
eBPF对象的生命周期
BPF的对象包括:
- BPF程序
- BPF映射
- 调试信息
创建BPF映射的过程
进行bpf(BPF_MAP_CREATE, ...)系统调用时, 内核会:
- 分配一个
struct bpf_map对象 - 设置该对象的引用计数:
refcnt=1 - 返回一个fd给用户空间
如果进程退出或者崩溃, 那么BPF映射对应的fd也会被关闭, 导致refcnt--变为0, 之后就会被内核释放掉
加载BPF程序的过程
对于引入了BPF映射的BPF程序, 加载分为两个阶段
- 创建映射: 这些映射fd之后会放到
BPF_LD_IMM64指令的imm字段中, 成为BPF程序的一部分 - 对BPF程序进行检验. 检验器会把其引用的映射的refcnt++, 并设置改程序的refcnt=1
此后
- 用户空间close()映射的fd时, 由于BPF程序还在使用, 因此映射不会被删除.
- 当BPF程序的fd被关闭时, 如果其refcnt变为0, 那么就会回收该BPF程序, 其所有引用的映射的
refcnt--
把BPF程序attach到钩子上
把BPFattach到hook上之后, BPF程序的refcnt++. 此时创建, 加载BPF的用户空间程序就可以退出了. 因此还有hook保持着对BPF程序的引用, BPF程序并不会被回收.
总之, 只要BPF对象的引用计数大于0, 内核就不会回收
BPF文件系统(BPFFS)
用户空间的程序可以把一个BPF或者BPF映射固定到BPFFS, 以生成一个文件. pin操作会使得BPF对象refcnt++, 因此即使这个BPF程序没有attach到任何地方, 或者一个BPF映射没有被任何地方使用, 在加载程序退出后, 这些BPF对象任然会存活
如果想要取消某个固定的对象, 只要调用unlink()即可, 也可以直接用rm命令删除这个文件
总结
create -> refcnt=1attach -> refcnt++detach -> refcnt--pin -> refcnt++unpin -> refcnt--unlink -> refcnt--close -> refcnt--
eBPF程序相关操作
https://stackoverflow.com/questions/68278120/ebpf-difference-between-loading-attaching-and-linking
加载: load
通过bpf(BPF_PROG_LOAD, ...)系统调用加载程序, 将其指令注入内核。程序通过验证器会进行许多检查并可能重写一些指令(特别是对于地图访问)。如果启用了 JIT 编译,则程序可能是 JIT 编译的。内核会为这个程序建立一个struct bpf_prog对象, 包含有关此程序的信息,例如eBPF字节码和JIT编译的指令。
在这个过程结束时,程序位于内核内存中, 它不依附于特定对象。它有一个引用计数器,内核会一直保持它直到计数器归零。引用可以由文件描述符保存到程序:例如,一个由bpf()系统调用返回到加载应用程序。可以通过附加、链接、固定程序或在prog_array 映射中引用它来创建其他引用。如果没有引用保留(例如,加载应用程序在加载程序后立即退出,从而关闭其指向该程序的文件描述符),则将其从内核中删除。
“附加类型”(attach type)的概念取决于程序类型(prog_type)。有些程序类型没有这个概念:XDP 程序只是附加到接口的 XDP 钩子上。附加到 cgroups 的程序确实有一个“附加类型”,它告诉程序附加到哪里,确切地说。
加载程序大多与这些附加类型分开。但是某些程序类型需要在加载时就说明附加类型, 在进行bpf()系统调用时, 通过union bpf_attr的expected_attach_type来传递预期的附加类型. 验证器和系统调用处理程序使用这种预期的附加类型来执行各种验证。
附加: attach
现在BPF程序已经被加载到内核中随时可以执行. 通过attach可以把程序挂到一些事件的钩子上. 当事件发生时BPF程序就会被调用.
链接: link
当加载BPF的程序关闭时, 由于BPF程序引用归零, 就会被内核卸载. 那么如何在程序关闭时保持BPF程序的运行呢? 此时可以使用链接.
