robots
![]()
测试程序
int fd;
struct stat st;
void *mem;
void processMem(void)
{
char ch = *((char*)mem);
printf("%c\n", ch);
}
int main(void)
{
fd = open("./test", O_RDONLY);
fstat(fd, &st);
mem = mmap(NULL, st.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
processMem();
}
触发缺页异常
![]()
-
((char)mem)最终被编译成一个内存读指令, rax为mem, 但此时CPU并不能感知到刚刚mmap的虚拟地址区域, 指令执行的详细过程如下
- CPU执行[rax]时用的地址是虚拟地址, 会被送入MMU中, 尝试转化为物理地址
- 物理地址是在电路层面能够直接用于访问内存的地址, 类似于实模式下内存地址的概念
- cr3指向全局页目录, MMU尝试用虚拟地址逐级匹配页表项, 以完成虚拟到物理地址的映射
- 虚拟地址转化出来的其实是线性段地址, 但由于x86下是平摊模式, 段基址为0, 所以这里就把线性地址当做物理地址
- 根据之前对于mmap()的分析可以知道, mmap()并没有没有分配页框, 页没有设置页表, 因此MMU转换地址时注定发生异常, 会向CPU发送一个缺页异常的中断信号, CPU接收到以后会根据中断号调用异常处理函数: page_fault()
陷入中断
- x86_64下每个task都有自己的内核栈, 用来当做陷入内核态时的工作环境. 除此之外还有与每个CPU相关的专用栈, 中断栈就属于这一类. 当外部硬件中断发生时CPU就会切换到这个栈, 作为中断处理的工作环境
- 陷入中断后
- 从IDT中读入cs:ip
- 从TSS中读入RSP0作为中断栈
- CPU把cs的最低2bit作为CPL, 表示当前的权限级别
- TSS中保存有4个SS:RSP, 当权限切换到x时, CPU就会自动载入第x个SS:RSP作为中断栈
- 还有一种利用IST进行的栈切换, 缺页中断并不使用, 所以不讨论
- 接着CPU向中断栈依次push如下内容
- 发送中断时的ss:sp
- 发送中断时的标志寄存器: eflags
- 发送中断时的cs:ip (指向引起中断的指令, 因为这个指令执行失败, 中断处理完成后要重新执行)
- 错误代码, 这里是0x4
- 以上这部分不需要代码借入, 全部由CPU的电路完成
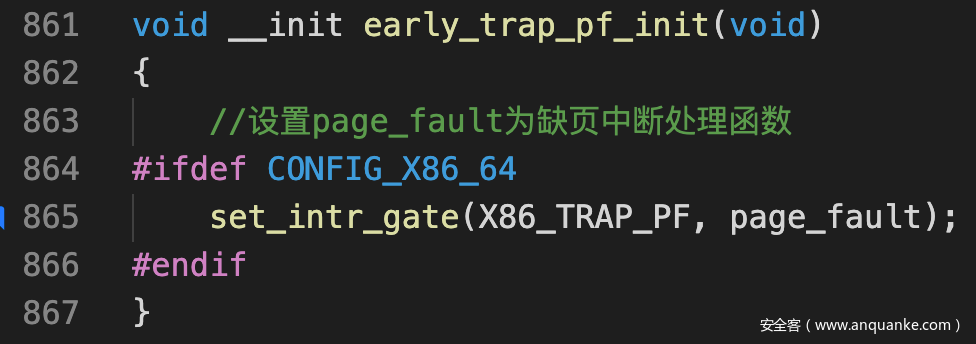
- 内核在初始化时就指定了page_fault为中断处理的入口
![]()
![]()
page_fault
- page_fault是一个标号, 而非函数, 在entry_64.S中通过trace_idtentry宏展开来的定义, trace_idtentry宏会转化为对idtentry宏的调用
![]()
- idtentry宏的具体实现不用关心, 主要负责包装IDT中处理函数的入口, 创建一个符合C函数调用约定的环境
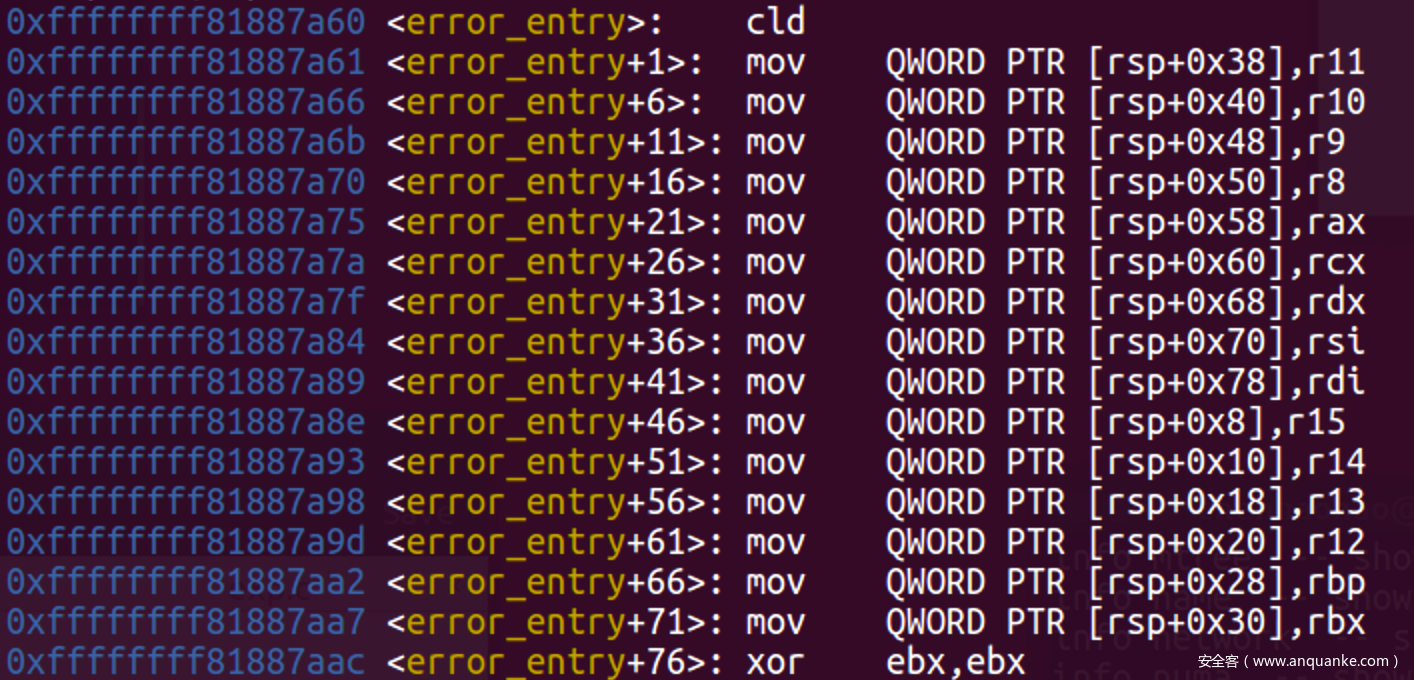
- 首先在栈上分配足够的空间用来保存错误代码和中断现场:pt_regs, 然后调用error_entry构造pt_regs
![]()
