
前言
在安全领域,提到防御,其实分为两类,一类是做检测detection,一类是做缓解mitigation,当然最好就是将两类集成在一起。在后门防御领域也是一样,就检测来说,我们要检测模型是否被植入后门,如果被植入了后门,那么攻击的目标标签是什么?发动攻击所需的触发器是什么?
检测之后,就是缓解阶段,或者说修复阶段,对于输入的测试样本,我们可以检测其是否为毒化样本,如果是则直接丢弃;而对于后门模型,则通过修复模型来移除后门。
本文分析并复现后门防御领域最经典的工作之一,发表于S&P上的工作:Neural Cleanse.
后门攻击
在安全客上已经有文章介绍过后门攻击的概念,可以前去详细了解。这里再简单回顾一下。

如上图所示,攻击者首先选定目标标签4以及触发器,这里是右下角的白色小正方形,然后对训练集中的随机一批子集做毒化,即将触发器叠加于原样本上,并修改对应标签,之后再在其上训练模型。在测试阶段,如果测试样本带有触发器,则会将其分类到目标标签4,如果不带有触发器,则会进行正常的分类。
关键想法
从后门攻击的特性我们知道,不论原样本属于哪个标签,只要其带有触发器,就将生成一个目标标签的分类结果,并且我们知道相比于将样本分类为其他没受感染的标签,将样本分类为目标标签所需要的扰动更小。如果将分类问题看作是在多维空间中创建分区,每个维度捕获一些特征,那么被植入后门的模型相当于在其他标签与目标标签的区域中创建了捷径。我们可以从下面的示意图很直观地发现这一点:
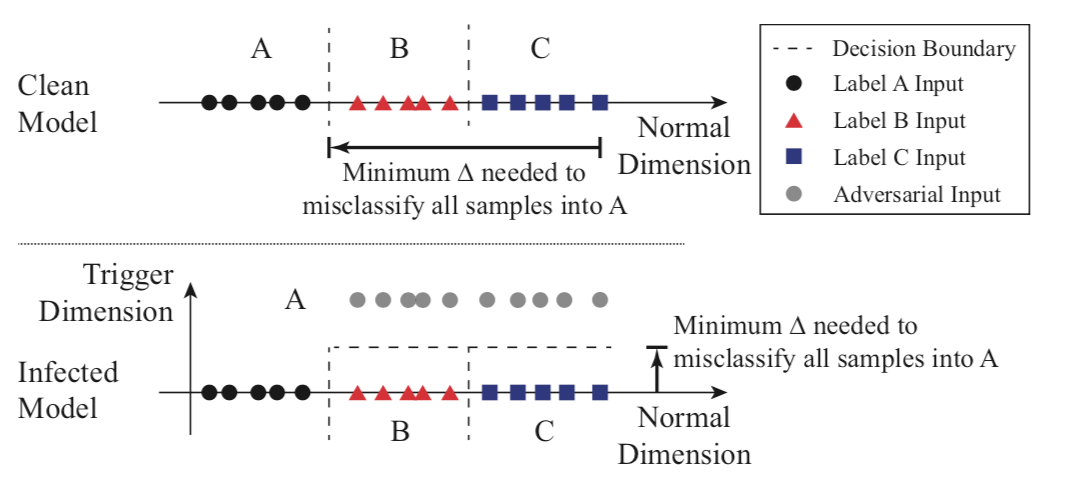
上图是一个简化的一维分类问题,存在3个标签(标签A表示圆,标签B表示三角形,标签C表示正方形)。图上显示了它们的样本在输入空间中的位置,以及模型的决策边界。上面是良性模型,下面是毒化模型。在毒化模型中我们看到,在属于B和C的区域中产生了另一个维度,任何带有触发器的样本在触发维度中都有较高的值(后门模型中的灰色圈),B或C中的任何输入只需要移动一小段距离,就会被错误地分类为A。
这也就意味着,我们可以通过测量从其他区域分类到目标区域的所有输入所需的最小扰动量来检测这些捷径。
形式化
我们设将类i的样本分类到类t,所需的扰动是!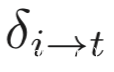
如果存在一个触发器,可以将类i的样本分类到类t,那么则有
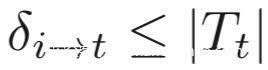
我们已经说过,不论原先的类别是什么,只要有触发器就能被分类为类t,所以就有:
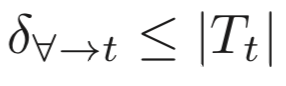
上式左边的项代表的就是将任意类分类为类t所需的最小扰动
如果触发器存在,那么进一步我们还有下式成立

