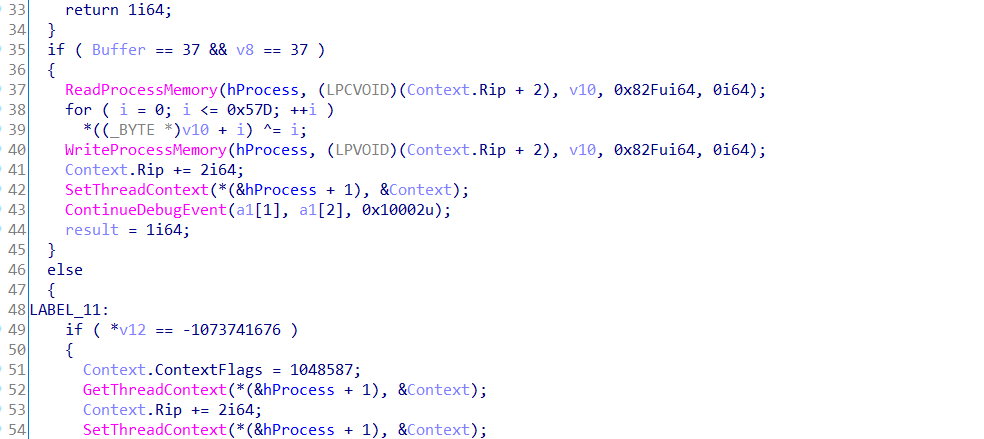
处理代码在这个位置,处理了0x57D个字节,然后异或解密,这里ida脚本patch一下
#include <idc.idc>
static main(){
auto addr = 0x401E1F;
auto i = 0;
for(i=0;i<0x57E;i++){
PatchByte(addr + i,Byte(addr + i) ^i);
}
}
之后讲标准连同断点一齐patch
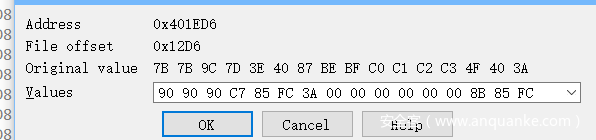
这里又遇到混淆,查找处理
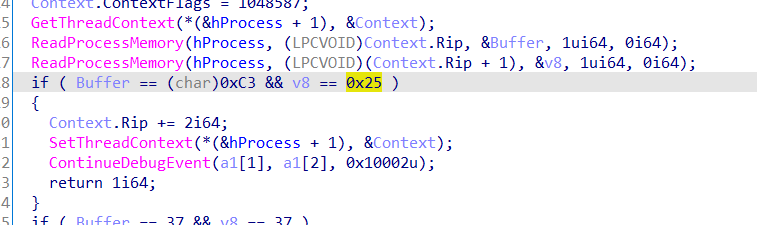
直接跳到两个字节之后,patch混淆的三个字节
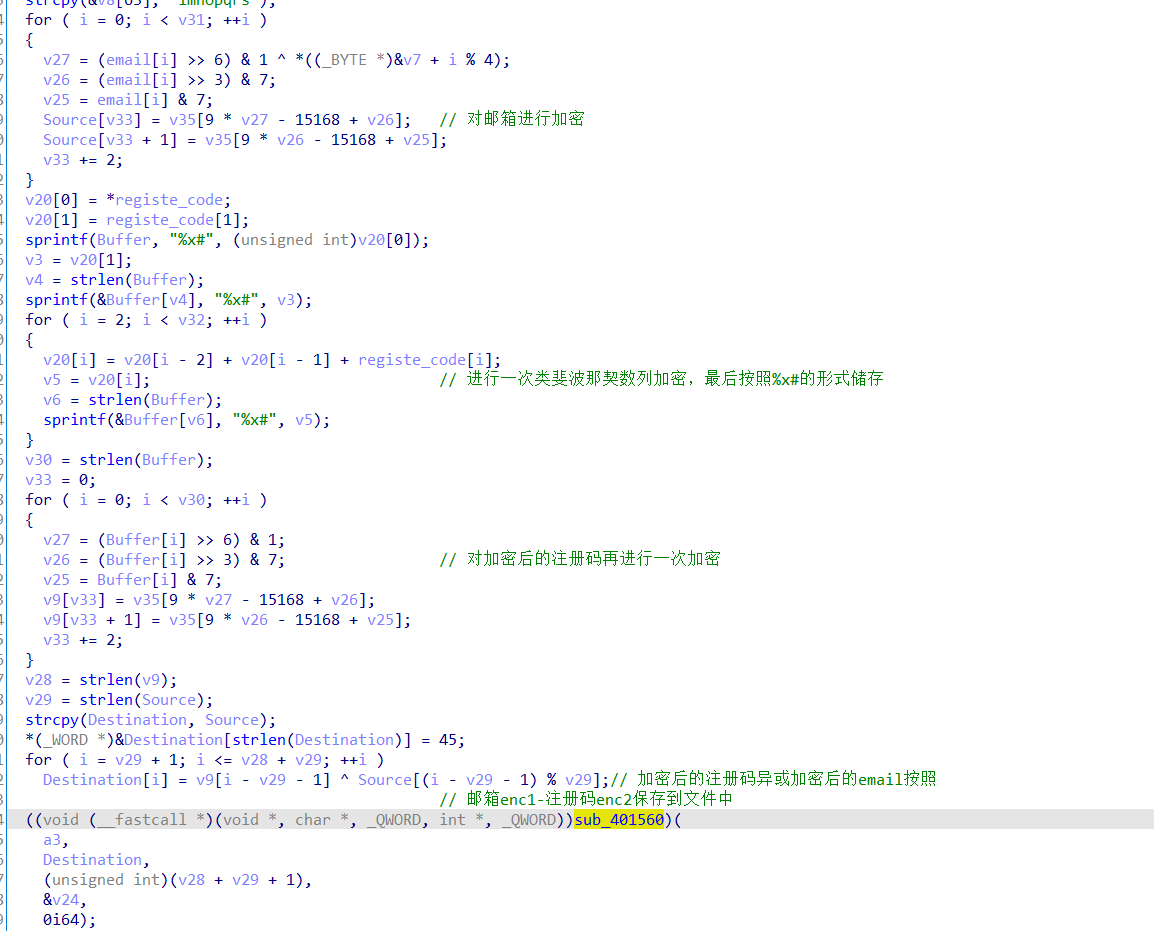
加密操作不复杂,查看验证函数

很简单,就是把邮箱密文和注册码密文按照-的分割来分别读取出来,最后把注册码最后一次与邮箱密文的异或加密给异或回去,经过这个解密操作后进行比较
但是这还没完,因为这个验证数组是被修过的,在主进程进行调试的某一时刻会重新修改此处内存,这一部分的实现主要是通过管道通信和环境变量的设置来完成的

主函数的主进程先是创建一个管道,然后把写句柄按照环境变量设置的方法传递到子进程,
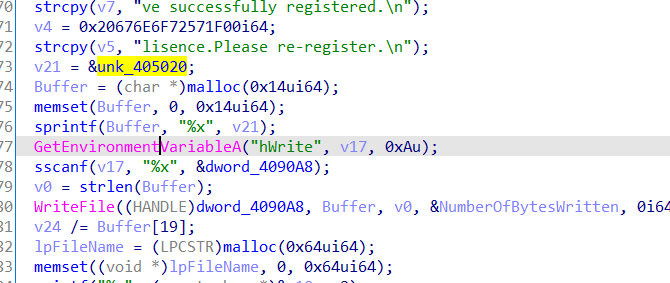
子进程在这里活得自己进程check数组的储存位置后利用v24/=Buffer[19]触发除零异常,在这之前讲内存地址用writefile写到管道中,子进程捕获异常后获取地址,修改内存位置的值,处理异常,子程序继续执行,但是check数组已被改变。
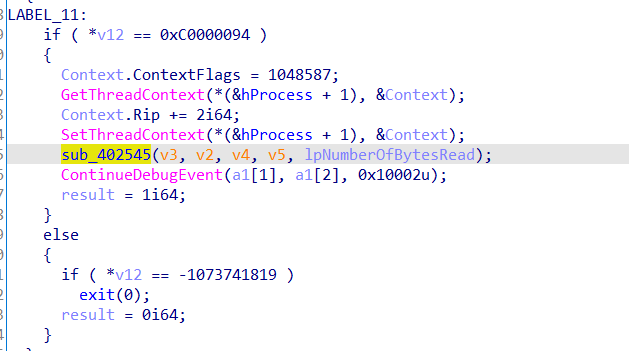
