
介紹
内存损坏漏洞这个话题,对于初学者来说是一道坎。当我第一次开始在Windows操作系统上探索这个话题时,我立刻被现代的、公开的、专门针对这个话题的信息的奇缺震惊了。因此,这篇文章的目的并不是提供新奇的内容,而是要记录自己在探索这个话题时踩过的坑,同时,也是为相关问题的探索过程做个记录。除此之外,还有一个目的为了整合和更新与漏洞缓解系统演变相关的信息,因为这些信息通常散落在不同的地方,并且有些已经过时了。这种演变使得现有的漏洞利用技术变得更加复杂,在某些情况下甚至使这些技术完全失效。当我探索这个主题时,我决定通过记录自己在现代操作系统上使用现代编译器进行的一些实验和研究,来帮助初学者来解决这些问题。在本文中,我们将专注于Windows 10和Visual Studio 2019,并使用我编写的一系列C/C++工具和易受攻击的应用程序(这些软件可以从本人的Github存储库进行下载)。在这个系列文章中,我们要着手进行的第一项研,将专注于在Wow64下运行的32位程序中的堆栈溢出问题。
经典的堆栈溢出漏洞
经典的堆栈溢出是最容易理解的一种内存破坏漏洞:一个易受攻击的应用程序包含这样一个函数,该函数会在没有验证处于用户控制下的数据的长度的情况下将其写入堆栈。这使得攻击者可以:
- 向堆栈写入一个shellcode;
- 覆盖当前函数的返回地址,使其指向shellcode。
如果堆栈能以这种方式被破坏而不破坏应用程序,那么当被利用的函数返回时,shellcode将被执行,具体如下面的示例所示:
#include
#include
#include
uint8_t OverflowData[] =
"AAAAAAAAAAAAAAAA" // 16 bytes for size of buffer
"BBBB"// +4 bytes for stack Cookie
"CCCC"// +4 bytes for EBP
"DDDD";// +4 bytes for return address
void Overflow(uint8_t* pInputBuf, uint32_t dwInputBufSize) {
char Buf[16] = { 0 };
memcpy(Buf, pInputBuf, dwInputBufSize);
}
int32_t wmain(int32_t nArgc, const wchar_t* pArgv[]) {
printf("... passing %d bytes of data to vulnerable function\r\n", sizeof(OverflowData) - 1);
Overflow(OverflowData, sizeof(OverflowData) - 1);
return 0;
}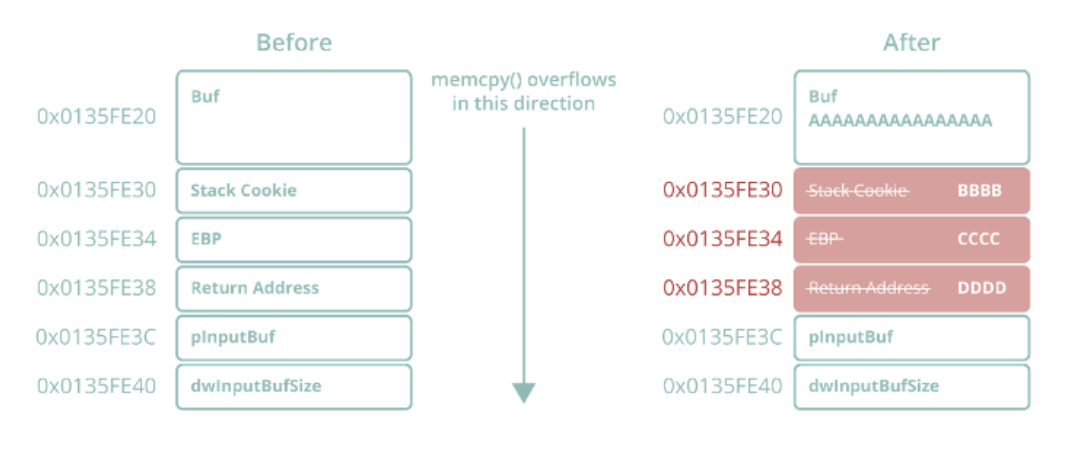
图1 用0x44444444覆盖返回地址的经典溢出漏洞
与字符串格式错误和堆溢出漏洞不同,对于栈溢出来说,攻击者仍然可以使用几十年前“Smashing the Stack for Fun and Profit”一文中提出的方法,来利用现代Windows应用程序中的这种漏洞。然而,现在针对这种攻击的缓解措施已经变得非常强大了。
在Windows 10上,默认情况下,使用Visual Studio 2019编译的应用程序将继承一组针对栈溢出漏洞的安全缓解措施,其中包括:
- SafeCRT
- 堆栈Cookie与安全的变量排序
