
前言
后门攻击是AI安全领域目前非常火热的研究方向,其涉及的攻击面很广,在外包阶段,攻击者可以控制模型训练过程植入后门,在协作学习阶段,攻击者可以控制部分参与方提交恶意数据实现攻击,甚至在模型训练完成后,对于训练好的模型也能植入后门模块,或者在将其部署于平台后也可以进行攻击,比如通过hook技术、row hammer技术等。
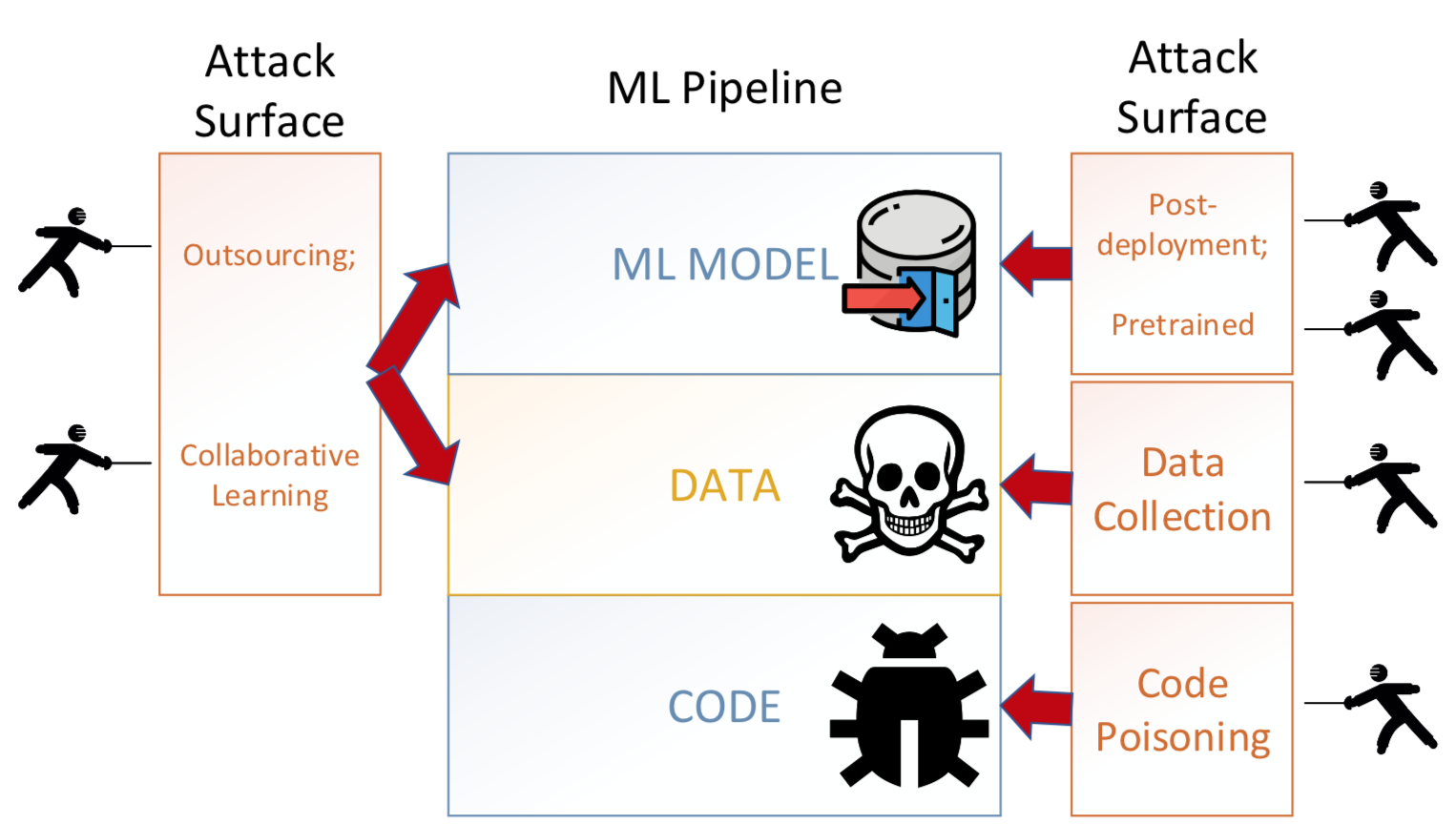
随着攻击的研究逐渐深入,相关的防御方案也被提了出来,对于攻击者而言,接下来再要设计攻击方案,必须要考虑是否能够规避已知的防御方案,而对于防御者而言,需要考虑已有防御方案的缺陷,以及如何改正,才能进一步提高检测效率,不论是从哪方面来看,都有必要对目前典型的防御方案做一个全面的了解。
本文就会从样本和模型两个角度,介绍目前典型的方案,这里说的“典型”的标准是指引用量高,常被研究人员哪来作为对比使用,以及发在顶会订刊上的工作,限于篇幅,不可能面面俱到,但是从这些典型方案中基本能了解防御者的防御假设、设计思想等,对我们之后的工作具有参考价值。
防御
对于一个完整的AI系统而言,最重要的两个组件就是数据和模型,做攻击是从这两门着手,所以我们在分析防御方案时,也分别从数据(样本)和模型两个角度进行研究。
样本角度
从样本的角度来分析,可以分成两种,一种方案仅仅检测是否为毒化样本,另一种方案则是会对输入样本进行转换,使样本中可能存在的触发器失效,以实现防御。
[1]认为对抗样本和毒化样本之间存在一些相似之处,都需要通过小扰动强化错误的预测输出,如下所示
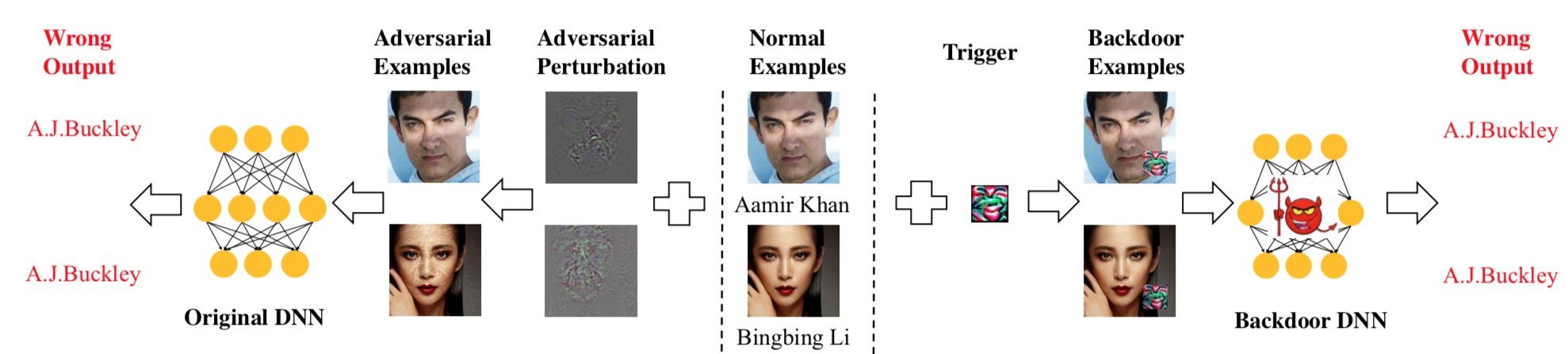
左边是对抗样本,加上的扰动为对抗噪声;右边为毒化样本,加上的扰动为触发器。它们在推理过程中会表现异常,所以可以用类似的方法检测,所以研究人员将检测对抗样本的方法应用于检测毒化样本,根据毒化样本的模型敏感性、特征空间和激活空间中的行为等,确定了四种检测毒化样本的方法,对应的示意图分别如下
第一种是基于模型突变的:
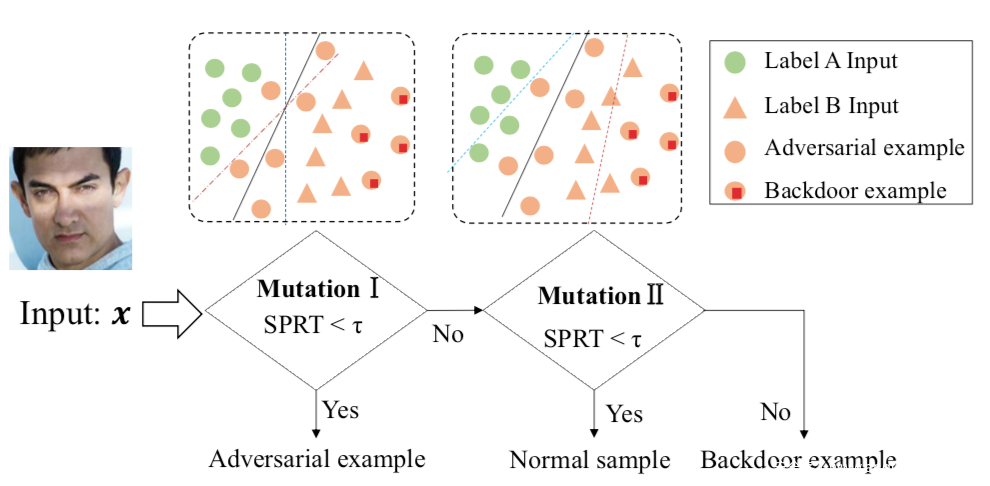
首先设置一个较小的突变率检测模型是否为对抗样本,如果不是,则以较大的突变率继续,检测是否为毒化样本。
第二种,基于激活空间,其依据是毒化样本和良性样本在不同网络层的激活空间的行为是不同的。
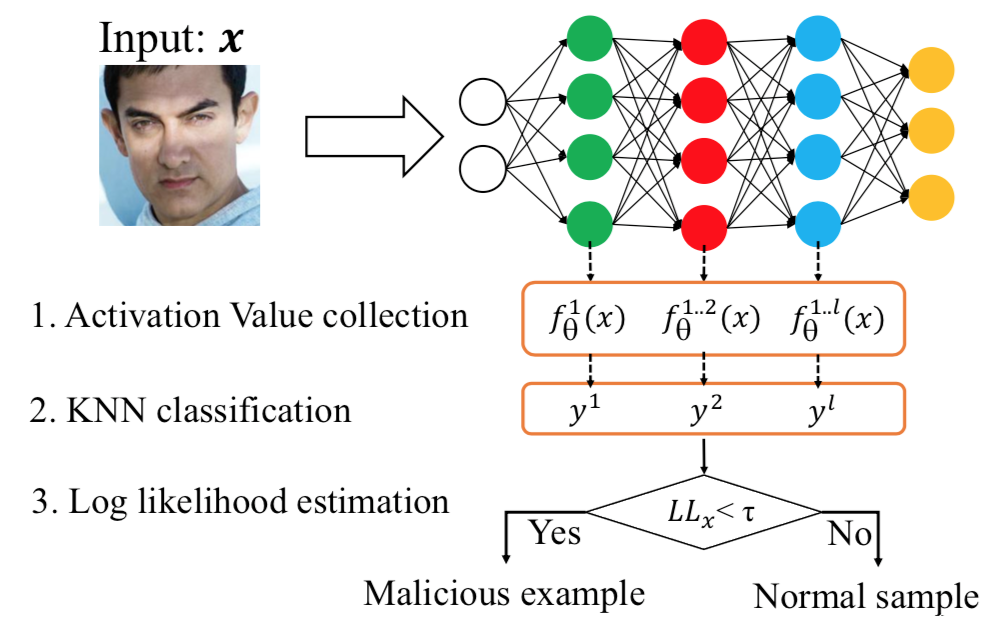
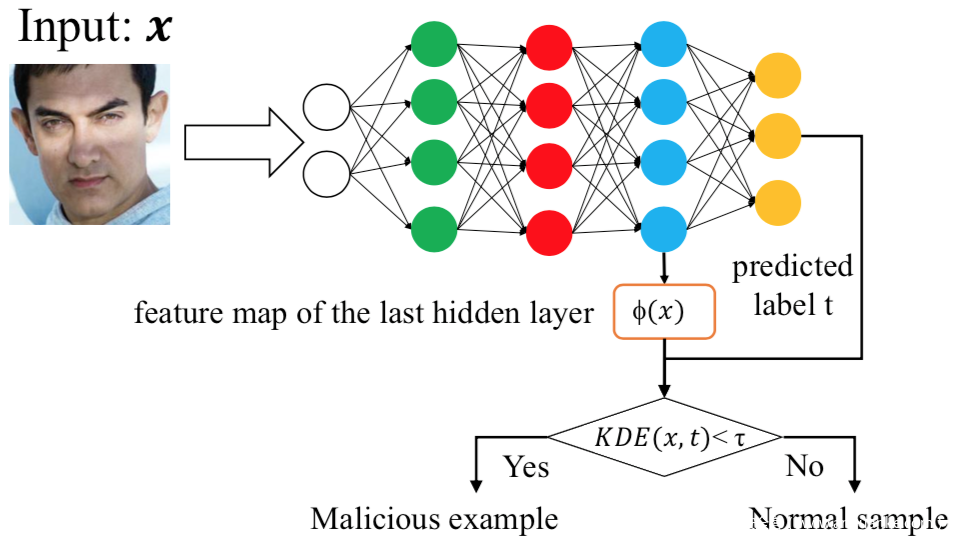
第三种,基于核密度估计,该方法专注于特征空间的异常检测,在特征空间中,被错误分类到目标类别的毒化样本和属于目标类别的良性样本会具有不同的行为。
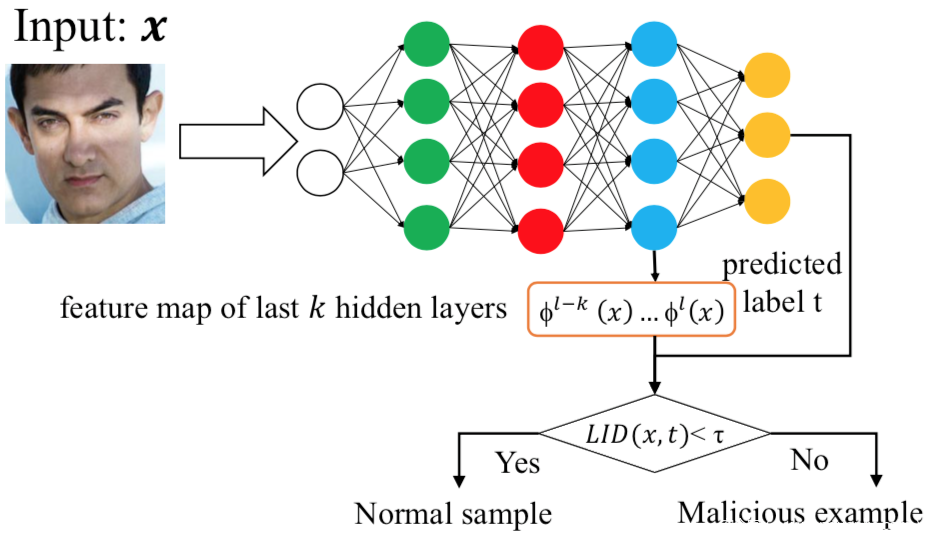
第四种,基于局部本征维(LID),其利用LID的估计来量化目标样本与正常样本之间的距离,因为毒化样本的LID值明显高于正常数据,所以可以用于检测。
[2]利用字典学习和稀疏逼近来描述良性样本的统计行为以及识别毒化样本。其框架组成如下所示