BPF程序可以attach到一个链接, 而不是传统的钩子. 链接本身attacah到内核的钩子. 这为操作程序提供了更好的接口. 一个优点时可以固定这种链接, 在加载程序退出时保持BPF继续运行. 另一个优点是更容易跟踪程序中持有的引用, 以确保加载程序意外退出时没有BPF程序被加载
不要把BPF程序的链接与编译ELF文件时的链接弄混. 目标文件的链接重定位过程与BPF的链接无关
固定: pin
Pin是一种保持BPF对象(程序, 映射, 链接)引用的方法. 通过bpf(BPF_OBJ_PIN, ...)这个系统调用完成, 这会在eBPF的虚拟文件系统中创建一个路径, 并且之后可以用过open()该路径来获取该BPF对象的文件描述符. 只要一个对象被固定住, 他就会一直保留在内核中, 不需要pin或者map就可运行它. 只要存在其他引用(文件描述符. 附加到一些钩子, 或者被其他程序引用)程序就会一直加载在内核中, attach之后可以直接运行
固定一个BPF链接可以确保: attach到该链接的程序在加载程序退出并关闭他的文件描述符之后, 仍然被加载
总结
- load: 向内核注入一段程序并进行检验. BPF程序可能重写某些指令并链接到内部的BPF对象. 可能会发生JIT编译. 有时候需要
expected_attach_type字段 - attach: 把BPF程序附加到与程序类型相关的钩子上
- link: 根据程序类型把程序附加到BPF链接上, 而不是直接附加到常规的附着点上. BPF链接会附加到常规的钩子上, 以提供更灵活的接口来管理程序
- pin: 程序或者链接可以被固定到bpf文件系统以实现持久化(重启后失效)
例子一: 用eBPF跟踪socket
首先需要编译出BPF程序, 这里调用了助手函数bpf_trace_printk, 这会向内核追踪日志中写入消息, 可以通过读取/sys/kernel/debug/tracing/trace_pipe获取输出
//clang -O2 -target bpf -c ./prog.c -o ./prog.o
#include <linux/bpf.h>
static int (*bpf_trace_printk)(const char *fmt, int fmt_size, ...) = (void *) BPF_FUNC_trace_printk;
unsigned long prog(void){
char fmt[]="Get";
bpf_trace_printk(fmt, sizeof(fmt));
return 0;
}
编译后的指令如下, 对于外部助手的函数被翻译为call 6
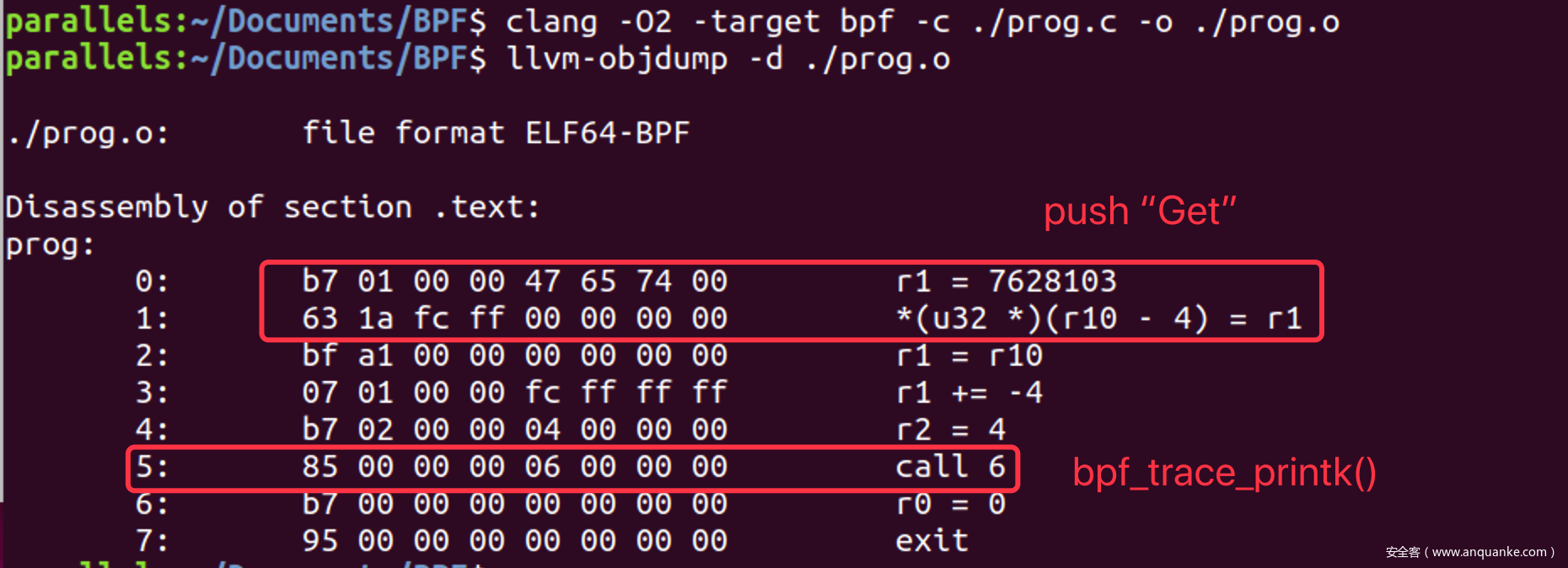
再用llvm-objcopy提取text段的指令到prog.text文件

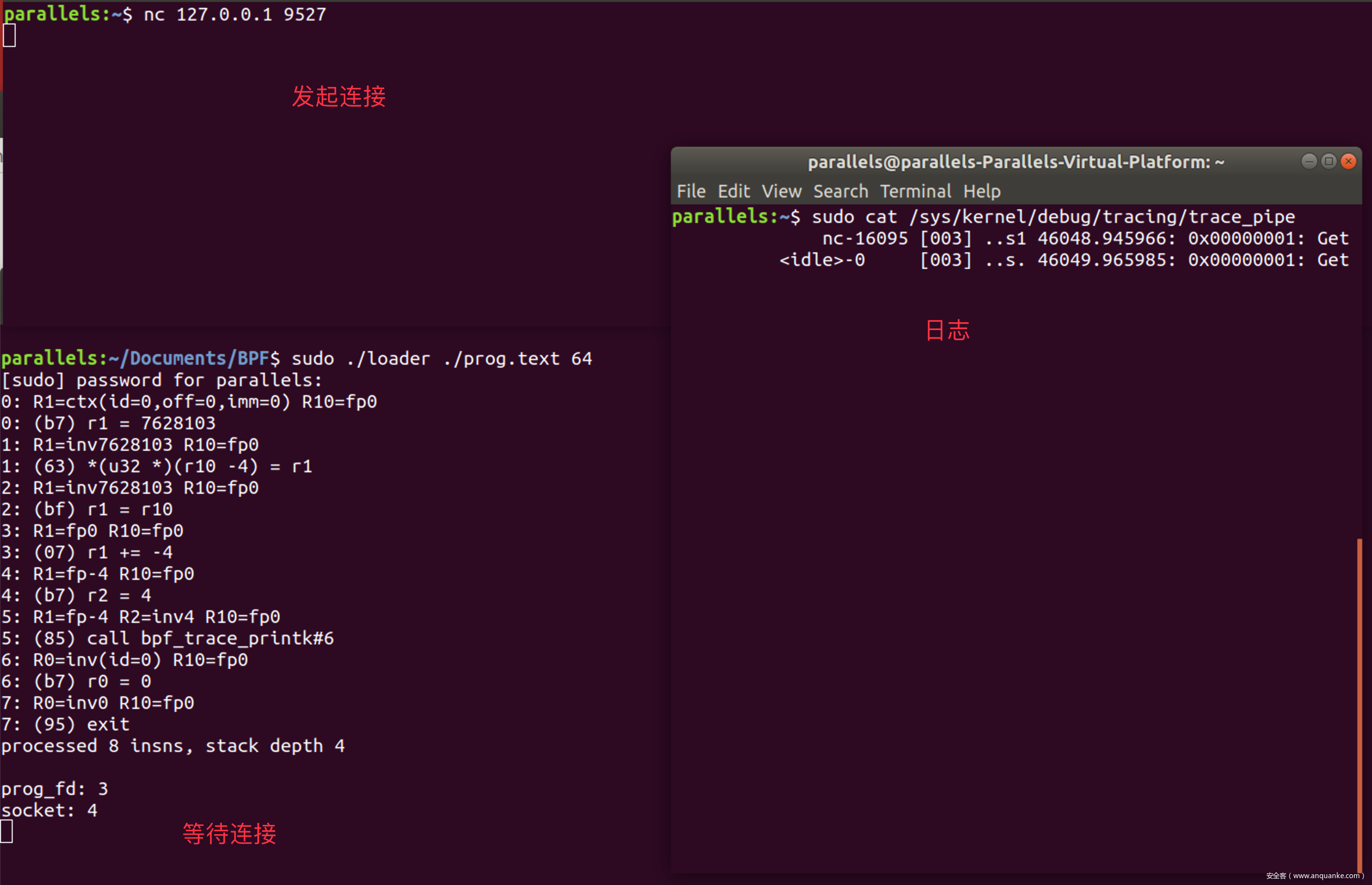
加载器首先需要读入指令, 然后向内核注入此程序, 以获取BPF程序对应的文件描述符. 接着开启一个socket, 通过socketopt()函数让eBPF程序附着在socket上. 整体代码如下
//gcc ./loader.c -o loader
#include <stdio.h>
#include <stdlib.h> //为了exit()函数
#include <stdint.h> //为了uint64_t等标准类型的定义
#include <errno.h> //为了错误处理
#include <linux/bpf.h> //位于/usr/include/linux/bpf.h, 包含BPF系统调用的一些常量, 以及一些结构体的定义
#include <sys/syscall.h> //为了syscall()
//类型转换, 减少warning, 也可以不要
#define ptr_to_u64(x) ((uint64_t)x)
//对于系统调用的包装, __NR_bpf就是bpf对应的系统调用号, 一切BPF相关操作都通过这个系统调用与内核交互
int bpf(enum bpf_cmd cmd, union bpf_attr *attr, unsigned int size)
{
return syscall(__NR_bpf, cmd, attr, size);
}
//用于保存BPF验证器的输出日志
#define LOG_BUF_SIZE 0x1000