因此,我们只需要对所有的类别测量
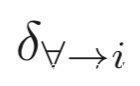
如果找到一个异常小的值,那么就说明存在触发器,此时的i就是后门攻击的目标标签。
检测后门
有上面的内容我们已经知道怎么检测了,可以分为三步:
步骤1
先给定一个标签i,将其视作目标标签,然后计算
同时通过优化找到Tt
步骤2
对于模型的所有标签重复上一步
步骤3
在逆向每个标签对应的触发器后,我们用触发器的像素数量作为触发器大小的度量,此时我们使用异常检测算法检测是否存在一个异常小的值,如果存在,那么就说明存在后门,该触发器可以用于触发对应的后门攻击,其对应的标签就是目标标签
那么这里就有一个关键问题了,怎么逆向得到触发器?
关键细节
逆向触发器
首先定义对样本叠加触发器的一般形式
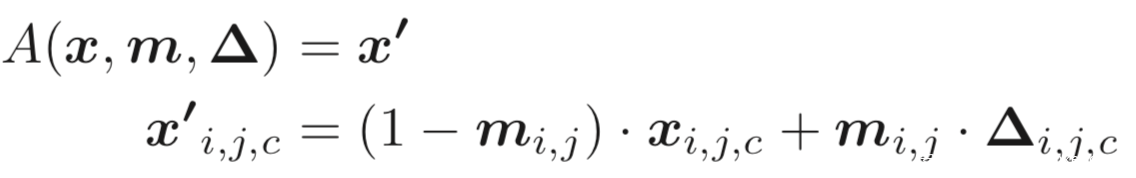
A表示将触发器叠加于原样本x的函数,Δ表示触发器的pattern,它是一个三维矩阵,和输入图像的维度相同(包括高度、宽度和颜色通道)。m是一个称为mask的2维矩阵,它决定触发器能覆盖多少比率的原图像。mask中的值从0到1不等。当用于特定像素(i, j)的mi,j=1时,触发器完全重写原始颜色,即

当mi,j=0时,则完全不修改,即

我们的优化过程有两个目标,对于目标标签yt,第一个目标是找到一个触发器(m, Δ),它会将原图像错误地分类为yt。第二个目标是找到一个尽可能小的触发器,在这里我们用L1范数来度量触发器的大小,这实际上是一个多目标优化问题,优化过程可以表示如下

上式中f是模型的预测函数;l(·)是测量分类误差的损失函数,这里使用交叉熵;λ是第二个目标的权重。较小的λ对触发器大小的控制具有较低的权重,但会有较高的成功率产生错误分类。X是一组原图像。它来自用户可以访问的良性数据集。
使用Adam优化器进行求解上式
异常检测
利用上一小节的方法,我们可以得到每个标签对应的触发器及其L1范数。
接下来需要检测异常值,本文使用了一种基于MAD的技术。首先计算所有数据点与中位数之间的绝对偏差,这些绝对偏差的中值称为MAD,同时提供分布的可靠度量。然后,将数据点的异常指数定义为数据点的绝对偏差,并除以MAD。当假定基础分布为正态分布时,应用常数估计器(1.4826)对异常指数进行规范化处理。任何异常指数大于2的数据点都有大于95%的异常概率。在这里我们将任何大于2的异常指数标记为孤立点和受感染的值。
实战
训练后门模型
既然要检测后门模型,自然需要先训练得到毒化模型,这里使用GTSRB数据集
German Traffic Sign Recognition Benchmark (GTSRB) 是一个德国交通标志检测数据,通过模式识别技术辅助驾驶员进行交通标识识别。该数据集中的样本都是交通标志