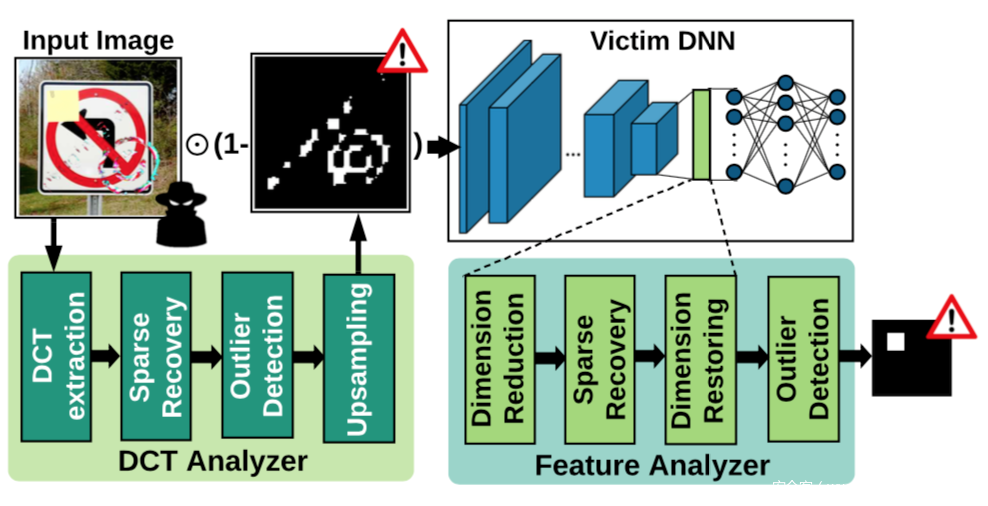
可以看到两个核心模块,分别是DCT分析器,以及特征分析器,对应来表征模型的输入空间和潜在表示,通过结合两个分析器的决策,实现毒化样本的识别。
其中DCT分析器是作为图像预处理的一个步骤,它会在频率域中检查所有输入的样本,以搜索良性样本中异常的可以频率成分,为此,首先将输入图像变换到频域,然后对提取的频率分量进行稀疏恢复,并使用稀疏逼近重建信号,接着检测异常重构错误,并生成一个具有非零值的二进制掩码,该值表示潜在的触发器携带区域,此外为了确保尺寸兼容,DCT分析器中还有一个最近邻上采样组件。
而特征分析器用于研究潜在特征中的模式,以发现异常,将其放置在模型的倒数第二层,以利用模型从输入图像中提取的所有视觉信息进行分类决策,其中的稀疏恢复模块的作用是1.对输入特征去噪和2.对重构错误进行异常检测以区分毒化样本。而降维模块是为了自适应调整特征大小,同时最大限度保留信号的信息内容。
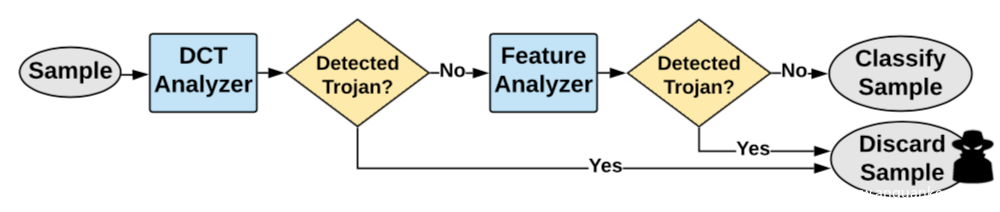
其工作流程如下
[3]应用差分隐私提升异常值检测(outlier detection)和奇异值检测(novelty detection)的效果,并应用于检测毒化样本,其理论分析比较繁琐,感兴趣的可以阅读原论文,我们这里就看实验结果
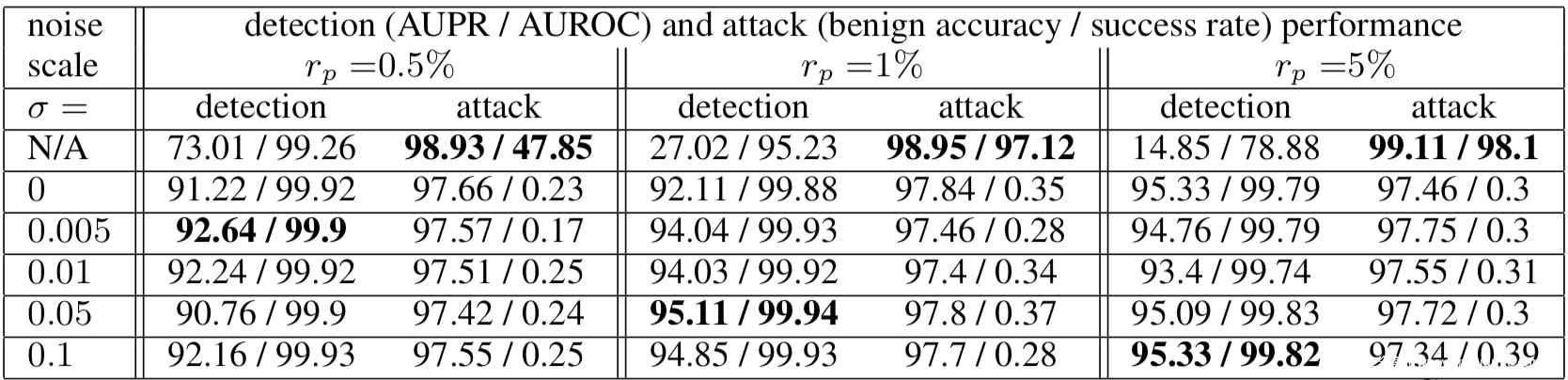
σ =N/A表示训练的分类模型没有应用差分隐私。在干净的数据上,良性的准确性仍然很高。当投毒率为0.5%时,后门成功率只有一半左右,当投毒率为1%时,后门成功率为97.12%。从表2可以看出,差分隐私有效地限制了后门攻击的成功率,所有情况下的成功率都低于0.5%,而良性精度的准确率降低很小,但是可以显著提高检测性能。
[4]通过激活聚类的方法检测毒化样本,其通过分析训练数据导致的神经网络激活情况来确定训练数据是否被毒化,以及哪些样本是毒化样本。该方案背后的关键思想是,当毒化样本和正常样本都被分到目标类别时,模型做出这种决策的原因是不同的,对于正常样本而言,会根据学习到的输入特征并进行分类,而对于毒化样本人眼,会识别和原类别、触发器关联的特征,并进行分类。这种机制上的差异会在网络的激活中体现出来。如下图所示,显示的最后一个隐层的激活,将良性样本和毒化样本投影到他们的前三个主成分上。
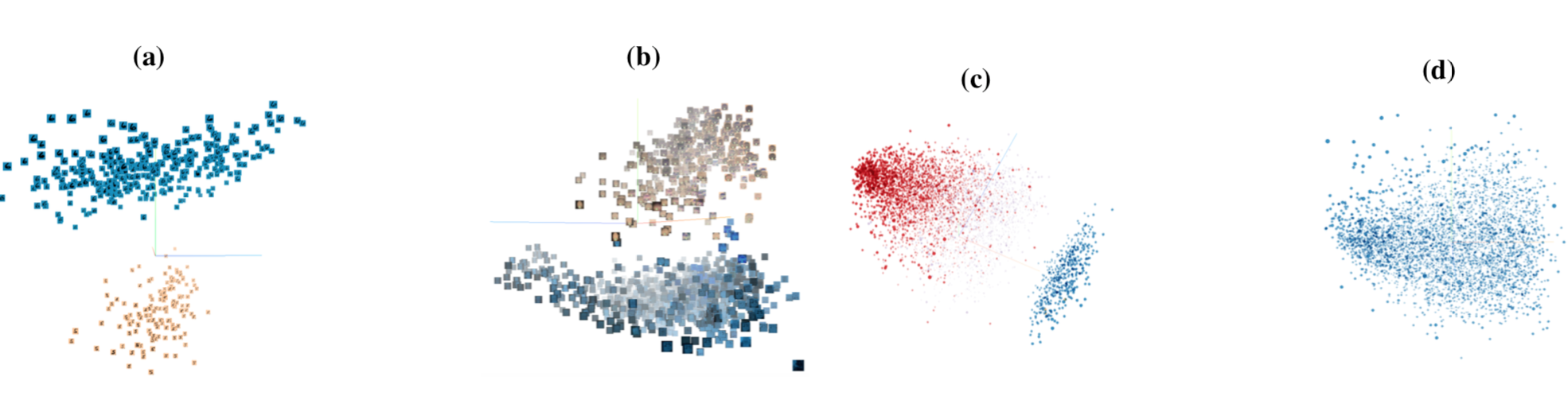
图a显示了MNIST毒化数据集中类6的数据的激活情况,图b是LISA毒化数据集中限速类的激活情况,图c是Rotten Tomatoes movie reviews数据集的负面类的激活情况,可以发现,毒化数据和良性数据会被激活分成两个不同的簇,相比之下,图d是良性数据集,其并没有被分成不同的簇。
[5]发现后门攻击会在神经网络学习的特征表示的协方差谱中留下可检测的痕迹,研究人员称之为光谱特征,并使用该特征对毒化样本进行检测并直接丢弃他们,,然后使用剩下的良性样本对模型进行重训练。该过程如下所示

