
前言
这里根据红日安全PHP-Audit-Labs对一些函数缺陷的分析,从PHP内核层面来分析一些函数的可利用的地方,标题所说的函数缺陷并不一定是函数本身的缺陷,也可能是函数在使用过程中存在某些问题,造成了漏洞,以下是对部分函数的分析
[+]in_array/array_search函数缺陷
下面请看代码
<?php
$whiteList = range(1,24);
//$id = 233;
//$id = '1';
$id = "1' or '1'='1";
if(!in_array($id,$whiteList)){
die("only 1 to 24");
}else{
$query = "select * from user where id = '". $id . "';";
echo $query;
}
三个$id分别对应die、输出语句、输出语句,这就是因为in_array函数的第三个参数导致的,先贴出函数原型:
in_array :(PHP 4, PHP 5, PHP 7)
功能 :检查数组中是否存在某个值
定义 : bool in_array ( mixed $needle , array $haystack [, bool $strict = FALSE ] )
在 $haystack 中搜索 $needle ,如果第三个参数 $strict 的值为 TRUE ,则 in_array() 函数会进行强检查,检查 $needle 的类型是否和 $haystack 中的相同。如果找到 $haystack ,则返回 TRUE,否则返回 FALSE。
通过$id='1'也可以很明显的知道,在这里之所以能通过in_array肯定是仅是进行了弱类型的比较,因为此处$whiteList的键值的int型,如果进行强比较是无法通过的,下面对该函数进行分析:
ext/standard/array.c
/* {{{ proto bool in_array(mixed needle, array haystack [, bool strict])
Checks if the given value exists in the array */
PHP_FUNCTION(in_array)
{
php_search_array(INTERNAL_FUNCTION_PARAM_PASSTHRU, 0);
}
/* }}} */
/* {{{ proto mixed array_search(mixed needle, array haystack [, bool strict])
Searches the array for a given value and returns the corresponding key if successful */
PHP_FUNCTION(array_search)
{
php_search_array(INTERNAL_FUNCTION_PARAM_PASSTHRU, 1);
}
/* }}} */
其实可以发现array_search和in_array的内部实现一样,跟进:
/* void php_search_array(INTERNAL_FUNCTION_PARAMETERS, int behavior)
* 0 = return boolean
* 1 = return key
*/
static inline void php_search_array(INTERNAL_FUNCTION_PARAMETERS, int behavior) /* {{{ */
{
zval *value, /* value to check for */
*array, /* array to check in */
*entry; /* pointer to array entry */
zend_ulong num_idx;
zend_string *str_idx;
zend_bool strict = 0; /* strict comparison or not */
/*参数定义,需要2-3个参数,前两个参数是必须的,后面参数是可选的,而可选参数默认是0*/
ZEND_PARSE_PARAMETERS_START(2, 3)
Z_PARAM_ZVAL(value)
Z_PARAM_ARRAY(array)
Z_PARAM_OPTIONAL
Z_PARAM_BOOL(strict)
ZEND_PARSE_PARAMETERS_END();
if (strict) {
...
} else {
if (Z_TYPE_P(value) == IS_LONG) {
// ZEND_HASH_FOREACH_KEY_VAL(hashtable, 数值索引, 字符串索引, 值)
ZEND_HASH_FOREACH_KEY_VAL_IND(Z_ARRVAL_P(array), num_idx, str_idx, entry) {
if (fast_equal_check_long(value, entry)) {
if (behavior == 0) {
RETURN_TRUE;
} else {
if (str_idx) {
RETVAL_STR_COPY(str_idx);
} else {
RETVAL_LONG(num_idx);
}
return;
}
}
} ZEND_HASH_FOREACH_END();
} else if (Z_TYPE_P(value) == IS_STRING) {
ZEND_HASH_FOREACH_KEY_VAL_IND(Z_ARRVAL_P(array), num_idx, str_idx, entry) {
if (fast_equal_check_string(value, entry)) {
if (behavior == 0) {
RETURN_TRUE;
} else {
if (str_idx) {
RETVAL_STR_COPY(str_idx);
} else {
RETVAL_LONG(num_idx);
}
return;
}
}
} ZEND_HASH_FOREACH_END();
} else {
ZEND_HASH_FOREACH_KEY_VAL_IND(Z_ARRVAL_P(array), num_idx, str_idx, entry) {
if (fast_equal_check_function(value, entry)) {
if (behavior == 0) {
RETURN_TRUE;
} else {
if (str_idx) {
RETVAL_STR_COPY(str_idx);
} else {
RETVAL_LONG(num_idx);
}
return;
}
}
} ZEND_HASH_FOREACH_END();
}
}
RETURN_FALSE;
}
由于使用默认strict,因此这里进行省略,默认可选参数下会进入后面的else分支,当我们传入的value是字符型时进入else if (Z_TYPE_P(value) == IS_STRING) {中,这里先获得数组的值,然后进入关键函数fast_equal_check_string中,可以看到当是默认strict时都是用该函数进行判断,跟进:
static zend_always_inline int fast_equal_check_string(zval *op1, zval *op2)
{
zval result;
if (EXPECTED(Z_TYPE_P(op2) == IS_STRING)) {
return zend_fast_equal_strings(Z_STR_P(op1), Z_STR_P(op2));
}
// 参数1:执行结果
// 参数2: php输入的查找项: '1'
// 参数3: php数组当前项
compare_function(&result, op1, op2);
return Z_LVAL(result) == 0;
}
这里先了解一下PHP源码所定义的8中数据类型:

这里op2是整形,因此会直接使用compare_function进行比较,该函数实在太长,主要是现根据两个参数的数据类型来进行逻辑处理,这里op1 = IS_STRING,op2 = IS_LONG,但是IS_LONG跟IS_STRING的情况不存在,就进入转换类型的分支,所以这里直接将对应的处理部分贴下:
// Zend/zend_types.h源码定义了如下,这里在比较时用得上,因此一起列出
#define IS_UNDEF 0
#define IS_NULL 1
#define IS_FALSE 2
#define IS_TRUE 3
#define IS_LONG 4 // op2
#define IS_DOUBLE 5
#define IS_STRING 6 // op1
#define IS_ARRAY 7
#define IS_OBJECT 8
#define IS_RESOURCE 9
#define IS_REFERENCE 10
ZEND_API int ZEND_FASTCALL compare_function(zval *result, zval *op1, zval *op2) /* {{{ */
{
int ret;
int converted = 0; //注意是0
zval op1_copy, op2_copy;
zval *op_free, tmp_free;
if (!converted) {
if (Z_TYPE_P(op1) < IS_TRUE) {
ZVAL_LONG(result, zval_is_true(op2) ? -1 : 0);
return SUCCESS;
} else if (Z_TYPE_P(op1) == IS_TRUE) {
ZVAL_LONG(result, zval_is_true(op2) ? 0 : 1);
return SUCCESS;
} else if (Z_TYPE_P(op2) < IS_TRUE) {
ZVAL_LONG(result, zval_is_true(op1) ? 1 : 0);
return SUCCESS;
} else if (Z_TYPE_P(op2) == IS_TRUE) {
ZVAL_LONG(result, zval_is_true(op1) ? 0 : -1);
return SUCCESS;
} else {
//前面都没有匹配成功,直接到该else分支
op1 = zendi_convert_scalar_to_number(op1, &op1_copy, result, 1);
op2 = zendi_convert_scalar_to_number(op2, &op2_copy, result, 1);
if (EG(exception)) {
if (result != op1) {
ZVAL_UNDEF(result);
}
return FAILURE;
}
converted = 1;
}
if(!converted)判断了左右操作数还没有转换为number时候的处理,接着调用zendi_convert_scalar_to_number直接将其转换为number.因此这部分代码当操作数不是数字数据类型时,它们将被转换为数字,然后使得转换标志converted = 1,不妨跟踪下这个宏函数:
#define zendi_convert_scalar_to_number(op, holder, result, silent) \
