
深度学习的成功往往依赖于海量数据的支持,其中监督技术成熟,但是对海量的数据进行标记需要花费大量的时间和资源。而无监督学习不需要对数据标签的依赖,可以自动发现数据中潜在的结构,节省了大量时间以及硬件资源。因此学界以及工业界对无监督学习算法的投入与研究越来越多。
由于带有标签的漏洞数据极为宝贵,极光无限在设计维阵产品中AI端的时候,大量使用了无监督学习,尤其是对比学习,以此来弥补一开始标注数据不足的问题。
无监督学习旨在从大量数据中学习同类数据的相同特性,并将其编码为高级表征,之后根据不同的具体任务对学习模型进行微调即可达到优异的效果。例如在分类任务中,首先使用无监督学习算法获得数据的抽象表示,之后只需少量带有标签的数据训练分类器即可。
无监督学习大体可分为生成式学习与对比式学习,生成式学习以自编码器(例如GAN,VAE等等)这类方法为代表,由数据生成数据,使之在整体或者高级语义上与训练数据相近。而对比式学习着重于学习同类样本之间的共同特征,区分非同类样本之间的不同之处。与生成式学习比较,对比式学习不需要关注样本上繁琐的细节,只需要在抽象语义级别的特征空间上学会对数据的区分即可,因此模型以及其优化变得更加简单,且泛化更强。
对比学习的目标是学习一个编码器,此编码器对同类数据进行相似的编码,并使不同类的数据的编码结果尽可能的不同。在计算机视觉任务上,对比学习用于提取通用的视觉表征,实现的算法有多种,例如通过互信息最大化相同目标之间的联系(Deep InfoMAX[1]),使用自回归模型预测潜在空间(CPC[2]),这些方法的共同特性是将输入的样本分为政府样本进行学习:正样本之间的高级表示应该相似,而正样本与负样本之间的应该不同。
我们将着重介绍在对比学习领域取得显著成果的三篇文章:MOCO[3],simCLR[4]以及BYOL[5]。
MOCO
受NLP任务的启发,MOCO将图片数据分别编码成查询向量(query vector)与键向量(key vector),在训练过程中尽量提高每个查询向量与自己相对应的键向量的相似度,同时降低与其他图片的键向量的相似度。