处理除零异常,此处sub_402545进行修改内存,进行了加花,patch即可,改call+ret+popq为jmp即可

看到对内存进行了一次异或操作
现在分析完后就可以写脚本
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void map(char key,int *x,int *y){
int i = 0,j = 0;
char table[9][9]={'\0'};
strcpy(table[0],"ABCDEFGH");
strcpy(table[1],"12345678");
strcpy(table[2],"0IJKLMNO");
strcpy(table[3],"+OPQRStu");
strcpy(table[4],"\\vwxyzTU");
strcpy(table[5],"abcdefgh");
strcpy(table[6],"VWXYZijk");
strcpy(table[7],"lmnopqrs");
for(i=0;i<8;i++){
for(j=0;j<8;j++){
if(table[i][j]==key){
*x = i;
*y = j;
return ;
}
}
}
}
int main()
{
int x,y,z;
int count = 0;
int i = 0,j = 0,k = 0;
char tmp[10]={'\0'};
int result[100]={0};
char plain[376]={'\0'};
int flag[376]={29,110,78,63,57,58,40,41,23,20,55,70,67,48,17,18,45,46,2,12,48,49,50,62,37,38,5,118,94,45,15,12,29,30,63,76,102,
21,56,59,21,22,6,117,111,28,3,0,13,124,127,3,16,108,122,11,5,6,42,43,33,82,125,14,80,83,127,124,91,90,86,88,108,16,6,119,113,114,
80,81,125,14,17,98,120,123,107,104,118,120,126,112,113,112,67,64,93,81,70,58,5,121,66,76,121,122,87,38,35,95,74,68,109,108,108,111,
73,74,102,103,84,90,94,80,99,98,82,81,189,190,157,156,169,168,151,153,173,209,198,183,177,178,144,227,220,160,183,185,139,138,187,184,
165,166,183,182,130,241,221,174,190,176,134,138,153,232,229,150,184,185,180,199,225,146,128,131,141,142,162,163,165,164,171,216,247,132,
148,231,241,128,131,128,208,163,129,242,233,232,217,216,230,231,213,214,241,242,209,162,147,146,144,227,196,197,201,200,199,196,231,228,
193,192,240,241,240,241,252,143,166,213,248,251,213,214,199,180,141,140,163,208,222,223,236,237,233,234,203,186,186,201,231,148,176,204,
219,213,46,47,44,47,57,58,22,23,23,22,23,25,41,85,65,64,82,46,55,59,41,42,6,117,84,40,63,49,48,62,58,52,13,126,110,31,25,26,57,74,73,72,