- error_entry关闭中断后把对应寄存器保存到栈上的pt_regs中
![]()
- 然后根据cs判断需要切换gs, 执行swapgs指令, 然后ret返回
![]()
- 回到page_fault, 进行三个操作
- 设置第一个参数为rsp, 因为rsp上存放着pt_regs, 所以在C中函数第一个参数就是struct pt_regs* regs
- 然后把CPU压入的错误代码放入rsi中作为第二个参数, 并把原来的错误码设置为-1, 所以C中函数第二个参数就是unsigned long error_code,
- 此时已经满足C中函数调用的约定, 调用C编写的do_page_fault进行真正的处理工作
![]()
- 对于缺页异常, 错误代码含义如下
- P=0: 由页不存在引起的, P=1 页存在, 是权限问题引起的
- W=0: 由读引起的, W=1: 由写引起的
- U=0: 内核态下引起的异常, U=1: 用户态(CPL=3)下引起的
- I=1: 由取指令引起的, 只在页支持执行权限时使用
![]()
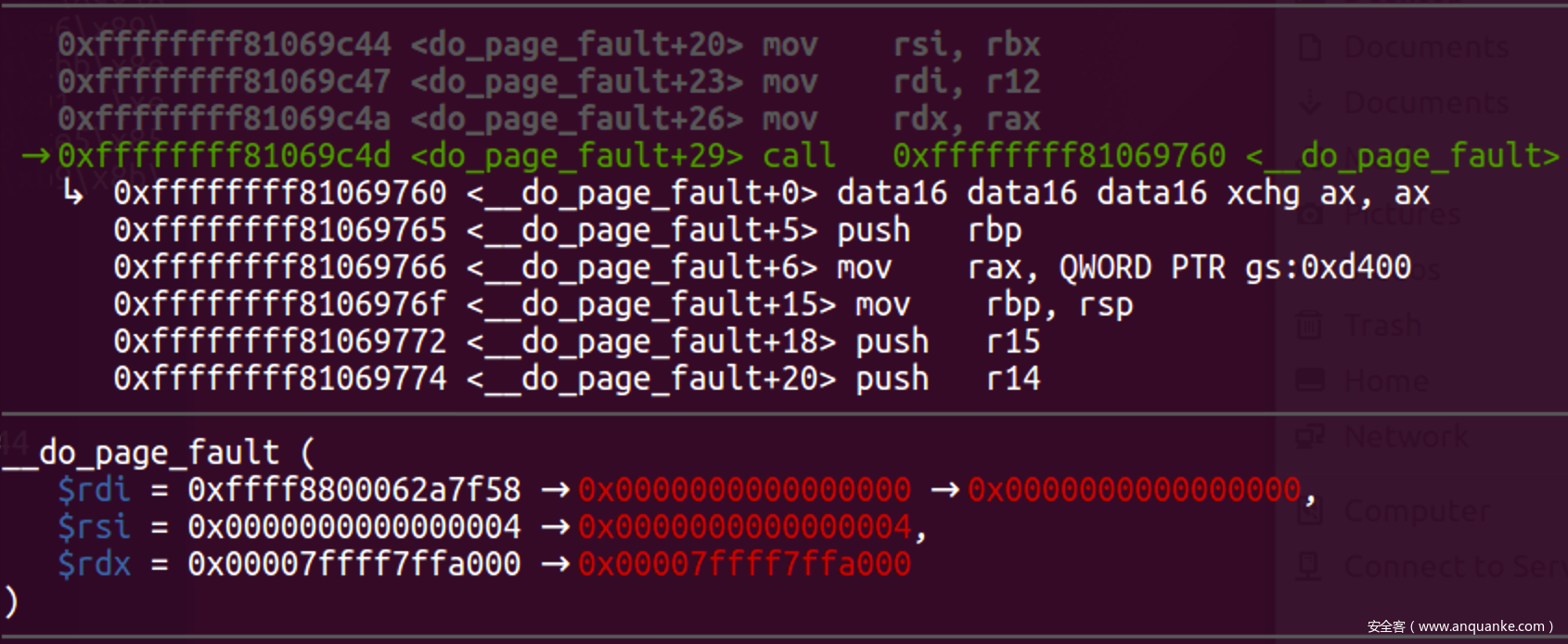
do_page_fault()
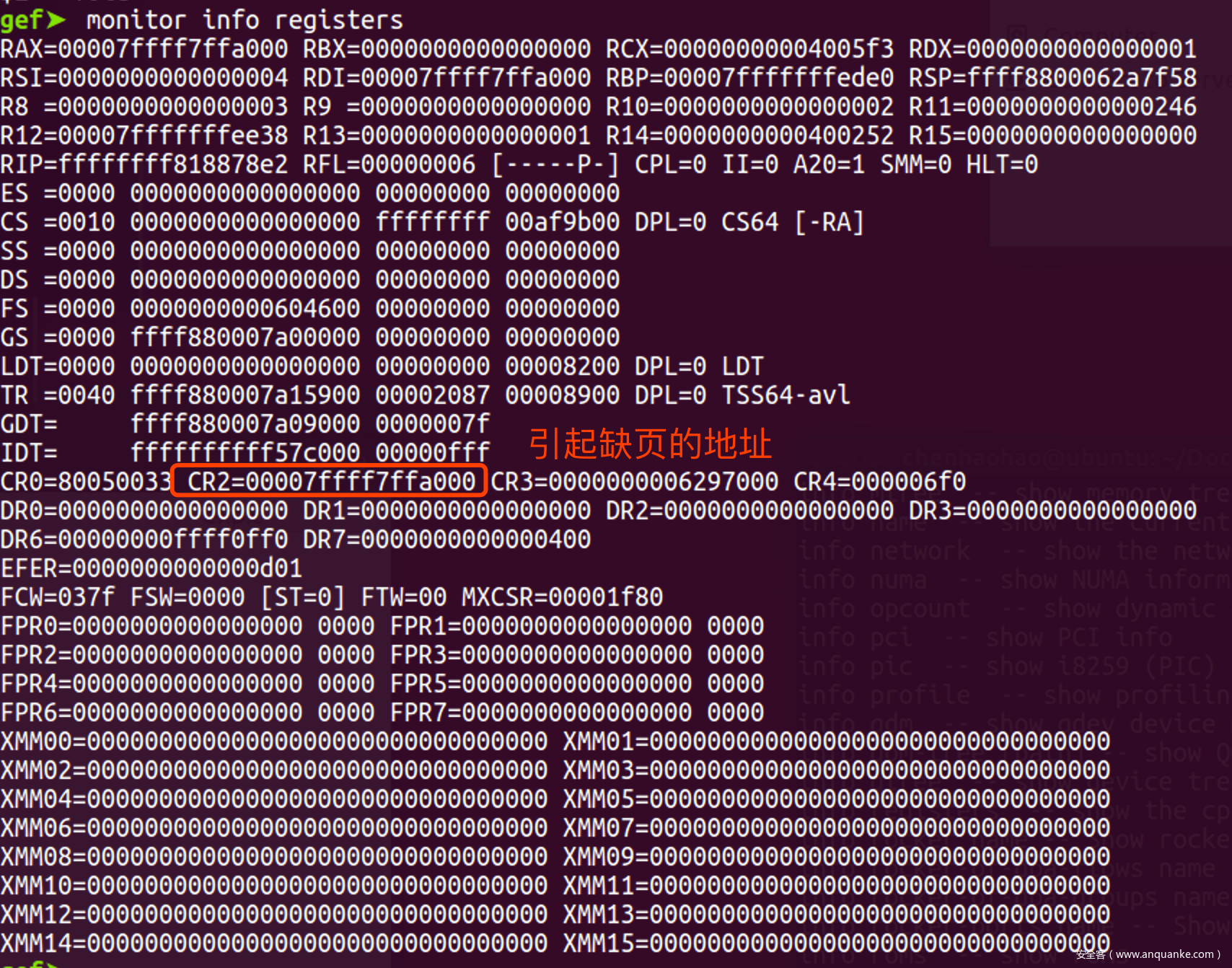
- 有了中断现场, 错误代码后, 对于缺页异常还需要一个参数: 引起缺页异常的地址, CPU把这个地址放在CR2寄存器中, 如下
![]()
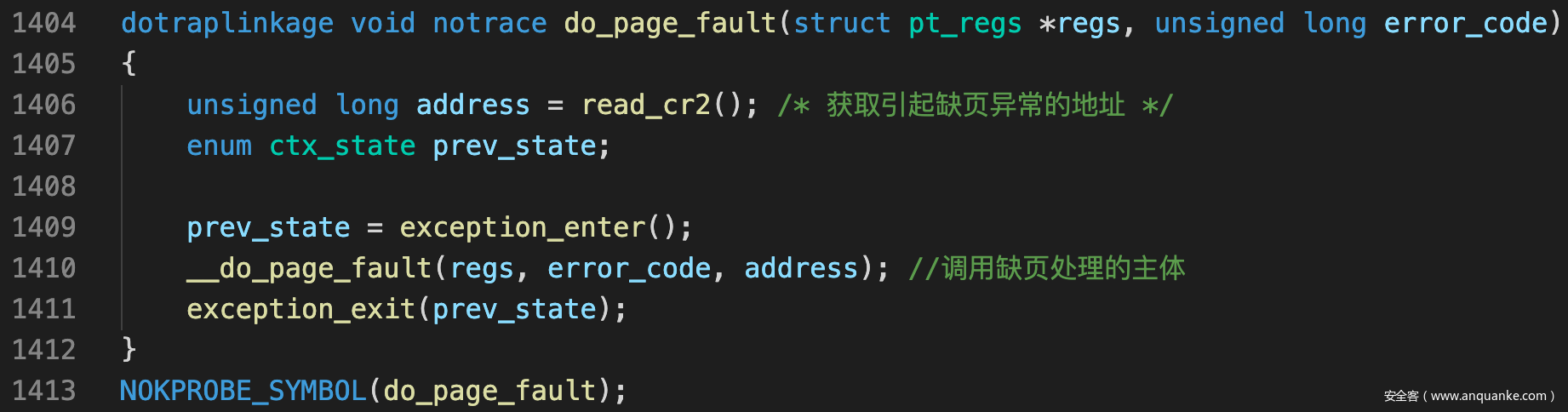
- 所以do_page_fault就干了两件事
- 读cr2获取缺页异常的地址
- 调用主要处理函数__do_page_fault()
![]()
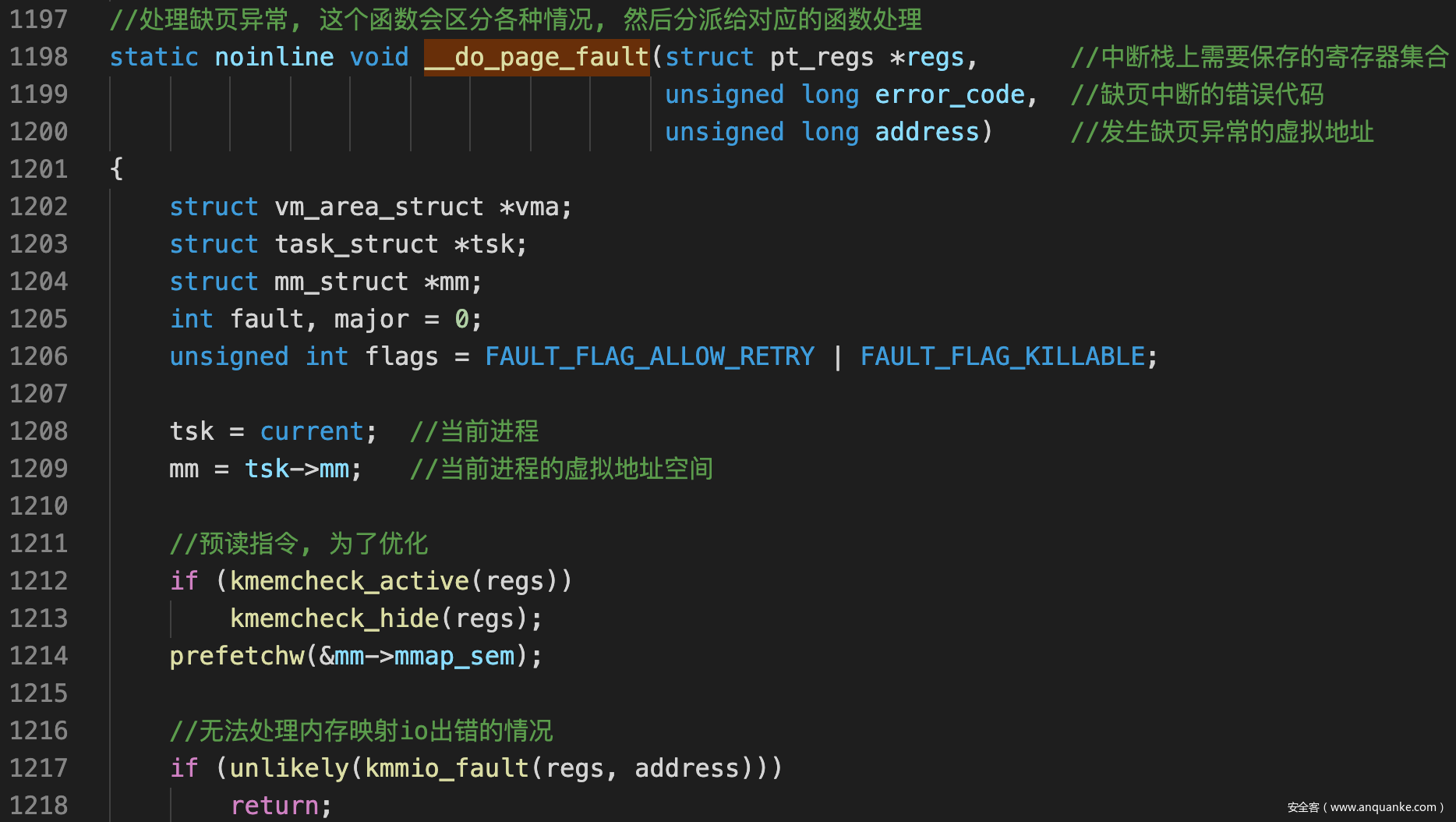
__do_page_fault()
![]()
- 对应到do_page_fault()的参数, do_page_fault()是一个分配器函数, 主要任务就是分配引起缺页异常的各个情况, 然后分派给各个进程完成
![]()
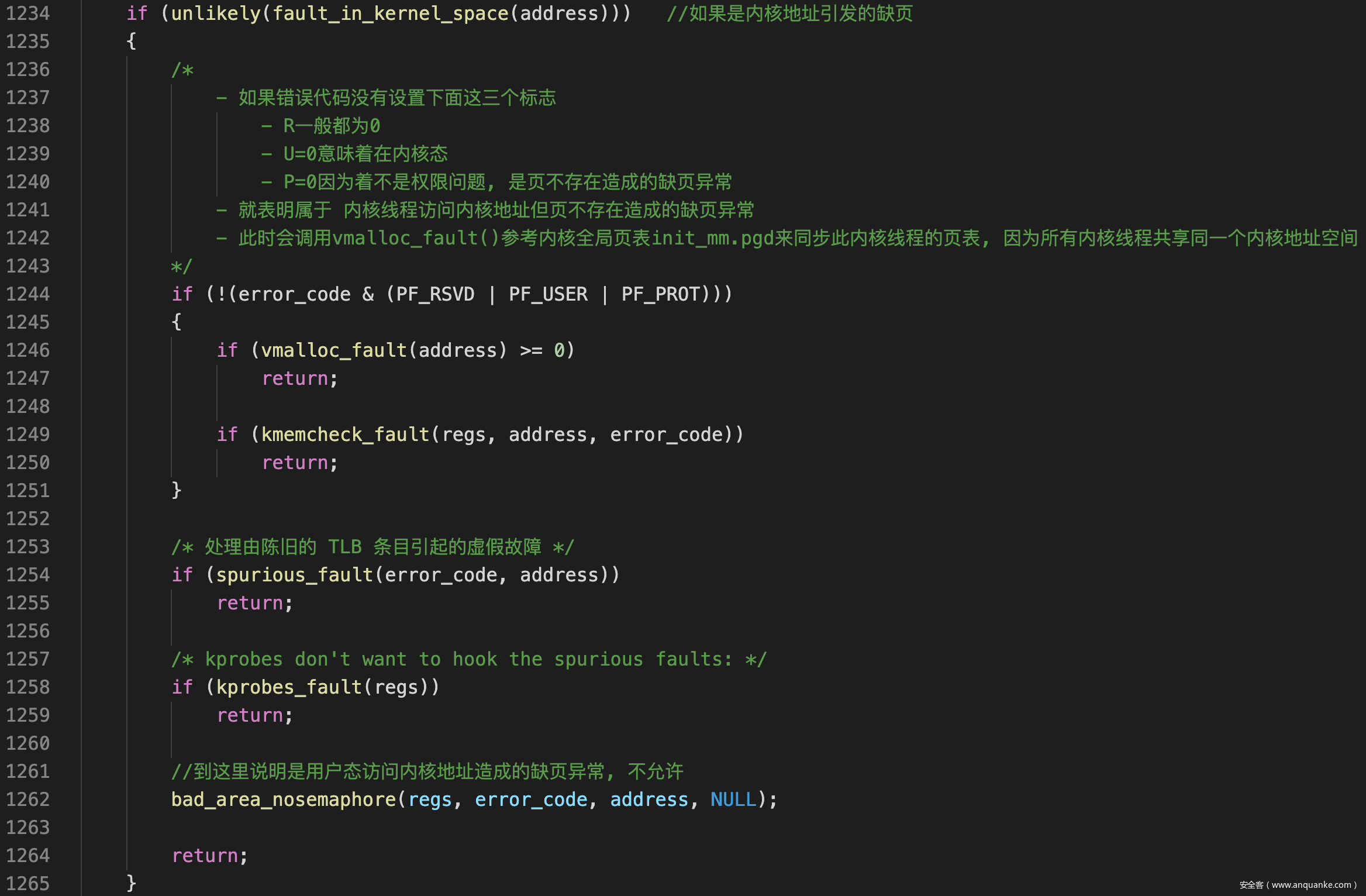
- __do_page_fault()先处理内核地址引发的缺页异常, 我们的调试的异常并不属于这一类
![]()
- 这里需要解释下什么叫内核线程的页表, 通过页表进行地址转换时会用到TLB缓存一部分转换的地址, 从而提高速度, 每次切换页表(也就是写入cr3)都会导致TLB失效, 代价比较大, 因此linux使用了惰性TLB机制, 尽量减少页表的切换
- 在进程描述符中有两个字段mm与active_mm, mm指向该进程拥有的地址空间, active_mm指向该进程活动的地址空间
- 对于用户进程 mm==active_mm, 不用做出区分
- 对于内核线程
- 其不拥有自己独立的地址空间, 这也是我称之为内核线程而非进程的原因, 为了强调这一点, 其mm为NULL
- 由于用户进程只使用用户地址空间部分(0~TASK_MAXSIZE), 因此内核线程就可以借用用户进程的页表中内核地址的部分. 而且就借用切换到内核线程之前运行的那个用户进程的地址空间, 因此其active_mm为前一个用户进程的mm
- 如果从用户进程A切换到内核进程B, B直接借用了A的地址空间的内核部分, 就不需要设置cr3切换页表了. 并且内核线程不会随便使用用户地址空间的部分, TLB中的信息仍然有效, 十分友好.