char bpf_log_buf[LOG_BUF_SIZE];
//通过系统调用, 向内核加载一段BPF指令
int bpf_prog_load(enum bpf_prog_type type, const struct bpf_insn* insns, int insn_cnt, const char* license)
{
union bpf_attr attr = {
.prog_type = type, //程序类型
.insns = ptr_to_u64(insns), //指向指令数组的指针
.insn_cnt = insn_cnt, //有多少条指令
.license = ptr_to_u64(license), //指向整数字符串的指针
.log_buf = ptr_to_u64(bpf_log_buf), //log输出缓冲区
.log_size = LOG_BUF_SIZE, //log缓冲区大小
.log_level = 2, //log等级
};
return bpf(BPF_PROG_LOAD, &attr, sizeof(attr));
}
//开启一个socket
int get_listen_socket(char *ip, int port){
//获取一个TCP类型的socket
int sock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
//设置地址对象, 采用IPv4
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof(serv_addr));
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr.s_addr = inet_addr(ip);
serv_addr.sin_port = htons(port);
//把socket绑定的指定地址
bind(sock, (struct sockaddr *)(&serv_addr), sizeof(serv_addr));
//socket进入监听模式
listen(sock, 20);
return sock;
}
//保存BPF程序
struct bpf_insn bpf_prog[0x100];
int main(int argc, char **argv){
//先从文件中读入BPF指令
int text_len = atoi(argv[2]);
int file = open(argv[1], O_RDONLY);
if(read(file, (void *)bpf_prog, text_len)<0){
perror("read prog fail");
exit(-1);
}
close(file);
//把BPF程序加载进入内核, 注意这里程序类型一定要是BPF_PROG_TYPE_SOCKET_FILTER, 表示BPF程序用于socket
int prog_fd = bpf_prog_load(BPF_PROG_TYPE_SOCKET_FILTER, bpf_prog, text_len/sizeof(bpf_prog[0]), "GPL");
printf("%s\n", bpf_log_buf);
if(prog_fd<0){
perror("BPF load prog");
exit(-1);
}
printf("prog_fd: %d\n", prog_fd);
//打开一个socket进入监听状态
int sock = get_listen_socket("0.0.0.0", 9527);
printf("socket: %d\n", sock);
//把已经加载的BPF程序附加到socket上, 这样当数据到来时这个BPF程序就会被调用
if(setsockopt(sock, SOL_SOCKET, SO_ATTACH_BPF, &prog_fd, sizeof(prog_fd))<0){
perror("set socket error");
exit(-1);
}
//调用accept()等待链接到来
struct sockaddr_in clnt_addr;
socklen_t clnt_addr_size = sizeof(clnt_addr);