101,22,60,61,2,12,21,105,126,15,9,10,43,88,116,7,22,24,25,23,47,46,109,30,0,113,121,122,106,25,4,119,100,23,15,115,106,100,77,76,66,65,105,
24,27,26,27,26,22,101,66,76,122,6,45,44,46,95,89,90,118,119,117,123,78,64,115,0,33,82,96,110,86,42,54,71,75,120};
for(i=374;i>=0;i--){
flag[i] = flag[i] ^ i ^ flag[i+1];
}
for(i=0;i<376;i+=2){
map(flag[i],&x,&y);
map(flag[i+1],&y,&z);
plain[j++] = ((x << 6)|(y << 3)|(z));
}
j = 0;
for(i=0;i<strlen(plain);i++){
while(plain[i+j]!='#'&&plain[i+j]!='\0'){
j++;
}
strncpy(tmp,plain+i,j);
result[k++] = strtoul(tmp,0,16);
count++;
i = i+j;
j = 0;
}
for(i = count-1;i>=2;i--){
result[i] = result[i] - result[i-1] - result[i-2];
}
for(i=0;i<count;i++)
printf("%c",result[i]);
return 0;
}
这里全程静态,对照主进程干的事就能大致还原子进程干的事。
动调也很方便,那就让ida直接调试子进程,不给主进程,对照着主进程调试器干的事,你也干同样的事,也能很好的分析。
MR_CheckIN
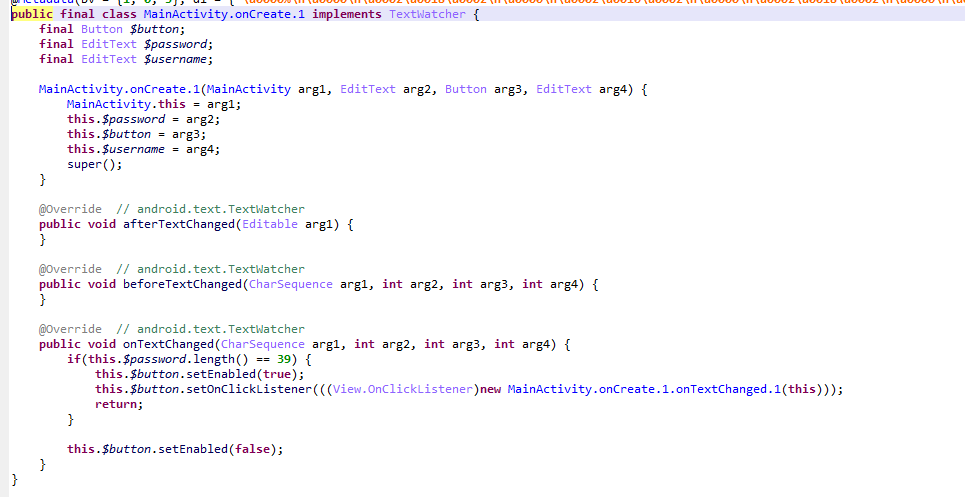
这里干了件事,密码长度为39时才开启登录button

这里就是点击的监听,首先登录用户名已经限定为MRCTF
密码已知39位,先判断格式,再进行一次[6,13)位的md5校验,查出是Andr01d
然后

此处将strings类型的[13,39)位传入check进行判断,返回值为1则正确
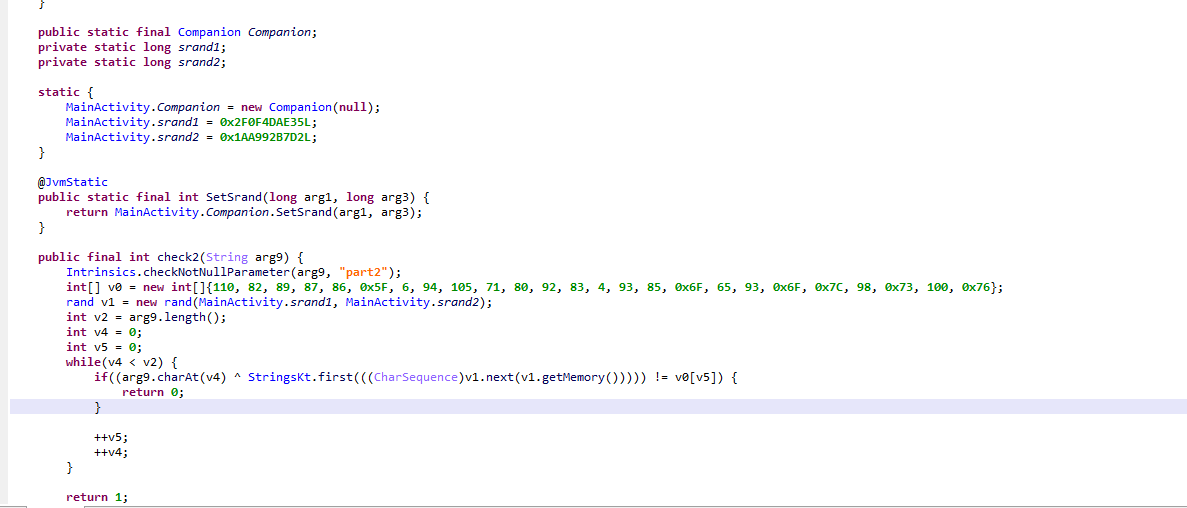
现在很清晰了,就是传入的字符串逐个与一个生成的数组作异或后进行比较,这里指向了rand,并且传入了两个srand值,猜测就是进行随机数种子初始化
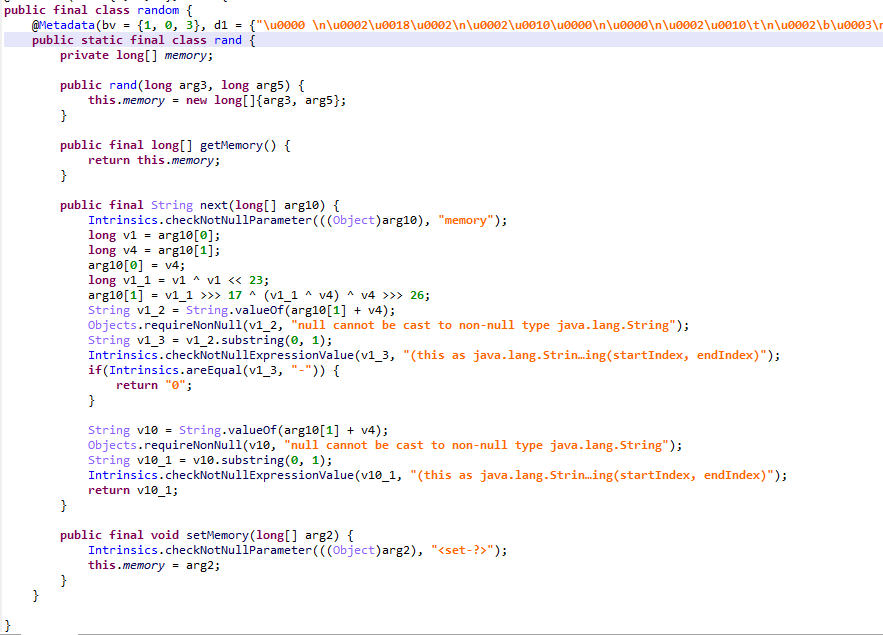
这里其实是用到了 XorShift128Plus 随机数生成算法,进行了简单修改,这种算法用于js的Math.random(),不一样的就是此处的种子不是随机的,由于之前传入了种子,所以生成的序列是固定不变的,那么直接得到这个序列就可以得到flag
然而并不是这么简单,我在java层调用了so函数,使得种子srand1和srand2发生了改变,所以直接得不到真正的随机序列

调用位置就在这里,可以看到是jni.test()
随便提取一个架构的so进行分析,按理平时一般会搜索test就能找到函数,我在这里做一个混淆替换
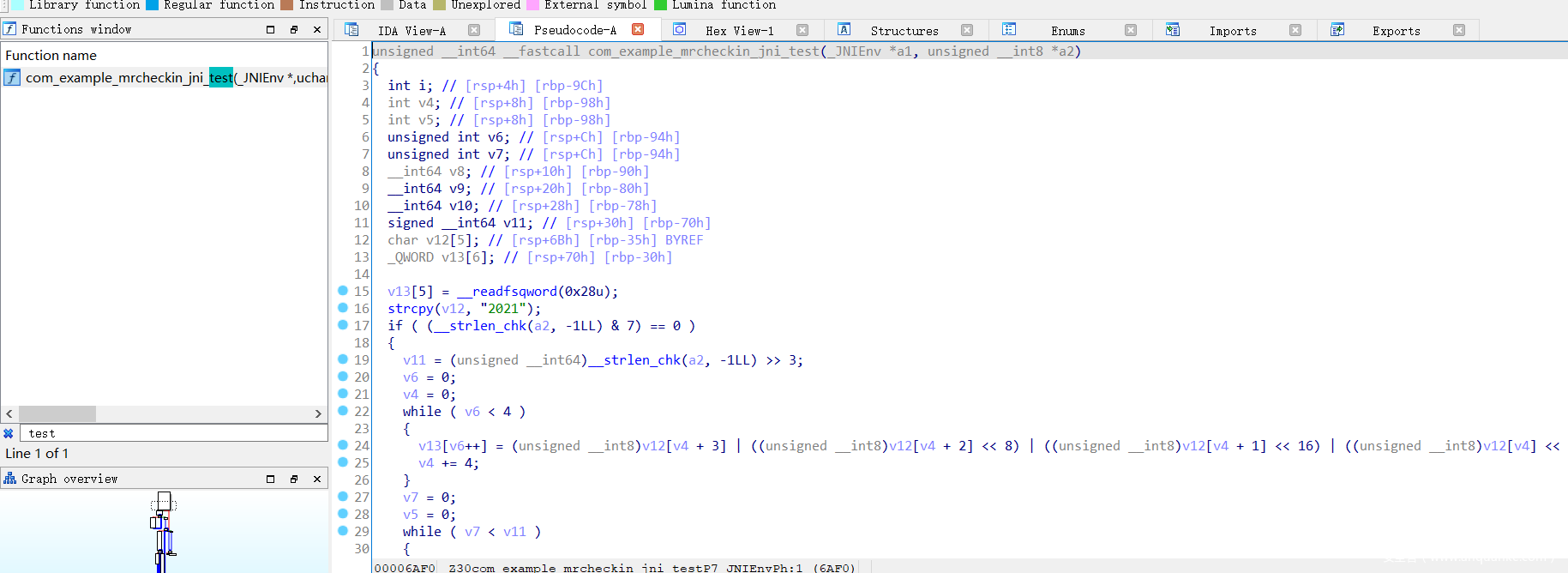

乍一看是一个tea,但是这是假的逻辑,完全不执行,真正的逻辑已经被注册到一另一个名称的函数中
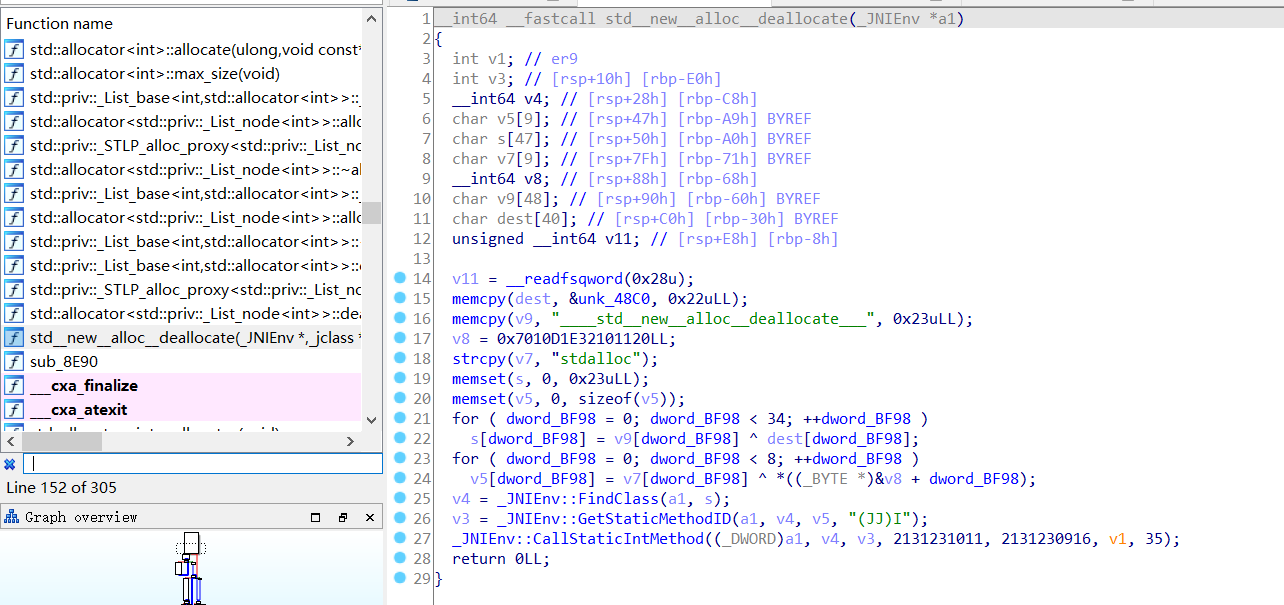
再次进行了字符串隐藏,主逻辑是在so层用JNI提供的接口调用SetSrand,重置随机数种子,在这里设置为两个长整型2131231011和2131230916
进行解密
#include <stdio.h>
long long int x=0x7F080123,y=0x7F0800C4;
long long int MyRand(long long x,long long y);
int main()
{
int i=0;
long long res;
char find[100]={'\0'};
unsigned char random[20]={'\0'};
int flag[]={110,82,89,87,86,95,6,94,105,71,80,92,83,4,93,85,111,65,93,111,124,98,115,100,118};
for(i=0;i<25;i++){
res = MyRand(x,y);
if(res<0) res = 0;
sprintf(find,"%lld",res);
random[i] = find[0];
printf("%c",flag[i]^random[i]);
}
return 0;
}
long long int MyRand(long long tmp0,long long tmp1){
long long int result;
tmp1 = x;
tmp0 = y;
x = tmp0;
tmp1 = (tmp1 << 23)^tmp1;
y = tmp1^tmp0^((tmp1 >> 17)&0x00007fffffffffff)^((tmp0>>26)&0x0000003fffffffff);
result = y + tmp0;
return result;
}
_check1n_welc0me_to_MRCTF,拼接即可
当然这题也可以直接jeb附加调试得到随机数序列,这种方案则直接绕开了所有的坑,更简单。
欢迎各位师傅在评论区提出自己的观点和看法。