MOCO使用两个神经网络对数据进行编码:encoder和momentum encoder。encoder负责编码当前样本的高级抽象表示,而momentum encoder负责编码多个样本(包括当前样本)的高级抽象表示。随后利用对比损失来对网络进行训练:对于当前样本,最大化其encoder与momentum encoder中自身的编码结果,同时最小化与momentum encoder中其他样本的编码结果。
由于对比学习的特性,参与对比学习损失的样本数往往越多越好,MOCO对参与momentum encoder中的样本采用队列更新的方式:首先对所有参与过momentum encoder的样本建立动态字典(dynamic dictionary),在之后训练过程中每一个batch会淘汰掉字典中最早被编码的数据。在参数更新阶段,MOCO只会对encoder中的参数进行更新,而momentum encoder参数的更新会使用动量更新法:使momentum encoder的参数逐步向encoder参数逼近。
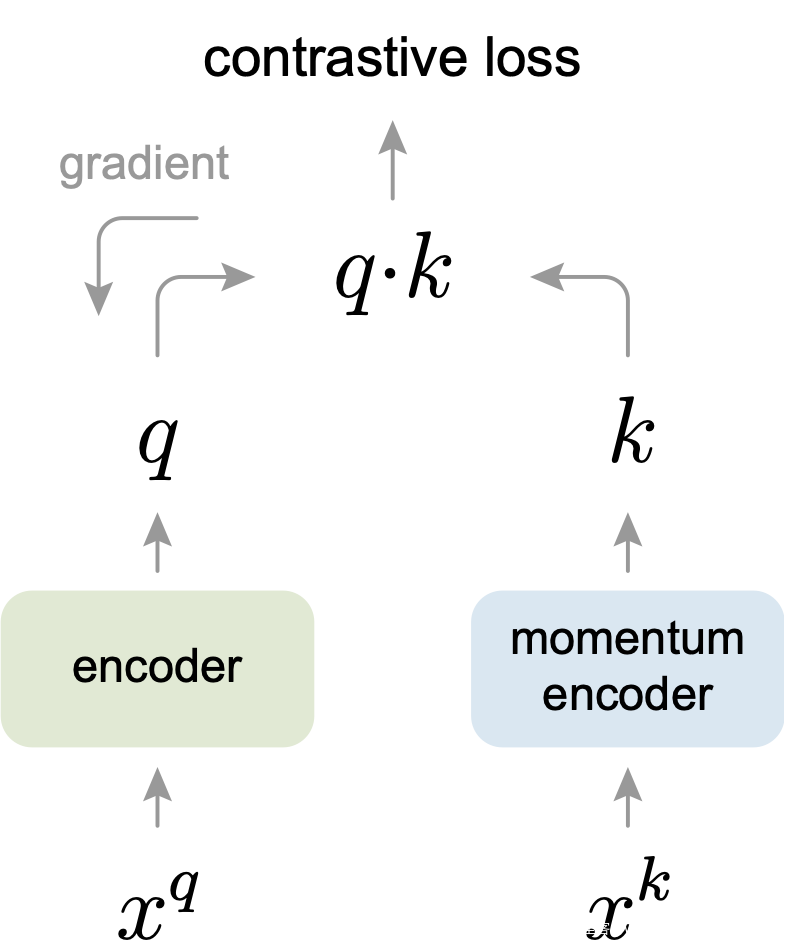
▲MOCO网络架构
simCLR
simCLR背后的思想非常简单:好的视觉表征对于同一目标不同视角的输入都应该具有不变性。simCLR对输入的图片进行数据增强,以此来模拟图片不同视角下的输入。之后采用对比损失最大化相同目标在不同数据增强下的相似度,并最小化不同目标之间的相似度。
simCLR的架构由两个相同的网络模块组成。对于每一个输入网络的minibatch: simCLR首先会对mini batch中每张输入的图片进行两次随机数据增强(随机剪裁、滤镜、颜色过滤、灰度化等)来得到图片两种不同的视角,随后将得到的两个表征送入两个卷积编码器(如resnet)获得抽象表示,之后对这些表示形式应用非线性变换进行投影得到投影表示。最后使用余弦相似度来度量投影的相似度。由此可以得到优化目标:对于minibatch中同一图片,最大化其两个数据增强投影的相似度,并最小化不同图片之间的投影相似度。