int clnt_sock = accept(sock, (struct sockaddr *)(&clnt_addr), &clnt_addr_size);
}
运行loader然后读入内核日志, 用nc向loader发起链接就可以看到日志的输出
例子二: 用eBPF跟踪系统调用
我们使用同一个BPF程序, 加载BPF的过程与上文类似, 区别在与attach的过程, 本例中需要通过perf机制来跟踪系统调用. 有关perf的部分只做简要介绍, 具体的可以看perf_event_open系统调用的手册
perf_event_open系统调用用于打开一个被测量事件的文件描述符
/*
evt_attr: 描述要监视的事件的属性
pid: 要监视的进程id, 设为-1的话表示监视所有进程
cpu: 要见识的CPU
group_fd: 事件组id, 暂时不用管
flags: 相关表示, 暂时不用管
*/
static int perf_event_open(struct perf_event_attr *evt_attr, pid_t pid, int cpu, int group_fd, unsigned long flags)
{
int ret;
ret = syscall(__NR_perf_event_open, evt_attr, pid, cpu, group_fd, flags);
return ret;
}
重点在于配置struct perf_event_attr, 主要成员如下
struct perf_event_attr {
__u32 type; /* 事件类型 */
__u32 size; /* attribute结构的大小 */
__u64 config; /* 含义根据事件类型而定, 描述具体的事件配置 */
union {
__u64 sample_period; /* 取样时长 Period of sampling */
__u64 sample_freq; /* 取样频率 Frequency of sampling */
};
__u64 sample_type; /* 取样种类 */
...;
union {
__u32 wakeup_events; /* 每n个事件唤醒一次 */
__u32 wakeup_watermark; /* bytes before wakeup */
};
};
本例中我们要测量的是跟踪点类型中, 进入execve这一事件, 因此可以把struct perf_event_attr的type设置为PERF_TYPE_TRACEPOINT, 表示跟踪点类型的事件. 此时config的值就表示具体要观测哪一个跟踪点, 这个值可以从debugfs中获取, 路径/sys/kernel/debug/tracing/events/<某一事件>/<某一跟踪点>/id中保存着具体的跟踪点的值. 如下

因此如下设置就可以打开测量对应事件的efd
//设置一个perf事件属性的对象
struct perf_event_attr attr = {};
attr.type = PERF_TYPE_TRACEPOINT; //跟踪点类型
attr.sample_type = PERF_SAMPLE_RAW; //记录其他数据, 通常由跟踪点事件返回
attr.sample_period = 1; //每次事件发送都进行取样
attr.wakeup_events = 1; //每次取样都唤醒
attr.config = 678; // 观测进入execve的事件, 来自于: /sys/kernel/debug/tracing/events/syscalls/sys_enter_execve/id
//开启一个事件观测, 跟踪所有进程, group_fd为-1表示不启用事件组
int efd = perf_event_open(&attr, -1/*pid*/, 0/*cpu*/, -1/*group_fd*/, 0);
if(efd<0){
perror("perf event open error");
exit(-1);
}
printf("efd: %d\n", efd);
接着通过ioctl()打开事件后, 再把BPF程序附着到此事件上就可在每次进入execve时触发BPF程序
ioctl(efd, PERF_EVENT_IOC_RESET, 0); //重置事件观测
ioctl(efd, PERF_EVENT_IOC_ENABLE, 0); //启动事件观测