((Z_TYPE_P(op) == IS_LONG || Z_TYPE_P(op) == IS_DOUBLE) ? (op) : \
(((op) == result) ? (_convert_scalar_to_number((op), silent, 1), (op)) : \
(silent ? _zendi_convert_scalar_to_number((op), holder) : \
_zendi_convert_scalar_to_number_noisy((op), holder))))
这里op2是IS_LONG,因此不做处理保留,而op1是字符串,所以_zendi_convert_scalar_to_number_noisy,这里放出最后的处理:
static zend_always_inline zval* _zendi_convert_scalar_to_number_ex(zval *op, zval *holder, zend_bool silent) /* {{{ */
{
switch (Z_TYPE_P(op)) {
case IS_NULL:
case IS_FALSE:
ZVAL_LONG(holder, 0);
return holder;
case IS_TRUE:
ZVAL_LONG(holder, 1);
return holder;
case IS_STRING:
if ((Z_TYPE_INFO_P(holder) = is_numeric_string(Z_STRVAL_P(op), Z_STRLEN_P(op), &Z_LVAL_P(holder), &Z_DVAL_P(holder), silent ? 1 : -1)) == 0) {
ZVAL_LONG(holder, 0);
if (!silent) {
zend_error(E_WARNING, "A non-numeric value encountered");
}
}
return holder;
case IS_RESOURCE:
ZVAL_LONG(holder, Z_RES_HANDLE_P(op));
return holder;
case IS_OBJECT:
convert_object_to_type(op, holder, _IS_NUMBER, convert_scalar_to_number);
if (UNEXPECTED(EG(exception)) ||
UNEXPECTED(Z_TYPE_P(holder) != IS_LONG && Z_TYPE_P(holder) != IS_DOUBLE)) {
ZVAL_LONG(holder, 1);
}
return holder;
case IS_LONG:
case IS_DOUBLE:
default:
return op;
}
}
这里终于涉及到op=IS_STRING的处理,可以看到会调用is_numeric_string,并且在调用该函数时silent=0,因此调用is_numeric_string传入的最后一个参数是-1,也就是dval
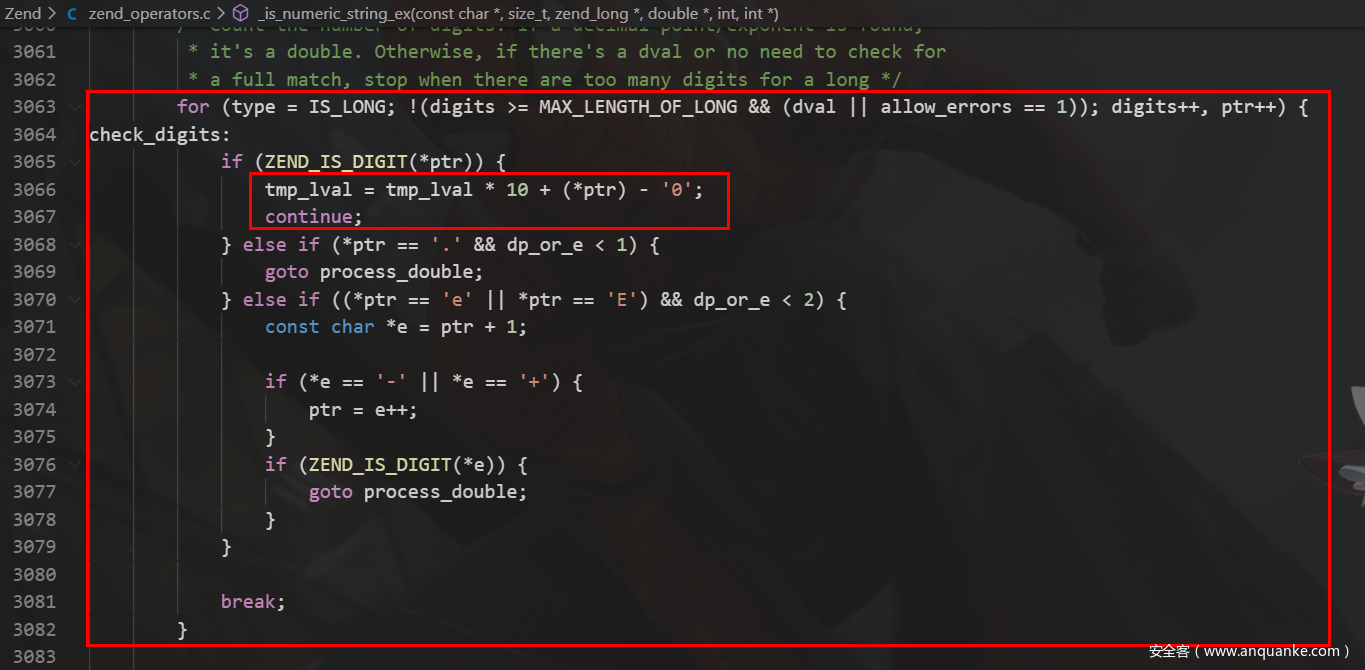
这里就是字符转数字的关键步骤了,将字符串字符一个一个的处理,如果当前字符是数字就进行tmp_lval*10 + (*ptr) - '0'运算,直到遇到第一个不是数字的字符,并且最终会return 0
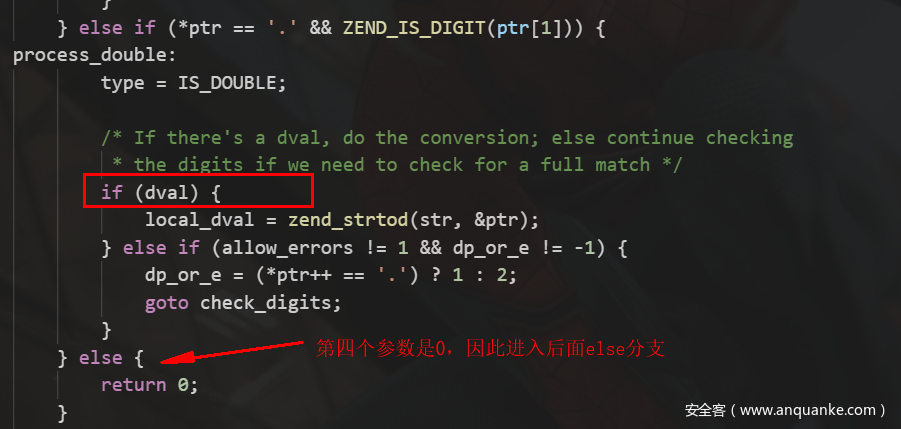
回到if ((Z_TYPE_INFO_P(holder) = is_numeric_string(Z_STRVAL_P(op), Z_STRLEN_P(op), &Z_LVAL_P(holder), &Z_DVAL_P(holder), silent ? 1 : -1)) == 0)因此Z_TYPE_INFO_P(holder) = 1再通过ZVAL_LONG(holder,0)将其赋值为0后,又赋值给result,因此回到快检测函数:
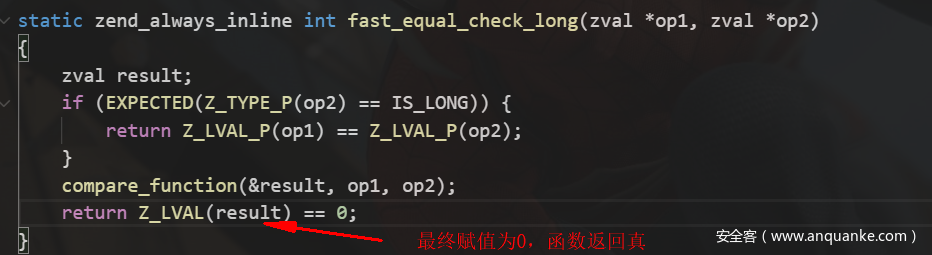
整个流程分析完成,也就是in_array()如果第三个参数为0或者默认时,仅是对数组中的值和查询的值进行一个弱类型比较
前文也看到array_search和in_array在底层实现一样,因此array_search也存在该缺陷:
<?php
$arr = array("true" => 1);
var_dump(array_search('1Crispr',$arr));
//Output: string(4) "true"
[+]filter_var/parse_url函数缺陷
<?php
function is_valid_url($url){
if(filter_var($url,FILTER_VALIDATE_URL)){
if (preg_match('/data:\/\//i', $url)) {
return false;
}
return true;
}
return false;
}
//$url = "data://baidu.com/plain;base64,d2hvYW1p";
if(is_valid_url($url)){
$r = parse_url($url);
if(preg_match('/baidu\.com$/',$r['host'])){
$code = file_get_contents($url);
echo $code;
}
}
上面这个例子中可以知道,如果没有对data协议进行过滤,我们可以使用data协议来进行绕过,无论怎么绕过,第一层绕过的始终是filter_var($url,FILTER_VALIDATE_URL)对这个函数进行分析,先将其函数原型贴出:
filter_var : (PHP 5 >= 5.2.0, PHP 7)
功能 :使用特定的过滤器过滤一个变量
定义 :mixed filter_var ( mixed $variable [, int $filter = FILTER_DEFAULT [, mixed $options ]] )
FILTER_VALIDATE_URL是一种过滤器,用来判断是否是一个合法的url,不过该判断是一个非常弱的判断,可以从下面的例子中发现:
<?php
//$url = "javascript://123";
//$url = "data://123";
//$url = "ftp://";
//$url = "php://123"
//$url = "compress.zlib://data:123";
//$url = "xx://xxx";
$url = "xx://xx;google.com";
var_dump(filter_var($url,FILTER_VALIDATE_URL));
这些都能够通过filter_var,既然如此看似不合法的url都能通过,这里还是从源码进行分析:
PHP_FUNCTION(filter_var)
{
zend_long filter = FILTER_DEFAULT;
zval *filter_args = NULL, *data;
if (zend_parse_parameters(ZEND_NUM_ARGS(), "z|lz", &data, &filter, &filter_args) == FAILURE) {
return;
}
if (!PHP_FILTER_ID_EXISTS(filter)) {
RETURN_FALSE;
}
ZVAL_DUP(return_value, data);
php_filter_call(return_value, filter, filter_args, 1, FILTER_REQUIRE_SCALAR);
}
前面是对参数进行处理,这里直接看到php_filter_call,其调用情况:
static void php_filter_call(zval *filtered, zend_long filter, zval *filter_args, const int copy, zend_long filter_flags) /* {{{ */
{ ...
php_zval_filter(filtered, filter, filter_flags, options, charset, copy);
...
}
static void php_zval_filter(zval *value, zend_long filter, zend_long flags, zval *options, char* charset, zend_bool copy) /* {{{ */
{
filter_list_entry filter_func;
filter_func = php_find_filter(filter);
if (!filter_func.id) {
/* Find default filter */
filter_func = php_find_filter(FILTER_DEFAULT);
}
/* #49274, fatal error with object without a toString method
Fails nicely instead of getting a recovarable fatal error. */
if (Z_TYPE_P(value) == IS_OBJECT) {
zend_class_entry *ce;
ce = Z_OBJCE_P(value);
if (!ce->__tostring) {
zval_ptr_dtor(value);
/* #67167: doesn't return null on failure for objects */
if (flags & FILTER_NULL_ON_FAILURE) {
ZVAL_NULL(value);
} else {
ZVAL_FALSE(value);
}
goto handle_default;
}
}
/* Here be strings */
convert_to_string(value);
filter_func.function(value, flags, options, charset);
handle_default:
if (options && Z_TYPE_P(options) == IS_ARRAY &&
((flags & FILTER_NULL_ON_FAILURE && Z_TYPE_P(value) == IS_NULL) ||
(!(flags & FILTER_NULL_ON_FAILURE) && Z_TYPE_P(value) == IS_FALSE))) {
zval *tmp;
if ((tmp = zend_hash_str_find(Z_ARRVAL_P(options), "default", sizeof("default") - 1)) != NULL) {
ZVAL_COPY(value, tmp);
}
}
}
/* }}} */
根据filter来寻找过滤的函数,将value转化成字符串后调用寻找到的过滤函数来进行处理,URL过滤器对应的函数:
//ext/filter/logical_filters.c
void php_filter_validate_url(PHP_INPUT_FILTER_PARAM_DECL) /* {{{ */
{
php_url *url;
size_t old_len = Z_STRLEN_P(value);
...
