
前言
在授权测试网站时,若是遇到了 .git 文件泄露。相信大家都是直接上工具一把梭把项目还原,然后直接白盒审计开干。可是是否有了解过 .git 的文件系统和格式呢?本文就来简单分析下 .git文件泄露利用工具是如何工作的。不过在开始前,需要先对 git 有个了解。
.git目录文件结构
这里仅列出我们 git还原 时 需要的重点目录和文件:
├── HEAD — 当前 branch 指针。一般指向 refs/heads/ 里的 branch
├── index — 当前branch 项目文件的 map
├── logs — 日志目录
│ ├── HEAD — 日志记录
├── objects — 项目文件目录
│ ├── info — pack文件指针(通常在客户端)
│ └── pack — pack文件目录
└── refs — branch 和 tags 目录
├── heads — 存放各个 branches 的指针
├── stash — 存放 stash文件
了解git
引用官方文档的 解释:
Git 是一个内容寻址文件系统,听起来很酷。但这是什么意思呢? 这意味着,Git 的核心部分是一个简单的键值对数据库(key-value data store)。 你可以向 Git 仓库中插入任意类型的内容,它会返回一个唯一的键,通过该键可以在任意时刻再次取回该内容。
在开始分析 git 之前,首先得先知道 git 仓库中的一些术语:
-
Object(对象) 在 git 中,存储的数据将会保存至
.git/objects目录下,内容经过 zlib 压缩,并且文件名使用 SHA1 Hash 命名。 - Blob(数据对象) 在 git 中,源文件内容在 git 中的表现形式。
- Tree object(树对象) 类似于一个目录 map,用于指向 blobs 和其他 tree objects
- Commit object(提交对象) 用于指向一个 tree object,并且包含 commit author 和 parent commits
- Tag object(标签对象) 用于指向一个 commit object,并且包含一些数据
-
Reference 用于指向单个 object。通常是一个 commit 或是一个 tag。存放在
.git/refs/目录下
小试牛刀
单个 commit
(1) 使用命令 git init 创建一个 git 仓库,会在当前目录下生成一个 .git 文件夹
/var/www/html/testgit
$ git init
Initialized empty Git repository in /var/www/html/testgit/.git/
/var/www/html/testgit
$ ls -la
total 12
drwxr-xr-x 3 xp xp 4096 Mar 26 23:29 .
drwxr-xr-x 17 xp xp 4096 Mar 25 16:18 ..
drwxr-xr-x 7 xp xp 4096 Mar 26 23:29 .git(2)使用命令 echo value1 > t1.txt 新建一个文件
(3) 使用命令 git add . 将 更改 写入 .git/index 中 (这里的更改指:对文件的新增、修改、删除 操作)
此时查看 .git/index ,发现已经将 t1.txt 存入。
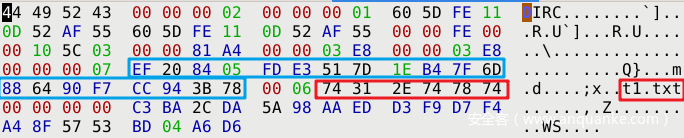
这里 index 文件内容看不懂没关系,后文会解析 index 文件结构。上图我们先注意 红框 和 蓝框 的值
继续探究 .git 目录,发现此时新增了一个 .git/objects/ef/20... 文件
对照上图可以发现这个 文件夹名 ef 和 文件名 20… 就是上图中 蓝框部分
由于这些文件都是 zlib 压缩过的,所以我们需要使用 zlib 解压出来。
使用命令 zlib_decompress 压缩文件名 解压后文件名,将该文件解压后读取。
blob object,文件开头写明类型是一个 blob,存放着 源文件 的内容
(4) 使用命令 git commit -m "update",将 更改 提交到一个新版本。
查看 .git/index,发现多了一个 TREE:

同时 .git/refs/heads/master 的值改变
$ cat master
0217860c7ea88435e37b65c4e0dd6d43f7fb0930在 .git/objects 下发现多了两个文件夹 02 和 65
$ ls
0265 ef info pack由于 /refs/heads/master 指向的是 0217...,所以我们优先查看 0271... 的文件内容:
commit object,文件开头写明类型是一个 commit。指向一个 tree object,SHA1 Hash 为 6533...
commit 161tree 6533c8092d36a63fa6fcb003ae656c6b425a3faf
author xp <xp@debianx.localdomain> 1616773555+0800
committer xp <xp@debianx.localdomain> 1616773555+0800
update指向的 SHA1 Hash 恰好正是在 .git/objects 下新增的另一个文件,查看 6533... 的文件内容:
tree object,文件开头写明类型是一个 tree。存放的是 git 项目的目录结构,文件后面有些乱码,乱码部分正是 blob object 的位置
$ catsource
tree 34100644 t1.txt� ���Q}�m�d��̔;x
(5) 查看 logs 日志,位置在 /.git/logs/HEAD。发现新的 commit 被记录。并且记录值中有 commit object 的 SHA1 Hash。
0000... 0217...... xp <xp@debianx.localdomain> 1616773555+0800commit (initial): update至此,一个最简单的 commit 已基本分析完毕。得出流程:
- 当使用
git add .时,在objects下新增一个 blob object;index文件内容 新增一个 blob object 的位置 - 当使用
git commit时,在objects下新增 tree object 和 commit object,其中指向关系为:
- 更新
index文件 - 记录 log日志。日志内容包含
commit object
总结这个流程:我们可以得出,源文件的内容被保存在 blob obejct 中,若想定位 blob object文件位置,按照 git 的原理,需要经过 commit object 和 tree object 才能定位到 blob obejct
多个 commit
上文演示的就只是一个 commit,那如果有多个 commit,指针(尤其是 .git/refs/heads/master)会如何表现呢?
在测试项目中使用 echo value2 > t2.txt 生成一个新文件。并使用 git add . 和 git commit 进行提交。
提交完毕后查看 refs/heads/master:
$ cat master
8ff0b11444a3960f4320ce690029d4c8a6f6c966根据前文得出的 指向关系,refs/heads/master 指向的是一个 commit。查看该 commit 内容:
commit 209tree dc3b76e70a3936c0d976a1e07f865355da613caa
parent 0217860c7ea88435e37b65c4e0dd6d43f7fb0930
author xp <xp@debianx.localdomain> 1616812227+0800
committer xp <xp@debianx.localdomain> 1616812227+0800
update发现当 git中有多个commit时,commit object 不仅指向 tree object(第一行),还指向它的父级commit object(第二行)
查看指向的 tree object dc3b…。tree object 功能就是存放各个 blob 的位置关系。

若是继续对应着找到 blob,就能看到源文件的内容了。
拓展:
若存在文件夹,tree object 是如何存放的呢?
在测试项目中输入命令:
$ mkdir d1
$ mkdir d2
$ mkdir d1/d1_1
$ echo valued1_1 > d1/d1_1/dv1.txt
$ echo valued2 > d2/dv2.txt
$ git add .
$ git commit -m"udpate"直接对着 refs/heads/master 的值找到 commit object ,接着找到 tree object。发现其格式长这样:
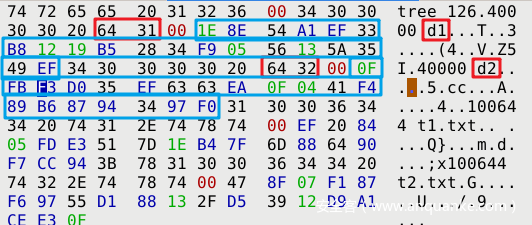
跟着追踪 d1 的 SHA1 HASH。发现这也是是一个 tree object

再次追踪 d1_1 的 SHA1 HASH。由于其是一个目录,自然也是一个 tree object。

综上所述可以得出结论:多层目录就是靠父 tree object 指向子 tree object 来实现的。
偷个官方图:
存在 branch 的情况
一个常规项目中,通常都会有多个 branch 的存在。branch 即项目分支,初始的 git 项目默认的 branch 就是 master。多个分支可以让项目扩展性更强。
举几个例子:一个项目可以划分2个分支,一个用于生产环境,一个用于测试环境。平时开发的代码就提交到测试环境中。当测试调试完毕后,便可将测试环境分支与生产环境分支合并。是项目更易维护和扩展。
或者有些项目中又分开了好几个小项目,但是只想使用一个 git 进行管理。就可以使用分支来进行分类管理。
简单使用 branch:
首先当前我们的测试项目文件夹结构如下:
将当前的项目新开一个分支:
$git branch program_1查看分支:
$git branch
* master
program_1此时,program_1 和 master 就是两个不同的分支了。master 左边的 星号 代表当前分支。
此时去查看 /refs/heads/ 下的文件,会发现多了一个名为 program_1 的指针文件
$ ls
master program_1再创建一个文件 echo v1 > master_new1.txt。然后 git add .git commit。然后查看 /refs/heads/ 下的文件:
/var/www/html/testgit/.git/refs/heads
$ cat master
7be8f938e8cc517a448e54b81b20a2f023ed5f07/var/www/html/testgit/.git/refs/heads
$ cat program_1
eae414f0eb9308948fd287fbcbe5c468bceaf7f5各自对应的 tree object
[master]
$ strings zlib_decode
tree 169
40000 d1
40000 d2
100644 master_new1.txt
100644 t1.txt
;x100644 t2.txt
[program_1]
$ strings zlib_decode
tree 126
40000 d1
40000 d2
100644 t1.txt
;x100644 t2.txt可以发现,不同分支是互不影响的,master 分支下新建的文件不会被 program_1 分支记录
再去看看 log日志,发现 log日志不区分branch,存放着所有的 commit object SHA1 Hash

