
概要:本文将介绍几篇不同于RNN的循环结构在ANN中的应用,这些循环结构的核心就是残差模块。
人工神经网络(ANN)发展这么多年,从建立单个神经元的数学模型,感知机到后来的MLP,CNN,RNN再到最近两年大火的Transformer,虽然最初受到了神经科学的启发和影响,但是ANN最近多年的进步并不依赖于神经科学方面的知识。随着模型越来越大,越来越深,复杂程度越来越高,我们更难将其简单地与大脑结构进行对比来建立其中的联系。
但是最近一些论文对于ResNet或者说对于其残差模块的深入研究,有可能给建立人脑与ANN之间的联系架起一座新的桥梁,残差模块是一种特殊的循环结构。
循环结构在人脑中广泛存在,但是在ANN中,除了在循环神经网络(RNN)中被借鉴,在其他主流架构中并不多见,最近两年,RNN更是被Transformer为主的Attention模型全面超越,再难在自然语言处理(NLP)任务中出现。我们将介绍几篇不同于RNN的循环结构在ANN中的应用,这些循环结构的核心就是残差模块。
01 残差模块
随着残差连接网络的出现,残差连接模块已成为新的设计范式。然而,对于残差模块在网络中起到的核心作用依然没有明确的解释。从优化角度来说,在反向传播过程中残差连接的加入有效地避免了梯度消失与爆炸问题,能够使梯度更好得在深层网络中进行传播[1,2]。
另一方面,残差连接的加入似乎使网络学习的过程发生了变化:残差连接促使网络从表征学习(每个网络层都对来自上一层的输入进行重新表征变换)变换到了迭代式表征(残差模块对来自上一层的输入进行细化与微调)。这点可以在一些实验中体现出来:对于已训练好的ResNet网络,若是删除其中某些残差块或调换某些残差块之间的顺序,并不会太多影响网络的性能。但此特性并没有在VGG网络中发现。
另一项研究[3]通过实验以及理论在一定程度上证明了ResNet中的各个残差块并不总是学习全新的表征,网络中大部分残差块倾向于逐步完善前几层提取的特征。通过对残差模块的泰勒展开公式研究表明,对于输入的特征,残差模块会自然地鼓励其输出沿着损失函数对输入特征的负梯度方向前进。
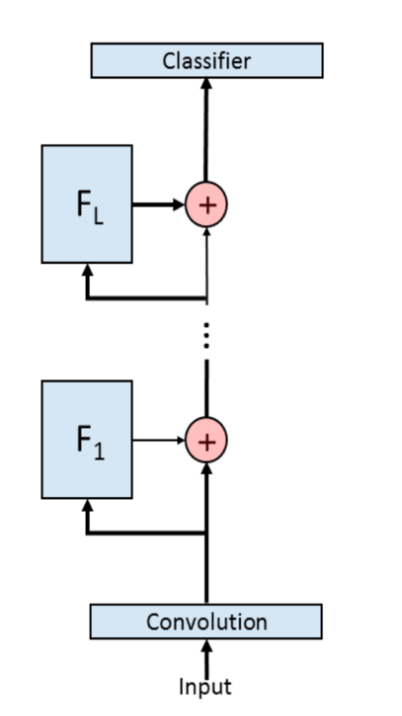
▲典型的ResNet架构
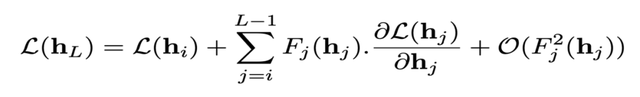
▲对ResNet中某个残差模块的泰勒展开
对残差连接的分析对网络的设计给出了新的灵感。根据迭代特征细化的特性,残差网络中的某些层参数可能存在冗余,这暗示了网络中的某些层可以重复使用(循环)而不会对网络性能产生巨大影响。另一方面,迭代特征细化的特性也契合了自适应计算的主题:网络可以自主地决定样本信息需要流经网络中的哪些层,从而实现动态计算资源分配。
02 CORnet:脑结构驱动的模型架构
CORnet[4]是一种使用卷积网络对人类视觉神经系统进行直接对齐的尝试。有证据表明,迭代式表征更加符合人脑部分脑区的神经表现(如视觉区域等)。在人脑中,实现迭代式表征的一个可能机制便是神经元之间的循环连接。相较于人工深度神经网络,人类视觉神经系统拥有以下特点:层数少,层内神经元数量多且存在大量的循环连接。CORnet使用4个具有相似结构的带有残差连接的卷积模块来模拟视觉系统中的4个主要神经区域(V1,V2,V4,IT)。每个区域的神经元数量各不相同且会预先规定一个循环次数。每个区域的结构如下:
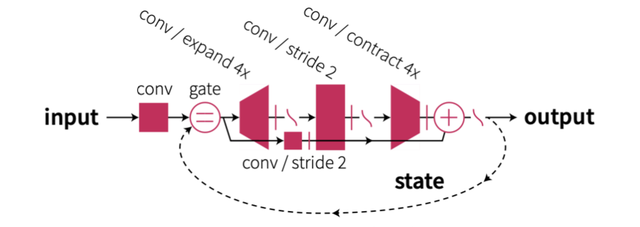
每个层的工作原理概述如下:输入首先经过第一个卷积层进行特征提取。之后经过类似于ResNet中的Bottleneck结构。信息流会按照约定的循环次数在类Bottleneck中进行循环流动,在达到循环次数后信息停止循环并输出。
CORnet具有参数少,结构简单的特性(只比ResNet多了循环)。通过实验证明,在同样层数数量级下:在Imagenet数据集上CORnet的表现要优于传统卷积神经网络。之后的消融实验也表明循环连接是网络表现优异的关键原因。
03 SACT:懂“跳层”的神经网络
在传统的ResNet中,每个样本都遵循完全相同的路径通过网络,每一层都会完善前一层的特征。但是并非所有的样本都同样难以分类,一些样本往往足够简单,网络的前几层提取的特征已足以进行分类。另一些样本可能需要更多的细化步骤后才能被正确分类。SACT(Spatially adaptive computation time)[5]结合以上假设以及残差网络特征迭代的观点,将自适应计算时间机制添加到了ResNet网络中。