if(ioctl(efd, PERF_EVENT_IOC_SET_BPF, prog_fd)<0){ //把BPF程序附着到此事件上
perror("ioctl event set bpf error");
exit(-1);
}
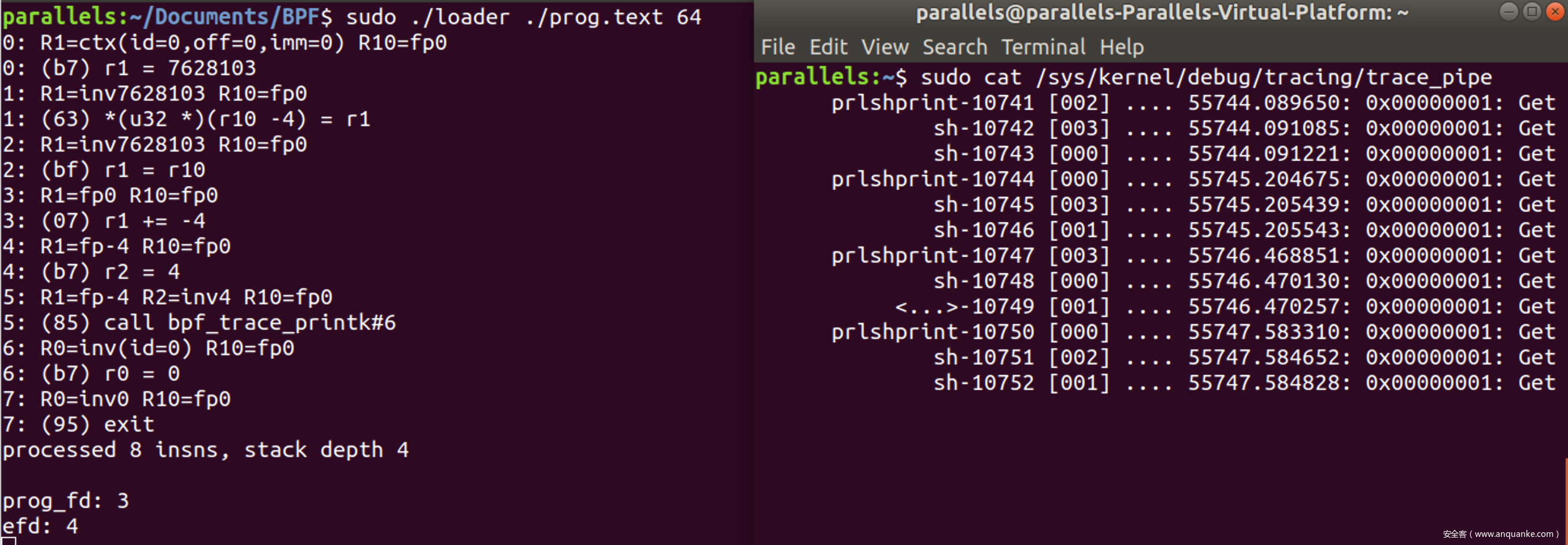
整体代码如下, 加载BPF程序时要注意, 此时BPF程序的类型为BPF_PROG_TYPE_TRACEPOINT, 为追踪点类型的BPF程序
//gcc ./loader.c -o loader
#include <linux/bpf.h>
#include <stdio.h>
#include <sys/syscall.h>
#include <linux/perf_event.h>
#include <stdlib.h>
#include <stdint.h>
#include <errno.h>
#include <fcntl.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <stdlib.h>
//类型转换, 减少warning, 也可以不要
#define ptr_to_u64(x) ((uint64_t)x)
//对于系统调用的包装, __NR_bpf就是bpf对应的系统调用号, 一切BPF相关操作都通过这个系统调用与内核交互
int bpf(enum bpf_cmd cmd, union bpf_attr *attr, unsigned int size)
{
return syscall(__NR_bpf, cmd, attr, size);
}
//对于perf_event_open系统调用的包装, libc里面不提供, 要自己定义
static int perf_event_open(struct perf_event_attr *evt_attr, pid_t pid, int cpu, int group_fd, unsigned long flags)
{
int ret;
ret = syscall(__NR_perf_event_open, evt_attr, pid, cpu, group_fd, flags);
return ret;
}
//用于保存BPF验证器的输出日志
#define LOG_BUF_SIZE 0x1000
char bpf_log_buf[LOG_BUF_SIZE];
//通过系统调用, 向内核加载一段BPF指令
int bpf_prog_load(enum bpf_prog_type type, const struct bpf_insn* insns, int insn_cnt, const char* license)
{
union bpf_attr attr = {
.prog_type = type, //程序类型
.insns = ptr_to_u64(insns), //指向指令数组的指针
.insn_cnt = insn_cnt, //有多少条指令
.license = ptr_to_u64(license), //指向整数字符串的指针
.log_buf = ptr_to_u64(bpf_log_buf), //log输出缓冲区
.log_size = LOG_BUF_SIZE, //log缓冲区大小
.log_level = 2, //log等级
};
return bpf(BPF_PROG_LOAD, &attr, sizeof(attr));
}
//保存BPF程序
struct bpf_insn bpf_prog[0x100];
int main(int argc, char **argv){
//先从文件中读入BPF指令
int text_len = atoi(argv[2]);
int file = open(argv[1], O_RDONLY);
if(read(file, (void *)bpf_prog, text_len)<0){
perror("read prog fail");
exit(-1);
}
close(file);
//把BPF程序加载进入内核, 注意这里程序类型一定要是BPF_PROG_TYPE_TRACEPOINT, 表示BPF程序用于内核中预定义的追踪点
int prog_fd = bpf_prog_load(BPF_PROG_TYPE_TRACEPOINT, bpf_prog, text_len/sizeof(bpf_prog[0]), "GPL");