首先使用数据集训练神经网络,然后对于每个类,都提取每个输入学到的表示,然后使用SVD,也就是奇异值分解算法对这些表示的协方差矩阵进行运算,并使用他们来计算每个样本的离群值分数,删除有高分的输入样本并进行重训练。
[6]故意对输入样本进行扰动,比如叠加各种图像模式,并观察模型会对扰动后的样本如何分类,如果分类的结果的熵值较低,则不符合良性样本低熵的特性。其示意图如下
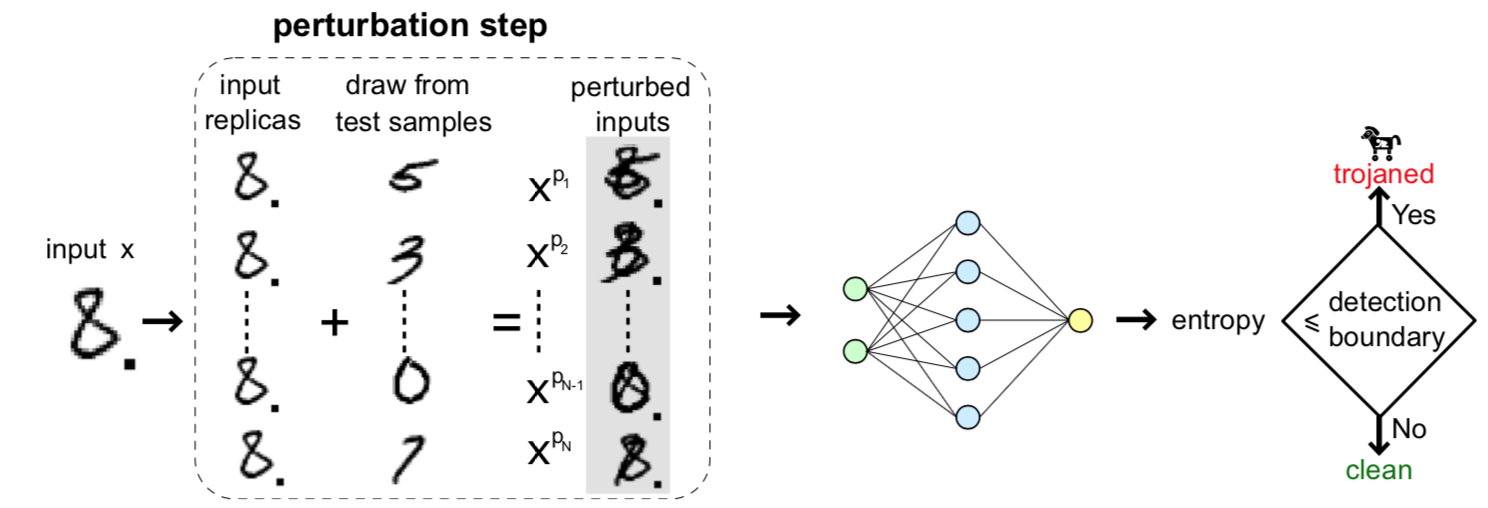
将输入样本x复制N份,对每一份复制后的样本用不同的模式进行扰动,然后根据扰动后的样本被模型分类的结果,分析结果的熵值来判断输入样本是否为毒化样本,较低熵值的x则为毒化样本。因为对于毒化样本而言,不管输入图像受到怎样的强烈扰动,扰动得到的样本的预测往往是一致的,都会是目标类别。熵的计算表示如下
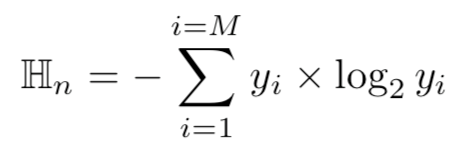
对于N份样本,总的熵计算如下
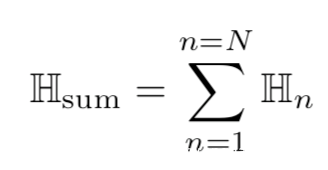
[7]会分析模型接收的输入样本,并定位触发器后实现修复。该方案的背后的直觉可以用下图来说明
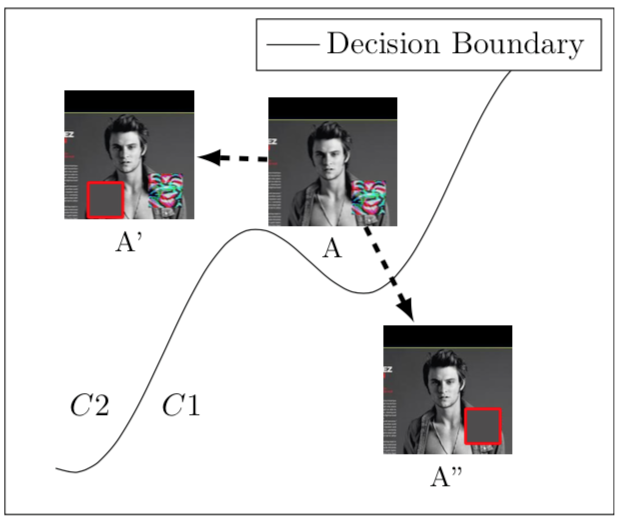
图像A的右下角存在触发器,尽管A的原样本属于C1,但是由于触发器的存在,此时会被分类为C2,而只要我们能够找到触发器的位置并覆盖它就可实现毒化样本的修复,这里的关键是如何定位触发器以及用什么进行覆盖,如果定位不好,就会像A’一样,修复是没有效果的,而至于用什么进行覆盖,最简单的办法就是使用整张图像的主色进行覆盖,图中A’’就是在定位触发器并用主色,即灰色进行覆盖,此时的图像就可以被正确分类为C1了。本文定位触发器的伪码表示如下

简单来说,将触发器阻断器放在图像的各个随机位置上,观察模型此时对图像的预测,如果与源图像不同,则说明该位置是触发器所在的区域。
应用该方案的效果是很明显的,下图是原图、毒化样本、以及应用该方案修复的样本的对比

我们以第二行为例,(e)所示的停车标志的毒化样本,而后门触发器是小的黄色正方形。图像的原样本如(d)所示。后门触发器,即(e)中的黄色方块,在(f)中被触发器阻挡器覆盖。值得注意的是,触发阻挡器的颜色对于抵抗后门触发的效果至关重要。例如,如果触发器阻挡器是黄色的,那么覆盖后门触发器不会改变对(d)中毒化图像的预测,从而使防御失败。所以作者使用后门图像的主色来构造触发阻挡器。这背后的直觉是,后门触发器的颜色不太可能与后门图像的主色调相同。因为通过使用图像的主色构造触发阻挡器,创建了一个与后门图像的干净版本(如(d))相似的固定图像(如(f))。
[8]是一个在模型运行期间进行防御的方案,能够对毒化样本进行转换使其不再具有触发效果。该方案的流程如下
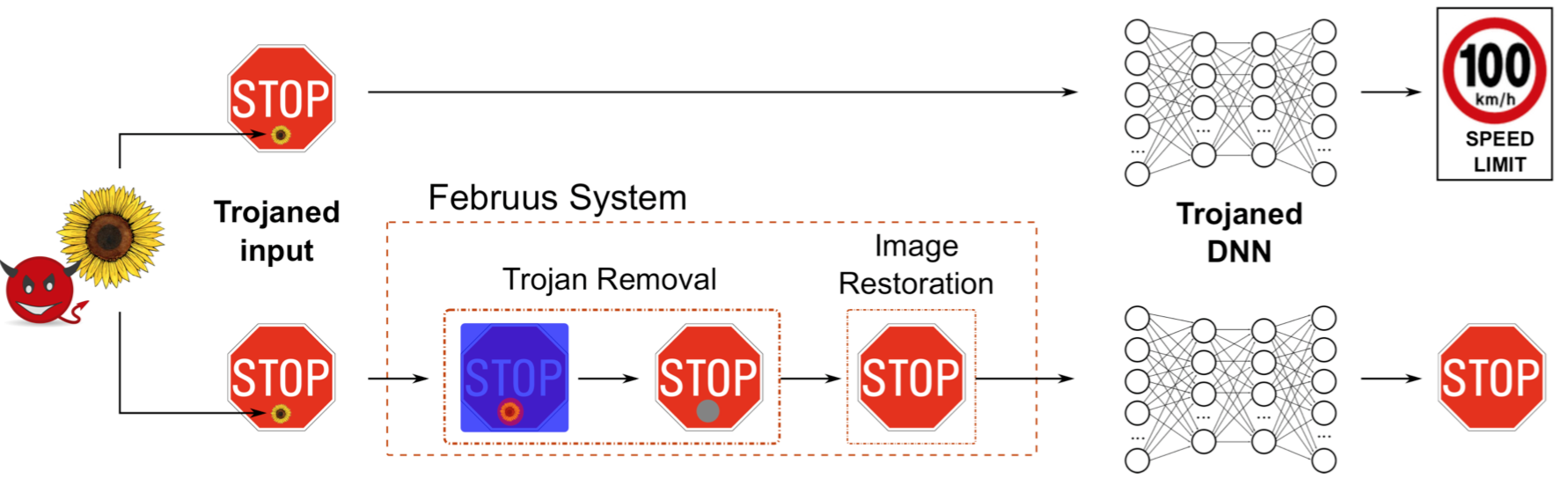
Februus系统会去除毒化样本中的触发器,并修复移除的区域,然后将修图后的图像作为样本输入模型中进行预测。这里涉及到两个问题,怎么确定要移除的区域以及怎么修复被移除的区域。