- 这里需要注意, 本质上一个内核线程的active_mm是随机一个用户进程的mm, 如果访问内核地址时发生溢出, __do_page_fault()就会调用vmalloc_fault()参考init_mm.pgd设置这个用户进程mm中的内核地址部分. 我们可以认为当运行很长时间后, 所有用户进程的内核地址部分都与init_mm.pgd同步
- 理解了惰性TLB之后就可以理解为什么 __do_page_fault()不让内核态的程序随便访问用户地址了
![]()
- 现在进入了最常见的用户进程访问用户地址造成的缺页的情况, __do_page_fault()首先设置了一些flags
![]()
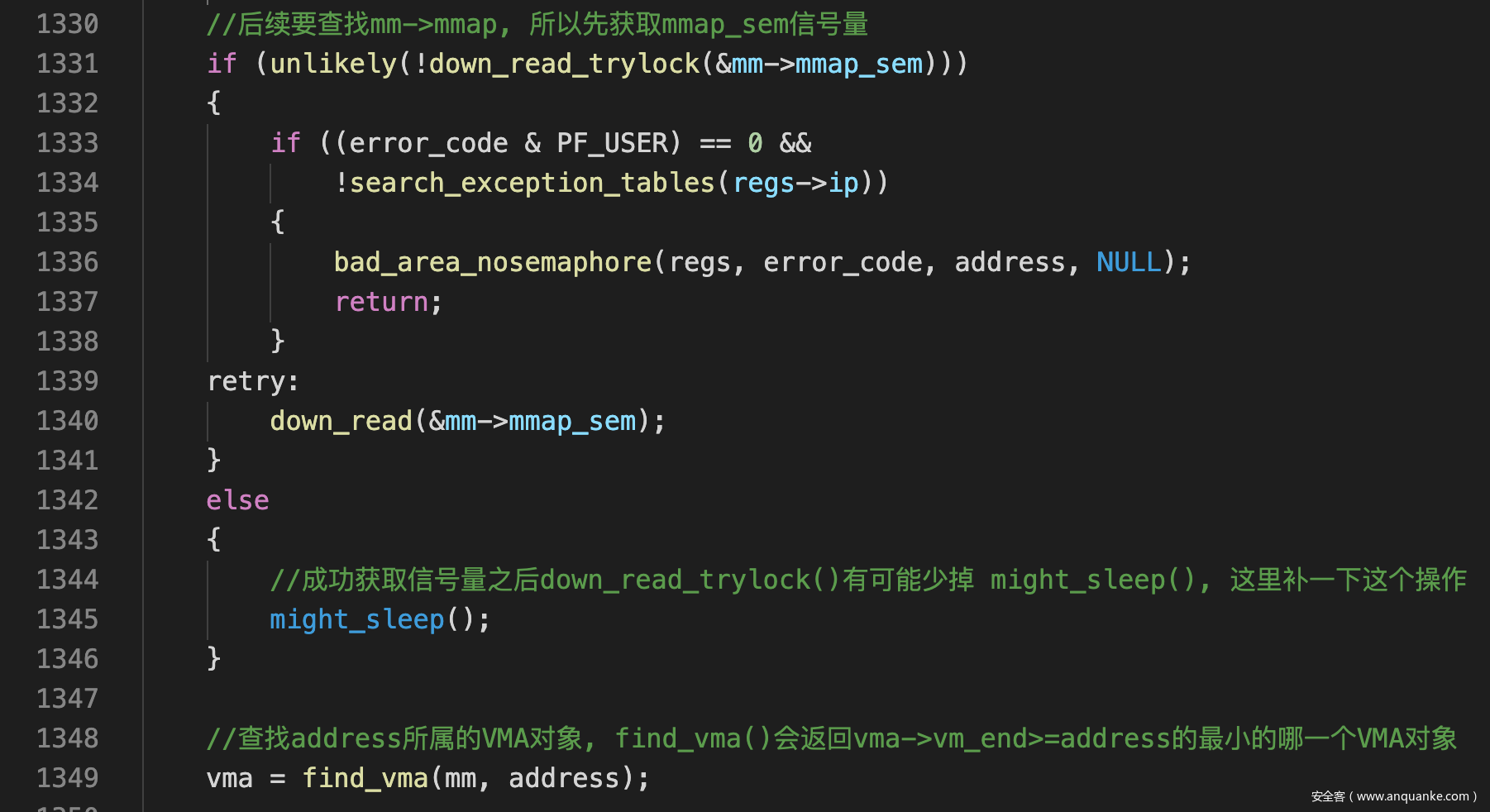
- 然后获取mm->mmap_sem, 在地址空间mm中搜索vm->end比address大的第一个VMA对象
![]()
- 然后判断address是否真的是用户地址空间中映射的地址, 如果是的话进入good_area逻辑, 我们调试的进程也是进入这部分. 后续还有对栈空间不足这一情况的判断, 不是重点就不细说了
![]()
- __do_page_fault()首先会调用access_error()判读下本次内存访问是否有权限问题, 如果没问题的话调用handle_mm_fault()处理
![]()
- 这里有必要说一下内存的权限, 内存的权限保存在两个位置:
- 页表项PTE的bit中, 这部分被MMU使用, 是硬件判断否引发缺页异常的依据
- vma->vm_flags中, 这部分被内核使用, 记录了这片虚拟内存真实的权限,
- 所以缺页异常发生时, 内核需要结合vma->vm_flags判断是自己比较懒进行了写时复制造成的权限问题, 还是映射时权限本来就不够, 这部分工作由access_error()完成
- 下图为页表项结构
![]()
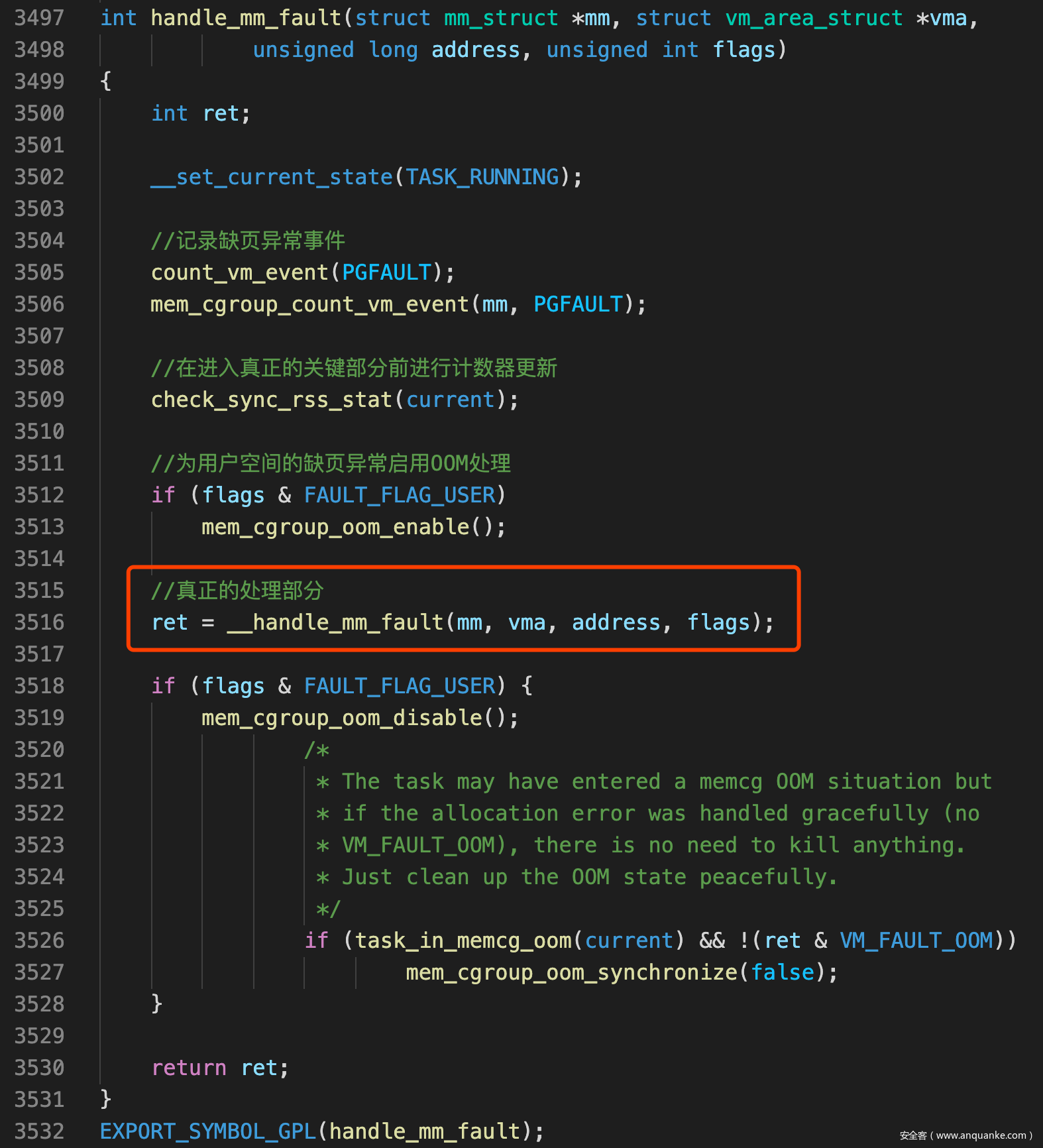
handle_mm_fault()
![]()
- handle_mm_fault()这是一个包裹函数, 进行一个预处理后调用真正的处理函数__handle_mm_fault()
![]()
__handle_mm_fault()
- __handle_mm_fault()先进行一些简单的处理, 这些不是重点
![]()
![]()
- __handle_page_fault()下一步就是在页表中分配逐级分配对应的页表项, pgd中每一项总是存在的, 因此不需要分配, 但是对于次级页表就不一样了
![]()
![]()
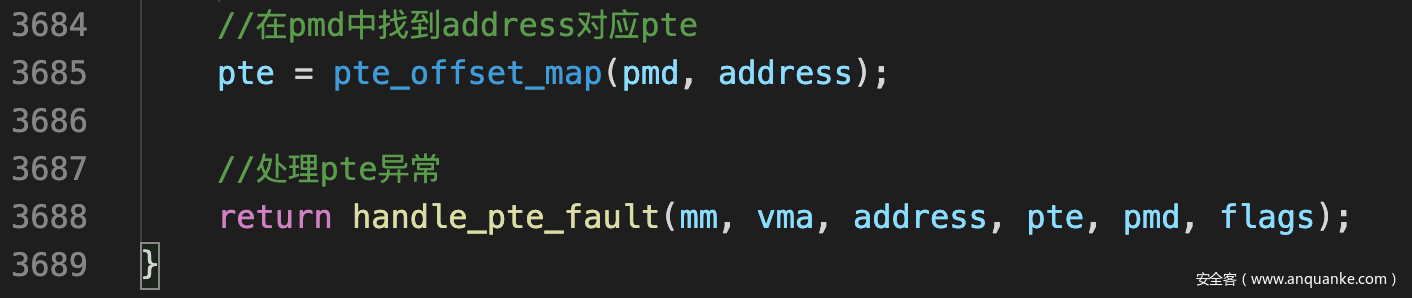