/* Use parse_url - if it returns false, we return NULL */
url = php_url_parse_ex(Z_STRVAL_P(value), Z_STRLEN_P(value));
if (url == NULL) {
RETURN_VALIDATION_FAILED
}
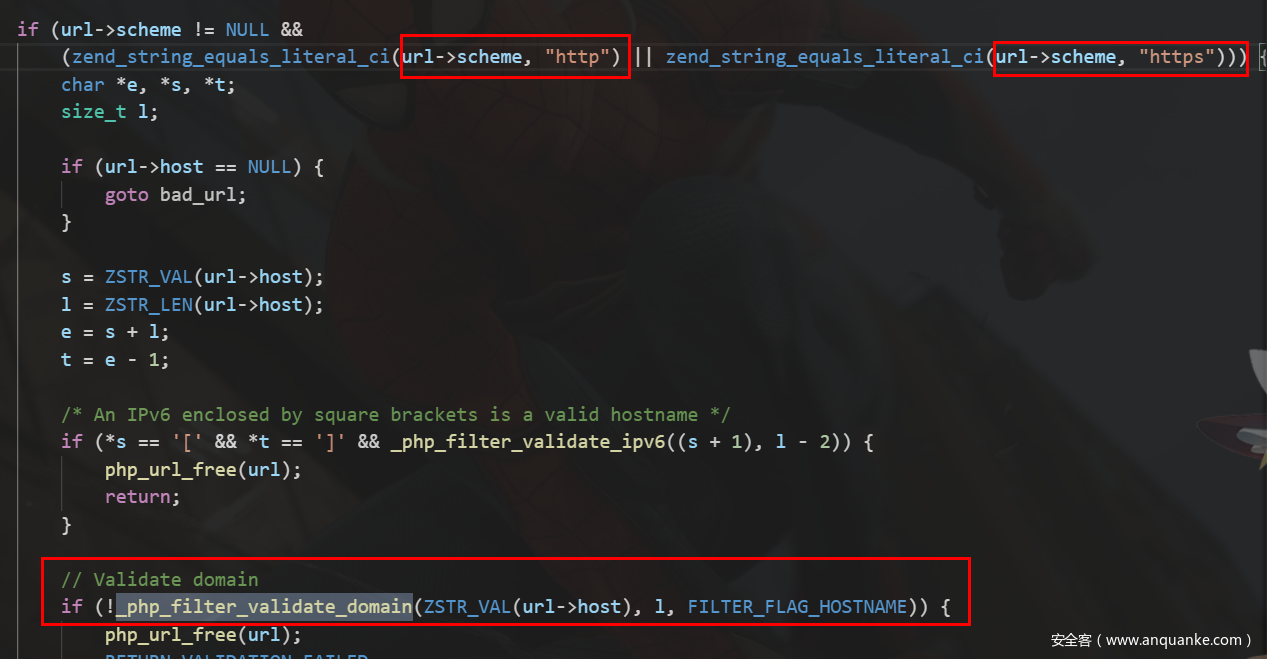
if (url->scheme != NULL &&
(zend_string_equals_literal_ci(url->scheme, "http") || zend_string_equals_literal_ci(url->scheme, "https"))) {
char *e, *s, *t;
size_t l;
if (url->host == NULL) {
goto bad_url;
}
s = ZSTR_VAL(url->host);
l = ZSTR_LEN(url->host);
e = s + l;
t = e - 1;
/* An IPv6 enclosed by square brackets is a valid hostname */
if (*s == '[' && *t == ']' && _php_filter_validate_ipv6((s + 1), l - 2)) {
php_url_free(url);
return;
}
// Validate domain
if (!_php_filter_validate_domain(ZSTR_VAL(url->host), l, FILTER_FLAG_HOSTNAME)) {
php_url_free(url);
RETURN_VALIDATION_FAILED
}
}
if (
url->scheme == NULL ||
/* some schemas allow the host to be empty */
(url->host == NULL && (strcmp(ZSTR_VAL(url->scheme), "mailto") && strcmp(ZSTR_VAL(url->scheme), "news") && strcmp(ZSTR_VAL(url->scheme), "file"))) ||
((flags & FILTER_FLAG_PATH_REQUIRED) && url->path == NULL) || ((flags & FILTER_FLAG_QUERY_REQUIRED) && url->query == NULL)
) {
bad_url:
php_url_free(url);
RETURN_VALIDATION_FAILED
}
php_url_free(url);
}
这里还对Ipv6地址进行了判断,以及后面对域名的判断,我们重点还是看php_url_parse_ex函数:
if ((e = memchr(s, ':', length)) && e != s) {
/* validate scheme */
p = s;
while (p < e) {
/* scheme = 1*[ lowalpha | digit | "+" | "-" | "." ] */
if (!isalpha(*p) && !isdigit(*p) && *p != '+' && *p != '.' && *p != '-') {
if (e + 1 < ue && e < s + strcspn(s, "?#")) {
goto parse_port;
} else if (s + 1 < ue && *s == '/' && *(s + 1) == '/') { /* relative-scheme URL */
s += 2;
e = 0;
goto parse_host;
} else {
goto just_path;
}
}
p++;
}
if (e + 1 == ue) { /* only scheme is available */
ret->scheme = estrndup(s, (e - s));
php_replace_controlchars_ex(ret->scheme, (e - s));
return ret;
}
/*
* certain schemas like mailto: and zlib: may not have any / after them
* this check ensures we support those.
*/
if (*(e+1) != '/') {
/* check if the data we get is a port this allows us to
* correctly parse things like a.com:80
*/
p = e + 1;
while (p < ue && isdigit(*p)) {
p++;
}
if ((p == ue || *p == '/') && (p - e) < 7) {
goto parse_port;
}
ret->scheme = estrndup(s, (e-s));
php_replace_controlchars_ex(ret->scheme, (e - s));
s = e + 1;
goto just_path;
} else {
ret->scheme = estrndup(s, (e-s));
php_replace_controlchars_ex(ret->scheme, (e - s));
if (e + 2 < ue && *(e + 2) == '/') {
s = e + 3;
if (!strncasecmp("file", ret->scheme, sizeof("file"))) {
if (e + 3 < ue && *(e + 3) == '/') {
/* support windows drive letters as in:
file:///c:/somedir/file.txt
*/
if (e + 5 < ue && *(e + 5) == ':') {
s = e + 4;
}
goto just_path;
}
}
} else {
s = e + 1;
goto just_path;
}
}
} else if (e) { /* no scheme; starts with colon: look for port */
[+]php_url_parse_ex函数
这里直接引用 https://www.cnblogs.com/hf99/p/9637354.html
如果s中含有冒号则e指向冒号,且同时如果冒号不在s的开头,p指向s
当p不指向冒号向循环,p指向下一位
如果p指向的值是字母或者数字或者是+,-,.则指针指向下一位,这就代表冒号前面的值其实是任意的字母、数字、+、-、.