printf("%s\n", bpf_log_buf);
if(prog_fd<0){
perror("BPF load prog");
exit(-1);
}
printf("prog_fd: %d\n", prog_fd);
//设置一个perf事件属性的对象
struct perf_event_attr attr = {};
attr.type = PERF_TYPE_TRACEPOINT; //跟踪点类型
attr.sample_type = PERF_SAMPLE_RAW; //记录其他数据, 通常由跟踪点事件返回
attr.sample_period = 1; //每次事件发送都进行取样
attr.wakeup_events = 1; //每次取样都唤醒
attr.config = 678; // 观测进入execve的事件, 来自于: /sys/kernel/debug/tracing/events/syscalls/sys_enter_execve/id
//开启一个事件观测, 跟踪所有进程, group_fd为-1表示不启用事件组
int efd = perf_event_open(&attr, -1/*pid*/, 0/*cpu*/, -1/*group_fd*/, 0);
if(efd<0){
perror("perf event open error");
exit(-1);
}
printf("efd: %d\n", efd);
ioctl(efd, PERF_EVENT_IOC_RESET, 0); //重置事件观测
ioctl(efd, PERF_EVENT_IOC_ENABLE, 0); //启动事件观测
if(ioctl(efd, PERF_EVENT_IOC_SET_BPF, prog_fd)<0){ //把BPF程序附着到此事件上
perror("ioctl event set bpf error");
exit(-1);
}
//程序不能立即退出, 不然BPF程序会被卸载
getchar();
}
运行效果如图
回到HelloWorld
至此, 再让我们回顾一下<<linux内核观测技术BPF>>一书中的HelloWorld, BPF程序如下. 其通过段名来表示这个BPF程序要附着到哪里
//clang -O2 -target bpf -c ./bpf.c -o bpf.o
#include <linux/bpf.h>
#define SEC(NAME) __attribute((section(NAME), used)) //设置段属性, 表示把某一变量或者函数放到ELF文件中名为NAME的段中
//bpf_trace_printk()被编译为内核的一部分,永远不会被编译到你的 BPF 目标文件中。当尝试加载您的程序时,该函数会load_bpf_file()执行一个重定位步骤,
static int (*bpf_trace_printk)(const char *fmt, int fmt_size, ...) = (void *) BPF_FUNC_trace_printk;
//把bpf_prog编译到名为tracepoint/syscalls/sys_enter_execve的段中
SEC("tracepoint/syscalls/sys_enter_execve")
int bpf_prog(void* ctx){
char msg[] = "Hello";
bpf_trace_printk(msg, sizeof(msg)); //在内核跟踪日志中打印消息
return 0;
}
//程序许可证, 为了与内核兼容
char _license[] SEC("license") = "GPL";
接着是最令人困惑的loader程序, 由于引用了bpf_load.c中的两个函数, 因此先分析这两个函数的源码. 要注意此时加载的编译出来的ELF格式的目标文件, 不再是单纯的指令
#include <stdio.h>
#include "bpf_load.h"
int main(int argc, char **argv){
if(load_bpf_file(argv[1])!=0){
printf("error\n");
}
read_trace_pipe();
}
load_bpf_file()源码分析
