
本文是《AI与安全》系列文章的第四篇。
在前文中,我们介绍了Attack AI的基础概念,即黑客对AI发起的攻击,主要可以分为三种攻击类型,破坏模型完整性、可用性和机密性的攻击。

在本文,我们将介绍破坏模型可用性的一些攻击示例。
模型的可用性主要是指模型能够被正常使用。这一块的攻击面主要是算法系统依赖的底层框架、依赖库,攻击方式主要是对模型代码或底层依赖库的代码进行漏洞挖掘和利用,如溢出攻击、DDos攻击。
由于在野0day的信息无法获取,因此我们考虑对近年机器学习库相关的CVE进行一次简单的数据分析。
0x01 漏洞的来源
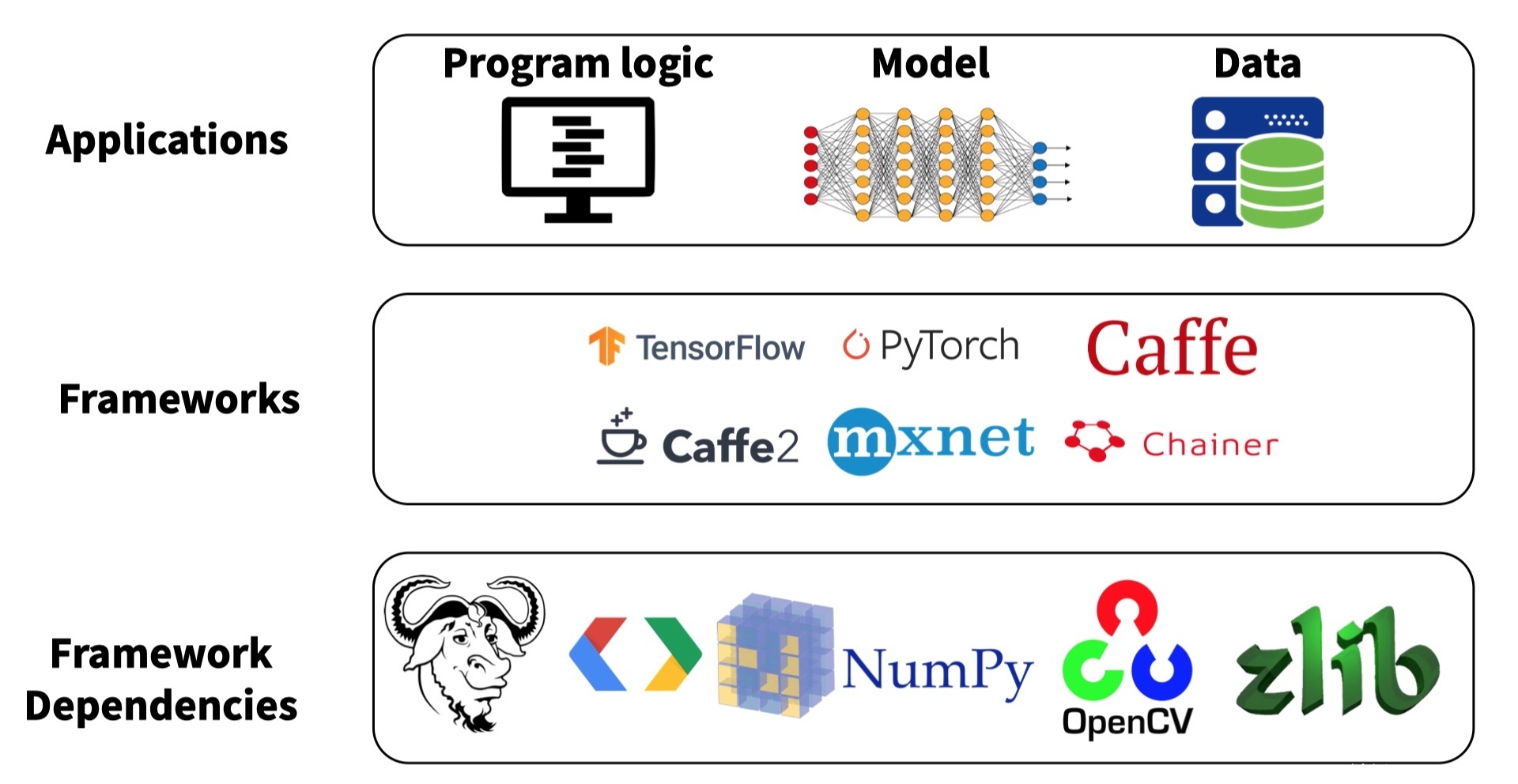
众所周知,当前运行的大多机器学习模型或是深度学习模型,都是基于一些底层的机器学习/深度学习框架和三方包。尤其是深度学习模型,系统框架非常多,主流的包括Tensorflow、Torch、Caffe等。通过使用深度学习框架,算法人员可以无需关心神经网络和训练过程的实现细节,更多关注应用本身的业务逻辑。 开发人员可以在框架上直接构建自己的模型,并利用框架提供的接口对模型进行训练。这些框架简化了深度学习应用的设计和开发难度,甚至仅通过几十行代码就能将一个深度学习模型构建出来。