切换 branch
使用命令 git checkout program_1。将当前分支切换至 master 上。
此时查看测试项目下的文件,发现在 master 分支中创建的文件已经消失:
$ ls
d1 d2 t1.txt t2.txt查看 .git/HEAD 文件,这个文件也是个指针文件,用来指明当前的分支。当前指向正是 program_1
$ cat HEAD
ref: refs/heads/program_1综上所述,可以对 branch 做个简单的小结:
各个 branch 的指针文件存放在 /refs/heads 下。并且互不干扰。每个 branch 仅记录其自身的 tree object 和 blob object。但是 logs/HEAD 日志将会记录所有的 commit object 的 SHA1 Hash。
index文件结构解析
前文都是在学习 git 存储源文件的原理,使用 commit object、tree object 最终定位到 blob object。blob object 就是源文件的内容。
而这一节,我们直接解析 .git/index 文件,文章开过说过,index 是 当前 branch 的 blob object map 。我们是否可以直接通过解析 index 文件来定位到 当前 branch 的所有 blob object 呢?
答案是可以的,我们直接看 index 文件也能发现 blob object 的原始文件名的存在:

想要解析 index 文件,就得先学学其文件结构和格式。
这一部分参考了许多 Git: Understanding the Index File 的内容。如果我们只是单纯的是想靠解析 index 来定位所有的 blob objects的话,也没必要解析的太细,仅需知道哪个位是我们需要的位即可。
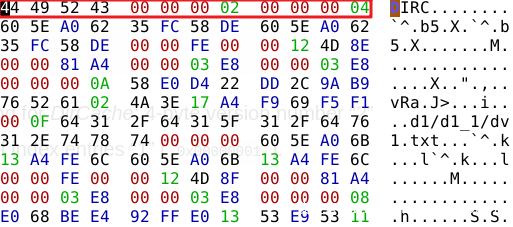
Header
index 文件开头是一个 12字节 的 header,其中 前4字节 是固定的,值为”DIRC”。中间4字节 是版本号。后面4字节 为该 index 包含的 Entry 数量
Index Entry
这个数据存放当前 git 分支中 blob object 的信息。若我们只是为了定位 blob object 位置的话,其中有很多无用数据,但是为了能够解析 index 文件,我们还是需要了解的。
首先是 8字节 的 ctime 和 8字节 的 mtime。用于表示该文件几时创建几时修改。这个并不重要
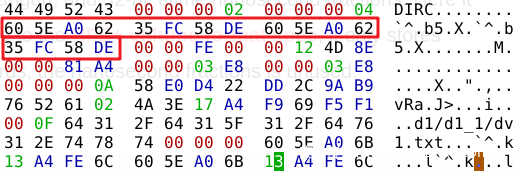
接下来是 4字节 的 dev 和 4字节 的 ino 以及4字节 的 mode(表示文件权限)。也并不重要
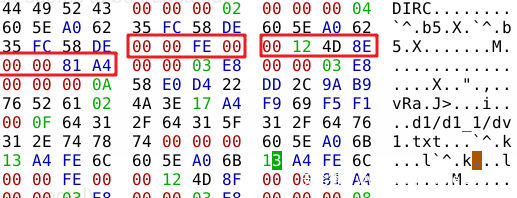
接下来是 4字节 的 uid 和 4字节 的 gid 以及 4字节 的 文件大小。并不重要