针对第一个问题,我们使用可视化工具GradCAM定位触发器所在位置,定位之后使用中和色框进行替换,如下所示,在使用GradCAM定位到人脸脖子出的触发器后,进行移除

接着是图像修复阶段,因为直接使用上图中最后的图像输入给模型时会导致模型的性能降低10%左右,所以需要高保真度地重建被移除的区域的信息,我们使用了一种基于GAN的方法,G根据输入图像描绘mask区域,并由D是被图像是真实的还是描绘的,该过程如下所示

该方案的效果还是不错的,下图分别是原图、移除图、修复图的对比

[9]从相对于损失函数的输入梯度中提取触发器信号,并基于输入梯度和触发器信号的相似性,将毒化样本和良性样本进行区分,并且进一步使用触发器信号检测目标类别和原类别,然后将触发器信号叠加于所有数据并将毒化样本的标签给为原类别,用这部分数据集对模型进行重训练以消除后门。研究人员观察到后门攻击的两个现象:1.毒化模型包含后门神经元,它们只有在触发器或者说触发器模式存在时才会被激活;2.这些神经元的权重比其他神经元的权重大得多。并且有以下命题:损失函数E相对于输入xi的梯度与激活神经元的权重线性相关,其计算公式如下
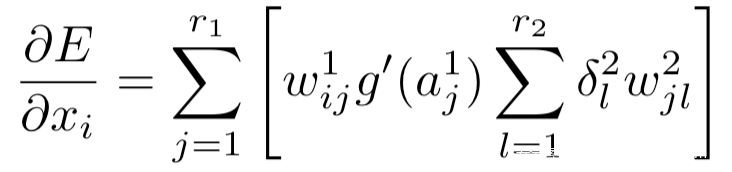
作为防御最关键的一步就是从噪声输入梯度z中提取触发器信号,z如下所示
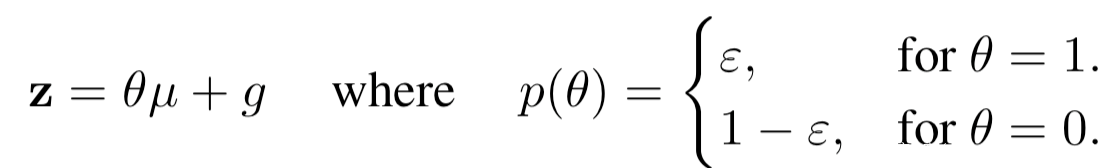
上式中的的u是z的二阶矩阵的特征向量,对应的是epislon以及||u||>0时的最大特征值。所以我们可以从被分为目标类的毒化样本、良性样本中提取出触发器信号u作为二阶矩阵的最大特征向量,而这一步可以通过对包含输入梯度z的矩进行奇异值分解得到
接着使用简单的高斯混合模型(GMM)聚类算法,根据输入梯度的第一个主成分值过滤毒化样本即可,该聚类的误差概率由下式给出
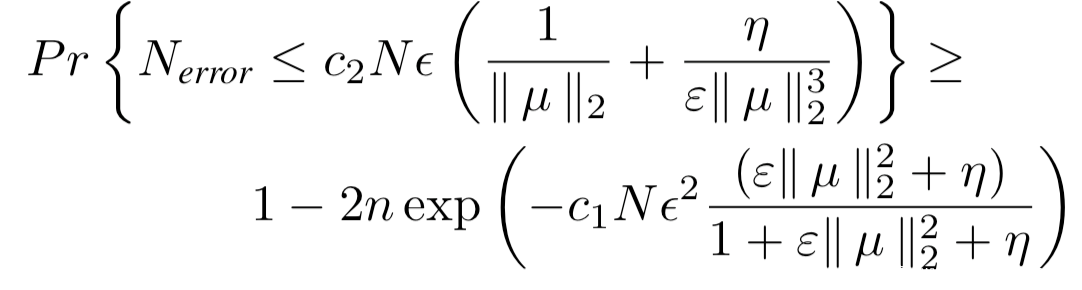
其中N是样本总数,Nerror是误分类的样本数量。接着构造数据集进行重训练即可。我们来看实验数据
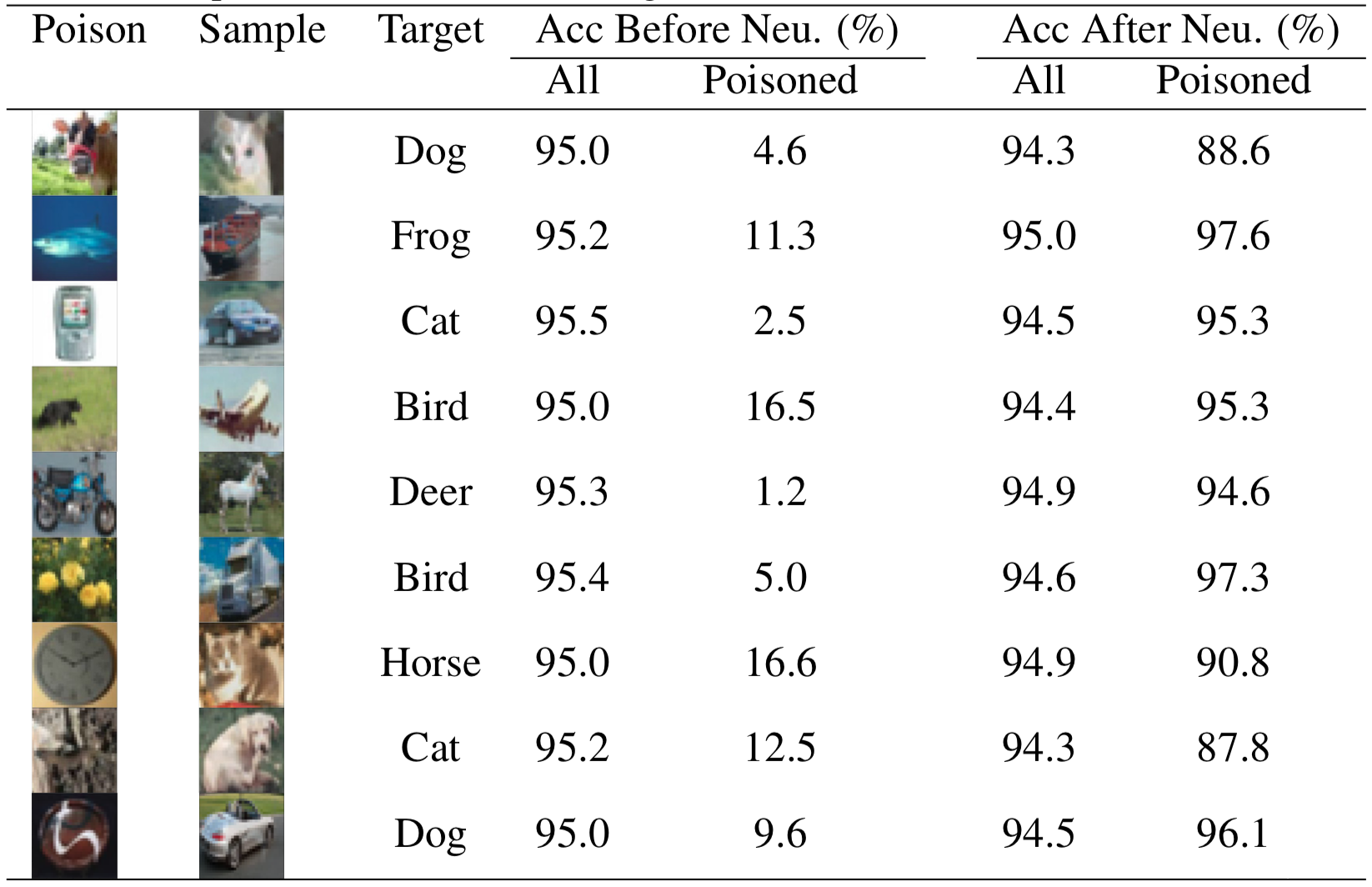
上表中的neu代表是对模型进行重训练以消除后门,从表中的数据可以看出,重训练后毒化样本的准确率均在90%左右,实现了极大的提升。
模型角度
从模型的角度来做防御,关键点就是找到毒化模型和良性模型之间的差异,比如模型内部神经元激活的差异、样本误分类所需的扰动的差异等。
[10]通过结合剪枝和微调对去除毒化模型中的后门。BadNets的研究表明,毒化样本输入模型时,会激活良性样本输入时处于休眠状态的神经元,攻击者是利用这些神经元被用于识别触发器并最终触发后门行为。下图是良性样本和毒化样本分别输入模型时,最后一层卷积层神经元的平均激活。从下图的结果可以看到,后门神经元的激活在b图中非常明显。
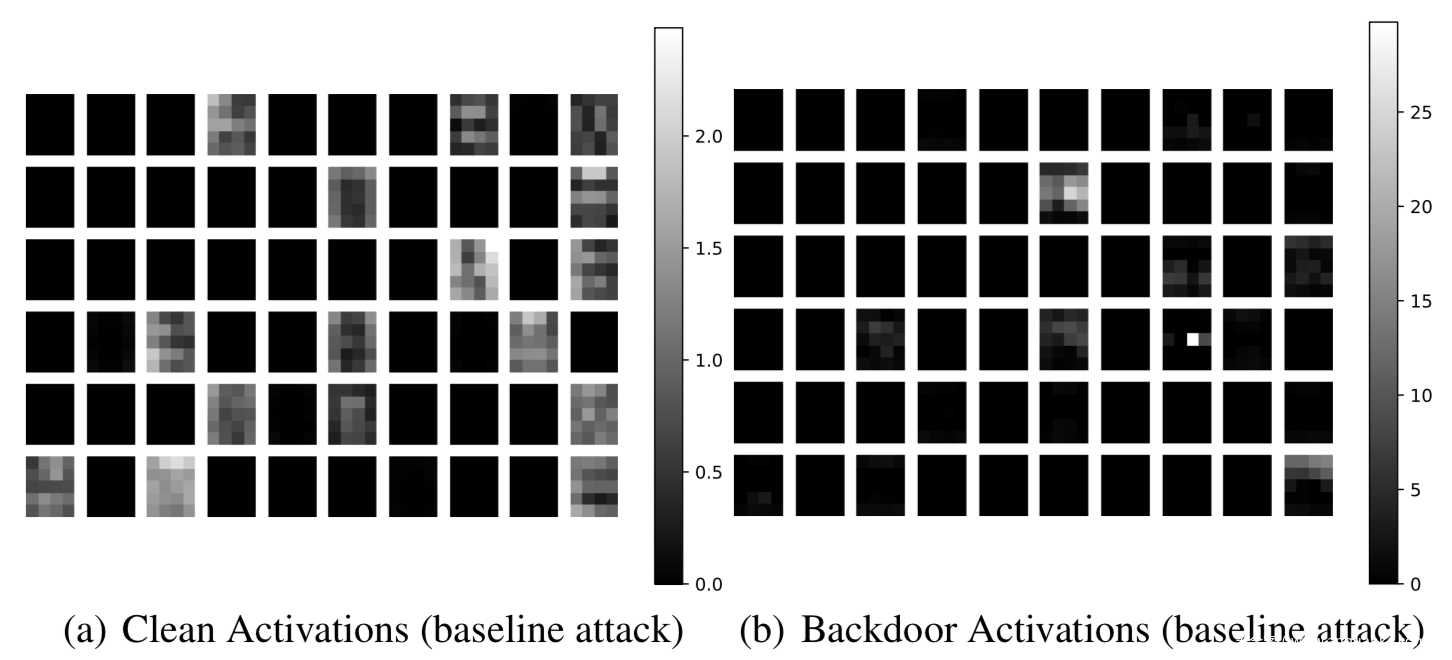
所以我们可以将这些神经元清除以实现防御,该方案称为pruning,即剪枝,该方案虽然有效,但是也容易被绕过。仅使用微调进行防御也是如此,所以作者提出的方案结合两类技术,首先对后门模型进行剪枝,然后对剪枝后的模型进行微调,其背后的思想是通过剪枝去除后门神经元,通过微调恢复剪枝带来的准确率的下降。