具体而言,SACT以ResNet中的Stage(每个Stage由输入特征图尺寸相同的Block组成)为单位,特征图在流经某个Stage前,特征图上的每一个像素都会额外赋予一个0-1之间的值,称之为停止分数。
特征图在Stage中顺序经过每一个Block,每经过一个Block后都会对输出特征图上的像素进行停止分数的计算,该Block有两个输出:1)输出特征图乘以其相应的停止分数,2)停止分数本身。如果在顺序经过几个Block后,某个像素在这些Block上的累计停止分数达到了阈值,则该像素便不会经过Stage中后续的Block,而是直接作为该Stage在该位置的最终输出。也就是说:SACT将Stage的输出变为了自身中Block输出的加权平均(总和为1),并且权值的计算是顺序的。
通过这种机制,可以让网络自行评估信息流该经过多少个Block。在训练过程中:将每个样本在前向过程中通过的Block数量作为度量添加到损失函数中,该损失鼓励样本经过少的Block。以此来进行训练。
实验证明,在高分辨率的输入下SACT可以获得比ResNet更好的性能。并且可以显式地展现出网络对输入图片上的像素分配的计算资源,在一定程度上可以解释卷及网络的行为。
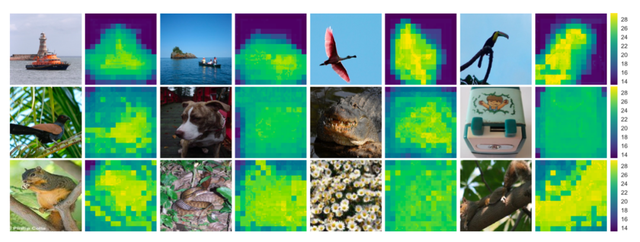
▲训练好的SACT网络对不同图片的计算资源可视化,像素越亮表示分配的计算资源越多
这儿提到SACT这种结构是因为,早在2016年一项研究中发现,尽管人类的视觉皮层不包含像ResNet那样的超深层网络,但是它确实包含循环连接。然后,作者探索了具有权重共享的ResNet,并展示了它们与具有跳过连接的展开式标准RNN等效。作者发现,具有权重共享的ResNet与没有权重共享的ResNet几乎一样好,同时所需的参数大大减少。因此,他们认为超深度网络的成功实际上可能源于它们可以近似递归计算的事实。那么SACT在循环中起到了判断循环次数的作用,而不用像CORnet中认为设定循环次数。
残差结构已经被广泛应用于当前神经网络的架构设计中,但是我们对其的认知还远远不够,残差可能只是表象,循环才是其发挥作用的真正内核。对其的深入研究,不但可以在实际应用中取得成果,而且我们可以将其与人脑结构建立联系,也许在不久的将来,我们真的可以建立一个统一人脑和ANN的智能泛化理论。
引用文献:
1. Andreas Veit, Michael J Wilber, and Serge Belongie. Residual networks behave like ensembles of relatively shallow networks. In Advances in Neural Information Processing Systems, pp. 550–558, 2016.
2. Klaus Greff, Rupesh K Srivastava, and Ju ̈rgen Schmidhuber. Highway and residual networks learn unrolled iterative estimation. arXiv preprint arXiv:1612.07771, 2016.
3. Stanisław Jastrzebski, Devansh Arpit, Nicolas Ballas, Vikas Verma, Tong Che, and Yoshua Bengio. Residual connections encourage iterative inference. arXiv preprint arXiv:1710.04773, 2017.
4. Kubilius, Jonas, et al. “Brain-like object recognition with high-performing shallow recurrent ANNs.” arXiv preprint arXiv:1909.06161 (2019).
5. Figurnov, Michael, et al. “Spatially adaptive computation time for residual networks.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
6. Liao Q, Poggio T. Bridging the gaps between residual learning, recurrent neural networks and visual cortex[J]. arXiv preprint arXiv:1604.03640, 2016.