定义模型

毒化原样本
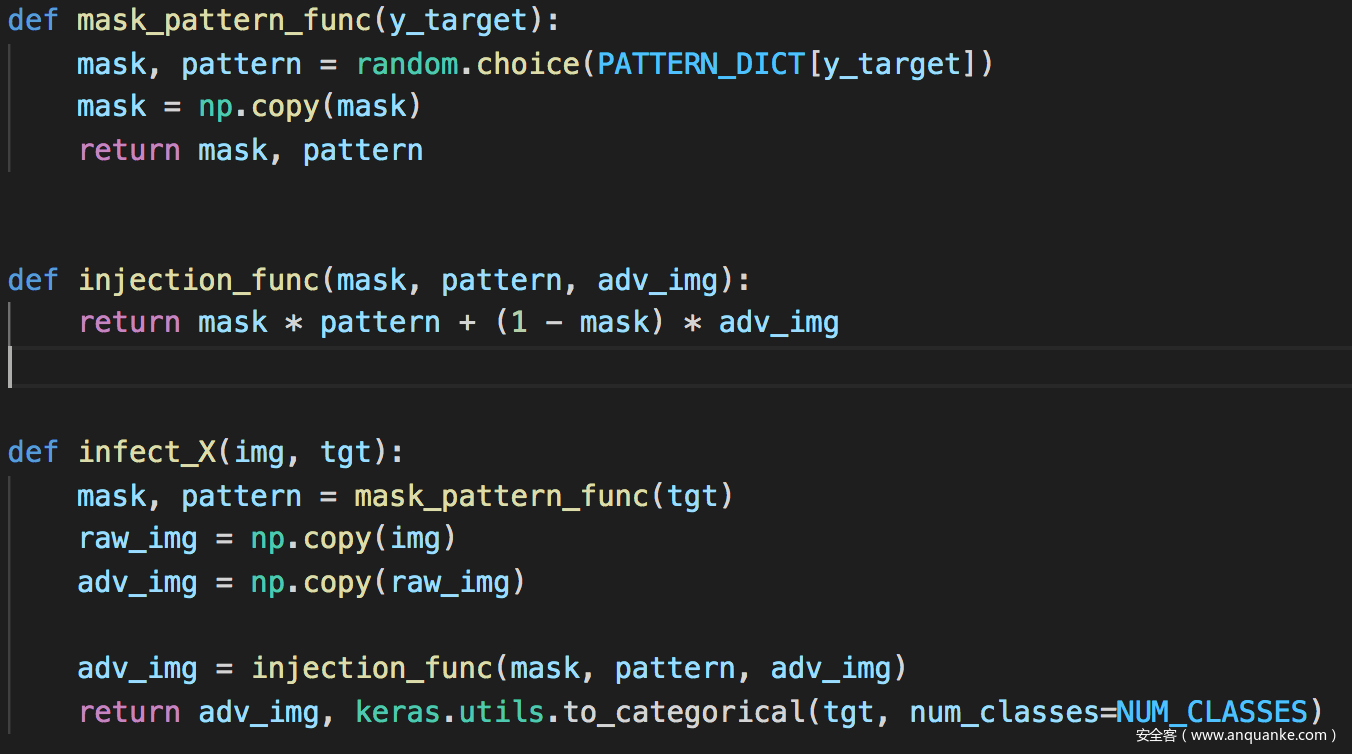