[11]提出了第一个鲁棒、可扩展的模型后门检测和缓解技术,可以检测后门并恢复触发器实现后门检测,并使用输入过滤、剪枝、unlearning等方法实现缓解。
在检测后门方面,该方案的关键思想可以用下图表示
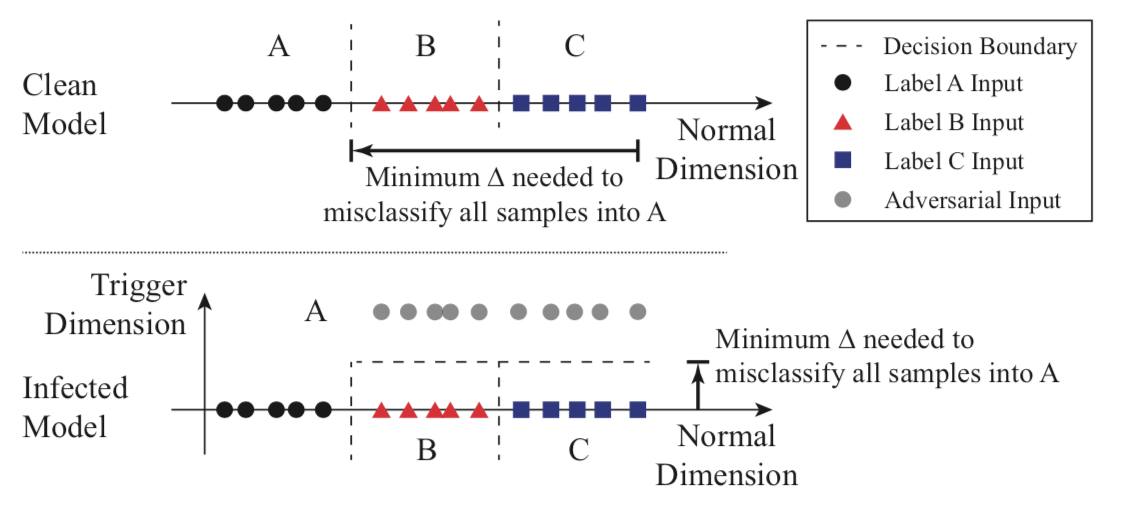
对于良性模型而言,需要更多的改动才能将B和C类的样本跨越决策边界移动到类A的区域中;而对于毒化模型而言,因为存在后门的影响,所以仅需更少的改动就可以将B和C类的样本误分类为A。所以只需要遍历所有的输出类别,找到是否输出为某个类别时需要明显较小的修改,就可以实现误分类。
在判断出模型存在后门后,我们可以逆向得到触发器,从下图可以看到,攻击者使用的触发器与逆向得到的触发器虽然在视觉上可能不太相似,但是在后门攻击使用的有效性上是一致的

利用触发器我们就可以检测出哪些神经元会被激活,所以就可以利用这一点检测并过滤所有会激活这些神经元的输入样本;此外通过从模型中去除与后门相关的神经元对模型进行修补以增强其鲁棒性。
[12]提出了第一个具有最小模型先验知识的黑盒木马检测方案,使用条件生成模型从查询模型中学习潜在触发器的概率分布,从而检测模型中是否存在后门。该方案背后的关键思想与[11]类似,如下所示
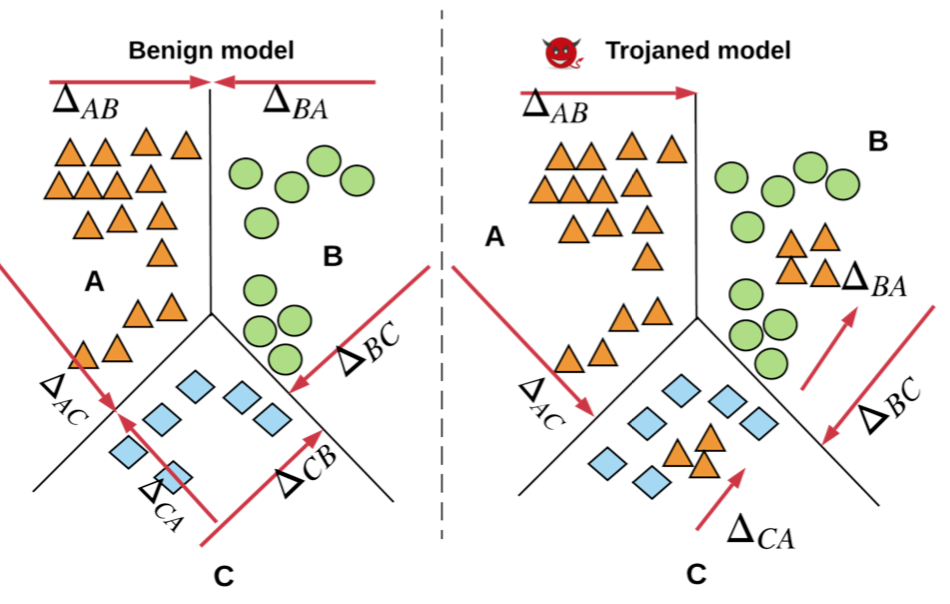
考虑有三个类别的分类问题,毒化样本生成的过程可以看做在原样本周围添加冗余,并将其标记为目标类别。设deltaAB是将A类数据移动到B类所需的扰动,图中其他的注记的含义以此类推,那么一个目标类别为A的毒化模型满足deltaA远小于deltaB和deltaC,但是对于良性模型而言,这三个值之间的差异较小。该方案的总体框架如下所示

首先使用模型逆向攻击生成包含所有类的替代训练集,然后训练cGAN生成触发器,并将查询模型作为鉴别器d
这里的关键是cGAN,其示意图如下
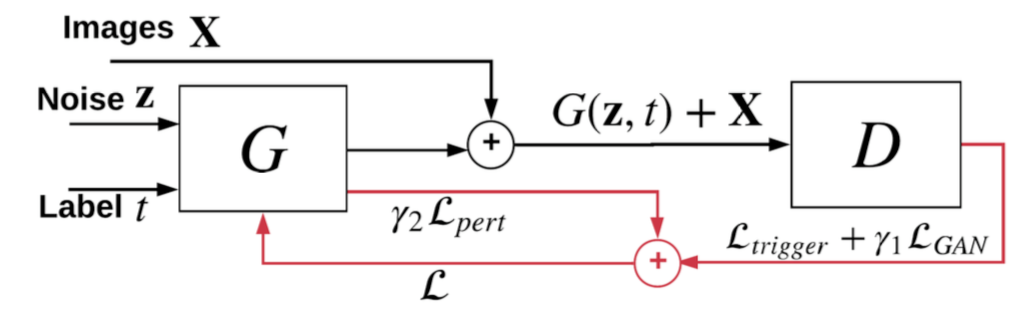
其中z是随机噪声,t是目标类别,G被训练用于学习触发器的分布,被查询的模型会将生成的触发器叠加于X上得到的样本预测为目标类别,最后使用触发器的扰动水平(变化幅度)作为异常检测的统计量,如果扰动水平异常的小,则该类别就是目标类别。
[13]将后门检测任务形式化为非凸优化问题,通过求解目标函数即可求解优化问题,不过它不是将后门检测直接建模为优化问题,而是在可解释技术下设计了一个新的目标函数,以更有效的方式检测后门的存在并恢复触发器。
给定一个毒化模型,检测触发器可以看做是在求解下面的优化问题
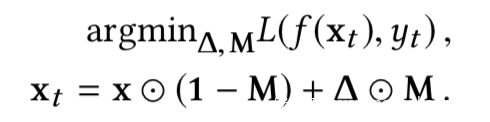
上式中M是mask,表示触发器的形状和位置;三角形是触发器pattern,表示触发器的颜色,将其进行操作就得到了触发器;x是矩阵形式的输入样本,xt是带有触发器的样本,即毒化样本,yt代表着目标类别。