接下来的就是重要内容了。20字节 的 SHA1 Hash Object ID。可帮助我们定位 blob object
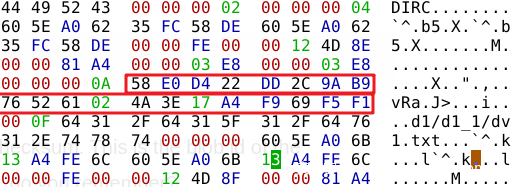
根据前文,我们可以知道这段 SHA1 Hash ID 对应的文件为 objects/58/e0d422dd2c9ab9765261024a3e17a4f969f5f1。
接下来是 2字节 的 flags

最后就是源文件名称,长度不限,最后以 00 结尾。
注意:为了数据对齐,需要凑3个00。
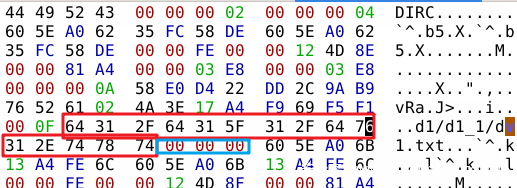
至此,一个完整的 blob object 信息就包括以上的内容。若存在多个 blob object。则将会在上一个 blob object 的 00 字节之后继续重复上文的结构。
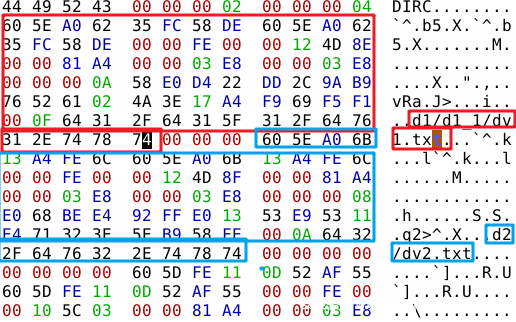
以上就是一个 index entry 的结构。一个 index entry 对应 一个 blob object
Extension: Cache Tree
Index Entry 的数据段的后面,接着就是 Extension 的段。这一个数据段中比较重要的就是 Cache Tree。
由于前文的 index entry 没有存储目录结构, Cache Tree 便承担了描述目录结构的工作。
header
该数据段开头为 4字节 固定字符 “TREE”
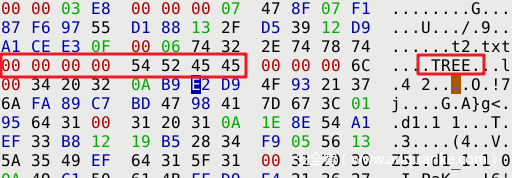
ps:这里往后图是补的,数据可能和上面的有些出入。不过这里我们主要目的是了解结构,数据有出入不太影响
之后 4字节 为 Cache Tree 段的长度。这里长度为 6C。整个 Cache Tree 的范围如图所示
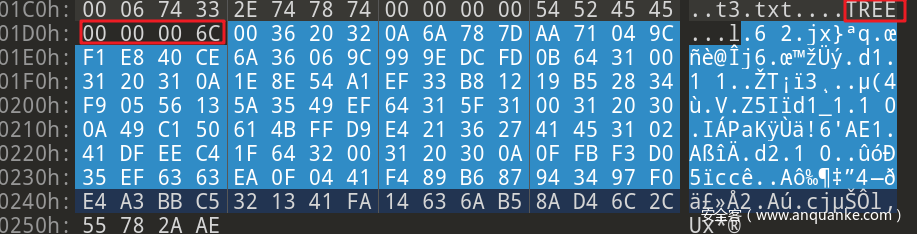
在这个范围中是 Cache Tree 的主体内容 (entries):
path component
这个区域放的是目录名,但由于 Cache Tree 开头放的是根目录,所以这里是空的,非根目录将会显示其目录名。非根目录会在下文提到。
Number
通过 \x00 隔开前面的字符。第1个字节 表示该目录下存在多少个 entry,也就是 object 的数量;随后使用 空格(\x20) 进行分割, 第2个字节 表示该目录下有多少个子目录。
ps:解析这两个字节时,不需要进行十六进制与十进制的转换。直接解析该十六进制对应的字符即可
在这个例子中我们可以得知,第一个字节对应的是 字符6,第二个字节对应的是 字符2。也就是说 该目录下存在 6个entry,2个子目录。

path
通过 \x0a 隔开前面的字符,后面 20个字节 为该 Tree object 的 SHA1 Hash Object ID。

验证一下,发现该 Object ID 确实对应着 Tree object:
$ cd .git/objects/6a
$ zlib_decompress 787daa71049cf1e840ce6a36069c999edcfd0b source
$ catsource
tree 195100644222.txt......至此。Cache Tree的结构解析完毕。接下来的 Cache Tree entries 的解析也是如法炮制即可。注意接下来的 entries 不是根目录而是子目录,path component 段将存放子目录的名字:

至此,大致的 index文件结构分析完毕。我们可以通过解析 Index Entry 段来获取各个 blob object 的存储位置。
pack文件结构解析
在学习 pack 文件结构之前,我们得先了解下 pack 文件是什么,以及如何生成的。
产生方式
pack 文件类似于一个压缩包,可以把 objects/ 下的 各个 object 打包进一个 pack 文件中。object 的数据存储也是使用 zlib 压缩的方式。
触发 git 生成 pack 文件的方式有两种:
-
git gc命令打包文件 - 当项目文件很多很大时,
git push项目到远程服务器时
git gc 命令打包文件
在测试项目中执行命令 git gc。即可自动将当前的 objects 打包。
打包完毕后,会在 objects/info 下生成一个 packs 指针文件。指向其对应的 pack 文件名
P pack-7fa98ff75e506caa53df2208549ea663f5bdb08e.pack真正的 pack 文件位于 objects/pack/ 下。此处存在两个文件:”idx文件”(可以理解为 pack的索引文件) 和 “pack文件”(被压缩打包的所有 obejcts)。
$ ls
pack-7fa98ff75e506caa53df2208549ea663f5bdb08e.idx
pack-7fa98ff75e506caa53df2208549ea663f5bdb08e.pack打包之后, branch 指针文件将存放在 .git/info/refs 中
$ cat refs
dd75afa5e9830021be45f644297e5193ed930959refs/heads/masterpush到远程服务器时自动打包
当使用 git push 时,若项目文件很多很大,git 为了方便传输,会将所有的 objects 打包进 pack 文件中,远程推送时仅发送 idx 和 pack 文件即可。
运行以下命令:
#创建一个 git 仓库,作为“远程”仓库使用
~/Templates
$ git init --bare sample.git
$ mkdir client
$ cd client
#切换到另一个目录下,clone “远程”仓库
~/Templates/client ⌚ 23:21:31
$ git clone ~/Templates/sample.git
$ cd sample/
#随便拷贝一个大项目过来。使得git项目文件很多很大,只有这样 git 在远程推送时才会自动打包
~/Templates/client/sample
$ cp-r /var/www/html/mybb/mybb-mybb_1825/* ./
$ git add .
$ git commit -m update
$ git push运行完毕后,查看客户端的 .git/objects 。会发现 objects 下都是 objects的 “散装文件”
$ ls
00 0f 1e 2c ......再去 “远程”仓库下查看 .git/objects。发现只有 objects/pack 下有 idx 和 pack 文件。而 info 下并没有指针文件。
尝试还原 pack文件
假设我们仅得到一个 pack文件,该如何还原?
首先,我们需要一个空目录,接着在这目录下使用命令 git init 初始化 git 项目
接着使用命令 git unpack-objects < pack-....pack 进行还原:
/xxx/
$ git init
/xxx/
$ unpack-objects < pack-....pack
/xxx/.git/objects
$ ls
00 0f 1e...注意:该命令仅将 pack 还原成 object,并没用将 object 还原成源文件
pack-*.idx 文件结构
该文件是 pack 的索引文件,存放着 被压缩的 objects 在 pack 文件中的偏移值等信息。
编辑器名字为 010 Editor
首先前 4字节 是固定格式:FF 74 4F 63。
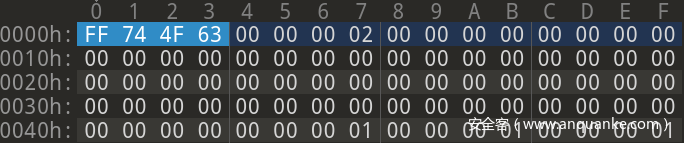
接下来是 4字节 的 版本号。git 创建默认的是 2
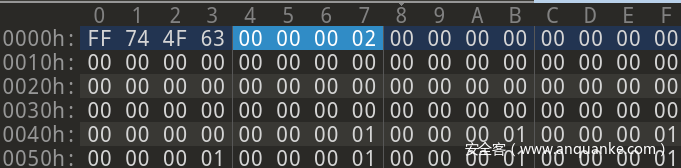
接下来是 256 个 4字节 的 “网络字节序整数”。
前面有了 8字节 的数据,再加上个 1024字节 的字节序,换算成十六进制,1032 为 408。所以 字节序 的范围为 0008h – 0407h
可以发现,字节序 结束的那一个字节,写明了当前 idx文件 中包含着多少个 object 的信息。Demo 中为 9