- 现在address的相关页表结构已经建立完毕, 调用handle_pte_fault()处理PTE引起的异常, 也就是要真正分配页框并设置PTE以建立完整的映射了
![]()
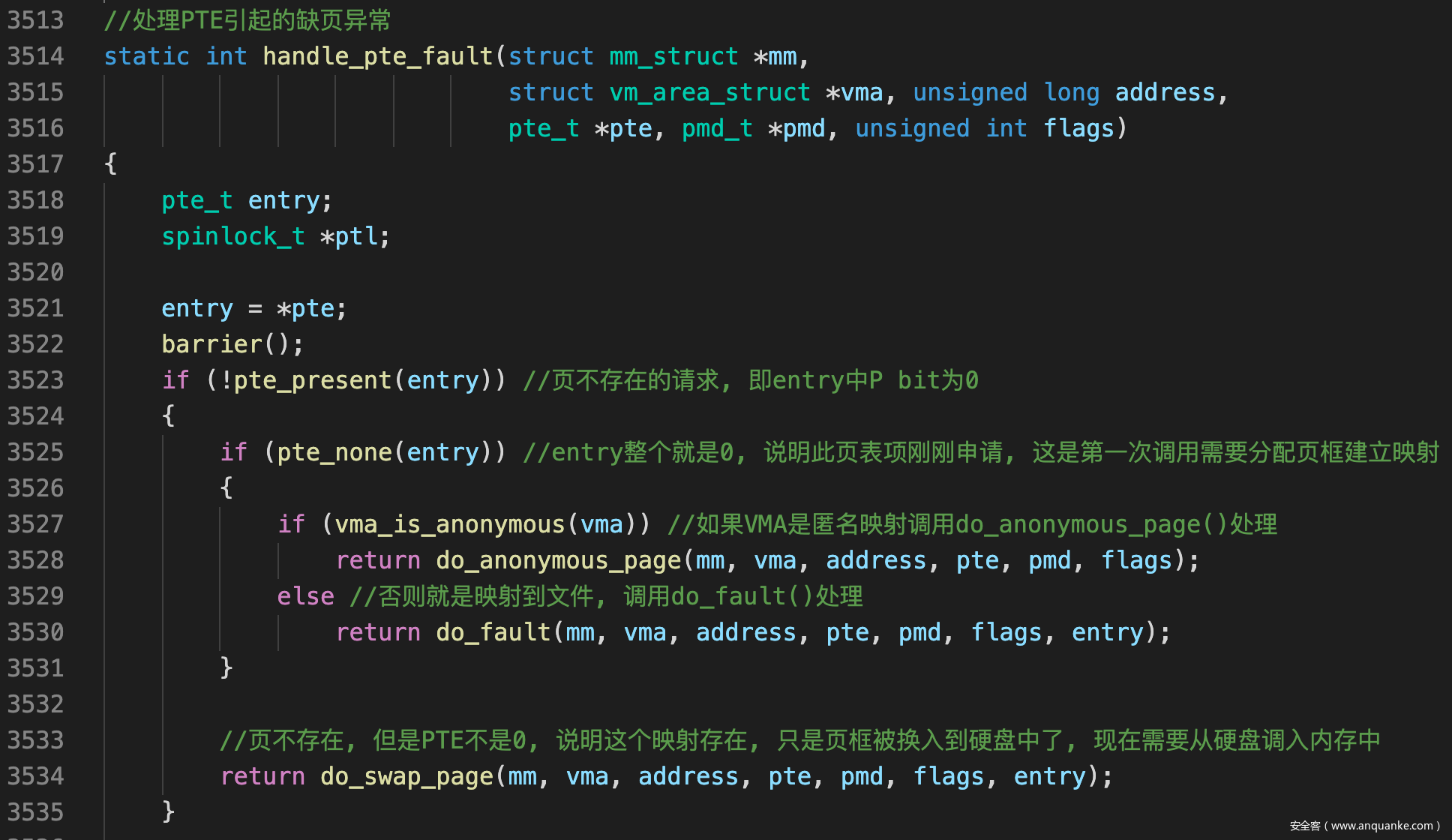
handle_pte_fault()
- 这个函数也适合分配器函数, 首先处理页不存在的情况, 会衍生处三种处理
- 匿名映射区刚刚建立页表项造成PTE为none, 调用do_anonymous_page()处理
- 文件映射区刚刚建立页表项造成PTE为none, 调用do_fault()处理
- 页框被换出, 因此页不存在但是PTE不是none, 调用do_swap_page()处理
![]()
- 接着判断页存在的缺页异常, 这种情况就属于写时复制了, 调用do_wp_page()处理, 然后写入pte并更新缓存
- 写时复制: 进程需要映射一个可读可写入页, 内核之前偷懒, 只分配了一个可读页, 这样多个进程就可以共享一个页, 现在进程真的需要写入了, 就只能把原来页复制一份给他写入
![]()
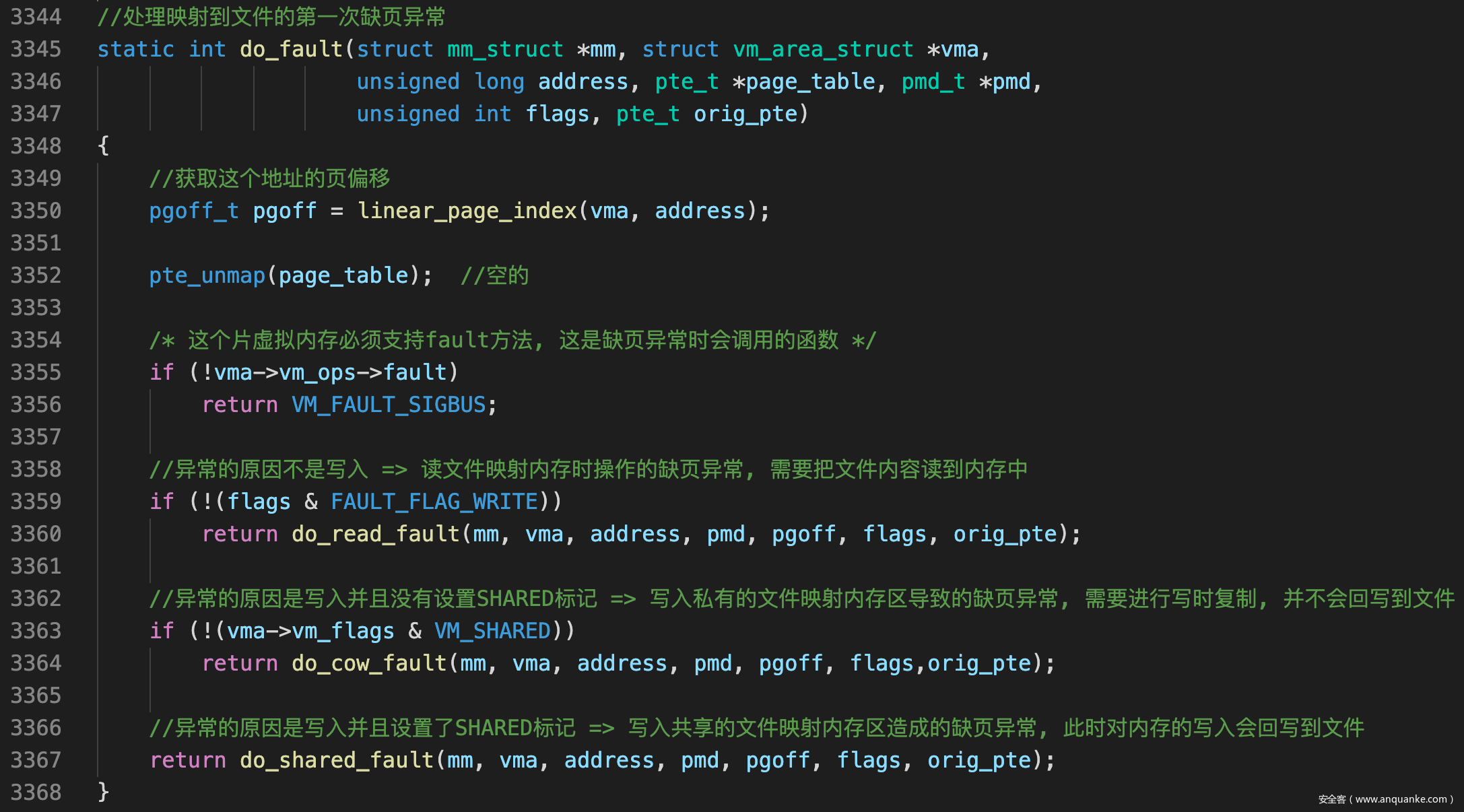
do_fault()
- 这玩意也是一个分配器, 处理映射到文件的第一次缺页异常, 我们调试的程序会调用do_read_fault()处理
![]()
do_read_fault()
- do_read_fault()则进行了一个局部性优化, 如果要在address周围映射多个页则调用do_fault_around, 否则就调用__do_fault()
- 在我们调试的程序中会调用do_fault_around()
![]()
![]()
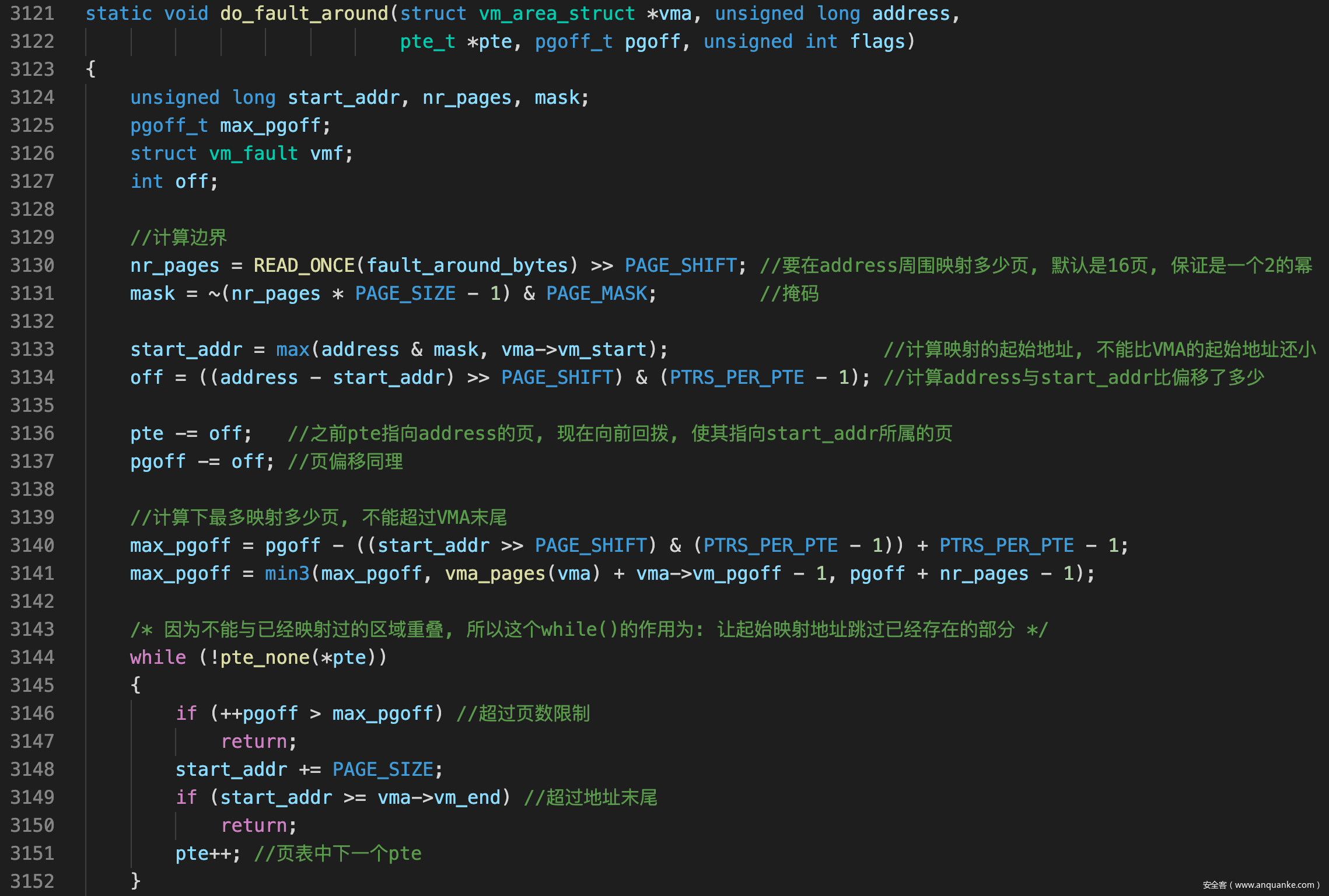
do_fault_around()
- do_fault_around()首先需要根据fault_around_bytes计算要映射的范围
![]()
- 然后初始化一个vmf对象传递相关参数, 调用vm_ops->map_pages()进行处理
![]()
- 根据之前mmap时的设置, 可以得知会调用filemap_map_pages()函数来处理映射
![]()
filemap_map_pages()
- 至此不得不说一下内核中的地址空间(address_space), 这里的地址空间不是内存的, 而是对于文件的一种重要的抽象
- 基本概念
- 块设备(比如硬盘) 逻辑上可以理解为以块为单位进行读写的一维数组
- 文件则就是一段连续的字节. 注意: 文件在硬盘上并不是以连续的块储存的, 因为多次删除申请之后会出现空洞的问题, 造成空间浪费.