如果冒号所在位置小于str,且?#在冒号后面(如果有的话),就跳转到port解析部分
如果str的长度大于1且str的前两个字符是//,s指向//后面的一个字符,e变为0,跳转到host解析
如果冒号是最后一位字符,则冒号前面的东西会当作scheme返回
如果冒号后面不是/,则p指向冒号后面一位
当p小于str且p指向的为数字字符,p一直指向后一位,直到p指向str末尾或者p指向的字符为/,同时冒号后面的数字位数小于6位,跳转到port解析
如果冒号后面不是纯数字或数字后面有一个/,那么冒号前面的内容就当作scheme,放在ret的scheme参数中,s指向冒号后一位,跳转到path解析
如果冒号后面是/,那么冒号前面的内容就当作scheme,放在ret的scheme参数中。如果下面一位也是/,那么s指向//后面一位,如果scheme为file,那么判断接下来一位是不是/,如果是,判断冒号后是否有五个字符,如果有那么第五个字符是不是冒号(为了处理file:///c:),s指向///后的一位字符,跳转到path解析
如果冒号后面不是三个/,s指向冒号后面一位,之后跳转到path解析
如果冒号在str开头,那么进行port解析
因此只要是该url满足其要求,都能够通过filter_var的url过滤器,所以在这里强调其实一个非常弱的过滤器,其实在parse_url的处理中底层也使用了该函数,不过关于parse_url的函数缺陷,之后在进行分析,因此在此题中如果没有过滤data协议,完全可以使用data协议进行绕过,但是此时由于过滤data://,因此使用的是另外一个协议compress.zlib
该函数对压缩流进行读取
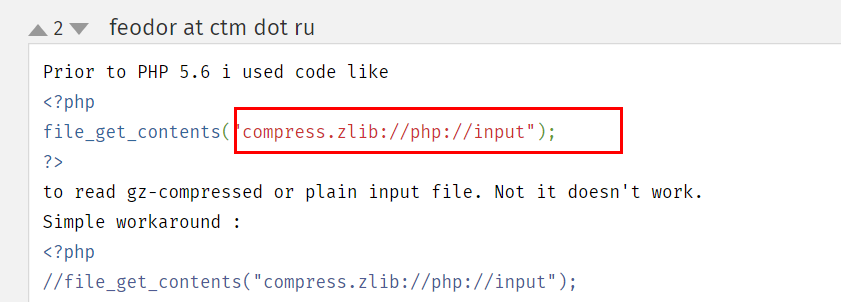
可以在官方示例中看到,能够将流进行读取,因此compress.zlib同样读取能够data协议流,因此我们构造$url = "compress.zlib://data:@baidu.com/;base64,aGVsbG8=";即可进行绕过
根据上述内容也就解释了为什么形如xx://xx;google.com也能通过parse_url,因为在底层处理中,完全没有涉及分号;的对应处理,在解析时也只是将其视为一个简单的字符串,但如果是http或者是https协议则会进行_php_filter_validate_domain处理,导致无法使用该种形式进行绕过
理解libcurl和parse_url解析时的区别
借blackhat上的这张图进行说明:
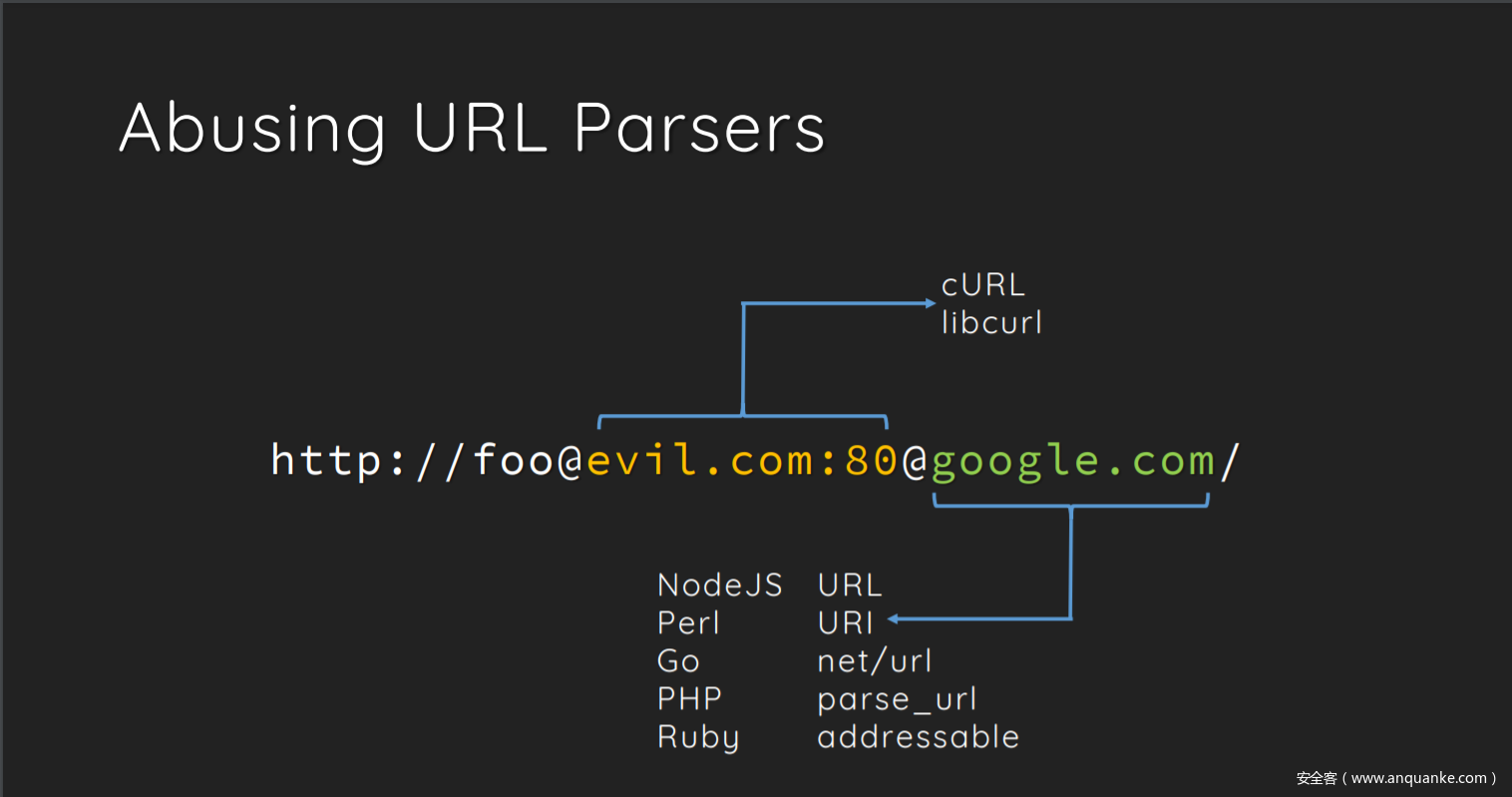
可以看到curl和parse_url对于解析host的相对位置是不同的,在PHP中parse_url倾向于解析较后面,其实在源码中有着相应的答案:
//e是字符串的结尾
/* check for login and password */
if ((p = zend_memrchr(s, '@', (e-s)))) {
if ((pp = memchr(s, ':', (p-s)))) {
ret->user = zend_string_init(s, (pp-s), 0);
php_replace_controlchars_ex(ZSTR_VAL(ret->user), ZSTR_LEN(ret->user));
pp++;
ret->pass = zend_string_init(pp, (p-pp), 0);
php_replace_controlchars_ex(ZSTR_VAL(ret->pass), ZSTR_LEN(ret->pass));
} else {
ret->user = zend_string_init(s, (p-s), 0);
php_replace_controlchars_ex(ZSTR_VAL(ret->user), ZSTR_LEN(ret->user));
}
s = p + 1;
}
看到这一段,对于user和password的解析过程,先对整个字符串判断是否出现@,并将指针指向p,如果有则判断@前面是否出现冒号,如果有则指向pp,将冒号前的字符串赋值给$ret->user,就是user,将冒号后一直到@符号前的字符串赋值给$ret->pass,否则若是字符串没有出现冒号,则将@符号前面的整个字符串赋值为$ret->user,这一段的关键在于如何定位@符号,也就是zend_memrchr函数是如何实现的?
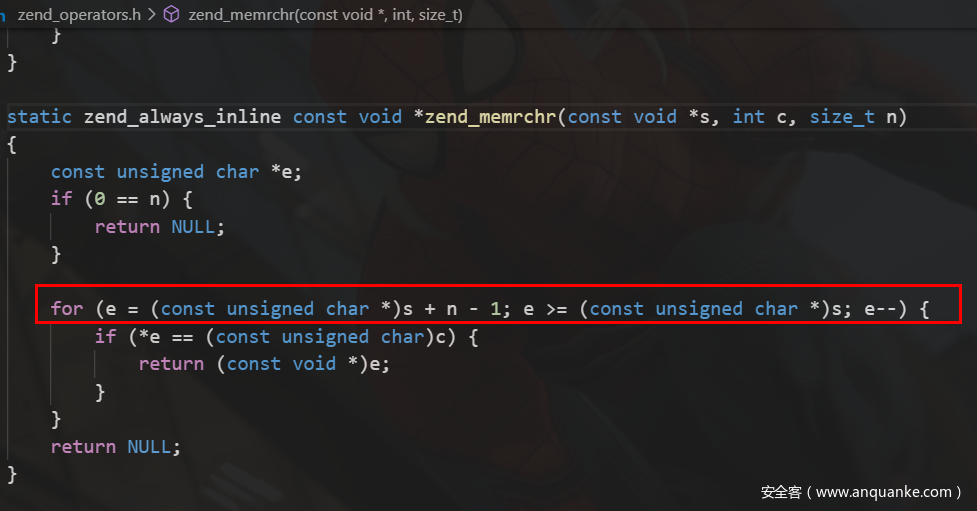
可以很明显的知道,该函数的搜索过程是自后向前的,因此他会从最后一个匹配@的字符串进行返回,因此在parse_url中,host匹配最后一个@后面符合格式的host
来看一下curl中对url的处理,在ext/curl/interface.c中php_curl_option_url函数的处理涉及到对url的处理,跟进看下:
static int php_curl_option_url(php_curl *ch, const char *url, const size_t len) /* {{{ */
{
/* Disable file:// if open_basedir are used */
if (PG(open_basedir) && *PG(open_basedir)) {
#if LIBCURL_VERSION_NUM >= 0x071304
curl_easy_setopt(ch->cp, CURLOPT_PROTOCOLS, CURLPROTO_ALL & ~CURLPROTO_FILE);
#else
php_url *uri;
if (!(uri = php_url_parse_ex(url, len))) {
php_error_docref(NULL, E_WARNING, "Invalid URL '%s'", url);
return FAILURE;
}
if (uri->scheme && zend_string_equals_literal_ci(uri->scheme, "file")) {
php_error_docref(NULL, E_WARNING, "Protocol 'file' disabled in cURL");
php_url_free(uri);
return FAILURE;
}
php_url_free(uri);
#endif
发现这里居然调用的是php_url_parse_ex,那不是和parse_url调用的一个底层函数,但是我们仔细看,php_url_parse_ex这个函数在这里的作用就是解析这个url使用了什么协议,再根据解析出来的协议$uri->scheme对比是否是file协议,真正调用过程中对url的解析处理在libcurl中,因为phpcurl也相当于是调用libcurl的动态链接库,不过貌似很早已经被修复了,因此到这里不在继续,能够从源码角度了解parse_url解析时,host匹配的是最后一个@后面符合格式的host就行
[+]strpos函数利用
一般在匹配某段输入中存在黑名单中的关键词,可能会使用strpos进行比较,该函数是用来查找字符串首次出现的位置,下面贴一下其函数原型:
strpos — 查找字符串首次出现的位置
作用:主要是用来查找字符在字符串中首次出现的位置。
结构:int strpos ( string $haystack , mixed $needle [, int $offset = 0 ] )
<?php
class Login{
private $format;
public function __construct($user,$pass)
{
$this->format =
<<<XML
<login>
<user v='%s' ></user>
<pass v='%s' ></pass>
</login>
XML;
$this->loginViaXml($user,$pass);
}
public function loginViaXml($user,$pass)
{
if(
!strpos($user,'<') || !strpos($user,'>') &&
!strpos($pass,'<') || !strpos($pass,'>')
)
{
$xml = sprintf($this->format,$user,$pass);
$this->login($xml);
}else{
die("no");
}
}
function login($xmld)
{
print_r($xmld);
}
}
new Login('user','pass');
这里的业务是通过格式化字符串的方式,使用xml结构存储用户的登录信息,并且判断$user或者$pass不能含有尖括号以避免注入,但是使用这种方式真的可以防止注入吗?