如果模型是良性的,或者具有将xt误分类为yt的能力,在理想情况下,给定模型f和非目标类,我们不能通过上式解出mask和pattern;但是由于神经网络的非凸优化特性,我们总是可以求解的。对于良性模型而言,求解的结果是误报,而对于毒化模型而言,求解可以得到触发器。但是我们的目的是检测模型是否为毒化模型,如果是则恢复触发器,为此,需要解决误报的问题,本文就是通过设计的新的优化函数实现的,在新的函数中引入四个正则化项求解触发器,并利用这些正则化项设计新的度量从而确定模型是否存在后门。四个正则项分别为
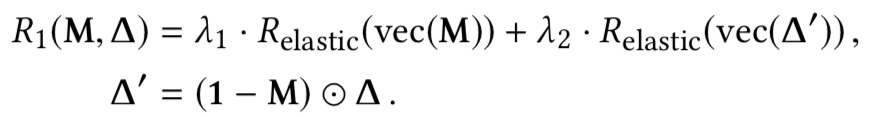
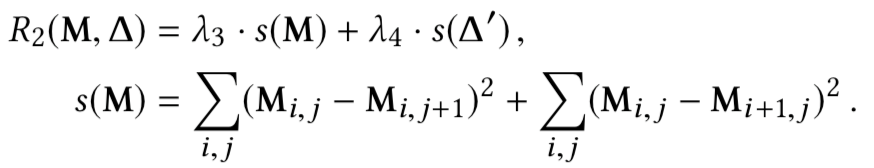
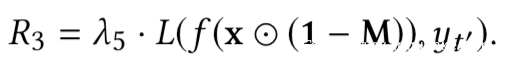
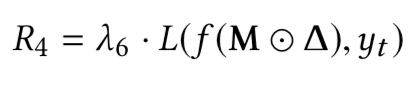
而根据正则项设计的新的度量为:
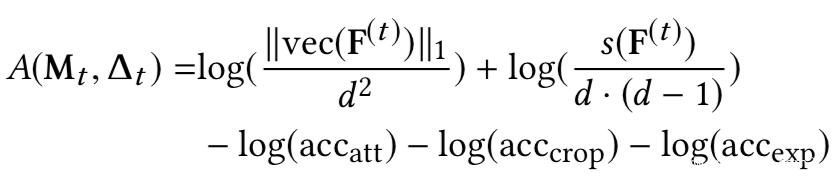
利用四个正则项构建的新的优化函数,以及新的度量指标进行实验并与Neural Cleanse进行对比
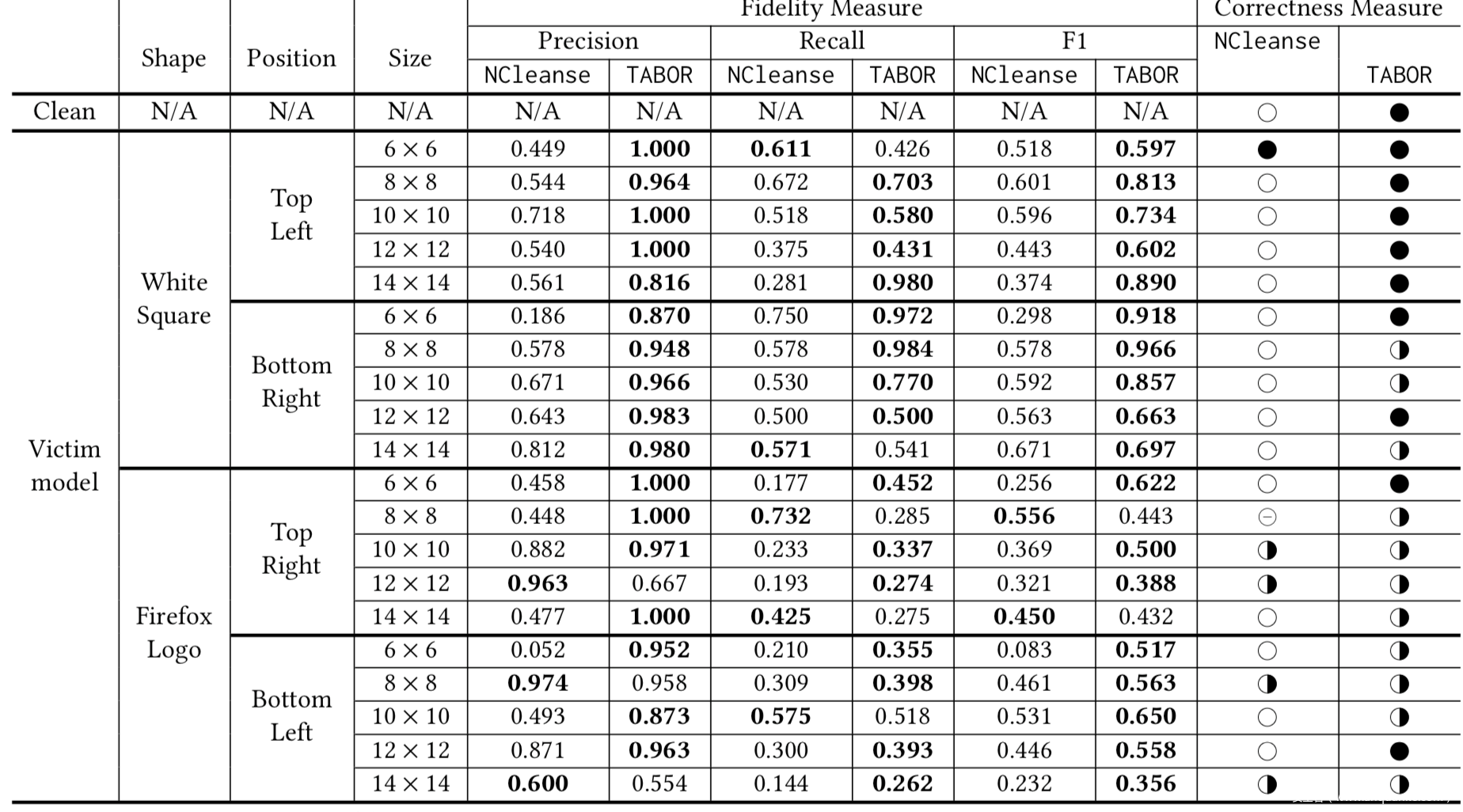
从实验结果看出,不论是在precision还是recall,F1上,该方案的效果大多数情况下都是更好的。
[14]使用输出解释技术提取模型的知识,本质上利用的是良性模型和毒化模型对良性样本的输出解释存在巨大差异。它利用生成输出层的解释热图,良性模型和毒化模型生成的热图会有不同的特征度量解释贡献,如稀疏性、平滑性、持久性等,其分别表示为:
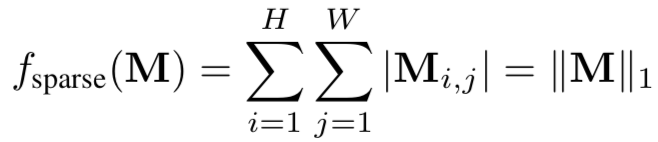
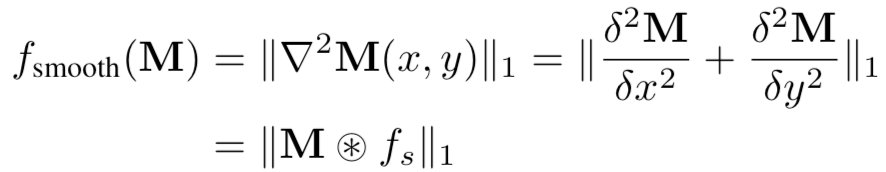
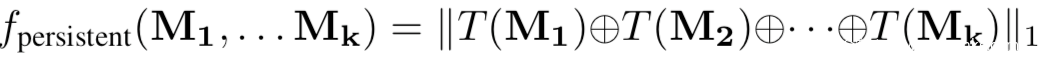
再联合利用这些特征,即
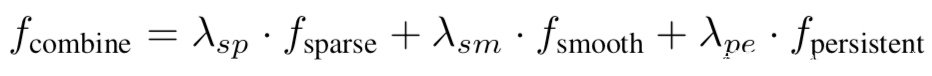
使用离群点检测方式得到离群点即可,因为作者通过观察每一个输出类的saliency map注意到,在不同的输入图像之间,攻击类别的热力图是最稀疏、最平滑、最持久的。该方案的后门检测处理步骤的流程示意如下
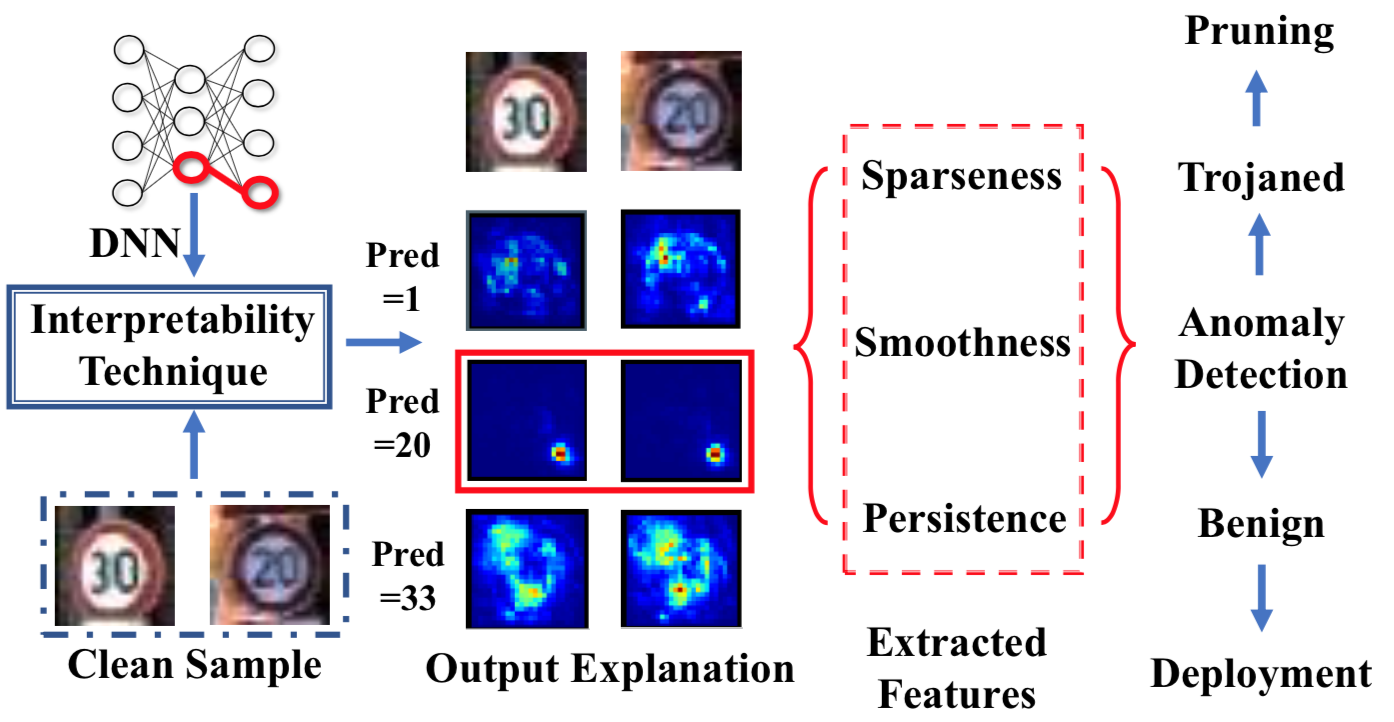
它通过生成解释热图来解释分类器在不同良性图像和不同输出标签上的输出,output explanation一列中的第三行中,当输出为攻击类别即pred=20时,后门模型有显著的可区别特征。
[15]认为后门行为抽象出来本质上可以用下图表示,c中当毒化样本输入时会有后门神经元输出较大激活从而导致误分类
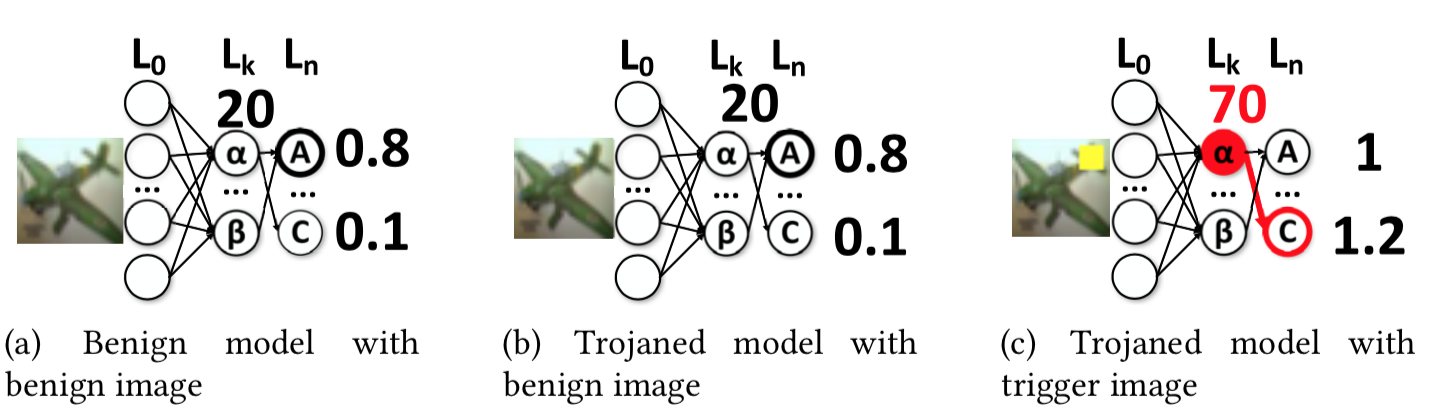
基于此,[15]对一个神经元引入不同程度的刺激,分析其输出的激活如何变化,从而分析神经元内部的行为。无论输入是什么,会对某一特定输出标签输出高激活的神经元我们就认为是后门神经元。然后使用第一步刺激分析的结果,通过优化过程逆向得到后门触发器,以确认神经元确实是有问题的。完整的流程示意图如下所示