- 文件系统(比如Ex2 Ex3): 文件的数据块以何种方式保存在硬盘上
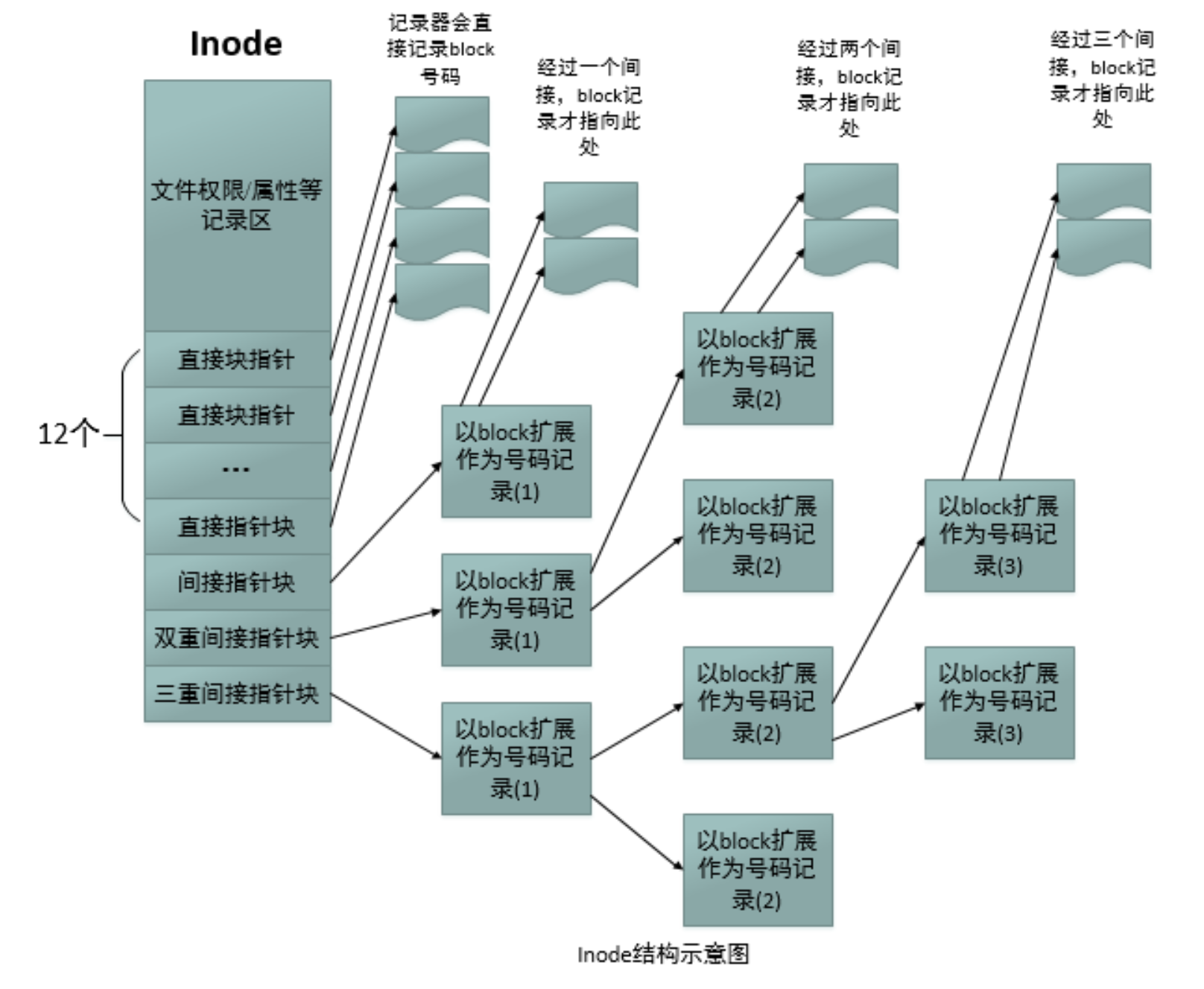
- 内核用索引节点(inode)保存文件的元信息:
- 包含: 文件字节数, 权限, 时间戳, 链接数, 块指针
- 每一个文件对应一个inode结构, 其中的块指针可以作为块设备的下标, 找到真正保存文件数据的block, 当一个block不足以保存一个文件时, Inode就会通过多级块指针来保存block号码
- Inode的典型结构如下
![]()
- 内核用超级块(super_block)来表示文件系统, 每种文件系统都有一个, 超级块保存了下面两种信息
- 文件系统的关键信息, 比如块长度, 最大文件长度
- 读,写,操作inode的方法
- inode记录了文件信息, 超级块则记录了怎么使用inode获取文件的数据, 至此已经可以完成对文件的读写. 但是我们还差了一个抽象: 缓存. 如果每一次读文件的写入都直接传递到块设备中, 那么效率会很低, 因此linux又把文件抽象出地址空间(address_space)
- 在打开一个文件时, 地址空间在内存中申请多个页缓存, 并使用基数树来组织这些页以加快查找速度, 然后把文件中的相关数据读入到内存页中从而建立起一个完善的缓存. 在必要的时候也会进行文件的回写操作. 除此之外地址空间还提供了一系列的标准操作方法, 把文件抽象成一个一维数组, 方便操作.
- 例子:
- 假设现在有两个文件系统Ext2 Ext3, 那么内核中就会有两个超级块
- 假设Ext2中有两个文件FileA, FileB, 硬盘上就会有两个对应的Inode, 内核会把Inode读入内存中以加速访问, 这两个Inode都使用Ext2的超级块
- 进程Process打开了三次FileA:
- 那么内核就会创建三个文件对象(struct file), 每个文件对象中都有一个对应的地址空间, 三个文件对象的文件指针是独立的, 也就是说lseek一个打开的文件, 不会影响别人
- 顺便说一下, 描述进程的对象task_struct中有一个数组files, 里面保存在此进程所有打开的文件对象, 暴露给用户的文件描述符fd就是files数组的下标
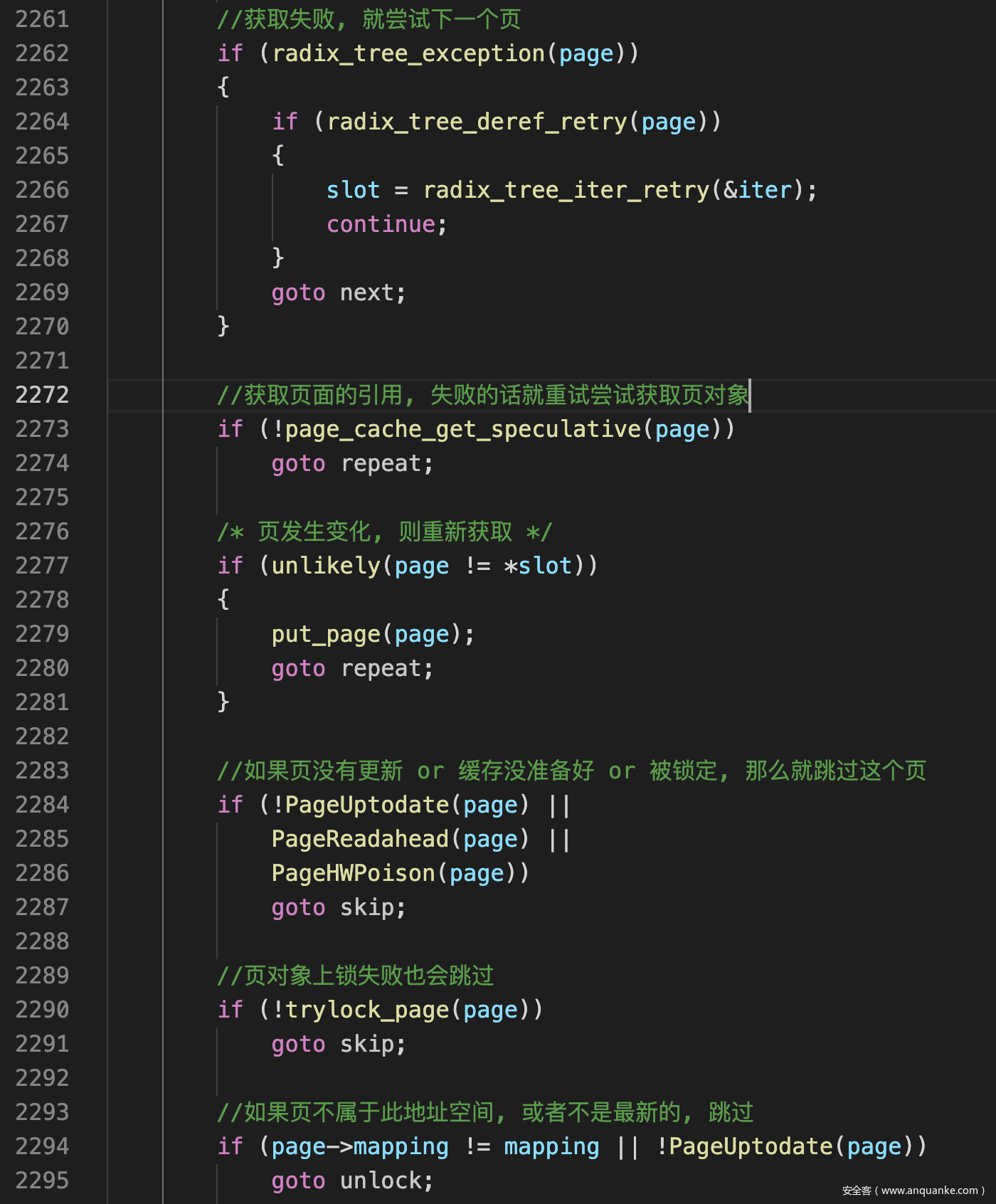
- 理解了地址空间后, filemap_map_pages()的任务就明确了: 打开文件时地址空间已经把部分文件内存从硬盘中缓存找内存中, filemap_map_pages()则只需要搜索地址空间的缓存, 找到内存页, 然后把缓存页链接入页表中
- filemap_map_pages首先从vmf->pgoff开始, 通过地址空间的基数树搜索对应的缓存页
![]()
![]()
- 最后把获取到的缓存页写入页表对应的PTE中, 建立起虚拟地址到物理页框的映射
![]()
- 我们需要明确一点, filemap_map_pages()只是一种利用缓存的优化, 不保证所有的页都能成功映射, 对于映射失败的页当MMU访问到时又会进入缺页异常的处理中.