我们可以构造new Login("<'> </user> \n<evil-tag></evil-tag>\n //",'pass');
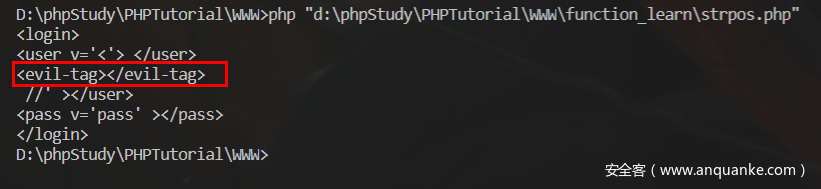
成功进行了注入,但是在我们的输入中是存在尖括号,为何strpos会失效呢?
strpos函数返回查找到的子字符串的下标。如果字符串开头就是我们要搜索的目标,则返回下标0;如果搜索不到,则返回false 这里没有对strpos有深刻的理解,导致在这里直接将结果进行取反,而我们知道false和0取反后的效果是等价的,均为真,因此这里针对尖括号的过滤是有权限的,但事实上并非strpos的缺陷,只是在使用时存在缺陷导致了绕过,因此如果用strpos来判断字符串中是否存在某个字符时必须使用===false
下面简单分析strpos底层的实现:
PHP_FUNCTION(strpos)
{
zval *needle;
zend_string *haystack;
const char *found = NULL;
char needle_char[2];
zend_long offset = 0;
ZEND_PARSE_PARAMETERS_START(2, 3)
Z_PARAM_STR(haystack)
Z_PARAM_ZVAL(needle)
Z_PARAM_OPTIONAL
Z_PARAM_LONG(offset)
ZEND_PARSE_PARAMETERS_END();
if (offset < 0) {
offset += (zend_long)ZSTR_LEN(haystack);
}
if (offset < 0 || (size_t)offset > ZSTR_LEN(haystack)) {
php_error_docref(NULL, E_WARNING, "Offset not contained in string");
RETURN_FALSE;
}
if (Z_TYPE_P(needle) == IS_STRING) {
if (!Z_STRLEN_P(needle)) {
php_error_docref(NULL, E_WARNING, "Empty needle");
RETURN_FALSE;
}
found = (char*)php_memnstr(ZSTR_VAL(haystack) + offset,
Z_STRVAL_P(needle),
Z_STRLEN_P(needle),
ZSTR_VAL(haystack) + ZSTR_LEN(haystack));
} else {
if (php_needle_char(needle, needle_char) != SUCCESS) {
RETURN_FALSE;
}
needle_char[1] = 0;
php_error_docref(NULL, E_DEPRECATED,
"Non-string needles will be interpreted as strings in the future. " \
"Use an explicit chr() call to preserve the current behavior");
found = (char*)php_memnstr(ZSTR_VAL(haystack) + offset,
needle_char,
1,
ZSTR_VAL(haystack) + ZSTR_LEN(haystack));
}
if (found) {
RETURN_LONG(found - ZSTR_VAL(haystack));
} else {
RETURN_FALSE;
}
}
其中第三个参数offset指从字符串的第几位开始,默认是0,主要是调用php_memnstr进行搜素匹配,其为函数zend_memnstr的宏定义:
static inline const char * zend_memnstr(const char *haystack /*目标符串*/,
const char *needle/*预查找字符串*/, int needle_len, char *end){
const char *p = haystack;//目标字符串首指针
const char ne = needle[needle_len-1];//预查找字符串的最后一个字符
if(needle_len == 1){//所查找的字符串是一个字符,则使用系统函数memchr
return (char *)memchr(p, *needle, (end-p));
}
if(needle_len > end-haystack){//所查找的字符串比目标字符串还长,则无需查找,直接返回找不着
return NULL;
}
end -= needle_len;//其实只要查找到end-neele_len位置就可以了
while(p<end){//从头指针一字符一字符地找
//如果头字符和尾字符同时匹配,则用memcmp比较是否已经找到
if((p = (char *)memchr(p, *needle, (end-p+1))) && ne == p[needle_len-1]){
if(!memcmp(needle, p, needle_len-1)){
return p;
}
}
if(p == NULL){//如果连头一个字符都没找着,则停止查找最合适
return NULL;
}
p++;//头指针向后移动一下
}
return NULL;//到尾了还没找着,则返回NULL
}
也是比较容易理解,此处理解strpos在未匹配到时返回False,在第一个位置匹配到将会返回0,并且正确使用strpos即可
[+]parse_str函数的利用
先来看一下官方文档对于该函数的原型介绍:
功能 :parse_str的作用就是解析字符串并且注册成变量,它在注册变量之前不会验证当前变量是否存在,所以会直接覆盖掉当前作用域中原有的变量。
定义 :void parse_str( string$encoded_string[, array &$result ] )
如果 encoded_string 是 URL 传入的查询字符串(query string),则将它解析为变量并设置到当前作用域(如果提供了 result 则会设置到该数组里 )。
8.0.0 result 是必须项。
7.2.0 不带第二个参数的情况下使用 parse_str() 会产生E_DEPRECATED 警告
也就是说,该函数将字符串赋值式中的字符串解析为变量,值为该变量的值,并且不会检验变量是否已经存在,如果存在也会将其覆盖,变量覆盖的相关漏洞也很常见了,这里不再谈论变量覆盖的利用问题,而是先从底层开始分析,再看从底层能够发掘出什么样的问题,注意从PHP7.2开始不使用第二个参数会出现警告,但是不影响程序执行
PHP_FUNCTION(parse_str)
{
char *arg;
zval *arrayArg = NULL;
char *res = NULL;
size_t arglen;
ZEND_PARSE_PARAMETERS_START(1, 2)
Z_PARAM_STRING(arg, arglen)
Z_PARAM_OPTIONAL
Z_PARAM_ZVAL(arrayArg)
ZEND_PARSE_PARAMETERS_END();
res = estrndup(arg, arglen);
if (arrayArg == NULL) {
zval tmp;
zend_array *symbol_table;
if (zend_forbid_dynamic_call("parse_str() with a single argument") == FAILURE) {
efree(res);
return;
}
php_error_docref(NULL, E_DEPRECATED, "Calling parse_str() without the result argument is deprecated");
symbol_table = zend_rebuild_symbol_table();
ZVAL_ARR(&tmp, symbol_table);
sapi_module.treat_data(PARSE_STRING, res, &tmp);
if (UNEXPECTED(zend_hash_del(symbol_table, ZSTR_KNOWN(ZEND_STR_THIS)) == SUCCESS)) {
zend_throw_error(NULL, "Cannot re-assign $this");
}
} else {
arrayArg = zend_try_array_init(arrayArg);
if (!arrayArg) {
efree(res);
return;
}
sapi_module.treat_data(PARSE_STRING, res, arrayArg);
}
}
/* }}} */
在这里可以发现,无论是有没有第二个参数,最终都是调用sapi_module.treat_data处理数据,而在PHP中$_GET、$_COOKIE、$_SERVER、$_ENV、$_FILES、$_REQUEST这六个变量都是通过如下的调用序列进行初始化。
[main() -> php_request_startup() -> php_hash_environment() ]
在请求初始化时,通过调用 php_hash_environment 函数初始化以上的六个预定义的变量。如下所示为php_hash_environment函数的部分代码(考虑到篇幅问题)
...
for (p=PG(variables_order); p && *p; p++) {
switch(*p) {
case 'p':
case 'P':
if (!_gpc_flags[0] && !SG(headers_sent) && SG(request_info).request_method && !strcasecmp(SG(request_info).request_method, "POST")) {
sapi_module.treat_data(PARSE_POST, NULL, NULL TSRMLS_CC); /* POST Data */
_gpc_flags[0] = 1;
if (PG(register_globals)) {
php_autoglobal_merge(&EG(symbol_table), Z_ARRVAL_P(PG(http_globals)[TRACK_VARS_POST]) TSRMLS_CC);
}
}
break;
case 'c':
case 'C':
if (!_gpc_flags[1]) {
sapi_module.treat_data(PARSE_COOKIE, NULL, NULL TSRMLS_CC); /* Cookie Data */
_gpc_flags[1] = 1;
if (PG(register_globals)) {
php_autoglobal_merge(&EG(symbol_table), Z_ARRVAL_P(PG(http_globals)[TRACK_VARS_COOKIE]) TSRMLS_CC);
}
}
break;
case 'g':
case 'G':
if (!_gpc_flags[2]) {
sapi_module.treat_data(PARSE_GET, NULL, NULL TSRMLS_CC); /* GET Data */
_gpc_flags[2] = 1;
if (PG(register_globals)) {
php_autoglobal_merge(&EG(symbol_table), Z_ARRVAL_P(PG(http_globals)[TRACK_VARS_GET]) TSRMLS_CC);
}
}
break;
...