接下来是所谓的 object names。 每个占 20字节。数量为9个,也就是 字节序 结束的字节中写明的数量
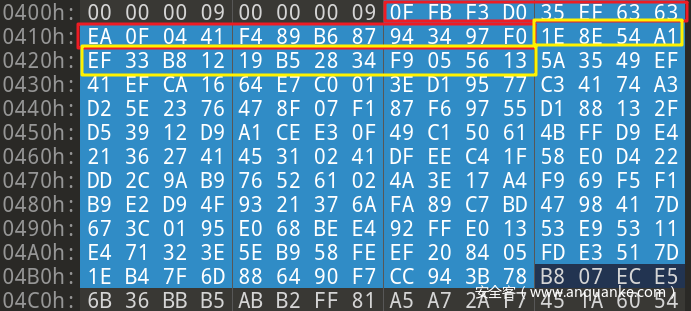
接下来是 CRC,每个占 4字节,数量也是9个。

重点。接下来这个是每个 object 在 pack文件中的偏移量。每个占 4字节,数量 9 个
备注:手册上说若 pack 文件大于 2G,则会有一个 8字节 偏移值

接下来是 20字节的 pack文件校验和 和 20字节 idx文件校验和

至此,整个 idx文件结构解析完毕。idx文件对于我们来说最有用的部分就是 记录了 object 在 pack文件中的偏移值 那一块。这点我们在接下来解析 pack文件时会详细说。
pack-*.pack 文件结构
开始解析 pack文件之前,补充一个小知识:\x78 是 zlib文件格式的开头。
header
首先,pack 开头 4字节 为固定字符 “PACK”;中间 4字节 为版本号,默认为2; 最后 4字节 为 obejcts 数量,这里是 9。
object entries
该数据段存放的是 obejct 相关信息 及 其被 zlib 压缩后的内容。
接下来的分析就要结合 idx文件进行分析了。前文提到过,idx文件中记录了 每个 obejct 在 pack文件中的偏移值。
我们再去翻一下 idx文件 记录偏移值的那一块数据:

根据 idx的文件结构,每 4字节 代表着一个 object 在 pack文件中的偏移。所以我们可以整理出如下的偏移值,并手动从低到高进行排序。
ps:h 表示 16进制的意思
根据以上整理好的偏移值可以得知:
第一个 object 开头在 pack 文件的 0ch 处,换成十进制也就是 12。刚好就在 pack文件的 header 后面。
第一个 object 结束在 pack 文件的 92h-1h 处,因为 92h 是第二个 obejct 的开头
所以第一个 Object 段 在 pack文件中的位置为:

但这一部分并不是全都是被 zlib压缩的 Object 数据。这一小节的开头提到过, zlib格式的开头是 \x78。而这一段的开头是 \x91\x0a。
representation
想要解析这个段值的含义,我们得将其转换成二进制:
\x91 \x0a
1001000100001010
MSB type length LSB其中,第1位为 MSB 位,全称 “最高有效位(most significant bit) ”。不过咱也不是很懂。。就先放着先吧。。
之后 3位 为 type 位。type的值有如下的定义:
所以我们这个 obejct 的类型为 commit
往后 11位 为 length位。官方给了个公式来计算 length位的长度: (n-1)*7+4(n为字节数,这个例子中字节数为 2)
最后1位 应该是 LSB位,全称 “最低有效字节(least significant byte)”。暂时也不太了解这个的作用。。
总结一下:该数据包含了 4个部分,其中对我们来说有用的是 type位。
ps:官方手册提到,这段数据是不定长的。所以确定 representation 的尽头需要靠 zlib的固定标头 \x78
Deltified representation
这一个数据段为被 zlib 压缩后的数据。我们可以将之导出,然后用 zlib 还原验证:
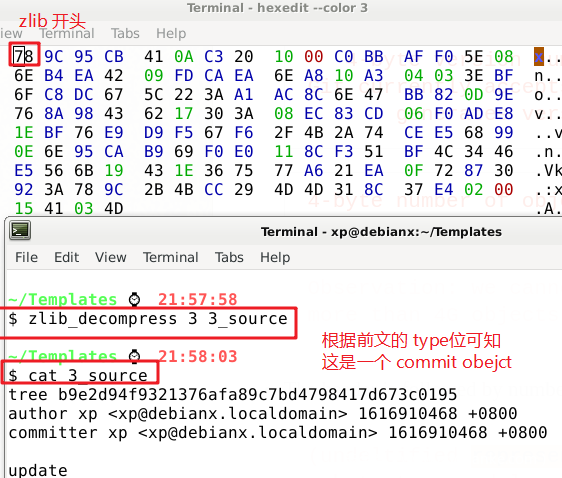
至此,这就是一整个完整的 object entries 数据段了。接下来分析剩下的 object entries 时如法炮制即可。
总结 一下:pack文件 除了 header 段,剩下的都是 representation段,存放的都是 object 的信息。
.git泄露利用
手工还原
如果目标网站没有禁用目录浏览的话,我们是可以将其全部爬取下来,然后用 git 命令还原。这样子是最完整的。
工具还原
这里我们对比两种常见的 git泄露还原工具:GitHack 和 Git_Extract。项目地址在文末。
GitHack
程序结构:
classScanner(object):
........
if__name__ == '__main__':
s = Scanner()
s.scan()
......代码很简洁,先实例化了 Scanner类来进行扫描。跟进看看。
首先下载 index 文件
data = self._request_data(sys.argv[-1] +'/index')
withopen('index', 'wb') asf:
f.write(data)之后调用 parse() 函数对 index 文件进行解析。
forentryinparse('index'):
if"sha1"inentry.keys():
self.queue.put((entry["sha1"].strip(), entry["name"].strip()))
try:
printentry['name']
exceptExceptionase:
passparse() 函数的解析方法就是根据前文 index 的格式 来进行解析,通过解析 index entry,抓取 blob objects 的路径。最后通过 yield 关键字将 SHA1 Hash object ID 返回回来
......
index = collections.OrderedDict()
# 4字节的 "DIRC"
index["signature"] = f.read(4).decode("ascii")
# 4字节的 version
index["version"] = read("I")
# 4字节的 index entry数量
index["entries"] = read("I")
yieldindex
#解析每个 index entry 对应的信息
forninrange(index["entries"]):
......
#获取20字节的 SHA1 Hash Object ID
entry["sha1"] = binascii.hexlify(f.read(20)).decode("ascii")
......随后开启多线程调用 get_back_file() 方法,根据解析 index 获取到的 SHA1 Hash object ID,下载对应的文件,并进行 zlib 解压和还原
sha1, file_name = self.queue.get(timeout=0.5)
#根据 SHA1 Hash Object ID 下载对应的 blob object
folder = '/objects/%s/'%sha1[:2]
data = self._request_data(self.base_url+folder+sha1[2:])
data = zlib.decompress(data)
#把文件内容从 blob object 中挑出来
data = re.sub(r'blob \d+\00', '', data)
target_dir = os.path.join(self.domain, os.path.dirname(file_name))
#将blob object 中的文件内容写入文件中
iftarget_dirandnotos.path.exists(target_dir):
os.makedirs(target_dir)
withopen(os.path.join(self.domain, file_name), 'wb') asf:
f.write(data)至此,便可通过 Web泄露的 .git 来还原原始项目了:
$ ls
d1 d2 t1.txt t2.txt总结:该工具是通过解析 index 文件来 下载 blob object 来还原 源文件。
Git_Extract
这款工具不一样的地方在于,可下载 非当前 branch 的文件。
我们来简单分析下它的源码:
程序结构:
__author__ = 'gakki429'
classGitExtract(object):
......
if__name__ == '__main__':
iflen(sys.argv) == 2:
GIT_HOST = sys.argv[1]
Git = GitExtract(GIT_HOST)
Git.git_init()
else:
_print('Usage:\n\tpython {} http://example.com/.git/'.format((sys.argv[0])), 'red')首先该工具初始化了 GitExtract 类。在构造方法中判断是否正确使用程序,接着创建一个文件夹,用于存放一会儿还原的文件。
接着调用了 git_init() 方法,该方法如下:
defgit_init(self):
self.git_parse_pack()
self.git_head()
self.git_logs()
self.git_index_cache()
self.git_stash()
self.git_other()
_print('[*] Extract Done')(1) 通过 pack文件还原