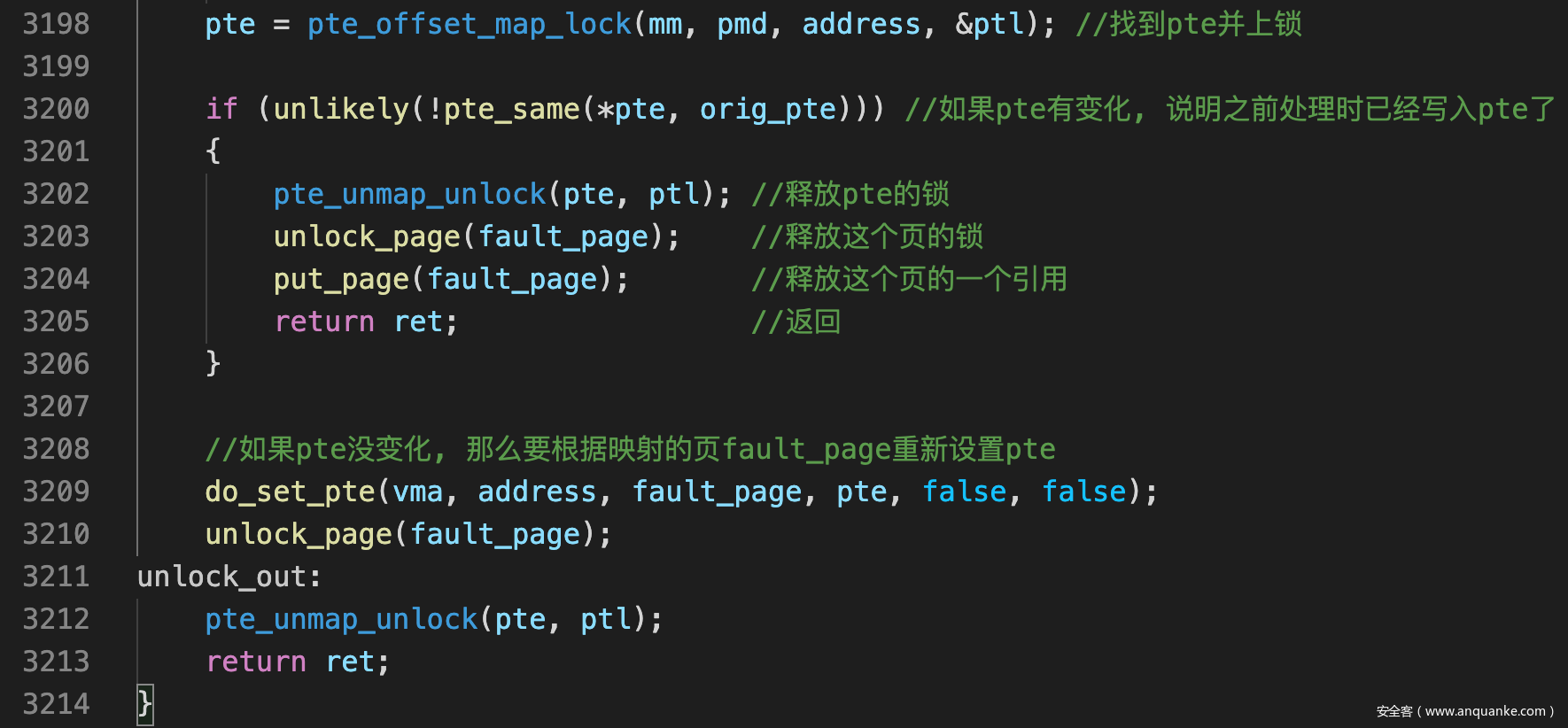
- 回顾下do_read_fault()
![]()
- do_fault_around()结束后返回到do_read_fault()中, 如果do_read_fault()发现引起缺页的pte处理成功, 则其任务完成, 否则就只能调用do_fault()来单独处理此pte, do_fault()才是更加传统与通用的处理
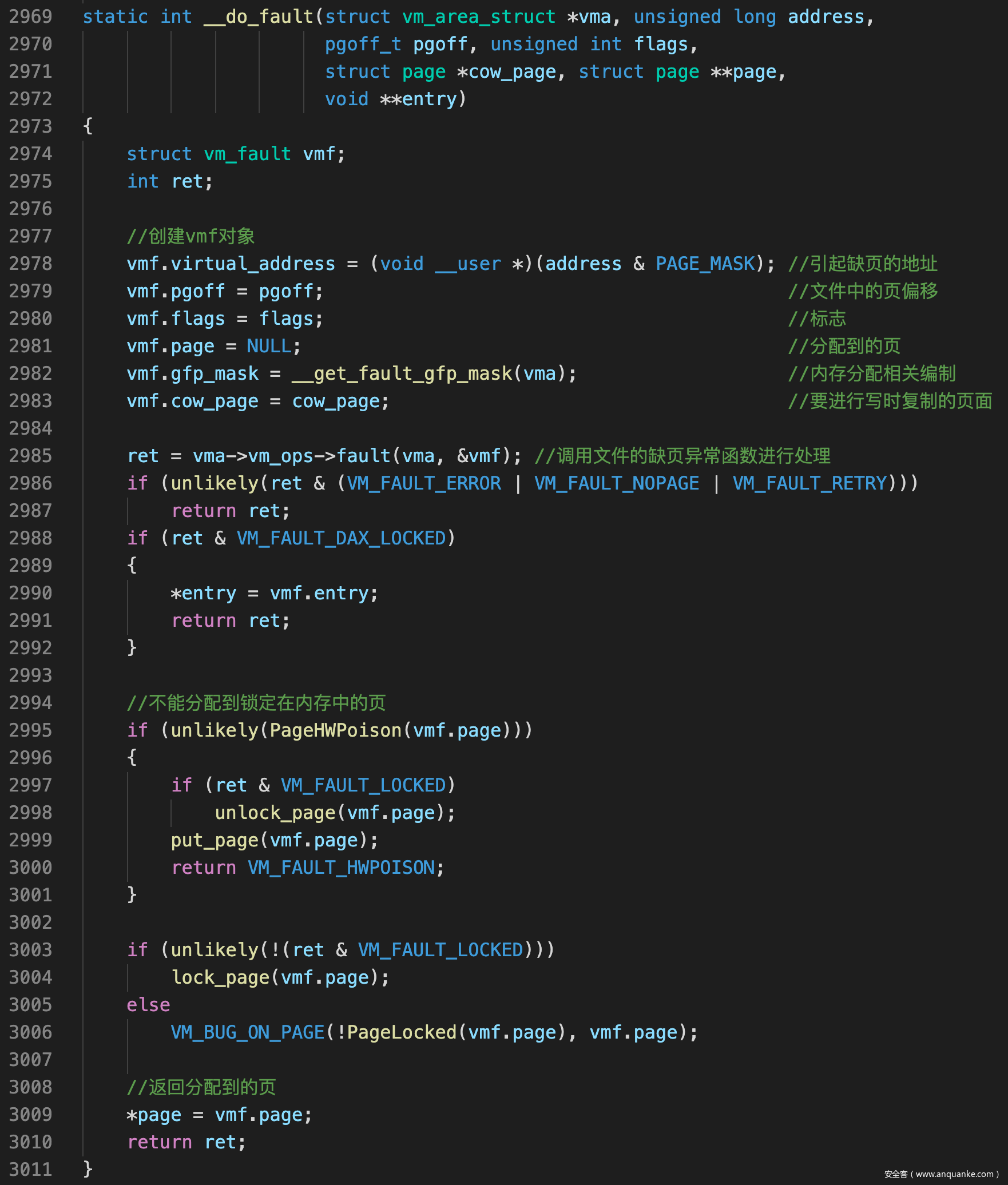
__do_fault()
- __do_fault()的任务有三部分
- 创建vmf的对象, 用于传递参数
- 调用vm_ops->fault()函数处理缺页异常, 这个函数由具体的文件对象设置
- 处理返回值, 设置page指针, 返回到do_read_fault()之后由do_read_fault()设置页表对应的PTE
![]()
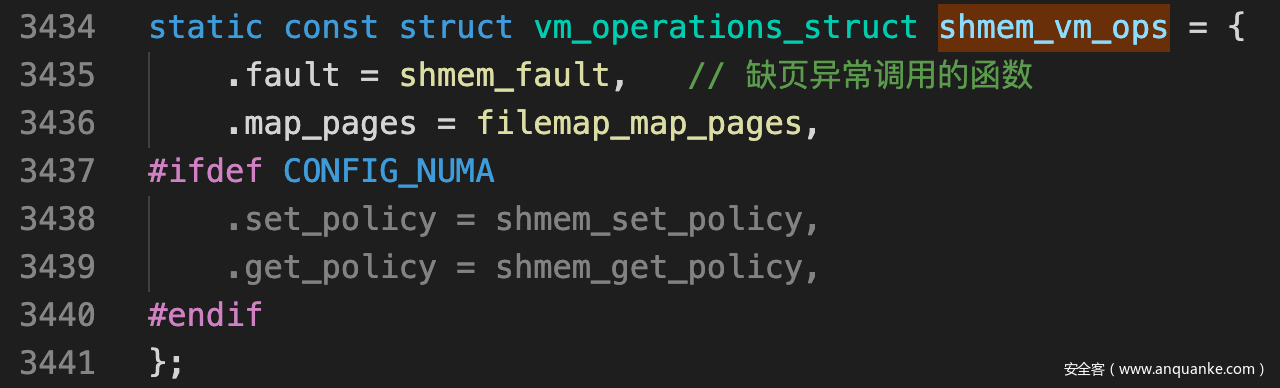
- 在mmap建立VMA对象时, vm_ops->fault对应与shmem_fault()函数
![]()
shmem_fault()
![]()
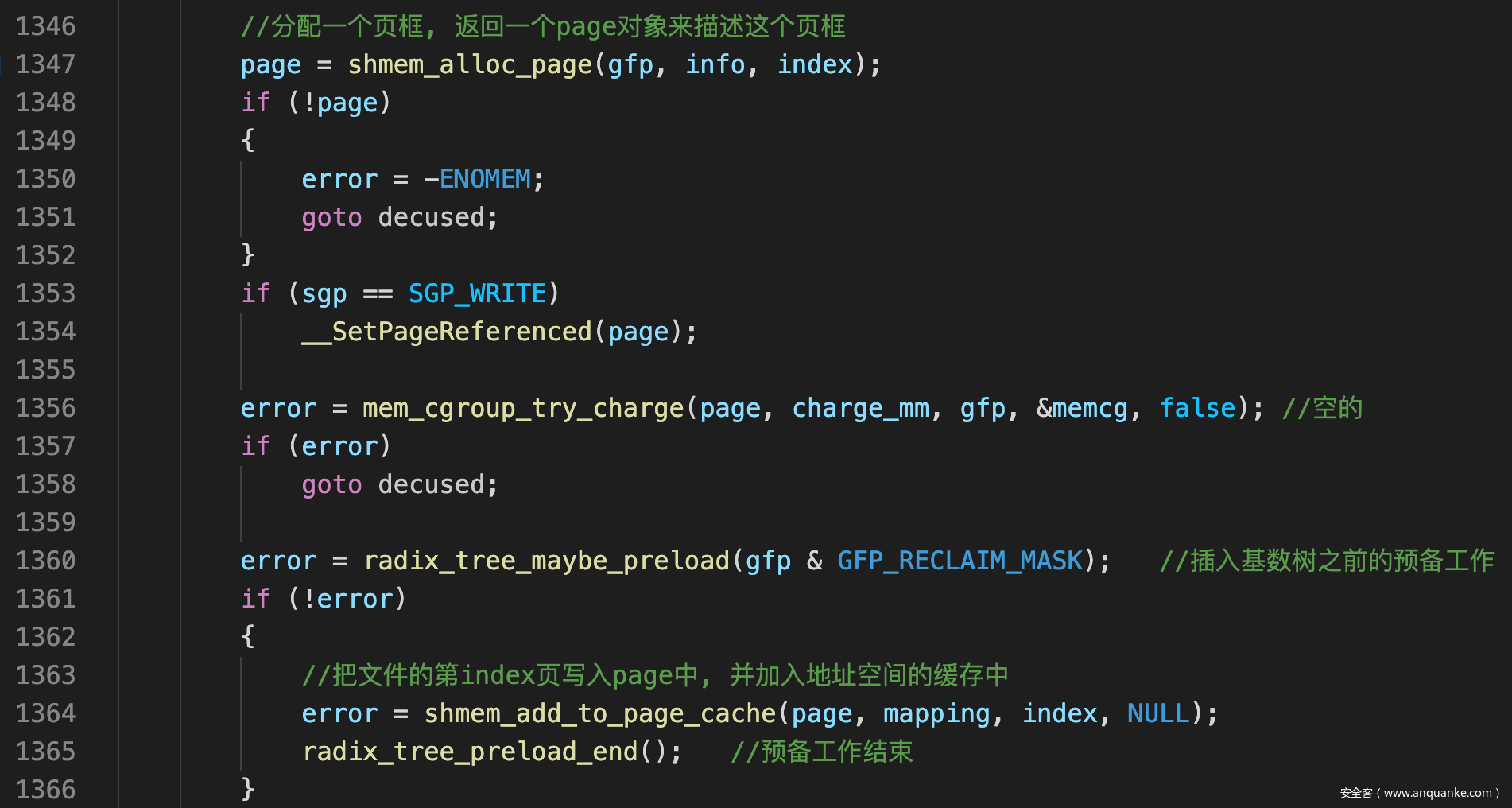
- 然后调用shmem_getpage_gfp()进行页分配工作
![]()
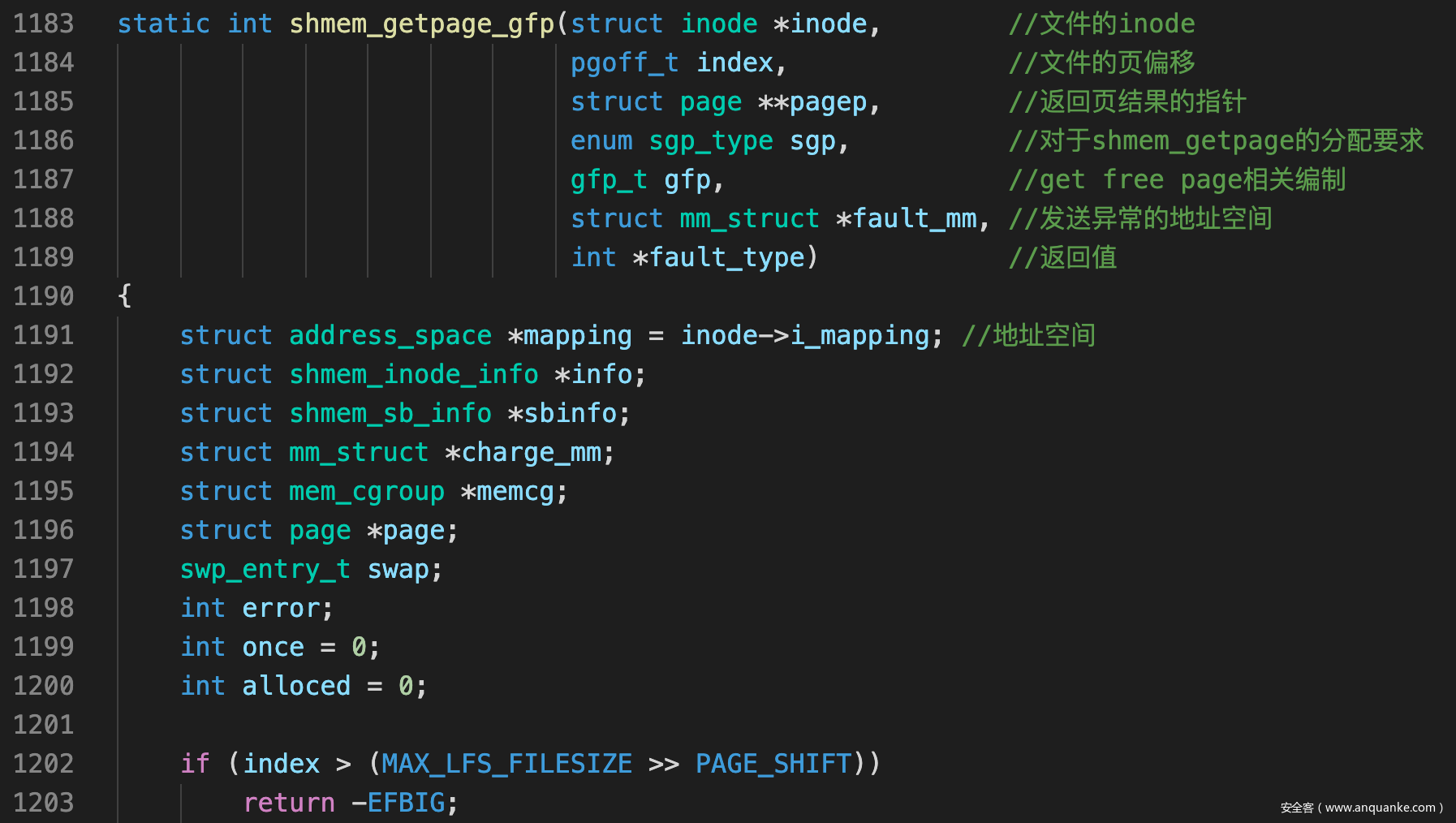
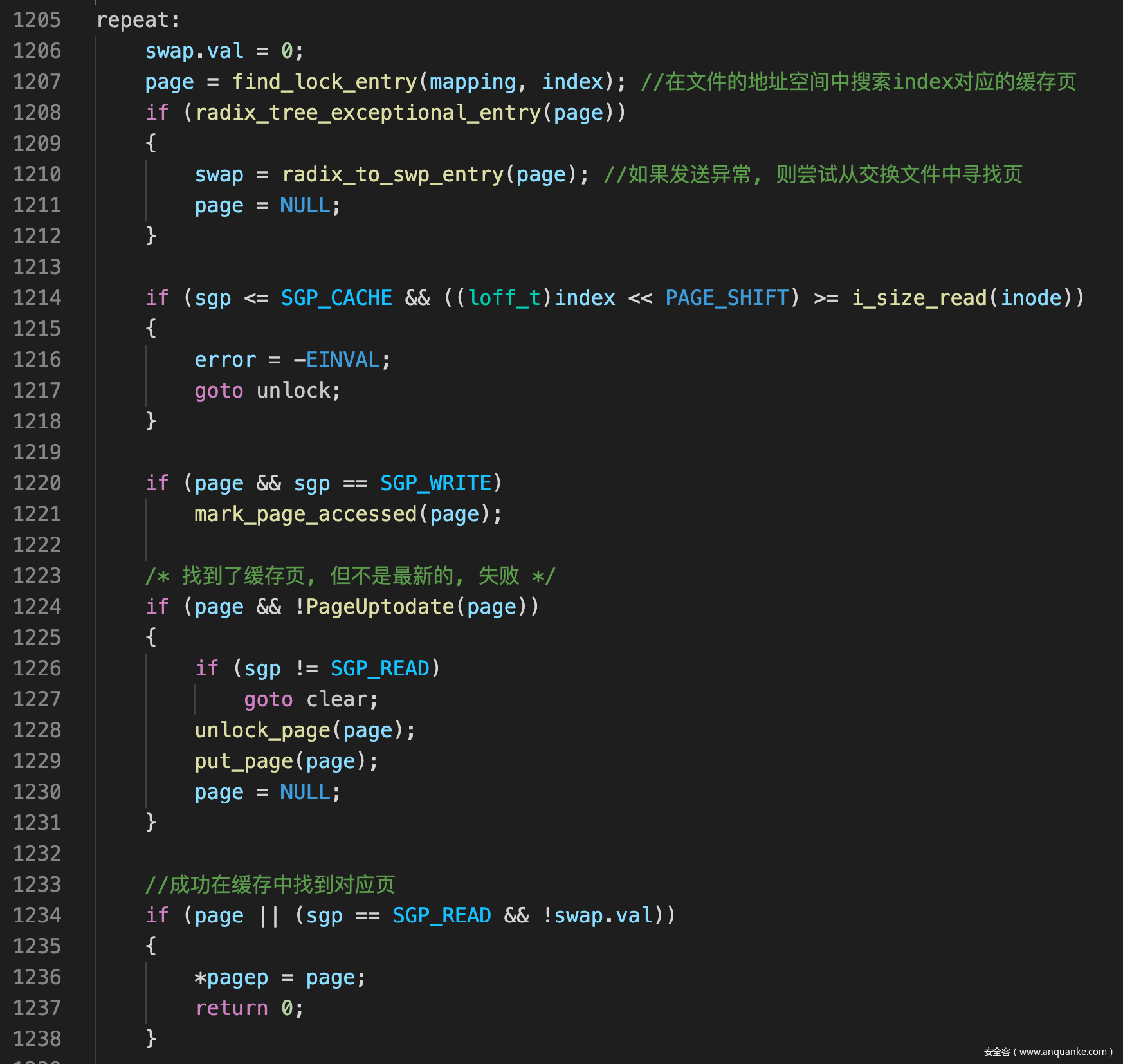