可以看到,在$_POST,$_GET等变量的解析中,同样是调用sapi_module.treat_data进行数据的处理,treat_data是属于sapi_module_struct中的一个成员,定位到main/php_variables.c
if (arg == PARSE_GET) { /* GET data */
c_var = SG(request_info).query_string;
if (c_var && *c_var) {
res = (char *) estrdup(c_var);
free_buffer = 1;
} else {
free_buffer = 0;
}
} else if (arg == PARSE_COOKIE) { /* Cookie data */
c_var = SG(request_info).cookie_data;
if (c_var && *c_var) {
res = (char *) estrdup(c_var);
free_buffer = 1;
} else {
free_buffer = 0;
}
} else if (arg == PARSE_STRING) { /* String data */
res = str;
free_buffer = 1;
}
if (!res) {
return;
}
可以看到对于GET型的处理是第一种,而对于parse_str也就是PARSE_STRING是第三种,继续向下跟进:
var = php_strtok_r(res, separator, &strtok_buf);
...
while (var) {
val = strchr(var, '=');
if (arg == PARSE_COOKIE) {
/* Remove leading spaces from cookie names,
needed for multi-cookie header where ; can be followed by a space */
while (isspace(*var)) {
var++;
}
if (var == val || *var == '\0') {
goto next_cookie;
}
}
if (val) { /* have a value */
int val_len;
unsigned int new_val_len;
*val++ = '\0';
php_url_decode(var, strlen(var));//先进行urldecode
val_len = php_url_decode(val, strlen(val));
val = estrndup(val, val_len);
if (sapi_module.input_filter(arg, var, &val, val_len, &new_val_len TSRMLS_CC)) {
php_register_variable_safe(var, val, new_val_len, array_ptr TSRMLS_CC);
}
efree(val);
} else {
...
通过php_strtok_r把res根据”&”分割”key=value”段, 接下来分别为var和val复制为key和value, 经过调试在php_register_variable_safe中会调用main/php_variables.c的php_register_variable_ex函数
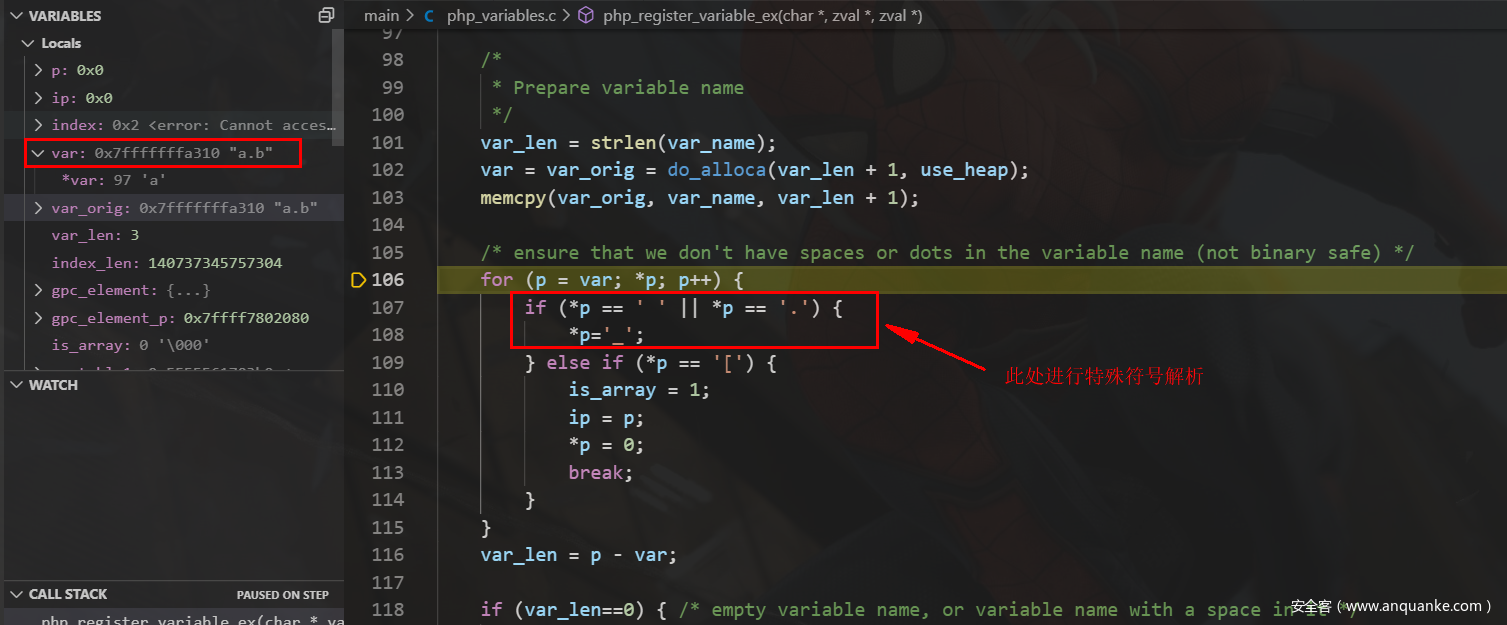
会对变量的空格、点变成下划线,而当解析变量中出现形如a[b中会将is_array=1
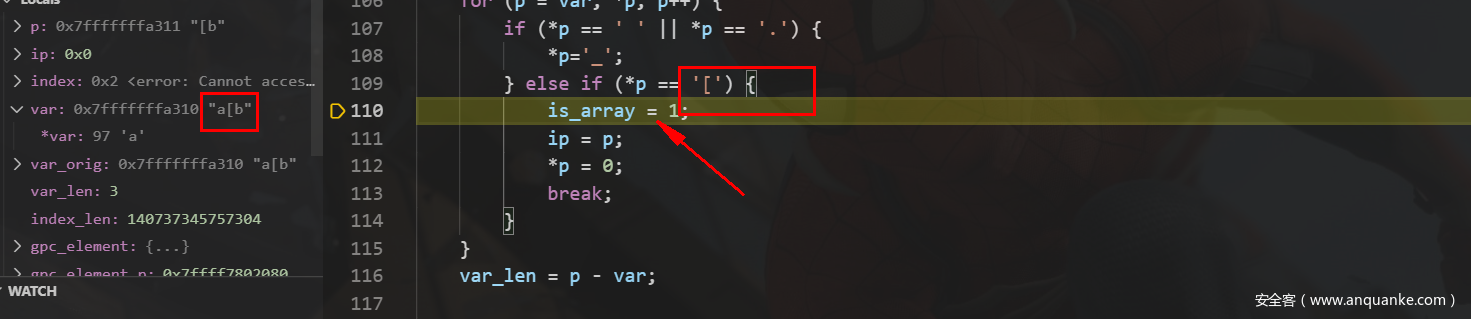
进入到is_array后的处理,我们根据注释以及代码也可以发现:
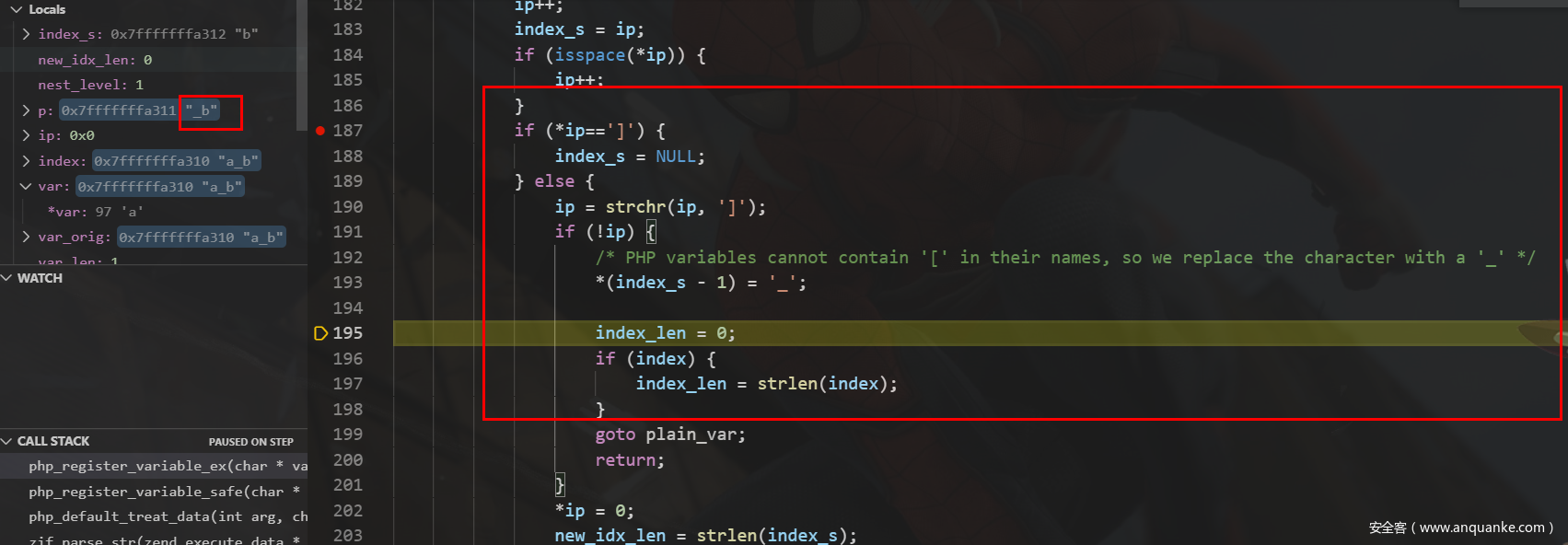
并且在此之前前文代码中已经提到,会先对传入变量进行urldecode处理,因此总结起来为:
PHP需要将所有参数转换为有效的变量名,在解析查询字符串时,它会做两件事:
- 删除空白符
- 将某些字符(点、括号、空格等)转换为下划线(包括空格)
因此我们基于此可以将填充数据后最终解析成相同变量的所有不同填充形式的数据都进行fuzz,这里贴下已有的脚本
<?php
foreach(
[
"{chr}foo_bar",
"foo{chr}bar",
"foo_bar{chr}"
] as $k => $arg) {
for($i=0;$i<=255;$i++) {
echo "\033[999D\033[K\r";
echo "[".$arg."] check ".bin2hex(chr($i))."";
parse_str(str_replace("{chr}",chr($i),$arg)."=bla",$o);
/* yes... I've added a sleep time on each loop just for
the scenic effect :)
like that movie with unrealistic
brute-force where the password are obtained
one byte at a time (∩`-´)⊃━☆゚.*・。゚
*/
usleep(5000);
if(isset($o["foo_bar"])) {
echo "\033[999D\033[K\r";
echo $arg." -> ".bin2hex(chr($i))." (".chr($i).")\n";
}
}
echo "\033[999D\033[K\r";
echo "\n";
}
得到如下数据都能解析成相同变量:
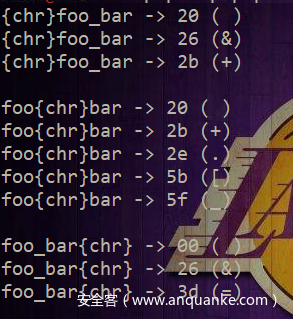
[+]escapeshellcmd/escapeshellarg函数利用
我们知道命令注入是很常见的一个问题,原因就是开发者对于用户的输入没有进行过滤而直接拼接到语句中进行执行,因此在PHP中提供了若干对输入进行过滤的函数以避免命令注入,这里最常见的便是escapeshellcmd和escapeshellarg
这里先将两者的函数原型贴一下:
escapeshellarg
escapeshellarg — 把字符串转码为可以在 shell 命令里使用的参数
功能 :escapeshellarg() 将给字符串增加一个单引号并且能引用或者转码任何已经存在的单引号,这样以确保能够直接将一个字符串传入 shell 函数,shell 函数包含 exec(),system() 执行运算符(反引号)
定义 :string escapeshellarg ( string $arg )
escapeshellcmd
escapeshellcmd — shell 元字符转义
escapeshellcmd() 对字符串中可能会欺骗 shell 命令执行任意命令的字符进行转义。 此函数保证用户输入的数据在传送到 exec() 或 system() 函数,或者 执行操作符 之前进行转义。
反斜线(\)会在以下字符之前插入: &#;`|*?~<>^()[]{}$\, \x0A 和 \xFF。 ‘ 和 “ 仅在不配对儿的时候被转义。 在 Windows 平台上,所有这些字符以及 % 和 ! 字符都会被空格代替。
而两者的功能有着一定的差别:
escapeshellarg
- 1.确保用户只传递一个参数给命令
- 2.用户不能指定更多的参数
- 3.用户不能执行不同的命令
escapeshellcmd
- 1.确保用户只执行一个命令
- 2.用户可以指定更多的参数
- 3.用户不能执行更多的命令
来看一下escapeshellarg/escapeshellcmd的输出
<?php
//$file = "sth -or -exec cat /etc/passwd ; -quit";
//system("find /tmp -iname ".escapeshellcmd($file));
$arg = "1 ' or '1=1";
echo escapeshellarg($arg);
// Output: /etc/passwd
// Output: '1 '\'' or '\''1=1'
?>