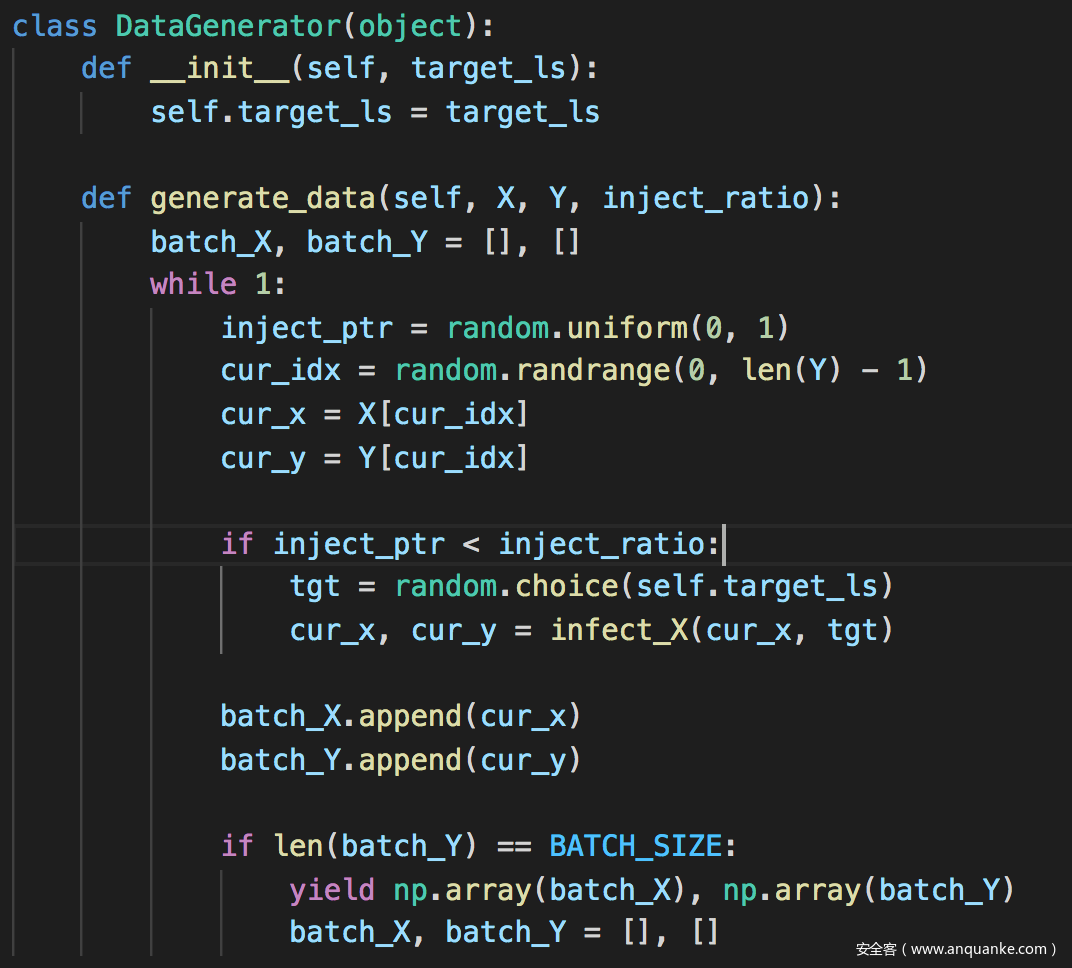
训练模型