- 安全的结构化异常处理(SafeSEH)
- 数据执行保护(DEP)
- 地址空间布局随机化(ASLR)
- 结构化异常处理覆盖保护(SEHOP)
就算让易受攻击的CRT API(如strcpy)“退休”并通过SafeCRT库引入这些API的安全版本(如strcpy_s),也无法全面解决栈溢出的问题。这是因为像memcpy这样的API仍然有效,并且这些CRT API的非POSIX变体也是如此(例如KERNEL32.DLL!lstrcpyA)。当我们试图在Visual Studio 2019中编译包含这些“被退休”的API的应用程序时,会触发严重的编译错误,尽管这些错误是可抑制的。
堆栈Cookie是试图“修复”和防止栈溢出漏洞在运行时被利用的第一道防护机制。SafeSEH和SEHOP是在堆栈Cookie外围工作的两种缓解措复施,而DEP和ASLR并不是针对堆栈的缓解方法,因为它们并不能防止堆栈溢出攻击或EIP劫持的发生。相反,它们的作用提高通过这种攻击执行shellcode的难度。所有这些缓解措施都将随着本文的推进而深入探讨。下一节将重点讨论堆栈Cookie——目前我们在尝试利用栈溢出时的主要对手。
堆栈Cookie、GS与GS++
随着Visual Studio 2003的发布,微软在其MSVC编译器中加入了一个新的栈溢出防御功能,称为GS。两年后,他们在发布Visual Studio 2005时默认启用了该功能。
关于GS,网上的信息虽然非常丰富,但是大部分都是过时的和/或不完整的信息。之所以出现这种情况,是因为GS的安全缓解措施自最初发布以来已经发生了重大的变化:在Visual Studio 2010中,一个名为GS++的增强版GS取代了原来的GS功能。令人困惑的是,微软从未更新其编译器选项的名称,尽管实际上是GS++,但至今仍是“/GS”。
从根本上说,GS其实是一种安全缓解措施,它被编译进二进制级别的程序,在包含Microsoft所谓的“GS缓冲区”(易受堆栈溢出攻击的缓冲区)的函数中放置策略性堆栈损坏检查(借助于堆栈Cookie)。最初的GS只考虑包含8个或更多元素,元素大小为1或2(字符和宽字符)字节的数组作为GS缓冲区,而GS++对此定义进行了实质性扩展,包括:
- 任何数组(无论长度或元素大小)
- 结构体(无论其内容是什么)
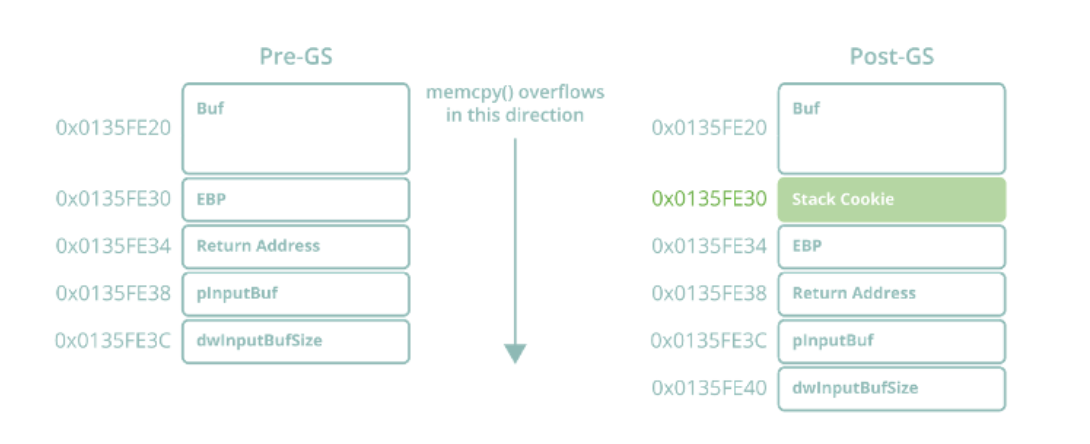
图2 GS堆栈的canary机制
这个增强技术对现代堆栈溢出漏洞有很大的意义,因为它基本上使所有容易受到堆栈溢出攻击的函数免于受到基于返回地址的EIP劫持技术的影响。这反过来又会对其他陈旧的利用技术产生影响,比如通过部分EIP覆盖来绕过ASLR的技术——2007年著名的Vista CVE-2007-0038 Animated Cursor漏洞就利用结构溢出而流行起来的。随着2010年GS++的出现,在典型的堆栈溢出情况下,部分EIP覆盖作为ASLR绕过的方法已经失效。

MSDN上关于GS的信息(最后一次更新是在四年前的2016年),在GS覆盖率方面,与我自己的一些测试结果是相矛盾的。例如,微软将以下变量列为非GS缓冲区的例子:
char *pBuf[20];
void *pv[20];
char buf[4];
int buf[2];
struct { int a; int b; };然而在我自己使用VS2019进行的测试中,这些变量都会导致堆栈Cookie的产生。
究竟什么是堆栈Cookie,它们是如何工作的?