此外,算法模型和框架还强依赖于大量三方包,如numpy、pandas、计算机视觉常用的openCV、自然语言处理常用的NLTK等等。因此,一旦这些深度学习框架和三方包中存在漏洞,就会被引入模型,破坏模型的可用性。
0x02漏洞分析
1-数据来源
考虑到最便捷的数据集获取方式,我们考虑使用cvedetail对 TOP10 机器学习框架、第三方包的cve数据进行收集。若该库未被cvedetail收纳,则不计入本次分析。
cvedetail上的所有数据取自NVD (National Vulnerability Database,美国国家通用漏洞数据库)提供的XML。相比 CVE官网官网而言,维度更全、搜索功能更全面,但可能缺少一些已发布的漏洞。详细介绍见此:https://www.cvedetails.com/how-does-it-work.php
CVE Detail 首页
CVE官网
(注:因为数据集受限,样本数较少,下列数据分析结果仅供参考。)
常见的机器学习三方包:
- numpy
- pandas
- NLTK
- openNLP
- openCV
TOP10 机器学习框架:
- TensorFlow
- Theano
- Scikit-learn
- Caffe
- H20
- Amazon Machine Learning
- Torch
- Google Cloud ML Engine
- Azure ML studio
- Spark ML lib
2-数据分析
据 cvedetails 所示,从2000年至2019年,上述共有6个常见库被爆出了66个漏洞。
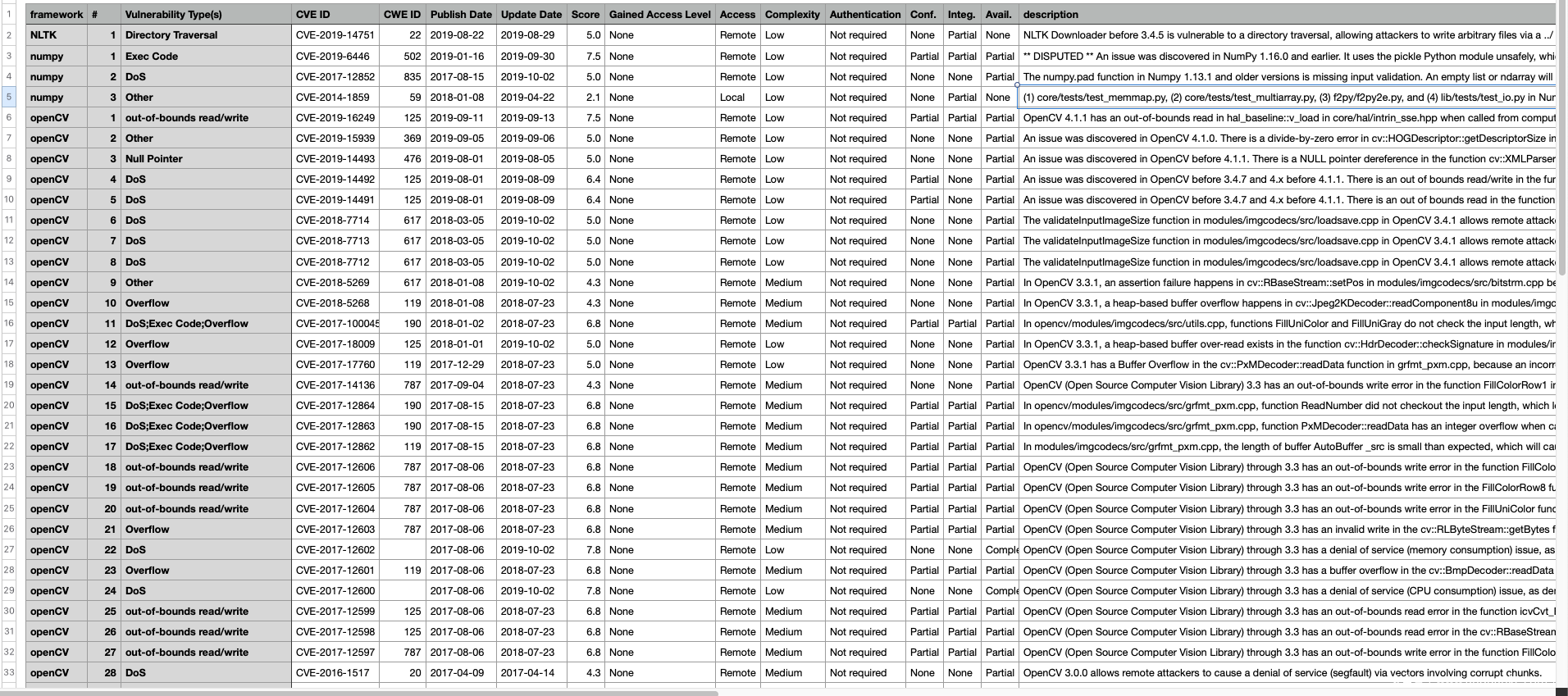
首先,从库的角度来看。NLP类框架的漏洞是最少的,基本在1个左右;openCV的漏洞数最高,有29个。
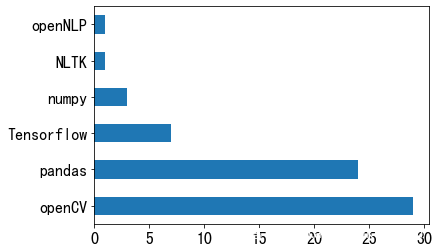
openCV的漏洞主要集中在DoS、远程代码执行和溢出攻击上。

Tensorflow和openCV也是难兄难弟。
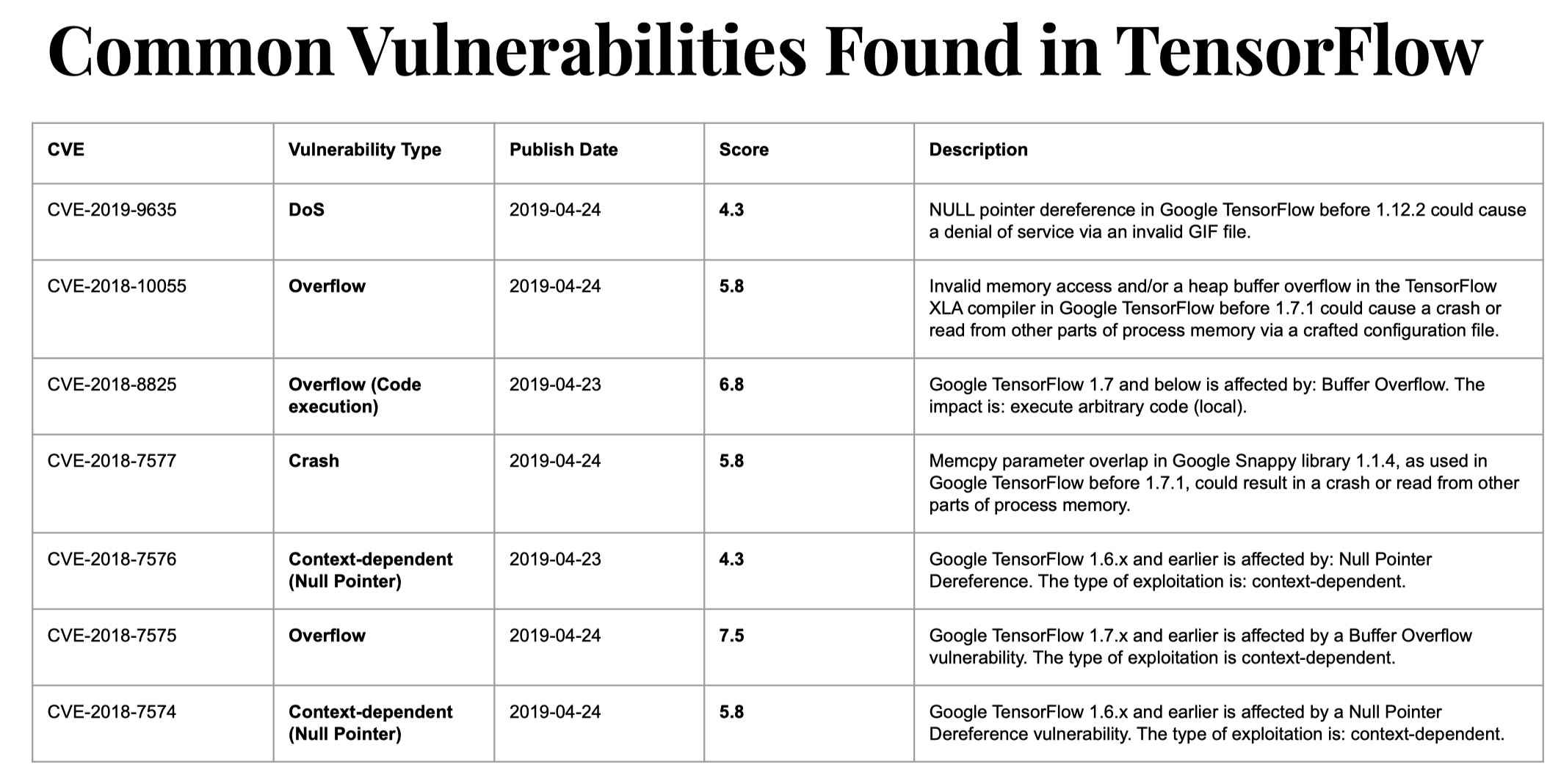
从漏洞类型来看,前三名分别是DoS、溢出和代码执行;CSRF、XSS、XXE相对少见。
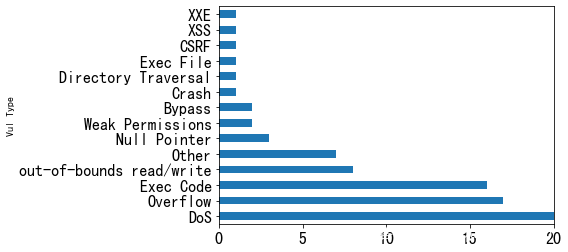