训练10个epoch,可以看到良性样本的准确率和后门攻击的准确率都在不错的水平

逆向触发器
得到后门模型后,就用上文介绍的思路通过逆向工程得到触发器
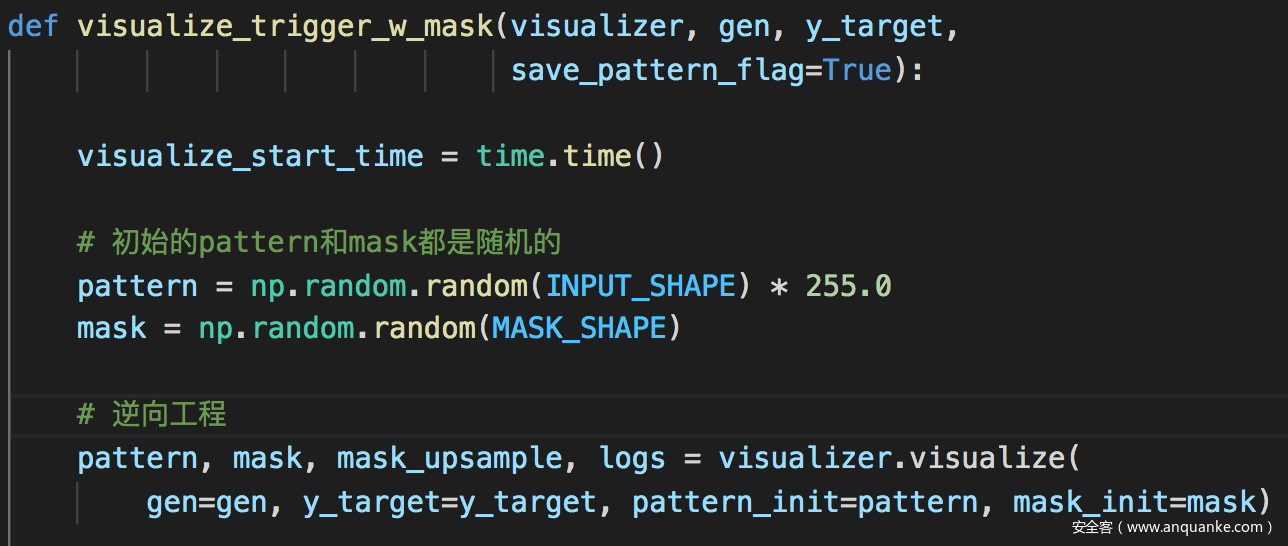
这里的关键在visualize

运行完毕后会对每个标签都生成逆向得到的pattern和mask,以及叠加后得到的最终的触发器
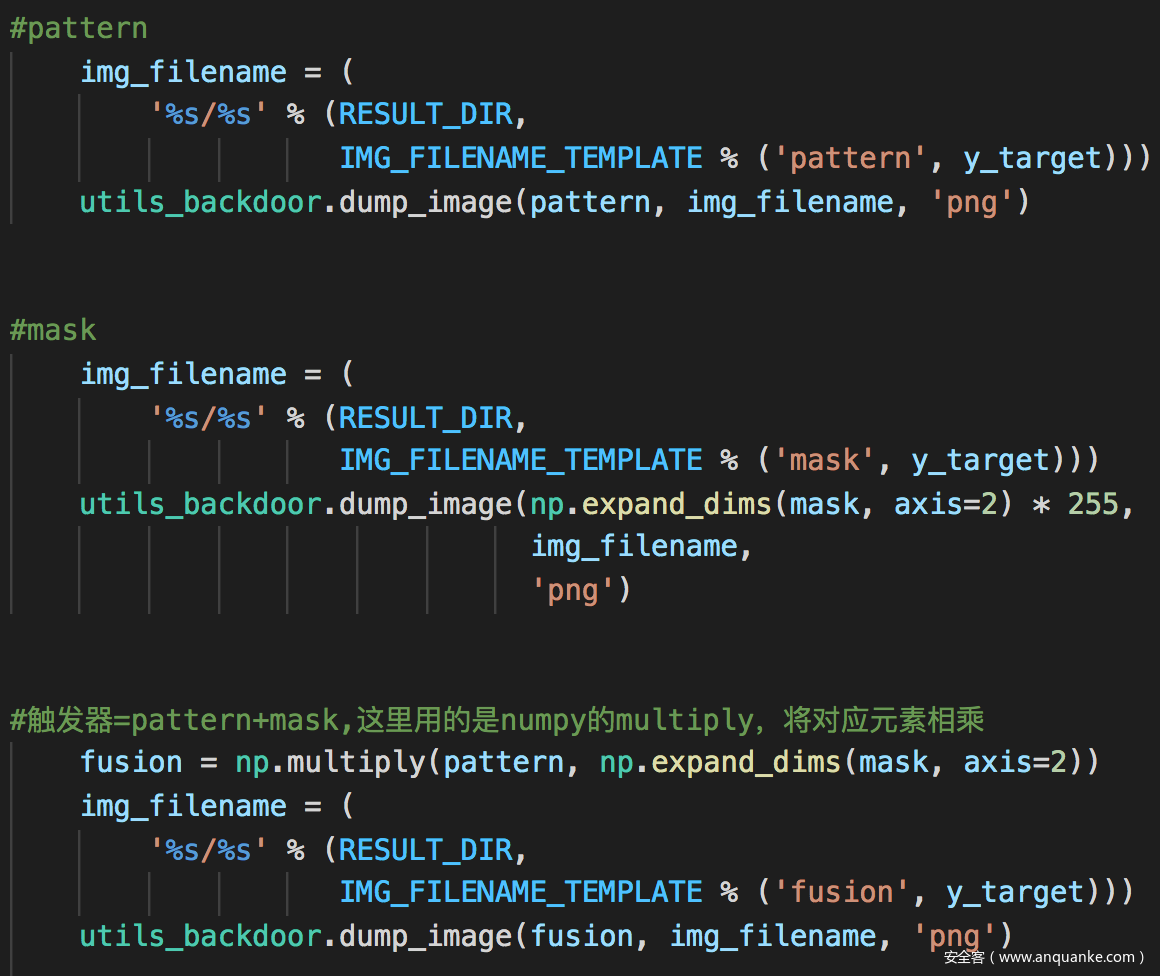
运行如下