- 堆栈Cookie在Visual Studio 2019中是默认设置的。它们可以使用/GS标志进行配置,我们可以在项目设置的 Project -> Properties -> C/C++ -> Code Generation -> Security Check字段中设置该标志。
- 当加载了一个用/GS编译的PE时,它会初始化一个新的随机堆栈Cookie种子值,并将其作为一个全局变量存储在其.data段中。
- 每当一个包含GS缓冲区的函数被调用时,它都会将这个堆栈Cookie种子与EBP寄存器进行XOR运算,并将其存储在保存的EBP寄存器和返回地址之前的堆栈上。
- 在受保护的函数返回之前,它会再次用>EBP对其保存的伪唯一性堆栈Cookie进行XOR运算,以获得原始的堆栈Cookie种子值,并进行相应的检查,以确保它仍然与存储在.data段的种子相匹配。
- 如果这个值不匹配,应用程序会抛出一个安全异常并终止执行。
由于攻击者不可能在覆盖返回地址的同时不覆盖函数栈帧中保存的堆栈Cookie,这种机制能够阻止栈溢出漏洞利用代码通过RET指令劫持EIP,从而达到任意执行代码的目的。
在现代编译环境中编译并执行图1所示的栈溢出项目,会出现STATUS_STACK_BUFFER_OVERRUN异常(代码0xC0000409);使用调试器可以逐步剖析其出错原因。
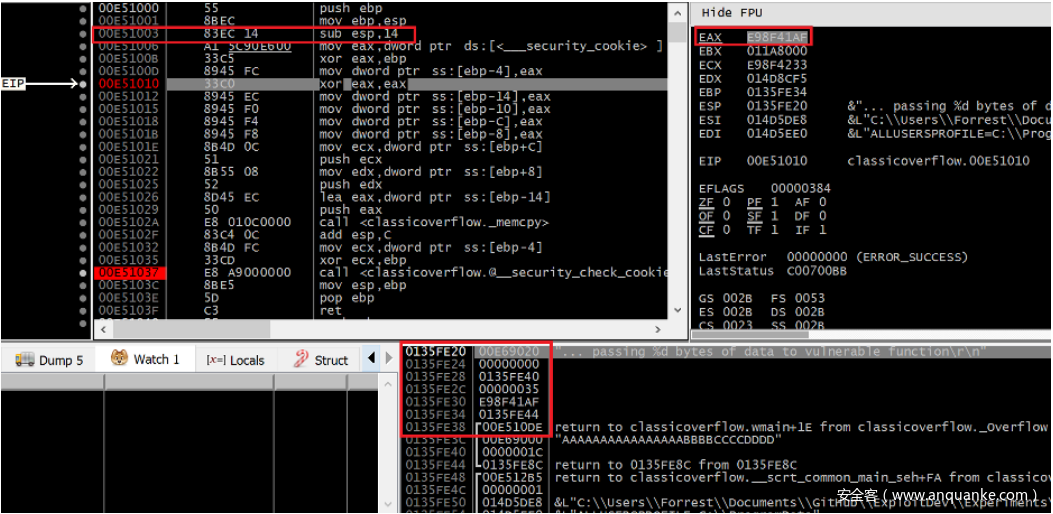
图3 易受攻击的函数在其栈帧被初始化后的调试跟踪情况
值得注意的是,图3中创建的栈帧的大小为0x14(20)字节,尽管该函数中缓冲区的大小为0x10(16)字节。实际上,多出来的4个字节是用于存放堆栈Cookie的,实际上,我们可以在栈帧中看到这个堆栈Cookie,其值为0xE98F41AF,位于0x0135FE30处,正好在保存的EBP寄存器和返回地址之前。重新审视图1中的溢出数据,我们可以推测出memcpy函数用我们预定的28个字节覆盖大小为16个字节的本地缓冲区并返回后,堆栈将是什么样子。
uint8_t OverflowData[] =
"AAAAAAAAAAAAAAAA" // 16 bytes for size of buffer
"BBBB"// +4 bytes for stack Cookie
"CCCC"// +4 bytes for EBP