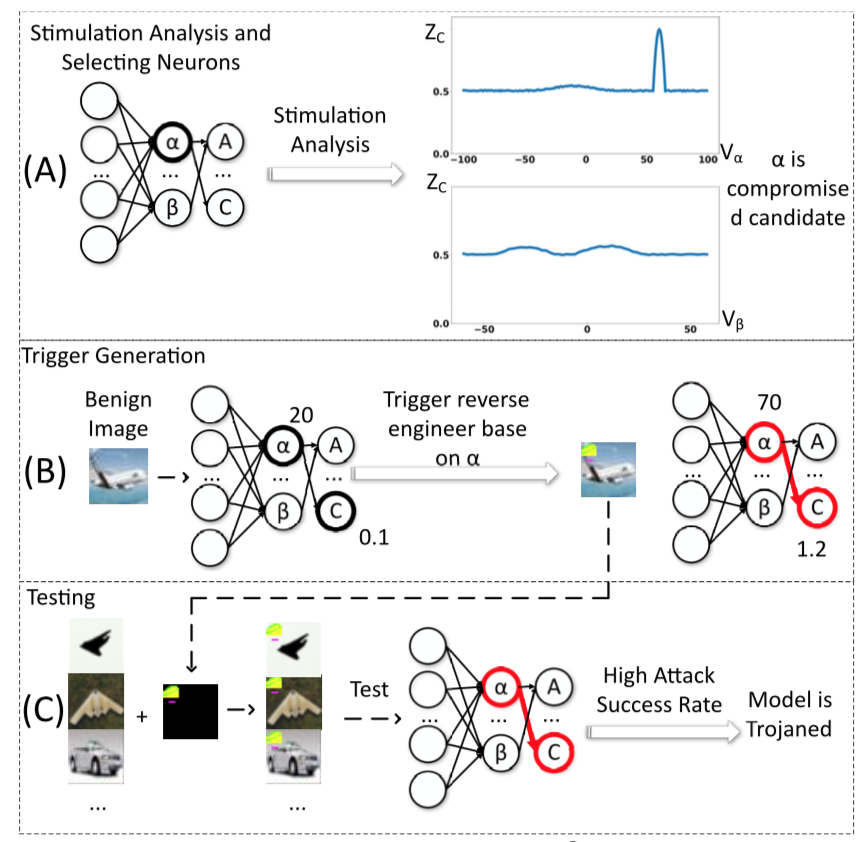
在图a中,进行刺激分析后得到它们的激活变化情况,可以看到神经元a出现了一个波峰,而神经元b则没有,所以神经元a可能是后门神经元,为了验证这一点,在图b中,基于优化的方法得到一个输入模式(其作用和触发器相同),当其叠加于输入样本时,神经元a的激活会变大,从而导致误分类,而在图c中,通过在其他测试样本上应用该触发模式,还是会导致误分类,从而表明该模型确实被植入后门了。
[16]提出了用于高维无采样生成模型的最大熵阶近似器(MESA),并用其恢复触发器的分布,并在此基础上,能够移除触发器,并对模型进行重训练。MESA的形象化表示如下
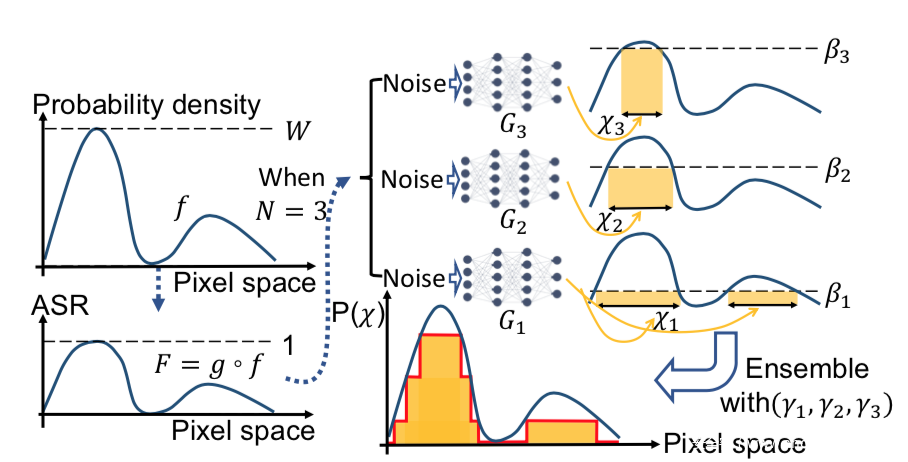
其主要是通过集成N个子模型G1,G2…来近似f,并让每个子模型Gi只学习f的一部分,f的划分采用阶梯近似的方法
下图则是MESA对触发器分布建模的形象化表示
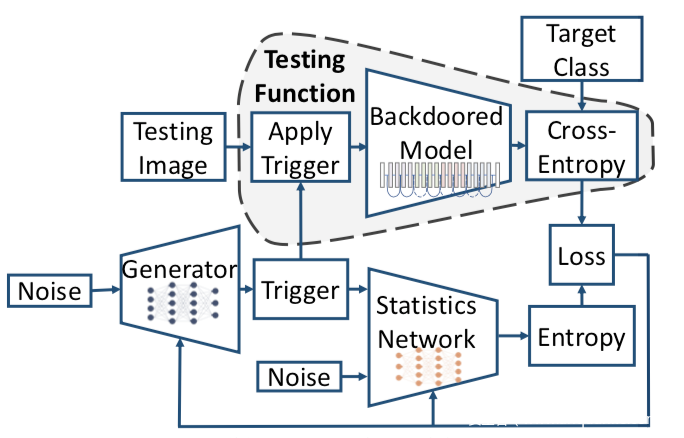
从一批随机噪声开始,生成一批触发器,并将它们输入毒化模型以及带有另一批独立噪声的统计网络,这两个分支分别计算softmax输出和触发器的熵,使用合并后的损失来更新触发器和统计网络。
在不同a,B下生成的触发器分布以及ASR如图所示
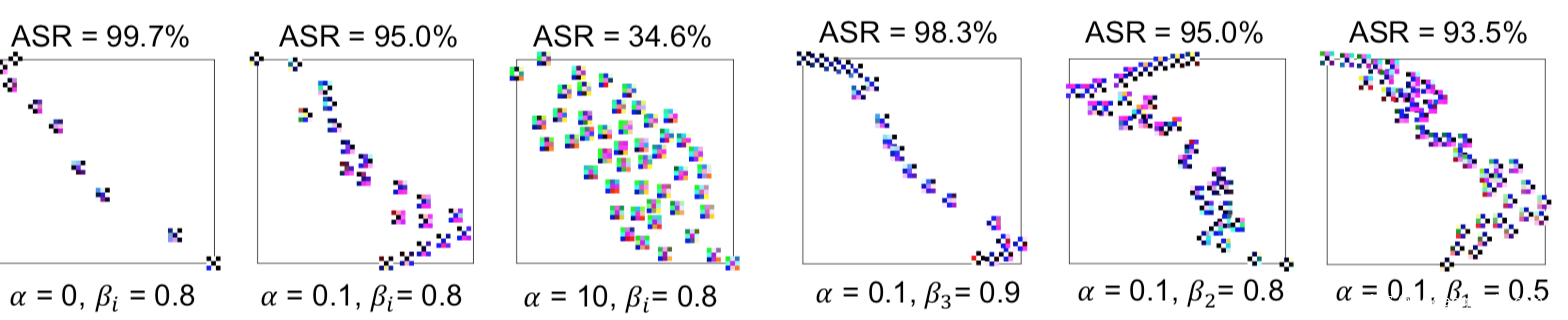
我们来看看防御效果
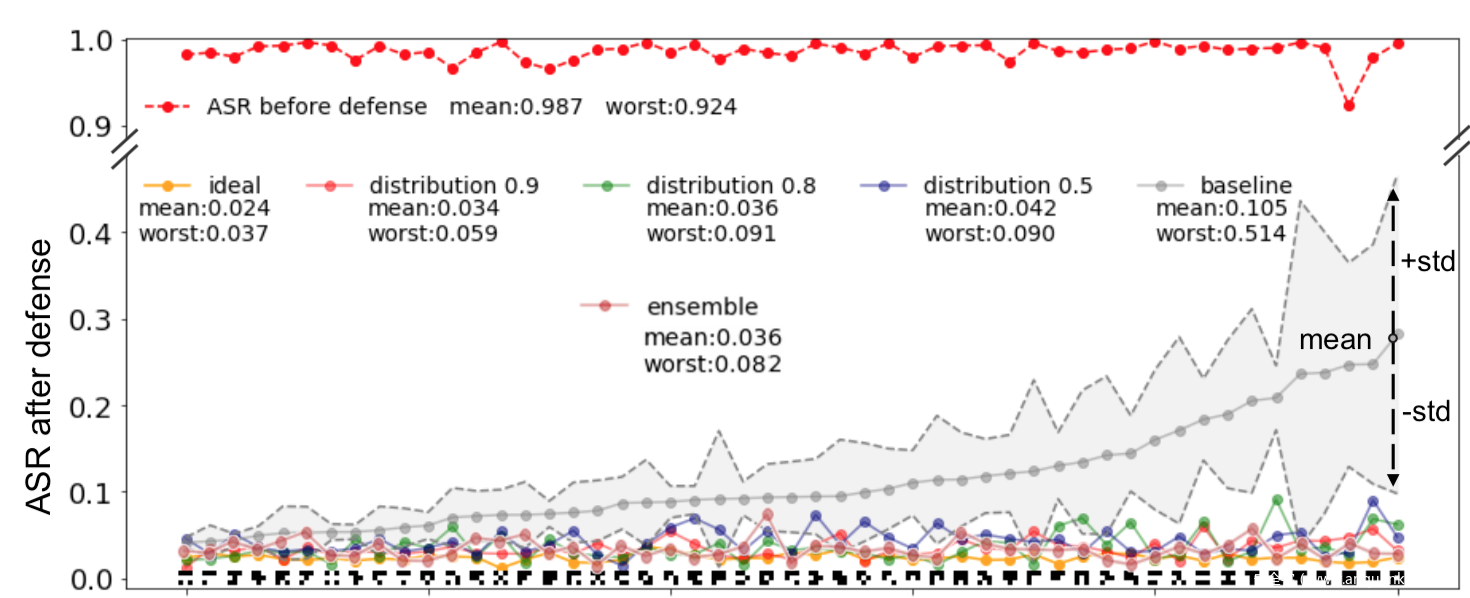
这是对51种触发器应用该方案进行防御的效果,这里我们是通过评估触发器对重训练后的模型的ASR来判断防御性能好坏。
在这里,重复十次,并根据平均表现来排序结果。当α = 0.1, βi = 0.5, 0.8, 0.9,我们的防御把原始触发器的ASR从92%以上降低到9.1%。通过对51个触发器的平均计算,使用βi = 0.9的防御方法获得了最佳的后防御ASR=3.4%,这非常接近直接使用原始触发器进行模型再训练的理想防御方法的2.4%。作为对比,基线防御方案在其防御性能上表现出显著的随机性:尽管它在“easy”触发器(上图靠左边的触发器)上实现了与我们提出的防御相当的结果,但在“hard”触发器(上图靠右的触发器)上的结果与我们的方法相比在防御后的ASR上有巨大的差异。在差异最大的情况下时,我们提出的βi = 0.9的防御方法在最坏情况下给出了5.9%的ASR,而基线ASR达到了51%以上,是所提出方法的8倍。结果表明,该方法显著提高了模型的鲁棒性。
总结
从后门攻击的对象来看,代码、数据、模型都可能会收到攻击者攻击,但是这些实际上是机器学习整个供应链中重要的环节,如果没有防御方案可以对其进行防御,则整个供应链都会受到影响。为了确保供应链的安全,就需要有针对性地进行防御。不过从本文归纳的经典方案来看,目前的防御方案大多数需要进行额外的训练得到新模型进行检测或者额外的计算、转换以识别毒化样本,这实际上增加了供应链终端也就是模型使用者的负担,因为MLaaS的提出就是为了解决终端用户计算能力不足、专业知识不够的情况,现在的防御方案却又要求在终端用户处进行防御,相当于降低了MLaaS的作用。所以在防御这块还是存在很多可以改进的地方,希望各位读者也能参与进来,为后门防御做出自己的贡献。