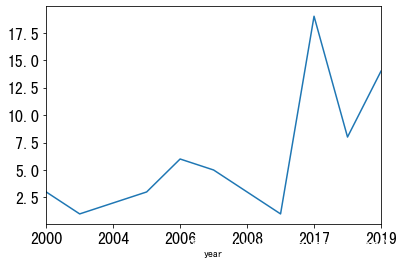
从这些CVE的发布年份来看,2000年-2010年的漏洞主要是传统艺能选手pandas,2017-2019年,漏洞的发现数出现了井喷式的发展,一度高达19个(2017年),这或许和这几年机器学习和深度学习模型的火热发展相关。
感兴趣的小伙伴可以下载该数据集进行更深入的分析: https://github.com/verazuo/ml_cve_analysis
0x03 case by case
最后,我们挑选两个比较典型的CVE进行介绍。
案例1 CVE-2017-12852:对基于TensorFlow的语音识别应用进行拒绝服务攻击
numpy 是TensorFlow所依赖的一个负责科学计算的python库。TensorFlow的很多应用在进行矩阵运算的时候都会用到它。 CVE-2017-12852这个漏洞就是numpy库里的一个简单逻辑漏洞。 这个问题的简单情况如下图所示,发生在numpy中的pad函数。
在pad函数中,存在这样一个while循环,循环结束需要使 pad_before > safe_pad和pad_after > safe_pad同时不成立, 而在这个例子中,可以使pad_before和 pad_after不断增大,而safe_pad不断减小,使得循环始终无法结束,从而导致拒绝服务。