load_bpf_file()会直接进入do_load_bpf_file()
int load_bpf_file(char *path)
{
return do_load_bpf_file(path, NULL);
}
do_load_bpf_file()的加载ELF格式的目标文件后, 会进行三次扫描, 第一次扫描证书与映射相关的段. 第二次扫描为BPF映射重写某些BPF指令, 第三次扫描则为了加载BPF程序. 我们重点关注第三次的
static int do_load_bpf_file(const char *path, fixup_map_cb fixup_map)
{
int fd, i, ret, maps_shndx = -1, strtabidx = -1;
Elf *elf;
GElf_Ehdr ehdr;
GElf_Shdr shdr, shdr_prog;
Elf_Data *data, *data_prog, *data_maps = NULL, *symbols = NULL;
char *shname, *shname_prog;
int nr_maps = 0;
/* reset global variables */
kern_version = 0;
memset(license, 0, sizeof(license));
memset(processed_sec, 0, sizeof(processed_sec));
if (elf_version(EV_CURRENT) == EV_NONE)
return 1;
//打开文件
fd = open(path, O_RDONLY, 0);
if (fd < 0)
return 1;
//解析ELF格式
elf = elf_begin(fd, ELF_C_READ, NULL);
...;
/* 遍历elf文件的所有段以获取license和BPF映射的信息, */
for (i = 1; i < ehdr.e_shnum; i++) {
...;
}
/* 遍历所有的只读段, 并为BPF映射重写一些bpf指令 */
for (i = 1; i < ehdr.e_shnum; i++) {
...;
}
/* 加载程序 */
for (i = 1; i < ehdr.e_shnum; i++) {
if (processed_sec[i])
continue;
if (get_sec(elf, i, &ehdr, &shname, &shdr, &data)) //获取这个段
continue;
//下列字符串表示要追踪的事件类型
//如果段名是有效的事件类型, 那么就会进入load_and_attach(), 把这个段中的BPF指令加载进入内核, 并附加到指定事件上
//bpf.o中设置bpf_prog()函数所在段名为"tracepoint/syscalls/sys_enter_execve", 因此会进入load_and_attach()
if (memcmp(shname, "kprobe/", 7) == 0 ||
memcmp(shname, "kretprobe/", 10) == 0 ||
memcmp(shname, "tracepoint/", 11) == 0 ||
memcmp(shname, "raw_tracepoint/", 15) == 0 ||
memcmp(shname, "xdp", 3) == 0 ||
memcmp(shname, "perf_event", 10) == 0 ||
memcmp(shname, "socket", 6) == 0 ||
memcmp(shname, "cgroup/", 7) == 0 ||
memcmp(shname, "sockops", 7) == 0 ||
memcmp(shname, "sk_skb", 6) == 0 ||
memcmp(shname, "sk_msg", 6) == 0) {
ret = load_and_attach(shname, data->d_buf,data->d_size);
if (ret != 0)
goto done;
}
}
...;
}
对于load_and_attach(), do_load_bpf_file()传入的段名就是要附着的事件名, 段中的内容就是eBPF指令数组, 段的长度就是以字节为单位的BPF程序的长度.