参考
[1]A unified framework for analyzing and detecting malicious examples of dnn models
[2]Cleann: Accelerated trojan shield for embedded neural networks
[3]Robust anomaly detection and backdoor attack detection via differential privacy,
[4]Backdoor Attacks on Deep Neural Networks by Activation Clustering
[5]Spectral Signatures in Backdoor Attacks
[6]STRIP: A Defence Against Trojan Attacks on Deep Neural Networks
[7]Model Agnostic Defence against Backdoor Attacks in Machine Learning
[8]Februus: Input Purification Defense Against Trojan Attacks on Deep Neural Network Systems
[9]Poison as a Cure: Detecting & Neutralizing Variable-Sized Backdoor Attacks in Deep Neural Networks
[10]Fine-Pruning: Defending Against Backdooring Attacks on Deep Neural Networks
[11]Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks
[12]DeepInspect: A Black-box Trojan Detection and Mitigation Framework for Deep Neural Networks
[13]TABOR: A Highly Accurate Approach to Inspecting and Restoring Trojan Backdoors in AI Systems
[14]NeuronInspect: Detecting Backdoors in Neural Networks via Output Explanations
[15]ABS: Scanning Neural Networks for Back-Doors by Artificial Brain Stimulation
[16]Defending Neural Backdoors via Generative Distribution Modeling