如对于一个基于Tensorflow搭建的语音识别应用,攻击者通过构造语音文件,导致上图中显示的循环无法结束,从而使应用程序长时间占用CPU而不返回结果,最终导致拒绝服务攻击。
如对于这个模型 , 当给定一个正常的狗叫的音频文件,应用可以识别声音内容为 “dog bark”,其过程如下:
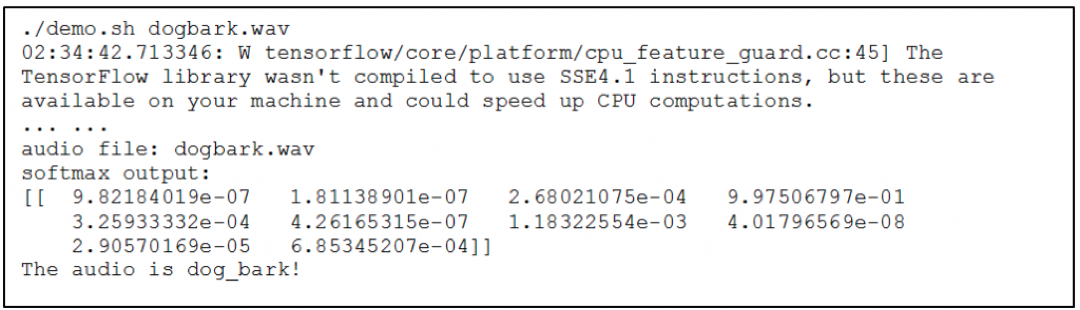
当给定一个恶意的声音文件可导致拒绝服务, 程序无法正常结束:
案例2 CVE-2019-14751 :目录遍历攻击
NLTK包是用来做自然语言处理的三方包,提供了很多NLP相关数据集。这些数据集通过ZIP归档文件传输给NTLK。NLTK Downloader实现了一个自定义函数_unzip_iter(),用于提取这些ZIP文件。3.4.5版本之前的NLTK可能受到目录遍历的攻击。
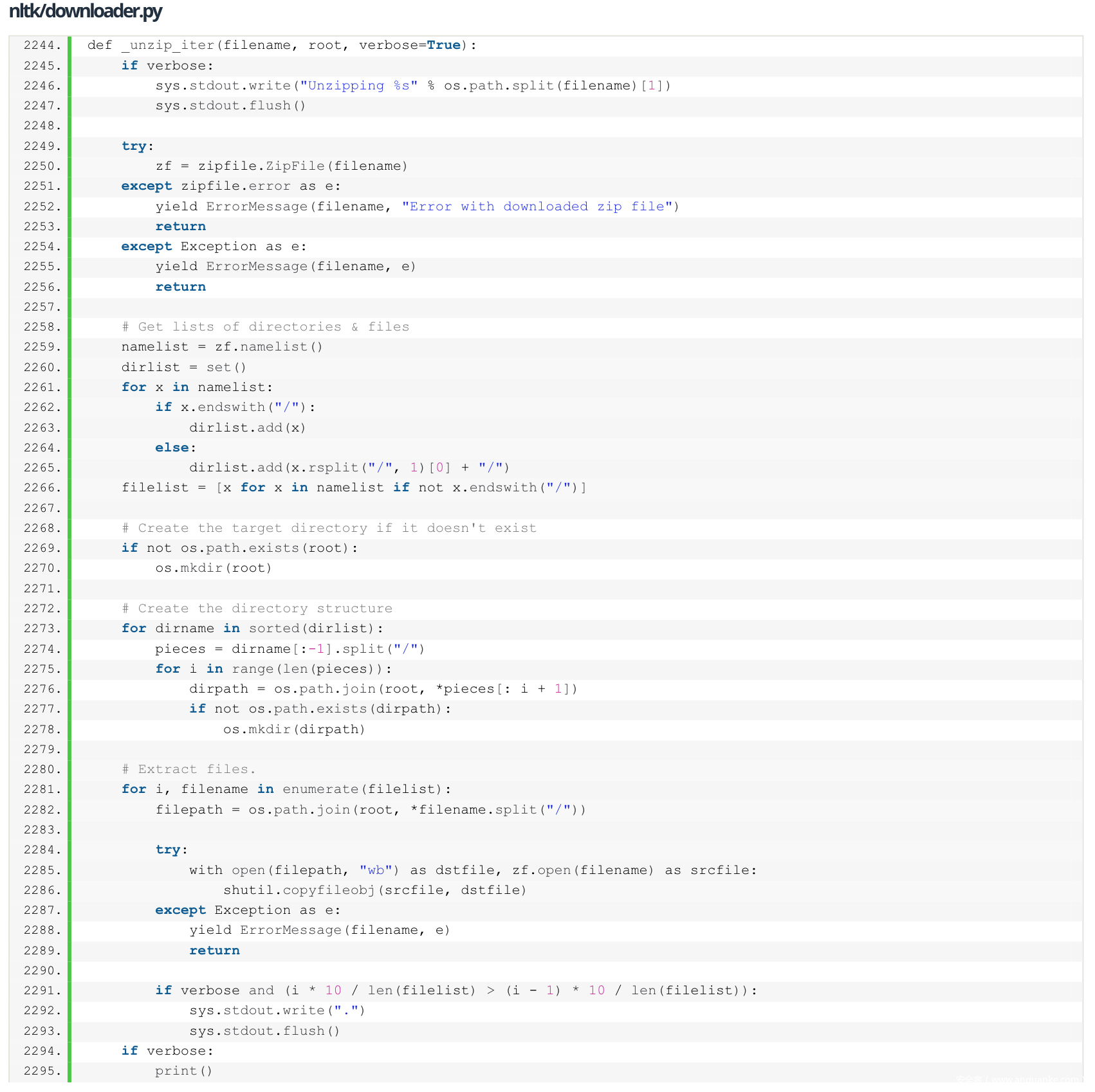
如上图所示,2280-2286行,filepath 被创建来记录ZIP包里的每个文件。这些文件在2286行被写入。
因为在提取路径上没有进行任何验证,所以攻击者可以使用带有相对路径的压缩包将任意文件写入文件系统。例如,NLTK Downloader将尝试在下载时将压缩包解压缩到$HOME/nltk_data/中。如果ZIP归档包含一个名为files/../../../../../tmp/evil.txt的文件,这个相对路径将被解析为/tmp/evil.txt
0x04 References
[1] https://papers.put.as/papers/ml/2019/DenisPOC.pdf
[2] https://www.cvedetails.com/
[3] Xiao Q, Li K, Zhang D, et al. Security risks in deep learning implementations[C]//2018 IEEE Security and Privacy Workshops (SPW). IEEE, 2018: 123-128.
[4] https://salvatoresecurity.com/zip-slip-in-nltk-cve-2019-14751/