load_and_attach()首先根据段名解析出段的类型, 并调用bpf_load_program()把BPF程序注入内核, 这个在之前已经说过
static int load_and_attach(const char* event, struct bpf_insn* prog, int size)
{
//首先判断是哪种事件类型
bool is_socket = strncmp(event, "socket", 6) == 0;
bool is_kprobe = strncmp(event, "kprobe/", 7) == 0;
bool is_kretprobe = strncmp(event, "kretprobe/", 10) == 0;
bool is_tracepoint = strncmp(event, "tracepoint/", 11) == 0; //对本BPF程序属于这种
...;
//计算有多少条指令
size_t insns_cnt = size / sizeof(struct bpf_insn);
enum bpf_prog_type prog_type;
char buf[256];
int fd, efd, err, id;
//设置要观测事件的属性
struct perf_event_attr attr = {};
attr.type = PERF_TYPE_TRACEPOINT; //默认为追踪点
attr.sample_type = PERF_SAMPLE_RAW;
attr.sample_period = 1; //每次触发都取样
attr.wakeup_events = 1; //每次取样都触发
//根据事件类型设置prog_type变量, 之后进行bpf系统调用加载程序时会用到
if (is_socket) {
prog_type = BPF_PROG_TYPE_SOCKET_FILTER;
} else if (is_kprobe || is_kretprobe) {
prog_type = BPF_PROG_TYPE_KPROBE;
} else if (is_tracepoint) { //对本BPF程序属于这种
prog_type = BPF_PROG_TYPE_TRACEPOINT;
} else if (is_raw_tracepoint) {
...
} else {
printf("Unknown event '%s'\n", event);
return -1;
}
...
//进行bpf系统调用, 把BPF程序加载如内核中
fd = bpf_load_program(prog_type, prog, insns_cnt, license, kern_version, bpf_log_buf, BPF_LOG_BUF_SIZE);
接下来load_and_attach()根据段名中要观测的事件, 通过debugfs获取跟踪点的id, 这一步在例2中是手动完成的
//根据要观测事件, 构造debugfs路径, 获取事件的id
if (is_kprobe || is_kretprobe) {
...;
} else if (is_tracepoint) {
//bpf.o中bpf_prog()函数所在段名为"tracepoint/syscalls/sys_enter_execve", 这是为了跳过前缀"tracepoint/"
event += 11;
if (*event == 0) {
printf("event name cannot be empty\n");
return -1;
}
strcpy(buf, DEBUGFS); //DEBUGFS为:"/sys/kernel/debug/tracing/"
strcat(buf, "events/"); //buf = "/sys/kernel/debug/tracing/events"
strcat(buf, event); //buf = "/sys/kernel/debug/tracing/events/syscalls/sys_enter_execve"
strcat(buf, "/id"); //buf = "/sys/kernel/debug/tracing/events/syscalls/sys_enter_execve/id"
}
efd = open(buf, O_RDONLY, 0); //打开debugfs中获取跟踪点对应的文件
if (efd < 0) {
printf("failed to open event %s\n", event);
return -1;
}
err = read(efd, buf, sizeof(buf)); //读入文件内容, 获取字符串格式的跟踪点id
if (err < 0 || err >= sizeof(buf)) {
printf("read from '%s' failed '%s'\n", event, strerror(errno));
return -1;
}
close(efd);
//用跟踪点id设置事件属性的config
buf[err] = 0;
id = atoi(buf);
attr.config = id;
接下来调用perf_event_open()打开要观测事件, 启动后把BPF程序附着上去, 这样当事件被触发时就会调用对应的BPF程序
efd = sys_perf_event_open(&attr, -1 /*pid*/, 0 /*cpu*/, -1 /*group_fd*/, 0); //打开观测事件的fd
...;
err = ioctl(efd, PERF_EVENT_IOC_ENABLE, 0); //启动此观测事件
...;
err = ioctl(efd, PERF_EVENT_IOC_SET_BPF, fd); //把对应BPF程序附着到观测的事件上
...;
return 0;
}
read_trace_pipe()源码分析
read_trace_pipe()就简单许多, 循环打印内核跟踪日志/sys/kernel/debug/tracing/trace_pipe
void read_trace_pipe(void)
{
int trace_fd;
trace_fd = open(DEBUGFS "trace_pipe", O_RDONLY, 0); //打开/sys/kernel/debug/tracing/trace_pipe文件
if (trace_fd < 0)
return;
while (1) { //循环输出文件内容
static char buf[4096];
ssize_t sz;
sz = read(trace_fd, buf, sizeof(buf) - 1);
if (sz > 0) {
buf[sz] = 0;
puts(buf);
}
}
}
总结
我们可以发现, HelloWorld程序中引入的bpf_load.c不过是把我们之前手动的一些操作自动化, 其原理仍为: 编译BPF指令, bpf()把BPF程序加载入内核, perf_event_open()挂载BPF程序到具体事件. 令人劝退的HelloWorld页不再劝退
至此我们已经自底向上的了解了BPF如何使用, 利用的第一步是熟悉, 接下来会进一步探究BPF虚拟机实现的原理, 为后续利用进行铺垫.