escapeshellcmd允许执行多个参数意味着如果该可执行程序中本身就有能够执行命令或者读取文件的参数,最典型的例子就是find,示例如上,escapeshellarg的处理是如果字符串中出现了'则先将其转义后,再将每一部分用单引号括起来,但是这里如果将escapeshellarg和escapeshellcmd混用将会导致参数的注入.
这里我们借助BUUCTF 2018 Online Tool这个题来分析这两个函数的源码以及利用的过程:
<?php
if (isset($_SERVER['HTTP_X_FORWARDED_FOR'])) {
$_SERVER['REMOTE_ADDR'] = $_SERVER['HTTP_X_FORWARDED_FOR'];
}
if(!isset($_GET['host'])) {
highlight_file(__FILE__);
} else {
$host = $_GET['host'];
$host = escapeshellarg($host);
$host = escapeshellcmd($host);
$sandbox = md5("glzjin". $_SERVER['REMOTE_ADDR']);
echo 'you are in sandbox '.$sandbox;
@mkdir($sandbox);
chdir($sandbox);
echo system("nmap -T5 -sT -Pn --host-timeout 2 -F ".$host);
}
可以看到这里使用escapeshellarg和escapeshellcmd对$host进行过滤后拼接到了nmap语句中,这样两重过滤应该显得更严格,但是事实并非如此,namp中有一个参数-oG可以实现将命令和结果写到文件,所以我们可以控制自己的输入写入文件。但是如何进行绕过上面两个函数的过滤呢?
我们先来看看payload:
?host=' <?php phpinfo();?> -oG exp.php '
为何加入单引号后能够绕过,不是对单引号进行转义了吗?
在exec.c中escapeshellarg调用了php_escape_shell_arg函数对输入进行处理,跟进查看:
/* {{{ php_escape_shell_arg
*/
PHPAPI zend_string *php_escape_shell_arg(char *str)
{
size_t x, y = 0;
size_t l = strlen(str);
zend_string *cmd;
uint64_t estimate = (4 * (uint64_t)l) + 3;
/* max command line length - two single quotes - \0 byte length */
if (l > cmd_max_len - 2 - 1) {
php_error_docref(NULL, E_ERROR, "Argument exceeds the allowed length of %zu bytes", cmd_max_len);
return ZSTR_EMPTY_ALLOC();
}
cmd = zend_string_safe_alloc(4, l, 2, 0); /* worst case */
ZSTR_VAL(cmd)[y++] = '\'';
for (x = 0; x < l; x++) {
//这一段是5.2.6新加的,就是在处理多字节符号的时候,当多字节字符小于0的时候不处理,大于1的时候跳过,等于1的时候执行过滤动作
int mb_len = php_mblen(str + x, (l - x));
/* skip non-valid multibyte characters */
if (mb_len < 0) {
continue;
} else if (mb_len > 1) {
memcpy(ZSTR_VAL(cmd) + y, str + x, mb_len);
y += mb_len;
x += mb_len - 1;
continue;
}
switch (str[x]) {
case '\'':
ZSTR_VAL(cmd)[y++] = '\'';
ZSTR_VAL(cmd)[y++] = '\\';
ZSTR_VAL(cmd)[y++] = '\'';
#endif
/* fall-through */
default:
ZSTR_VAL(cmd)[y++] = str[x];
}
}
ZSTR_VAL(cmd)[y++] = '\'';
#endif
ZSTR_VAL(cmd)[y] = '\0';
if (y > cmd_max_len + 1) {
php_error_docref(NULL, E_ERROR, "Escaped argument exceeds the allowed length of %zu bytes", cmd_max_len);
zend_string_release_ex(cmd, 0);
return ZSTR_EMPTY_ALLOC();
}
if ((estimate - y) > 4096) {
/* realloc if the estimate was way overill
* Arbitrary cutoff point of 4096 */
cmd = zend_string_truncate(cmd, y, 0);
}
ZSTR_LEN(cmd) = y;
return cmd;
}
可以很明显的看到,如果字符串中存在单引号',则先在其前面一次填充单引号,斜杠,单引号,再将这个原本的单引号处理ZSTR_VAL(cmd)[y++] = str[x];
而在未处理和循环完成后都进行了
ZSTR_VAL(cmd)[y++] = '\'';
因此总结起来就是首先将字符串用单引号包围,然后遇到单引号则在其前面加上单引号,反斜杠,单引号,各位有兴趣也可以自己验证一下看是否和源码一致
因此可以自己推导一遍exp经过escapeshellarg处理后的样子:
<?php
$arg = "' <?php phpinfo();?> -oG exp.php '";
echo escapeshellarg($arg);
/* Output: ''\'' <?php phpinfo();?> -oG exp.php '\''' */
?>
和输出是一样的,这样原来的exp经过过滤后变成了如上的形状,接着再经过escapeshellcmd的处理,同样在底层调用php_escape_shell_cmd函数,继续分析:
//篇幅原因这里选择关键处理步骤
...
#ifndef PHP_WIN32
case '"':
case '\'':
if (!p && (p = memchr(str + x + 1, str[x], l - x - 1))) {
/* noop */
} else if (p && *p == str[x]) {
p = NULL;
} else {
ZSTR_VAL(cmd)[y++] = '\\';
}
ZSTR_VAL(cmd)[y++] = str[x];
break;
#else
/* % is Windows specific for environmental variables, ^%PATH% will
output PATH while ^%PATH^% will not. escapeshellcmd->val will escape all % and !.
*/
case '%':
case '!':
case '"':
case '\'':
#endif
case '#': /* This is character-set independent */
case '&':
case ';':
case '`':
case '|':
case '*':
case '?':
case '~':
case '<':
case '>':
case '^':
case '(':
case ')':
case '[':
case ']':
case '{':
case '}':
case '$':
case '\\':
case '\x0A': /* excluding these two */
case '\xFF':
#ifdef PHP_WIN32
ZSTR_VAL(cmd)[y++] = '^';
#else
ZSTR_VAL(cmd)[y++] = '\\';
#endif
/* fall-through */
default:
ZSTR_VAL(cmd)[y++] = str[x];
}
}
...