shmem_getpage_gfp()
![]()
![]()
- 没找到的话会尝试从交换文件中寻找对应页, 这部分我们不关心, 如果交换文件中没有的话就会新分配一个页框, 然后在地址空间中建立缓存, 完成映射工作
![]()
- 至此我们可以发现mmap机制依赖于地址空间, 本质上, 地址空间把文件映射到内存, 但是这个映射一个打开的文件只有一份, 是面向内核的, mmap借助此机制把文件映射到用户进程的内存中
写时复制COW
- 之前我们在分配器函数handle_pte_fault()中说过, 如果需要进行写时复制则会进入do_wp_page()函数, 这是一个很重要的机制, 有必要说一下
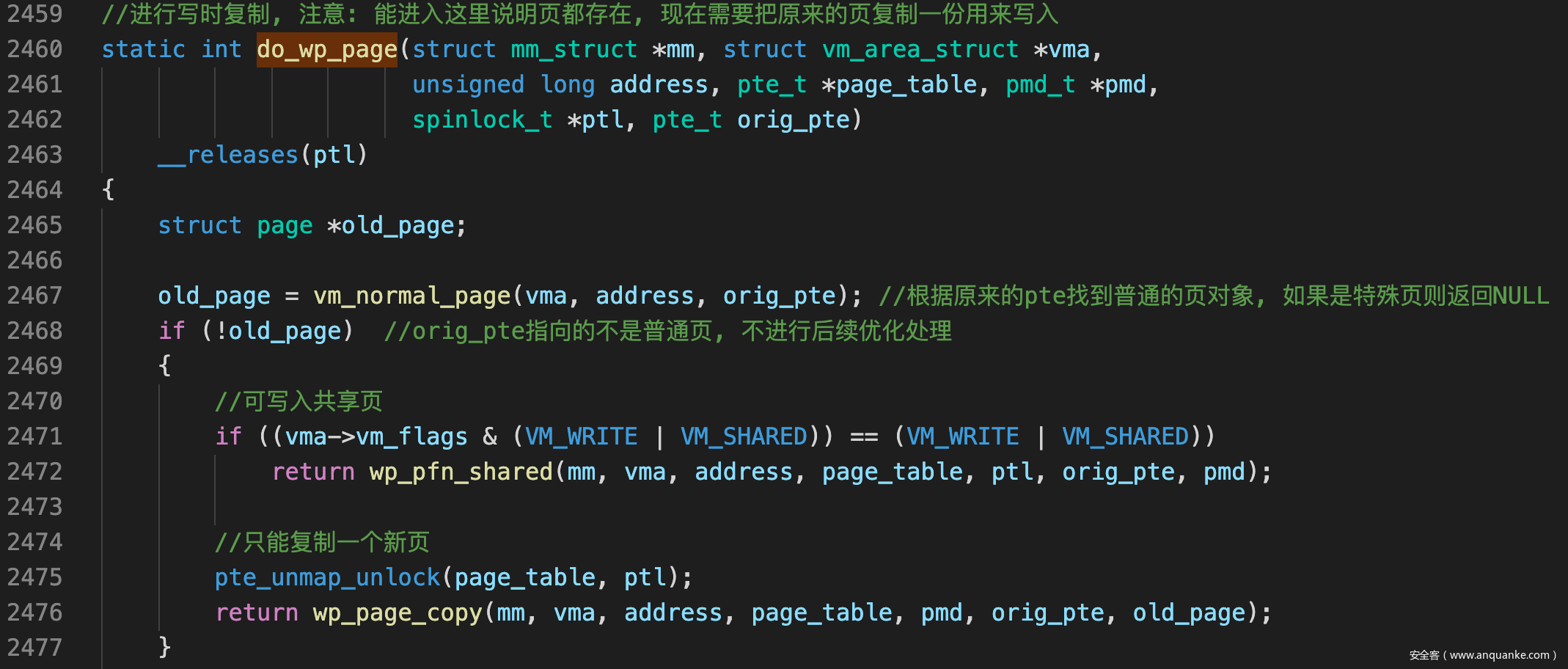
do_wp_page()
- do_wp_page首先根据pte找到其指向的页, 并判断是否为普通页, 如果不是则不进行后续优化, 分派到两种处理函数中. 根据pte找到页对象的原理如下:
- 内核把整个物理内存视为一维的页数组, 每一个页通过一个页对象(struct page)来描述, 这样就得到了一个页对象组成的一维数组(struct page mem_map[] ), 该数组中的元素与物理内存中的页框一一对应
- pte中包含页框的物理地址, 稍加转换就可以变成mem_map中的索引, 从而找到描述这个页框的页的对象
![]()
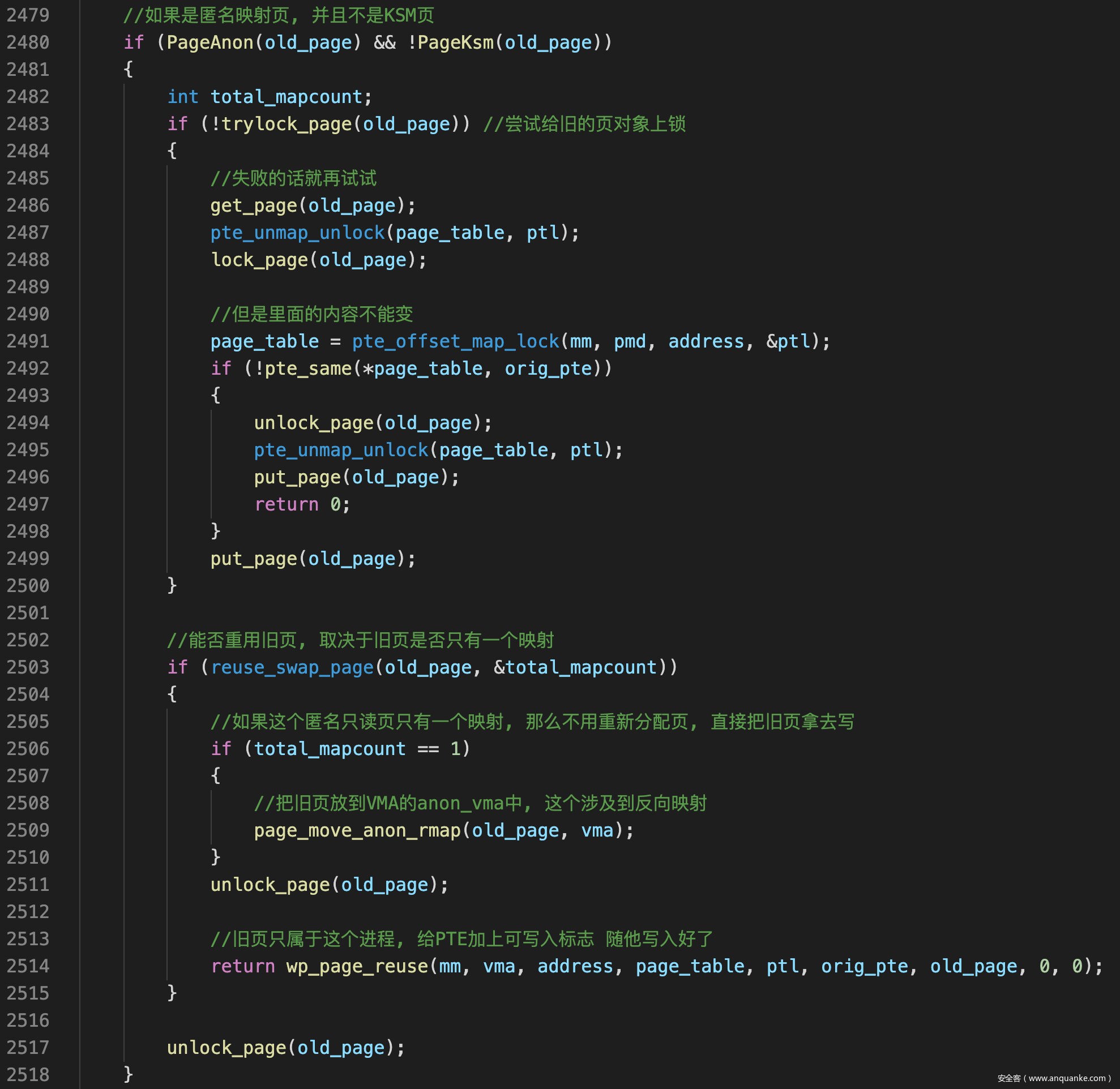