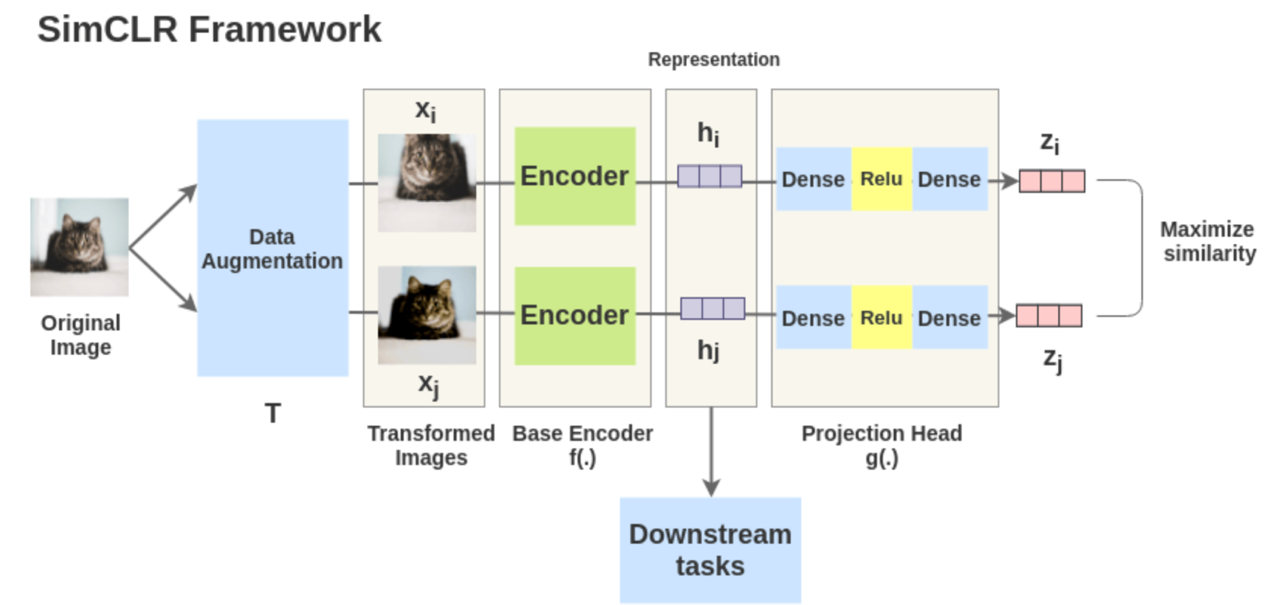
▲simCLR网络框架
BYOL
通常,大多数对比学习的方法通过最大化同一图像的不同增强视图表示之间的相似度,同时最小化不同图像的增强视图表示之间的相似度来实现。这些方法的成功往往依赖于大批量,存储库或定制的挖掘策略来处理图像,以对其进行检索。此外,这些方法的性能很大程度上取决于图像增强的选择。与之前的方法相比,BYOL不使用不同图像之间的对比,仅仅需要同一图像不同的视角即可进行对比学习。
与simCLR类似,BYOL也是由两个并行的网络组成,分别为在线网络与目标网络。两个网络都包含卷积编码层和投影层。但是在线网络在投影层后会紧跟一个预测层。每张图片首先经过两次数据增强获得增强视图,增强视图分别经过在线网络以及目标网络。通过L2损失来最小化在线网络预测层与目标网络投影层的输出。以此更好的提取视觉特征。
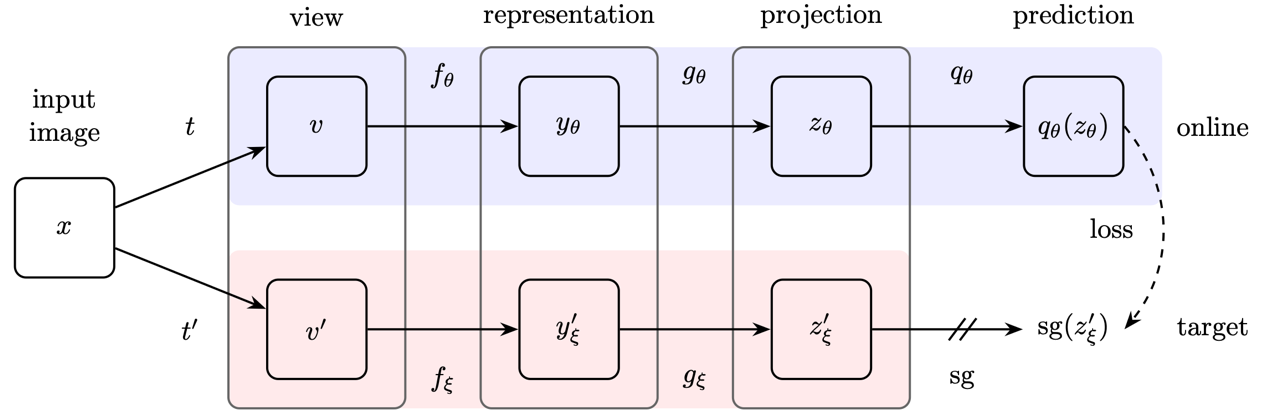
▲BYOL网络框架
除了寻找精巧的网络架构设计之外,研究者亦发现在现有的无监督算法中加大网络的规模往往也可以获得更加优秀的结果,即越大的无监督模型拥有更高的标签效率(达到相同的精度但使用更少的标签数据),这可能是因为更大型的网络可以更好的学习数据的一般特征。但是越大的网络往往伴随着参数冗余。
为了解决这一问题,论文[6]给出了一种结合无监督与自监督技术的新型网络训练范式:首先使用大模型对训练数据进行无监督训练以提取通用视觉表征,之后根据特定任务使用少量标签对模型进行微调。最后使用自监督技术对网络进行精炼和知识蒸馏,以得到精确度高且结构更加紧凑的模型。
对于实验部分,研究者使用simCLR的改进版本:通过将卷积编码器resnet50改为resnet152(对其宽度进行适当调整,并增加了SK通道注意力机制),以及加深投影层的数量。在Imagenet数据集上仅使用1%的带标签数据进行微调便实现了14%的相对精度提升。随后进行以知识蒸馏为主的自监督训练:将微调后的网络当作教师网络,学生网络可使用相同架构或较小的网络来得到更加紧凑的模型。