可以看到,如果是有引号存在,会在该引号后面的字符串中寻找是否还出现引号,如果出现则不处理,但如果没有则会加入反斜杠进行转义,同时会判断
&#;`|*?~<>^()[]{}$\,\x0A和\xFF //如果出现则进行转义
因此经过escapeshellarg处理后在经过escapeshellcmd处理,最终会变成
''\\'' \<\?php phpinfo\(\)\;\?\> -oG exp.php '\\'''
此时在进行拼接,system函数传入为如下语句:
nmap -T5 -sT -Pn --host-timeout 2 -F ''\\'' \<\?php phpinfo\(\)\;\?\> -oG exp.php '\\'''
而在linux中是支持空白连接符的,并且\这里视为将反斜杠进行转义,linux解析时双反斜杠也不会影响其他语句的执行:
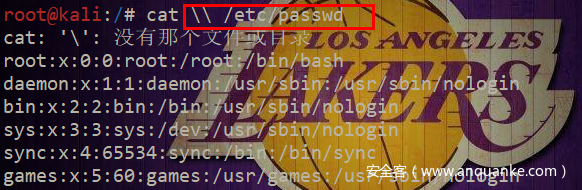
再将空白连接符去除进行简化得到
nmap -T5 -sT -Pn --host-timeout 2 -F \<\?php phpinfo\(\)\;\?\> -oG exp.php
最终进行写入,当然关于escapeshell和escapecmd混合使用的漏洞还有许多,有兴趣的大佬可以研究PHPmailer的两个CVECVE-2016-10045和CVE-2016-10033
[+]深入理解$_REQUEST数组
关于$_REQUEST这个全局变量应该都不陌生,在官方文档中是如下描述的:
$_REQUEST — HTTP Request 变量
默认情况下包含了$_GET,$_POST和$_COOKIE的数组。
其实官方文档的介绍中容易让人产生误解,我们来看这样一个简单的demo
//Don't forget, because $_REQUEST is a different variable than $_GET and $_POST, it is treated as such in PHP -- modifying $_GET or $_POST elements at runtime will not affect the ellements in $_REQUEST, nor vice versa.
<?php
$_GET['foo'] = 'a';
$_POST['bar'] = 'b';
var_dump($_GET); // Element 'foo' is string(1) "a"
var_dump($_POST); // Element 'bar' is string(1) "b"
var_dump($_REQUEST); // Does not contain elements 'foo' or 'bar'
?>
也就是说虽然$_REQUEST默认情况下包含了$_GET,$_POST和$_COOKIE,但是对一方的处理完全不会影响另一方,这里如果我们想要对输入进行过滤,而代码是这样的
...
class foo{
public function filterParams(){
$_GET = array_map('addslashes',$_GET);
$_POST = array_map('addslashes',$_POST);
}
public function login(){
$this->filterParams();
$sql = "select * from users where username = $_REQUEST['user'] and password = $_REQUEST['pass']";
}
}
...
本意是想对输入全部进行转义,这样能够避免注入,但事实上对$_GET和$_POST的操作并不会影响$_REQUEST这个预定义变量,下面我们从内核角度来看$_REQUEST是如何实现的
其实在PHP中$_GET、$_COOKIE、$_SERVER、$_ENV、$_FILES、$_REQUEST这六个变量都是通过如下的调用序列进行初始化。
[main() -> php_request_startup() -> php_hash_environment() ]
在请求初始化时,通过调用 php_hash_environment 函数初始化以上的六个预定义的变量。
而在此之前,apache处理到response阶段的时候, 会将控制权交给PHP模块, PHP模块会在处理请求之前首先间接调用php_request_startup
int php_request_startup(TSRMLS_D)
{
int retval = SUCCESS;
#if PHP_SIGCHILD
signal(SIGCHLD, sigchld_handler);
#endif
if (php_start_sapi() == FAILURE) {
return FAILURE;
}
php_output_activate(TSRMLS_C);
sapi_activate(TSRMLS_C);
php_hash_environment(TSRMLS_C);
zend_try {
PG(during_request_startup) = 1;
php_output_activate(TSRMLS_C);
if (PG(expose_php)) {
sapi_add_header(SAPI_PHP_VERSION_HEADER, sizeof(SAPI_PHP_VERSION_HEADER)-1, 1);
}
} zend_catch {
retval = FAILURE;
} zend_end_try();
return retval;
}
其中php_hash_environment(TSRMLS_C)函数调用 , 这个函数就是在请求处理前, 初始化请求相关的变量的函数,在这个函数中,会通过php_auto_globals_create_request来注册$_REQUEST大变量:
static zend_bool php_auto_globals_create_request(zend_string *name)
{
zval form_variables;
unsigned char _gpc_flags[3] = {0, 0, 0};
char *p;
array_init(&form_variables);
if (PG(request_order) != NULL) {
p = PG(request_order);
} else {
p = PG(variables_order);
}
for (; p && *p; p++) {
switch (*p) {
case 'g':
case 'G':
if (!_gpc_flags[0]) {
php_autoglobal_merge(Z_ARRVAL(form_variables), Z_ARRVAL(PG(http_globals)[TRACK_VARS_GET]));
_gpc_flags[0] = 1;
}
break;
case 'p':
case 'P':
if (!_gpc_flags[1]) {
php_autoglobal_merge(Z_ARRVAL(form_variables), Z_ARRVAL(PG(http_globals)[TRACK_VARS_POST]));
_gpc_flags[1] = 1;
}
break;
case 'c':
case 'C':
if (!_gpc_flags[2]) {
php_autoglobal_merge(Z_ARRVAL(form_variables), Z_ARRVAL(PG(http_globals)[TRACK_VARS_COOKIE]));
_gpc_flags[2] = 1;
}
break;
}
}
zend_hash_update(&EG(symbol_table), name, &form_variables);
return 0;
}
这里只是将$_GET, $_POST, $_COOKIEmerge起来,调用php_autoglobal_merge将相关变量的值写到符号表,最终调用zend_hash_update,将相关变量的值赋值给&EG(symbol_table),因此在这里$_REQUEST可以理解为一个全新的预定义变量,因其对$_POST、$_GET并不是引用,而知相当于将其重新赋值后写到符号表中,是一个崭新的变量(个人是如此理解的,如有不当,还请谅解)
这里就引出了另外一个话题,注意到在进行switch之前进行了p = PG(variables_order);操作
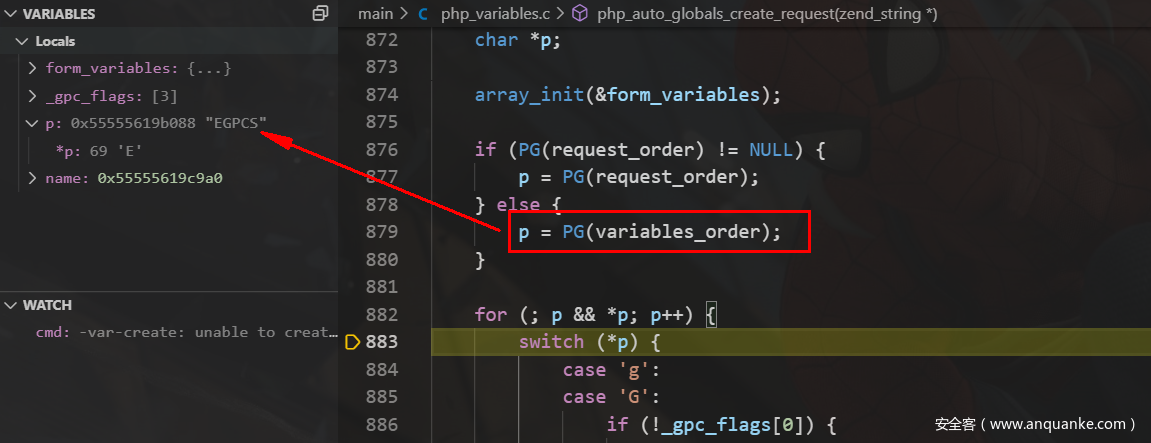
检测是否设置request_order,如果未设置则按照variables_order顺序来指导大变量的生成

这一点从官方文档中也得到了映证
不过这里php.ini中是存在request_order=”GP”的,但是动调的时候PG(request_order==NULL),这一点没有想明白,不过即使是根据request_order也是先G后P,因此POST的变量名和GET变量名一致时仍然会进行覆盖
而variables_order这其实是用来控制PHP是否生成某个大变量以及大变量的生成顺序,该顺序在php.ini中已经定义
; variables_order
; Default Value: "EGPCS"
; Development Value: "GPCS"
; Production Value: "GPCS"
一般在php.ini中都使用variables_order = "GPCS"
默认的顺序为EGPCS,在官方文档中也能看到:
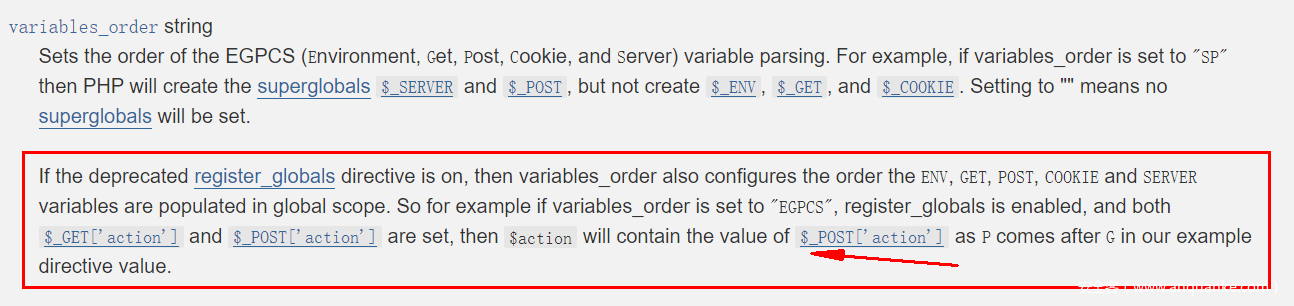
因P在G之后进行处理,因此如果同时存在$_GET['foo']和$_POST['foo'],那么根据默认的规则,最终$_POST['foo']的数据会将$_GET['foo']的数据覆盖掉,最终的$_REQUEST[‘foo’]的数据自然是POST中的数据
示例如下:
var_dump($_REQUEST['foo']);

因此整个预定义变量$_REQUEST的原理也就至此,该种特性之前也被用来在CTF中进行考察
总结
总的来说,从内核层面来分析函数能够对函数有更深层次的了解,在此过程中需要结合动态调试来试着分析整个执行过程,并且需要对PHP的内核有一定的了解,对函数的参数类型和个数要有一定的敏感度,并且多去查阅官方文档,对函数参数以及官方文档中标注意的地方多关注
参考链接:
https://github.com/hongriSec/PHP-Audit-Labs
https://www.bookstack.cn/read/php-internals/22.md