- 对于普通的匿名页, 如果只有自己这个进程映射到他的话, 想写入就写入好了, 反正是只有自己拥有他
![]()
- 如果是可写入的共享页, 就要调用wp_page_shared()处理, 这个函数干的事情只有两件
- 如果映射到文件并且设置了vm_ops->page_mkwrite()的话就调用这个方法
- 设置pte的写入标志, 让多个进程读写同一个页面以达到共享效果, 至于怎么同步就是共享他的进程的事情了
![]()
- 排除掉各种特殊情况与可优化情况后, 回归最本质的操作: 调用wp_page_copy()复制一个页
![]()
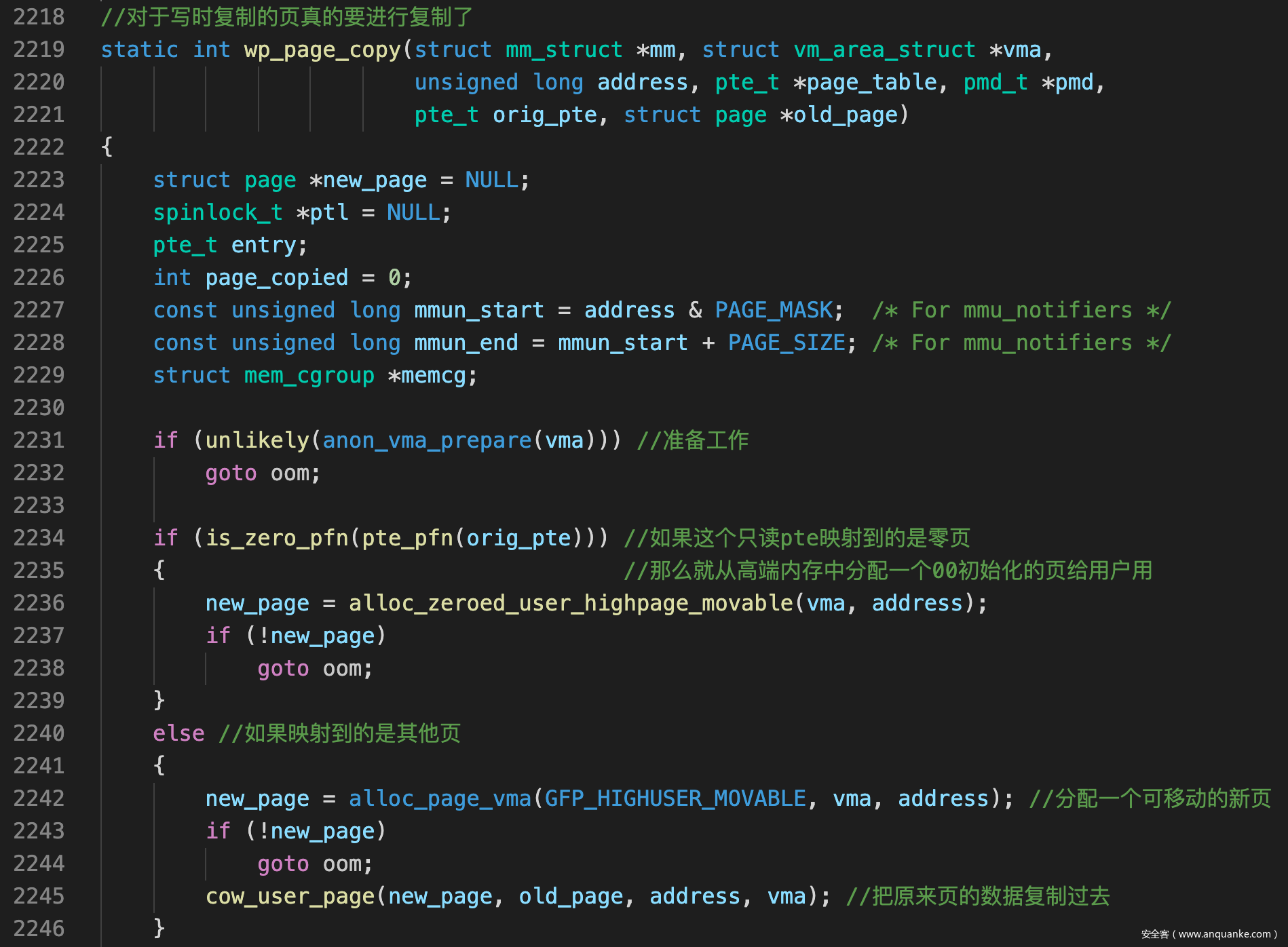
wp_page_copy()
- 这里需要说一下零页的优化:
- 由于00初始化是最常见的, 因此内核建立了一个只读的用00填充的物理页, 称之为零页
- 所有进程的匿名映射页在写入之前都会映射到零页中, 这样既可以进行00初始化又可以减少页框的分配
- 当尝试写入这样的匿名页时, 由于零页只读, 因此会进入COW部分, 才真正分配页框
- pte_pfn()用于从pte中获取页框号(page frame number), is_zero_pfn()用于判断是不是零页的页框号
- wp_page_copy()考虑两种情况
- 如果发现原来映射到的是零页, 就会分配一个00初始化页面
- 否则, 先分配一个页框, 然后把原来页的内存复制过去
![]()
- 新页复制后以后创建新的pte, 构建新的映射, 结束COW处理
![]()
(完)