得到的mask、pattern、触发器如下所示
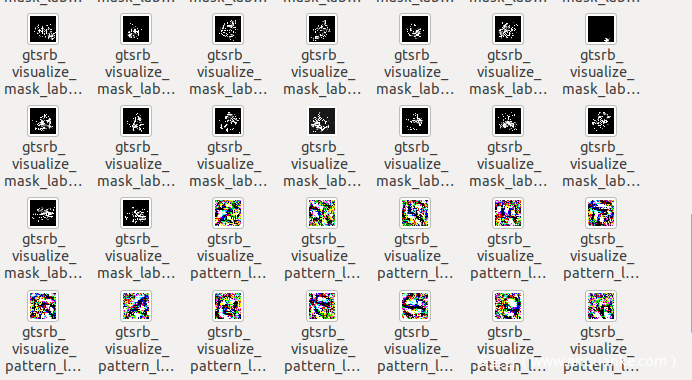
以label42,mask如下

pattern如下
异常值检测

结果如下

在上文我们已经说了,如果异常指数大于2就是异常,这里是2.97,说明该模型是后门模型,此外从结果可以看出这里检测到33是目标标签
总结
这个工作是后门防御领域的经典之作,后续很多做防御的工作都是受此启发,从这里引申开来的。其方案中的一些关键想法一直在后门防御领域应用着,如:
1.如果目标标签是A,则将其他类别的样本分到类A所需的扰动小于分到其他类别所需的扰动;
2.可以在黑盒情况下逆向触发器,这一点也有很多工作在做,如[3-5]
3.在逆向触发器的基础上,为训练集样本加上触发器并打上正确的标签进行学习就可以实现后门模型的修补
等一系列开创性的想法都在指引着该领域后续的发展。
当然其也存在很多不足,尤其是需要为每一类都重复逆向工程的步骤,耗费的时间、算力较大,一直在被后续的防御方案指出。
参考
1.Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks
2.https://github.com/bolunwang/backdoor/
3.POISONED CLASSIFIERS ARE NOT ONLY BACKDOORED, THEY ARE FUNDAMENTALLY BROKEN
4.Reverse engineering imperceptible backdoor attacks on deep neural networks for detection and training set cleansing
5.NNoculation: Broad Spectrum and Targeted Treatment of Backdoored DNNs.