"DDDD";// +4 bytes for return address地址范围0x0135FE20到0x0135FE30之间的(本地缓冲区长度为16个字节)内存将被字符A(即0x41)所覆盖。而0x0135FE30处的堆栈Cookie将被字符B所覆盖,导致新的值变为0x42424242。对于新值0x43434343,应使用字符C覆盖保存在0x0135FE34处的EBP寄存器;对于新值0x44444444,应使用字符D覆盖0x0135FE38处的返回地址。如果溢出成功,则会把新地址0x44444444重定向到EIP。

图4 易受攻击的函数的堆栈溢出后的调试跟踪情况
不出所料,在memcpy函数返回之后,我们可以看到堆栈确实被我们的预期数据破坏了,其中包括返回地址0x0135FE38,现在已经变为0x44444444。在过去,当这个函数返回时,会出现访问冲突异常,并断言0x44444444是一个要执行的无效地址。但是,堆栈Cookie安全检查将阻止这种情况。首次执行该函数时,如果将存储在.data段中的堆栈Cookie种子与EBP进行XOR运算,结果将为0xE98F41AF,然后将其保存到堆栈中。由于这个值在溢出期间将被值0x42424242所覆盖(如果我们希望能够覆盖返回地址并劫持EIP,这是不可避免的),从而生成有毒的堆栈Cookie值,即0x43778C76(在ECX中可以清楚看到),现在,该值将被传递给内部函数__security_check_Cookie进行验证。
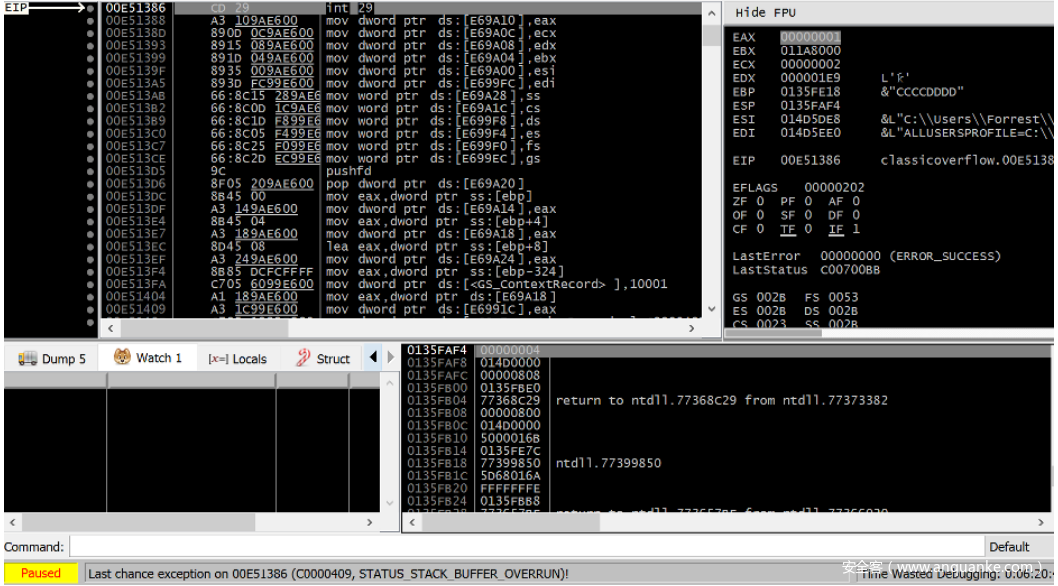
图5 在允许调用__security_check_Cookie后,易受攻击的应用程序的调试跟踪会抛出安全异常
一旦这个函数被调用,就会导致STATUS_STACK_BUFFER_OVERRUN异常(代码0xC0000409)。这虽然会导致进程崩溃,但也防止了攻击者成功利用该漏洞。
当您熟悉这些概念和实际例子后,会注意到关于堆栈Cookie的几个“有趣”的事情:
- 它们不能防止堆栈溢出的发生。攻击者仍然可以随心所欲地在堆栈上覆盖任意数量的数据。
- 它们只是针对每个函数的伪随机值。这意味着,如果.data中的堆栈Cookie种子发生内存泄漏,同时堆栈指针也发生泄漏,攻击者就可以准确地预测Cookie,并将其嵌入到其溢出中以绕过安全异常。
从根本上来说(假设它们无法通过内存泄漏进行预测),堆栈Cookie只能防止我们通过易受攻击的函数的返回地址来劫持EIP。这意味着我们仍然可以以任何方式破坏堆栈,并能够在安全检查和RET指令之前执行任意代码。那么,这在现代堆栈溢出的可靠利用过程中有什么价值呢?
小结
在本文中,我们为读者介绍了堆栈溢出漏洞,以及当前系统提供的针对该类漏洞的缓解措施,在下一篇文章中,我们将继续为读者详细介绍SHE劫持技术。