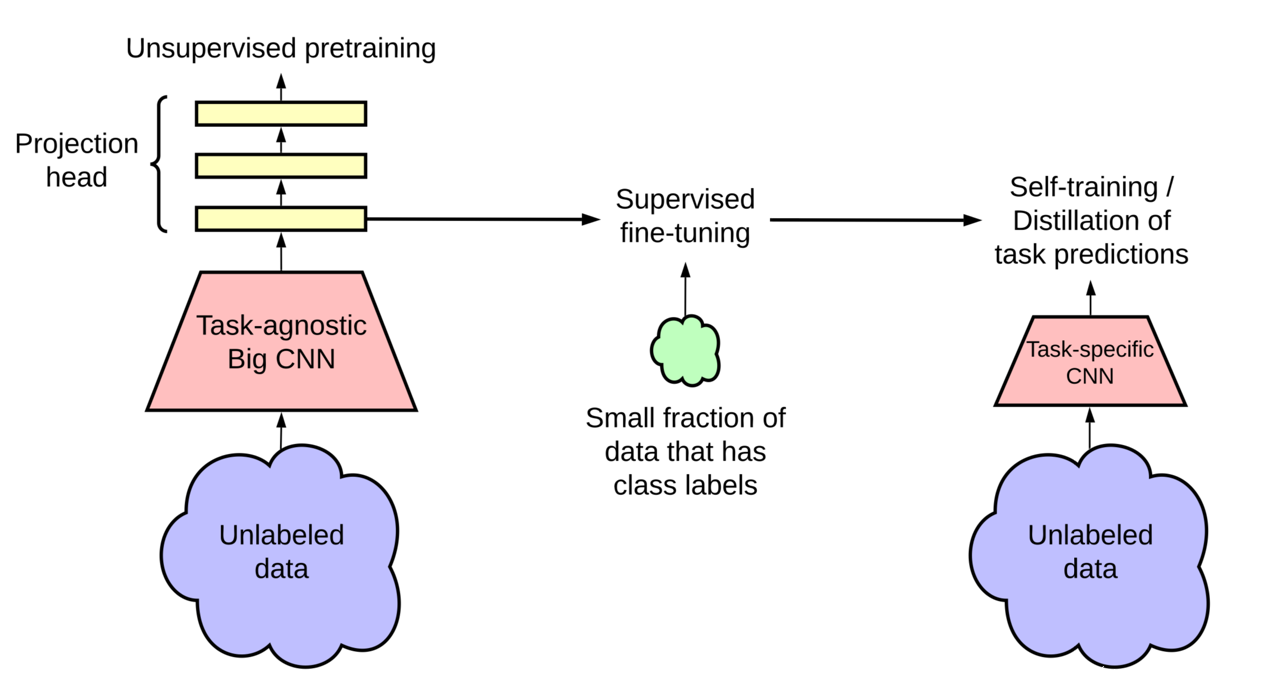
▲范式架构
参考文献:
[1] Hjelm, R. Devon, et al. “Learning deep representations by mutual information estimation and maximization.” arXiv preprint arXiv:1808.06670 (2018).
[2] Oord, Aaron van den, Yazhe Li, and Oriol Vinyals. “Representation learning with contrastive predictive coding.” arXiv preprint arXiv:1807.03748 (2018).
[3] He, Kaiming, et al. “Momentum contrast for unsupervised visual representation learning.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
[4] Chen, Ting, et al. “A simple framework for contrastive learning of visual representations.” arXiv preprint arXiv:2002.05709(2020).
[5] Grill, Jean-Bastien, et al. “Bootstrap your own latent: A new approach to self-supervised learning.” arXiv preprint arXiv:2006.07733 (2020).
[6] Chen, Ting, et al. “Big self-supervised models are strong semi-supervised learners.” arXiv preprint arXiv:2006.10029(2020).