git_init 首先调用 git_parse_pack() 函数尝试解析 pack文件
ps:具体的代码解析操作就不贴出来了,不然就太长了
[git_extract.pyline223]
defgit_parse_pack(self):
#仅根据 objects/info/packs 来找 pack文件
pack_path = 'objects/info/packs'
packs = self.download_file(pack_path)
packs_hash = re.findall(r'P pack-([a-z0-9]{40}).pack', packs, re.S|re.M)
forpack_hashinpacks_hash:
#下载 idx 和 pack文件进行解析
pack = GitPack(self.git_path, pack_hash)
self.download_file(pack.idx_path)
self.download_file(pack.pack_path, big_file=True)
pack.pack_init()
[git_pack.py]
defpack_init(self):
#解析 pack 和 idx文件
self.pack_header()
self.idx_header()
self.extract_pack()
#将解析结果输出至 objects 目录下
self.pack_to_object_file()
[git_extract.pyline236]
defgit_parse_pack(self):
#通过解析 info/refs 这一 branch 指针文件,得到 commit SHA1 Hash Object ID。便于将 object 还原成 源文件
self.git_parse_info_refs()
......
#将解析各个 object 并将 blob object 还原成 源文件
self.git_extract_by_hash('\n'.join(unparse_hash), ['commit', 'tag'])这里提一点:由于 pack文件的文件名很长,所以若不是允许目录浏览的话,没法爆破到 objects/pack/ 里的文件。所以该工具只能对能够确定目录的 objects/info/packs 进行解析,再间接找到 objects/pack 里的文件。
但是假设开放了目录浏览,那其实我们可以手动下载 .git 所有内容,然后用 git 命令还原即可。
(2)通过 log文件 还原
git_init 接着调用 git_head() 函数尝试解析 head文件,该文件也是 branch指针文件
[git_extract.pyline163]
defgit_head(self):
head = self.download_file('HEAD')
ifhead:
_print('[*] Analyze .git/HEAD')
refs = re.findall(r'ref: (.*)', head, re.M)
#解析 head 文件,从中提取 commit SHA1 Hash Object ID
self.git_refs(refs)接着调用 git_logs 尝试解析 log文件,该文件在前文提到过,存放着所有 branch 的 SHA1 Hash Object ID。这也就是 Git_Extract 能够还原所有 branch 文件的原因
[git_extract.pyline204]
defgit_logs(self):
logs = self.download_file('logs/HEAD')
iflogs:
_print('[*] Analyze .git/logs/HEAD')
#解析 log文件,从中提取 SHA1 Hash Obejct ID,并依次解析和还原
self.git_extract_by_hash(logs)(3)通过 index文件 还原
git_init 接着调用 git_index_cache() 尝试解析 index文件
[git_extract.pyline254]
defgit_index_cache(self):
#解析 Index Entries 和 Cache Tree
index.index_init()
......
#解析 Tree object 来还原文件
self.git_parse_tree(tree_hash)
......
#还原源文件
self.git_save_blob('../', path, _hash)至此,主力的三种还原方式已分析完毕,接下来的应该都是不太常见的还原方式。
(4)分析 stash
首先,什么是 stash?
假设这样一个场景:当开发人员做某个功能做到一半的时候,需要紧急做另一个功能,开发希望保存当前的更改,然后回退到之前的 commit 进行开发时,stash 就派上用场了:
只要开发人员使用 git add . 保存更改后,再使用 git stash 。即可暂存当前的项目,并且会在 /refs/stash 中留下一个 object 指针。但是 index文件并不会记录 stash 的内容。
在 Git_Extract 中,git_init 调用了 git_stash() 方法,尝试根据 /refs/stash 来还原 stash文件
[git_extract.pyline242]
defgit_stash(self):
stash = self.download_file('refs/stash')
....
self.git_extract_by_hash(stash)(5)另类文件
最后,git_init 调用了 git_other() 方法。这个方法下载的是一些非常规的文件:
defgit_other(self):
hash_path = [
'packed-refs',
'refs/remotes/origin/HEAD',
'ORIG_HEAD',
'FETCH_HEAD',
'refs/wip/index/refs/heads/master', # PlaidCTF 2020 magit wip mode
'refs/wip/wtree/refs/heads/master',
]
info_path = [
'config',
'description',
'info/exclude',
'COMMIT_EDITMSG',
]
#将之一一下载或根据文件内的 Hash ID尝试还原文件
forpathinhash_path:
data = self.download_file(path)
ifdata:
self.git_extract_by_hash(data)
forpathininfo_path:
self.download_file(path)至此,Git_Extract 大致的工作流程分析完毕。
总结:该工具主要通过三种方式还原 git 文件:客户端pack文件、index文件、log日志
Reference:
Git Internals – Plumbing and Porcelain